Redis是基于内存操作的非关系型数据库,在内存空间不足的时候,为了保证程序的运行和命中率,就会淘汰一部分数据。如何淘汰数据?这就是Redis的内存回收策略。
Redis中的内存回收策略主要有两个方面:
Redis过期策略:删除已经过期的数据;
Redis淘汰策略:内存使用到达maxmemory上限时触发内存淘汰策略回收数据。
在Redis 官方文档中,有下面一段话:
There are two special functions called periodically by the event loop:
1. `serverCron()` is called periodically (according to `server.hz` frequency), and performs tasks that must be performed from time to time, like checking for timedout clients.
2. `beforeSleep()` is called every time the event loop fired, Redis served a few requests, and is returning back into the event loop.
Inside server.c you can find code that handles other vital things of the Redis server:
* `call()` is used in order to call a given command in the context of a given client.
* `activeExpireCycle()` handles eviciton of keys with a time to live set via the `EXPIRE` command.
* `freeMemoryIfNeeded()` is called when a new write command should be performed but Redis is out of memory according to the `maxmemory` directive.其中 activeExpireCycle() 和 freeMemoryIfNeeded() 就是内存回收策略的实现。而 activeExpireCycle() 的调用在 serverCron() 和 beforeSleep() 方法里面,定期删除过期的 key,而freeMemoryIfNeeded() 方法主要是当内存不够时,进行内存淘汰策略回收数据。
所以, Redis 采用「惰性删除+定期删除」这两种策略配和使用,在 CPU 使用上和避免内存浪费之间取得平衡。
1、Redis过期策略
如果一个 key 过期了,Redis会通过过期删除策略对过期的 key 进行删除。
Redis的过期策略有两种:惰性删除和定期删除。惰性删除为被动删除策略,而定期删除为主动删除策略。
通过EXPIRE命令和PEXPIRE命令,可以设置Redis中的某个 key 的生存时间(Time To Live,TTL),在经过设置的时间之后,服务器就会自动删除生存时间为0的 key 。
设置 key 的过期时间命令如下:
EXPIRE <key> <ttl> :设置 key 的生存时间,ttl单位为秒。
PEXPIRE <key> <ttl> :设置 key 的生存时间,ttl单位为毫秒。
EXPIREAT <key> <timestamp> :设置 key 的过期时间,timestamp为指定的秒数时间戳。
PEXPIREAT <key> <timestamp> :设置 key 的过期时间,timestamp为指定的毫秒数时间戳。
SETEX <key> <ttl> <value>:设置 key 的值为value,并设置超时时间,ttl单位为毫秒。
1.1、被动方式(passive way)
Redis不会主动扫描过期的 key 进行删除,而是在客户端尝试访问 key 时,检查 key 是否过期
- 如果 key 已经失效,就删除 key ;
- 如果 key 没有失效,就返回该 key 的值;
但是那些从未被查询过的 key ,即使这些 key 已经失效了,也无法删除。
惰性删除策略的优点:对CPU时间来说是最友好的,程序只会在获取 key 时才进行过期检查,并且只会删除当前执行的 key ,而不会在删除其他无关的过期 key 。
惰性删除策略的缺点:对内存不够友好,如果一个 key 已经过期,这个 key 有可能仍然保留在数据库中,所占用的内存不会释放。如果数据库中有非常多的过期 key ,而这些过期 key 又恰好没有被访问到的话,那么它们也许永远也不会被删除(除非用户手动执行FLUSHDB),我们甚至可以将这种情况看作是一种内存泄漏——无用的垃圾数据占用了大量的内存。
惰性删除的实现
Redis 解析完客户端执行的命令请求之后,会调用函数 processCommand 处理该命令请求,而处理命令请求之前还有很多校验逻辑,其中就有最大内存检测。如果配置文件中使用指令“maxmemory <bytes>”设置了最大内存限制,且当前内存使用量超过了该配置阈值,服务器会拒绝执行带有“m”(CMD_DENYOOM)标识的命令,如SET命令、APPEND命令和LPUSH命令等。
int processCommand(client *c) {
int is_denyoom_command = (c->cmd->flags & CMD_DENYOOM) ||
(c->cmd->proc == execCommand &&
(c->mstate.cmd_flags & CMD_DENYOOM));
/* Handle the maxmemory directive.
