目录
线性表的定义及其基本操作(顺序表插入、删除、查找、修改)
四、线性表的链接存储结构
1. 单链表
2. 循环链表
3. 双向链表
a. 双向链表节点结构
b. 创建一个新的节点
c. 在链表末尾插入节点
d. 在指定位置插入节点
e. 删除指定位置的节点
f. 遍历并打印链表
g. 主函数
h. 代码整合
五、复杂性分析
1. 空间效率比较
2. 时间效率比较
线性表的定义及其基本操作(顺序表插入、删除、查找、修改)
一个线性表是由零个或多个具有相同类型的结点组成的有序集合。
按照线性表结点间的逻辑顺序依次将它们存储于一组地址连续的存储单元中的存储方式被称为线性表的顺序存储方式。按顺序存储方式存储的线性表具有顺序存储结构,一般称之为顺序表。换言之,在程序中采用定长的一维数组,按照顺序存储方式存储的线性表,被称为顺序表。

【数据结构】线性表(一)线性表的定义及其基本操作(顺序表插入、删除、查找、修改)-CSDN博客![]() https://blog.csdn.net/m0_63834988/article/details/132089038?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_63834988/article/details/132089038?spm=1001.2014.3001.5501
四、线性表的链接存储结构
1. 单链表
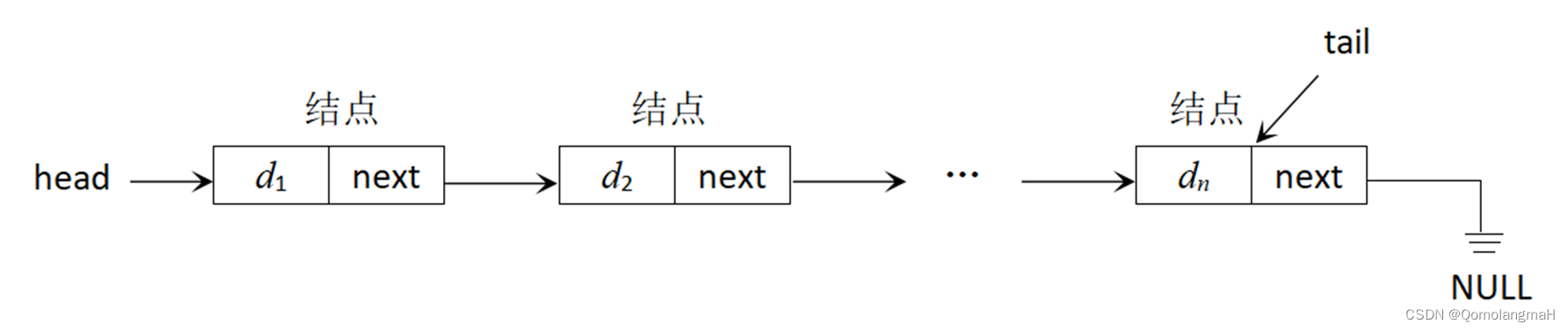
顺序表的优点是存取速度快。但是,无论是插入一个结点,还是删除一个结点,都需要调整一批结点的地址。要克服该缺点,就必须给出一种不同于顺序存储的存储方式。用链接存储方式存储的线性表被称为链表,可以克服上述缺点。
链表中的结点用存储单元(若干个连续字节)来存放,存储单元之间既可以是(存储空间上)连续的,也可以是不连续的,甚至可以零散地分布在存储空间中的任何位置。换言之,链表中结点的逻辑次序和物理次序之间并无必然联系。最重要的是,链表可以在不移动结点位置的前提下根据需要随时添加删除结点,动态调整。
【数据结构】线性表(二)单链表及其基本操作(创建、插入、删除、修改、遍历打印)-CSDN博客![]() https://blog.csdn.net/m0_63834988/article/details/133914875?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_63834988/article/details/133914875?spm=1001.2014.3001.5501
2. 循环链表
从单链表的一个结点出发,只能访问到链接在它后面的结点,而无法访问位于它前面的结点,这对一些实际应用很不方便。解决的办法是把链接结构“循环化”,即把表尾结点的next域存放指向哨位结点的指针,而不是存放空指针NULL,这样的单链表被称为循环链表。循环链表使用户可以从链表的任何位置开始,访问链表中的任意结点。

【数据结构】线性表(三)循环链表的各种操作(创建、插入、查找、删除、修改、遍历打印、释放内存空间)-CSDN博客![]() https://blog.csdn.net/m0_63834988/article/details/133914085?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_63834988/article/details/133914085?spm=1001.2014.3001.5501
3. 双向链表
在循环链表中,从一个结点出发,必须遍历整个链表,方可找到其前驱结点,时间复杂度为O(n) . 双向链表将很好地解决该问题。所谓双向链表,系指链表中任一结点P都是由data域、左指针域left(pre)和右指针域right(next)构成的,左指针域和右指针域分别存放P的左右两边相邻结点的地址信息。

双向链表的优点是可以在常量时间内删除或插入一个节点,因为只需要修改节点的前后指针,而不需要像单向链表那样遍历到指定位置。而在单向链表中,删除或插入一个节点需要先找到前一个节点,然后修改指针。然而,双向链表相对于单向链表需要更多的内存空间来存储额外的指针。另外,由于多了一个指针,插入和删除节点时需要更多的操作。
a. 双向链表节点结构
typedef struct Node {
int data;
struct Node* prev;
struct Node* next;
} Node; 包含一个整数data以及两个指针prev和next,分别指向前一个节点和后一个节点。
b. 创建一个新的节点
Node* createNode(int data) {
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->data = data;
newNode->prev = NULL;
newNode->next = NULL;
return newNode;
} 创建一个新的节点,它接受一个整数作为参数,并分配内存来存储节点。然后,节点的data被设置为传入的整数,prev和next指针被初始化为NULL,最后返回新创建的节点指针。
c. 在链表末尾插入节点
void append(Node** head, int data) {
Node* newNode = createNode(data);
if (*head == NULL) {
*head = newNode;
} else {
Node* current = *head;
while (current->next != NULL) {
current = current->next;
}
current->next = newNode;
