1、前言
SpringBoot不用我多介绍了吧,目前后端最流行的框架。后端开发人员最基本的要求。
Druid数据库连接池,出自国内 ”java圣地" 阿里巴巴。
Druid是一个用于大数据实时查询和分析的高容错、高性能开源分布式系统,旨在快速处理大规模的数据,并能够实现快速查询和分析。
- Druid的低延迟数据摄取架构允许事件在它们创建后毫秒内可被查询到,这使其具有快速的交互式查询能力。同时,Druid的数据在系统更新时依然可用,规模的扩大和缩小都不会造成数据丢失,这意味着它具有高可用性。
- Druid出自Alibaba,已实现每天能够处理数十亿事件和TB级数据,说明其具有可扩展性。在实际应用场景中,例如需要交互式聚合和快速探究大量数据、需要实时查询分析、具有大量数据等情况下,Druid都可以发挥出其高可用、高容错、高性能的优势。
总的来说,Druid是一个功能强大、性能优异且具有良好扩展性的分布式系统,适用于处理大规模数据并支持实时查询和分析。
如果想了解Druid数据库连接池在Java中最基本的使用,可以看我之前的文章:
Alibaba Druid数据库连接池直接起飞
其他文档的链接地址:
- GitHub地址: https://github.com/alibaba/druid
- 官方文档: https://github.com/alibaba/druid/wiki/Druid连接池介绍
- Starter文档: https://github.com/alibaba/druid/tree/master/druid-spring-boot-starter
2、Druid数据库连接池的基本参数
| 参数名称 | 默认值 | 说明 |
|---|---|---|
| driver-class-name | null | 数据库连接驱动 |
| username | null | 数据库连接用户名 |
| password | null | 数据库连接密码 |
| url | null | 数据库连接的URL |
| initial-size | 0 | 初始化时建立连接的个数 |
| max-active | 8 | 最大连接池数量 |
| min-idle | 0 | 最小连接池数量 |
| max-wait | -1 | 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。 |
| use-global-data-source-stat | true | 是否开启SQL统计 |
| validation-query | null | 用来检测连接是否有效的sql,要求是一个查询语句,常用SELECT 1 FROM DUAL |
| validation-query-timeout | -1 | 检测连接是否有效的超时时间,单位是秒 |
| login-timeout | null | Druid Monitor登录超时时间 |
| transaction-query-timeout | null | 事务查询超时时间 |
| query-timeout | null | 查询超时时间 |
| test-while-idle | true | 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。 |
| time-between-eviction-runs-millis | 60s | 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 |
| min-evictable-idle-time-millis | 30分钟 | 配置一个连接在池中最小生存的时间,单位是毫秒 |
| max-evictable-idle-time-millis | 7小时 | 配置连接池中连接,在时间段内一直空闲,被逐出连接池的时间,单位毫秒。 |
| default-read-only | null | 设置连接为只读状态 |
| default-transaction-isolation | null | 事务的隔离级别 |
以上标红的属性都是常用的属性,Druid连接池的参数有很多,在后面的配置中可以自行配置
3、实践
项目环境:
- IDEA 2023
- SpringBoot
- Mybatis-plus
- lombok
- Druid-starter
- MySQL 8.0
3.1、导入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.3.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.20</version>
</dependency>
3.2、yaml文件
server:
port: 8888
spring:
data:
redis:
host: localhost
