目录
- 参考引用
- 一、数据集介绍
- 二、环境配置
- 三、构建训练数据集
- 四、修改配置文件
- 五、训练及tensorboard可视化
- 六、效果测试
- 七、遇到的BUG
参考引用
你的陈某某-基于YOLOv5的PCB板缺陷检测
一、数据集介绍
印刷电路板(PCB)瑕疵数据集。它是一个公共合成PCB数据集,包含1386张图像,具有6种缺陷(漏孔、鼠咬、开路、短路、杂散、杂铜),用于图像检测、分类和配准任务。
下载地址:数据集
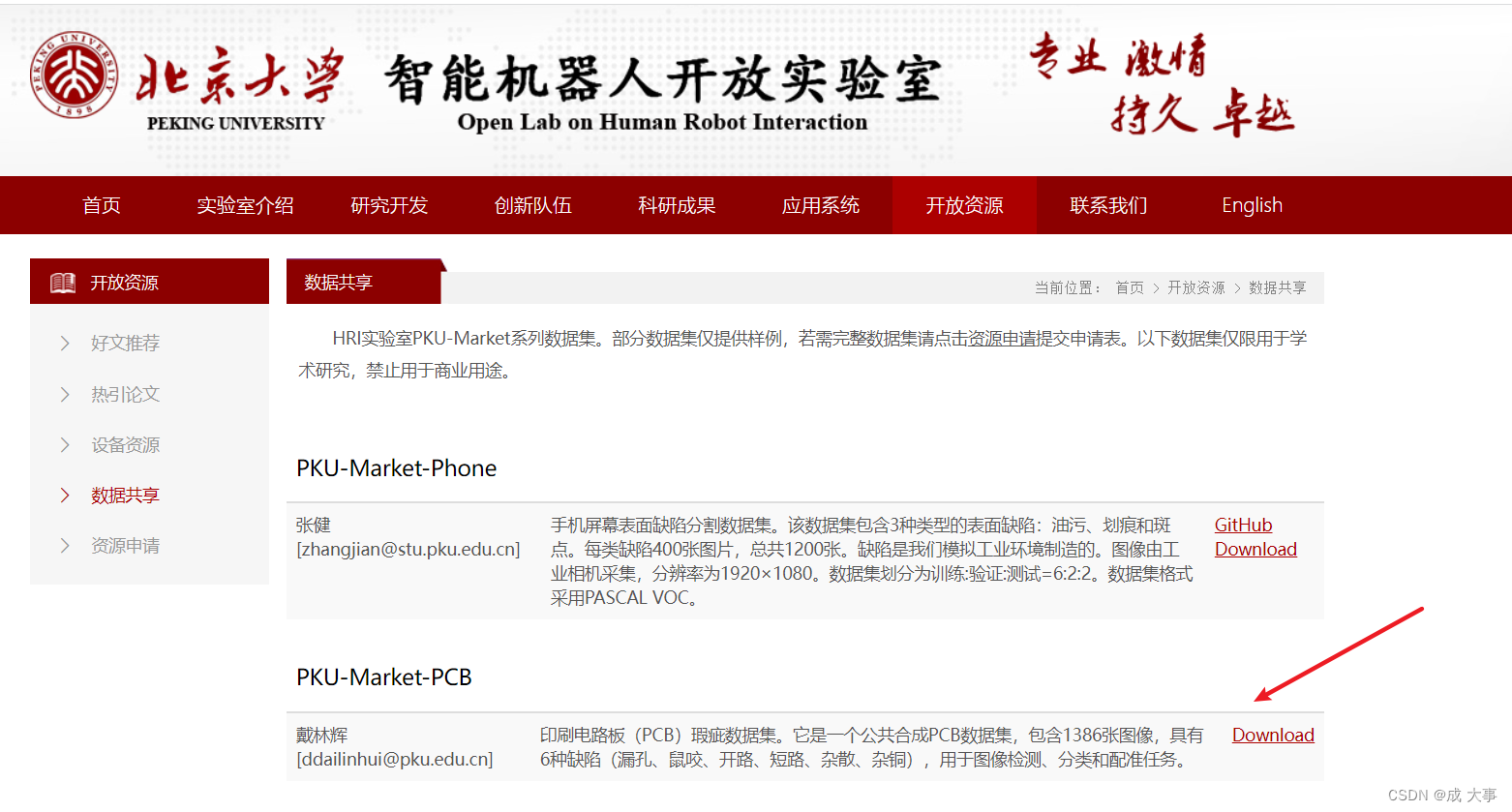
数据样本示例:

二、环境配置
1、Gitub官网下载yolov5源码:官方地址
2、Anaconda 安装配置(省略)
3、创建新的环境(python=3.8就行,因为使用的是7.0的版本,3.6有点低。)
conda create -n pytorch python=3.8.5
4、安装pytorch:pytorch官网
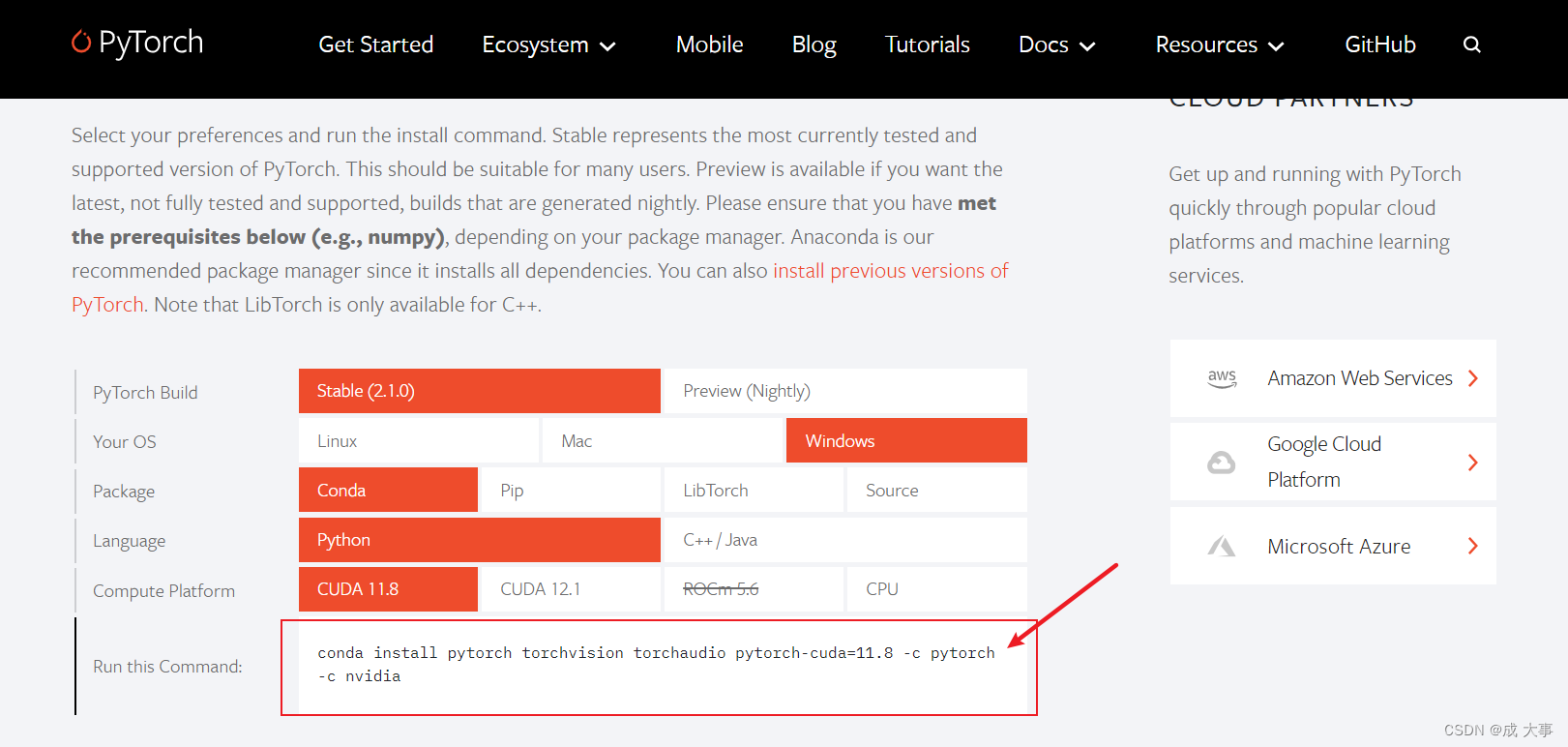
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
5、yolov5的依赖下载
根据下载的 yolov5中的requirements.txt进行安装(缺啥补啥)【注意:具体安装以yolov5的readme.md为主!】
pip install -r requirements.txt
三、构建训练数据集
1、先构建数据集文件夹
下载好的PCB_DATASET解压后。是下面这种格式。
官网下载的PCB数据按照缺陷类划分文件夹的
将每个文件夹内的东西都复制出来到这个文件中。
然后删掉分类的文件夹。
images文件夹内的内容也是一样的。
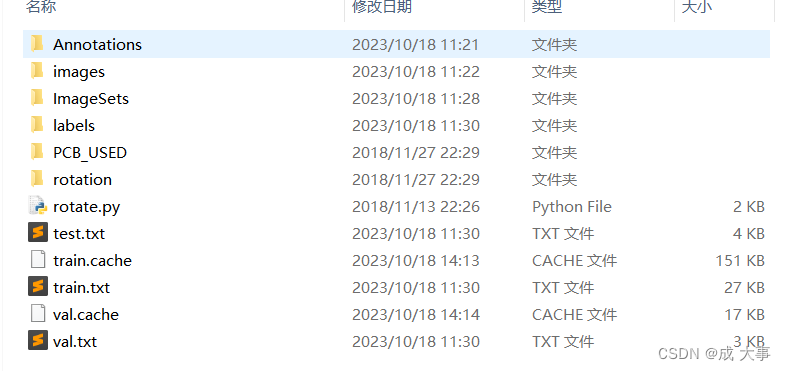
├── PCB_DATASET
│ ├── Annotations 进行 detection 任务时的标签文件,xml 形式,文件名与图片名一一对应
│ ├── images 存放 .jpg 格式的图片文件
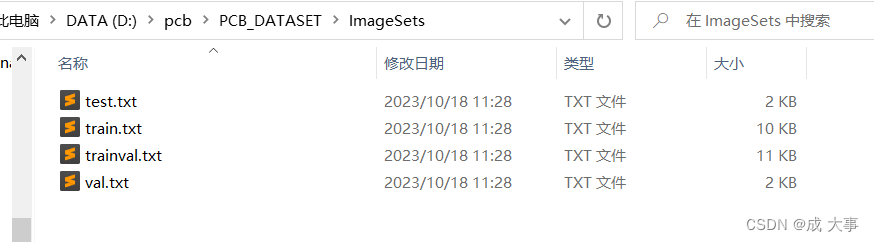
│ ├── ImageSets 存放的是分类和检测的数据集分割文件,包含 train.txt,val.txt ,trainval.txt,test.txt
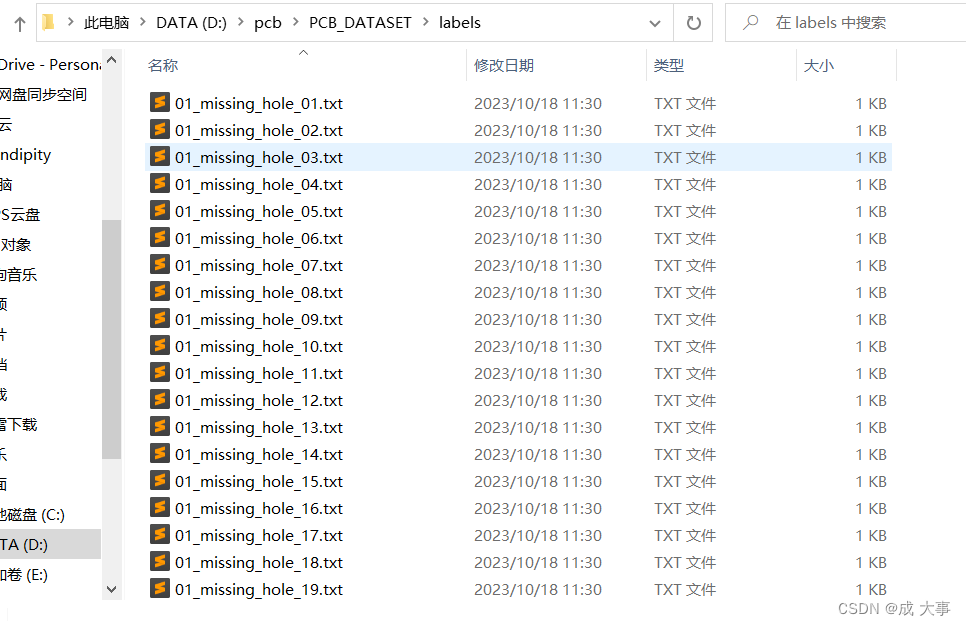
