这个标题很大,但是落点很小,只是我,一个开发者在学习和使用 hooks 中的一点感受和总结。
React hook 的由来
React hook 的由来,其实也可以看作是前端技术不断演进的结果。
在 world wide web 刚刚诞生的洪荒时代,还没有 js,Web 页面也都是静态的,更没有所谓的前端工程师,页面的内容与更新完全由后端生成。这就使得页面的任意一点更新,都要刷新页面由后端重新生成,体验非常糟糕。随后就有了 Brendan 十天创世、网景微软浏览器之争、HTML 的改进、W3C 小组的建立等等。
后来 ajax 技术被逐渐重视,页面按钮提交/获取信息终于不用再刷新页面了,交互体验升级。随后又迎来了 jquery 的时代,可以方便地操作 DOM 和实现各种效果,大大降低了前端门槛。前端队伍的壮大,也催生了越发复杂的交互,Web page 也逐渐向着 Web App 的方向进化。
jquery 可以将一大段的 HTML 结构的字符串通过 . h t m l 、 .html、 .html、.append、$.before 的方式插入到页面上,虽然可以帮助我们以更舒服的方式来操作 DOM,但不能从根本上解决当 DOM 操作量过多时的前端侧压力大的问题。
随着页面内容和交互越来越复杂,如何解决这些繁琐、巨量的 DOM 操作带来的前端侧压力的问题,并能够把各个 HTML 分散到不同的文件中,然后根据实际情况渲染出相应的内容呢?
这时候的前端们借鉴了后端技术,归纳出一个公式:html = template(data),也就带来了模板引擎方案。模板引擎方案倾向于点对点地解决繁琐 DOM 操作问题,它并没有也不打算替换掉 jquery,两者是共存的。
随后陆续诞生了不少模板引擎,像 handlebars、Mustache 等等。无论是选用了哪种模板引擎,都离不开 html = template(data) 的模式,模板引擎的本质都是简化了拼接字符串的过程,通过类 HTML 的语法快速搭建起各种页面结构,通过变更数据源 data 来对同一个模板渲染出不同的效果。
这成就了模板引擎,但也限制住了它,它立足于「实现高效的字符串拼接」,但也局限于此,你不能指望模板引擎去做太复杂的事情。早期的模板引擎在性能上也不如人意,由于不够智能,它更新 DOM 的方式是将已经渲染好的 DOM 注销,然后重新渲染,如果操作 DOM 频繁,体验和性能都会有问题。
虽然模板引擎有其局限性,但是 html=template(data) 的模式还是很有启发性,一批前端先驱也许是从中汲取了灵感,决定要继续在 「数据驱动视图」的方向上深入摸索。模板引擎的问题在于对真实 DOM 的修改过于粗暴,导致了 DOM 操作的范围太大,进而影响了性能。
既然真实的 DOM 性能耗费太大了,那操作假的 DOM 好了。既然修改的范围太大,那每次修改的范围变小。
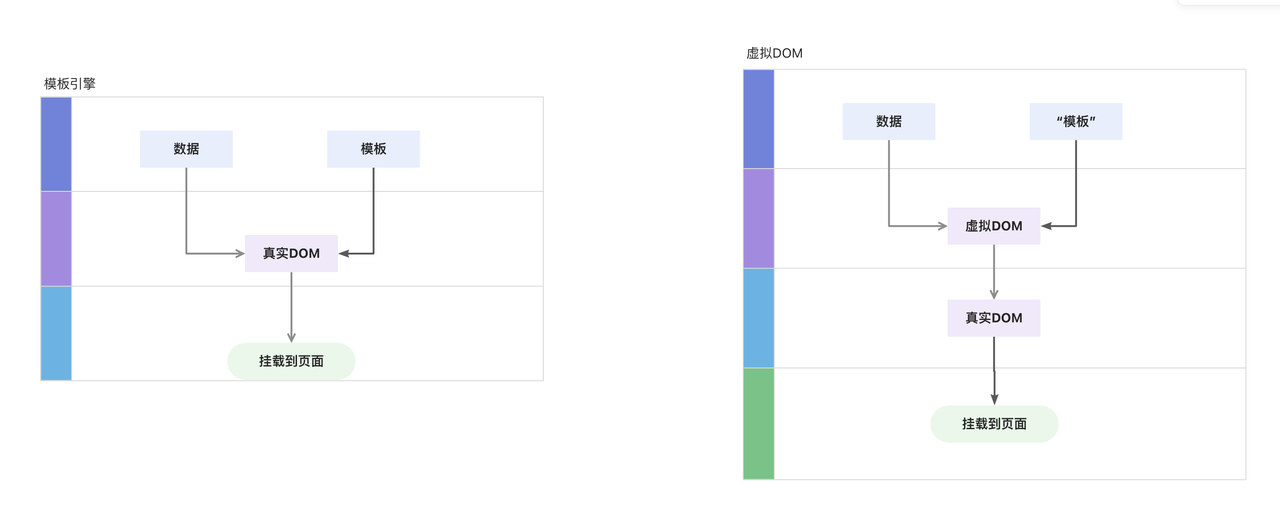
于是,模板引擎方案中的本来是“数据+模板”形成真实 DOM 的过程中加入了虚拟 DOM 这一层。
注意上图, 右侧的“模板”是打引号的,因为这里不一定是真的模板,起到类似模板的作用即可。比如 JSX 并不是模板,只是一种类似模板语法的 js 拓展,它拥有完全的 js 能力。加入了虚拟 DOM 这一层后,能做的事情就很多了,首先是可以 diff,也可以实现同一套代码跨平台了。
现在假的 DOM 有了,通过 diff(找不同)+ patch(使一致)的协调过程,也可以一种较为精确地方式修改 DOM 了。我们来到了 15.x 版本的 React。
我们这时候有了 class 组件,有了函数式组件,但是为什么还需要加入 hook 呢?