port: 6379
main:
lazy-initialization: true
banner-mode: off
datasource:
druid:
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: 123456
url: jdbc:mysql://localhost:3306/taobao?serverTimezone=Asia/Shanghai
initial-size: 1 # 初始化时建立连接的个数
max-active: 1 # 最大连接池数量
min-idle: 1 # 最小连接池数量
max-wait: 6000 # 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。
# pool-prepared-statements: false # 是否缓存preparedStatement, MySQL建议关闭
use-global-data-source-stat: true # 开启SQL统计
validation-query: SELECT 1 FROM DUAL #用来检测连接是否有效的sql,要求是一个查询语句,常用SELECT 1 FROM DUAL
validation-query-timeout: 3000 # 检测连接是否有效的超时时间,单位是秒
login-timeout: 3000 # 登录超时时间
transaction-query-timeout: 3000 # 事务查询超时时间
query-timeout: 3000 # 查询超时时间
# test-on-borrow: false # 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。
# test-on-return: false # 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能
test-while-idle: true # 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。
# time-between-eviction-runs-millis: 30000 # 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
# min-evictable-idle-time-millis: 300000 #配置一个连接在池中最小生存的时间,单位是毫秒
# max-evictable-idle-time-millis: 600000 #配置连接池中连接,在时间段内一直空闲,被逐出连接池的时间,单位毫秒。
default-read-only: false # 是否只读
default-transaction-isolation: 4 #事务的隔离级别
web-stat-filter: # 开启Druid过滤器
enabled: true # 开启StatFilter
url-pattern: /*
exclusions: "*.jpg,*.png,*.jpeg"
profile-enable: true # 是否监控单个URL调用的SQL列表
stat-view-servlet: # 开启Druid Servlet拦截
enabled: true # 是否启用StatViewServlet
url-pattern: /druid/* #监控页面拦截url
reset-enable: true #是否启用重置功能
login-password: druid
login-username: druid
aop-patterns:
- /database/list
filter: # 进行慢SQL展示
stat:
enabled: true
slow-sql-millis: 500
log-slow-sql: true # 以日志的形式输入SQL
merge-sql: true # 是否合并SQL
db-type: mysql
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
banner: false
mapper-locations: classpath:/mapper/*.xml
3.3、运行
项目启动后, 我们可以直接访问http://localhost:项目端口/druid/login.html就可以进行Druid Monitor.
这些页面都是Druid已经写好了的,就在我们引入的Jar包或者依赖里头:
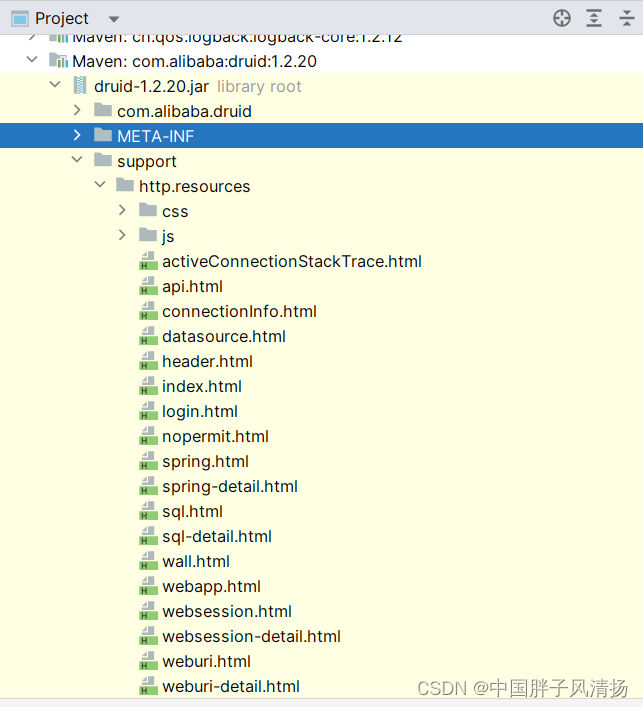
3.3.1、登录页面
我们可以在登录页面输入我们设置好的login-username用户名和login-password密码进行登录.
3.3.2 、首页
我们可以在首页看到一些列运行的环境.
