一、介绍是Stable Diffusion(简称SD)
1.SD是什么
Stable diffusion是一个基于Latent Diffusion Models(潜在扩散模型,LDMs)的文图生成(text-to-image)模型。简单的来说SD是可以通过提示词生成图片的应用。目前已经发布了V4版本,可以更好的稳定扩散。 我们的目的就是能快速使用它,所以不去深究SD原理也是可以的。
2.SD能干什么
1)、刷视频可以刷到一些up、博主发的一些AI绘画的视频,就是基本的应用,通过大模型和描述词的结合生成漂亮的图片,不仅可以生成真实的图片还可以生成各种各样画风的人物和风景图。

2)、我们还可以用SD去训练制作一套属于我们自己的头像、壁纸,或者用SD去训练我们自己和家人的脸型,让图片上的我们身穿各种衣服处于各种场景。
3)、对于修复模糊照片和室内效果图等也有很大帮助
下面会具体说明。
二、本地部署SD
1.A卡和mac系统
A卡和mac系统目前来说还不能完全的匹配使用,需要自己不断测试,这个问题比较玄学,而且身边没有A卡和mac的计算机,所以我推荐两个大佬的解决办法。
针对mac系统:https://www.cnblogs.com/cheflone/p/17157938.html
针对AMD显卡:https://www.bilibili.com/video/BV1YV4y1o73q/?vd_source=80933838b024b85e550fb038b841810d
2.最低配置和推荐配置
最低配置要求
推荐配置
CPU: Intel Core i5以上
Intel Core i7以上
内存:8GB以上
内存:32GB或更高
显卡:显存至少6GB以上
显卡:显存12GB或更高
存储:至少50GB可用硬盘空间
存储:100G可用硬盘空间
操作系统:windows7以上
操作系统:windows10以上
以下是一些可用于优化stable diffusion性能的建议:
使用SSD存储:使用固态硬盘可以显著提高文件读取速度,从而加快stable diffusion的启动和加载时间。
关闭其他程序:确保在stable diffusion运行期间关闭其他运行的程序,从而释放系统资源并提高性能。
更新驱动程序:确保你的操作系统和显卡驱动程序是最新的,可以提供更好的性能和可靠性。
