学习大数据还是绕不开始祖级别的技术hadoop。我们不用了解其太多,只要理解其大体流程,然后用python代码模拟主要流程来熟悉其思想。
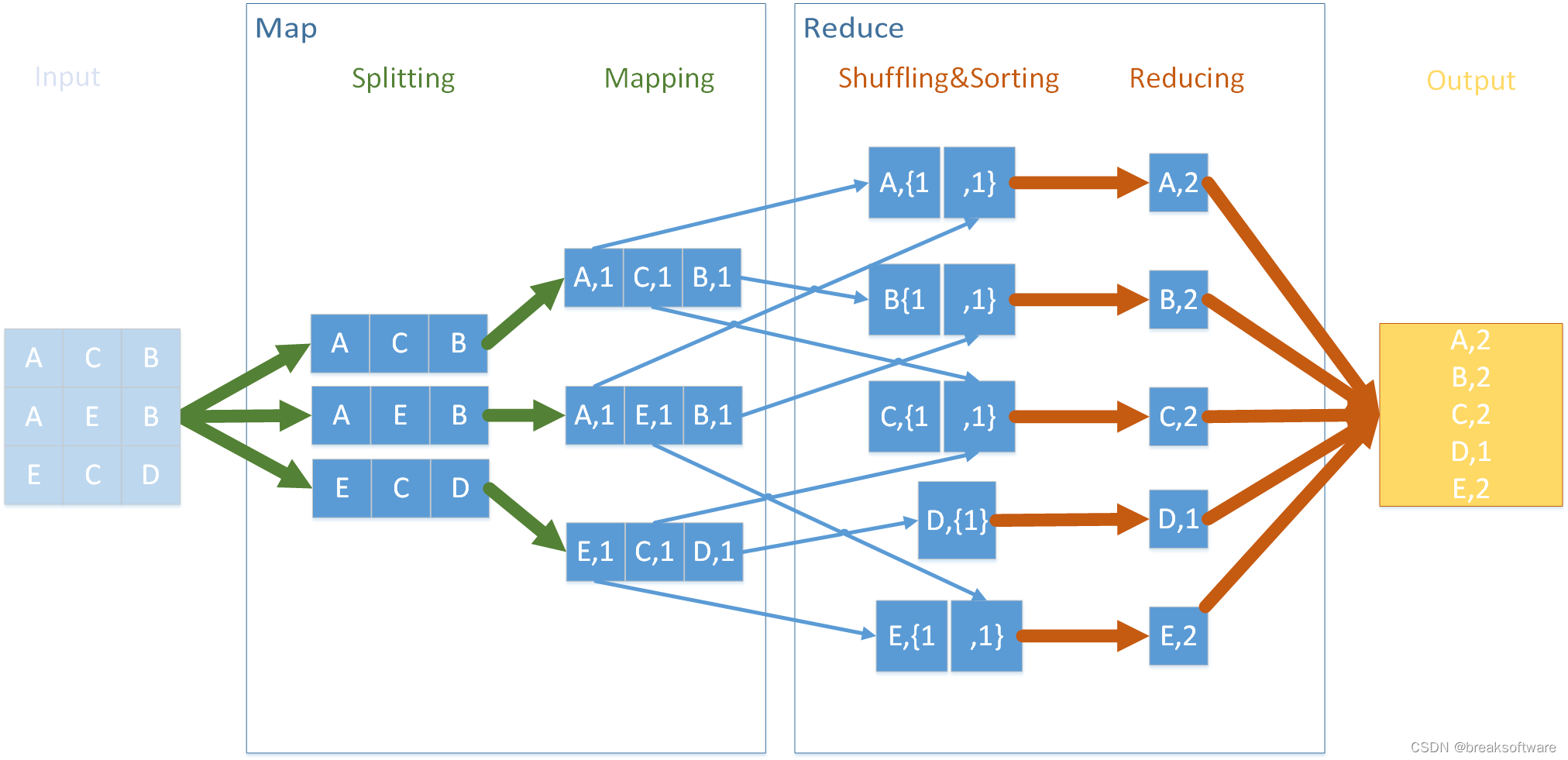
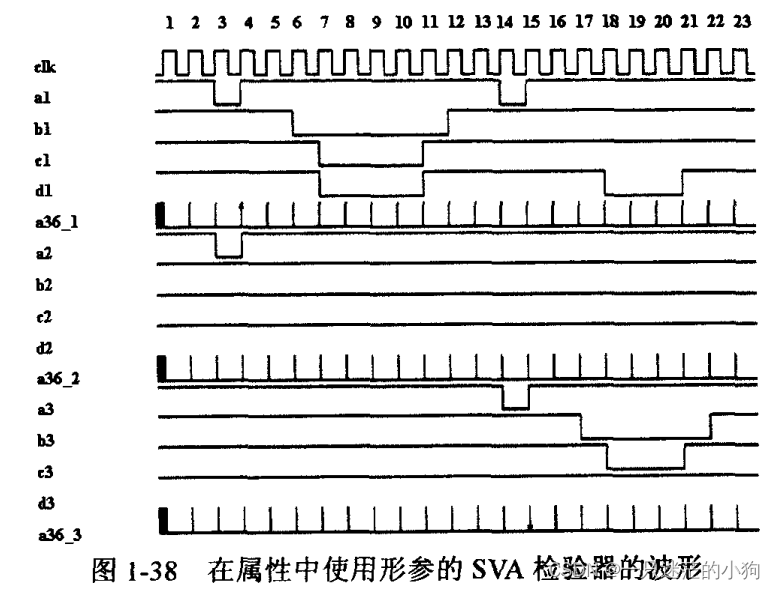
还是以单词统计为例,如果使用hadoop流程实现,则如下图。
为什么要搞这么复杂呢?
顾名思义,“大数据”意味着庞大的数据量需要计算。提升计算效率的方法无非如下:
- 更高效的算法
- 更高频率的处理器
- 更多的可并行执行的流程
- 更多的处理器
“更多的可并行执行的流程”意味着不同计算流程之间数据不存在前后依赖,这个也是GPU计算的基础。在这个前提下,我们又有足够多的处理器,则可以提升计算的并行度,大大缩短计算的时间。
沿着这个思路,我们该怎么做呢?
- 切分原始数据到符合计算的最小单元。
- 组合最小计算单元为可并行处理的数据单元。
- 执行并行计算。
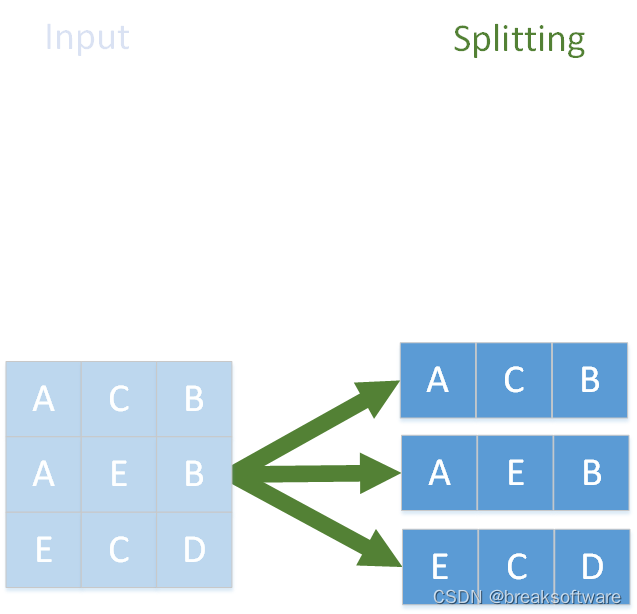
以上图所表达的数据为例。
