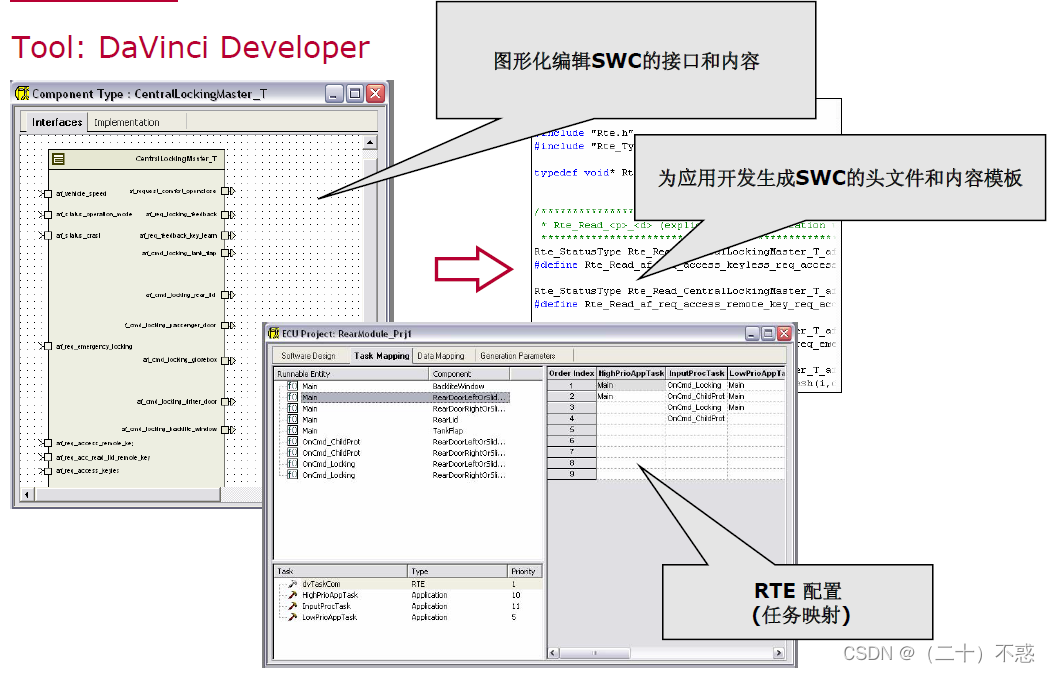
接着我的上一篇文章《网页爬虫完全指南》,这篇文章将涵盖几乎所有的 Python 网页爬取工具。我们从最基本的开始讲起,逐步涉及到当前最前沿的技术,并且对它们的利弊进行分析。
当然,我们不能全面地介绍每个工具,但这篇文章应该足以让你很好地知道哪些工具做什么,以及何时使用每一种工具。
注意: 本文中所涉及到的 Python 均指 Python3。
本文要点:
- Web 基础
- 手动创建一个 socket 并且发送 HTTP 请求
- urllib3 & LXML
- requests & BeautifulSoup
- Scrapy(爬虫框架)
- Selenium(浏览器自动化测试框架) & Chrome——headless
- 总结
Web 基础
互联网其实是 非常复杂的 ——我们通过浏览器浏览一个简单的网页时,其背后其实涉及到许多技术和概念。 我并不打算对其进行逐一讲解, 但我会告诉你如果想要从网络中爬取数据需要了解哪些最重要的知识。
HyperText Transfer Protocol(超文本传输协议,简称 HTTP)
HTTP 采用 C/S 模型 , 在 HTTP 客户机(如 浏览器,Python 程序, curl(命令行工具),Requests 等等) 创建一个连接并向 HTTP 服务器(如 Nginx,Apache 等)发送信息(“我想浏览产品页”)。
然后服务器返回一个响应(如 HTML 代码)并且关闭连接。与 FTP 这些有状态协议不同,HTTP 的每个事务都是独立的,因此被称为无状态协议。
基本上,当你在浏览器中键入网站地址时,HTTP 请求如下所示:
GET /product/ HTTP/1.1
Host: example.com
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/web\
p,*/*;q=0.8
Accept-Encoding: gzip, deflate, sdch, br
Connection: keep-alive
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit\
/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36
在这个请求的第一行, 你可以获得如下的信息:
- 使用 Get 动词或者方法, 意味着我们从指定的路径 /product/ 请求数据。还有其他 HTTP 谓词,你可以在这里看到完整的列表。
- HTTP 协议的版本。在本教程中,我们将重点讨论 HTTP1。
- 多个 header 字段。
以下是最重要的 header 字段:
- Host: 服务器的域名。如果没有给出端口号,则默认为 80* . *
- User-Agent: 包含有关发起请求的客户端的信息, 包括 OS 等信息。比如说上面的例子中,表明了我的浏览器(Chrome),在
Mac OS X 系统上.
