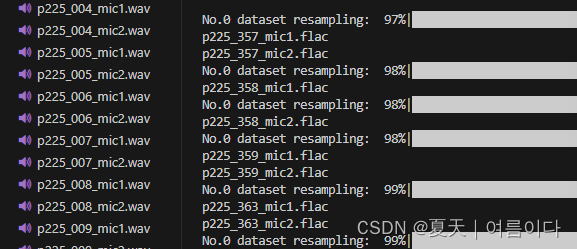
把flac结尾的,替换为wav文件,然后对wav文件进行重采样(48000->22050),可以更换采样率,运行后保存为新的地址,所有文件都在同一文件夹下(保证能运行)。
# 把flac结尾的,替换为wav文件,然后对wav文件进行重采样(48000->22050)
## 运行后保存为新的地址,所有文件都在同一文件夹下
import os
import librosa
import tqdm
import soundfile as sf
if __name__ == '__main__':
audioExt = 'flac'
outputExt = 'wav'
input_sample = 48000
output_sample = 22050
audioDirectory = ['语音文件夹路径']
outputDirectory = [ '保存到新的文件夹的路径']
for i, dire in enumerate(audioDirectory):
# 寻找"directory"文件夹中,格式为“ext”的音频文件,返回值为绝对路径的列表类型
clean_speech_paths = librosa.util.find_files(
directory=dire,
ext=audioExt,
recurse=True,
)
for file in tqdm.tqdm(clean_speech_paths, desc='No.{} dataset resampling'.format(i)):
fileName = os.path.basename(file)
print(fileName)
if audioExt in fileName:
fileName=fileName.replace(audioExt,outputExt)
y, sr = librosa.load(file, sr=input_sample)
y_16k = librosa.resample(y, orig_sr=sr, target_sr=output_sample)
outputFileName = os.path.join(outputDirectory[i], fileName)
sf.write(outputFileName, y_16k, output_sample)
结果
![2023年中国气体压缩机市场规模及产量分析[图]](https://img-blog.csdnimg.cn/img_convert/e08b1706503e2d39716bdb6504f0e32b.png)