官方的说法是这样的:
- 在组件之间复用状态逻辑很难
- 复杂组件变得难以理解
- 难以理解的 class
诚然这些都是 class 的痛点所在,我们在使用 class 编写一个简单组件会遇到哪些问题:
- 难以琢磨的 this
- 关联的逻辑被拆分
- 熟练记忆众多的生命周期,在合适的生命周期里做适当的事情
- 代码量相对更多,尤其是写简单组件时
class FriendStatus extends React.Component {
constructor(props) {
super(props);
this.state = { isOnline: null };
this.handleStatusChange = this.handleStatusChange.bind(this); // 要手动绑定this
}
componentDidMount() {
ChatAPI.subscribeToFriendStatus( // 订阅和取消订阅逻辑的分散
this.props.friend.id,
this.handleStatusChange
);
}
componentWillUnmount() { // 要熟练记忆并使用各种生命周期,在适当的生命周期里做适当的事情
ChatAPI.unsubscribeFromFriendStatus(
this.props.friend.id,
this.handleStatusChange
);
}
handleStatusChange(status) {
this.setState({
isOnline: status.isOnline
});
}
render() {
if (this.state.isOnline === null) {
return 'Loading...';
}
return this.state.isOnline ? 'Online' : 'Offline';
}
}
React 的理念表达 UI = f(data) 中, React 组件的定位也更像是函数,像上面的示例其实就是 UI = render(state),关键的是 render 方法,其余的都是些通过 this 传参和一些外围支持函数。
针对上述问题,React 决定给函数组件带来新的能力。
过去的函数组件都是无状态组件,它们只能被动从外部接受数据。我希望组件在更新后仍旧保留我上次输入的值或者选中与否的状态,这些值或者状态最终会反应到宿主实例上(对浏览器来说就是 DOM)展示给用户,这是太常见的需求了。为了实现这种维护自身局部状态的功能,React 给函数组件绑定了一个局部状态。
这种绑定局部状态的方式,就是 React hook useState。
React 为了让函数能够更好地构建组件,还使用了很多特性来增强函数,绑定局部状态就是这些增强函数的特性之一。
所谓 React hook,就是这些增强函数组件能力特性的钩子,把这些特性「钩」进纯函数。 纯函数组件可以通过useState获得绑定局部状态的能力,通过useEffect来获得页面更新后执行副作用的能力,甚至通过你的自定义 hook useCounter 来获得加、减数值、设置数值、重置计数器等一整套管理计数器的逻辑。这些都是 hook 所赋予的能力。
React 官方说没有计划将 Class 从 React 中移除,但现在重心在增强函数式组件上。作为开发者的我们,只要还在使用 React,就无法完全拒绝 hooks。
虽然 hooks 并不完美,也有很多人吐槽,我们尝试去拥抱它吧。
React hook 的实现
前面我们提到了,React hook 是有益于构建 UI 的一系列特性,是用来增强函数式组件的。更具体的来说,hook 是一类特殊的函数。那么这类增强普通无状态组件的特殊函数究竟是何方神圣?我们既然要探寻 hook,就绕不开它的实现原理。
我们拿 useState 为例,它是怎么做到在一次次函数组件被执行时,保持住过去的 state 呢?
虽然源码是复杂的,但原理可能是简单的。简单地说,之所以能保持住 state,是在一个函数组件之外的地方,保存了一个「对象」,这个对象里记录了之前的状态。
那究竟如何实现?我们从一段简略版的useState的实现里来一窥究竟。
首先我们是这么用 useState 的:
function App () {
const [num, setNum] = useState(0);
const [age, setAge] = useState(18);
const clickNum = () => {
setNum(num => num + 1);
// setNum(num => num + 1); // 是可能调用多次的