我们有一个一维数组,元素分别是“A C B”,"A E B"和“E C D”。

我们可以把它分成三个独立的数组



这三个独立的数组可以再切分,这个切分可以并行执行,因为每组的切分和其他组没有任何关系。
[
[A,C,B]
[A,E,B]
[E,C,D]
]
作为一种通用的框架,需要协调好内部数据之间传输的格式。MapReduce正如其名,选择了Map结构来存储中间数据。如下图,切分后的字母为Key,Value是1(可以是个随意值)。
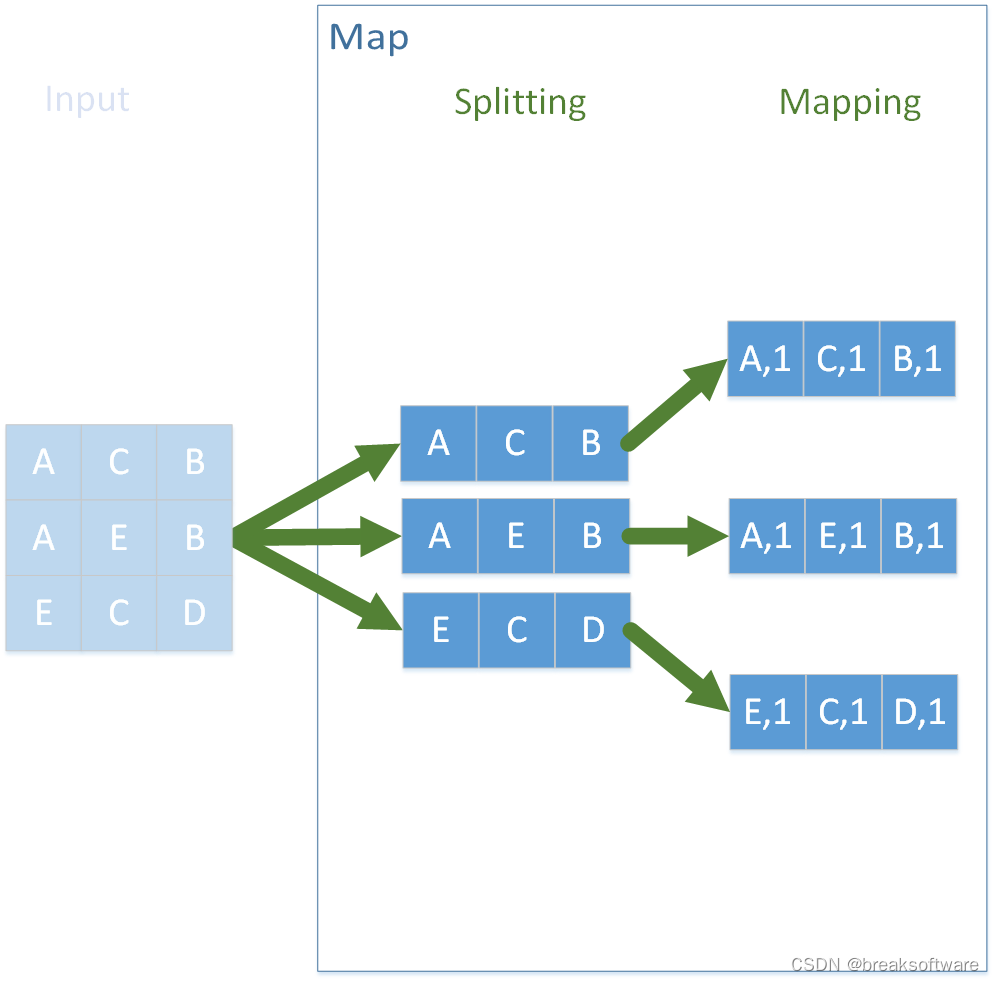
如上图,Map操作包括了Splitting和Mapping,它们将原始数据处理成若干个最小计算单元,且这个单元是内部通用结构map。
Mapping完的结构不适合高效的并行计算,因为数据存在关联关系。比如我们计算A的个数,则需要同时依赖第一组和第二组数据,没办法最大并行优化。
为了增加后续计算的可并行性,Reduce操作将这些最小计算单元归类(Shuffling&Sorting )。这个归类的过程的输入是一个个map,输出还是map。再次呼应了MapReduce的名字。