│ ├── labels 存放label标注信息的txt文件,与图片一一对应
├── ImageSets(train,val,test建议按照8:1:1比例划分)
│ ├── train.txt 写着用于训练的图片名称
│ ├── val.txt 写着用于验证的图片名称
│ ├── trainval.txt train与val的合集
│ ├── test.txt 写着用于测试的图片名称
2、训练数据生成,分为两个代码(训练集划分代码与用于yolo训练的txt格式代码)
(1)训练集划分代码
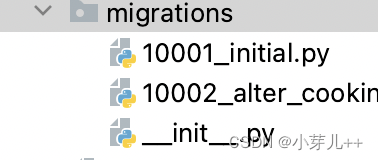
在PCB_DATASET文件夹下新建ImageSets文件夹。
用途:主要是将数据集分类成训练数据集和测试数据集,默认train,val,test按照比例进行随机分类,运行后ImagesSets文件夹中会出现四个文件,主要是生成的训练数据集和测试数据集的图片名称。
import os
import random
trainval_percent = 0.9
train_percent = 0.9
xmlfilepath = 'D:\\pcb\\PCB_DATASET\\Annotations'
txtsavepath = 'D:\\pcb\\PCB_DATASET\\ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open(txtsavepath+'\\trainval.txt', 'w')
ftest = open(txtsavepath+'\\test.txt', 'w')
ftrain = open(txtsavepath+'\\train.txt', 'w')
fval = open(txtsavepath+'\\val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
如下图。同时data目录下也会出现这四个文件,内容是训练数据集和测试数据集的图片路径。
(b)用于yolo训练的txt格式代码
用途:主要是将图片数据集标注后的xml文件中的标注信息读取出来并写入txt文件。
# xml解析包
import xml.etree.ElementTree as ET
import pickle
import os