}
const clickAage = () => {
setNum(age => age + 3);
// setNum(num => num + 1); // 是可能调用多次的
}
return <div>
<button onClick={clickNum}>num: {num}</button>
<button onClick={clickAage}>age:{age}</button>
</div>
}
因为 jsx 需要 babel 的支持,我们的简略版 demo 为了 UI 无关更简单的展示、使用 useState,我们将上述常见使用方式稍稍改造为:
当执行了 App() 时,将返回一个对象,我们调用对象的方法,就是模拟点击。
function App () {
const [num, setNum] = useState(0);
const [age, setAge] = useState(10);
console.log(isMount ? '初次渲染' : '更新');
console.log('num:', num);
console.log('age:', age);
const clickNum = () => {
setNum(num => num + 1);
// setNum(num => num + 1); // 是可能调用多次的
}
const clickAge = () => {
setAge(age => age + 3);
// setNum(num => num + 1); // 是可能调用多次的
}
return {
clickNum,
clickAge
}
}
那我们就从这个函数开始。
首先,组件要挂载到页面上,App 函数肯定是需要执行的。执行一开始,我们就遇到了 useState 这个函数。现在请暂时忘记 useState 是个 React hook, 它只是一个函数,跟其他函数没有任何不同。
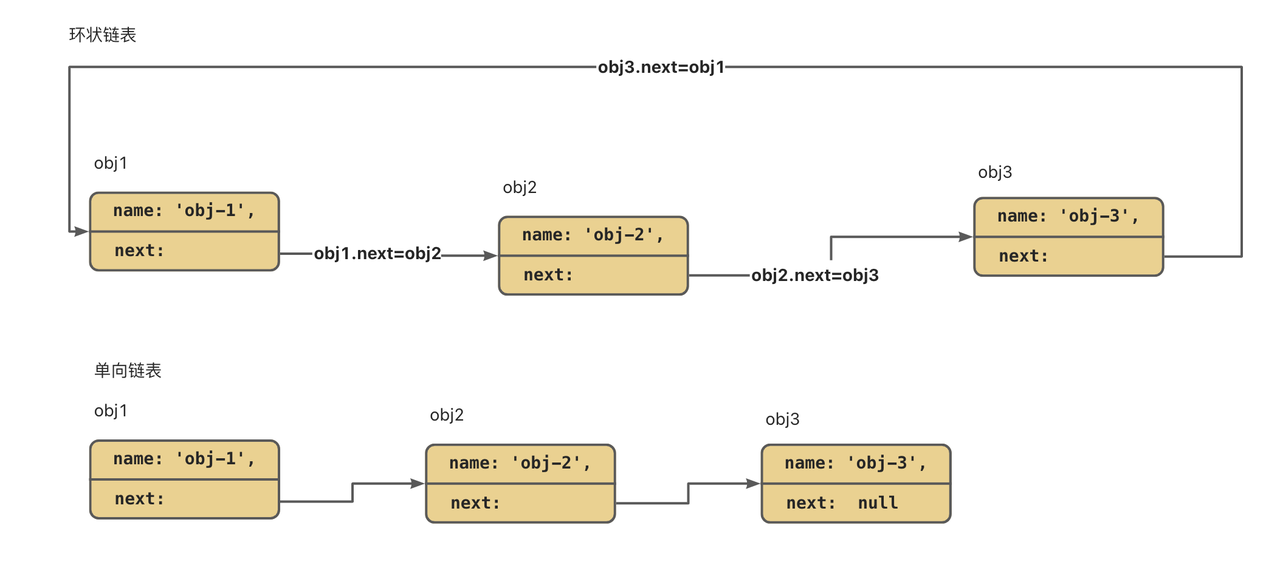
在开始 useState 函数之前,先简单了解下链表 这种数据结构。
u1 -> u2 -> u3 -> u1,这是环状链表。
u1 -> u2 -> u3 -> null,这是单向链表。
我们使用的链表,所需要的预备知识只有这些,它能保证我们按照一定顺序方便的读取数据。
在之前表述的 useState 原理中,我们提到:
之所以能保持住state,是在一个函数组件之外的地方,保存了一个「对象」,这个对象里记录了之前的状态。
那我们在函数之外,先声明一些必要的东西:
// 组件是分初次渲染和后续更新的,那么就需要一个东西来判断这两个不同阶段,简单起见,我们是使用这个变量好了。
let isMount = true; // 最开始肯定是true
// 我们在组件中,经常是使用多个useState的,那么需要一个变量,来记录我们当前实在处理那个hook。
let workInProgressHook = null; // 指向当前正在处理的那个hook
// 针对App这个组件,我们需要一种数据结构来记录App内所使用的hook都有哪些,以及记录App函数本身。这种结构我们就命名为fiber
const fiber = {
stateNode: App, // 对函组件来说,stateNode就是函数本身
memorizedState: null // 链表结构。用来记录App里所使用的hook的。
}
// 使用 setNum是会更新组件的, 那么我们也需要一种可以更新组件的方法。这个方法就叫做 schedule
function schedule () {
// 每次执行更新组件时,都需要从头开始执行各个useState,而fiber.memorizedState记录着链表的起点。即workInProgressHook重置为hook链表的起点
workInProgressHook = fiber.memorizedState;
// 执行 App()
const app = fiber.stateNode();
// 执行完 App函数了,意味着初次渲染已经结束了,这时候标志位该改变了。
isMount = false;
return app;
}
外面的东西准备好了,开始 useState 这个函数的内部。
在开始之前,我们对 useState 有几个疑问:
-
useState 究竟怎么保持住之前的状态的?
-
如果多次调用 setNum 这类更新状态的函数,该怎么处理这些函数呢?
-
如果这个 useState 执行完了,怎么知道下一个 hook 该去哪里找呢?