使用外部显卡:如果您的计算机配备了内置显卡,可以考虑添加外部显卡。外部显卡通常比内置显卡提供更好的性能。
结论:
要在stable diffusion上获得最佳性能,需要正确的硬件配置,可帮助用户提高性能和流畅度。
3.整合包一键部署,小白福音
本地部署不了,还要花费大量时间去测试,因为每个人的计算机环境不一样,同样的步我建议直接使用整合包,因为如果自己去部署的话百分十八十可能成功骤在别人电脑上就正常,自己电脑上就不正常了。整合包解决了这些问题,解压出来就可使用非常方便:
在这里推荐两个大佬的整合包:
秋叶整合包地址:https://pan.baidu.com/s/1_ibEk2OpKHxmEg4AnFOpSA 提取码:b145
星空整合包地址:
https://pan.baidu.com/s/1_FYbDpkX6Q6hDVHJpCMRxA?pwd=o852
这篇文章以秋叶的整合包为主:
下载秋叶整合包解压到存储空间大的盘符中
解压出来后先点击:启动器运行依赖。
点击安装
解压第二个sd-webui-aki-v4压缩包。打开文件,点击A启动器,等待安装完成进入界面。
点击一键启动,在这个界面稍等一会。

如果出现报错可在启动器“疑难解答”中扫描并修复
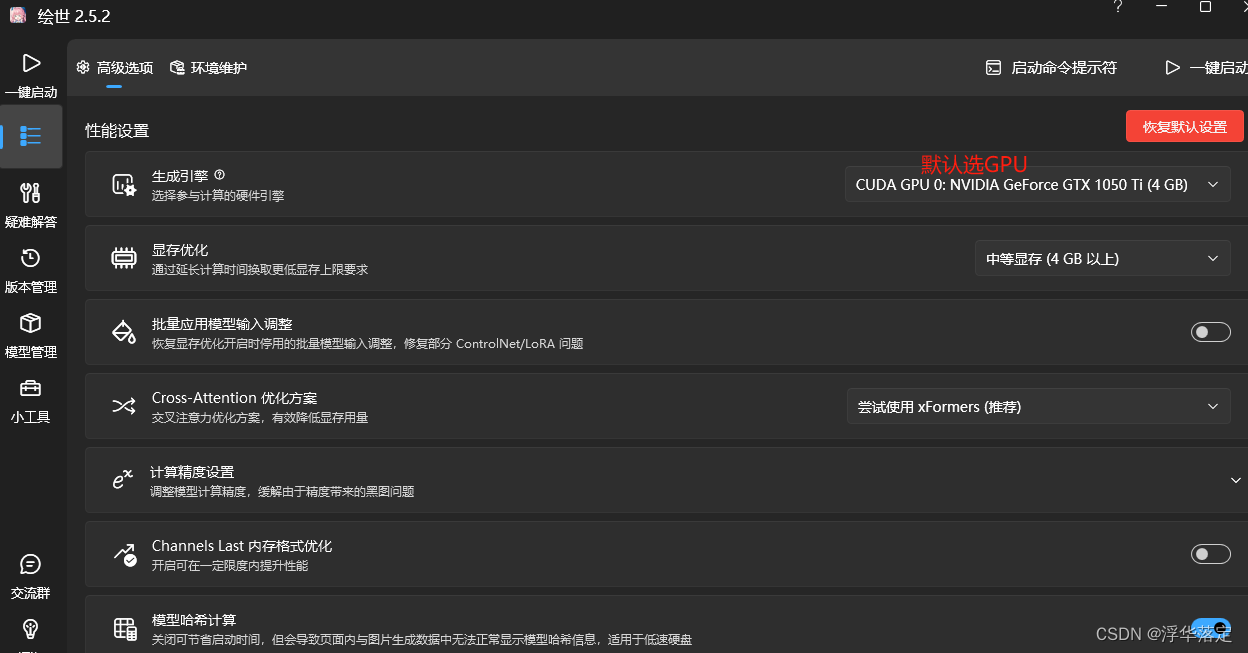
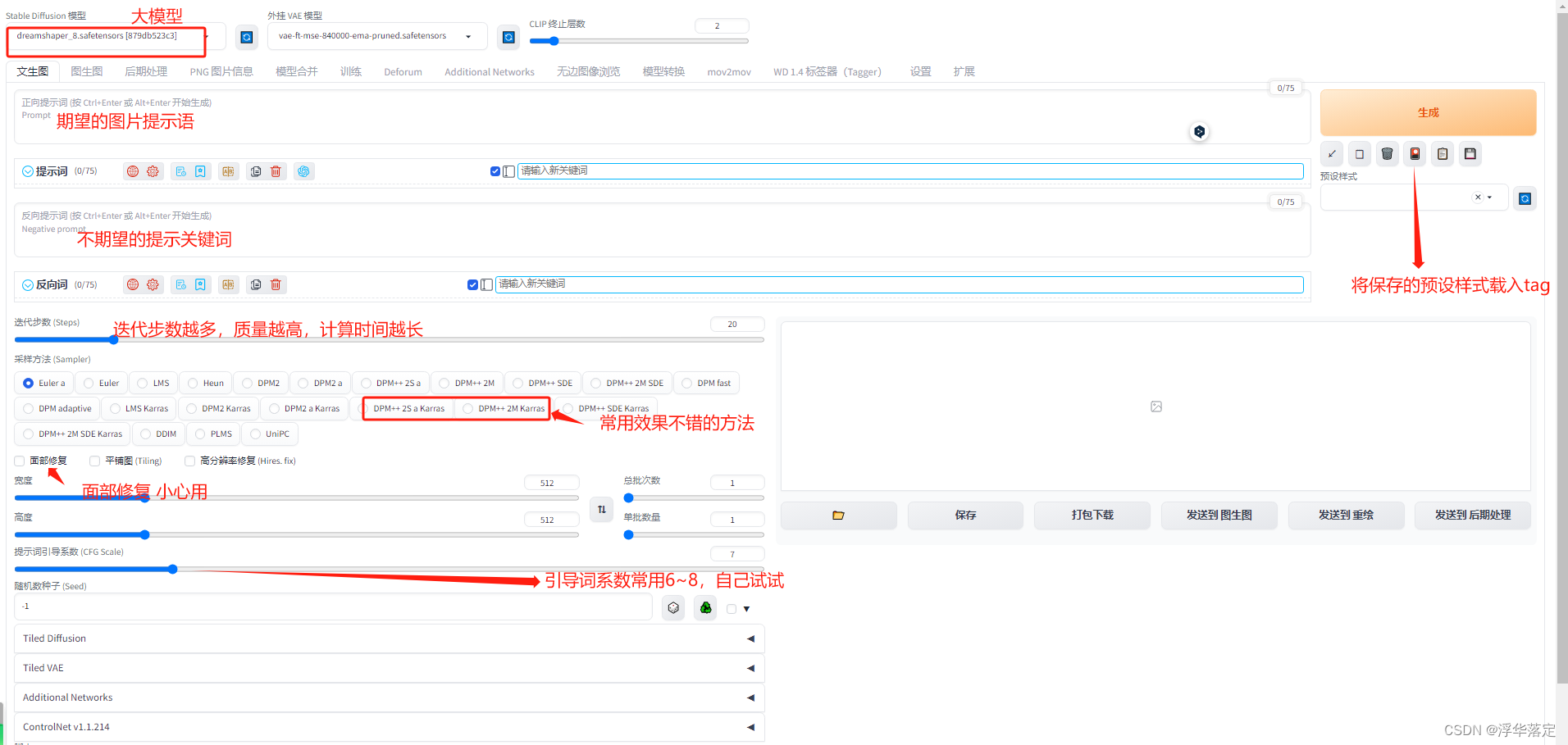
下面这个就是SD页面。看着功能很多实际上基础使用中,有很多用不上。一张图介绍主界面。
三.WebUI界面介绍(基本常用)和使用方法
1.文生图
1.绘画关键词
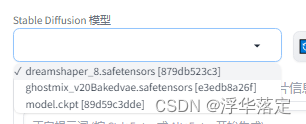
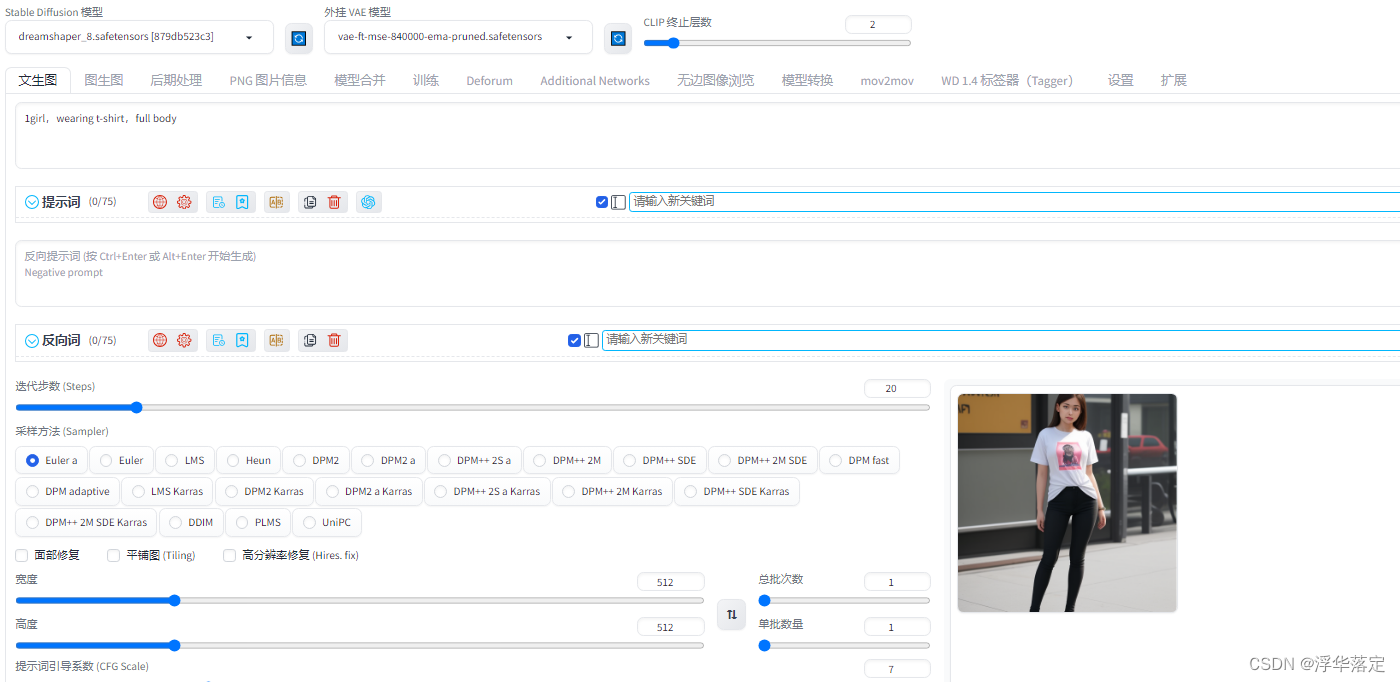
生成一张图片最重要的就是tag(关键词),tag越准确图片越接近自己想要的。怎么写关键词呢?单词、词组、短句子都可以。在这里说一下画之前先确定想要的画风,然后选择合适的模型,在这里我们使用真实画风举例。选择dreamshaper_8.safetensors大模型。
怎么下载模型会在后面详细说明
选择完模型之后输入关键词:如果我们想要一个穿着T恤的女孩可以写1girl,wearing t-shirt,full body,注意每个词组之间用逗号隔开,点击生成,你的第一张图就出来了!
