从数据处理的方式角度:
流式: 一条数据一条数据的处理
微批量: 一小批一小批的处理
批量: 一批数据一批数据的处理(Spark)
从数据处理的延迟角度
离线: 数据处理的延迟是以小时,天为单位
准(近)实时: 以秒为单位
实时:延迟以毫秒为单位,
Spark是一个批量数据处理的离线数据分析框架
为了适应实时分析的场景,创建新功能模块,SparkStreaming
SparkStreaming 微批次 准实时
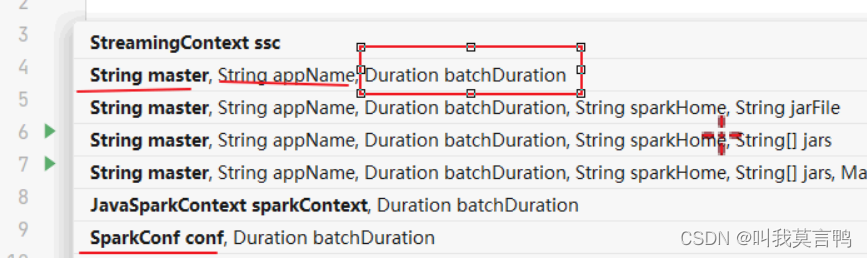
批量多少才可以
采用时间范围来接收数据批次
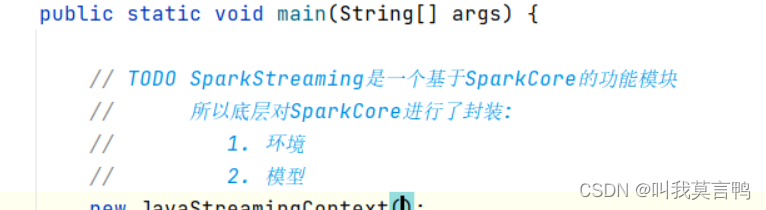
使用新模块是对SparkCore的封装的功能模块
ctrl+p 提示
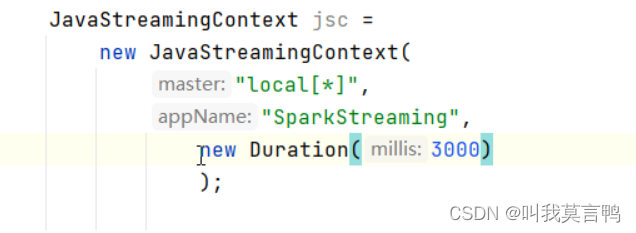
持续时间duration
采集周期
SparkStreaming需要采集器,周期性采集数据
jsc.awaitTermination 等待采集器结束,
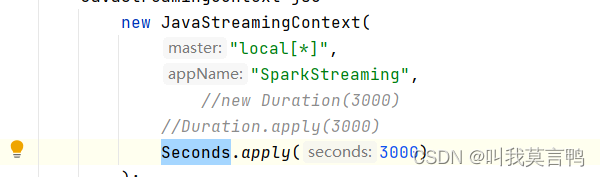
设置为3000秒一个周期


rdd.collect从exector采集到Driver端的内存中
dstream.print
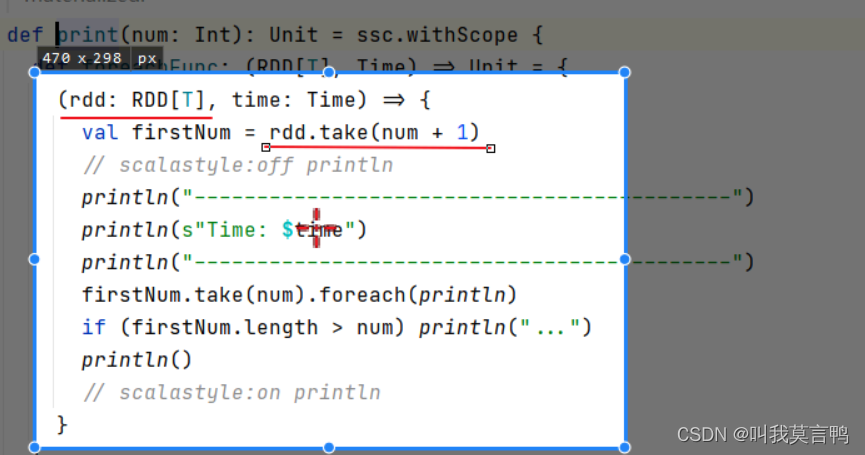
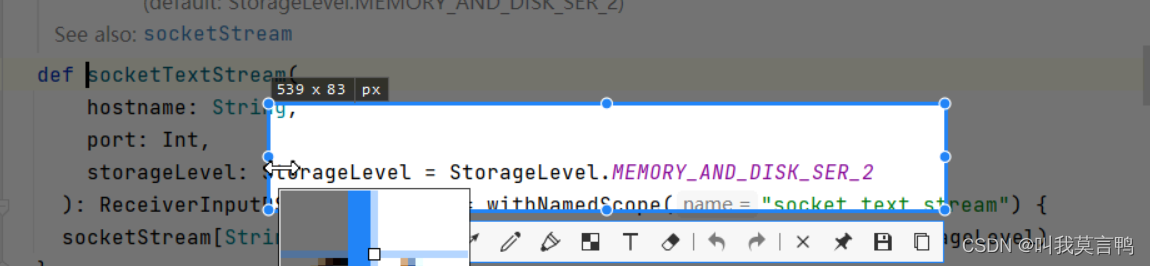
默认存储方式为内存+磁盘 2个副本
一般不会采用socket接收数据
因为如果速率不一致, 处理太慢,就会产生数据积压,那么就需要一个缓冲区了,这时候,就需要Kafka了
为什么不用flume
1.flume的应用面窄 而Kafka是个消息传输队列系统
2.flume是单点消峰,每个机器都得装一个flume,无法分布式,性能不如Kafka
Kafka是集群 而Flume是单点, 无法集中管理
](https://img-blog.csdnimg.cn/9bc2e13e15f44887a761b2b34e5e01ad.png)
所以Kafka再传输数据时最重要的是V
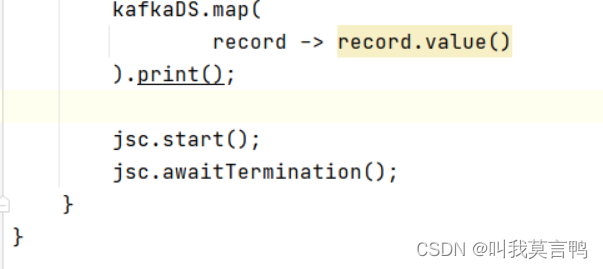