带着这些疑问,我们进入 useState 的内部:
// 计算新状态,返回改变状态的方法
function useState(initialState) {
// 声明一个hook对象,hook对象里将有三个属性,分别用来记录一些东西,这些东西跟我们上述的三个疑问相关
// 1. memorizedState, 记录着state的初始状态 (疑问1相关)
// 2. queue, queue.pending 也是个链表,像上面所说,setNum是可能被调用多次的,这里的链表,就是记录这些setNum。 (疑问2相关)
// 3. next, 链表结构,表示在App函数中所使用的下一个useState (疑问3相关)
let hook;
if (isMount) {
// 首次渲染,也就是第一次进入到本useState内部,每一个useState对应一个自己的hook对象,所以这时候本useState还没有自己的的hook数据结构,创建一个
hook = {
memorizedState: initialState,
queue: {
pending: null // 此时还是null的,当我们以后调用setNum时,这里才会被改变
},
next: null
}
// 虽然现在是在首次渲染阶段,但是,却不一定是进入的第一个useState,需要判断
if (!fiber.memorizedState) {
// 这时候才是首次渲染的第一个useState. 将当前hook赋值给fiber.memorizedState
fiber.memorizedState = hook;
} else {
// 首次渲染进入的第2、3、4...N 个useState
// 前面我们提到过,workInProgressHook的用处是,记录当前正在处理的hook (即useState),当进入第N(N>1)个useState时,workInProgressHook已经存在了,并且指向了上一个hook
// 这时候我们需要把本hook,添加到这个链表的结尾
workInProgressHook.next = hook;
}
// workInProgressHook指向当前的hook
workInProgressHook = hook;
} else {
// 非首次渲染的更新阶段
// 只要不是首次渲染,workInProgressHook所在的这条记录hook顺序的链表肯定已经建立好了。而且 fiber.memorizedState 记录着这条链表的起点。
// 组件更新,也就是至少经历了一次schedule方法,在schedule方法里,有两个步骤:
// 1. workInProgressHook = fiber.memorizedState,将workInProgressHook置为hook链表的起点。初次渲染阶段建立好了hook链表,所以更新时,workInProgressHook肯定是存在的
// 2. 执行App函数,意味着App函数里所有的hook也会被重新执行一遍
hook = workInProgressHook; // 更新阶段此时的hook,是初次渲染时已经建立好的hook,取出来即可。 所以,这就是为什么不能在条件语句中使用React hook。
// 将workInProgressHook往后移动一位,下次进来时的workInProgressHook就是下一个当前的hook
workInProgressHook = workInProgressHook.next;
}
// 上述都是在建立、操作hook链表,useState还要处理state。
let state = hook.memorizedState; // 可能是传参的初始值,也可能是记录的上一个状态值。新的状态,都是在上一个状态的基础上处理的。
if (hook.queue.pending) {
let firstUpdate = hook.queue.pending.next; // hook.queue.pending是个环装链表,记录着多次调用setNum的顺序,并且指向着链表的最后一个,那么hook.queue.pending.next就指向了第一个
do {
const action = firstUpdate.action;
state = action(state); // 所以,多次调用setNum,state是这么被计算出来的
firstUpdate.next = firstUpdate.next
} while (firstUpdate !== hook.queue.pending.next) // 一直处理action,直到回到环状链表第一位,说明已经完全处理了
hook.queue.pending = null;
}
hook.memorizedState = state; // 这就是useState能保持住过去的state的原因
return [state, dispatchAction.bind(null, hook.queue)]
}
在 useState 中,主要是做了两件事:
-
建立 hook 的链表。将所有使用过的 hook 有序连接在一起,并通过移动指针,使链表里记录的 hook 和当前真正被处理的 hook 能够一一对应。
-
处理 state。在上一个 state 的基础上,通过 hook.queue.pending 链表来不断调用 action 函数,直到计算出最新的 state。
在最后,返回了 diapatchAction.bind(null, hook.queue), 这才是 setNum 的真正本体,可见在 setNum 函数中,是隐藏携带着hook.queue的。
接下来我们来看看 dispatchAction 的实现。
function dispatchAction(queue, action) {
// 每次dispatchAction触发的更新,都是用一个update对象来表述
const update = {
action,
next: null // 记录多次调用该dispatchAction的顺序的链表
}
if (queue.pending === null) {
// 说明此时,是这个hook的第一次调用dispatchAction
// 建立一个环状链表
update.next = update;
} else {
// 非第一调用dispatchAction
// 将当前的update的下一个update指向queue.pending.next
update.next = queue.pending.next;
// 将当前update添加到queue.pending链表的最后一位
queue.pending.next = update;
}
queue.pending = update; // 把每次dispatchAction 都把update赋值给queue.pending, queue.pending会在下一次dispatchAction中被使用,用来代表上一个update,从而建立起链表
// 每次dispatchAction都触发更新
schedule();
}
上面这段代码里,7 -18 行不太好理解,我来简单解释一下。
假设我们调用了 3 次setNum函数,产生了 3 个 update, A、B、C。
当产生第一个 update A 时:
A:此时 queue.pending === null,
执行 update.next = update, 即 A.next = A;
然后 queue.pending = A;
建立 A -> A 的环状链表
B:此时queue.pending 已经存在了,
update.next = queue.pending.next 即 B.next = A.next 也就是 B.next = A
queue.pending.next = update; 即 A.next = B, 破除了A->A的链条,将A->B
queue.pending = update 即 queue.pending = B
建立 B -> A -> B 的环状链表
C: 此时queue.pending 也已经存在了
update.next = queue.pending.next, 即 C.next = B.next, 而B.next = A , C.next = A
queue.pending.next = update, 即 B.next = C
queue.pending = update, 即 queue.pending = C
由于 C -> A , B -> C,而第二步中,A是指向B的,即
建立起 C -> A -> B -> C 环状链表
现在,我们已经完成了简略 useState 的代码了,可以操作试试看,全部代码如下:
let isMount = true;
let workInProgressHook = null;
const fiber = {
stateNode: App,
memorizedState: null
}
function schedule () {
workInProgressHook = fiber.memorizedState;
const app = fiber.stateNode();
isMount = false;
return app;
}
function useState(initialState) {
let hook;
if (isMount) {
hook = {
memorizedState: initialState,
queue: {
pending: null
},
next: null
}
if (!fiber.memorizedState) {
fiber.memorizedState = hook;