这里反向关键词是一个比较通用的提供给大家使用(asian, nude, smiling, tattoos, windows, 2girl, (text:1.3), (words:1.4), writing, deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime, close up, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck)
再演示一个例子,以这个例子详细说明tag。
我们再写tag之前可以先想一下照片质量的词,比如:高质量,8k画质,大师杰作什么的,这样出来的图片质量越好。 (8k, uhd, dslr, high quality, cinematic lighting, bokeh), (dramatic, award winning photography, incredible masterpiece:1.3) (strong depth of field),这些是质量词,然后想一下想要什么人想穿什么衣服:穿着修身T恤的,28岁左右,叫凯瑟琳的女孩。所以我们写:(editorial photograph of Catherine as a 28 y.o. female diplomat), (wearing a t-shirt, sophisticated top, intimate, detailed:1.3)然后想要人在什么背景中房间中?大街上?什么天气?比如在老旧的书房中就写,(background inside dark, moody, private study, old furniture:1.3)最后加一个镜头语言强景深(strong depth of field)这样我们就可以要我们想要的图了。除此之外,我们还可以加一些首饰tag、人物姿势tag、物品颜色tag。
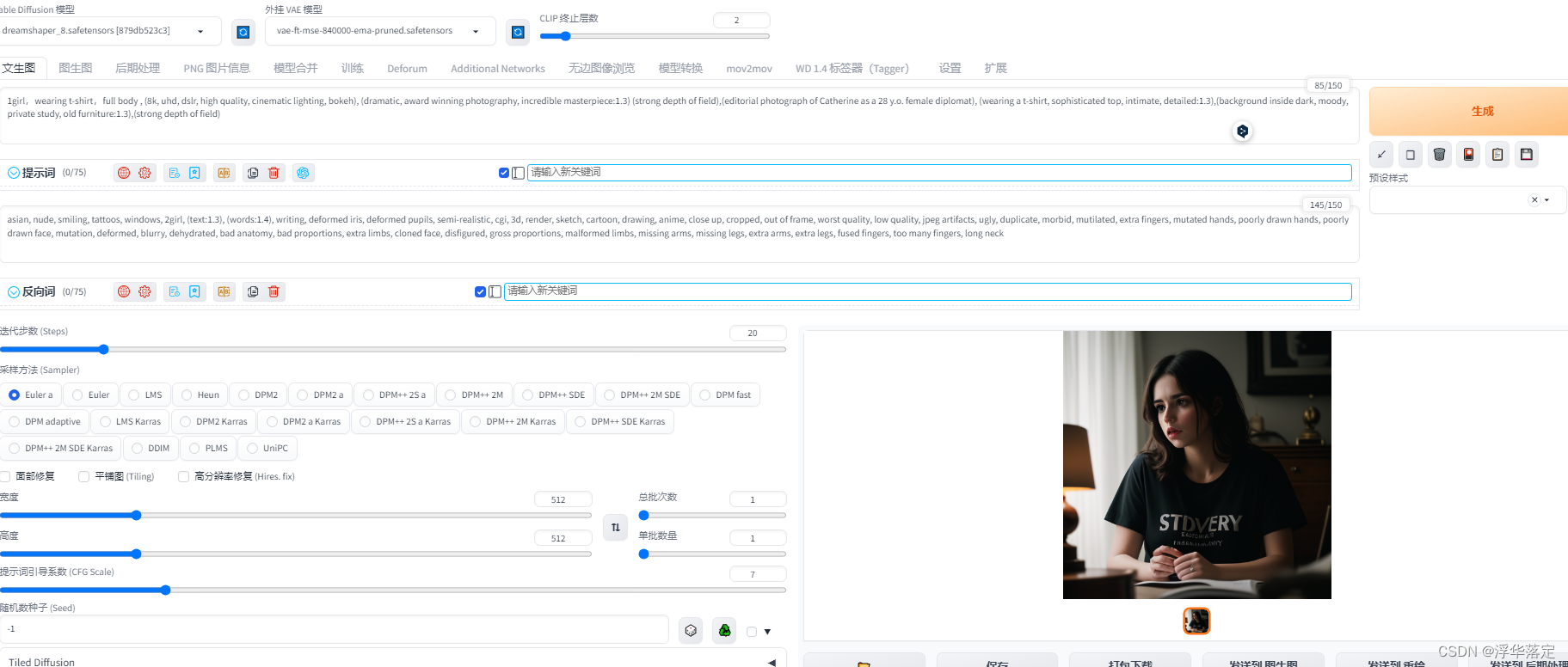
大家可以看到例子里有好多括号,这里讲一下括号的作用:提示词加括号代表权重,一个括号代表重要性增加1.1倍,两个括号,如:((XXX))代表1.1*1.1倍,如果想要固定值就在括号里改数字,例如(XXX XXX 1:3)代表1.3倍权重。画面中权重越高的就会很显眼。这些需要根据实际情况不断调试。减权重也可以就是用[ ]这个括号括起来。
反向关键词:当我们生成照片次数多了之后,渐渐的发现偶尔生成出来的照片多了几个手指,甚至会多了一只手,那怎么才能避免这些情况呢?
反向tag就是告诉SD,我不要那样的照片!
