1. 绪言
1.1 遗传编程概述
\quad\quad 自计算机出现以来,计算机科学的一个重要目标是让计算机自动进行程序设计,即只要明确地告诉计算机要解决的问题,而不需要告诉它如何去做,遗传规划便是在该领域内的一种尝试。它采用遗传算法的基本思想,但使用一种更为灵活的表示方式 —— 分层结构来表示解空间。这些分层结构的叶节点是问题的原始变量,中间节点则是组合这些原始变量的函数,这样每一个分层结构对应问题的一个解,也可以理解为求解该问题的一个计算机程序。遗传规划即是使用一些遗传操作动态地改变这些结构以获得解决该问题的可行的计算机程序。遗传规划的思想是斯坦福大学的 J.R.Koza 在 20 世纪 90 年代初提出的,1992 年和 1994 年他又先后出版专著 “Genetic programming: on the Programming of Computers by Means of NaturalSelection” 和 “Genetic Programming II: Automatic Discovery of Reusable Programs”, 又于 1999 年和 Forest 等人写了 “Genetic programming lll- Darwinian Invention andProblem Solving”,全面介绍了遗传规划的原理、实例和以及在各领域内的应用,因此他被视为遗传规划的奠基人。
1.2 遗传算法的局限性
\quad\quad 遗传算法是对字符串进行操作,逐步实现进化遗传。许多研究人员在此基础上提出的理论和方法,极大地丰富了遗传算法的内容。然而,用编码方法特别是定长字符串方法描述问题,极大地限制了遗传算法的应用范围。遗传算法的主要缺点如下:
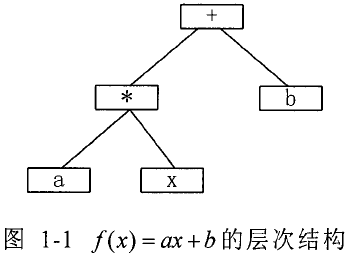
(1) 不能描述层次化问题:有许多的问题的自然描述是层次化的结构,而不是线性结构。例如数学表达式 f ( x ) = a x + b f(x)= ax+b f(x)=ax+b,是一个种层次结构的结构,如图 1-1 所示,这种非线性结构用线性结构来描述就相当困难。
(2) 不能描述层次化问题:如方程求解,数据回归,或者有分支,循环,递归的算法程序。
(3)线性字符串缺乏动态可变性:字符串的长度一旦确定,就比较难以改变,限制了问题的表示。
\quad\quad 遗传编程用非线性结构表示个体,因此弥补了遗传算法的部分缺点,它的实质是用广义的计算机程序来求解问题,它的基本思想是产生一个初始种群,然后根据适者生存原则,用遗传操作来处理这些个体,一代一代更替,使个体越来越接近问题的解。一般而言,遗传编程是基于遗传算法的基础上发展起来的新的进化算法,它克服了遗传算法的部分缺点,具有更大的通用性。