} else {
workInProgressHook.next = hook;
}
workInProgressHook = hook;
} else {
hook = workInProgressHook;
workInProgressHook = workInProgressHook.next;
}
let state = hook.memorizedState;
if (hook.queue.pending) {
let firstUpdate = hook.queue.pending.next
do {
const action = firstUpdate.action;
state = action(state);
firstUpdate.next = firstUpdate.next
} while (firstUpdate !== hook.queue.pending.next)
hook.queue.pending = null;
}
hook.memorizedState = state;
return [state, dispatchAction.bind(null, hook.queue)]
}
function dispatchAction(queue, action) {
const update = {
action,
next: null
}
if (queue.pending === null) {
update.next = update;
} else {
update.next = queue.pending.next;
queue.pending.next = update;
}
queue.pending = update;
schedule();
}
function App () {
const [num, setNum] = useState(0);
const [age, setAge] = useState(10);
console.log(isMount ? '初次渲染' : '更新');
console.log('num:', num);
console.log('age:', age);
const clickNum = () => {
setNum(num => num + 1);
// setNum(num => num + 1); // 是可能调用多次的
}
const clickAge = () => {
setAge(age => age + 3);
// setNum(num => num + 1); // 是可能调用多次的
}
return {
clickNum,
clickAge
}
}
window.App = schedule();
复制然后浏览器控制台粘贴,试试 App.clickNum() , App.clickAge() 吧。
由于我们是每次更新都调用了 schedule,所以 hook.queue.pending只要存在就会被执行,然后将 hook.queue.pending = null, 所以在我们的简略版 useState 里,queue.pending 所建立的环状链表没有被使用到。而在真实的 React 中,batchedUpdates会将多次 dispatchAction执行完后,再触发一次更新。这时候就需要环状链表了。
相信通过上面详细的代码注释讲解,对于前面我们对 useState 的 3 个疑问,应该已经有了答案。
- useState 究竟怎么保持住之前的状态?
每个 hook 都记录了上一次的 state,然后根据 queue.pending 链表中保存的 action,重新计算一遍,得到新的 state 返回。并记录此时的 state 供下一次状态更新使用。
- 如果我多次调用 setNum 这类 dispatch 函数,该怎么处理这些函数呢?
多次调用 dispatchAction 函数,会被存储在 hook.queue.pending 中,作为更新依据。每次组件更新完,hook.queue.pending 置 null。如果在之后再有 dispatchAction,则继续添加到 hook.queue.pending,并在 useState 函数中被依次执行 action,然后再次置 null。
- 如果这个 useState 执行完了,下一个 hook 该去哪里找呢?
在初次渲染的时候,所有组件内使用的 hook 都按顺序以链表的形式存在于组件对应的 fiber.memorizedState 中,并用一个 workInProgress 来标记当前正在处理的 hook。每处理完一个,workInProgress 将移动到 hook 的下一位,保证处理的 hook 的顺序和初次渲染时收集的顺序严格对应。
React hook 的理念
根据 Dan 的博客(https://overreacted.io/zh-hans/algebraic-effects-for-the-rest-of-us/), React hook 是在践行代数效应(algebraic effects)。我对代数效应不太懂,只能模糊的将「代数效应」理解为「使用某种方式(表达式/语法)来获得某种效果」,就像通过 useState 这种方式,让组件获得状态,对使用者来说,不必再关心究竟是如何实现的,React 会帮我们处理,而我们可以专注于用这些效应来做什么。
但为什么 hook 选择了函数式组件?是什么让函数式组件和类组件这么不同?
从写法上,过去的 class 组件的写法,基本是命令式的,当满足某个条件,去做一些事情。
class Box extends React.components {
componentDidMount () {
// fetch data
}
componentWillReceiveProps (props, nextProps) {
if (nextProps.id !== props.id) {
// this.setState
}
}
}
而 hook 的写法,则变成了声明式,先声明一些依赖,当依赖变化,自动执行某些逻辑。
function Box () {
useEffect(() => {
// fetch data
}, [])
useEffect(() => {
// setState
}, [id])
}
这两种哪种更好,可能因人而异。但我觉得对于第一次接触 React 的人来说,funciton 肯定是更亲切的。
两者更大的差别是更新方式不同,class 组件是通过改变组件实例的 this 中的 props、state 内的值,然后重新执行render 来拿到最新的 props、state,组件是不会再次实例化的。
而函数式组件,则在更新时重新执行了函数本身。每一次执行的函数,都可以看做相互独立的。
我觉得这种更新方式的区别,是不习惯函数式组件的主要原因。函数组件捕获了渲染所需要的值,所以有些情况下结果总是出人意料。
就像这个例子(https://codesandbox.io/s/react-hooks-playground-forked-ktf4uw?file=/src/index.tsx),当我们点击加号,然后尝试拖动窗口,看看控制台打印了什么?
没错,count is 0。
尽管你点击了很多次按钮,尽管最新的 count 已经变成了 N,但是每一次 App 的 context 都是独立的,在 handleWindowResize 被定义的时候,它看到的 count 是0, 然后被绑定事件。此后 count 变化,跟这一个 App 世界里的 handleWindowResize 已经没有关系了。会有新的 handleWindowResize 看到了新的 count,但是被绑定事件的,只有最初那个。
而 Class 版本是这样的:
class App extends Component {
constructor(props) {
super(props);
this.state = {
count: 0
};
this.handleWindowResize = this.handleWindowResize.bind(this);
this.handleClick = this.handleClick.bind(this);
}
handleWindowResize() {
console.log(`count is ${this.state.count}`);
}
handleClick() {
this.setState({
count: this.state.count + 1
});
}
componentDidMount() {
window.addEventListener("resize", this.handleWindowResize);
}
componentWillUnmount () {
window.removeEventListener('resize', this.handleWindowResize)
}
render() {
const { count } = this.state;
return (
<div className="App">
<button onClick={this.handleClick}>+</button>
<h1>{count}</h1>
</div>
);
}
}
在 Class 的版本里,App 的实例并不会再次创建,无论更新多少次 this.handleWindowResize、this.handleClick 还是一样,只是里面的this.state被 React 修改了。
从这个例子,我们多少能够看出 「函数捕获了渲染所需要的值」的意思,这也是函数组件和类组件的主要不同。
但为什么是给函数式组件增加 hook?