不想出现的东西,比如:多余的手,两个头,扭曲的脸等,可以照抄上面的。
总结一下我们写关键词的公式:
画质+主体+主体细节+人物服装+其他(背景、天气、构图等)
2.VAE
VAE简单的说就是一层滤镜,可以看到不同的VAE出来的效果有些不一样。

3.Lora的使用
点击这个图标,就会出来Lora的选择选项。
直接点击Lora就可以调用Lora
不同Lora可以控制不同的画面,比如可以控制脸型、服装、配饰等可以一起使用。我们可以调整不同的Lora权重生成我们独一无二的图片。Lora的下载安装在后文会说到。(如果想的话可以训练我们自己或者偶像的Lora控制出图的脸型,这样可以让自己穿不同的衣服在不同的环境中。)注意如果用的是动画风格的Lora,那就要选择动画风格的大模型,真实的大模型会出来奇奇怪怪的东西。
4.迭代步数
迭代步数与图片质量有很大关系,但是不代表迭代步数越高越好。太高了会导致过度计算出来的图片不伦不类,太低计算不足也会这样。
迭代步数一般在20-50之间
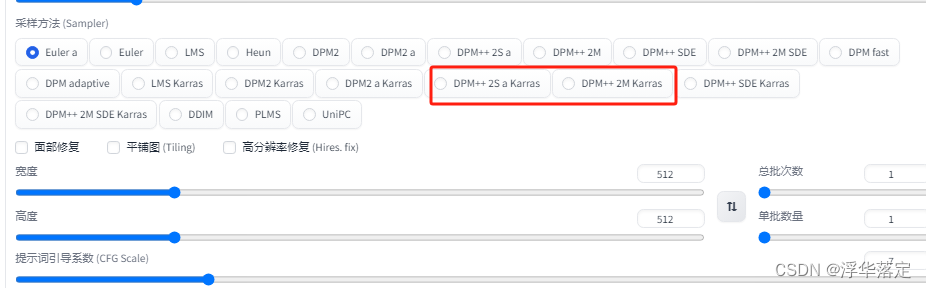
5.采样方法
不同的采样方法会出来不同效果的图,我推荐这三种采样方法,实际操作应用多,当让有时间的话也可以尝试一下其他的采样方法。
6.随机数种子
为什么有时候我们跟别人用的大模型、关键词、Lora还有其他参数都一样可偏偏生成出来的图就是不一样?
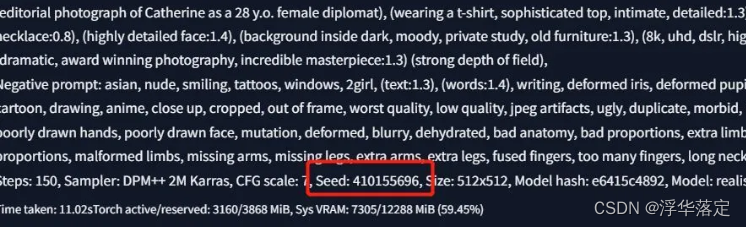
那是因为随机数种子(seed)的因素。Seed控制着图片形状,它会决定我们照片的基础轮廓,相当于决定了我们照片人物的外形轮廓,包括姿势和站位等当随机数为-1的时候,SD就会随机给你的照片生成一个种子,这个种子就理解成不一样的线稿就可以 怎么看自己照片用的seed值(随机教种子)是什么呢?在我们点击生成的照片下面,有一大串英文,里面的seed值就是我们当前生成照片的seed值。