# os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test', 'val']
classes = ['missing_hole', 'mouse_bite', 'open_circuit', 'short', 'spur', 'spurious_copper']
label_path = 'D:\\pcb\\PCB_DATASET\\labels'
ImageSets = 'D:\\pcb\\PCB_DATASET\\ImageSets'
images = 'D:\\pcb\\PCB_DATASET\\images'
# 进行归一化操作
def convert(size, box): # size:(原图w,原图h) , box:(xmin,xmax,ymin,ymax)
dw = 1./size[0] # 1/w
dh = 1./size[1] # 1/h
x = (box[0] + box[1])/2.0 # 物体在图中的中心点x坐标
y = (box[2] + box[3])/2.0 # 物体在图中的中心点y坐标
w = box[1] - box[0] # 物体实际像素宽度
h = box[3] - box[2] # 物体实际像素高度
x = x*dw # 物体中心点x的坐标比(相当于 x/原图w)
w = w*dw # 物体宽度的宽度比(相当于 w/原图w)
y = y*dh # 物体中心点y的坐标比(相当于 y/原图h)
h = h*dh # 物体宽度的宽度比(相当于 h/原图h)
return (x, y, w, h) # 返回 相对于原图的物体中心点的x坐标比,y坐标比,宽度比,高度比,取值范围[0-1]
# year ='2012', 对应图片的id(文件名)
def convert_annotation(image_id):
'''
将对应文件名的xml文件转化为label文件,xml文件包含了对应的bunding框以及图片长款大小等信息,
通过对其解析,然后进行归一化最终读到label文件中去,也就是说
一张图片文件对应一个xml文件,然后通过解析和归一化,能够将对应的信息保存到唯一一个label文件中去
labal文件中的格式:calss x y w h 同时,一张图片对应的类别有多个,所以对应的bunding的信息也有多个
'''