给函数式组件增加 hook,除了是要解决 class 的几个缺陷:
-
在组件之间复用状态逻辑很难
-
复杂组件变得难以理解
-
难以理解的 class
之外,从 React 理念的角度,UI = f(state)也说明了,组件应该只是数据的通道而已,组件本质上更贴近函数。从个人使用角度,其实很多情况下,我们本不需要那么重的 class,只是苦于无状态组件没法setState而已。
React hook 的意义
前面说了这么多 hook,都是在说它如何实现,和 Class 组件有何不同,但还有一个最根本的问题没有回答,hook 给我们开发者带来了什么?
React 官网里提到了,Hook可以让组件之间状态可用逻辑更简单,并用高阶组件来对比,但是首要问题是,我们为什么要用 HOC?
先看这个例子(https://codesandbox.io/s/modest-visvesvaraya-v0i9fy?file=/src/Counter.jsx):
import React from "react";
function Count({ count, add, minus }) {
return (
<div style={{ flex: 1, alignItems: "center", justifyContent: "center" }}>
<div>You clicked {count} times</div>
<button
onClick={add}
title={"add"}
style={{ minHeight: 20, minWidth: 100 }}
>
+1
</button>
<button
onClick={minus}
title={"minus"}
style={{ minHeight: 20, minWidth: 100 }}
>
-1
</button>
</div>
);
}
const countNumber = (initNumber) => (WrappedComponent) =>
class CountNumber extends React.Component {
state = { count: initNumber };
add = () => this.setState({ count: this.state.count + 1 });
minus = () => this.setState({ count: this.state.count - 1 });
render() {
return (
<WrappedComponent
{...this.props}
count={this.state.count}
add={this.add.bind(this)}
minus={this.minus.bind(this)}
/>
);
}
};
export default countNumber(0)(Count);
效果就是展示当前数值,点击产生加减效果。

之所以要使用这种方式,是为了在被包裹组件外部提供一套可复用的状态和方法。本例中即 state、add、minus,从而使后面如果有其他功能相似的但样式不同的WrappedComponent,可以直接用 countNumber 包裹一下就行。
从这个例子中,其实可以看到我们使用 HOC 本质是想做两件事,传值和同步。
传值是将外面得到的值传给我们被包裹的组件。而同步,则是让被包裹的组件利用新值重新渲染。
从这里我们大致可以看到 HOC 的两个弊端:
-
因为我们想让子组件重新渲染的方式有限,要么高阶组件 setState,要么 forceUpdate,而这类方法都是 React 组件内的,无法独立于 React 组件使用,所以add\minus 这种业务逻辑和展示的 UI 逻辑,不得不粘合在一起。
-
使用 HOC 时,我们往往是多个 HOC 嵌套使用的。而 HOC 遵循透传与自身无关的 props 的约定,导致最终到达我们的组件时,有太多与组件并不太相关的 props,调试也相当复杂。我们没有一种很好的方法来解决多层 HOC 嵌套所带来的麻烦。
基于这两点,我们才能说 hooks 带来比 HOC 更能解决逻辑复用难、嵌套地狱等问题所谓的“优雅”方式。
HOC 里的业务逻辑不能抽到组件外的某个函数,只有组件内才有办法触发子组件重新渲染。而现在自定义 hook 带来了在组件外触发组件重新渲染的能力,那么难题就迎刃而解。
使用 hook,再也不用把业务逻辑和 UI 组件夹杂在一起了,上面的例子(https://codesandbox.io/s/modest-visvesvaraya-v0i9fy?file=/src/CounterWithHook.jsx),用 hook 的方式是这样实现的:
// 业务逻辑拆分到这里了
import { useState } from "react";
function useCounter() {
const [count, setCount] = useState(0);
const add = () => setCount((count) => count + 1);
const minus = () => setCount((count) => count - 1);
return {
count,
add,
minus
};
}
export default useCounter;
// 纯UI展示组件
import React from "react";
import useCounter from "./counterHook";
function Count() {
const { count, add, minus } = useCounter();
return (
<div style={{ flex: 1, alignItems: "center", justifyContent: "center" }}>
<div>You clicked {count} times</div>
<button
onClick={add}
title={"add"}
style={{ minHeight: 20, minWidth: 100 }}
>
+1
</button>
<button
onClick={minus}
title={"minus"}
style={{ minHeight: 20, minWidth: 100 }}
>
-1
</button>
</div>
);
}
export default Count;
这种拆分,让我们终于可以把业务和 UI 分离开了。如果想获取类似之前嵌套 HOC 那样的能力,只需要再引入一行 hook 就行了。
function Count() {
const { count, add, minus } = useCounter();
const { loading } = useLoading();
return loading ? (
<div>loading...please wait...</div>
) : (
<div style={{ flex: 1, alignItems: "center", justifyContent: "center" }}>
...
