CLIP模型
CLIP(Contrastive Language-Image Pre-Training) 模型是 OpenAI 在 2021 年初发布的用于匹配图像和文本的预训练神经网络模型,是近年来在多模态研究领域的经典之作。OpenAI 收集了 4 亿对图像文本对(一张图像和它对应的文本描述),分别将文本和图像进行编码,使用 metric learning进行训练。希望通过对比学习,模型能够学习到文本-图像对的匹配关系。
CLIP的论文地址
CLIP模型共有3个阶段:1阶段用作训练,2、3阶段用作推理。
- Contrastive pre-training:预训练阶段,使用图片 - 文本对进行对比学习训练;
- Create dataset classifier from label text:提取预测类别文本特征;
- Use for zero-shot predictiion:进行 Zero-Shot 推理预测;
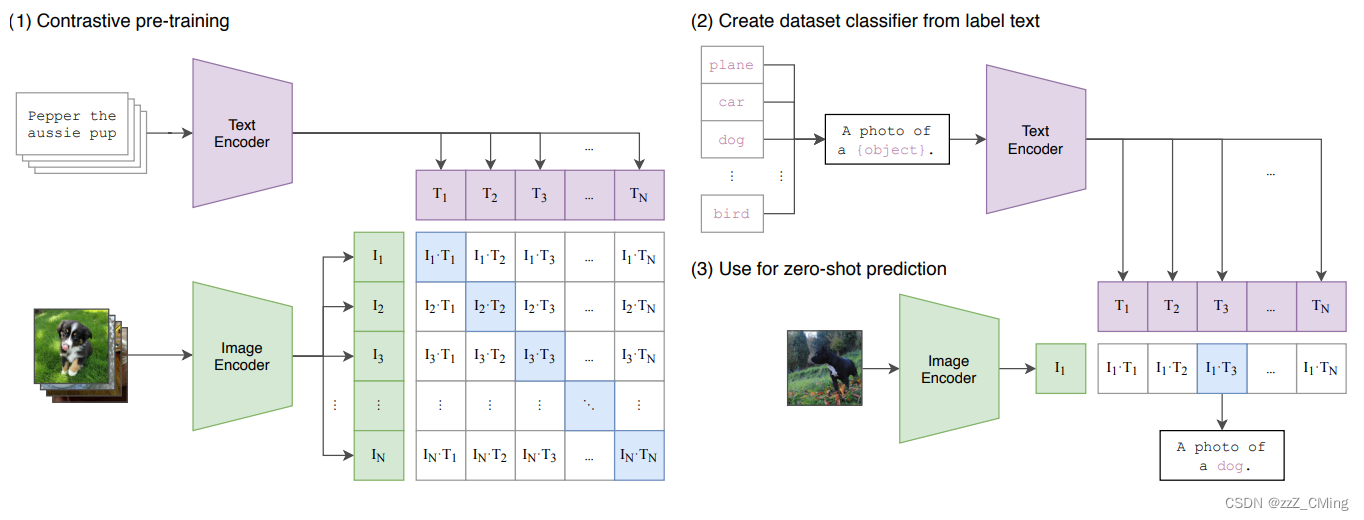
1、训练阶段
通过计算文本和目标图像的余弦相似度从而获取预测值。CLIP模型主要包含以下两个模型;
- Text Encoder:用来提取文本的特征,可以采用NLP中常用的text transformer模型;
- Image Encoder:用来提取图像的特征,可以采用常用CNN模型或者vision transformer模型;
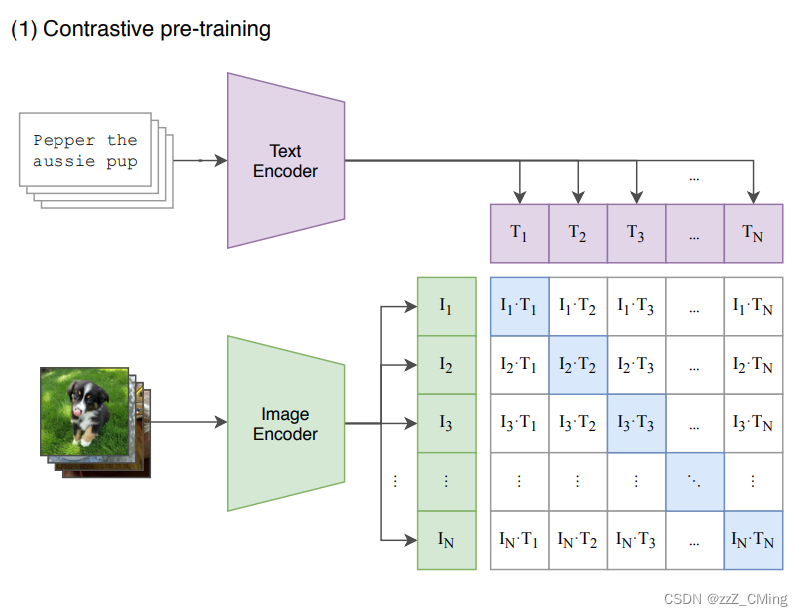
这里举例一个包含N个文本-图像对的训练batch,对提取的文本特征和图像特征进行训练的过程:
- 输入图片 —> 图像编码器 —> 图片特征向量;输入文字 —> 文字编码器 —> 文字特征向量;并进行线性投射,得到相同维度;
- 将N个文本特征和N个图像特征两两组合,形成一个具有N2个元素的矩阵;
- CLIP模型会预测计算出这N2个文本-图像对的相似度(文本特征和图像特征的余弦相似性即为相似度);
- 对角线上的N个元素因为图像-标签对应正确被作为训练的正样本,剩下的N2-N个元素作为负样本;
- CLIP的训练目标就是最大化N个正样本的相似度,同时最小化N2-N个负样本的相似度;
2、推理过程
CLIP的预测推理过程主要有以下两步:
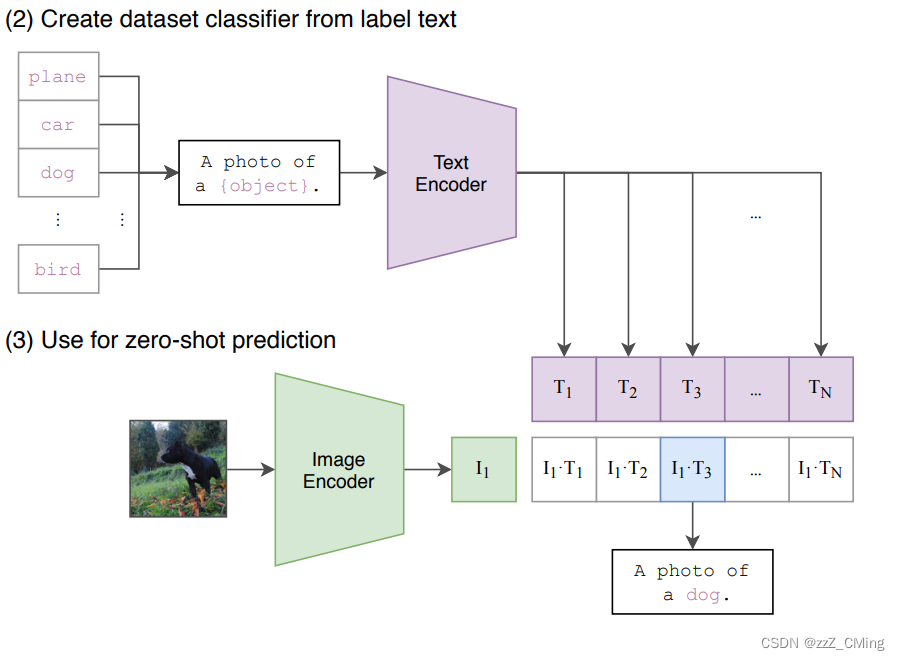
- 提取预测类别的文本特征:由于CLIP 预训练文本端的输出输入都是句子,因此需要将任务的分类标签按照提示模板 (prompt template)构造成描述文本(由单词构造成句子):
A photo of {object}.,然后再送入Text Encoder得到对应的文本特征。如果预测类别的数目为N,那么将得到N个文本特征。 - 进行 zero-shot 推理预测:将要预测的图像送入Image Encoder得到图像特征,然后与上述的N个文本特征计算余弦相似度(和训练过程一致),然后选择相似度最大的文本对应的类别作为图像分类预测结果。进一步地,可以将这些相似度看成输入,送入softmax后可以得到每个类别的预测概率。