只有当我们所有参数,包括随机数种子跟别人的照片都一样时,我们才能生成跟别人差不多一样的照片。
2.图生图
1.图生图
图生图功能顾名思义就是以已有的一张图生成另外一张图。这个对于出一批构图、形象或者画风相近的图很有帮助。
假如我们想要一张自己形象的动画风格的图片,我们就可以上传一张自己的照片,选择动画风格的大模型,输入tag:1men,the best quality, ultra-high definition, masterpieces, extreme detail, 8k,
这样就可以得到自己的动画、二次元形象了,再也不用花钱找别人设计了。
底下的参数需要看一下生成图片的分辨率还有重绘幅度,重绘幅度越低,成图和原图约不一样,重绘幅度为1时,就会跟原图一模一样。
一般在0.6-0.85区间内,大家可以根据需求多试试。
2涂鸦和涂鸦重绘
你可以在涂鸦功能里粗略的画几笔,SD会根据你画的计算生成一副精湛的图片。上传一张白色的图片当作画纸,用画笔随便画画,输入tag,就可以得到一幅画了。涂鸦重绘在原图基础上涂鸦,操作一样。
3.局部重绘
如果想让模特不动换一件衣服,那么可以采用局部重绘功能,上传一张图片。将衣服涂黑。

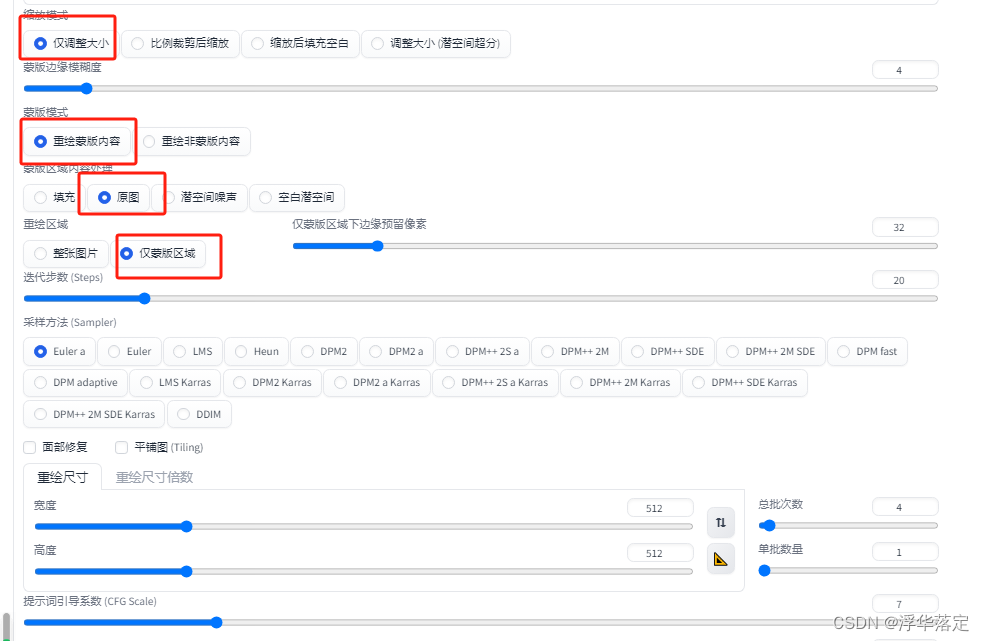
调整参数,将衣服相关的提示词删掉或者修改,生成图片,就可以出现不同的衣服。

同理如果想换脸就把脸部涂黑,就可以换脸。
4.重绘蒙版
如果有一件漂亮的衣服想让人穿上它,可以使用重绘蒙版。结合controlnet插件(后续会具体讲解controlnet插件)使用。