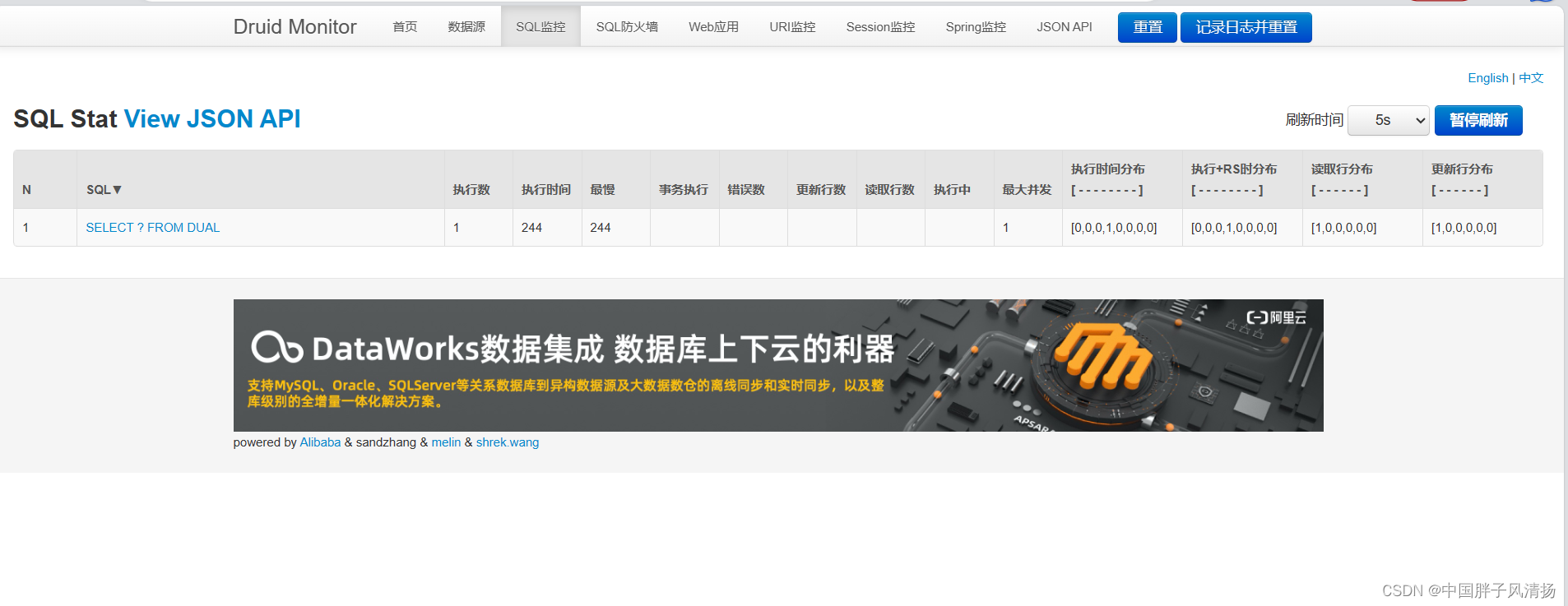
3.3.3 、SQL监控
因为我们配置了测试连接, 所以在项目启动后会进行一次连接测试, 连接测试的SQL就是validation-query参数所配置的SQL.
从图中也可以看出进行了连接测试
3.4 、编写controller进行测试
本项目使用了Mybatis-plus作为ORM框架, 具体的DAO层就是那么一套逻辑, 所以省略, 只显示controller接口层.
@RestController
@RequestMapping(value = "/database")
public class ProductController {
@Resource
private ProductMapper productMapper;
@GetMapping(value = "/list")
public List<Product> productList(){
return productMapper.selectPage(new Page<>(1, 10), null).getRecords();
}
}
我们可以很清楚的看到SQL的执行被监听到了.
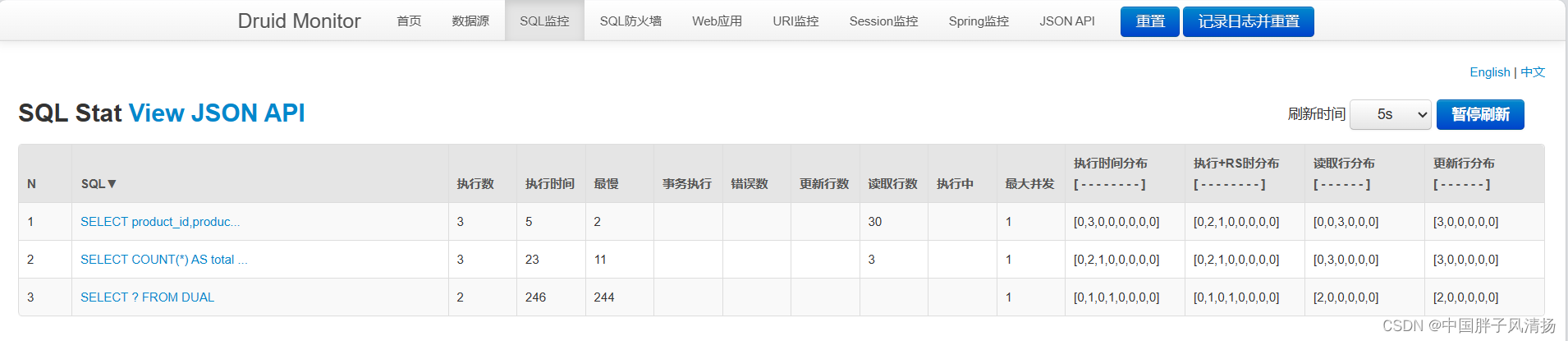
因为我执行了分页的操作, Mybatis-plus的底层是执行了统计数量和进行分页的两条SQL, 都被监听到了.