3、补充:zero-shot 零样本学习
zero-shot :零样本学习,域外泛化问题。利用训练集数据训练模型,使得模型能够对测试集的对象进行分类,但是训练集类别和测试集类别之间没有交集,期间需要借助类别的描述,来建立训练集和测试集之间的联系,从而使得模型有效。
可以发现CLIP其实就是两个模型:视觉模型 + 文本模型。
在计算机视觉中,即便想迁移VGG、MobileNet这种预训练模型,也需要经过预训练、微调等手段,才能学习数据集的数据特征,而CLIP可以直接实现zero-shot的图像分类,即不需要任何训练数据,就能在某个具体下游任务上实现分类,这也是CLIP亮点和强大之处。
我的猜测:CLIP的zero-shot能力是依赖于它预训练的4亿对图像-文本对,样本空间涵盖的太大,并不是真正的零样本学习,和解决域外泛化问题。和人脸比对的原理相似,依靠大量样本来学习分类对象的特征空间。人脸比对是image-to-image,CLIP是 image-to-text。
4、代码: CLIP实现zero-shot分类
OpenAI有关CLIP的代码链接地址
环境:
pip install ftfy regex tqdm
pip install git+https://github.com/openai/CLIP.git
Torch version: 1.9.0+cu102
4.1、模型加载
import clip
clip.available_models()
model, preprocess = clip.load("ViT-B/32")
model.cuda().eval()
input_resolution = model.visual.input_resolution
context_length = model.context_length
vocab_size = model.vocab_size
print("Model parameters:", f"{np.sum([int(np.prod(p.shape)) for p in model.parameters()]):,}")
print("Input resolution:", input_resolution)
print("Context length:", context_length)
print("Vocab size:", vocab_size)
4.2、图像、文本数据处理
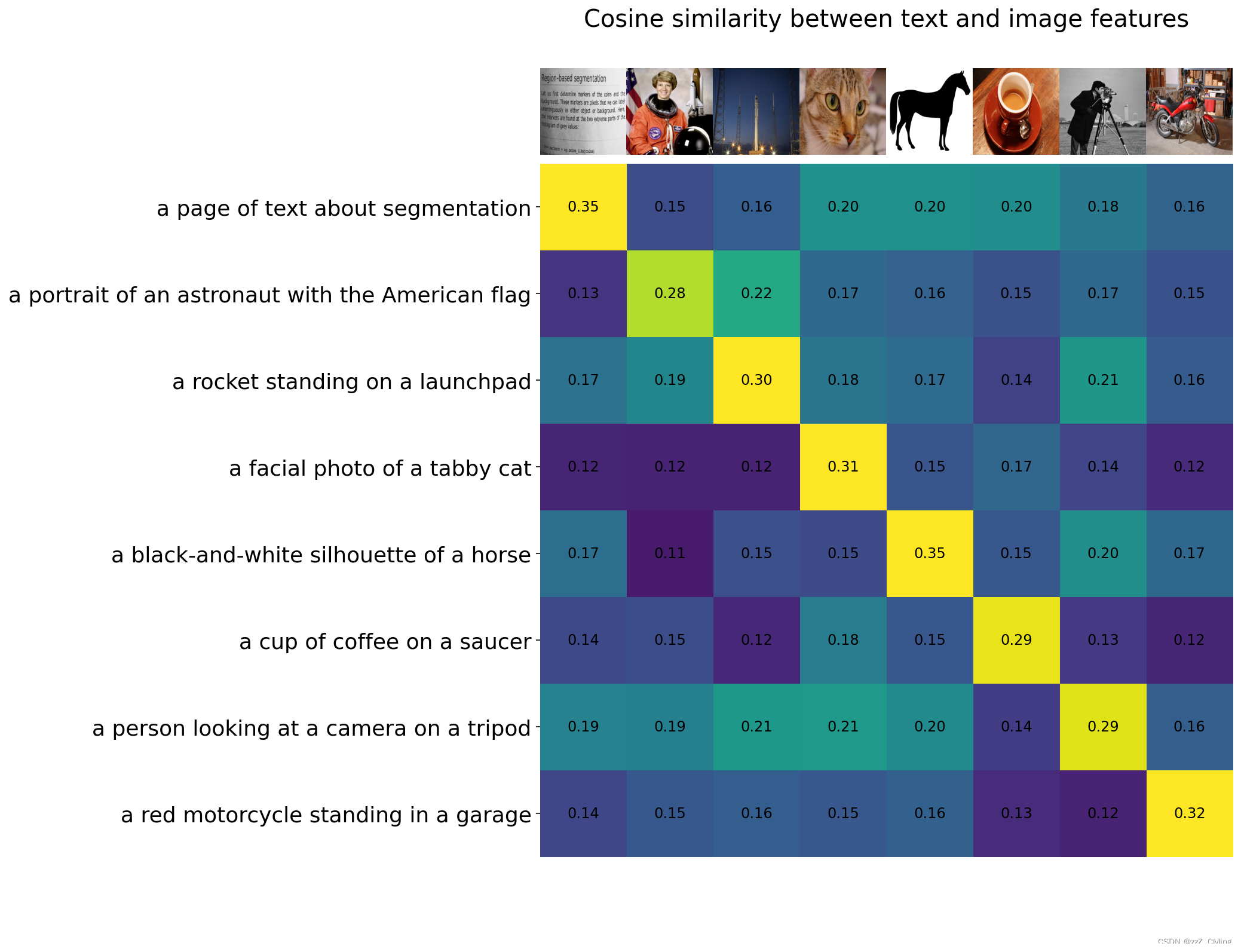
向模型提供8个示例图像及其文本描述,并比较相应特征之间的相似性
# images in skimage to use and their textual descriptions
descriptions = {