首先找一张模特图片用PS将衣服分离出来,用亮色做背景作为一号图片。再做一个1号图蒙版。
推荐一个小网站,图片素材资源不错
https://huaban.com/pins/5764547782
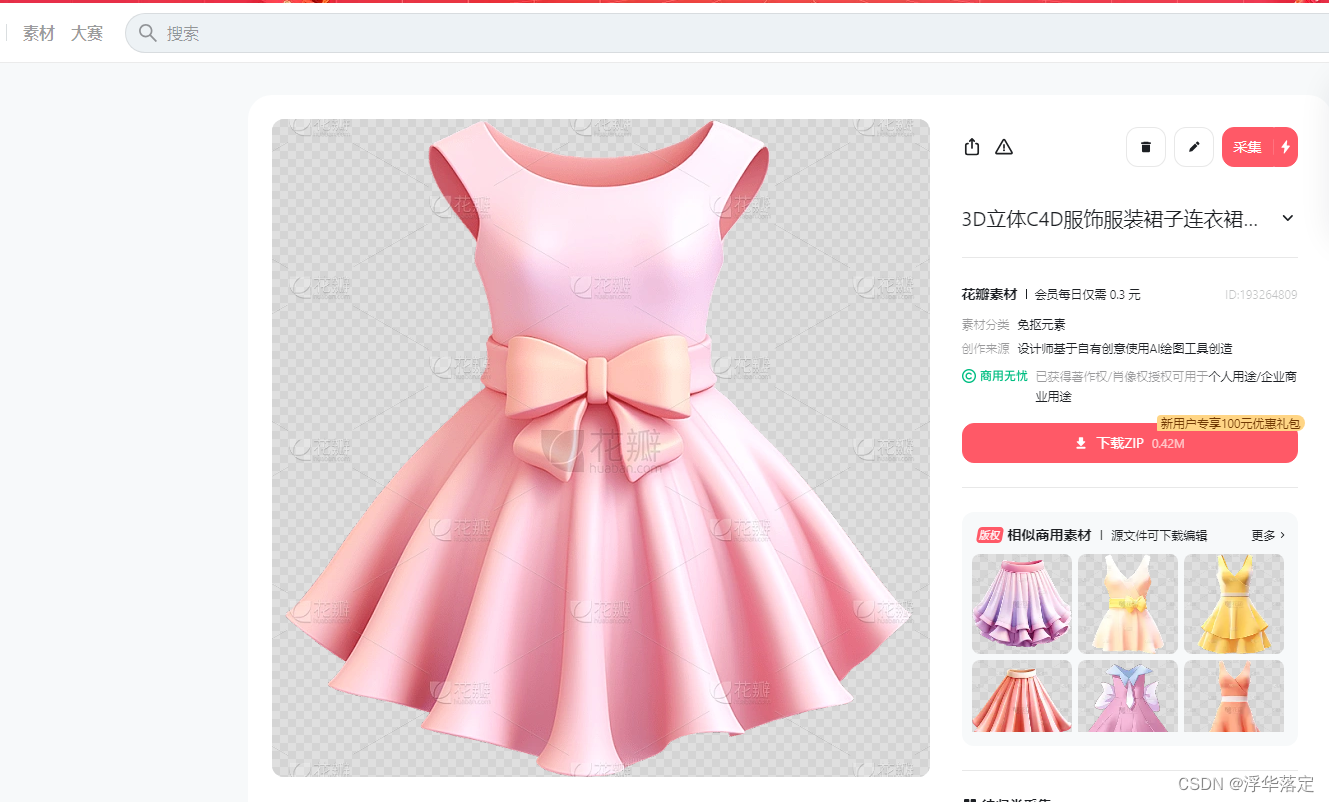


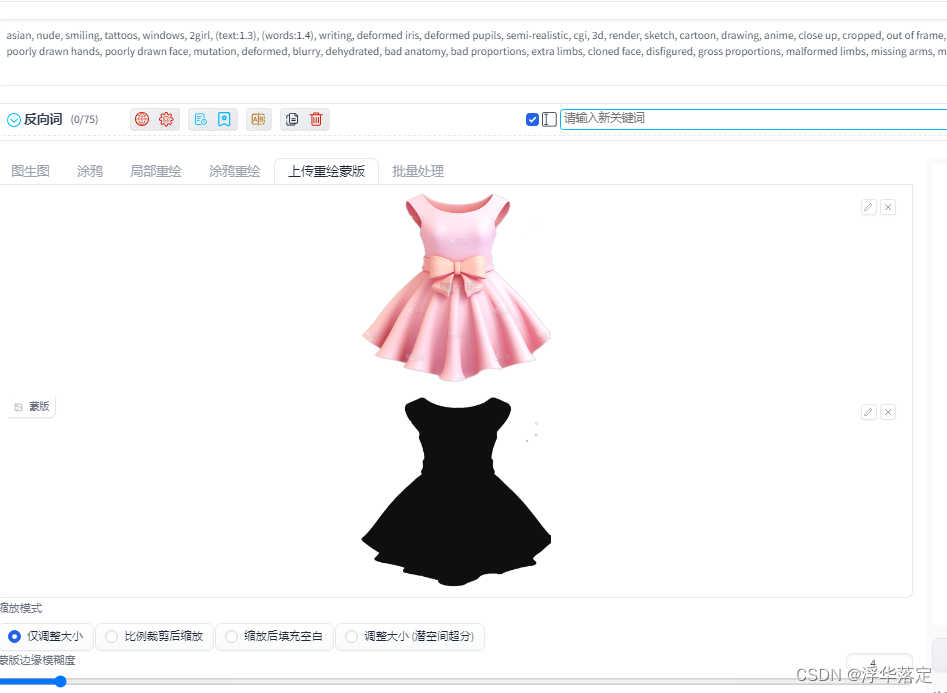
之后来到sd中图生图——局部重绘(上传蒙版)将一号图和蒙版放上去,调整参数,
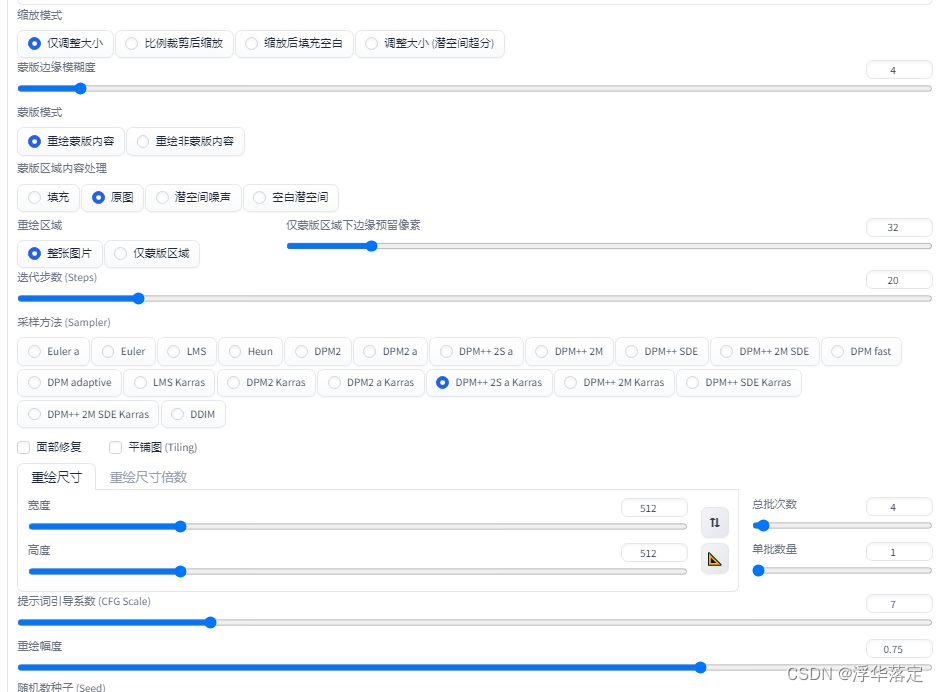
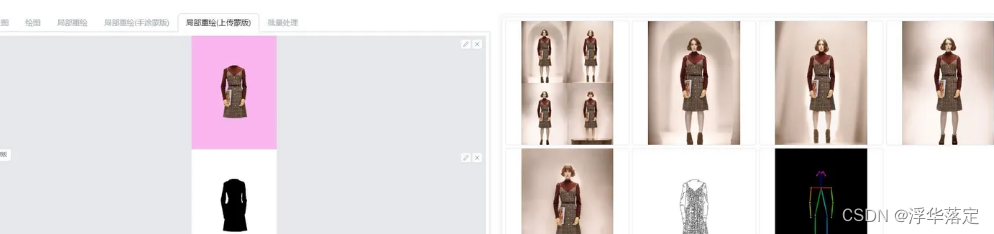
在ControlNet中一号图放0中,调整预处理器选择canny和模型选择canny(上面有链接,要提前下载安装好)。来到3D Openpose,调整角度、骨骼姿势,生成骨骼图片。
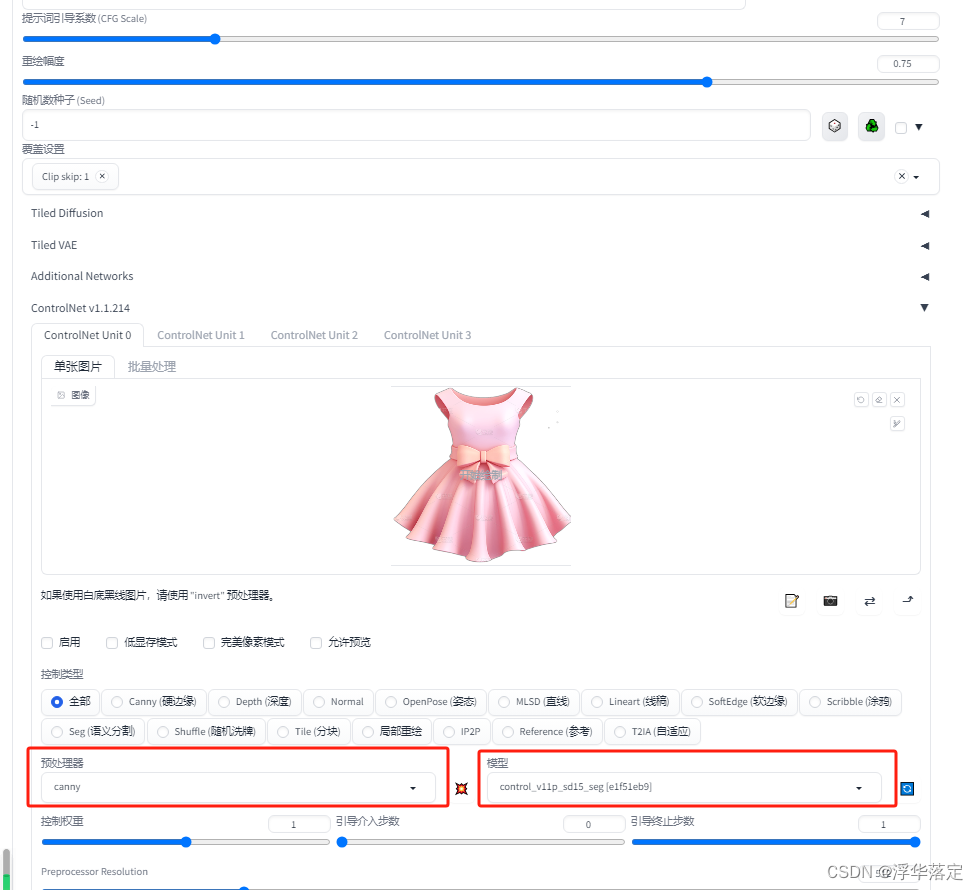
将骨骼图片放入Control Model-1中,预处理器无,模型选择openpose,引导时机0.7左右
输入需要的提示词点击生成,得到需要的图片,衣服相似度97%
3.后期处理
后期处理可以帮助我们处理模糊的图片。上传一张模糊的图片,调整Upscaler 1
修复二次元的照片选择”R-ESRGAN 4x+Anime68”
修复真人照片选择”R-ESRGAN 4x+”
其他的也可以尝试一下。
GFPGAN 强度调高点击生成就可以修复模糊照片啦。
4.图片反推(图片生成关键词)
1.PNG图片信息
上传一张图片,可以推理出这张图片的tag,将tag载入到文生图中可以得到与这张图片相似的图片。
2.标签器(Tagger)
标签器也可以反推tag,还可以给模型训练集批量打标。