这个header字段很重要,因为它要么用于统计(有多少用户访问我的移动和桌面网站),要么用于防止机器人的任何违规行为。因为这些报头是由客户端发送的,所以可以使用一种名为“报头欺骗”的技术对其进行修改。这正是我们的爬虫程序要做的,使他们看起来像一个正常的网页浏览器。 - Accept: 表明响应可接受的内容类型。有许多不同的内容类型和子类型: text/plain,text/html,
image/jpeg, application/json … - Cookie:name1=value1; name2=value2… 这个 header 字段包含一组键值对。这些称为会话
cookie,是网站用来验证用户身份和在浏览器中存储数据的工具。比如说,当你登录时填写完账号密码并提交,服务器会检查你输入的账号密码是否正确。如果无误,它将重定向并且在你的浏览器中注入一个会话cookie,浏览器会将此cookie连同随后的每个请求一起发送给服务器。 - Referrer :
这个字段包含请求实际URL的URL。网站通过此header字段来判断用户的来源,进而调整该用户的网站权限。例如,很多新闻网站都有付费订阅,只允许你浏览
10% 的帖子。但是,如果用户是来自像 Reddit 这样的新闻聚合器,就能浏览全部内容。网站使用 referrer
头字段来进行检查这一点。 有时,我们不得不伪造这个 header 字段来获取我们想要提取的内容。
当然 header 字段不仅仅是这些。你可以在此处获取更多的信息。
服务器将返回类似如下的响应:
HTTP/1.1 200 OK
Server: nginx/1.4.6 (Ubuntu) Content-Type: text/html; charset=utf-8 <!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" /> ...[HTML CODE]
在第一行我们能看到一个HTTP代码 200 OK 。这意味着我们的请求成功了。至于请求头,有很多 HTTP 代码,分为四个常见的类:2XX 用于成功请求,3XX 用于重定向,4XX 用于错误请求(最著名的是404未找到),5XX 用于服务器错误。
如果你使用 Web 浏览器发送 HTTP 请求,它将解析 HTML 代码,获取所有最终资源(JavaScript、CSS 和图像文件),并将结果呈现到主窗口中。
在下一节中,我们将看到使用 Python 执行 HTTP 请求的不同方法,并从响应中提取我们想要的数据。
手动创建一个 socket 并且发送 HTTP 请求 Socket(套接字)
在 Python 中执行 HTTP 请求的最基本方法是打开一个 socket 并手动发送 HTTP 请求:
import socket
HOST = 'www.google.com' # Server hostname or IP address
PORT = 80 # Port
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_address = (HOST, PORT)
client_socket.connect(server_address)
request_header = b'GET / HTTP/1.0\r\nHost: www.google.com\r\n\r\n'
client_socket.sendall(request_header)
response = ''
while True:
recv = client_socket.recv(1024)
if not recv:
break
response += str(recv)
现在我们有了 HTTP 响应,从其中提取数据的最基本方法就是使用正则表达式。
正则表达式
