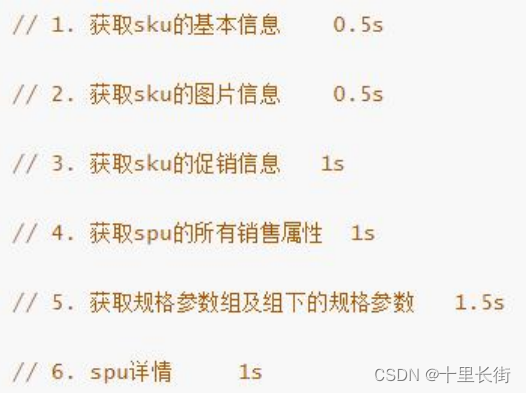
决策树学习的算法通常是一个递归地选择最优特征(选择方法的不同,对应着不同的算法),并根据该特征对训练数据进行分割,使得各个子数据集有一个最好的分类的过程。这一过程对应着对特征空间的划分,也对应着决策树的构建
步骤(译)
从根节点开始
计算所有可能特征的信息增益,并选择信息增益最高的特征
根据选择的特征对数据集进行拆分,并创建树的左右分支
继续重复分割过程,直到满足停止条件:
当一个节点100%是一个类时当分割节点时
将导致树超过最大深度
额外分割的信息增益小于阈值
当一个节点中的样例数量低于阈值时
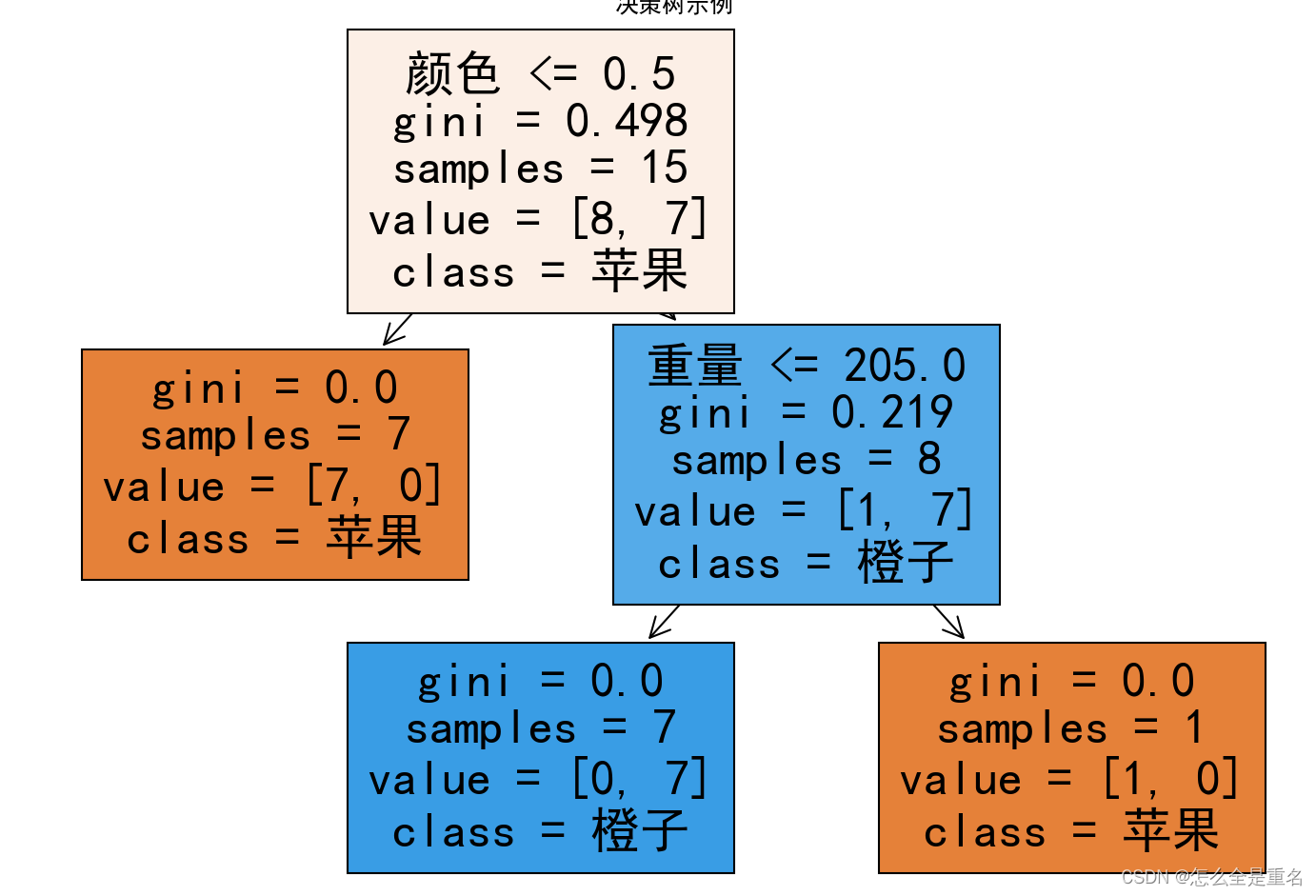
简单实例
# 导入所需的库
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
import matplotlib.pyplot as plt
import numpy as np
# 解决中文乱码问题
plt.rcParams['font.sans-serif']=['SimHei']
# 创建训练数据集
X = np.array([[0, 150], [0, 200], [1, 160], [1, 190], [0, 180],
[1, 140], [1, 210], [0, 175], [0, 220], [1, 165],
[1, 155], [0, 185], [0, 195], [1, 170], [1, 200]])
y = np.array([0, 0, 1, 1, 0, 1, 0, 0, 0, 1, 1, 0, 0, 1, 1])
# 创建深度等于3的决策树模型
model = DecisionTreeClassifier(max_depth=3)
# 训练模型
model.fit(X, y)
# 可视化生成的决策树
plt.figure(figsize=(12, 8))
tree.plot_tree(model, filled=True, feature_names=["颜色", "重量"], class_names=["苹果", "橙子"])
plt.title("决策树示例")
plt.show()