# 对应的通过year 找到相应的文件夹,并且打开相应image_id的xml文件,其对应bund文件
in_file = open('D:\\pcb\\PCB_DATASET\\Annotations\\%s.xml' % (image_id), encoding='utf-8')
# 准备在对应的image_id 中写入对应的label,分别为
# <object-class> <x> <y> <width> <height>
out_file = open(label_path+'\\%s.txt' % (image_id), 'w', encoding='utf-8')
# 解析xml文件
tree = ET.parse(in_file)
# 获得对应的键值对
root = tree.getroot()
# 获得图片的尺寸大小
size = root.find('size')
# 如果xml内的标记为空,增加判断条件
if size != None:
# 获得宽
w = int(size.find('width').text)
# 获得高
h = int(size.find('height').text)
# 遍历目标obj
for obj in root.iter('object'):
# 获得difficult ??
difficult = obj.find('difficult').text
# 获得类别 =string 类型
cls = obj.find('name').text
# 如果类别不是对应在我们预定好的class文件中,或difficult==1则跳过
if cls not in classes or int(difficult) == 1:
continue
# 通过类别名称找到id
cls_id = classes.index(cls)
# 找到bndbox 对象
xmlbox = obj.find('bndbox')
# 获取对应的bndbox的数组 = ['xmin','xmax','ymin','ymax']
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
print(image_id, cls, b)
# 带入进行归一化操作
# w = 宽, h = 高, b= bndbox的数组 = ['xmin','xmax','ymin','ymax']
bb = convert((w, h), b)