*
* Note that we do not want to reclaim memory if we are here re-entering
* the event loop since there is a busy Lua script running in timeout
* condition, to avoid mixing the propagation of scripts with the
* propagation of DELs due to eviction. */
if (server.maxmemory && !server.lua_timedout) {
int out_of_memory = freeMemoryIfNeededAndSafe() == C_ERR;
/* freeMemoryIfNeeded may flush slave output buffers. This may result
* into a slave, that may be the active client, to be freed. */
if (server.current_client == NULL) return C_ERR;
int reject_cmd_on_oom = is_denyoom_command;
/* If client is in MULTI/EXEC context, queuing may consume an unlimited
* amount of memory, so we want to stop that.
* However, we never want to reject DISCARD, or even EXEC (unless it
* contains denied commands, in which case is_denyoom_command is already
* set. */
if (c->flags & CLIENT_MULTI &&
c->cmd->proc != execCommand &&
c->cmd->proc != discardCommand) {
reject_cmd_on_oom = 1;
}
if (out_of_memory && reject_cmd_on_oom) {
rejectCommand(c, shared.oomerr);
return C_OK;
}
}
return C_OK;
}过期的惰性删除策略由 evict.c/freeMemoryIfNeededAndSafe()方法调用db.c/expireIfNeeded()实现, 所有读写数据库的Redis命令在执行之前都会调用freeMemoryIfNeededAndSafe() 对 key 进行校验
如果过期:那么expireIfNeeded函数将输入的 key 从数据库删除;
如果未过期:那么expireIfNeeded不做任何动作;
/* This is a wrapper for freeMemoryIfNeeded() that only really calls the
* function if right now there are the conditions to do so safely:
*
* - There must be no script in timeout condition.
* - Nor we are loading data right now.
*
*/
int freeMemoryIfNeededAndSafe(void) {
if (server.lua_timedout || server.loading) return C_OK;
return freeMemoryIfNeeded();
}/* This function is called when we are going to perform some operation
* in a given key, but such key may be already logically expired even if
* it still exists in the database. The main way this function is called
* is via lookupKey*() family of functions.
*
* The behavior of the function depends on the replication role of the
* instance, because slave instances do not expire keys, they wait
* for DELs from the master for consistency matters. However even
* slaves will try to have a coherent return value for the function,
* so that read commands executed in the slave side will be able to
* behave like if the key is expired even if still present (because the
* master has yet to propagate the DEL).
*
* In masters as a side effect of finding a key which is expired, such
* key will be evicted from the database. Also this may trigger the
* propagation of a DEL/UNLINK command in AOF / replication stream.
*
* The return value of the function is 0 if the key is still valid,
* otherwise the function returns 1 if the key is expired. */
int expireIfNeeded(redisDb *db, robj *key) {
if (!keyIsExpired(db,key)) return 0;
/* If we are running in the context of a slave, instead of
* evicting the expired key from the database, we return ASAP:
* the slave key expiration is controlled by the master that will
* send us synthesized DEL operations for expired keys.