"page": "a page of text about segmentation",
"chelsea": "a facial photo of a tabby cat",
"astronaut": "a portrait of an astronaut with the American flag",
"rocket": "a rocket standing on a launchpad",
"motorcycle_right": "a red motorcycle standing in a garage",
"camera": "a person looking at a camera on a tripod",
"horse": "a black-and-white silhouette of a horse",
"coffee": "a cup of coffee on a saucer"
}

4.3、建立图片特征
对图像进行归一化,对每个文本输入进行标记,并运行模型的前向传递以获得图像和文本特征
image_input = torch.tensor(np.stack(images)).cuda()
text_tokens = clip.tokenize(["This is " + desc for desc in texts]).cuda()
with torch.no_grad():
image_features = model.encode_image(image_input).float()
text_features = model.encode_text(text_tokens).float()
4.4、计算余弦相似度
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = text_features.cpu().numpy() @ image_features.cpu().numpy().T
count = len(descriptions)
plt.figure(figsize=(20, 14))
plt.imshow(similarity, vmin=0.1, vmax=0.3)
# plt.colorbar()
plt.yticks(range(count), texts, fontsize=18)
plt.xticks([])
for i, image in enumerate(original_images):
plt.imshow(image, extent=(i - 0.5, i + 0.5, -1.6, -0.6), origin="lower")
for x in range(similarity.shape[1]):
for y in range(similarity.shape[0]):