正则表达式(RE, or Regex)是字符串的搜索模式。你可以使用 regex 在更大的文本中搜索特定的字符或单词,例如,你可以识别网页上的所有电话号码。你也可以轻松地替换字符串,例如,可以将格式较差的 HTML 中的所有大写标记用小写标记替换。还可以验证一些输入。
你可能想知道,为什么在进行 Web 抓取时了解正则表达式很重要?毕竟,有各种不同的 Python 模块来解析 HTML、XPath 和 CSS 选择器。
在一个理想的语义世界中 ,数据很容易被机器读取,信息被嵌入到相关的 HTML 元素和具有一定意义的属性中。
但现实世界是混乱的,你经常会在 p 元素中搜索大量的文本。当你想要在这个巨大的文本块中提取特定数据(如价格、日期或名称)时,你必须使用正则表达式。
注意:
我的职业生涯开始和大多数码农一样,刚开始接触都是最基础的软件测试、编程语法。那时候在B站CSDN到处找学习资源,在这个吃技术的IT行业来说
,不断学习是至关重要的。但是我之前做的是最基础的业务工作,随着时间的消磨,让我产生了对自我价值和岗位意义的困惑。
我的程序员之路,一路走来都离不开每个阶段的计划,因为自己喜欢规划和总结,所以,我和朋友特意花了一段时间整理编写了下面的《python架构师
学习路线》,也整理了不少【网盘资源】,需要的朋友可以公众号【Python大本营】获取网盘链接。希望会给你带来帮助和方向。
当你的数据类似于下面这种的时候,正则表达式就能发挥很大的作用:
<p>Price : 19.99$</p>
我们可以使用 XPath 表达式选择这个文本节点,然后使用这种 regex 提取 price。请记住,正则表达式模式是从左到右应用的,每个源字符只使用一次。:
^Price\s:\s(\d+.\d{2})$
要提取 HTML 标记中的文本,使用 regex 是很烦人的,但它是可行的:
import re
html_content = '<p>Price : 19.99$</p>'
如你所见,通过 socket 手动发送 HTTP 请求并使用正则表达式解析响应是可以完成的,但这很复杂。所以有更高级别的 API 可以使这个任务变得更容易。
urllib3 & LXML
说明: 我们在学习 Python 中的 urllib 系列的库的时候很容易感到迷茫。Python 除了有作为标准库一部分的 urlib 和 urlib2,还有 urlib3。urllib2 在 Python3 中被分成很多模块,不过 urllib3 在短期内应该不会成为标准库的一部分。其实应该有一篇单独文章来讨论这些令人困惑的细节,在本篇中,我选择只讨论 urllib 3,因为它在 Python 世界中被广泛使用。
urllib3 是一个高级包,它允许你对 HTTP 请求做任何你想做的事情。我们可以用更少的代码行来完成上面的套接字操作:
import urllib3
http = urllib3.PoolManager()
r = http.request('GET', 'http://www.google.com')
print(r.data)
比套接字版本要简洁得多,对吗?不仅如此,API 也很简单,你可以轻松地做许多事情,比如添加 HTTP 头、使用代理、发布表单等等。
例如,如果我们必须设置一些 header 字段来使用代理,我们只需这样做:
import urllib3
user_agent_header = urllib3.make_headers(user_agent="<USER AGENT>")
pool = urllib3.ProxyManager(f'<PROXY IP>', headers=user_agent_header)
r = pool.request('GET', 'https://www.google.com/')
看见没?完全相同的行数。