# bb 对应的是归一化后的(x,y,w,h)
# 生成 calss x y w h 在label文件中
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
# 返回当前工作目录
wd = getcwd()
print(wd)
for image_set in sets:
'''
对所有的文件数据集进行遍历
做了两个工作:
1.将所有图片文件都遍历一遍,并且将其所有的全路径都写在对应的txt文件中去,方便定位
2.同时对所有的图片文件进行解析和转化,将其对应的bundingbox 以及类别的信息全部解析写到label 文件中去
最后再通过直接读取文件,就能找到对应的label 信息
'''
# 先找labels文件夹如果不存在则创建
if not os.path.exists(label_path):
os.makedirs(label_path+'\\')
# 读取在ImageSets/Main 中的train、test..等文件的内容
# 包含对应的文件名称
image_ids = open(ImageSets+'\\%s.txt' % (image_set)).read().strip().split()
# 打开对应的2012_train.txt 文件对其进行写入准备
list_file = open('D:\pcb\PCB_DATASET\\%s.txt' % (image_set), 'w')
# 将对应的文件_id以及全路径写进去并换行
for image_id in image_ids:
list_file.write(images+'\\%s.jpg\n' % (image_id))
# 调用 year = 年份 image_id = 对应的文件名_id
convert_annotation(image_id)
# 关闭文件
list_file.close()
# os.system(‘comand’) 会执行括号中的命令,如果命令成功执行,这条语句返回0,否则返回1
# os.system("cat 2007_train.txt 2007_val.txt 2012_train.txt 2012_val.txt > train.txt")
# os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt 2012_train.txt 2012_val.txt > train.all.txt")
运行后在labels文件夹中出现所有图片数据集的标注信息。