3.5 、其他参数
当我们能够进入到Druid Monitor后, 可以进入数据源页面.
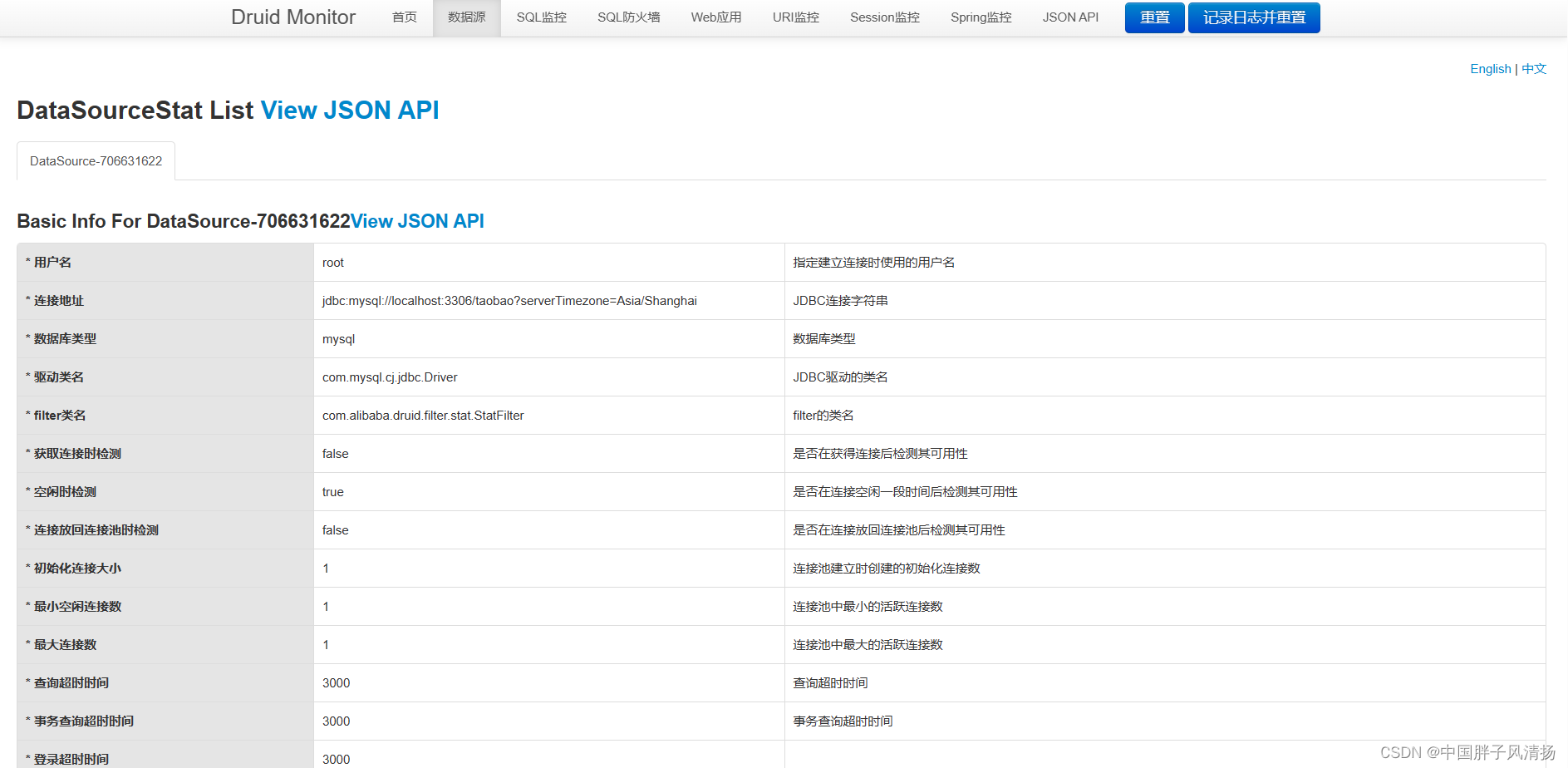
表格最左侧的参数就是Druid可以配置的参数, 我这里使用的是中文进行展示, 伙伴们可以切换成英文进行展示.