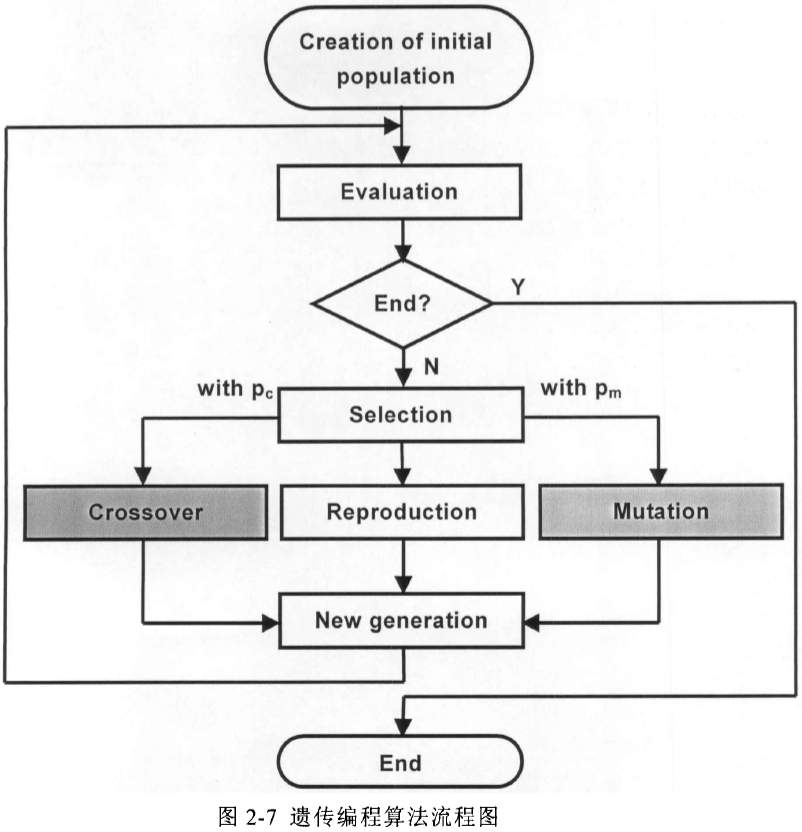
2. 遗传编程算法流程
遗传编程的求解步骤归纳如下:
(1)确定个体的表达方式,表现为确定函数符集合终止符集
(2)随机产生初始群体
(3)计算群体中各个体的适应度
(4)执行遗传操作,包括复制、交换、突变等
(5)循环执行(3)、(4) 直至满足终止条件。
3. 初始个体
3.1 遗传编程基础
遗传编程中的个体是由函数符号集 F = { f 1 , f 2 , ⋅ ⋅ ⋅ , f n } F=\{f_1, f_2, ···, f_n\} F={f1,f2,⋅⋅⋅,fn} 与 终止符集 T = { t 1 , t 2 , ⋅ ⋅ ⋅ , t m } T = \{t_1, t_2, ···, t_m\} T={t1,t2,⋅⋅⋅,tm} 通过属性层次结构组合而成。
函数符集 F F F 内的函数可以为:
\quad\quad 算法运算符: +、-、×、÷ 等。(其中除号为防止计算机溢出,规定分母不为零,称为保护性除法,一旦遇到分母为零时,最简单的处理方法令其商为被除数,或重新选择算术运算符)
\quad\quad 超越函数: sin、cos、log、exp 等。其中 log 要防止处理小于或等于零的自变量,采用保护性对数。
\quad\quad 布尔运算符: AND、OR、NOT 等
\quad\quad 条件表达式: If-then-else、Switch-case 等
\quad\quad 循环表达式: Do-until、While-do、For-do 等
\quad\quad 控制转移说明语句: Go to、Call、Jump 等
\quad\quad 变量赋值函数: a = 1, Read、Write 等
\quad\quad 其他定义的函数
终止符集是变量或常量
3.2 个体的树形表示
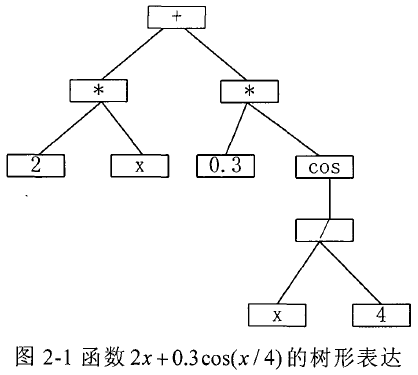
设函数符集为:
F
=
{
+
,
×
,
/
,
c
o
s
}
F = \{+, ×, /, cos\}
F={+,×,/,cos}
终止符集为:
T
=
{
x
,
p
}
T = \{x, p\}
T={x,p}
图 2-1 表示了一个由 F F F 和 T T T 组成的个体的层次化结构
3.3 初始个体生成原理
