进程
进程以概念为主,知道是怎么回事就行,工作一般都操作线程。
进程的基本概念
因为这些概念在OS教课书中讲的太多,故而这一块不会详述。
什么是进程?
通俗的说进程就是正在运行的程序。进程是动态的程序是静态的。
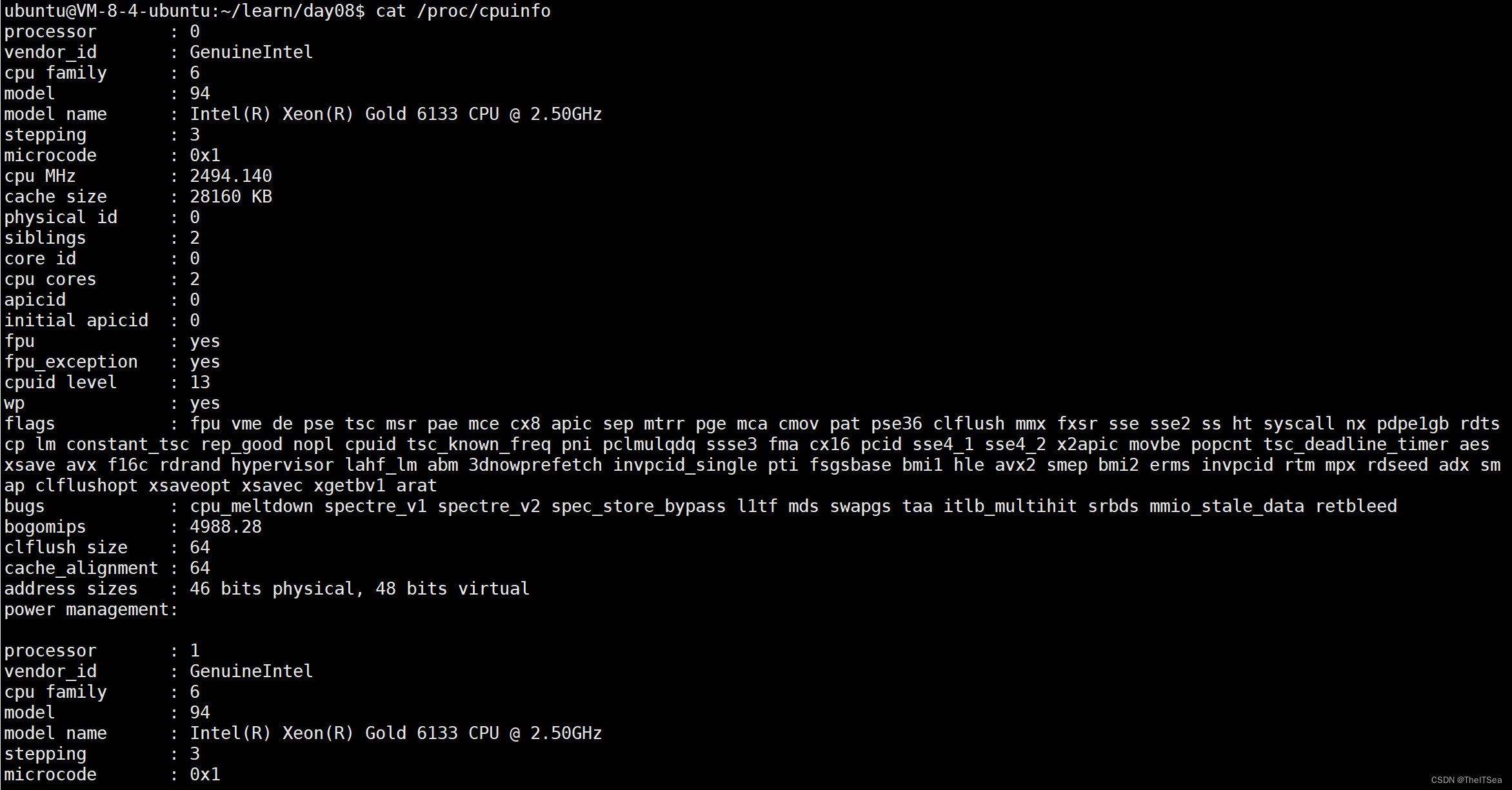
使用cat /proc/cpuinfo命令可以查看本机的cpu信息:
Linux如何管理进程
在OS的教科书上说OS管理进程使用的是PCB进程控制块,但其实Linux系统管理进程是通过task_struct任务描述符来进行的。
大量的task_struct连接起来成为一个任务队列。
也就是说OS想要知道有关进程的什么信息都能通过任务描述符来获得,下图是任务描述符的一个片段:
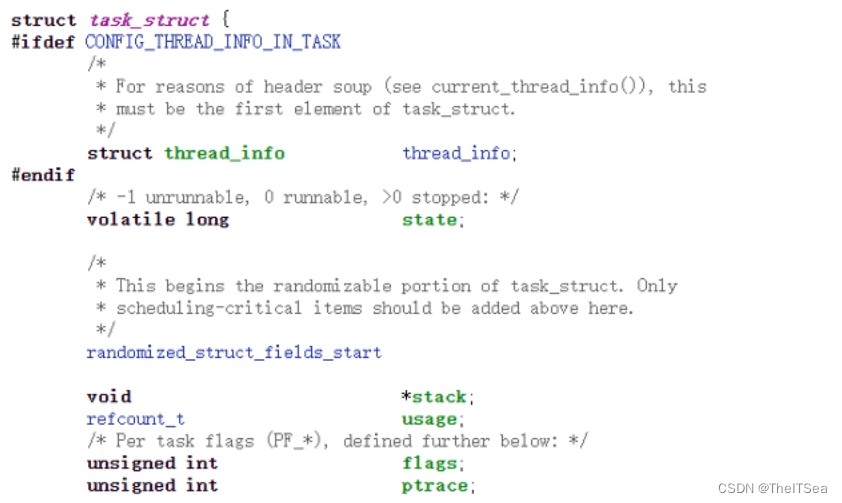
这完整的可以在Linux内核源码中看到。
task_struct描述了进程的一切信息。
但作为普通用户是没有权限去访问task_struct的,所以我们一般是通过PID去查找我们所要的进程的。
PID进程号
PID是一个正整数,给用户去标识不同的进程。
使用ps -l命令可以展示系统现有进程的PID:

PPID是Parent PID的意思,因为在Linux中进程之间存在亲缘关系。
上图表示的意思就是bash进程创建出了ps子进程,在Linux中,我们命令行内每输入的一个命令都是Shell程序的子进程。
使用ps -elf可以展示所有的进程信息:
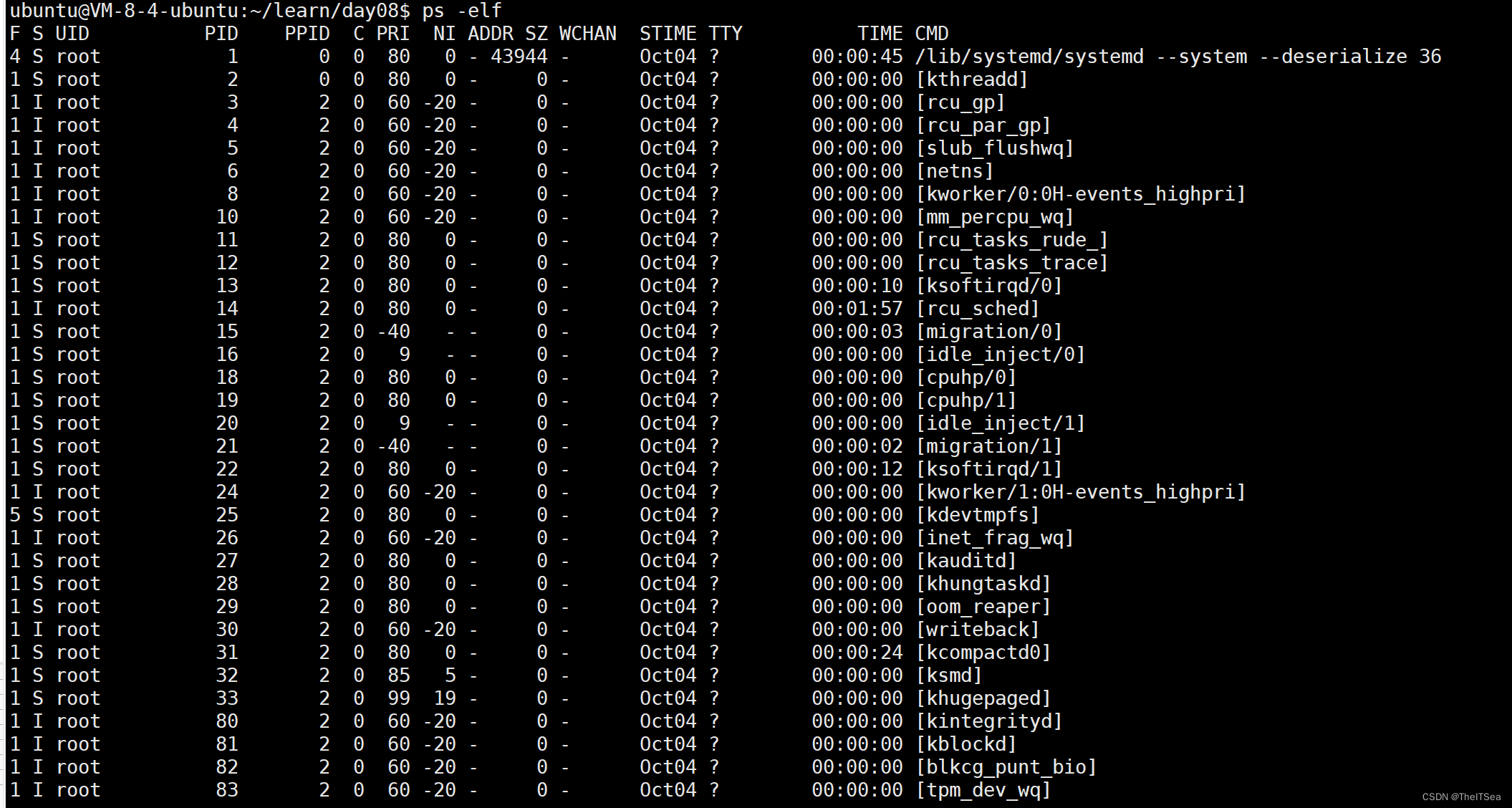
上图中用方括号括起来的进程都是内核进程,是由PID为2的进程启动的。
而通过查看所有的PID信息,可以验证Linux中进程之间的血缘关系,我们也大致可以得出Linux 系统的开机过程:
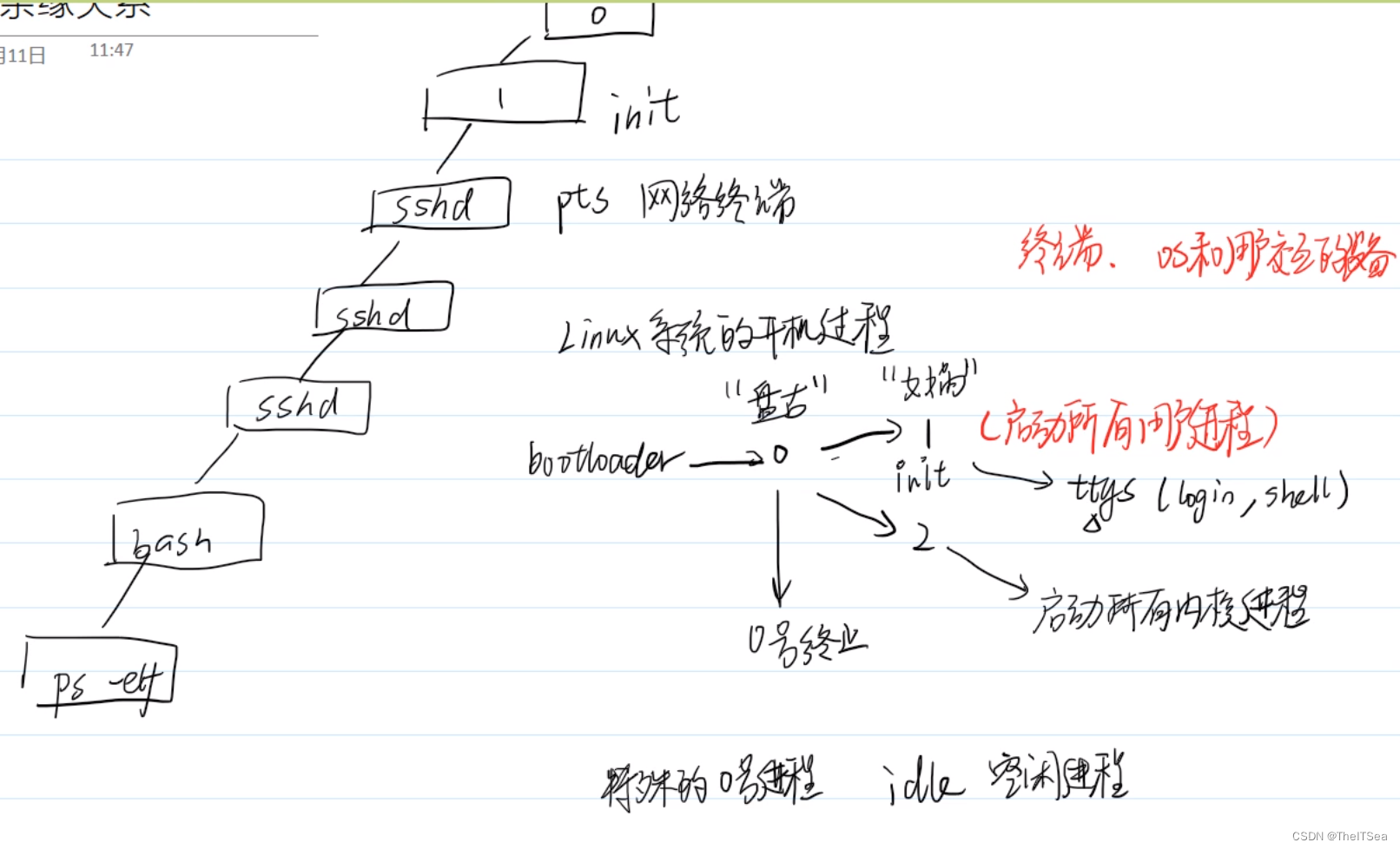
getpid系统调用:获取进程PID