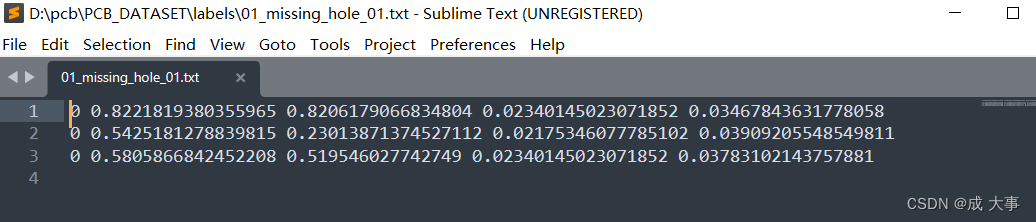
label文件夹中某文件内容如下:
四、修改配置文件
1、数据集方面:yolov5-7.0\data文件夹中,新建一个yolovs-pcb.yaml文件,内容设置如下:
train: D:\\pcb\\PCB_DATASET\\train.txt
val: D:\\pcb\\PCB_DATASET\\val.txt
test: D:\\pcb\\PCB_DATASET\\test.txt
# classes
nc: 6 # number of classes
names: [ 'missing_hole', 'mouse_bite', 'open_circuit', 'short', 'spur', 'spurious_copper' ] # class names
注意:路径,类别、标签名字(与标注文件中一致)
2、网络参数方面:yolov5-7.0\model文件夹中,复制yolov5s.yaml文件,为yolov5s-pcb.yaml,将内容进行修改
# Parameters
nc: 6 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
更改其中的nc即标签类别数目。一共是6类。
3、trian.py修改
主要用到的几个参数:–weights,–cfg,–data,–epochs,–batch-size,–img-size,–project,-workers
重点注意:–weights,–cfg,–data,其他的默认即可(batch_size,workers根据自己电脑属性进行设置)。
我的–weights,–cfg,–data设置如下:
parser.add_argument('--weights', type=str, default='yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='models/yolov5s-pcb.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/PCB.yaml', help='dataset.yaml path')
五、训练及tensorboard可视化
1、训练
两种方式:pycharm中运行或者终端cmd运行(看个人喜好)
2、训练过程可视化
