结构体和联合体详解
- 1.结构体struct
- 1.1 结构体struct的设计
- 1.2 结构体struct变量的定义和初始化
- 举例:使用结构体Student定义并初始化stu1变量。
- 举例:结构体嵌套的初始化方法。
- 1.3 结构体struct成员变量的访问(获取与赋值)
- 1.3.1 使用结构体指针访问和修改成员变量
- 1.3.2使用结构体指针访问和修改成员变量(函数)
- 1.4 结构体struct与数组的关系
- 1.5 结构体struct变量在内存中的表示(遵循内存对齐原则)(结构体大小)
- 1.5.1 内存对齐原则的深层次理解
- 为什么要进行内存对齐原则
- 进行内存对齐原则的优点
- 如何指定内存对齐数
- 2.联合体union
- 3.结构体和联合体
- 3.1 结构体和联合体的区别
- 3.2 结构体和联合体的结合
1.结构体struct
客观事物(实体)是复杂的,要描述它必须从多方面进行,也就是用不同的数据类型来描述不同的方面。基于此,就有了结构体struct类型。
结构体类型是c语言的一种自定义类型(设计类型),程序开发人员可以使用结构体来封装一些属性,设计出新的数据类型。
1.1 结构体struct的设计
可以使用结构体 (struct) 来存放一组不同类型的数据。结构体的定义形式为:
struct 结构体名称
{
成员1;
成员2;
...
};
其中,成员可以是基本数据类型,指针,数组或其它结构类型。
举例:如学生实体可以这样来描述:学生姓名 (用字符串描述),学生学号(用字符串描述),,性别(用字符串描述),年龄 (用整型数描述).这里用了属于 2 种不同数据类型,以及四个数据成员 (data member) 来描述学生实体。
struct Student
{
char s_name[8];
char s_id[8];
char s_sex[4];
int s_age;
};
注意:
- 关键字struct是数据类型说明符,指出该类型是结构体类型
- struct定义后面的**;**必不可少
- 标识符Student(上述例子)是结构体的类型名
1.2 结构体struct变量的定义和初始化
既然结构体是一种数据类型,那么就可以像其他基本数据类型一样用它来定义变量。
结构体是一种数据类型,是创建变量的模板,不占用内存空间;结构体变量才包含了实实在在的数据需要存储空间。
举例:使用结构体Student定义并初始化stu1变量。
struct Student
{
char s_name[8];
char s_id[8];
char s_sex[4];
int s_age;
};
int main()
{
//在.c文件中 struct Student stu1;
Student stu1 = {"nxx","2206","w",18};
return 0;
}
举例:结构体嵌套的初始化方法。
struct Date
{
int year;
int month;
int day;
};
struct Student
{
char s_name[8];
struct Date birthday;
};
int main()
{
struct Student stu1 = {"nxx",2000,01,01};
struct Student stu2 = {"nxx",{2000,01,01}};
struct Date date1 = {2000,01,01};
struct Student stu3 = {"nxx",date1};
return 0;
}
1.3 结构体struct成员变量的访问(获取与赋值)
获取和赋值结构体变量成员的一般格式:
结构体变量.成员名
struct Student
{
char s_name[8];
char s_id[8];
char s_sex[4];
int s_age;
};
int main()
{
struct Student stu1 = {"nxx","2206","w",18};
cout<< "stu1:"<< stu1.s_name<<" "<<stu1.s_id<<" "<< stu1.s_sex<<" "<< stu1.s_age<<endl;
//stu1.s_name = "aaa"; // error
strcpy(stu1.s_name,"aaa");
cout<< "stu1:"<< stu1.s_name<<" "<<stu1.s_id<<" "<< stu1.s_sex<<" "<< stu1.s_age<<endl;
struct Student stu2 = stu1;
cout<< "stu2:"<< stu2.s_name<<" "<<stu2.s_id<<" "<< stu2.s_sex<<" "<< stu2.s_age<<endl;
return 0;
}
注意:对结构变量整体赋值有三种情况
- 定义结构体变量 (用{ }初始化)
- 用已定义的结构变量初始化
- 结构体类型相同的变量可以作为整体相互赋值.
在其他情况的使用过程中只能对成员逐一赋值。
在c 语言中不存在对结构体类型的强制转换 (和内置类型的区别).