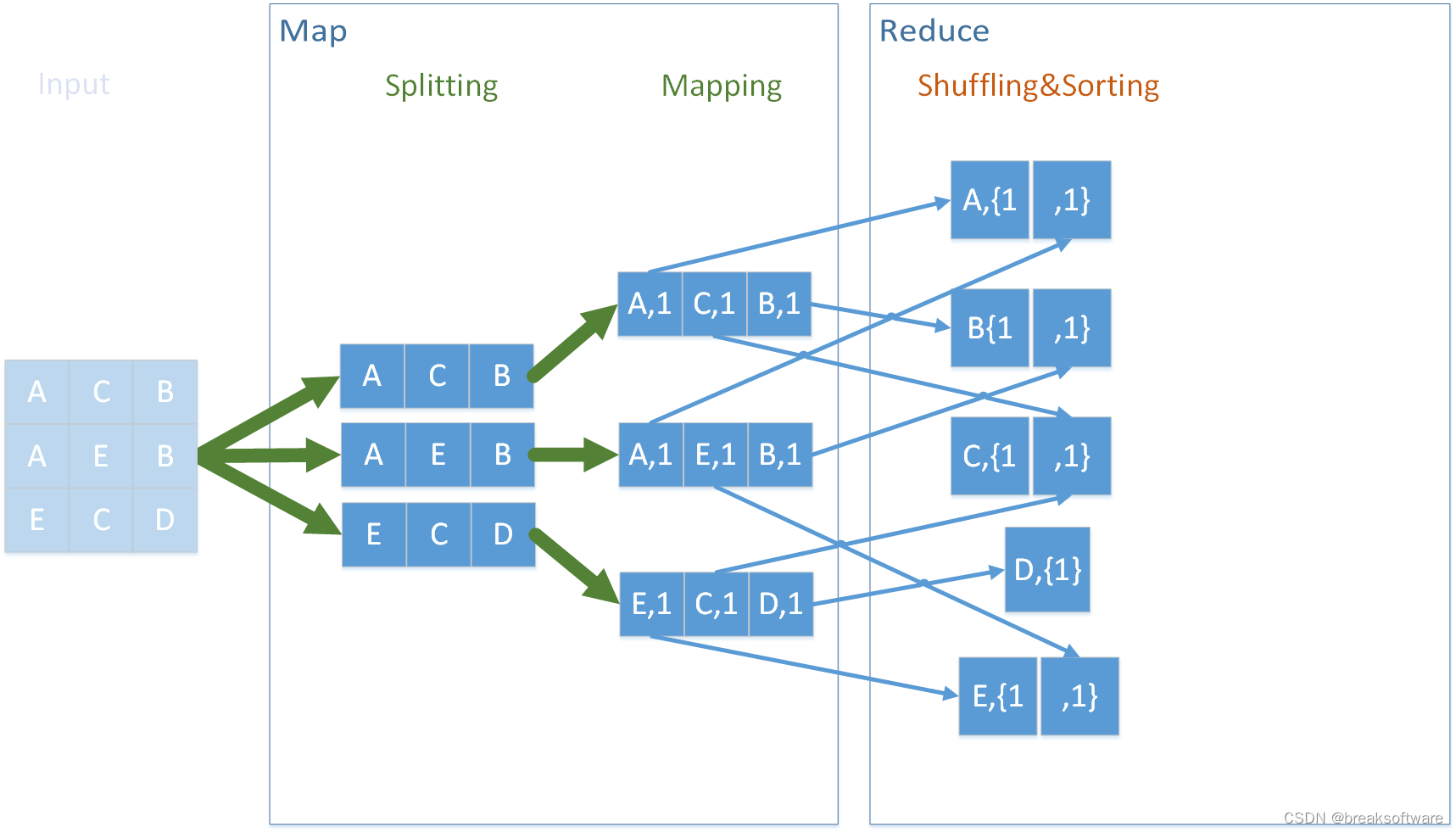
现在每组数据可以被独立分配到一个处理器上去计算了,因为它不依赖任何其他数据。比如计算A的个数,我们只要让一个处理器关注第一条数据,其他条数据根本不用关心。
最后的Reducing再将上述数据并行计算,它的输入和输出还是map,再次呼应MapReduce的名称。
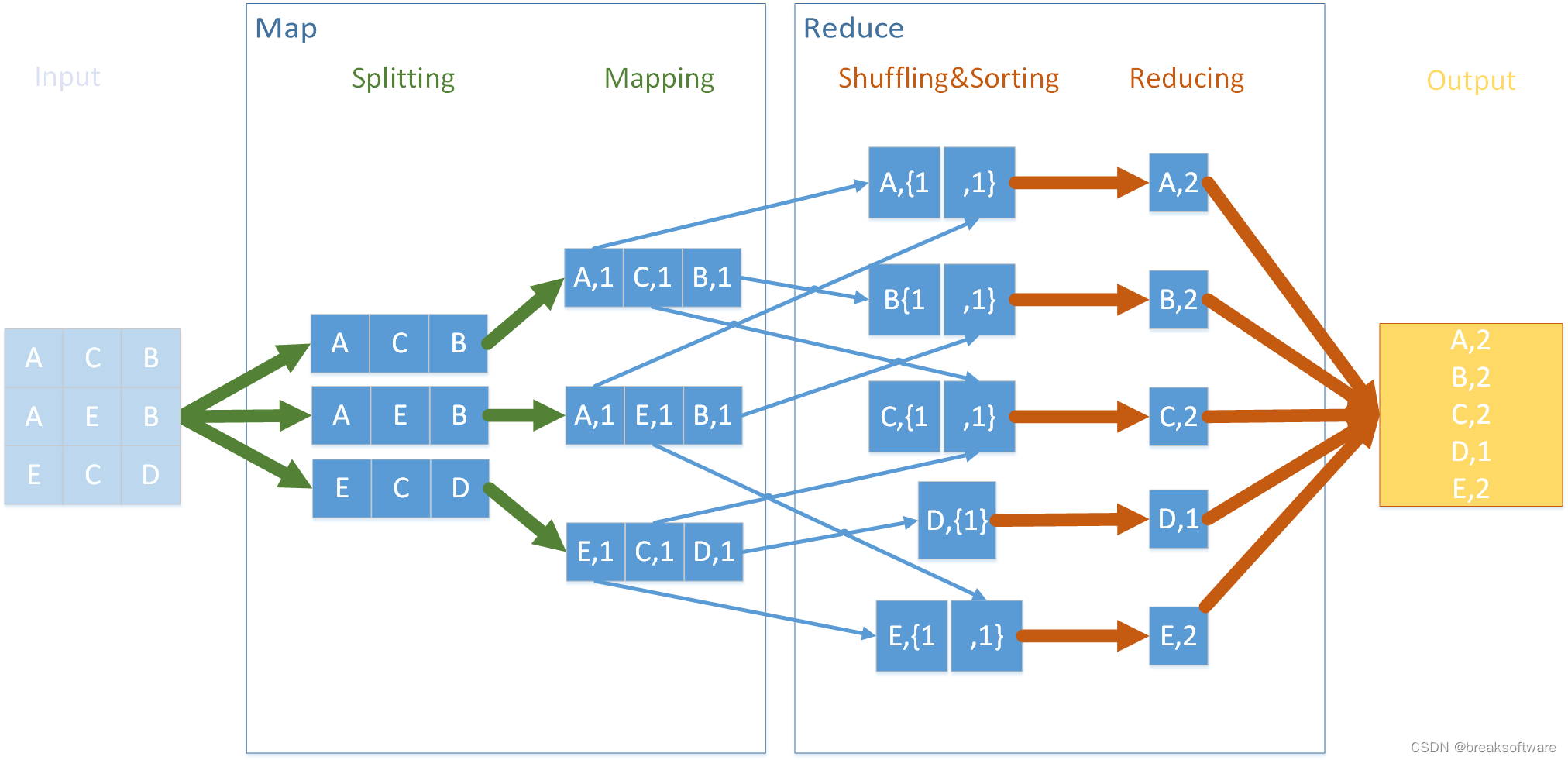
基于上面的拆解,我们使用python实现逻辑如下。需要注意的是,在流程中,我们传递的都是dict结构(map,即key value对)。
input = [
"A C B",
"A E B",
"E C D",
]
def split_map_shuffle_reduce(input):
# splitting
wordsSplitMap = {}
for (i, line) in zip(range(len(input)), input):
wordsSplitMap[i] = line.split()