简单演示:
再执行一次:
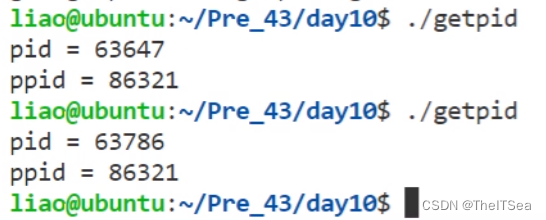
会发现两次的PID不同,这是因为两次执行就表示了这是两次不同的进程,所以PID号会不同,而ppid一样是因为它们都是当前这个Shell命令行所创建出来的进程。
进程的权限
之前提过文件的权限,rwx rwx rwx三段分别对应当前用户权限、同组其它用户对该文件权限和其他组用户对该文件权限。
而所谓的进程的权限其实就是看该进程的身份是谁,也就是说这个进程是哪个用户创建出来的那么它就应该具有什么权限:
getuid系统调用:获取进程的用户
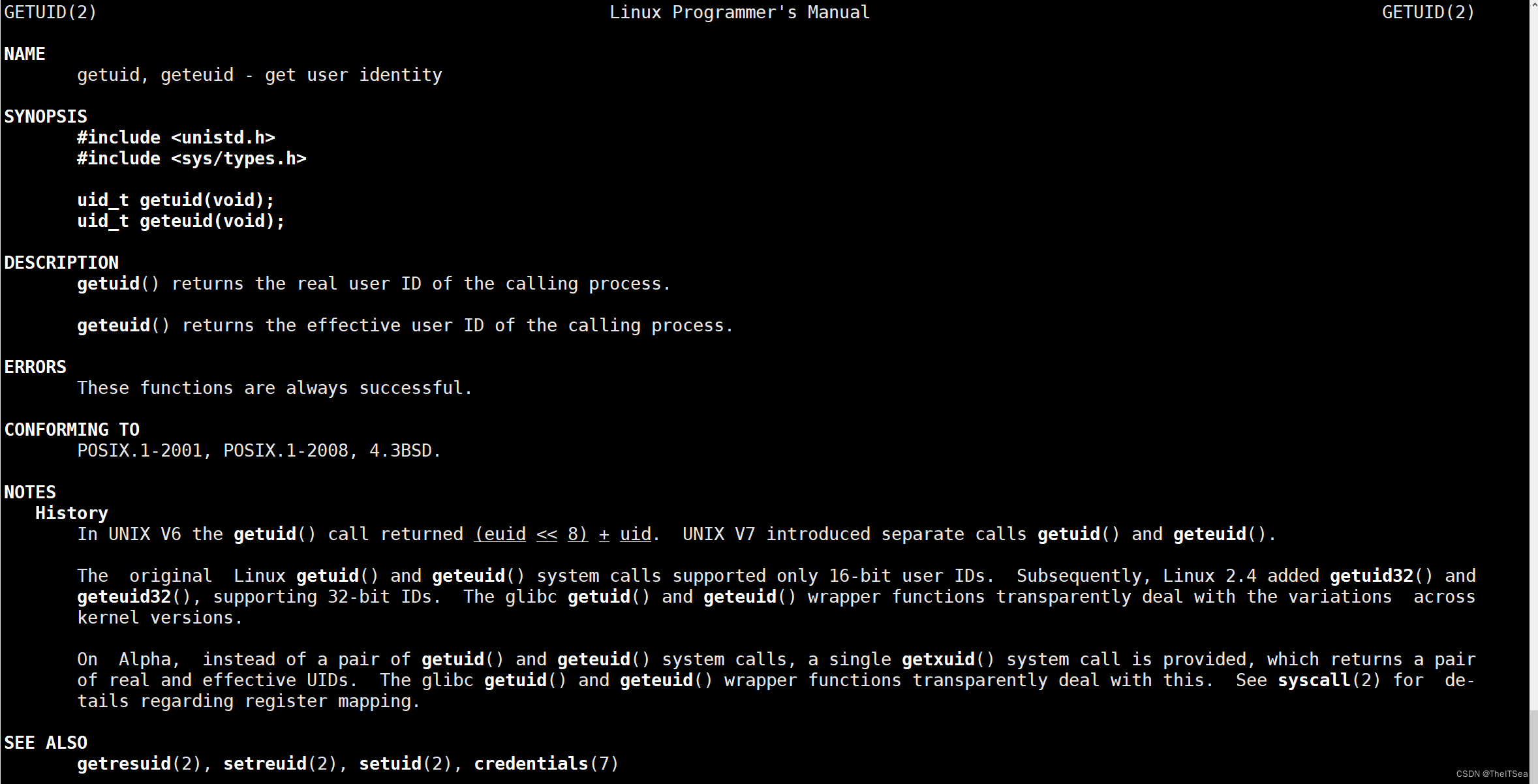
可以看见该函数有两种使用情况,一种是获得真实身份,一种是有效身份(也就是起作用的身份)。
我们可以来试一下:
测试代码如下:
#include <43func.h>
int main(){
uid_t uid = getuid();
uid_t euid = geteuid();
printf("uid = %d, euid = %d\n", uid, euid);
}
运行效果如下:
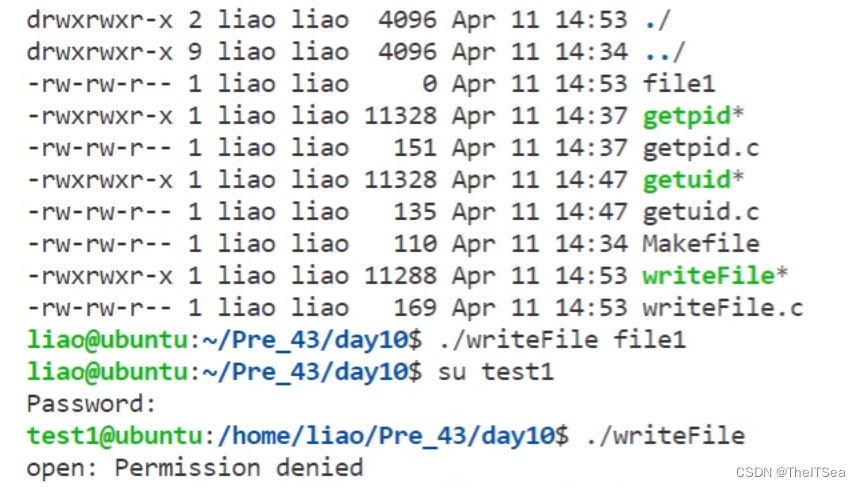
此时因为writeFile的其它用户是没有执行权限的,所以该用户test1执行writeFile程序是被禁止的。
现在来对我们要使用的进程文件writeFile的权限进行更改:
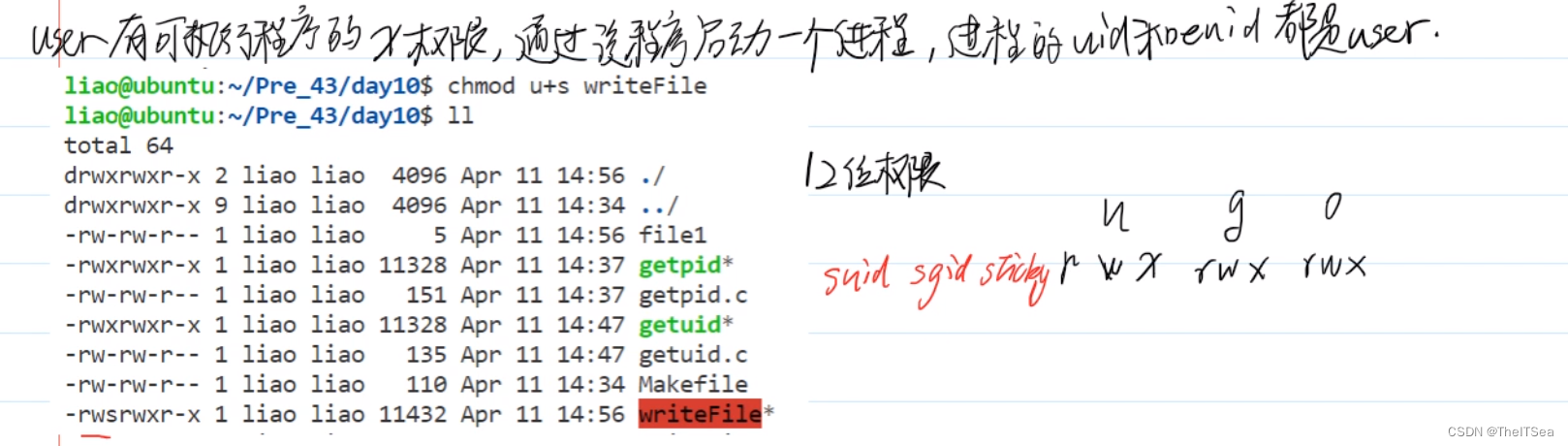
可以看见上图中writeFile的当前用户权限变为了rws,这是因为实际上文件是有十二位权限的,除了之前说的九个还有高三位的suid、sgid和stickey权限。
suid权限
先来看suid权限的作用,当满足以下条件时:
1、当前用户u的x权限和其它用户o的x权限必须存在
2、u的s存在(suid要存在)
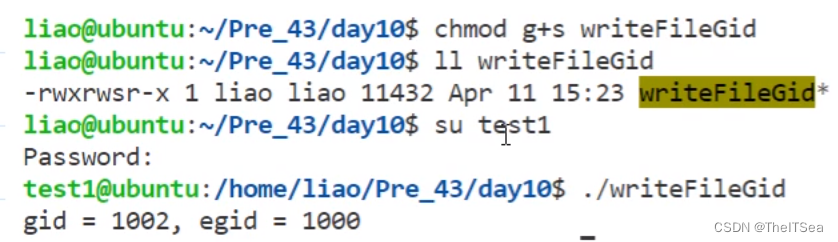
一旦上面的条件满足此时运行程序,当我们切换用户将得到下面的效果:
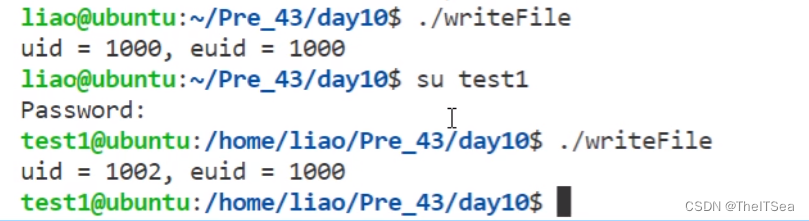
可以看见当其它组的用户通过该可执行程序启动的进程其euid会被更改为程序的拥有者。
因为上图中euid为1000即指的是图中的liao用户,它是该程序真正拥有者,所以它可以运行该程序,而我们切换用户test1后,再次执行该程序会发现虽然此时真实用户是UID为1002即test1用户,但其实真正在起作用的有效用户是euid为1000的liao用户。
我们系统用户密码的更改passwd命令也是这个原理:
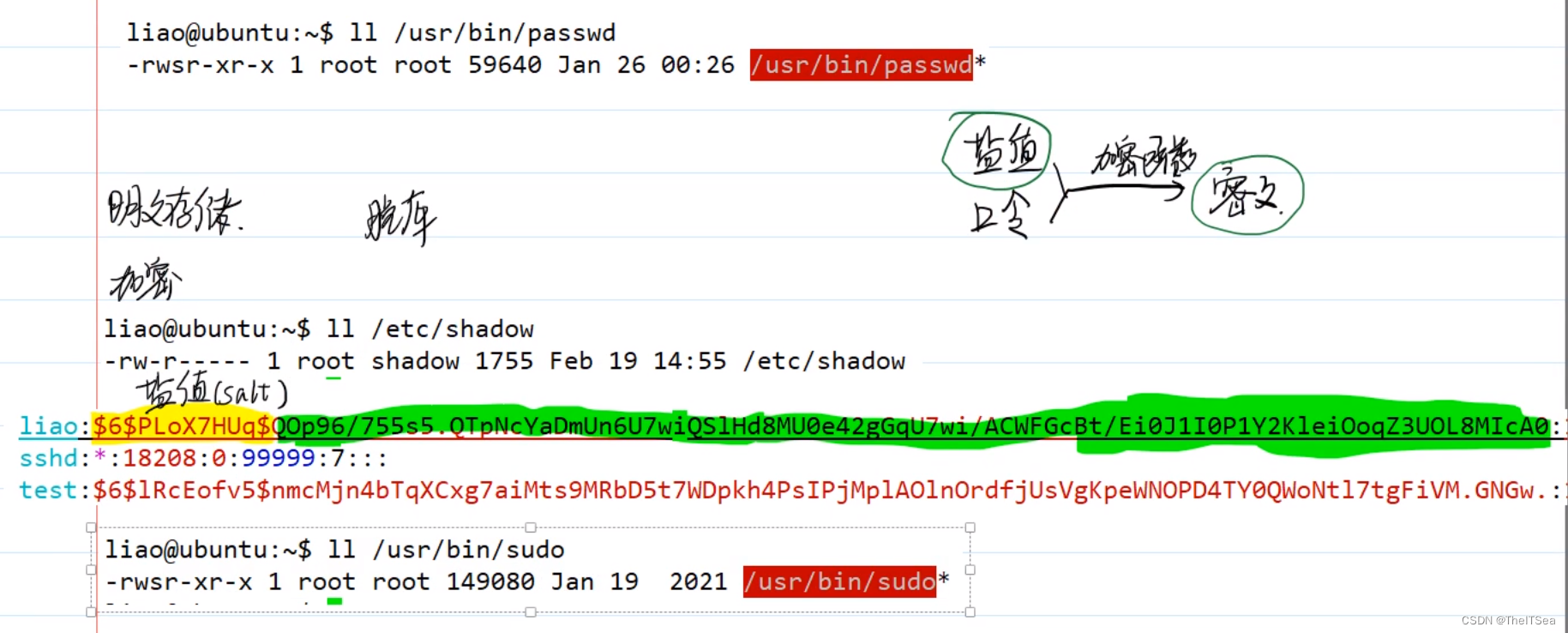
在shadow文件中可以看见我们的用户密码都是被加盐加密存储了的,passwd文件就拥有suid权限,另外sudo也一样具有suid权限,这就是为什么我们不用root用户也一样能进行密码更改和使用特权命令的原因:其真实用户和有效用户并非同一个,真正在起作用的有效用户其实是root。
sgid权限
再来看sgid权限的作用,当满足下面条件时:
1、同时拥有其它组用户o的x执行权限和同组其它用户g的x执行权限
2、拥有同组其它用户g的s权限(即sgid权限)
这个和suid区别不大,只不过一个是组一个是用户而已,举一反三就行:
sticky权限: 粘滞位
这是针对目录文件的使用的。
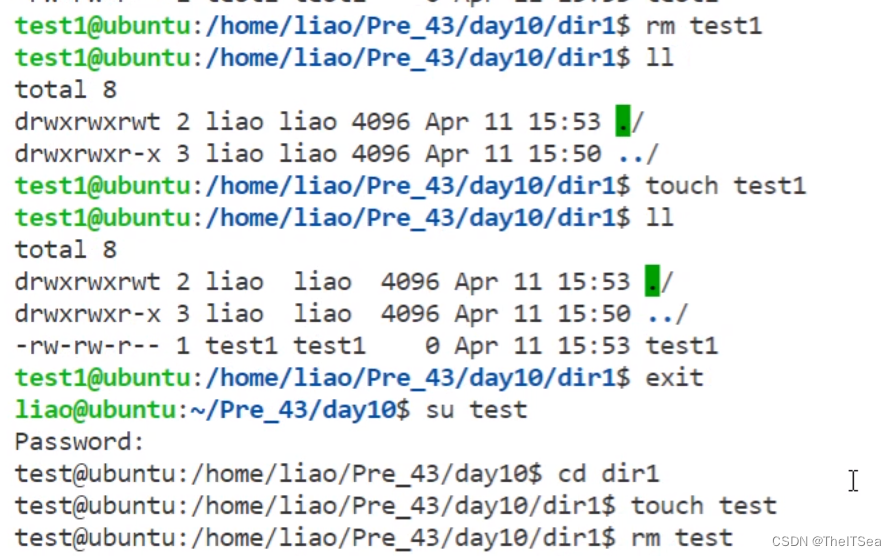
如果使用了粘滞位,对于某用户所创建的文件夹目录,其它用户同时拥有w写权限和t权限(即sticky权限)。此时其它用户可以创建文件,可以删除自己的文件,不能删除别人的文件。
测试如下:
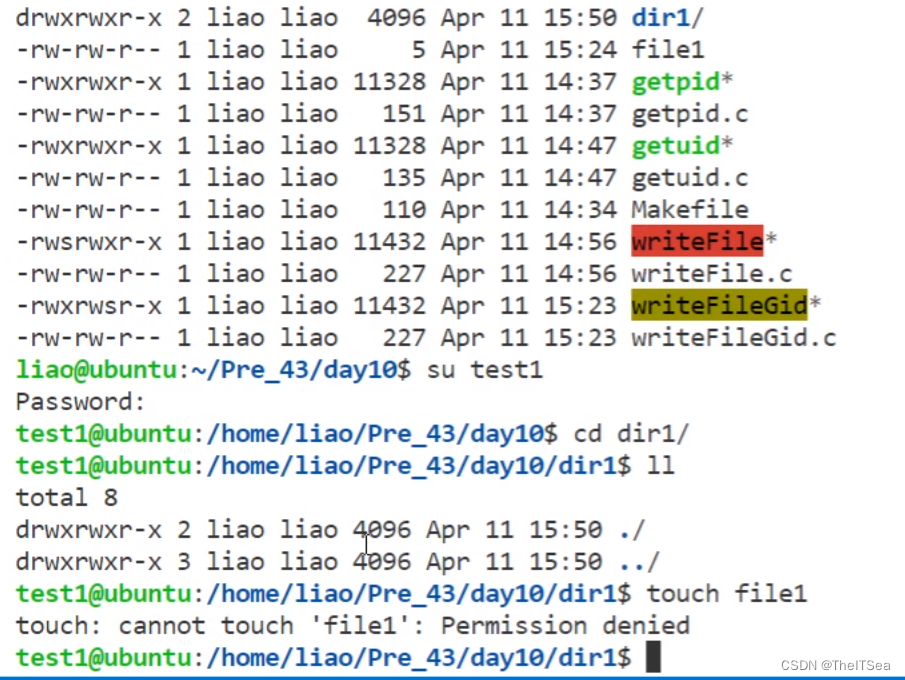
上图可以看到,当我们没有t权限时,其它用户是不能写dir1文件目录的,因为该目录是由用户liao所创建的。
那么现在我们给其增加t权限:
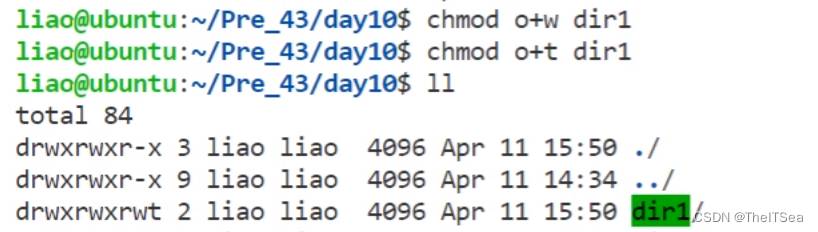

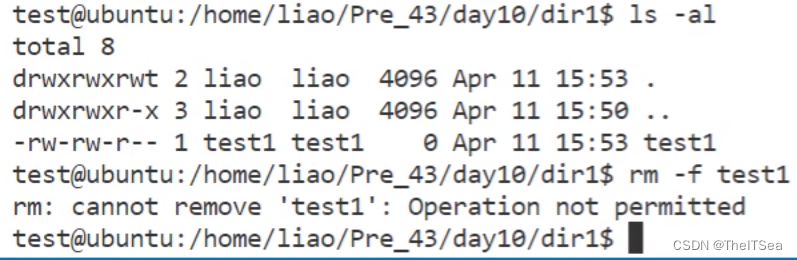
和我们预期所描述的相同。
进程相关的命令
ps命令查看系统当中的进程
ps命令因为很古早,所以使用方法上很多。
首先是ps -elf命令:
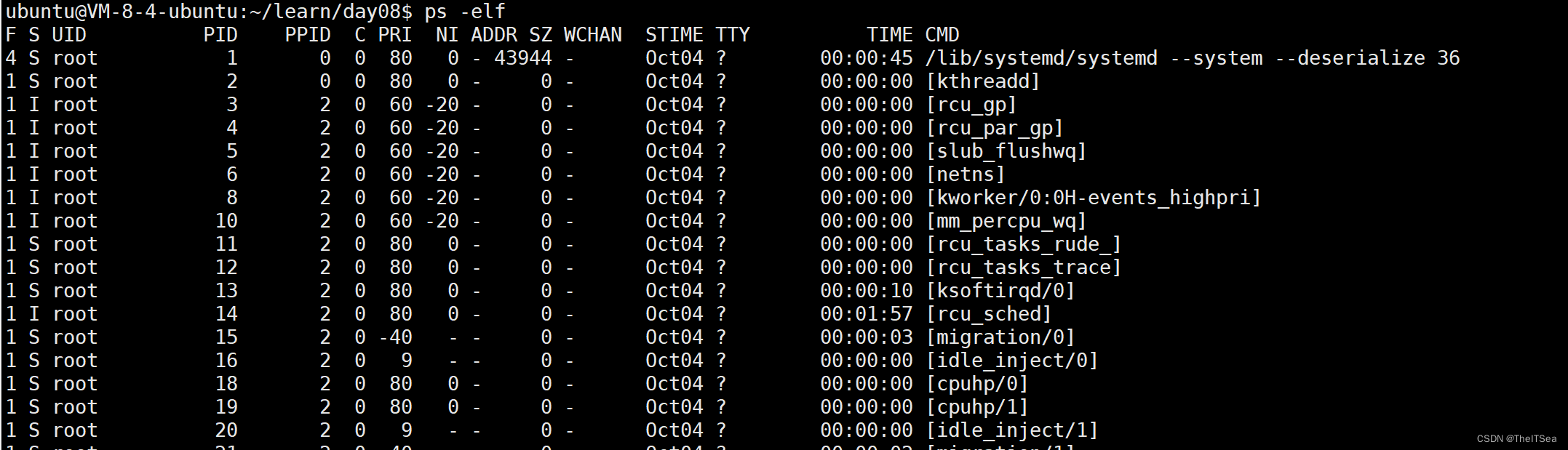
详细解释每一列内容:

上图中的右下部分就是其对应的Ststus状态对应的码。
而上上副图中的 I 状态其实就是Idle空闲进程。
从左往右有些位置应该是好理解的,那么C是什么,C列其实表示的是CPU的占有率。
PRI 和 NI 列是一样的,用来表示优先级。
其中PRI表示priority,NI表示nice。
ADDR表示地址,即该进程驻留内存的起始地址。
SZ表示该进程驻留内存的大小。
WCHAN表示阻塞的系统调用,意思是假如有一个进程被阻塞了,那么肯定是有原因的才被阻塞的,使用WCHAN就可以知道某进程被阻塞的原因是什么。
举个例子,我们之前所写的简易聊天程序,当被阻塞时我们就可以通过下面命令中的WCHAN列来查看其是被什么原因所阻塞的:

可以看见有pipe_w管道写阻塞,poll_s轮询阻塞。
STIME列表示启动时间。
TTY列表示终端,如上图中的两个终端号就有2和3,这是因为我们开了两个终端来模拟两个进程导致的(应该还记得简易聊天程序的过程吧)。
TIME列表示CPU占用总时间。
CMD列表示启动该进程的命令。
ps命令的另一种伯克利风格
即ps aux命令:
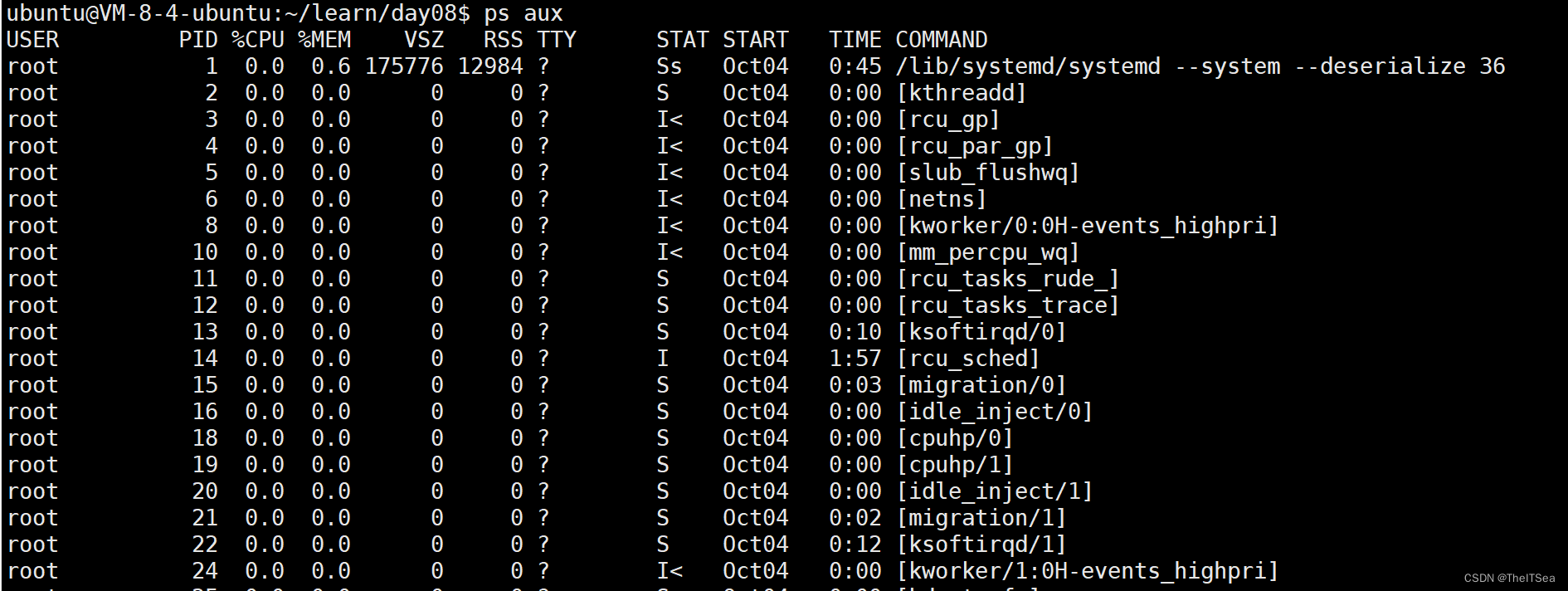
描述的事情上与ps -elf大同小异。
前面几列比较简单,说一下没见过的:
%MEM列表示内存占用率。
VSZ列表示该进程所占用的虚拟内存大小。
RSS列表示驻留在内存中的驻留集大小。
TTY列一样是终端。
STAT表示状态,伯克利风格的ps除了原来的状态码之外还有对应的后缀来修饰:

剩下的就都差不多了,不再赘述。
注意查看内存的话,也可以使用free命令,其查看的更加详细:

可以查看一下free的man手册,有更加详细的介绍:
top命令:获取实时的系统进程的状态信息
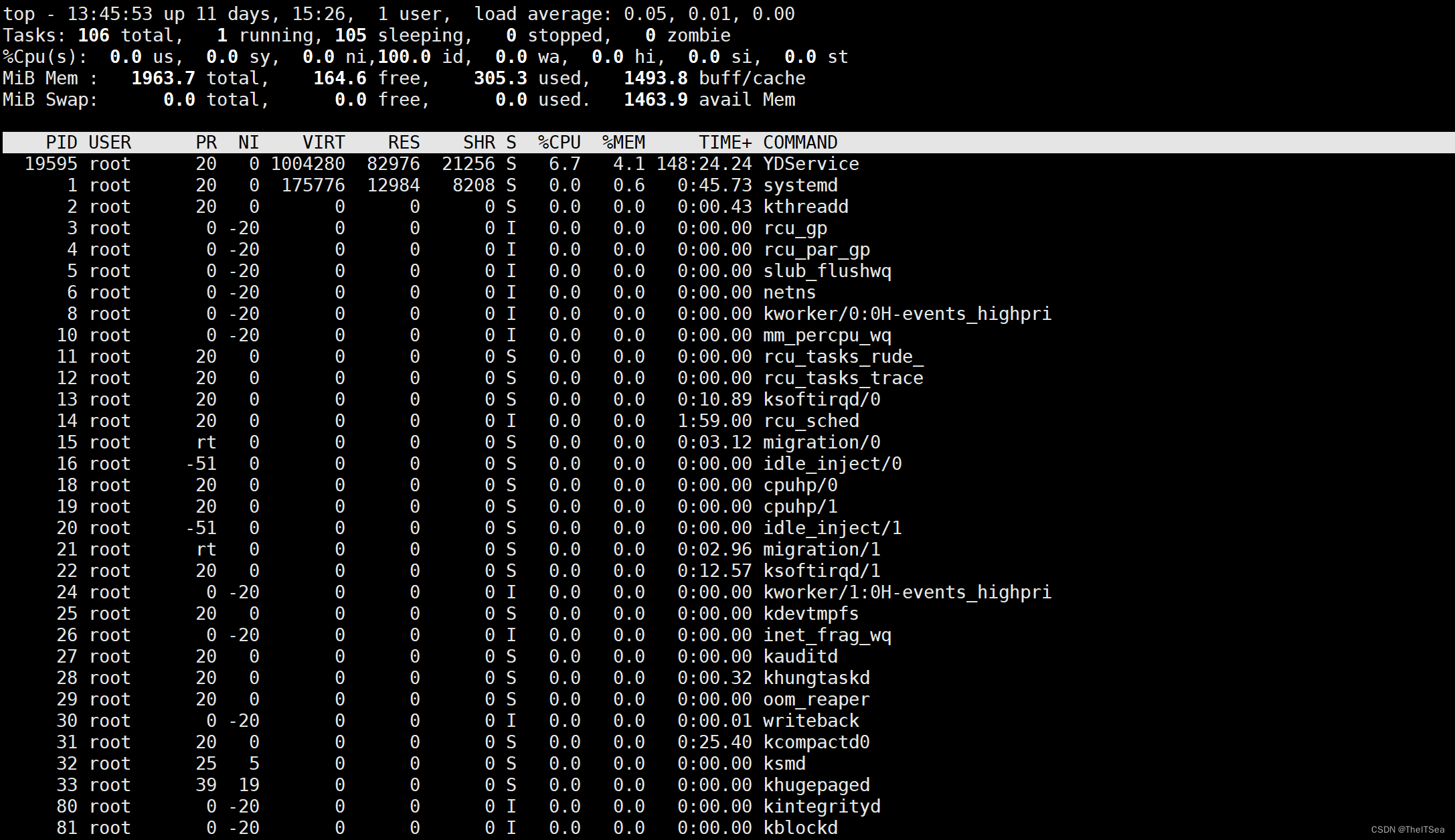
其中值得关注的一些内容:
第一行top后面的13:45:53等这是当前时间,后面的up 11 days,15:26这是开机时间,1user 表示有一个user正在使用这台机器,load average表示平均载荷,分成的三个部分好像是1分钟5分钟和15分钟内的平均工作负担,这里的载荷意思就是指就绪队列的任务数量,当这些值小于1时表示并未满载,tasks表示目前正有多少进程在运行,running表示运行中,sleeping表示睡眠中,stopped表示停止的,zombie表示僵尸状态。
第三行%Cpu开头的表示时间分配:
nice、renice命令:处理优先级系统
不同系统的优先级级别个数不同,我们用的Ubuntu是有140个,-40到99,数值越低其优先级级别越高。
这一百四十个又被分为两部分:
-40到59:实时优先级,使用于FIFO和RR调度算法
60到99:普通优先级,使用完全公平调度算法
注意:用户是无法修改调度策略的。正因为如此,我们才需要使用nice和renice这种方法来间接的修改优先级。
nice值的范围:-20到0到19,对应的实际优先级是60到80到99,这也就意味着我们是无法改变实时优先级的,只能调整普通优先级。
也就是nice值+80就为实际的优先级,使用nice值可以去调整普通优先级。
nice命令的基本使用
nice -n +某个值,表示以某个nice值启动进程,当设置的值超出了-20到10的范围时,就算不报错实际查看优先级依然是在-20到10的范围内,简单测试:
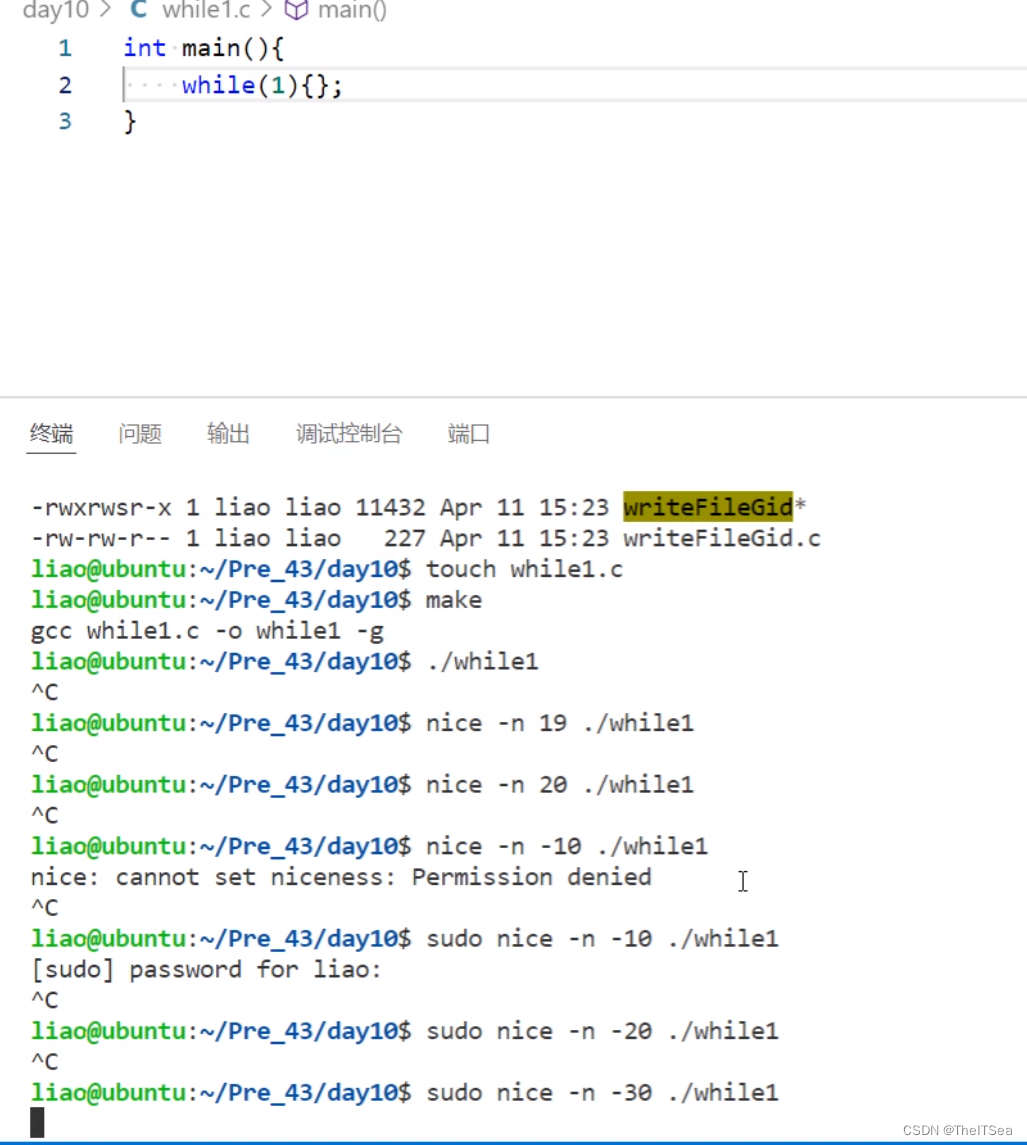
注意:低优先级往高优先级转需要root权限,而高优先级往低优先级转不需要权限。
renice命令:修改nice值
比如上面所写的程序,当不设置nice值默认启动时其nice值默认为0,对应的优先级则为80,我们可以使用renice命令进行重置nice的值:

renice -n 10 -p 86531命令的意思是使用renice命令将进程号为86531的进程的nice值重新设置为10。
前台进程和后台进程
前台进程主要指的是可以响应键盘中断的进程,什么是叫响应键盘中断?就是比如说ctrl+c终止还有ctrl+\终止以及ctrl+z可以暂停等键盘中断指令。
后台进程就顾名思义了,即不可以响应键盘中断的进程。
我们使用 ./的方式启动的进程都是前台进程,比如之前写的所有程序,它们都可以被上面所说的键盘中断指令给终止。
而怎么让其转换为后台进程?
就是在./命令的后面加上&符号即可,它就可以一直在后台启动了。
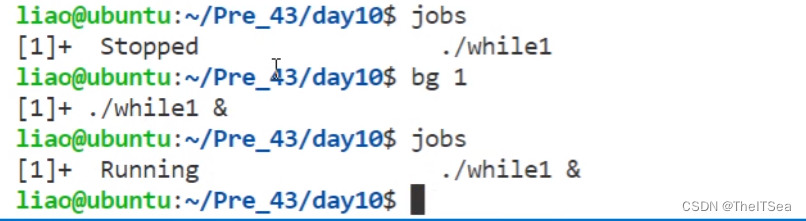
jobs命令查看前后台进程
使用jobs指令可以查看当前终端窗口里面有多少前后台进程,注意该命令只对bash终端有效:

fg命令拉取后台进程变成前台进程
使用fg命令我们又可以将后台运行的进程拉到前台来:
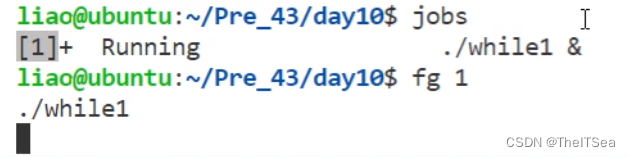
后面跟的数字就是使用jobs命令查看的后台进程的ID号。
此时想再切换回后台进程的话,只需要使用ctrl+z即可:
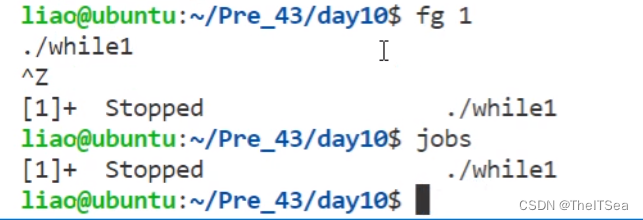
bg命令启动后台进程
但切换回后台该进程的运行状态实际上是暂停的状态,通过使用bg命令可以启动该后台进程:
kill -9杀死后台进程
杀死进程的话使用kill命令即可,先用ps -elf获得进程id,然后使用kill -9 +进程id号强制杀死(不管进程啥状态杀了就死)。
crontab定时任务
有两种模式,单用户定时任务和全局定时任务两种。
单用户定时任务:crontab -e
当我们使用该命令时就进入一个定时任务编辑界面,可以使用vim编辑,然后按照该定时任务描述的方式去写定时任务:

这句命令的意思是,在今年的10月17号周二的早上7:50分执行"123"数据的写入到默认家目录下的111.txt文件中:

注意该命令也可以使用通配符来写,能够实现更加丰富的功能。
全局用户定时任务
该定时任务在/etc/crontab文件中,我们使用vim打开:
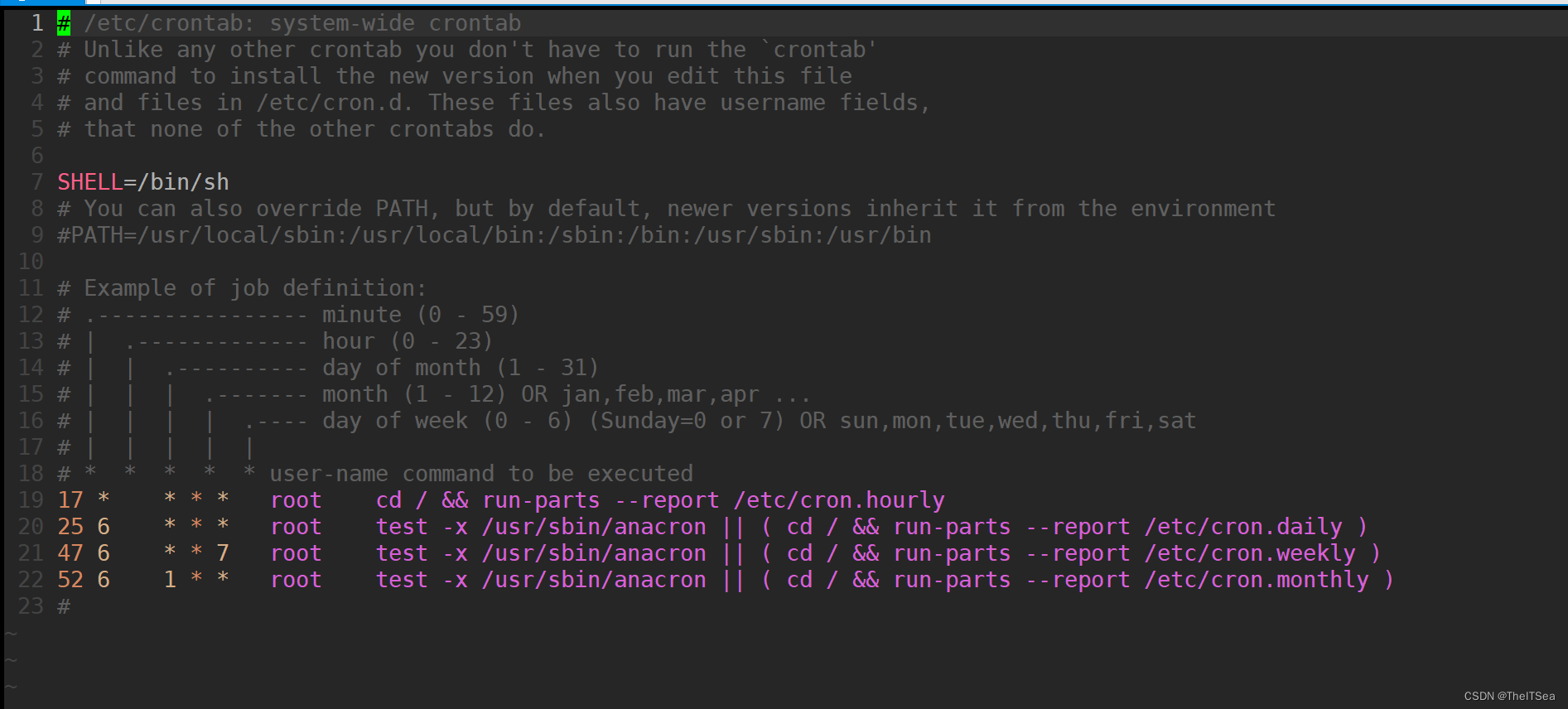
与我们之前说的单用户定时任务只不过多了一个user而已,可以对比着看一下,基本差不多。
代码中启动多个进程
system命令:执行一个shell命令
现在我们写一个睡眠程序sleep.c:
1 #include <43func.h>
2
3 int main(){
4 printf("I am going to sleep!\n");
5 sleep(10);
6 printf("I wake uo!\n");
7 }
编译运行,就是简单的睡眠十秒钟:

在其运行时可以通过ps -elf知道其确实是一个进程:
然后我们现在就可以使用system来执行启动该程序的命令,编写代码system.c:
1 #include <43func.h>
2
3 int main(){
4 printf("I am going to call him to sleep!\n");
5 system("./sleep");
6 printf("call over!\n");
7 }
执行效果:
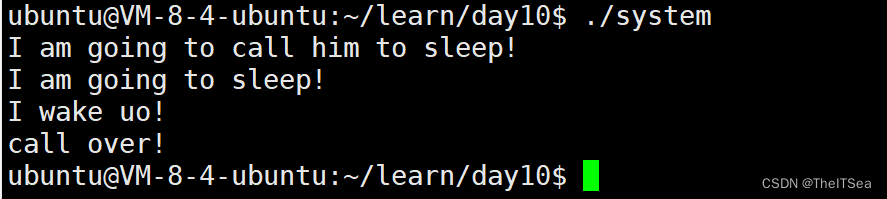
可以看见是成功在一个程序当中启动了另外一个程序。
看一下在其执行过程中有几个进程:

有三个进程在执行,在我们执行./system命令时,此时进程system开启,当打印完I am going to call him to sleep时,调用system函数执行./sleep命令,启动sleep程序,但并不是直接就启动了sleep程序的,它会先去打开sh-c这个进程,由该进程来打开sleep程序,当sleep程序执行完之后随之sh -c程序终止最后system继续执行直到程序终止:
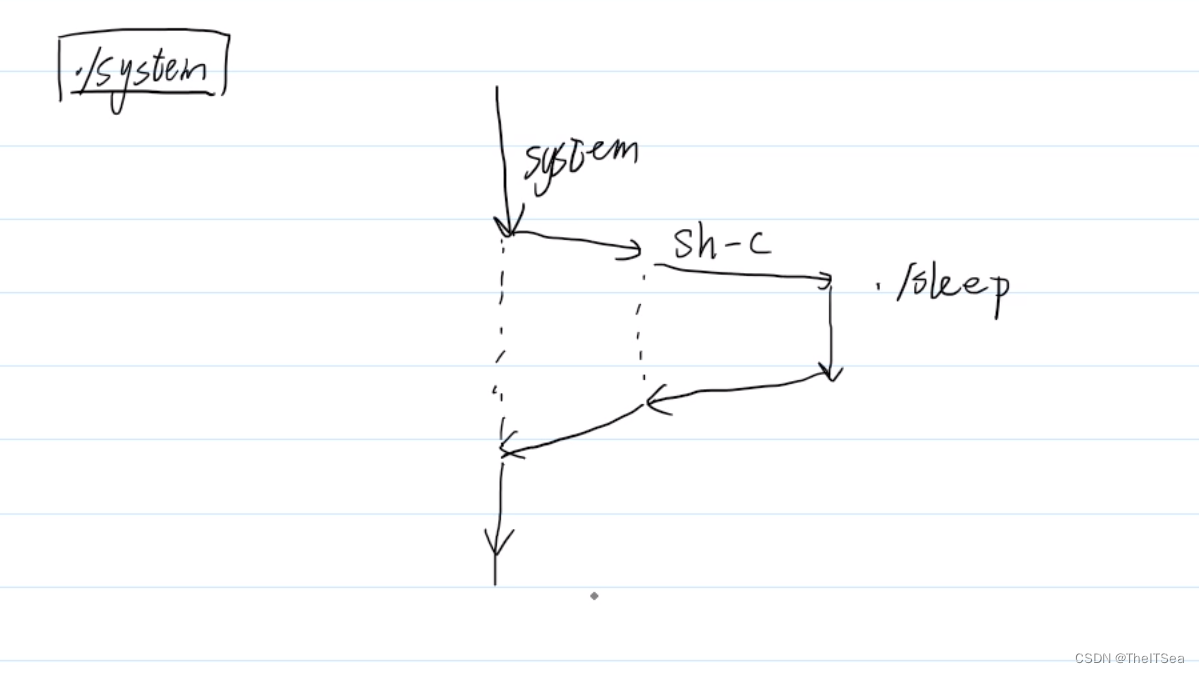
可以看见某时刻中是可以有三个进程在并发执行的。
所以自然而然的我们也可以使用该函数去调用其它语言编写的程序:
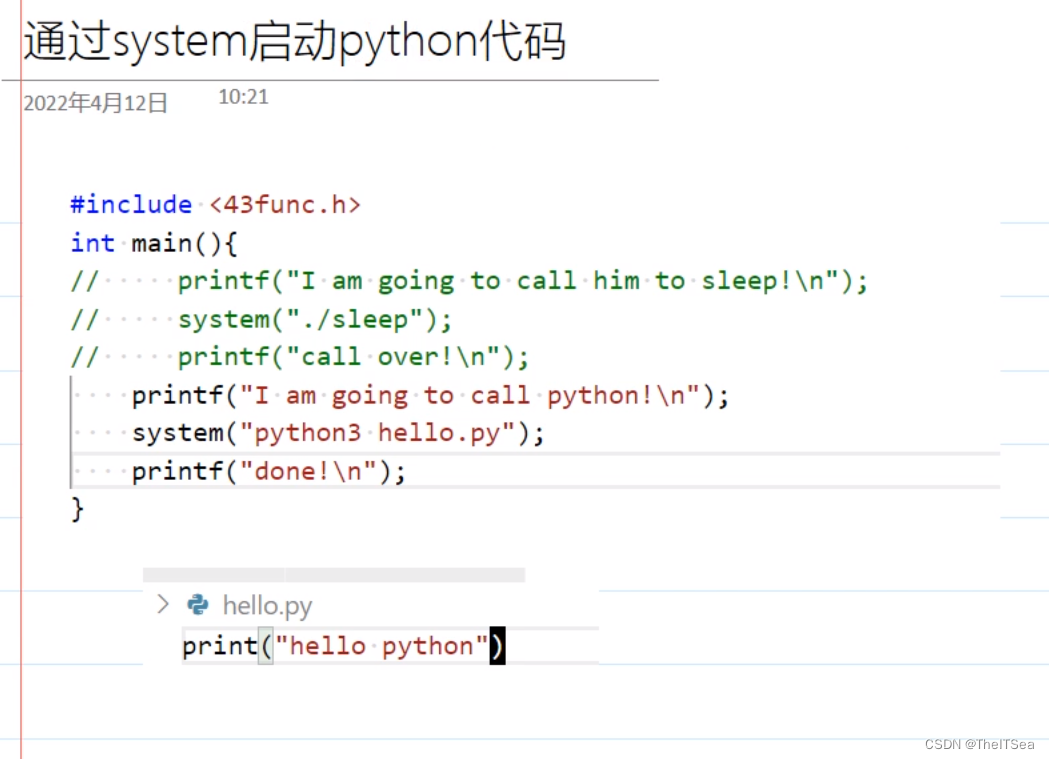
system的缺陷
因为system是个库函数,这意味着它在win平台下也是可以使用的,但是这样就会有性能损失,因为它调用其它程序时还是要再调用一下sh -c才可以,这会造成性能的损失,所以我们想要压榨更高的性能的话,应该直接用系统调用,也就是我们下面要说的fork。
fork系统调用
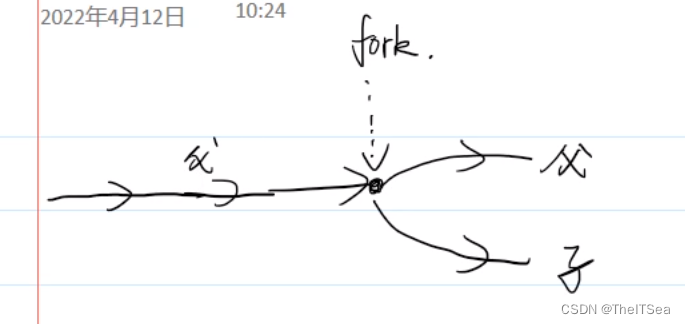
如图所示,父进程运行着运行着通过fork机制就可以产生新的分支,也就是从父进程中分出一个新的分支子进程。
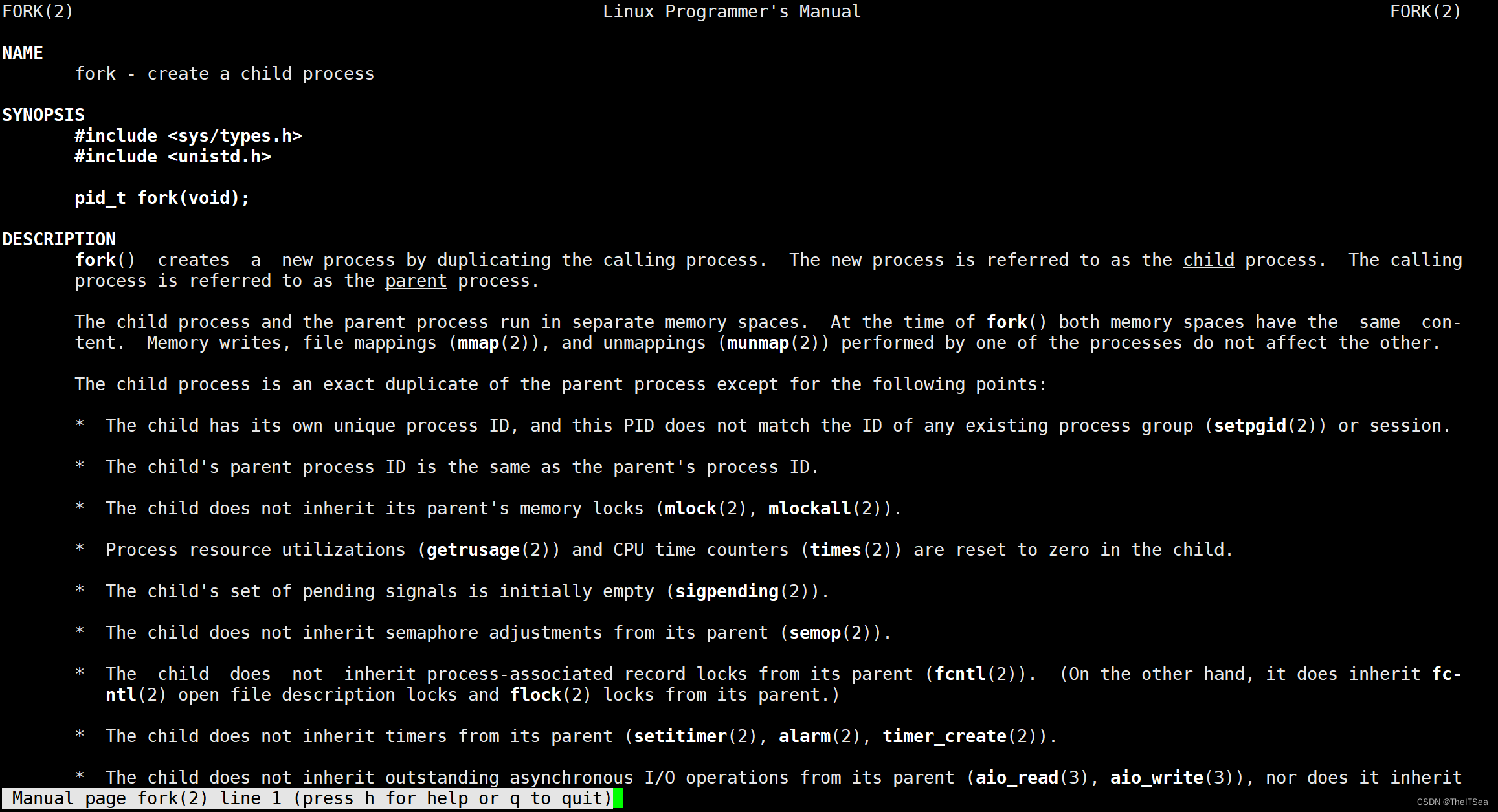
从description中可以看到,fork的作用是复制一份调用进程的内容来创建一个新的子进程。
即父进程和子进程是一种克隆和被克隆的关系。
如何理解?
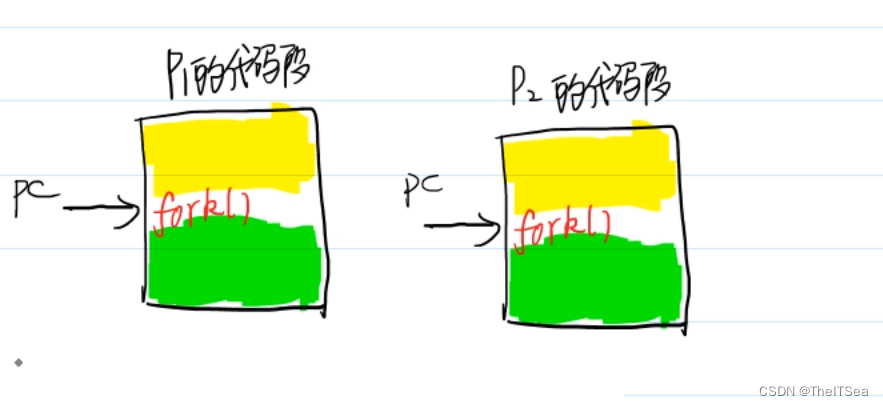
所谓进程的运行,其实就是pc程序计数器指针从进程的代码段开始一句一句执行的过程,以上图为例,此时P1作为父进程,黄色部分是已经执行过的代码段,而绿色部分是还没有执行的代码段,某一时刻PC指针运行到了中间的某个位置执行了fork系统调用,然后就在系统内存中创建了一个新的P2子进程,其所有内容包括PC指针所执行到的位置都相同,这就意味着两个进程其实都认为自己调用了fork系统调用,而fork 的返回值是:

fork系统调用的返回值有两个,我们用这两个不同的返回值来区分两个进程的父子关系。
父进程P1的fork系统调用返回子进程PID,而子进程的fork系统调用返回0
此时如果不加以控制,那么后续两个进程将执行一模一样的代码,那么有没有办法让父子进程后续不执行一样的代码呢?
肯定是有的,直接拿二者fork的返回值然后使用if条件语句使其走向不同的分支代码运行即可。
编写代码测试:
1 #include <43func.h>
2
3 int main(){
4 pid_t pid;
5 pid = fork();
6 if(pid == 0){
7 printf("I am child, pid = %d, ppid = %d\n",getpid(),getppid());
8 }else{
9 printf("I am parent, pid = %d, ppid = %d\n",getpid(),getppid());
10 sleep(1);
11 }
12 }
编译运行:

可以看见子进程的父进程PPID为父进程的PID。
fork的拷贝
在逻辑上,父子进程的用户态空间是拷贝的,而用户态空间有程序的栈数据、堆数据以及数据段数据等。
我们可以验证一下这个事情:
1 #include <43func.h>
2
3 int global = 1; //全局变量在数据段,即既不在栈上也不在堆上
4
5 int main(){
6
7 int stack = 2; //栈上的变量
8
9 int *pHeap = (int*)malloc(sizeof(int)); //堆上的变量
10 *pHeap = 3;
11
12 if(fork() == 0){
13 printf("I am child process, global = %d, stack = %d, *pHeap = %d\n",
14 global,stack,*pHeap);
15 ++global;
16 ++stack;
17 ++*pHeap;
18 printf("I am child process, global = %d, stack = %d, *pHeap = %d\n",
19 global,stack,*pHeap);
20 }else{
21 sleep(5);
22 printf("I am parent process, global = %d, stack = %d, *pHeap = %d\n",
23 global,stack,*pHeap);
24 }
25 }
上述代码逻辑是:如果fork的子进程和父进程使用的进程的用户态空间不是拷贝的,那么当我们让父进程睡眠五秒再打印用户态空间的数据内容的话,其值应该发生改变(即和++之后的数据内容相同),否则如果是拷贝的话那么就应该无关,即应该是和子进程的初始状态的各数据相同,看结果:

由此我们证明了父子进程的内容应该是拷贝的互不相关的。
FILE文件流的拷贝
我们使用fopen 的时候所得到的FILE文件流是在用户态的,又因为用户态是拷贝的,那么我们来测试一个很有意思的代码:
1 #include <43func.h>
2
3 int main(){
4 printf("hello\n");
5 fork();
6 printf("world\n");
7 }
这段代码应该会打印一个hello两个world,因为在二者中间我们fork了程序,在fork之前只有一个父进程在执行,即打印了hello,在fork之后有两个进程,则二者都打印了world,所以应该会打印一个hello两个world:

但有意思的是,我们稍微改一下:
1 #include <43func.h>
2
3 int main(){
4 printf("hello");
5 fork();
6 printf("world\n");
7 }
就变成了下面这样:

变成了两个hello两个world。
为什么?
首先要知道,printf的本质是往标准输出stdout中写入内容,当遇到换行符或者缓冲区满的时候才把内容写到屏幕上面(或者说写到了内核文件对象中),而上述程序中有没有换行的影响是有换行的时候,先将hello拷贝到FILE里面,FILE再拷贝到文件对象里面,执行完一步之后因为有换行符所以缓冲区被清空,即FILE里面不再有hello,此时执行fork,因为FILE文件缓冲区是空的所以没有hello可以打印。
而没有换行则不一样,不加换行意味着此时当执行打印world的时候FILE文件缓冲区里还有hello,所以父子进程都会打印helloworld。
总结就是:fork文件时要注意一下fork的时候文件流里面是否还有残留的数据。
也可以得出结论:用户态空间的所有数据是拷贝的,文件流属于用户态所以也是拷贝的。
内核态是拷贝还是共享的?
其实内核态的数据有一些是共享的有一些是拷贝的。
还记得之前说的内核态中的文件对象struct file(或者叫file object也行)和文件描述符吗,在内核态中我们常接触这两个数据,现阶段我们主要要掌握看这两个是拷贝的还是共享的,先给出结论:文件对象是共享的(不然多浪费空间),文件描述符(即文件对象的索引数组)则是不同的进程各自有一个,两个进程的不同的文件描述符可以指向同一个文件对象,也可以相同的描述符指向不同的文件对象,如果两个进程都看到了同一个文件对象那么该文件对象就是共享的:
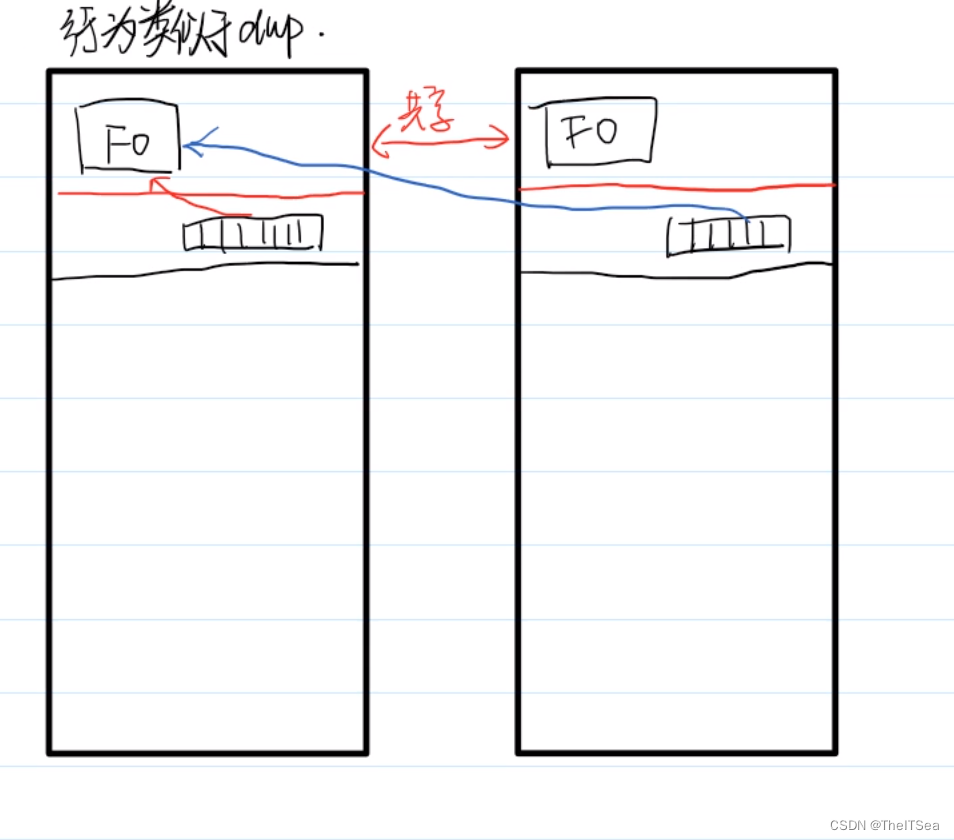
我们可以来简单测试这个事情:
1 #include <43func.h>
2
3 int main(){
4 int fd = open("file1",O_RDWR);
5 if(fork() == 0){
6 write(fd,"hello",5);
7 }else{
8 sleep(1);
9 write(fd,"world",5);
10 }
11 }
open操作内核态的文件对象,此时我们使用fork系统调用让父子进程两个往里面写数据,如果该文件对象是共享的,那么在沉睡一秒后的父进程将会追加子进程所写的该文件的内容,即输出helloworld;而如果是拷贝的,则父进程会覆盖子进程所写的内容,看结果:

可以看到输出的是helloworld,说明文件对象是共享的。
注意屏幕(标准输出设备)也是一个文件对象,在父子进程之间也是共享的。
exec函数族
首先说一下族的意思就是一堆函数,exec并不是简单的指一个函数,而是指一堆函数,使用man execv查看该函数族:
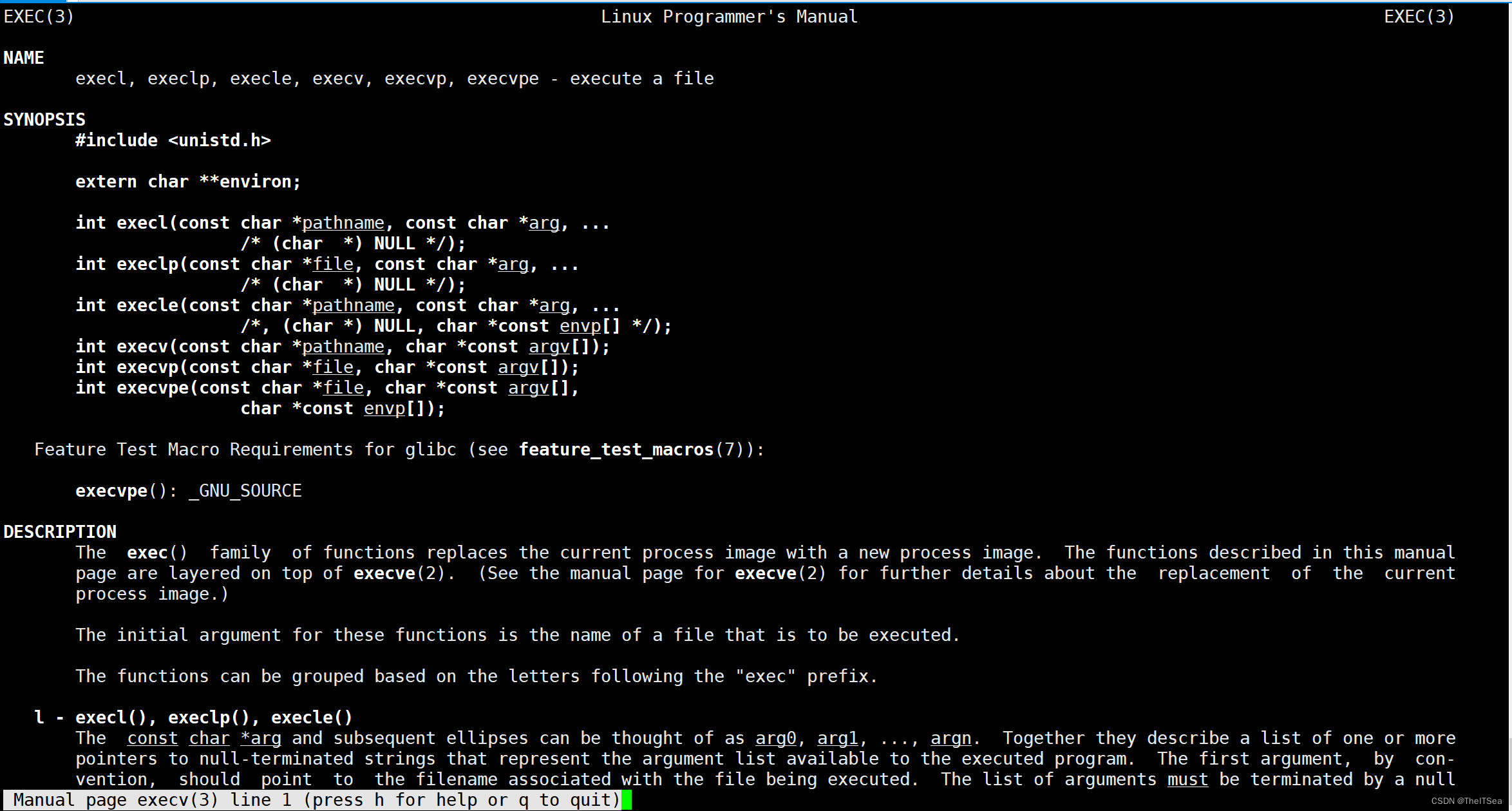
上面六个函数功能都是一样的,重点掌握execl和execv,execl中的l表示list,execv中的v表示vector。
这两个函数第一个参数都是一样的表示接收一个可执行程序的路径,但是execl的第二个参数表示接收一个可变参数,execv的第二个参数表示接收一个元素为char类型指针的数组。
而exec的作用就是将一个可执行程序文件加载到本进程的地址空间,画图来深刻理解一下:

上图使用一个程序在执行,PC指针从上往下一条一条指令执行,黄色部分是已经执行过的内容,绿色部分是还没执行的部分,当PC指针执行到中间某个位置即执行exec函数时,就会清空所有数据(栈上的、堆上的以及数据段上的),然后将path加载进来,取代原来的代码并且重置PC。
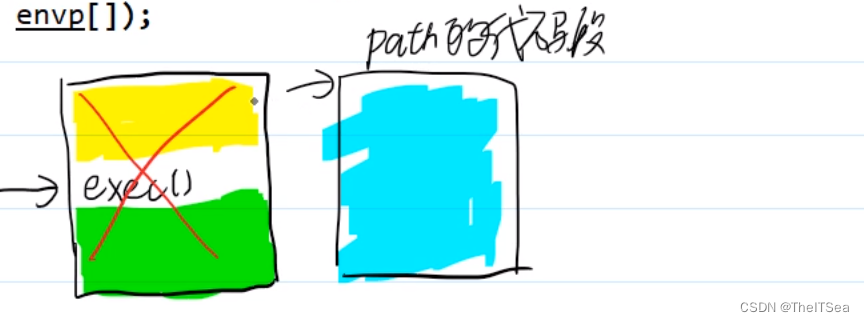
如上图所示就重新执行path的代码段。
execl接收可变参数创建新进程
我们来写个简单程序测试,首先是一个add.c:
1 #include <43func.h>
2
3 int main(int argc,char* argv[]){
4 ARGS_CHECK(argc,3);
5 int lhs = atoi(argv[1]);//atoi函数将字符串转换为数字
6 int rhs = atoi(argv[2]);
7 printf("lhs + rhs = %d\n",lhs+rhs);
8 }

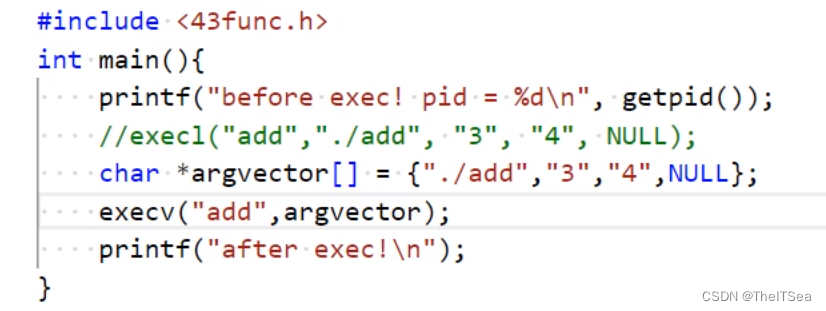
接下来我们使用另一个程序exec.c来启动该程序,此时我们不光需要知道add程序的可执行文件名是什么,也需要知道其对应的参数有哪些,但是不同的程序参数肯定都不一样,有的多有的少,此时就可以使用execl函数来调用,该函数就可以接收可变数量的参数,该可变数量的参数结尾使用空指针结束:
1 #include <43func.h>
2
3 int main(){
4 printf("before exec!\n");
5 execl("add","./add","3","4",NULL);
6 printf("after exec!\n");
7 }
执行结果如下:
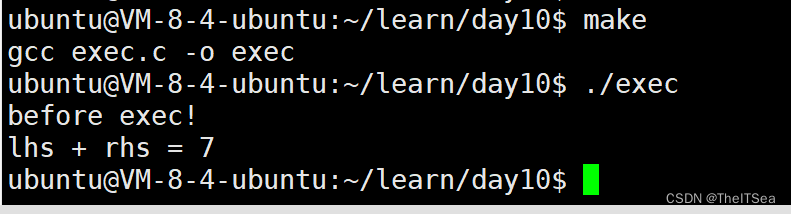
可以看见和我们之前说的是一致的,当exec程序执行时before exec肯定会执行打印,然后到exec函数时清空了exec.c程序的所有数据所以after exec不会被打印,此时接入了add.c程序,就打印出了 lhs + rhs = 7的结果。
注意虽然exec程序中途改用了add程序但改用之后进程依然没有改变嗷,可以打印进程号来验证。
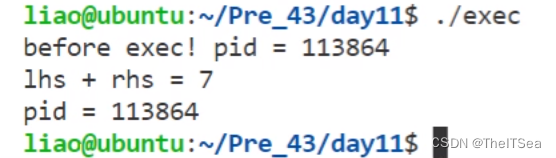
execv接收指针数组来创建新进程
虽然之前的execl可以解决创建新进程的问题了,但是不够方便,假设我们的程序参数个数改变或者其它什么发生改变,都要回来修改该代码,这是很不方便的,因此execv就出来使用一个指针数组来接收这些所有的参数,这样就方便管理了。
那么我们就可以将上面的代码修改如下:
注意:不管用的是execv还是execl最后一位参数都要填空指针嗷。
wait系统调用
wait系统调用涉及到进程的退出,在Linux中子进程的资源由父进程回收,父进程回收资源就是通过wait系统调用。

又出现了新的头文件,记得包括一下嗷:
1 #include <stdio.h>
2 #include <string.h>
3 #include <stdlib.h>
4 #include <sys/stat.h>
5 #include <unistd.h>
6 #include <sys/types.h>
7 #include <dirent.h>
8 #include <pwd.h>
9 #include <grp.h>
10 #include <time.h>
11 #include <fcntl.h>
12 #include <sys/mman.h>
13 #include <sys/select.h>
14 #include <sys/time.h>
15 #include <sys/wait.h>
16 #define ARGS_CHECK(argc,num) {if(argc != num){fprintf(stderr,"args error!\n"); return -1;}}
17 #define ERROR_CHECK(ret,num,msg){if(ret == num){perror(msg); return -1;}}
简单测试:


上图中就是当子进程运行结束之后资源就由父进程调用wait()系统调用来回收子进程的资源。
如果子进程未终止但是父进程已经终止的话,该进程就成了孤儿进程,这时候一般都要给它找一个新的父进程,一般是PID为1的系统进程。
1号进程每天的任务就是不停的wait wait所有的进程资源。
还有一种子进程终止,父进程一直不调用wait的情况,也就是所谓的僵尸进程:该进程已经终止了,但是其所拥有的资源还没有被回收。
示例:
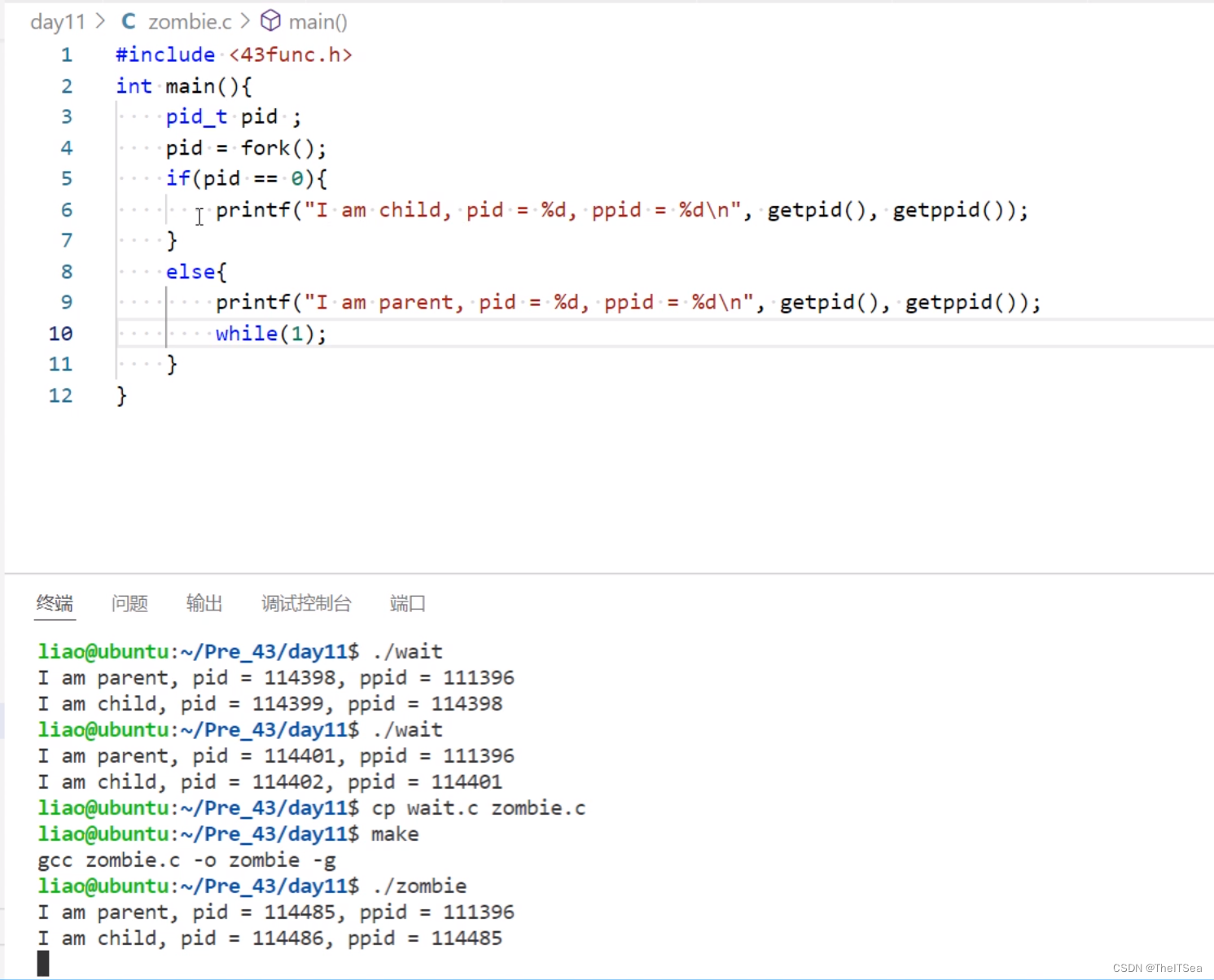
此时父进程一直在while1永真循环,但子进程已经死了,可是父进程还没有给其收尸:

可以看见该进程已经成了Z僵尸进程。
僵尸进程太多会拖慢系统的运行效率。
那僵尸进程怎么解决?把父进程杀死就好了,这时候虽然父进程也不会去收尸但此时僵尸进程会变成孤儿进程然后被安排一个新爹——也就是第1号的系统进程来负责回收这些僵尸进程。
同时使用wait系统调用还可以获取子进程的退出状态,带个参数就好了,这些参数的宏定义在man手册中是有的:

我们就可以通过比较这些参数来获得子进程的退出状态:
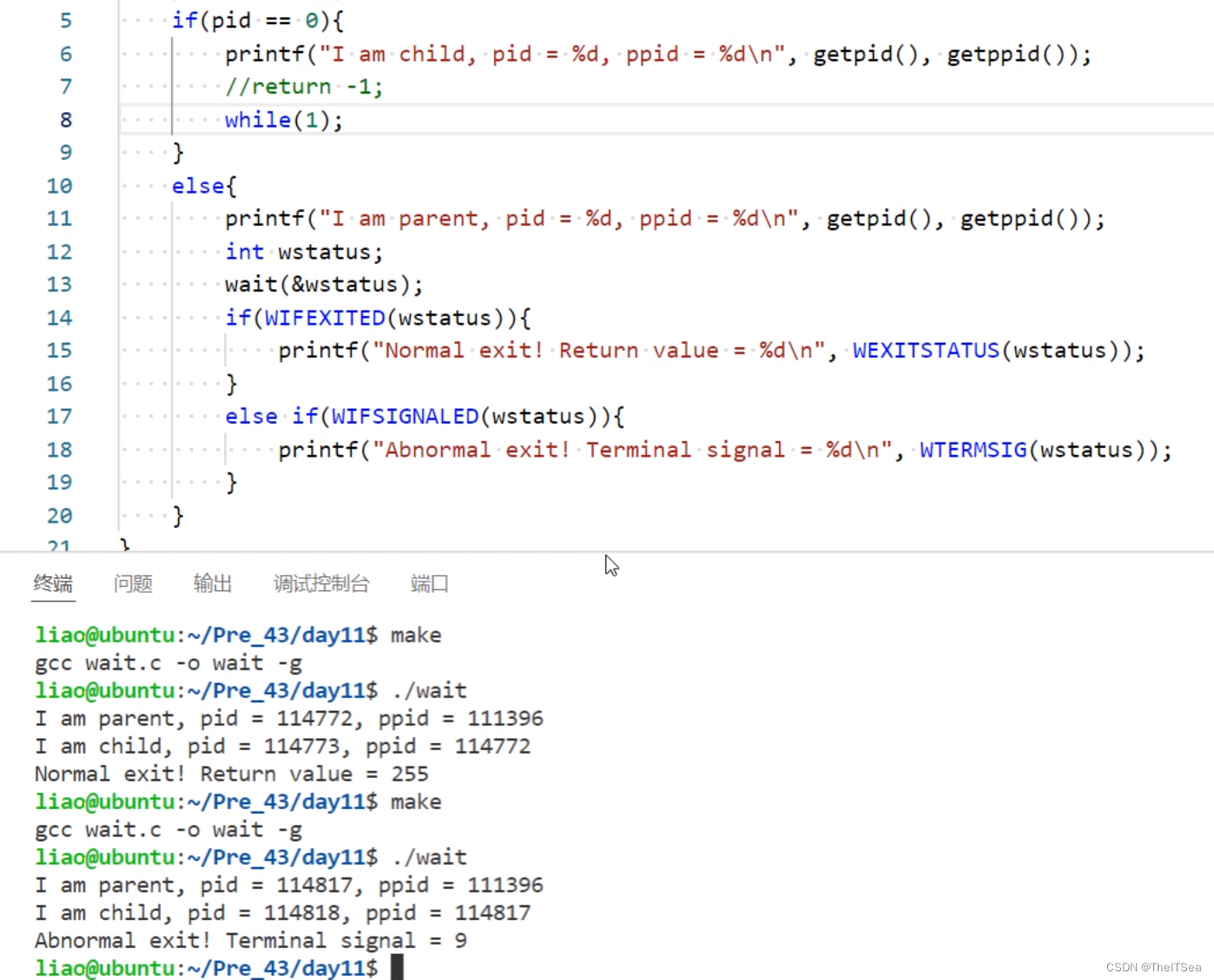
也可以自定义返回数字,wait都可以获取到的。
但该wait系统调用还是有缺陷,因为一个父进程很可能有多个子进程,可是wait只能等一个子进程死,也就是只能给一个子进程收尸,那么有没有办法可以去给指定的子进程收尸呢?
答案就是使用之前提到过的waitpid。
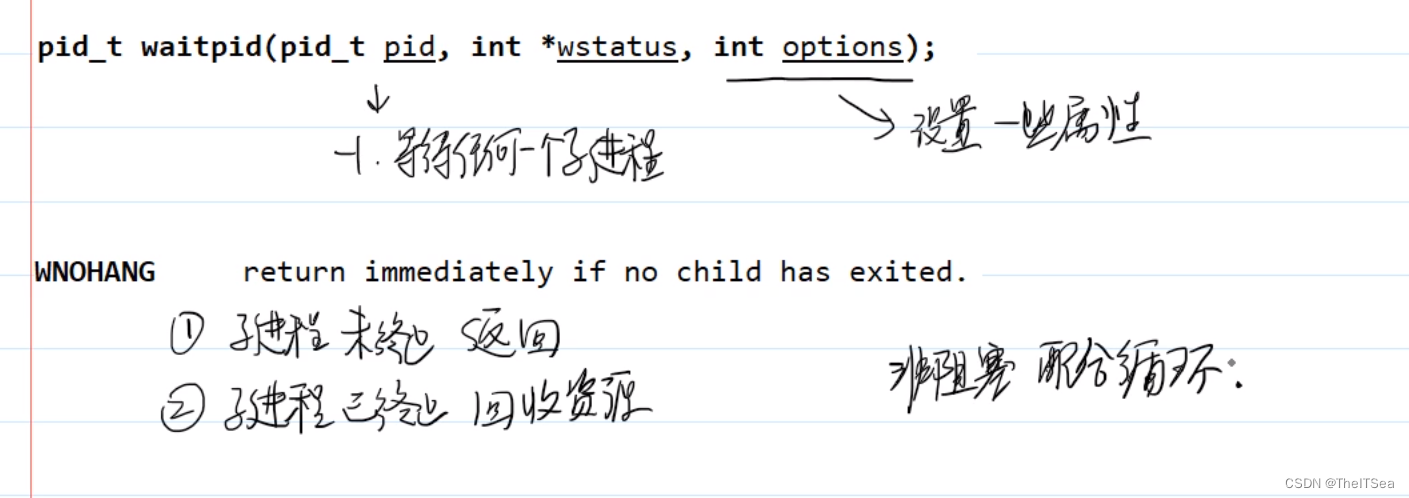
第一个参数设置为-1之后其实和我们wait就差不多了,这个函数最有用的就是可以进行一些属性的设置,而其中一个属性就是WNOHANG,
其作用是它来查看子进程死了没有,如果子进程死了那么就给它收尸回收其资源,如果没死它就立即返回0然后可以过一会儿再来查看子进程的状态以作出对应的判断,此时这种情况就是非阻塞的方式,这种方式就可以解放父进程让其去做更多的事情,同时为了避免父进程只监听一次子进程是否已经死了的情况,这种非阻塞的方式一般都配合循环来使用,在之前代码上简单修改进行一个简单的测试:
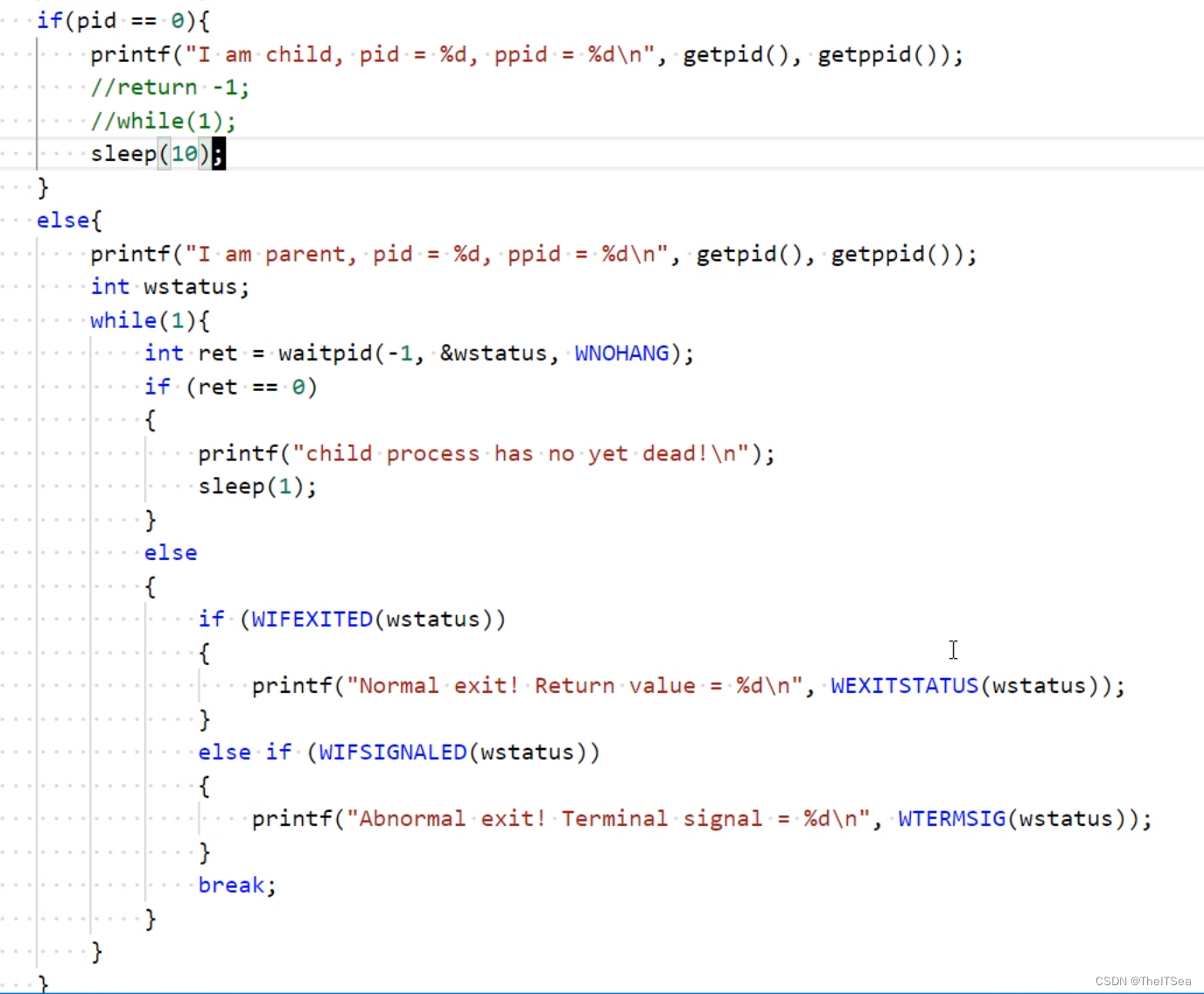
上图的代码就展示了当waitpid返回0时表示子进程还没死,那么就打印一句话,再通过死循环一直轮询,直到子进程死了那么就开始给它收尸回收其资源才break跳出循环结束父进程程序。
这就是WNOHANG属性的作用,实现同步非阻塞的进程管理,同步是指进程的执行有先后顺序并且严格执行该顺序,非阻塞的意思已经说过啦。
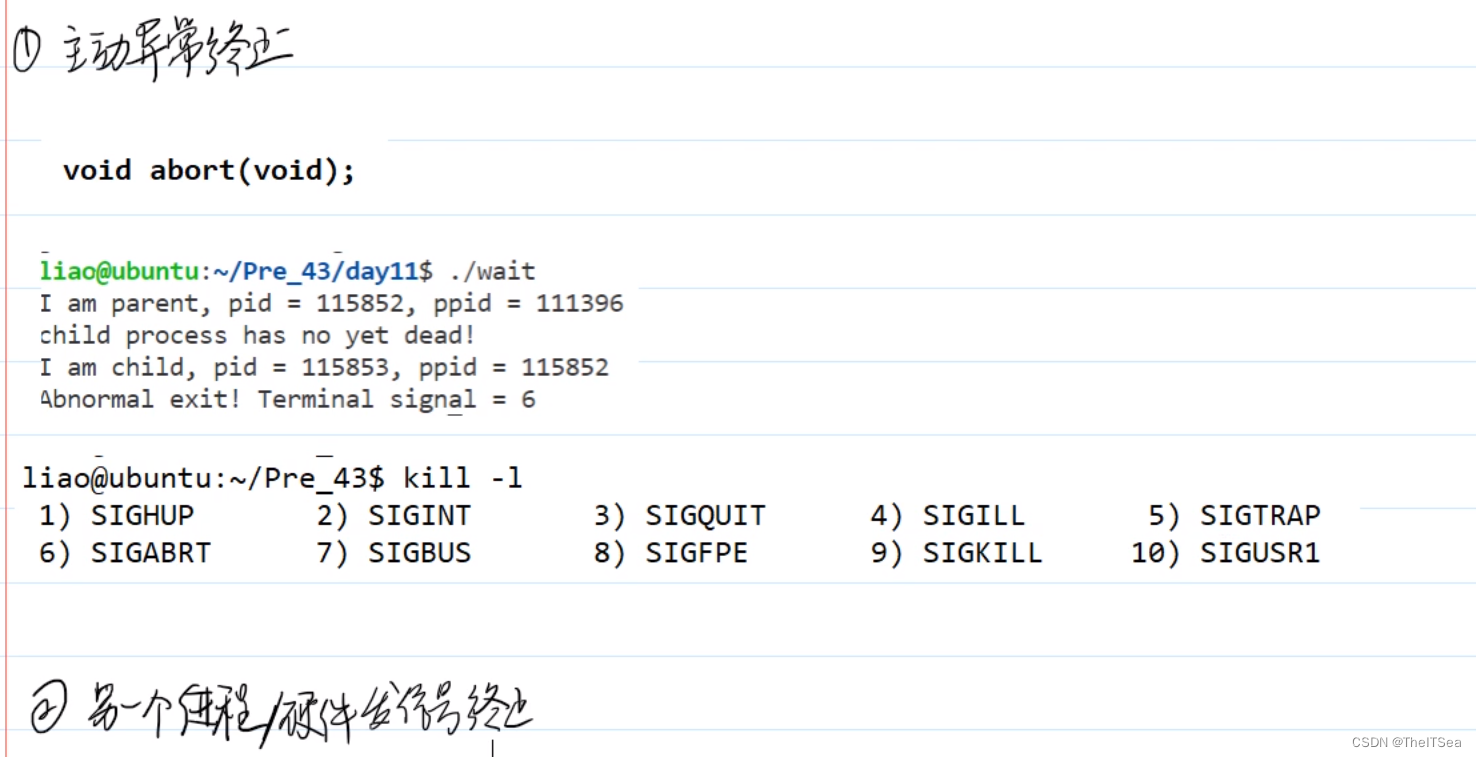
进程的终止
正常终止