*
* Still we try to return the right information to the caller,
* that is, 0 if we think the key should be still valid, 1 if
* we think the key is expired at this time. */
if (server.masterhost != NULL) return 1;
/* Delete the key */
server.stat_expiredkeys++;
propagateExpire(db,key,server.lazyfree_lazy_expire);
notifyKeyspaceEvent(NOTIFY_EXPIRED,
"expired",key,db->id);
return server.lazyfree_lazy_expire ? dbAsyncDelete(db,key) :
dbSyncDelete(db,key);
}1.2、主动方式(active way)
定期删除策略是每隔一段时间,程序就对数据库进行一次检查,从设置失效时间的 key 中,选择一部分失效的 key 进行删除操作。定期删除策略需要根据服务器的运行情况,合理地设置删除操作的执行时长和执行频率,减少删除操作对CPU时间的影响。
如果删除操作执行得太频繁,或者执行的时间太长,定期删除策略就会退化成定时删除策略,以至CPU时间过多地消耗在删除过期 key 上面。
如果删除操作执行得太少,或者执行的时间太短,定期删除策略又会和惰性删除策略一样,出现浪费内存的情况。
Redis 服务启动后,内部维护一个定时任务 databasesCron() ,默认每100ms执行一次(通过配置hz控制,1000/server.hz)。定时任务中删除过期 key 逻辑采用了自适应算法, 根据 key 的过期比例、 使用快慢两种速率模式回收 key 。定期删除策略通过 expire.c/activeExpireCycle(int type)实现,其中的入参 type 为 ACTIVE_EXPIRE_CYCLE_FAST(快)、ACTIVE_EXPIRE_CYCLE_SLOW(慢)回收模式。
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
server.hz = server.config_hz;
/* Adapt the server.hz value to the number of configured clients. If we have
* many clients, we want to call serverCron() with an higher frequency. */
if (server.dynamic_hz) {
while (listLength(server.clients) / server.hz >
MAX_CLIENTS_PER_CLOCK_TICK)
{
server.hz *= 2;
if (server.hz > CONFIG_MAX_HZ) {
server.hz = CONFIG_MAX_HZ;
break;
}
}
}
/* Handle background operations on Redis databases. */
databasesCron();
server.cronloops++;
return 1000/server.hz;
}Redis每隔 100ms 随机测试一些 key ,根据 key 的过期比例,使用快慢两种速率回收 key ,Redis 6.0之前的版本回收具体的流程:
1、随机选取20个带有过期时间的 key ;
2、删除其中已经过期的 key ;
3、如果超过25%的 key 被删除,则重复执行步骤1
定期删除不断重复的进行过期检测,直到过期的 keys 的百分百低于25%,这意味着,在任何给定的时刻,最多会清除1/4的过期 keys。
整个执行流程如下:
具体实现在 expire.c/activeExpireCycle() 方法里面,ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP 表示每次循环随机获取过期 key 的数量,默认值为20,循环终止条件为 expired > ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP/4,当过期 key 的数量小于等于5时,终止循环。
/* Try to expire a few timed out keys. The algorithm used is adaptive and
* will use few CPU cycles if there are few expiring keys, otherwise
* it will get more aggressive to avoid that too much memory is used by
* keys that can be removed from the keyspace.
*
* No more than CRON_DBS_PER_CALL databases are tested at every
* iteration.
*
* This kind of call is used when Redis detects that timelimit_exit is
* true, so there is more work to do, and we do it more incrementally from
* the beforeSleep() function of the event loop.
*
* Expire cycle type:
*
* If type is ACTIVE_EXPIRE_CYCLE_FAST the function will try to run a
* "fast" expire cycle that takes no longer than EXPIRE_FAST_CYCLE_DURATION
* microseconds, and is not repeated again before the same amount of time.
*
* If type is ACTIVE_EXPIRE_CYCLE_SLOW, that normal expire cycle is
* executed, where the time limit is a percentage of the REDIS_HZ period
* as specified by the ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC define. */
void activeExpireCycle(int type) {
for (j = 0; j < dbs_per_call && timelimit_exit == 0; j++) {
int expired;
redisDb *db = server.db+(current_db % server.dbnum);
/* Increment the DB now so we are sure if we run out of time
* in the current DB we'll restart from the next. This allows to
* distribute the time evenly across DBs. */
current_db++;
/* Continue to expire if at the end of the cycle more than 25%
* of the keys were expired. */
do {
/* We don't repeat the cycle if there are less than 25% of keys
* found expired in the current DB. */
} while (expired > ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP/4);
}
}Redis 6.0版本对 activeExpireCycle() 方法进行了调整,Redis 每隔100ms,就对一些 key 进行采样检查,检查是否过期,如果过期就进行删除,具体流程:
1、采样一定个数的key,采样的个数可以进行配置,并将其中过期的 key 全部删除;
2、如果过期 key 的占比超过可接受的过期 key 的百分比,则重复执行步骤1
3、如果过期 key 的比例降至可接受的过期 key 的百分比以下,结束回收流程。
其中从库中的过期 key 只能通过主库进行删除。
void activeExpireCycle(int type) {
/* Adjust the running parameters according to the configured expire
* effort. The default effort is 1, and the maximum configurable effort
* is 10. */
unsigned long
effort = server.active_expire_effort-1, /* Rescale from 0 to 9. */
config_cycle_acceptable_stale = ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE-
effort;
/* Accumulate some global stats as we expire keys, to have some idea
* about the number of keys that are already logically expired, but still
* existing inside the database. */
long total_sampled = 0;
long total_expired = 0;
for (j = 0; j < dbs_per_call && timelimit_exit == 0; j++) {
/* Expired and checked in a single loop. */
unsigned long expired, sampled;
redisDb *db = server.db+(current_db % server.dbnum);
/* Increment the DB now so we are sure if we run out of time
* in the current DB we'll restart from the next. This allows to
* distribute the time evenly across DBs. */
current_db++;
/* Continue to expire if at the end of the cycle there are still
* a big percentage of keys to expire, compared to the number of keys
* we scanned. The percentage, stored in config_cycle_acceptable_stale
* is not fixed, but depends on the Redis configured "expire effort". */
do {
unsigned long num, slots;
long long now, ttl_sum;
int ttl_samples;
iteration++;
/* If there is nothing to expire try next DB ASAP. */
if ((num = dictSize(db->expires)) == 0) {
db->avg_ttl = 0;
break;
}
slots = dictSlots(db->expires);
now = mstime();
/* When there are less than 1% filled slots, sampling the key
* space is expensive, so stop here waiting for better times...