</div>
);
}
export default Count;
useCounter、useLoading 各自维护各的,而我们所引入的的东西,一目了然。
在这个计数器的例子上,我们可以想的更远一些。既然现在逻辑和 UI 是可以拆分的,那如果提取出一个计数器的所有逻辑,是不是就可以套用任何 UI 库了?
从这个假设出发,如果我让 hook 提供这些能力:
-
可以设置计数器的初始值、每次加减值、最大值最小值、精度
-
可以通过返回的方法,直接获得超出最大最小值时按钮变灰无法点击等等效果。
-
可以通过返回的方法,直接获取中间输入框只能输入数字,不能输入文字等等功能。
而开发人员要做的,就是将这些放在任何 UI 库或原生的 button 与 input 之上,仅此而已。
function HookUsage() {
const { getInputProps, getIncrementButtonProps, getDecrementButtonProps } =
useNumberInput({
step: 0.01,
defaultValue: 1.53,
min: 1,
max: 6,
precision: 2,
})
const inc = getIncrementButtonProps()
const dec = getDecrementButtonProps()
const input = getInputProps()
return (
<HStack maxW='320px'>
<Button {...inc}>+</Button>
<Input {...input} />
<Button {...dec}>-</Button>
</HStack>
)
}
只需要这么几行代码,就可以得到这样的效果:

我们可以展望一个与 Antd、elementUI 这些完全不同的组件库。它可以只提供提炼后的业务组件逻辑,而不必提供 UI, 你可以把这些业务逻辑应用在任何 UI 库上。
Hooks 的出现可以让UI library转向logic library,而这种将组件状态、逻辑与UI展示关注点分离的设计理念,也叫做Headless UI。
Headless UI 着力于提供组件的交互逻辑,而 UI 部分让允许使用者自由选择,在满足 UI 定制拓展的前提下,还能实现逻辑的交互逻辑的复用,业界已经有一些这方面的探索,比如组件库 chakra。前面的例子,其实就是 chakra 提供的能力。chakra 底层是对 Headless UI 的实践,提供对外的 hook,上层则提供了自带 UI 的组件,总之就是让开发者既可以快速复用人家已经提炼好的而且是最难写的交互逻辑部分,又不至于真的从头去给 button、input 写样式。另外 chakra 提供了组成一个大组件的原子组件,比如 Table 组件,chakra 会提供:
Table,
Thead,
Tbody,
Tfoot,
Tr,
Th,
Td,
TableCaption,
TableContainer,
这让使用者可以根据实际需要自由组合,提供原子组件的还有 Material-UI,对于用习惯了 Antd、element UI 的这种整体组件的我们来说,提供了一种不同的方式,十分值得尝试。
在实际开发时,基于 hooks 甚至可以让经验丰富的人负责写逻辑,而新手来写 UI,分工合作,大大提升开发效率。
React hook 的局限
React hook的提出,在前端里是意义非凡的,但世界上没有完美的东西,hook 仍然存在着一些问题。当然这只是我个人在使用中的一点感受与困惑。
被强制的顺序
第一次接触 hook 时,对不能在嵌套或者条件里使用 hook 感到很奇怪,这非常反直觉。
useState、useEffect 明明就一个函数而已,居然限制我在什么地方使用?只要我传入的参数是正确的,你管我在哪儿用呢?
我们平时在项目里写一些工具函数时,会限制别人在什么地方使用么?顶多是判断一下宿主环境,但是对使用顺序,肯定是没有限制的。一个好的函数,应该像纯函数,同样的输入带来同样的输出,没有副作用,不需要使用者去思考在什么环境、什么层级、什么顺序下调用,对使用者的认知负担最小。
后来知道了,React 是通过调用时序来保证组件内状态正确的。
当然这并不是什么大问题,曾经 jsx 刚出的时候,js 夹杂 html 的语法同样被人诟病,现在也都真香了。开发者只要记住并遵守这些规则,就没什么负担了。
复杂的useEffct
相信很多同学在遇到这个 API 的时候,第一个问题就是被其描述「执行副作用」所迷惑。
啥是执行副作用?
React 说数据获取,设置订阅、手动更改 DOM 这些就是副作用。
为什么这些叫副作用?