异常终止
会话session

守护进程daemon

示例,写法一般比较固定:
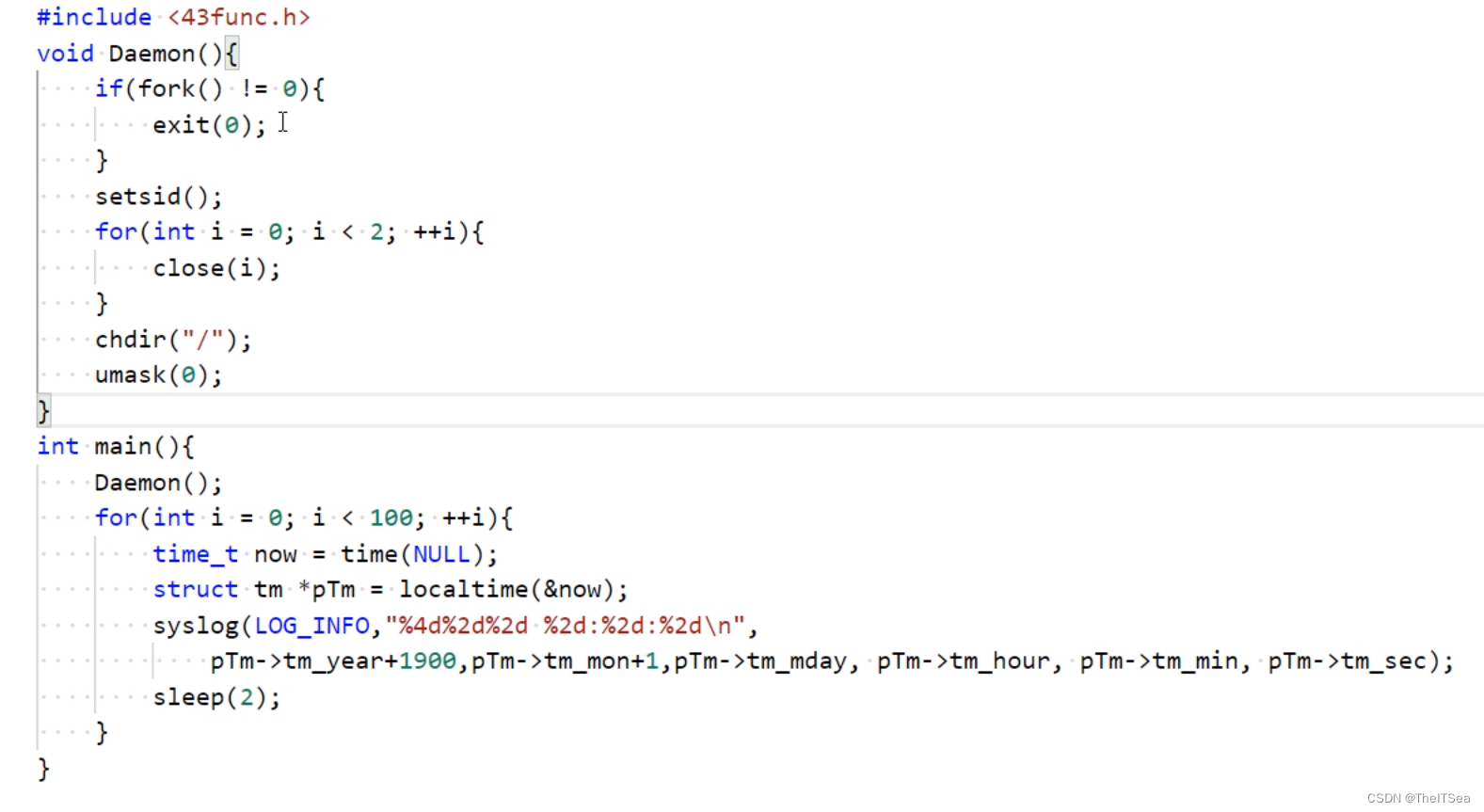
守护进程总是孤儿进程,因为其父进程已经没了。
Linux日志系统

进程间通信(Inter Process Communication)IPC
用来打破进程之间的隔离,从而进程可以共享数据。
进程间通信方法如下,但最重要的是管道和信号:

共享内存和信号量很难,学不懂的话也没事,因为在学习线程的时候这俩工具被更好用的东西取代了。
对于管道,之前学习的是在文件系统中的有名管道,而我们现在要学习的管道是匿名管道,其在文件系统中不存在,只用于父子进程之间。
匿名管道:popen库函数
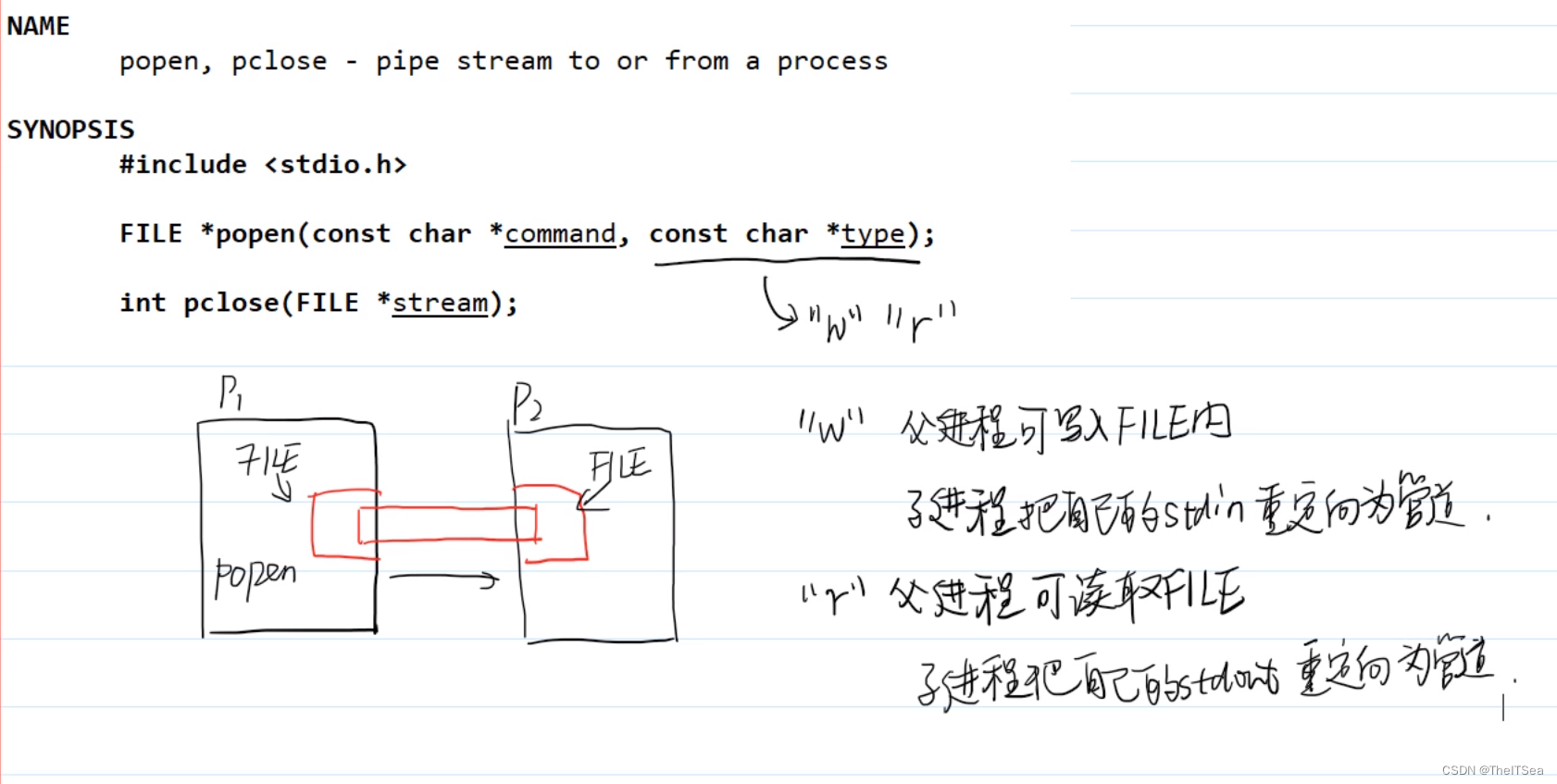
这个popen用的很少,知道有这回事儿即可。
pipe系统调用
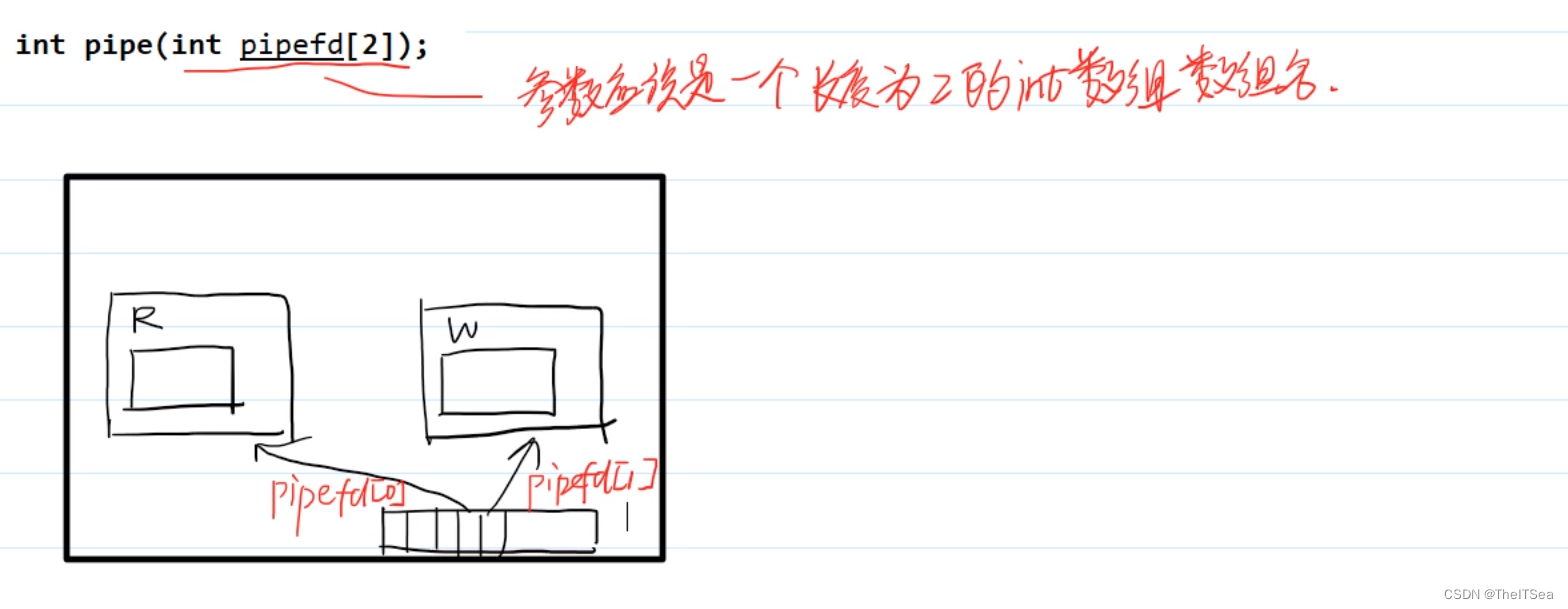
pipe做的事情很简单,在一个进程的内核态去创建出两个文件对象,对应的会有两个文件描述符去指向这两个文件对象,pipe需要传入的参数为一个大小为2的数组,其中pipefd[0]表示读,pipe[1]表示写。但如上图的形式现在只实现了自言自语,还没有做到进程间通信,简单测试:
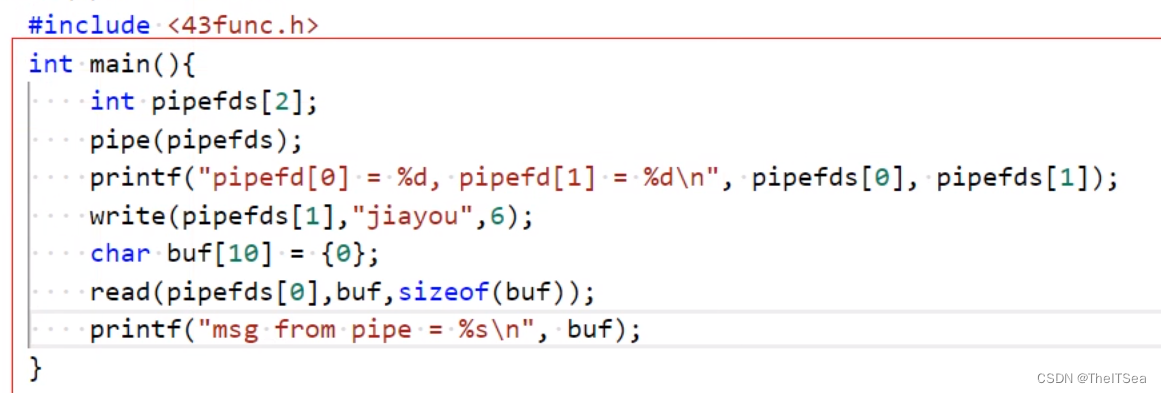
如果要实现进程间通信,那么我们可以先pipe再fork。
先pipe再fork
因为文件对象在父子进程之间是共享的,所以父子进程的文件描述符都会指向内核区相同的文件对象:
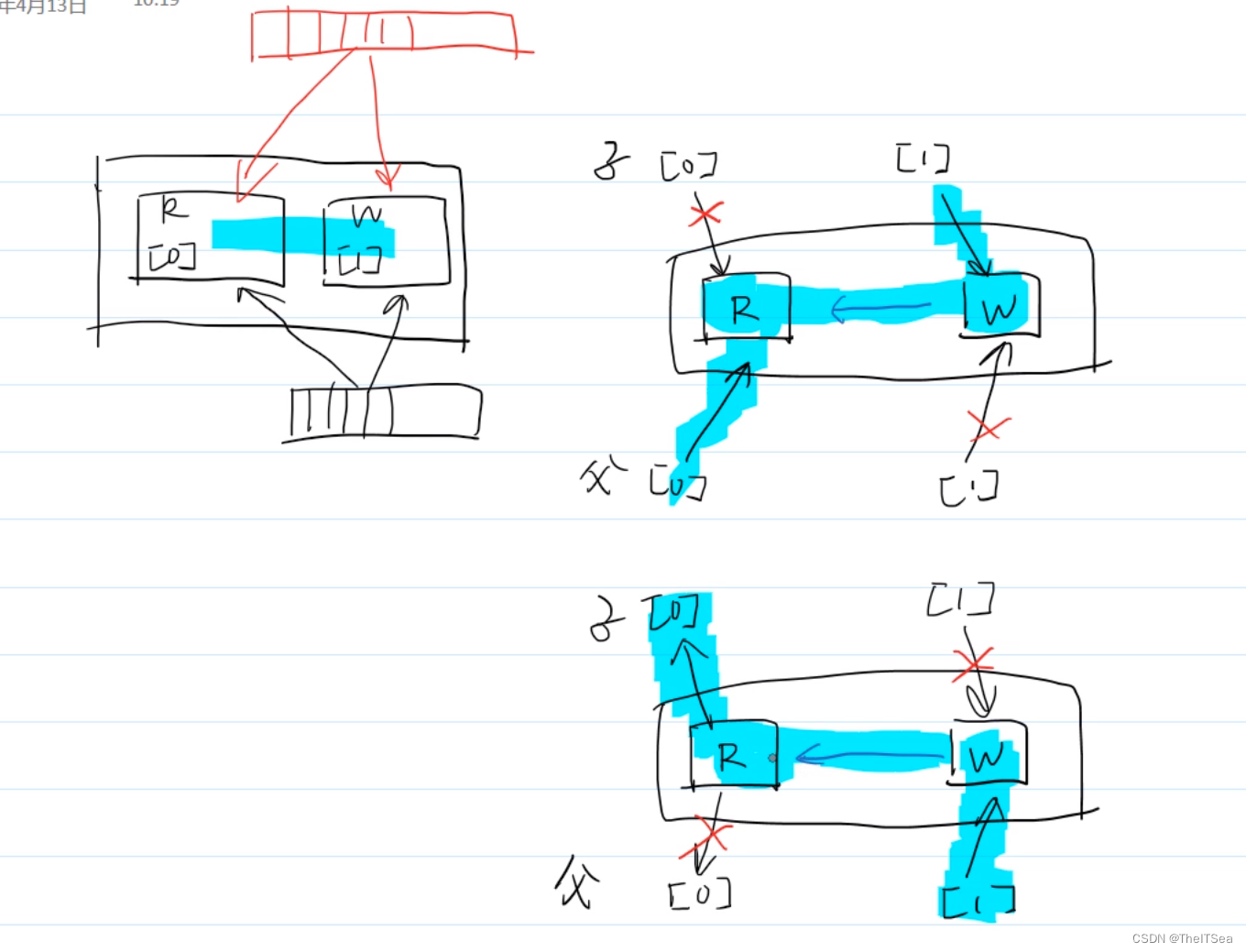
此时如上图所示,如果父进程读而子进程写的话,那么我们就可以关闭子进程的读和父进程的写,反过来同理。
但此时就成了单工通信,如果我们要实现全双工通信,那么可以再加一条管道即可:
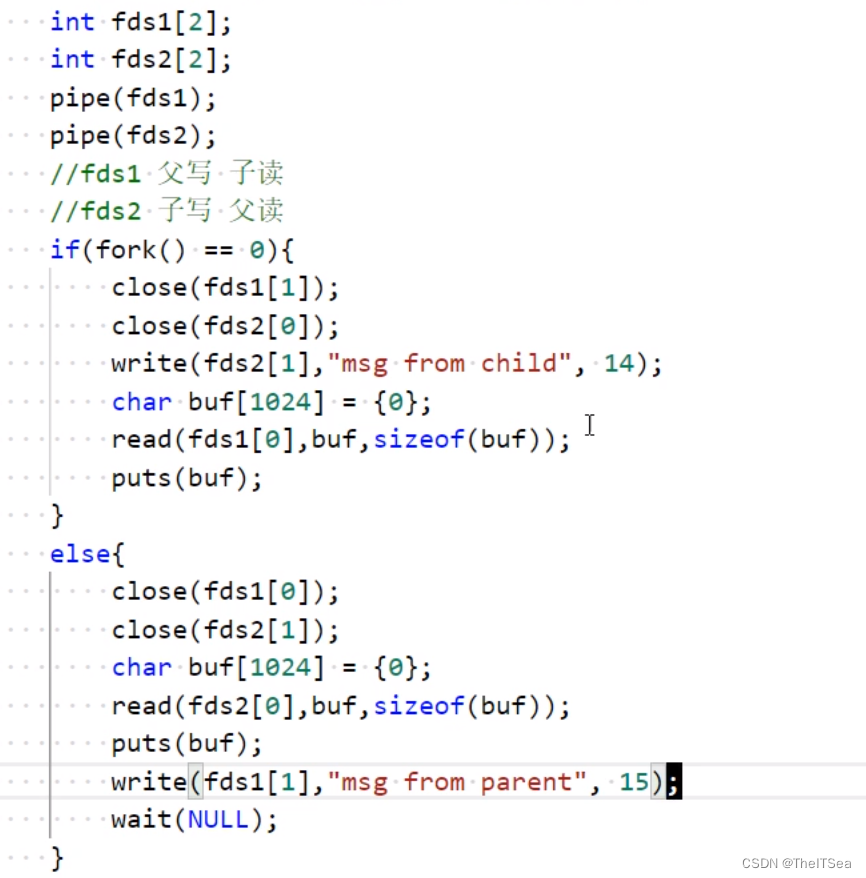
利用阻塞实现进程间同步的效果,如上图代码所示。
有名管道的函数