\quad\quad 初始群体由众多初始个体组成,初始个体为所要解决问题的各种可能的符号表达式,它通过随机方法产生。
\quad\quad 开始时在函数集 F F F 中按均匀分布随机地选出一个函数作为算法树的根结点。通常把根结点限制在函数集 F F F 中是为了生成一个层次化的复杂结构;相反,若从终止符 T T T 中随机选取根结点,则生成只有一个终止符的退化结构。一般情况下,从函数集中选出的函数 f f f 如果具有 Z ( f ) Z(f) Z(f) 个自变量,那么就要从该结点发出 Z ( f ) Z(f) Z(f) 个子节点。然后,对于每个子节点,从函数集 F F F 和终止符 T T T 的并集 C = F ∪ T C=F \cup T C=F∪T 中再按均匀分布随机地选出一个元素作为该条线的尾结点。如果此时选出的是一个函数,则重复执行上述过程。如果从并集 C C C 中选出的是终止符,它作为从节点发出的尾节点,则该分支点上的树就终止生长。上述过程从上到下,从左到右不断重复,直到一棵完整的树生成位置
初始群体中的初始个体通过某种随机方法产生,图 2-2 描述了一个初始个体的创建过程。
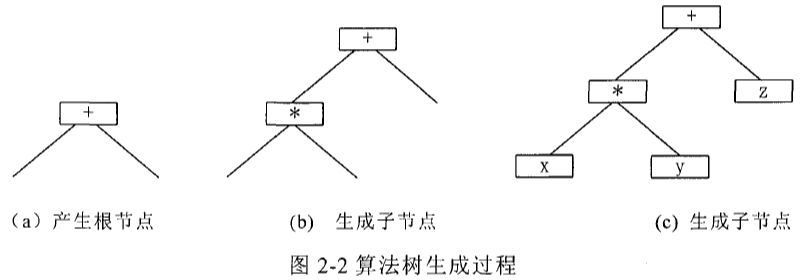
初始个体的生成方法有多种,它们的共同要求是要能产生不同的组合。常用的初始个体的生成方法有三种,即完全法,生长法和混合法:
\quad\quad (1)完全法(full): 完全法产生的初始个体,每一叶子的深度都等于给定的最大深度。所谓叶子的深度是指叶子距树根的层次。首先从函数集 F F F 中选取元素作为根节点,然后根据给定的最大深度分别从函数集 F F F 及终止符 T T T 中选取元素。假若待定节点的深度小于给定的最大深度,则该节点从函数集中随机选取,以便算法树延伸;若待定结点的深度等于给定的最大深度,则该节点从终止符集中选取,以便终止算法树的生长。
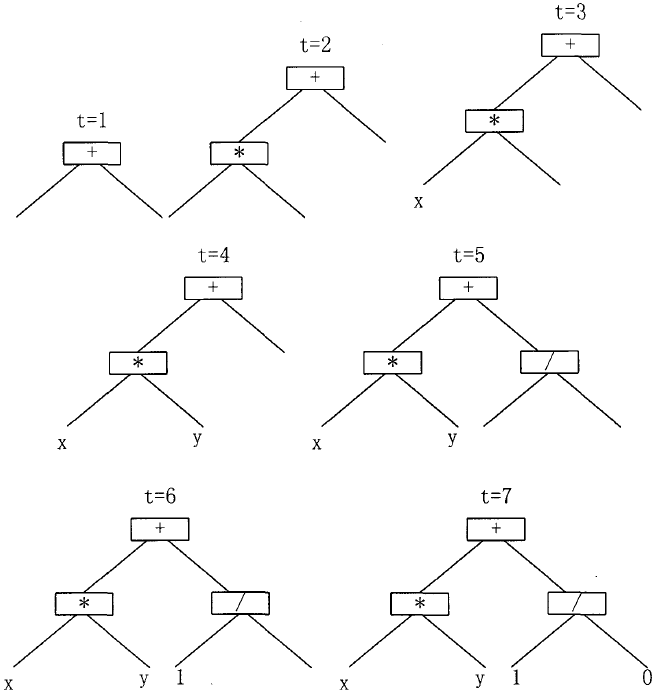
\quad\quad (2)生长法(grow): 用生长法形成的初始个体,每一叶子的深度不一定都等于给定的最大深度,但是算法树的最大深度要等于给定值。它也同样首先从函数集 F F F 中选取根节点,然后再选取外延的待定节点。假若待定节点的深度小于给定的最大深度,则该节点从函数集 F F F 及终止符 T T T 的并集 C = F ∪ T C=F \cup T C=F∪T 中选取。若待定结点的深度等于给定的最大深度,则该节点仅从终止符集中选取,以便终止算法树的生长。