* The dictionary will be resized asap. */
if (num && slots > DICT_HT_INITIAL_SIZE &&
(num*100/slots < 1)) break;
/* The main collection cycle. Sample random keys among keys
* with an expire set, checking for expired ones. */
expired = 0;
sampled = 0;
ttl_sum = 0;
ttl_samples = 0;
if (num > config_keys_per_loop)
num = config_keys_per_loop;
/* Here we access the low level representation of the hash table
* for speed concerns: this makes this code coupled with dict.c,
* but it hardly changed in ten years.
*
* Note that certain places of the hash table may be empty,
* so we want also a stop condition about the number of
* buckets that we scanned. However scanning for free buckets
* is very fast: we are in the cache line scanning a sequential
* array of NULL pointers, so we can scan a lot more buckets
* than keys in the same time. */
long max_buckets = num*20;
long checked_buckets = 0;
while (sampled < num && checked_buckets < max_buckets) {
for (int table = 0; table < 2; table++) {
if (table == 1 && !dictIsRehashing(db->expires)) break;
unsigned long idx = db->expires_cursor;
idx &= db->expires->ht[table].sizemask;
dictEntry *de = db->expires->ht[table].table[idx];
long long ttl;
/* Scan the current bucket of the current table. */
checked_buckets++;
while(de) {
/* Get the next entry now since this entry may get
* deleted. */
dictEntry *e = de;
de = de->next;
ttl = dictGetSignedIntegerVal(e)-now;
if (activeExpireCycleTryExpire(db,e,now)) expired++;
if (ttl > 0) {
/* We want the average TTL of keys yet
* not expired. */
ttl_sum += ttl;
ttl_samples++;
}
sampled++;
}
}
db->expires_cursor++;
}
total_expired += expired;
total_sampled += sampled;
/* We can't block forever here even if there are many keys to
* expire. So after a given amount of milliseconds return to the
* caller waiting for the other active expire cycle. */
if ((iteration & 0xf) == 0) { /* check once every 16 iterations. */
elapsed = ustime()-start;