共享内存
理解共享内存的前提是,每一个进程的虚拟地址即使相同,它们在真实的物理内存上的位置也绝不会相同,这是为了进程安全,但是使用共享内存的话就可以让不同的进程的虚拟内存页对应到同一个物理页。
这样的话即使有一百个进程要进行通信,那么一百个进程都会共享到这块内存,改该内存的内容其它的一百个进程都会收到消息,效率非常高,所以共享内存是效率最高的进程间通信机制。
库文件就经常使用共享内存。
共享内存的使用方法
System V的共享内存机制
这里介绍的是System V标准的共享内存机制,不介绍POSIX标准是因为其太复杂设计的不好再加上本身这块内容就很难,所以选用了AT&T公司的System V标准。
ftok库函数
因为我们要使用共享内存肯定就会涉及到一种多个进程找到同一个内容的需求,所以我们会给这个内容一个整数key来标识它的身份,但是只用key的话对于用户不够友好,不好记,所以为了方便用户系统提供了ftok函数来通过文件名来查找其对应的key值:

简单测试:

拿到key之后我们就可以去创建共享内存了。
shmget系统调用
使用shmget系统调用来生成共享内存:
简单测试:
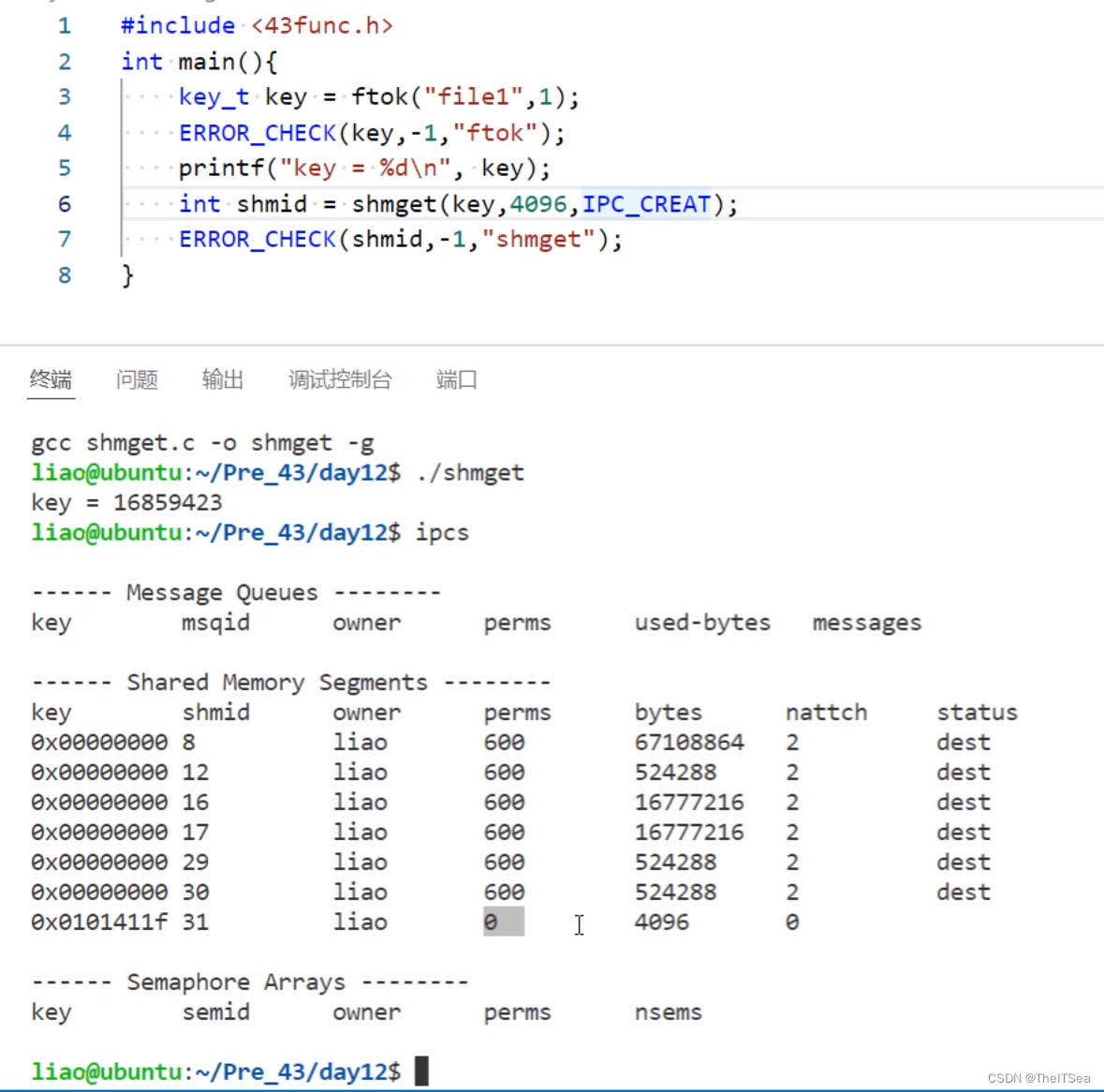
但此时我们发现一个问题是权限不对,我们使用ipcs查看了所有共享内存但发现我们创建的共享内存的权限只有0,所以我们要删掉它重新创建,使用ipcrm -M命令:
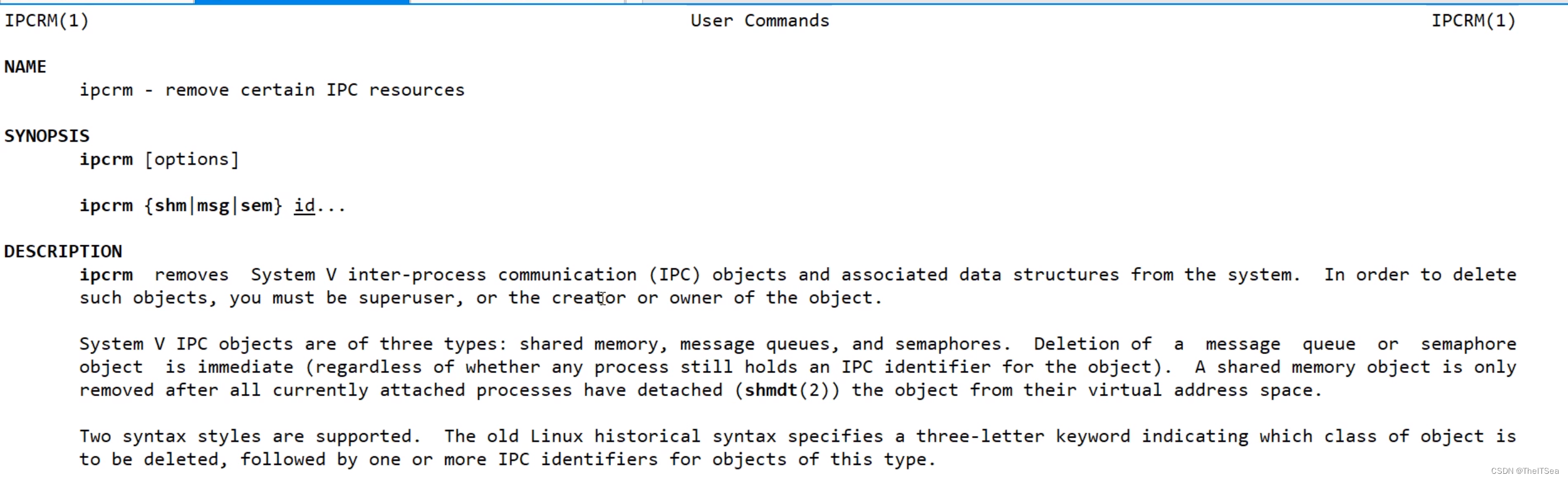
直接删去:
那么我们如何创建正确的具有读写权限的共享内存呢?其实直接让IPC_CREAT|0600即可:
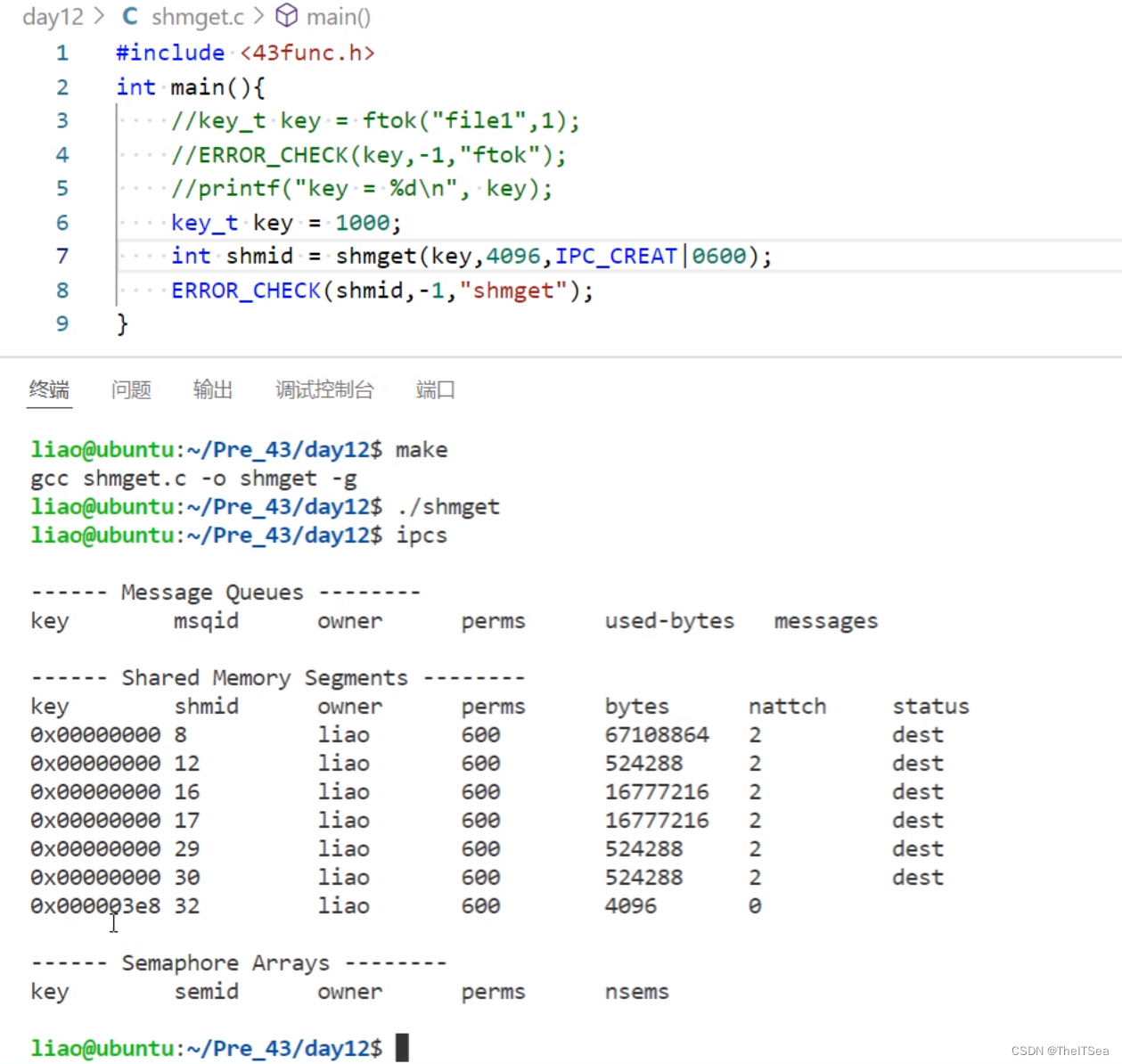
此时共享内存已经创建,但是还没有将该内存加载到进程的地址空间里面。
shmat和shmdt系统调用
其中shmat系统调用是用来帮助分配我们所创建共享内存的虚拟内存地址空间的,shmdt系统调用是用来回收所分配的虚拟内存的,这也就意味着其不会删除我们所创建的共享内存:

验证一下:
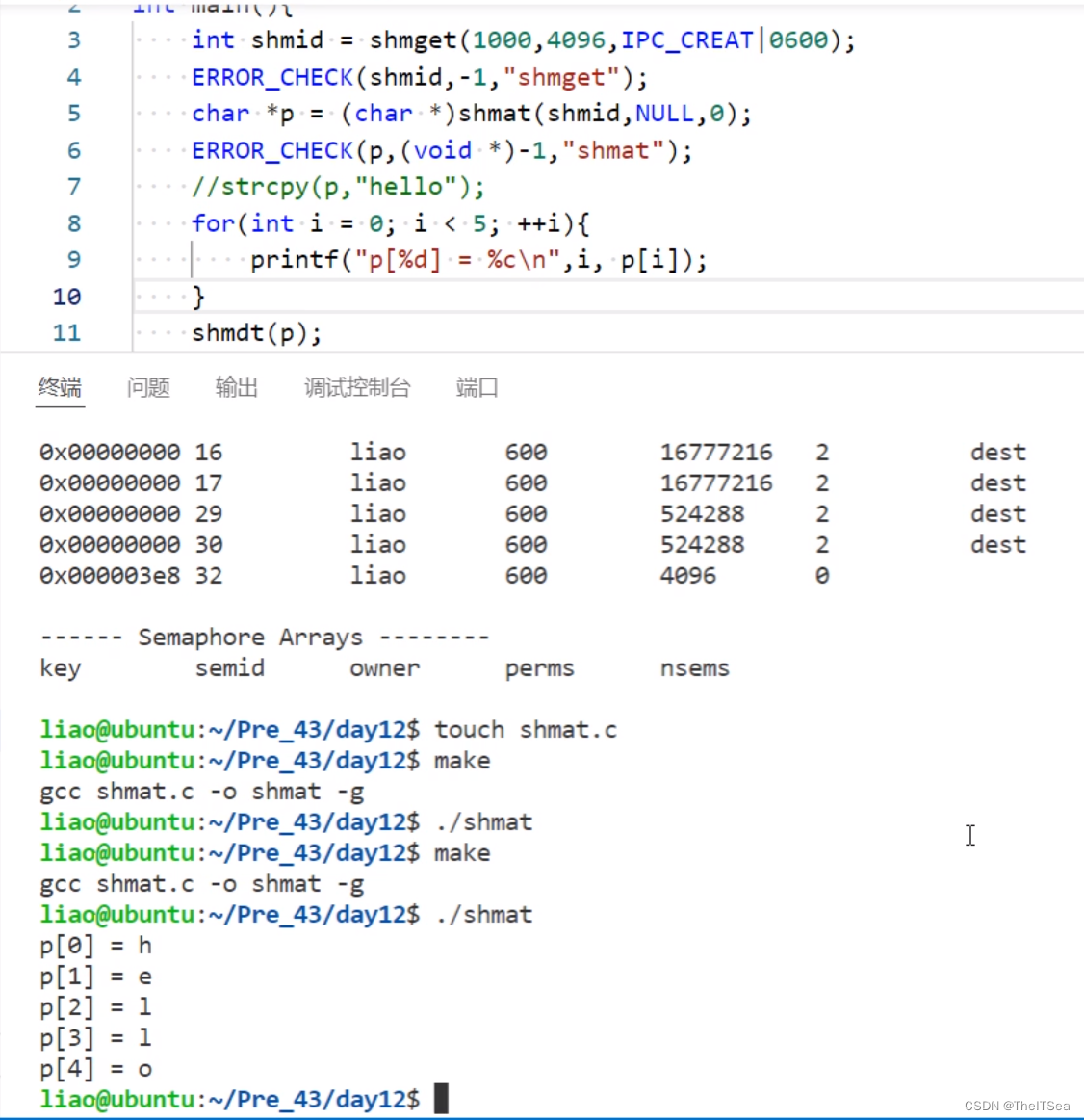
当我们在shmget函数中的第一个参数设置成IPC_PRIVATE(其值为0)之后,我们会发现不管创建几次其共享内存都会创建一个新的共享内存,因为一个进程创建的共享内存是0而另一个进程也通过这个0去访问该共享内存却访问不到(因为还是会创建一个新的)这时候咋办?
其实这种共享内存称为私有共享内存,又要共享又要私有,这种共享内存只能由父子进程之间来访问。
对于这种私有共享内存,我们一般的操作是先创建一片私有共享内存,为其创建内存空间之后就进行fork操作:
这就很类似于我们的匿名管道。
进程并发访问资源存在的竞争条件:

其实就是操作系统里面说过的东西,当我们把NUM设置成一千万这么大之后,父子进程并发执行,执行++p[0]到了后面很可能发生上图的情况,即每次运行并非都能达到我们想要的加到两千万的效果。
这是因为++p[0]的操作在汇编层面会被分为三步来做,而进程的时间片却很有可能在其中某句代码执行之前就被用完然后进程中断转到另一个进程去执行了,这就导致了结果的异常,也就是所谓的竞争条件。
怎么解决这个问题呢?
shmctl系统调用:获取共享内存状态

其中第二个参数cmd的类型在上图左侧的位置。
简单使用一下:
这个在工作当中用的很少,知道有这么回事情就好。