Lora模型训练时可以用到这个功能。如图所示调整完参数之后点击反推提示词,就可以给训练集的图片打上标了。

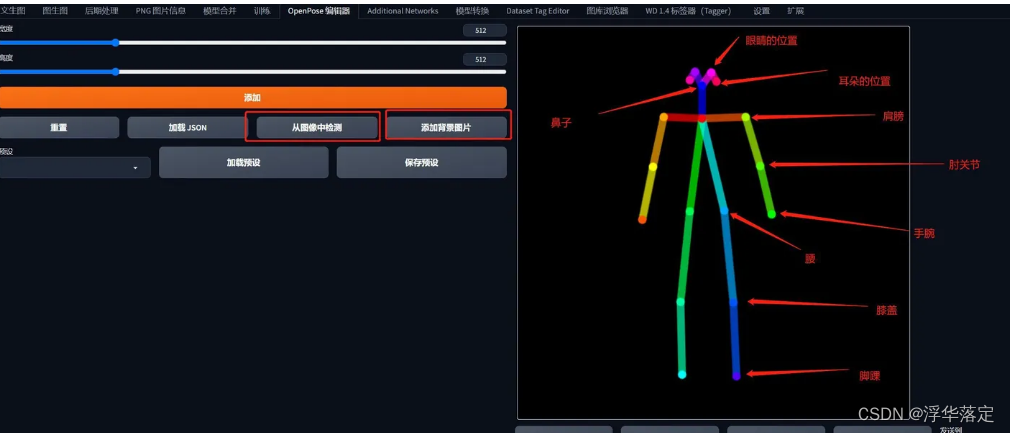
5.Openpose
Openpose可以通过调整节点,控制人物形态动作
也可以上传图片读取里面人物的动作
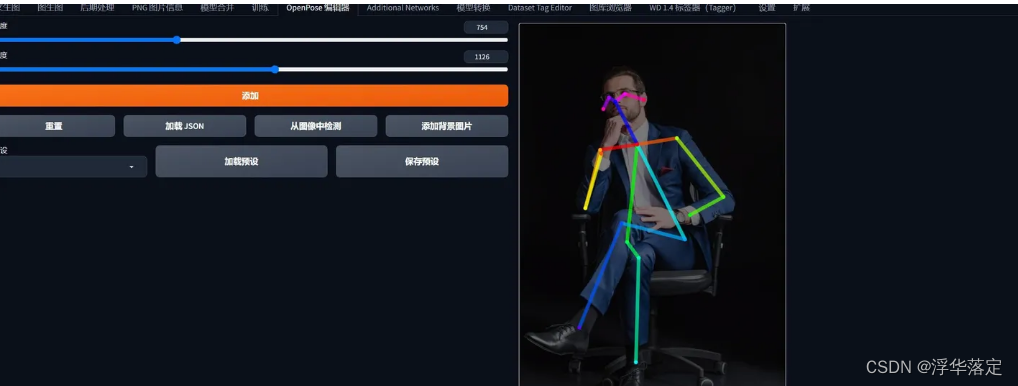
这对于出图有很大的帮助。
6.大模型的获取途径和选择

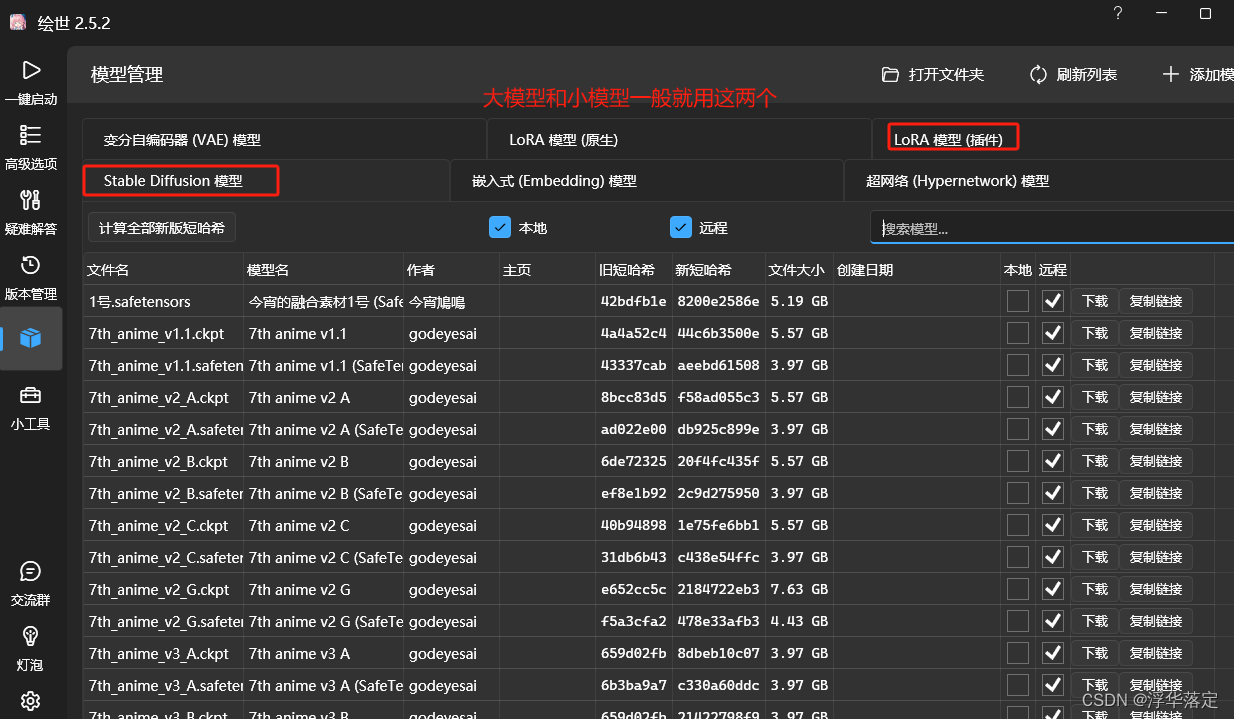
大模型的我们可以通过C站(civitai)下载,里面有各种风格模型,包括大模型和lora模型。
不过需要科学上网。国内也有一些移植的模型下载网站,但是模型数量较少。还可以上淘宝去买模型,不过免费的东西还是不要花这个钱了。
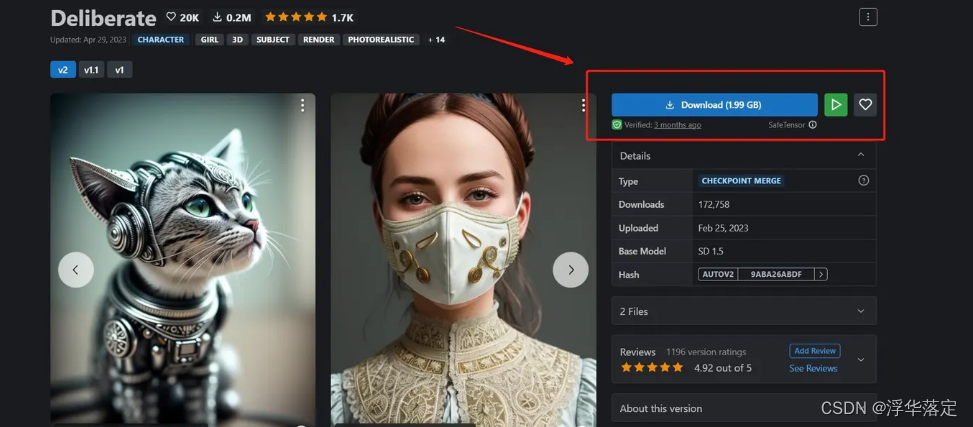
civitai :https://civitai.com/
点击Download就可以下载了,在这里我们还可以获取一些大佬的提示词、采样方法、迭代步数等信息,点击图片,在右下角就可以看到。不过有些没有被分享出来。
下载出来的模型放在models文件夹里,在WebUI点击刷新就可以使用了。

注意下载的模型的画风,按照需要选择模型。
7.Lora模型的作用
Lora的作用就像上文提到的可以控制人物的脸型、服饰、背景等。可以多个lora模型搭配使用,通过调整每个lora的权重来调整画面中出现的lora质量。注意多个lora权重数相加等于1。
四.ControlNet插件安装使用方法
1.安装方法和下载模型
打开扩展——可下载——点击加载扩展列表找到图里所示就可以下载了。