if (elapsed > timelimit) {
timelimit_exit = 1;
server.stat_expired_time_cap_reached_count++;
break;
}
}
/* We don't repeat the cycle for the current database if there are
* an acceptable amount of stale keys (logically expired but yet
* not reclaimed). */
} while (sampled == 0 ||
(expired*100/sampled) > config_cycle_acceptable_stale);
}
}当失效的 key 占检测样本的 key 的比例小于等于10%,就终止循环,结束回收流程。判断条件 (expired*100/sampled) > config_cycle_acceptable_stale) ,其中 config_cycle_acceptable_stale 的值为10。config_cycle_acceptable_stale的计算公式如下:
config_cycle_acceptable_stale = ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE-
effort;
effort = server.active_expire_effort-1, /* Rescale from 0 to 9. */
server.active_expire_effort 的默认值为1,ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE的默认值为10,所以结束回收的条件就是 (expired(失效的key的数量)/sampled(抽取key的数量)*100) > 10 。
定期删除的优点是:通过定期删除过期 key ,有效地减少了因为过期 key 带来的内存浪费。
定期删除的缺点是:会漏掉了很多过期 key ,然后你也没及时去查,也就没走惰性删除,造成大量过期 key 堆积在内存里。
Redis服务器使用的是惰性删除和定期删除两种策略,通过配合使用这两种删除策略,服务器可以很好地在合理使用CPU时间和避免浪费内存空间之间取得平衡。
1.3、RDB、AOF对过期 key 的处理
1.3.1、RDB对过期 key 的处理
执行SAVE命令或者BGSAVE命令创建一个新的RDB文件时,程序会对数据库中的 key 进行检查,已过期的 key 不会被保存到新创建的RDB文件中。
在启动Redis服务器时,如果服务器开启了RDB功能,那么服务器将对RDB文件进行载入:
如果服务器以主服务器模式运行,在载入RDB文件时会对文件中的 key 进行检查,未过期的 key 会被载入到数据库中,而过期的 key 则会被忽略。
如果服务器以从服务器模式运行,那么在载入RDB文件时,文件中保存的所有 key ,不论是否过期,都会被载入到数据库中。不过,因为主从服务器在进行数据同步的时候,从服务器的数据库就会被清空。
1.3.2、AOF对过期 key 的处理
当服务器以AOF持久化模式运行时,如果数据库中的某个 key 已经过期,但它还没有被惰性删除或者定期删除,那么AOF文件不会因为这个过期 key 而产生任何影响。当过期 key 被惰性删除或者定期删除之后,程序会向AOF文件追加(append)一条DEL命令,来显式地记录该 key 已被删除。因此,数据库中包含过期 key 不会对AOF重写造成影响。
2、Redis内存淘汰机制
2.1、内存淘汰策略(maxmemory-policy)
当Redis使用内存空间超过 maxmemory 的值时,Redis将根据配置的淘汰策略,尝试删除一部分 key 。Redis 4.0之前一共实现了6种内存淘汰策略,在4.0之后,又增加了volatile-lfu和all keys -lfu 2种淘汰策略。
根据淘汰数据类型分成两类:
- 设置过期时间 key 的淘汰策略:volatile-random、volatile-ttl、volatile-lru、volatile-lfu;
- 所有 key 范围的淘汰策略:all keys -lru、all keys -random、all keys -lfu;