因为理想状态下,Class 组件也好,函数组件也好,最好都是无任何副作用的纯函数,同样的输入永远是同样的输出,稳定可靠能预测。但是实际上在组件渲染完成后去执行一些逻辑是很常见的需求,就像组件渲染完了要修改 DOM、要请求接口。所以为了满足需求,尽管 Class 组件里的 render 是纯函数,还是将 Class 组件的副作用放在了 componentDidMount 生命周期中。尽管曾经的无状态组件是纯函数,还是增加了useEffect来在页面渲染之后做一些事情。所谓副作用,就是componentDidMount 让 Class 的 render 变的不纯。useEffect让无状态函组件变的不纯而已。
我们即使理解了副作用,接下来要理解 useEffect 本身。
先接触 React 生命周期的同学,在学习 useEffct 的时候,或多或少会用 componentDidMount 来类比 useEffct。如果你熟悉 Vue,可能会觉得 useEffct 类似 watcher ,然而当用多了以后,会发现 useEffect 都似是而非。
首先 useEffect 每次渲染完成后都会执行,只是根据依赖数组去判断是否要执行你的effect。它并不是componentDidMount,但为了实现componentDidMount的效果,我们需要使用空数组来模拟。这时候useEffect 可以看做 componentDidMount。当依赖数组为空时,effect 里返回的清除方法,等同于 componentWillUnmount。
useEffect 除了实现componentDidMount、componentWillUnmount 之外,还可以在依赖数组里设置需要监听的变量,这时看起来又像是 Vue 的 watcher。但是 useEffect 实际上是在页面更新后才会执行的。举个例子:
function App () {
let varibaleCannotReRender; // 普通变量,改变它并不会触发组件重新渲染
useEffect(() => {
// some code
}, [varibaleCannotReRender])
// 比如在一次点击事件中改变了varibaleCannotReRender
varibaleCannotReRender = '123'
}
页面不会渲染,effect 肯定不会执行,也不会有任何提示。所以 useEffect 也不是一个变量的 watcher。事实上只要页面重新渲染了,你的 useEffect 的依赖数组里即使有非 props/state 的本地变量也可以触发effect。
像这样,每次点击后,effect 都会执行,尽管我没有监听 num,b 也只是个普通变量。
function App() {
const [num, setNum] = useState(0);
let b = 1;
useEffect(() => {
console.log('effefct', b);
}, [b]);
const click = () => {
b = Math.random();
set((num) => num + 1);
};
return <div onClick={click}>App {get}</div>;
}
所以在理解 useEffect 上,过去的 React 生命周期, Vue 的 watcher 的经验都不能很好地迁移过来,可能最好的方式反而是忘记过去的那些经验,从头开始学习。
当然,即使你已经清楚了不同情况下 useEffect 都能带来什么效果,也不意味着就可以用好它。对于曾经重度使用 Class 组件的开发人员来说尤其如此,摒弃掉生命周期的还不够。
在 Class 组件中,UI渲染是props或者state在render函数中确定的,render可以是个无副作用的纯函数,每次调用了this.setState,新的props、state渲染出新的UI,UI与props、state之间保持了一致性。而 componentDidMount里的那些副作用,是不参与更新过程的,失去了与更新的同步。这是Class的思维模式。
而在 useEffect思维模式中,useEffect 是与每一次更新同步的,这里没有 mount 与 update,第一次渲染和第十次渲染一视同仁。你愿意的话,每一次渲染都可以去执行你的 effect。
这种思维模式上的区别,我认为是 useEffect 让人觉得困惑的原因。
useEffect 与更新同步,而实际业务中并不一定每一次更新都去执行 effect,所以需要用依赖数组来决定什么时候执行副作用,什么时候不执行。而依赖数组填写不当,又可能造成无限执行 effect、或者 effect 里拿到过时数值等情况。
在写业务的时候,我们总是不由自主的把功能、组件越写越大,useEffect 越来越复杂。当依赖数组越来越长的时候,就该考虑是不是设计上出了问题。我们应该尽量遵循单一性原则,让每个 useEffect,只做一件尽可能简单的事情。当然,这也并不容易。
函数的纯粹性
在 hook 出现之前的函数式组件,没有局部状态,信息都是外部传入的,它本身就是像个纯函数,一旦函数重新执行,你在组件里声明的变量、方法全都是新的,简单纯粹。那时候我们还是把这类组件叫做 SFC 的(staless function component)。
但引入了 hook 之后,无状态函数组件拥有了局部状态的能力,成了 FC 了。严格说这时候拥有了局部状态的函数, 是不能看做是纯函数了,但为了减轻一点思维上的负担,可以把 useState 理解成类似函数组件之外地方所声明的一种数据,这个数据每次变化了都传给你的函数组件。
// 把这种
function YourComponent () {
const [num, setNum] = useState(0);
return <span>{num}</span>
}
// 理解成这种形式,使用了useState,React就自动给你生成AutoContainer包裹你的函数。这样你的组件仍可以看成是纯函数。
function AutoContainer () {
const [num, setNum] = useState(0);
return <YourComponent num={num} />
}
function YourComponent (props) {
return <span>{props.num}</span>
}
每一次函数组件更新,就像一次快照一样捕获了当时环境,每次更新都拥有独一份的 context,更新之间互不干扰,充分利用了闭包特性,似乎也很纯粹。
如果一直是这样,也还好,一次次更新就像一个个平行宇宙,相似但不相同。props、state 等等context决定渲染,渲染之后是新的 context,各过各的,互不打扰。
但实际上,useRef 的出现,打破了这种纯粹性,useRef 让组件在每次渲染时都返回了同一个对象,就像一个空间宝石,在平行宇宙之间穿梭。而 useRef 的这一特性,使之成为了 hooks 的闭包救星,也造成了“遇事不决,useRef”的局面。说好的每次渲染都是独一份的 context,怎么还能拿到几次前更新的数据呢?
去掉 useRef 行不行?还真不行,有些场景就是需要一些值能够穿越多次渲染。
但是这样不相当于在 class 组件的 this 里加了个字段用来存数据吗?看得出来 React 是想拥抱函数式编程,但是,useRef却让它变得不那么“函数式”了。
写在最后
我真正开始使用 hooks 已经比较晚了,这篇啰嗦了 1 万多字的文章,其实是我在学习和使用中曾经问过自己的问题,在此我尝试给出这些问题的回答。能力有限,只能从一些局部角度来描述一些我所理解的东西,不全面也不够深刻,随着继续学习,可能会在未来有不一样的感悟。
hooks 很强大,掌握一门强大的技艺从来都是需要不断磨练和时间沉淀的,希望这篇文章,能稍稍解答一些你曾经有过的疑问。
参考文档:
https://overreacted.io/
https://zh-hans.reactjs.org/docs/thinking-in-react.html
https://zh-hans.reactjs.org/docs/hooks-effect.html
https://react.iamkasong.com/
https://juejin.cn/post/6944863057000529933