然而,有些事情 urllib 3并不容易处理。如果要添加 cookie,则必须手动创建相应的 header 字段并将其添加到请求中。
此外,urllib 3 还可以做一些请求不能做的事情,比如池和代理池的创建和管理,以及重试策略的控制。
简单地说,urllib 3 在抽象方面介于请求和套接字之间,尽管它比套接字更接近请求。
为了解析响应,我们将使用 lxml 包和 XPath 表达式。
XPath
XPath 是一种使用路径表达式在 XML 或 HTML 文档中选择节点或节点集的技术。与文档对象模型(DocumentObjectModel)一样,XPath 自 1999 年以来一直是 W3C 标准。即使 XPath 本身不是一种编程语言,它允许你编写可以直接访问特定节点或节点集的表达式,而无需遍历整个 XML 或 HTML 树。
可以将 XPath 看作一种专门用于 XML 或 HMTL 的正则表达式。
要使用 XPath 从 HTML 文档中提取数据,我们需要 3 件事:
- HTML 文档
- 一些 XPath 表达式
- 运行这些表达式的 XPath 引擎
首先,我们将使用我们通过 urllib 3 获得的 HTML。我们只想从 Google 主页中提取所有链接,所以我们将使用一个简单的 XPath 表达式 //a ,并使用 LXML 来运行它。LXML 是一个快速易用的 XML 和 HTML 处理库,支持 XPath。
安装 :
pip install lxml
下面是前面片段之后的代码:
from lxml import html
输出如下:
https://books.google.fr/bkshp?hl=fr&tab=wp
https://www.google.fr/shopping?hl=fr&source=og&tab=wf
https://www.blogger.com/?tab=wj
https://photos.google.com/?tab=wq&pageId=none
http://video.google.fr/?hl=fr&tab=wv
https://docs.google.com/document/?usp=docs_alc
...
https://www.google.fr/intl/fr/about/products?tab=wh
请记住,这个示例非常简单,并没有向你展示 XPath 有多强大。 (注意: 这个 XPath 表达式应该更改为 //a/@href 为了避免在 links 中迭代以获得它们的 href )。
如果你想了解更多关于 XPath 的知识,可以阅读这个很棒的介绍文档。这个 LXML 文档 也编写得很好,很适合基础阅读。.
XPath 表达式和 regexp 一样很强大,是从 HTML 中提取信息的最快方法之一。虽然 XPath 也像 regexp 一样很快就会变得凌乱,难以阅读和维护。
requests & BeautifulSoup(库)
gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==
image-17
下载量已经超过 11,000,000 次的 Requests 库是 Python 包中的佼佼者,它是 Python 使用最广泛的包。
安装:
pip install requests
使用 Requests 库发送一个请求是非常容易的事情:
import requests
使用 Requests 库可以很容易地执行 POST 请求、处理 cookie 和查询参数。
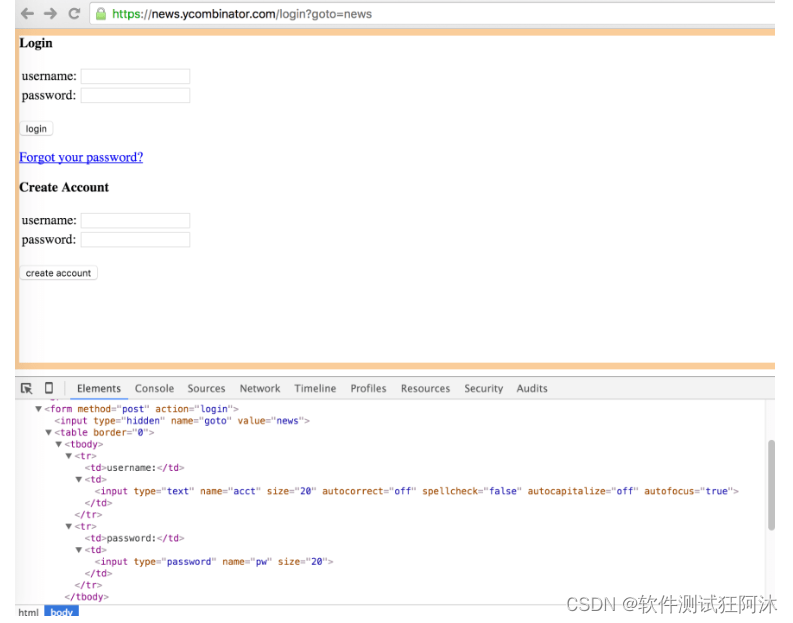
假设我们想要创建一个工具来自动提交我们的博客文章给 Hacker News 或任何其他论坛如 Buffer。在提交我们的链接之前,我们需要认证到这些网站。这就是我们要通过 Requests 和 BeautifulSoup 做的事情!