啰嗦一句:yolov5-7.0文件夹中一个runs文件夹,其中有检测结果和训练结果,如runs\train\exp\results.csv中保存了每个epoch训练信息,如下所示:

可视化操作:
a、打开一个新的终端,激活环境
【注意:使用tensorboard不需要安装tensorflow,直接pip install xxx安装了即可使用,yolov5安装文档会通过pip install -r requirements.txt自己安装上,若没有再尝试单独装!】
b、cd …\yolov5-7.0
c、tensorboard --logdir=runs或者python -m tensorboard.main --logdir=runs

d、复制其中的网址,去浏览器中打开(推荐谷歌)
e、可视化结果如下(能够边训练边观察):
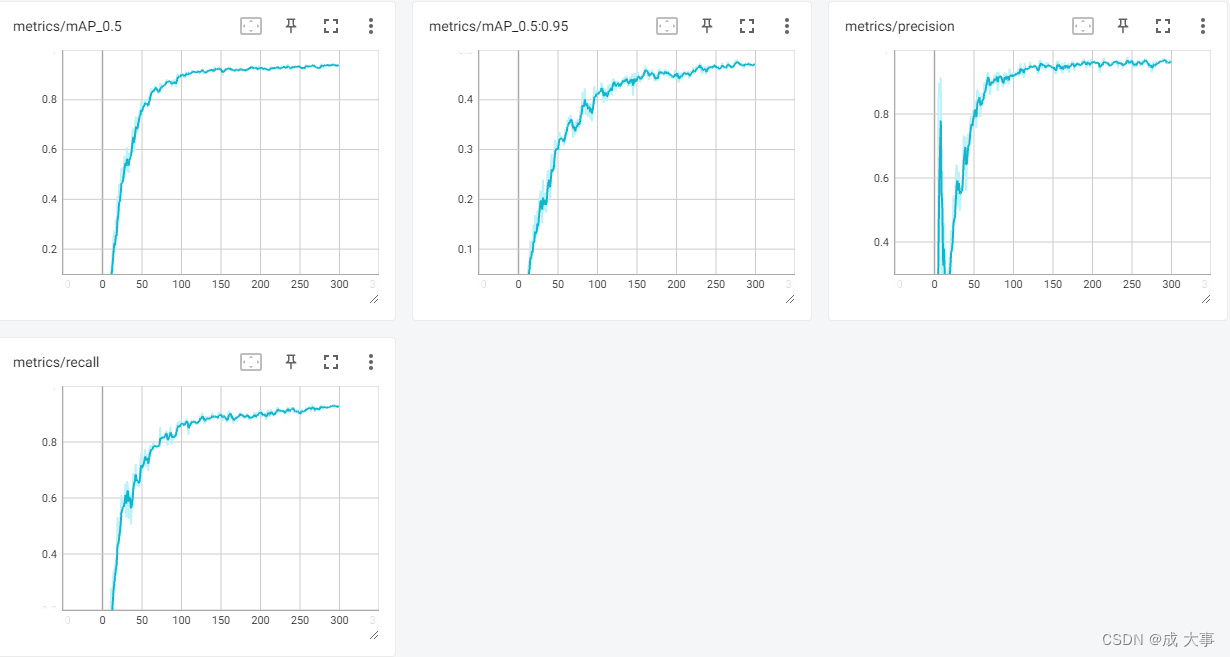
3、在NVIDIA GeForce GTX 1650 8G显卡训练结果如下(batch_size=16,workers=8):
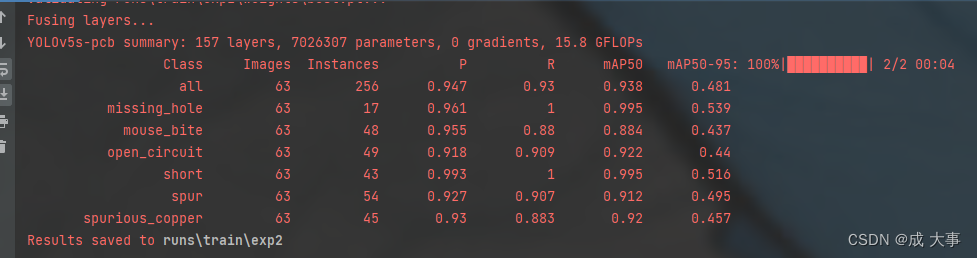
注意:可能 runs\train文件夹中会有多个exp文件,如exp1,exp2等,这是代表每一次新的训练。
当然你也可以修改本次训练结果的文件夹的名称。

六、效果测试
在CMD终端运行:
python detect.py --source data_ready\01_missing_hole_01.jpg --weights runs\train\exp\weights\best.pt
测试结果如下(好像效果不咋地,可以更换其他yolov5系列的网络试试,或者聚类重选anchor):

注:在pycharm中运行检测,只需更改train.py中的def parse_opt()函数中的–source与–weights即可。
七、遇到的BUG
1、‘FreeTypeFont’ object has no attribute ‘getsize’
运行时报错:AttributeError: ‘FreeTypeFont’ object has no attribute ‘getsize’
其实是pollow版本10.0之后,删除了getsize的方法,将pillow版本降低即可。
pip install Pillow==9.5 -i https://pypi.tuna.tsinghua.edu.cn/simple/