RDD的方法才叫算子
而DStream的方法不叫算子,叫做原语
Spark可以将一个范围的数据采集后,再进行计算,这个采集的范围,称之为窗口。
采集范围不是采集周期 采集范围是采集周期的整数倍
滑动窗口
滑窗计算

范围大小: 方框大小
滑动幅度:每次移动的距离
窗口处理过程中,根据窗口滑动幅度的不同,存在不同的类型,
什么是不同的类型?
- 滑动幅度小于窗口范围: 重复数据 就会存在重复数据 统计结果比实际数据多
- 滑动幅度等于窗口范围: 滚动窗口 数据结构与实际结果一致
- 滑动幅度大于窗口范围: 不会重复数据,但会丢失数据,统计结果小于实际数据
SparkStreaming数据的计算时间点为滑动时间点。滑动一次算一次。
也就是说,如果不专门设置滑动窗口,默认滑动窗口与采集时间一致。
sparkcore 和 sparksql对的都是有界数据流
而无界数据流是临时保存,所以必须要有输出。
Save和Print 或者转换成RDD调用行动算子
时间戳只有print方法才有
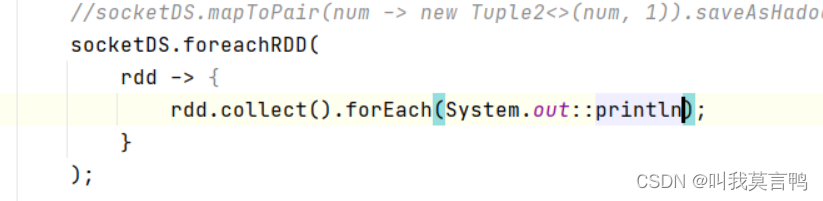
采集器一般不停止运行,但是特殊场景需要停止后重新启动(如业务升级)
停一般不再Main调用,而是创建新线程完成调用
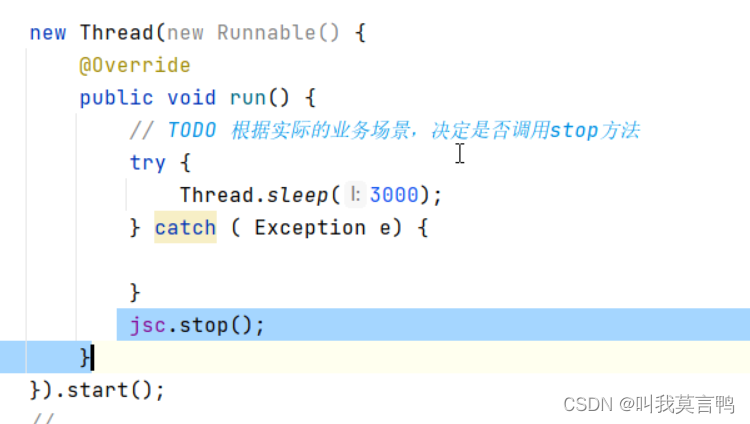
优雅关闭: 不接收新请求,但是将当前数据处理完,而不是打断丢失数据

多加了参数
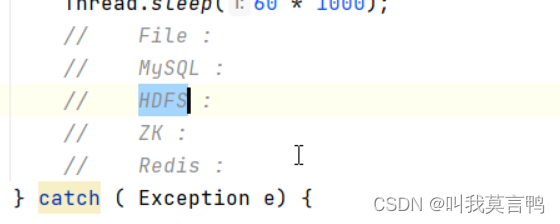
通过临时存储中修改特定文件的内容来开关
为什么需要另开一个线程来关闭
为了给他一些处理消息的时间,而不是直接就关闭



![2023年中国气体压缩机市场规模及产量分析[图]](https://img-blog.csdnimg.cn/img_convert/e08b1706503e2d39716bdb6504f0e32b.png)