plt.text(x, y, f"{similarity[y, x]:.2f}", ha="center", va="center", size=12)
for side in ["left", "top", "right", "bottom"]:
plt.gca().spines[side].set_visible(False)
plt.xlim([-0.5, count - 0.5])
plt.ylim([count + 0.5, -2])
plt.title("Cosine similarity between text and image features", size=20)
4.5、Zero-Shot图像分类
from torchvision.datasets import CIFAR100
cifar100 = CIFAR100(os.path.expanduser("~/.cache"), transform=preprocess, download=True)
text_descriptions = [f"This is a photo of a {label}" for label in cifar100.classes]
text_tokens = clip.tokenize(text_descriptions).cuda()
with torch.no_grad():
text_features = model.encode_text(text_tokens).float()
text_features /= text_features.norm(dim=-1, keepdim=True)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
top_probs, top_labels = text_probs.cpu().topk(5, dim=-1)
plt.figure(figsize=(16, 16))
for i, image in enumerate(original_images):
plt.subplot(4, 4, 2 * i + 1)
plt.imshow(image)
plt.axis("off")
plt.subplot(4, 4, 2 * i + 2)
y = np.arange(top_probs.shape[-1])
plt.grid()
plt.barh(y, top_probs[i])
plt.gca().invert_yaxis()
plt.gca().set_axisbelow(True)
plt.yticks(y, [cifar100.classes[index] for index in top_labels[i].numpy()])
plt.xlabel("probability")
plt.subplots_adjust(wspace=0.5)
plt.show()