文章目录
- (136)生产环境多队列创建&好处
- (137)容量调度器多队列提交案例
- 如何创建多个队列
- 如何向指定队列提交任务
- (138)容量调度器任务优先级
- (139)公平调度器案例
- 参考文献
(136)生产环境多队列创建&好处
生产环境下怎么创建队列?
- 调度器默认只会开一个default队列,这个肯定是不满足生产要求的;
- 可以按照框架来划分队列。比如说hive/spark/flink的任务分别放在不同的队列里,不过这么做的效率不高,企业用的不是很多。
- 按照业务模块来划分队列。比如说登录注册的业务,单独一个队列,购物车单独一个队列,下单功能单独一个队列,等等;
创建多队列的好处?
- 担心单一程序耗尽集群所有资源;
- 实现任务的降级使用。特殊时期可以保证重要的队列资源更充足。比如说双十一的时候,就给下单的那个队列,多补充资源。
降级怎么理解呢,就是队列之间区分优先级,资源的分配是按照队列所属的业务的优先级来进行的。
(137)容量调度器多队列提交案例
仅做了解。
需求1:default队列占总内存的40%,最大资源容量占总资源60%,hive队列占总内存的60%,最大资源容量占总资源80%。
需求2:配置队列优先级。
如何创建多个队列
接下来就需要在capacity-scheduler.xml中配置容量调度器的各项参数。直接抄教程的示例了:
<!-- 指定多队列,增加hive队列 -->
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,hive</value>
<description>
The queues at the this level (root is the root queue).
</description>
</property>
<!-- 降低default队列资源额定容量为40%,默认100% -->
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>40</value>
</property>
<!-- 降低default队列资源最大容量为60%,默认100% -->
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>60</value>
</property>
(2)为新加队列添加必要属性:
<!-- 指定hive队列的资源额定容量 -->
<property>
<name>yarn.scheduler.capacity.root.hive.capacity</name>
<value>60</value>
</property>
<!-- 用户最多可以使用队列多少资源,1表示 -->
<property>
<name>yarn.scheduler.capacity.root.hive.user-limit-factor</name>
<value>1</value>
</property>
<!-- 指定hive队列的资源最大容量 -->
<property>
<name>yarn.scheduler.capacity.root.hive.maximum-capacity</name>
<value>80</value>
</property>
<!-- 启动hive队列 -->
<property>
<name>yarn.scheduler.capacity.root.hive.state</name>
<value>RUNNING</value>
</property>
<!-- 哪些用户有权向队列提交作业 -->
<property>
<name>yarn.scheduler.capacity.root.hive.acl_submit_applications</name>
<value>*</value>
</property>
<!-- 哪些用户有权操作队列,管理员权限(查看/杀死) -->
<property>
<name>yarn.scheduler.capacity.root.hive.acl_administer_queue</name>
<value>*</value>
</property>
<!-- 哪些用户有权配置提交任务优先级 -->
<property>
<name>yarn.scheduler.capacity.root.hive.acl_application_max_priority</name>
<value>*</value>
</property>
<!-- 任务的超时时间设置:yarn application -appId appId -updateLifetime Timeout
参考资料:https://blog.cloudera.com/enforcing-application-lifetime-slas-yarn/ -->
<!-- 如果application指定了超时时间,则提交到该队列的application能够指定的最大超时时间不能超过该值。
-->
<property>
<name>yarn.scheduler.capacity.root.hive.maximum-application-lifetime</name>
<value>-1</value>
</property>
<!-- 如果application没指定超时时间,则用default-application-lifetime作为默认值 -->
<property>
<name>yarn.scheduler.capacity.root.hive.default-application-lifetime</name>
<value>-1</value>
</property>
如果任务超过了设定的超时时间,那么到时候就会被直接杀死,-1表示不设置。
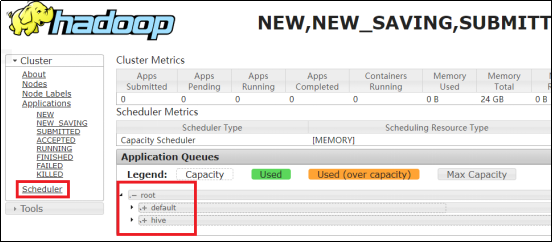
参数设置完成后,重启yarn,或者是执行yarn rmadmin -refreshQueues刷新队列配置。就可以看到两条队列了。
如何向指定队列提交任务
那如何向指定队列提交任务呢?