newNode->prev = current;
}
}- 创建一个新的节点,并将传入的整数作为节点的数据。
- 检查链表是否为空
- 如果为空,将链表头指针指向新节点;
- 否则,遍历链表找到最后一个节点,将最后一个节点的
next指针指向新节点,新节点的prev指针指向最后一个节点。
d. 在指定位置插入节点
void insert(Node** head, int data, int position) {
Node* newNode = createNode(data);
if (position == 0) {
newNode->next = *head;
if (*head != NULL) {
(*head)->prev = newNode;
}
*head = newNode;
} else {
Node* current = *head;
int i;
for (i = 0; i < position - 1 && current != NULL; i++) {
current = current->next;
}
if (current == NULL) {
printf("Invalid position\n");
return;
}
newNode->next = current->next;
newNode->prev = current;
if (current->next != NULL) {
current->next->prev = newNode;
}
current->next = newNode;
}
}- 创建一个新的节点,并将传入的整数作为节点的数据。
- 如果插入位置为0,表示在链表头插入新节点
- 将新节点的
next指针指向链表的头节点 - 如果链表不为空,将链表的头节点的
prev指针指向新节点,最后将链表的头指针指向新节点。
- 将新节点的
- 如果插入位置不为0
- 首先遍历链表找到插入位置的前一个节点
- 如果找到了位置或者遍历到链表末尾都没有找到指定位置,则输出"Invalid position"并返回。
- 否则,将新节点的
next指针指向当前节点的next指针所指向的节点,新节点的prev指针指向当前节点 - 如果当前节点的
next指针不为空,将当前节点的next指针所指向的节点的prev指针指向新节点,最后将当前节点的next指针指向新节点。
e. 删除指定位置的节点
void delete(Node** head, int position) {
if (*head == NULL) {
printf("List is empty\n");
return;
}
Node* temp = *head;
if (position == 0) {
*head = (*head)->next;
if (*head != NULL) {
(*head)->prev = NULL;
}
free(temp);
} else {
int i;
for (i = 0; i < position && temp != NULL; i++) {
temp = temp->next;
}
if (temp == NULL) {
printf("Invalid position\n");
return;
}
temp->prev->next = temp->next;
if (temp->next != NULL) {
temp->next->prev = temp->prev;
}
free(temp);
}
}- 如果链表为空,输出"List is empty"并返回。
- 如果要删除的节点是链表的头节点
- 将链表的头指针指向头节点的下一个节点,如果链表不为空,将新的头节点的
prev指针指向NULL,然后释放被删除的节点的内存。
- 将链表的头指针指向头节点的下一个节点,如果链表不为空,将新的头节点的
- 如果要删除的节点不是头节点
- 首先遍历链表找到要删除的节点
- 如果找到了指定位置的节点或者遍历到链表末尾都没有找到,则输出"Invalid position"并返回。
- 否则,将要删除节点的前一个节点的
next指针指向要删除节点的下一个节点,如果要删除节点的下一个节点不为空,将要删除节点的下一个节点的prev指针指向要删除节点的前一个节点。 - 最后释放要删除节点的内存。
f. 遍历并打印链表
void printList(Node* head) {
Node* current = head;
while (current != NULL) {
printf("%d ", current->data);
current = current->next;
}
printf("\n");
} 从链表的头节点开始,通过不断访问next指针,打印每个节点的数据,并移动到下一个节点,直到遍历完整个链表。
g. 主函数
int main() {
Node* head = NULL;
printList(head);
// 在链表末尾插入节点
append(&head, 1);
append(&head, 2);
append(&head, 3);
printList(head);
// 在指定位置插入节点
insert(&head, 4, 1);
printList(head);
// 删除指定位置的节点
delete(&head, 2);
printList(head);
return 0;
}
h. 代码整合
#include <stdio.h>
#include <stdlib.h>
// 双向链表节点结构
typedef struct Node {
int data;
struct Node* prev;
struct Node* next;
} Node;
// 创建一个新的节点