下面是 Hacker News 登录表单和相关的 DOM:
这个表单上有三个 标签。第一个带有 hidden 类型的名字为 “goto” 输入,另外两个是用户名和密码。
如果你在 Chrome 浏览器中提交表单,你会发现有很多事情发生:重定向和正在设置 cookie。这个 cookie 将由 Chrome 在每个后续请求上发送,以便服务器知道你已通过身份验证。
通过 Requests 来做这些工作将会变得非常简单,它将自动为我们处理重定向,而处理 cookie 则可以使用 _Session_Object 完成。
接下来我们需要的是 BeautifulSoup,它是一个 Python 库,它将帮助我们解析服务器返回的 HTML,以确定我们是否登录。
安装:
pip install beautifulsoup4
所以我们要做的就是通过 POST 请求将这三个带有我们登录凭证的输入发送到 /login 终端,并且验证一个只在登录成功时才出现的元素。
import requests
from bs4 import BeautifulSoup
BASE_URL = 'https://news.ycombinator.com'
USERNAME = ""
PASSWORD = ""
s = requests.Session()
data = {"gogo": "news", "acct": USERNAME, "pw": PASSWORD}
r = s.post(f'{BASE_URL}/login', data=data)
我们可以尝试提取主页上的每一个链接,以了解更多关于 BeautifulSoup 的信息。
顺便说一句,Hacker News 提供了一个功能强大的 API,所以我们这里只是以它为例,你真的应该直接使用 API,而不是爬取它! _
我们需要做的第一件事是观察分析Hacker News主页,以了解我们必须选择的结构和不同的 CSS 类。
我们可以看到所有的 posts 都在 里 ,因此,我们需要做的第一件事是选择所有这些标记。通过下面这行代码我们很容易实现:
links = soup.findAll('tr', class_='athing')
然后,对于每个链接,我们将提取其 ID、标题、url 和排名:
import requests
from bs4 import BeautifulSoup
r = requests.get('https://news.ycombinator.com')
soup = BeautifulSoup(r.text, 'html.parser')
links = soup.findAll('tr', class_='athing')
formatted_links = []
for link in links:
data = {
'id': link['id'],
'title': link.find_all('td')[2].a.text,
"url": link.find_all('td')[2].a['href'],
"rank": int(links[0].td.span.text.replace('.', ''))
}
formatted_links.append(data)
正如你所看到的,Requests 和 BeautifulSoup 是提取数据和自动化实现各种操作(如填写表单)的很好的库。如果你想做大规模的网络抓取项目,你仍然可以使用请求,但你需要自己处理很多事情。
在爬取大量网页的时候,你需要处理很多事情:
- 找到并行化代码的方法,使代码更高效
- 处理错误
- 存储爬取的数据
- 过滤和筛选数据
- 控制请求速度,这样就不会使服务器超载
- 幸运的是,我们可以使用工具处理所有这些事情。
Scrapy

scrapy 是一个强大的 Python Web 抓取框架。它提供了许多特性来异步下载、处理和保存网页。它处理多线程、爬行(从链接到查找网站中的每个URL的过程)、站点地图爬行等等。
Scrapy 还有一个名为 ScrapyShell 的交互模式。你可以使用 ScrapyShell 快速测试代码,比如 XPath 表达式或 CSS 选择器。
Scrapy 的缺点在于陡峭的学习曲线——有很多东西要学。
继续上述 Hacker News 的例子,我们将编写一个 ScrapySpider,它会抓取前 15 页的结果,并将所有内容保存在 CSV 文件中。
pip 安装 Scrapy:
pip install Scrapy
然后,你可以使用 scrapycli 生成项目的样板代码:
scrapy startproject hacker_news_scraper
在 hacker_news_scraper/spider 我们将使用Spider的代码创建一个新的 Python 文件:
from bs4 import BeautifulSoup