# {0: ['A', 'C', 'B'], 1: ['A', 'E', 'B'], 2: ['E', 'C', 'D']}
# mapping
words = {}
for (i, wordsOneline) in zip(range(len(wordsSplitMap.values())), wordsSplitMap.values()):
words[i] = map(lambda word: (word,1), wordsOneline)
# {0: {'A': 1,'C': 1, 'B': 1}, 1: {'A': 1,'E': 1, 'B': 1}, 2: {'E': 1,'C': 1, 'D': 1}}
# shuffling
shuffle_sort_words = {}
for wordmap in words.values():
for word in wordmap:
shuffle_sort_words.setdefault(word[0], []).append(word[1])
# {'A': [1, 1], 'C': [1, 1], 'B': [1, 1], 'E': [1, 1], 'D': [1]}
# reducing
wordCount = {}
for word, count in shuffle_sort_words.items():
wordCount.update({word: sum(count)})
# {'A': 2, 'C': 2, 'B': 2, 'E': 2, 'D': 1}
return wordCount
output = split_map_shuffle_reduce(input)
print(output)
{‘A’: 2, ‘C’: 2, ‘B’: 2, ‘E’: 2, ‘D’: 1}
参考资料
- https://www.whizlabs.com/blog/understanding-mapreduce-in-hadoop-know-how-to-get-started/











![[Hive] explode](https://img-blog.csdnimg.cn/89a7d7071c1345e6a89c9118c1d4edb9.png)