也可以通过网址下载安装:https://gitcode.net/ranting8323/sd-webui-controlnet
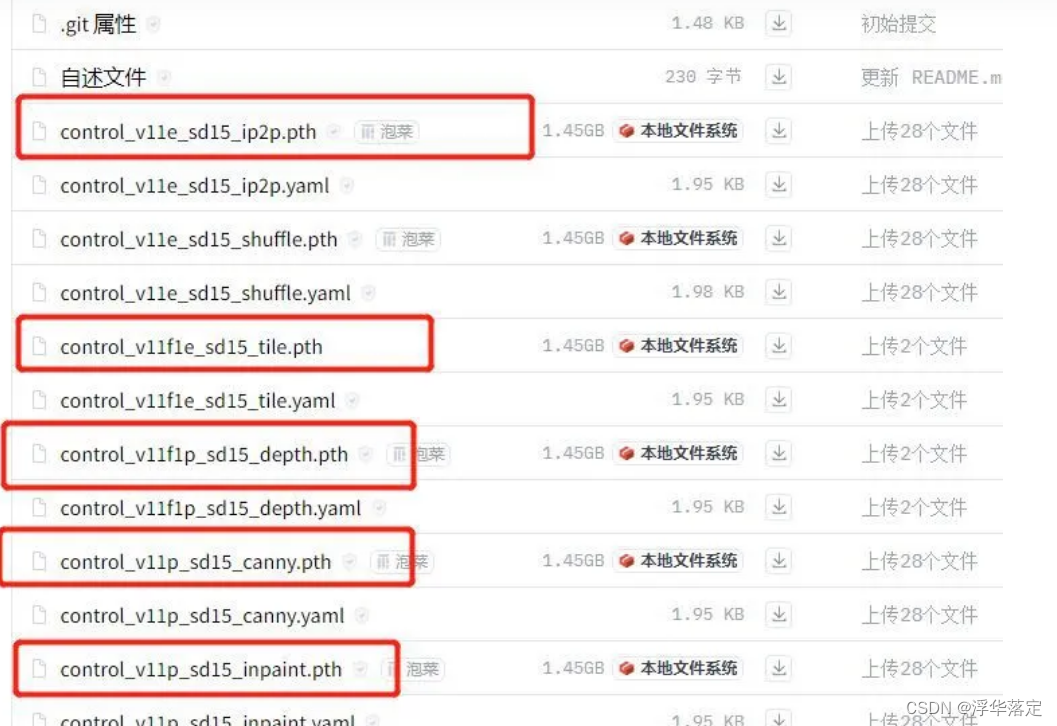
模型下载地址:https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main
看到这么多模型不用慌:常用的也就几个。
2.使用
插件模型安装好后就可以在主界面使用了。点击ControlNET就可以看到使用界面了。
比如我们有一张线稿图,就可以用这个插件上色。上传线稿图,点击启用,预处理器选择canny;模型选择canny调整参数。选择合适的模型,输入相对的tag,就可以生成图片了。
效果还不错哦。
前面我们提到的可以用openpose控制形态动作,但是没讲怎么用,这里就是使用方法了。
我们上传一张骨骼图,预处理器选择无,模型选择openpose,调整参数。这样就可以啦!
预处理器里面还有好多选项比如depth控制画面场景深度,openpose-hand可以控制手部动作等等。以后我会专门写一个controlNET插件相关的专栏来介绍这些。
五.结尾
本次stable diffusion基本使用方法就介绍到这里啦,略有不足的地方有很多,不过应该可以让大家轻松上手使用。以后我会写一些训练lora模型、controlnet插件等一些相关文章,包括有很多人想了解的如何利用lora模型做自己的产品效果图和如何变现的问题。










![2023年中国润滑油分散剂市场需求量及行业竞争现状分析[图]](https://img-blog.csdnimg.cn/img_convert/1b72b774330bd8e81b6607249d943e4f.png)