1.3.1 使用结构体指针访问和修改成员变量
内置类型能够定义指针变量,结构体类型也可以定义结构体类型指针。
结构体类型指针访问成员的获取和赋值形式:
- (*p).成员名(.的优先级高于 *,(*p) 两边的括号不能少)
- p-> 成员名 (>是 减号加大于号,中间没有空格称为指向符)
struct Student
{
char s_name[8];
char s_id[8];
char s_sex[4];
int s_age;
};
int main()
{
struct Student stu1 = {"nxx","2206","w",18};
struct Student *p = &stu1;
(*p).s_age = 17;
cout<< "stu1:"<< p->s_name<<" "<< p->s_id<<" "<< p->s_sex<<" "<< p->s_age<<endl;
p->s_age = 16;
cout<< "stu1:"<< (*p).s_name<<" "<<(*p).s_id<<" "<< (*p).s_sex<<" "<< (*p).s_age<<endl;
return 0;
}
1.3.2使用结构体指针访问和修改成员变量(函数)
struct Student
{
char s_name[8];
char s_id[8];
char s_sex[4];
int s_age;
};
void Print_a(struct Student stu)
{
cout<< "Print_a:"<< stu.s_name<<" "<<stu.s_id<<" "<< stu.s_sex<<" "<< stu.s_age<<endl;
}
void Print_b(struct Student *stu)
{
cout<< "Print_b:"<< stu->s_name<<" "<<stu->s_id<<" "<< stu->s_sex<<" "<< stu->s_age<<endl;
}
int main()
{
struct Student stu1 = {"nxx","2206","w",18};
Print_a(stu1);
Print_b(&stu1);
return 0;
}
1.4 结构体struct与数组的关系
struct Student stu1[] = {
{"aaa","2206","w",18},
{"bbb","2206","w",18}
};
1.5 结构体struct变量在内存中的表示(遵循内存对齐原则)(结构体大小)
struct Node
{
char cha;
int ia;
char chb;
};
int main()
{
struct Node node = {'a',1,'a'};
cout<<"sizeof(node)" << sizeof(node)<< endl; //12
cout<< "sizeof(struct Node)"<< sizeof(struct Node)<< endl;//12
return 0;
}
那么为什么sizeof(node)为什么会==12呐,按照我们之前的理解:sizeof(node) = sizeof(node.cha) +sizeof(node.cha) +sizeof(node.cha) = 6。但是我们实际运行起来,其大小却是12。这是为什么呐?
接下来,就要引出struct的内存对齐原则:
- 对齐数=min(编译器默认的一个对齐数,sizeof(该成员)) ;linux 中默认为4,vs 中的默认值为8)
- 结构体变量的首地址能够被min(结构体最大基本类型成员大小,对齐基数中)所整除
- 第一个成员在与结构体变量偏移量为0的地址
- 其他成员变量要对齐到对齐数的整数倍的地址处,如有需要编译器会在成员之间加上填充字节 (internal padding)
- 结构体总大小为最大对齐数的整数倍(每个成员变量除了第一个成员都有一个对齐数),如有需要编译器会在成员之间加上填充字节 (internal padding)
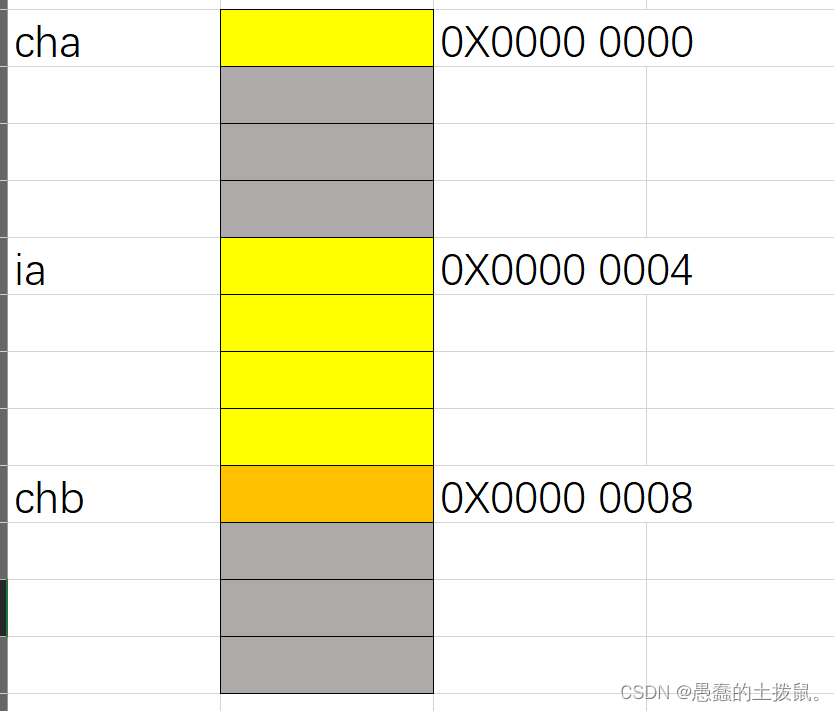
依据内存对齐原则,下面对结构体Node的大小进行分析:
struct Node
{
char cha;//1字节(对齐数==1,)
//这里要填充的原因参考4
int ia;//4字节(前面有3字节填充。对齐数==4,没有填充字节)