以向hive队列提交任务为例,就是执行
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount -D mapreduce.job.queuename=hive /input /output
就是加入了-D参数,指定了队列名。
如果不指定队列名的话,默认是都提交到default队列。
除了上述方式之外,也可以在jar包代码里写死要提交的队列名,如:
public class WcDrvier {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
conf.set("mapreduce.job.queuename","hive");
//1. 获取一个Job实例
Job job = Job.getInstance(conf);
。。。 。。。
//6. 提交Job
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
这样,这个任务在提交的时候,就会直接提交到hive队列。
(138)容量调度器任务优先级
资源紧张的时候,高优先级的任务将先获取到资源。
默认情况下,Yarn将所有任务的优先级限制为0,如果想使用任务的优先级功能,则需要做一些设置。
首先修改yarn-site.xml文件,增加以下参数:
<property>
<name>yarn.cluster.max-application-priority</name>
<value>5</value>
</property>
分发配置,并重启Yarn:
[atguigu@hadoop102 hadoop]$ xsync yarn-site.xml
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/stop-yarn.sh
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
然后通过连续提交下面任务,来模拟资源紧张的环境:
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi 5 2000000
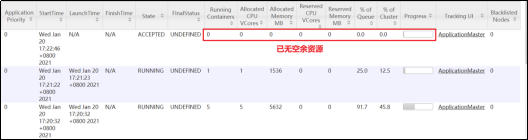
再次提交高优先级任务:
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi -D mapreduce.job.priority=5 5 2000000
通过-D设置了新提交的任务优先级是5,高于当前在运行的所有任务,这个任务马上就获取到了资源:

上面的例子是在任务提交时设置任务的优先级,也可以通过以下命令修改正在执行的任务的优先级:
yarn application -appID <ApplicationID> -updatePriority 优先级
(139)公平调度器案例
公平调度器,中大型公司主要使用的。
需求:在默认的default队列基础之上,再创建两个队列,分别是test和atguigu(以用户所属组命名)。期望实现下面效果:
- 提交任务时若指定队列,则提交至指定队列运行;
- 提交任务时未指定队列,test用户提交的任务到test队列运行,atguigu用户提交的任务到atguigu队列运行
公平调度器的配置涉及到两个文件,一个是yarn-site.xml,另一个是公平调度器队列分配文件fair-scheduler.xml(文件名可自定义)。
(1)配置文件参考资料:
https://hadoop.apache.org/docs/r3.1.3/hadoop-yarn/hadoop-yarn-site/FairScheduler.html
(2)任务队列放置规则参考资料:
https://blog.cloudera.com/untangling-apache-hadoop-yarn-part-4-fair-scheduler-queue-basics/
修改yarn-site.xml文件,如下:
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
<description>配置使用公平调度器</description>
</property>
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop/fair-scheduler.xml</value>
<description>指明公平调度器队列分配配置文件</description>
</property>
<property>
<name>yarn.scheduler.fair.preemption</name>
<value>false</value>
<description>禁止队列间资源抢占</description>
</property>
"禁止队列间资源抢占"这个功能就是之前提到过的,不同队列间的资源借调,这里是直接关掉了。
创建并配置fair-scheduler.xml:
<?xml version="1.0"?>
<allocations>
<!-- 单个队列中Application Master占用整个队列资源的最大比例,取值0-1 ,企业一般配置0.1 ,-->
<queueMaxAMShareDefault>0.5</queueMaxAMShareDefault>
<!-- 单个队列最大资源的默认值 test atguigu default -->
<queueMaxResourcesDefault>4096mb,4vcores</queueMaxResourcesDefault>
<!-- 增加一个队列test -->
<queue name="test">
<!-- 队列最小资源 -->
<minResources>2048mb,2vcores</minResources>
<!-- 队列最大资源 -->
<maxResources>4096mb,4vcores</maxResources>
<!-- 队列中最多同时运行的应用数,默认50,根据线程数配置 -->
<maxRunningApps>4</maxRunningApps>
<!-- 队列中Application Master占用资源的最大比例 -->
<maxAMShare>0.5</maxAMShare>
<!-- 该队列资源权重,默认值为1.0 -->
<weight>1.0</weight>
<!-- 队列内部的资源分配策略 -->
<schedulingPolicy>fair</schedulingPolicy>
</queue>
<!-- 增加一个队列atguigu -->
<queue name="atguigu" type="parent">
<!-- 队列最小资源 -->
<minResources>2048mb,2vcores</minResources>
<!-- 队列最大资源 -->
<maxResources>4096mb,4vcores</maxResources>
<!-- 队列中最多同时运行的应用数,默认50,根据线程数配置 -->
<maxRunningApps>4</maxRunningApps>
<!-- 队列中Application Master占用资源的最大比例 -->
<maxAMShare>0.5</maxAMShare>
<!-- 该队列资源权重,默认值为1.0 -->
<weight>1.0</weight>
<!-- 队列内部的资源分配策略 -->
<schedulingPolicy>fair</schedulingPolicy>
</queue>
<!-- 任务队列分配策略,可配置多层规则,从第一个规则开始匹配,直到匹配成功 -->
<queuePlacementPolicy>
<!-- 提交任务时指定队列,如未指定提交队列,则继续匹配下一个规则; false表示:如果指定队列不存在,不允许自动创建-->
<rule name="specified" create="false"/>
<!-- 提交到root.group.username队列,若root.group不存在,不允许自动创建;若root.group.user不存在,允许自动创建 -->
<rule name="nestedUserQueue" create="true">
<rule name="primaryGroup" create="false"/>
</rule>
<!-- 最后一个规则必须为reject或者default。Reject表示拒绝创建提交失败,default表示把任务提交到default队列 -->
<rule name="reject" />
</queuePlacementPolicy>
</allocations>
接着分发配置并重启yarn:
[atguigu@hadoop102 hadoop]$ xsync yarn-site.xml
[atguigu@hadoop102 hadoop]$ xsync fair-scheduler.xml
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/stop-yarn.sh
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
接下来可以测试提交任务,就不介绍了。
参考文献
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】