Node* createNode(int data) {
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->data = data;
newNode->prev = NULL;
newNode->next = NULL;
return newNode;
}
// 在链表末尾插入节点
void append(Node** head, int data) {
Node* newNode = createNode(data);
if (*head == NULL) {
*head = newNode;
} else {
Node* current = *head;
while (current->next != NULL) {
current = current->next;
}
current->next = newNode;
newNode->prev = current;
}
}
// 在指定位置插入节点
void insert(Node** head, int data, int position) {
Node* newNode = createNode(data);
if (position == 0) {
newNode->next = *head;
if (*head != NULL) {
(*head)->prev = newNode;
}
*head = newNode;
} else {
Node* current = *head;
int i;
for (i = 0; i < position - 1 && current != NULL; i++) {
current = current->next;
}
if (current == NULL) {
printf("Invalid position\n");
return;
}
newNode->next = current->next;
newNode->prev = current;
if (current->next != NULL) {
current->next->prev = newNode;
}
current->next = newNode;
}
}
// 删除指定位置的节点
void delete(Node** head, int position) {
if (*head == NULL) {
printf("List is empty\n");
return;
}
Node* temp = *head;
if (position == 0) {
*head = (*head)->next;
if (*head != NULL) {
(*head)->prev = NULL;
}
free(temp);
} else {
int i;
for (i = 0; i < position && temp != NULL; i++) {
temp = temp->next;
}
if (temp == NULL) {
printf("Invalid position\n");
return;
}
temp->prev->next = temp->next;
if (temp->next != NULL) {
temp->next->prev = temp->prev;
}
free(temp);
}
}
// 遍历并打印链表
void printList(Node* head) {
Node* current = head;
while (current != NULL) {
printf("%d ", current->data);
current = current->next;
}
printf("\n");
}
// 主函数
int main() {
Node* head = NULL;
printList(head);
// 在链表末尾插入节点
append(&head, 1);
append(&head, 2);
append(&head, 3);
printList(head);
// 在指定位置插入节点
insert(&head, 4, 1);
printList(head);
// 删除指定位置的节点
delete(&head, 2);
printList(head);
return 0;
}五、复杂性分析
到目前为止,本系列已详细介绍了线性表的两种存储方式——顺序存储和链接存储,下面从空间和时间复杂性两方面对二者进行比较分析。
1. 空间效率比较
顺序表所占用的空间来自于申请的数组空间,数组大小是事先确定的,很明显当表中的元素较少时,顺序表中的很多空间处于闲置状态,造成了空间的浪费;
链表所占用的空间是根据需要动态申请的,不存在浪费空间的问题,但是链表需要在每个结点上附加一个指针域,从而增加一定的空间开销。
2. 时间效率比较
线性表的基本操作是存取、插入和删除。对于顺序表,随机存取是非常容易的,但是每插入或删除一个元素,都需要移动若干元素。
对于链表,无法实现随机存取,必须要从表头开始遍历链表,直到发现要存取的元素,但是链表的插入和删除操作却非常简便,只需要修改几个指针。
- 当经常需要对线性表进行插入、删除操作时,链表的时间效率较高;
- 双向链表在某些场景下更加灵活和高效,特别是需要频繁的插入和删除操作时。然而,在内存有限的情况下,单向链表可能更为合适。
- 当经常需要对线性表进行存取且存取操作比插入、删除操作更为频繁时,顺序表的时间效率较高

![[自定义 Vue 组件] 小尾巴 Logo 组件 TailLogo](https://img-blog.csdnimg.cn/img_convert/449bcb8a6767e86ca8c4a8352341f863.png)