import scrapy
class HnSpider(scrapy.Spider):
name = "hacker-news"
allowed_domains = ["news.ycombinator.com"]
start_urls = [f'https://news.ycombinator.com/news?p={i}' for i in range(1,16)]
def parse(self, response):
soup = BeautifulSoup(response.text, 'html.parser')
links = soup.findAll('tr', class_='athing')
for link in links:
yield {
'id': link['id'],
'title': link.find_all('td')[2].a.text,
"url": link.find_all('td')[2].a['href'],
"rank": int(link.td.span.text.replace('.', ''))
}
Scrapy 中有很多规定,这里我们定义了一个启动 URL 数组。属性 name 将用于使用 Scrapy 命令行调用我们的 Spider。
数组中的每个 URL 调用解析方法。
然后,为了让我们的爬虫更好的在目标网站上爬数据,我们要对 Scrapy 进行微调。
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
AUTOTHROTTLE_ENABLED = True
# The initial download delay
AUTOTHROTTLE_START_DELAY = 5
你应该一直把这个爬虫程序一直运行着,它将通过分析响应时间和调整并发线程的数量来确保目标网站不会因为爬虫而负载过大。
你可以使用 ScrapyCLI 运行下面的代码并且设置不同的输出格式(CSV、JSON、XML等)。
scrapy crawl hacker-news -o links.json
类似于这样,最终爬取的结果会按照 json 的格式导出到一个名为 links 的 json 文件中
Selenium & Chrome —headless
对于大规模的网络抓取任务来说,Scrapy 是非常好的。但是,如果需要爬取用 JavaScript 框架编写的单页应用程序,这是不够的,因为它无法呈现 JavaScript 代码。
爬取这些 SPAs 是很有挑战性的,因为经常涉及很多 Ajax 调用和 WebSocket 连接。如果性能存在问题,你将不得不逐个复制 JavaScript 代码,这意味着使用浏览器检查器手动检查所有网络调用,并复制和你感兴趣的数据相关的 Ajax 调用。
在某些情况下,涉及到的异步 HTTP 调用太多,无法获取所需的数据,在 headless 模式的浏览器中呈现页面可能会更容易。
另一个很好的用例是对一个页面进行截图。这是我们将要对 Hacker News 主页做的事情(再次!)pip 安装 Selenium 包:
pip install selenium
你还需要 Chromedriver:
brew install chromedriver
然后,我们只需从 Selenium 包中导入 Webriver,配置 Chrome的Headless=True,并设置一个窗口大小(否则它非常小):
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
然后你应该得到一个很好的主页截图。

你可以使用 SeleniumAPI 和 Chrome 做更多的事情,比如:
- 执行 JavaScript
- 填写表单
- 点击元素
- 用 CSS 选择器或 XPath 表达式提取元素
Selenium 和 headless 模式下的 Chrome 简直是完美组合,能爬取到任何你想要爬取的数据。你可以将使用普通的 Chrome 浏览器所做的所有操作都设置为自动化。
Chrome 最大的缺点是需要大量的内存 /CPU 能力。通过一些微调,你可以将每个 Chrome 实例的内存占用减少到 300-400MB,但每个实例仍然需要一个 CPU 核心。
如果你想同时运行多个 Chrome 实例,你将需要强大的服务器(其成本迅速上升),以及持续监视资源。
总结
我希望这个概述将帮助你选择你的 Python 抓取工具,并希望你通过本文能有所收获。
我在这篇文章中所介绍的工具都是我在做自己的项目 ScrapingNinja 时用过的,这个项目很简单的网络爬虫 API。
这篇文章中提及的每一个工具,我之后都会单独写一篇博客来进行深入阐述其细节。
不要犹豫,在评论中告诉我你还想知道关于爬虫的哪些知识。我将会在下一篇文章中进行讲解分析。