深度学习——深度卷积神经网络(AlexNet)
文章目录
- 前言
- 一、学习表征
- 二、AlexNet实现
- 2.1. 模型设计
- 2.2. 激活函数
- 2.3. 容量控制与预处理
- 2.4. 训练模型
- 总结
前言
在前面学习了卷积神经网络的基本原理,之后将继续学习现代卷积神经网络架构。而本章将学习其中的AlexNet模型。
参考书:
《动手学深度学习》
一、学习表征
在2012年前,图像特征都是机械地计算出来的。事实上,设计一套新的特征函数、改进结果,并撰写论文是盛极一时的潮流。SIFT 、SURF、HOG(定向梯度直方图)、bags of visual words和类似的特征提取方法占据了主导地位。
有一组研究人员,想法则与众不同:他们认为特征本身应该被学习。此外,他们还认为,在合理地复杂性前提下,特征应该由多个共同学习的神经网络层组成,每个层都有可学习的参数。在机器视觉中,最底层可能检测边缘、颜色和纹理。
事实上,Alex Krizhevsky、Ilya Sutskever和Geoff Hinton提出了一种新的卷积神经网络变体AlexNet。在2012年ImageNet挑战赛中取得了轰动一时的成绩。
AlexNet的更高层建立在这些底层表示的基础上,以表示更大的特征,如眼睛、鼻子、草叶等等。而更高的层可以检测整个物体,如人、飞机、狗或飞盘。最终的隐藏神经元(位于全连接层)可以学习图像的综合表示,从而使属于不同类别的数据易于区分。
二、AlexNet实现
AlexNet和LeNet的架构非常相似,AlexNet使用了8层卷积神经网络,并以很大的优势赢得了2012年ImageNet图像识别挑战赛。
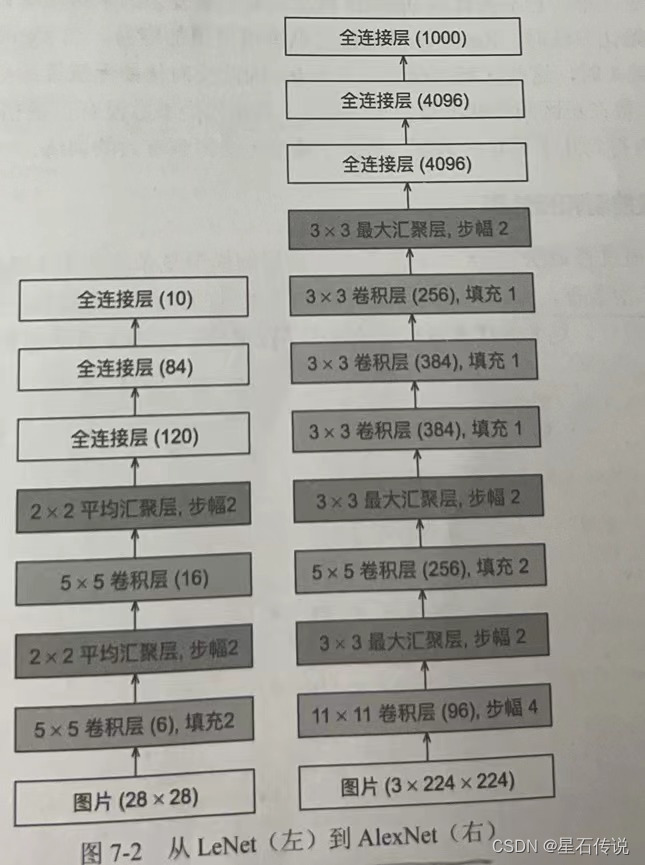
AlexNet和LeNet的设计理念非常相似,但也存在显著差异:
-
AlexNet比相对较小的LeNet5要深得多。AlexNet由八层组成:五个卷积层、两个全连接隐藏层和一个全连接输出层。
-
AlexNet使用ReLU而不是sigmoid作为其激活函数。
2.1. 模型设计
在AlexNet的第一层,卷积窗口的形状是 11 × 11 11\times11 11×11。
由于ImageNet中大多数图像的宽和高比MNIST图像的多10倍以上,因此,需要一个更大的卷积窗口来捕获目标。
第二层中的卷积窗口形状被缩减为 5 × 5 5\times5 5×5,然后是 3 × 3 3\times3 3×3。
此外,在第一层、第二层和第五层卷积层之后,加入窗口形状为
3
×
3
3\times3
3×3、步幅为2的最大汇聚层。
而且,AlexNet的卷积通道数目是LeNet的10倍。
在最后一个卷积层后有两个全连接层,分别有4096个输出。
这两个巨大的全连接层拥有将近1GB的模型参数。
由于早期GPU显存有限,原版的AlexNet采用了双数据流设计,使得每个GPU只负责存储和计算模型的一半参数。
2.2. 激活函数
AlexNet将sigmoid激活函数改为更简单的ReLU激活函数。
- 一方面,ReLU激活函数的计算更简单,它不需要如sigmoid激活函数那般复杂的求幂运算。
- 另一方面,当使用不同的参数初始化方法时,ReLU激活函数使训练模型更加容易。
当sigmoid激活函数的输出非常接近于0或1时,这些区域的梯度几乎为0,因此反向传播无法继续更新一些模型参数。
相反,ReLU激活函数在正区间的梯度总是1。
2.3. 容量控制与预处理
AlexNet通过暂退法控制全连接层的模型复杂度,而LeNet只使用了权重衰减。
为了进一步扩充数据,AlexNet在训练时增加了大量的图像增强数据,如翻转、裁切和变色。这使得模型更健壮,更大的样本量有效地减少了过拟合。
代码生成模型架构:
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
#开始使用一个11×11的卷积窗口来捕获对象,同时步幅为4,以减少输出的宽度和高度
nn.Conv2d(1,96,kernel_size=11,stride=4,padding=1),nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2),
#减小卷积窗口,使用填充为2来使输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96,256,kernel_size=5,padding=2),nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2),
#使用3个连续的卷积层和较小的卷积窗口
nn.Conv2d(256,384,kernel_size=3,padding=1),nn.ReLU(),