char chb;//1字节(,对齐数==1,后面有3字节对齐)
//这里要填充的原因参考5
};
1.5.1 内存对齐原则的深层次理解
为什么要进行内存对齐原则
- 内存大小的基本单位是字节(byte)。
理论上来讲,可以从任意地址访问变量。
但是实际上,CPU 并非逐字节读写内存,而是以 2,4,或 8 的倍数的字节块来读写内存,因此就会对基本数据类型的地址作出一些限制,即它的地址必须是 2,4或8 的倍数。那么就要求各种数据类型按照一定的规则在空间上排列,这就是对齐。
即内存对齐可以使得CPU一次就可以将所需的数据读进来。 - 有些平台每次读都是从偶地址开始,如果一个 int型(假设为 32 位系统)如果存放在偶地址开始的地方,那么一个读周期就可以读出这 32bit,而如果存放在奇地址开始的地方,就需要 2 个读周期,并对两次读出的结果的高低字节进行拼凑才能得到该 32bit 数据。显然在读取效率上下降很多。
同样,相比于存取对齐的数据,存取非对齐的数据需要花费更多的时间; - 由于不同平台对齐方式可能不同,如此一来,同样的结构在不同的平台其大小可能不同,在无意识的情况下互相发送的数据可能出现错乱,甚至引发严重的问题
- 此外,会有一些硬件设备的限制:
某些硬件设备只能存取对齐数据,存取非对齐的数据可能会引发异常;
某些硬件设备不能保证在存取非对齐数据的时候的操作是原子操作;
某些处理器虽然支持非对齐数据的访问,但会引发对齐陷阱(alignment trap);
某些硬件设备只支持简单数据指令非对齐存取,不支持复杂数据指令的非对齐存取。
进行内存对齐原则的优点
- 便于在不同的平台之间进行移植,因为有些硬件平台不能够支持任意地址的数据访问,只能在某些地址处取某些特定的数据,否则会抛出异常
- 提高内存的访问效率,因为 CPU 在读取内存时,是一块一块的读取
如何指定内存对齐数
预处理指令#pragma pack(n) 可以改变默认对齐数。n 取值是 1,2,4,8,16
#pragma pack(1)
struct Node
{
char cha;
int ia;
char chb;
};
//#pragma pack(1)需要以#pragma pack()结束,表示该种对齐方式到此结束
#pragma pack()
int main()
{
struct Node node = {'a',1,'a'};
cout<<"sizeof(node)" << sizeof(node)<< endl; //6
return 0;
}
2.联合体union
在联合体中,各成员共享同一段内存空间,一个联合变量的长度等于各成员中最长的长度。
应该说明的是,这里所谓的共享不是指把多个成员同时装入一个联合变量内,而是指该联合变量可被赋予任一成员值,但每次只能赋一种值,赋入新值则冲去旧值。(覆盖)
一个联合体类型必须经过定义之后,才能使用它,才能把一个变量声明定义为该联合体类型。
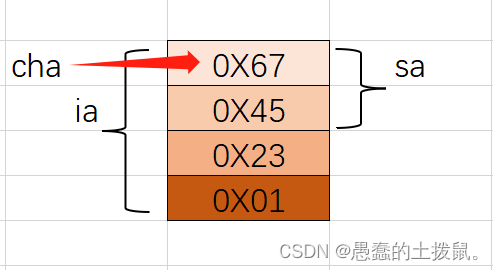
union Node
{
char cha;
int ia;
short sa;
};
int main()
{
union Node node;
node.ia = 0x01234567;
cout<< "sizeof(node):" << sizeof(node)<< endl; //6
//0X67->char类型g 0X01234567 0X4567
cout<< "node:"<< hex<< node.cha<< " "<< node.ia<< " "<< node.sa<< endl;
return 0;
}
图示说明:
3.结构体和联合体
3.1 结构体和联合体的区别
- 结构体将不同类型的数据组合成一个整体;
共同体是不同类型的几个变量共同占用一段内存。 - sizeof()大小:
sizeof(struct)是内存对齐后所有成员长度的总和
sizeof(union)是内存对齐后最长数据成员的长度 - 内存使用:
结构体中的每个成员都有自己独立的地址,它们是同时存在的
共同体中的所有成员占用同一段内存,它们不能同时存在(会覆盖)
3.2 结构体和联合体的结合
union UnDat1
{
unsigned int xi;
unsigned char s1,s2,s3,s4;
};
union UnDat2
{
unsigned int xi;
struct
{
unsigned char s1,s2,s3,s4;
};
};