Redis 默认淘汰策略是noeviction,在使用的内存空间超过maxmemory值时,并不会淘汰数据,如果缓存被写满,只读命令GET等可以正常执行,而执行SET, LPUSH等命令,Redis将会报错。
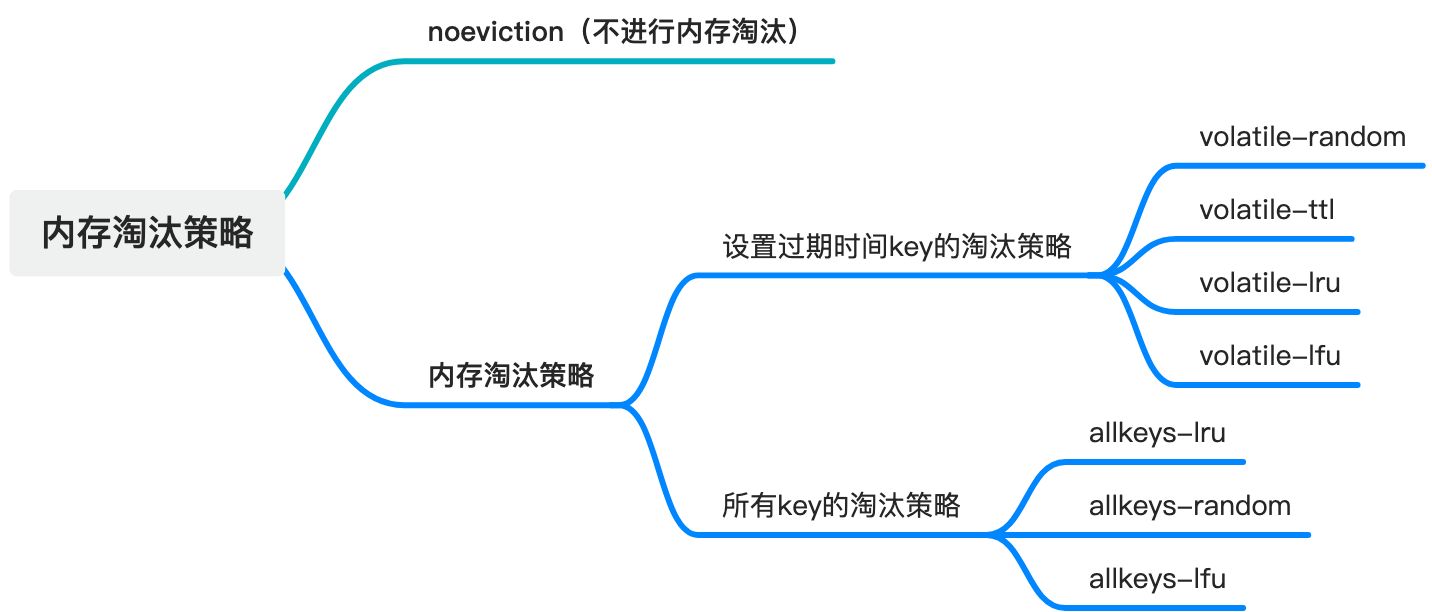
Redis淘汰策略:
- noeviction(默认):新写入操作会报错;
- volatile-ttl:在设置了过期时间的 key 中,越早过期的越先被删除;
- volatile-random:在设置了过期时间的 key 中,随机移除某个 key ;
- volatile-lru:在设置了过期时间的 key 中,使用LRU算法,移除最近最少使用的 key ;
- volatile-lfu:在设置了过期时间的 key 中,使用LFU算法,移除最最不经常使用的 key ;
- all keys -lru:在 key 中,使用LRU算法,移除最近最少使用的 key ;
- all keys -lfu:在 key 中,使用LFU算法,移除最近最少使用的 key ;
- all keys -random:在 key 中,随机移除某个 key ;
备注:
内存淘汰策略 Redis 官方文档
Key eviction | Redis
2.1、最大内存和内存回收策略
maxmemory用来设置redis存放数据的最大的内存大小,一旦超出这个内存大小之后,就会立即使用Redis的淘汰策略,来淘汰内存中的一些对象,以保证新数据的存入。当maxmemory限制达到的时,Redis会使用的行为由 Redis的maxmemory-policy配置指令来进行配置。
通过redis.conf可以设置maxmemory的值,或者之后使用CONFIG SET命令来配置maxmemory的值。
// 设置最大的内存限制
config set maxmemory 100mb修改Redis的配置文件 redis.confg 配置maxmemory的最大值。
maxmemory 100mb #内存限制为100mbmaxmemory设置为0表示没有内存限制。64位系统默认值为0,32位系统默认内存限制为3GB。
/* 32 bit instances are limited to 4GB of address space, so if there is
* no explicit limit in the user provided configuration we set a limit
* at 3 GB using maxmemory with 'noeviction' policy'. This avoids
* useless crashes of the Redis instance for out of memory. */
if (server.arch_bits == 32 && server.maxmemory == 0) {
serverLog(LL_WARNING,"Warning: 32 bit instance detected but no memory limit set. Setting 3 GB maxmemory limit with 'noeviction' policy now.");
server.maxmemory = 3072LL*(1024*1024); /* 3 GB */
server.maxmemory_policy = MAXMEMORY_NO_EVICTION;
}2.3、淘汰策略回收过程
理解回收进程如何工作是非常重要的:
1、客户端运行了新的命令,添加了新的数据
2、Redi检查内存使用情况,如果大于maxmemory的限制, 则根据设定好的策略进行回收。
3、执行新的命令
Redis的LRU算法并非完整的实现。这意味着Redis并没办法选择最佳候选来进行回收,也就是最久未被访问的 key 。相反它会尝试运行一个近似LRU的算法,通过对少量 keys 进行取样,然后回收其中一个最好的 key (被访问时间较早的)。
不过从Redis 3.0算法已经改进为回收 key 的候选池子。这改善了算法的性能,使得更加近似真是的LRU算法的行为。
Redis LRU有个很重要的点,你通过调整每次回收时检查的采样数量,以实现调整算法的精度。这个参数可以通过以下的配置指令调整:
maxmemory-samples 5
Redis为什么不使用真实的LRU实现是因为这需要太多的内存。不过近似的LRU算法对于应用而言应该是等价的。
参考
《Redis设计与实现》—— 黄健宏
《Redis5设计与源码分析》—— 陈雷