nn.Conv2d(384,384,kernel_size=3,padding=1),nn.ReLU(),
nn.Conv2d(384,256,kernel_size=3,padding=1),nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2),
#展平数据,即展开成一个向量
nn.Flatten(),
#这里,全连接层的输出数量太多,使用暂退层来缓解过拟合
nn.Linear(6400,4096),nn.ReLU(),
nn.Dropout(p=0.5), #有50%的概率在训练过程中将特征随机置为0
nn.Linear(4096,4096),nn.ReLU(),
nn.Dropout(p=0.5),
#最后的输出层,因为我们使用的是Fashion-MNIST,所以类别数为10,而非论文中的1000
nn.Linear(4096,10)
)
#构造一个高度和宽度都为224的单通道数据,来观察每一层输出的形状
X = torch.randn(1,1,224,224)
for layer in net:
X = layer(X)
print(layer.__class__.__name__,"输出形状为:\t", X.shape)
#结果:
Conv2d 输出形状为: torch.Size([1, 96, 54, 54])
ReLU 输出形状为: torch.Size([1, 96, 54, 54])
MaxPool2d 输出形状为: torch.Size([1, 96, 26, 26])
Conv2d 输出形状为: torch.Size([1, 256, 26, 26])
ReLU 输出形状为: torch.Size([1, 256, 26, 26])
MaxPool2d 输出形状为: torch.Size([1, 256, 12, 12])
Conv2d 输出形状为: torch.Size([1, 384, 12, 12])
ReLU 输出形状为: torch.Size([1, 384, 12, 12])
Conv2d 输出形状为: torch.Size([1, 384, 12, 12])
ReLU 输出形状为: torch.Size([1, 384, 12, 12])
Conv2d 输出形状为: torch.Size([1, 256, 12, 12])
ReLU 输出形状为: torch.Size([1, 256, 12, 12])
MaxPool2d 输出形状为: torch.Size([1, 256, 5, 5])
Flatten 输出形状为: torch.Size([1, 6400])
Linear 输出形状为: torch.Size([1, 4096])
ReLU 输出形状为: torch.Size([1, 4096])
Dropout 输出形状为: torch.Size([1, 4096])
Linear 输出形状为: torch.Size([1, 4096])
ReLU 输出形状为: torch.Size([1, 4096])
Dropout 输出形状为: torch.Size([1, 4096])
Linear 输出形状为: torch.Size([1, 10])
手写计算:

2.4. 训练模型
将AlexNet直接应用于Fashion-MNIST的一个问题是,[Fashion-MNIST图像的分辨率](28×28像素)
(低于ImageNet图像。) 为了解决这个问题,(我们将它们增加到224×224)
(通常来讲这不是一个明智的做法,但在这里这样做是为了有效使用AlexNet架构)
#读取数据集
batch_size = 128
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size,resize=224)
#训练
lr,num_epochs = 0.01,10
d2l.train_ch6(net,train_iter,test_iter,num_epochs,lr,d2l.try_gpu())
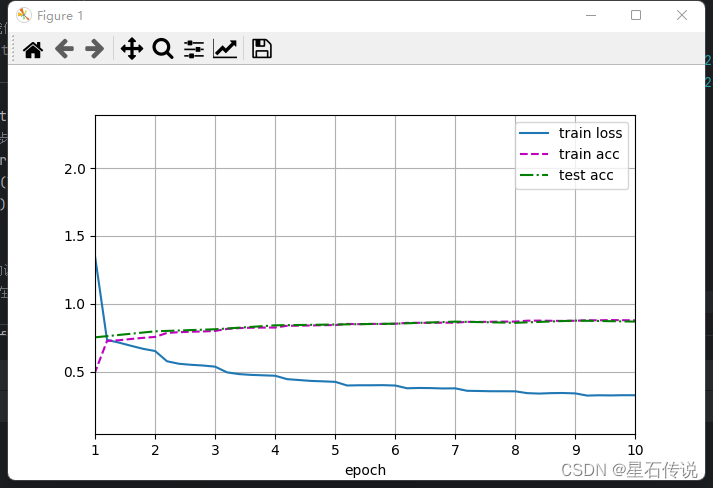
d2l.plt.show()
#结果:
loss 0.328, train acc 0.879, test acc 0.870
26.0 examples/sec on cpu
总结
AlexNet的架构与LeNet相似,但使用了更多的卷积层和更多的参数来拟合大规模数据集。虽然它已经被更有效的架构所超越,但它是从浅层网络到深层网络的关键一步。
Dropout、ReLU和预处理是提升计算机视觉任务性能的其他关键步骤。
是以圣人不行而知,不见而明,不为而成。
–2023-10-14 进阶篇