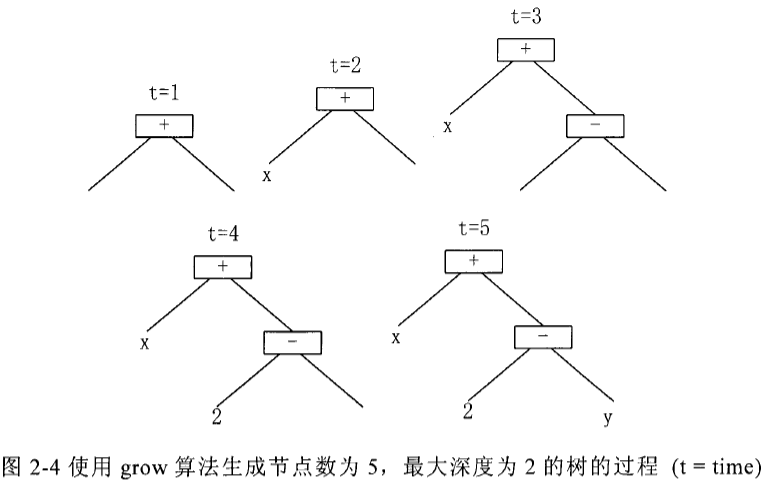
\quad\quad (3)混合法(ramped half and half): 混合法是完全法和生长法的两者的综合。其实现方法是:初始个体的深度在 2 至给定的最大深度之间随机选取,然后一半的初始个体用完全法产生,另一半的初始个体用生长法产生。
在 full 和 grow 两者方法中,为了防止产生的初始树节点数目太多,需限定都树的最大深度不超过一个给定的数 maxd
可以看出,用完全法将产生非常大的个体树,而用生长法生成的树,大小和形状有更多的差异。
4. 个体评价(适应度值度量)
\quad\quad 在遗传编程的种群中,每个个体都代表了一个求解问题的解,个体的好坏,也就是个体代表的解接近问题的程度,需要一个数据来衡量,这就是适应度,计算适应度的函数称为适应度函数,遗传编程根据个体的适应度来选择个体并组成下一代,适应度函数的好坏,直接影响着进化过程。
常见的适应度度量有以下四种:原始适应度、标准适应度、调和适应度和归一化适应度。
4.1 原始适应度(Fawfitness)
原始适应度是以求解问题本身的自然属性来陈述的。种群
t
t
t 中某一个个体
i
i
i 的原始适应度
r
(
i
,
t
)
r(i, t)
r(i,t) 可以定义为:
r
(
i
,
t
)
=
∑
i
=
1
N
c
∣
p
(
i
,
j
)
−
c
(
j
)
∣
r(i, t) = \sum_{i=1}^{Nc} |p(i, j) - c(j)|
r(i,t)=i=1∑Nc∣p(i,j)−c(j)∣
式中, p ( i , j ) p(i, j) p(i,j) 是个体 i i i 在实例 j j j 下计算的返回值, N c Nc Nc 是适应度计算实例数目, c ( j ) c(j) c(j) 是适应度计算实例 j j j 的准确值。
原始适应度有时越大越好,有时越小越好,常采用的原始适应度形式有:
(1)预测问题中,用预测值和实际值的离差衡量,越小越好;
(2)模式识别问题中,用匹配的像素点数目衡量,越大越好;
(3)机器人控制中,用碰壁次数衡量,越小越好;
(4)分类问题中,用正确分类的次数衡量,越大越好;
(5)人工生命问题中,用发现或吃掉的食物数衡量,越大越好;
(6)博弈问题中,用赢取的货币衡量,越大越好。
4.2 标准适应度(standardized fitness)
\quad\quad 鉴于原始适应度有时越大越好,有时越小越好,为了统一衡量标准引出了标准适应度 s ( i , t ) s(i,t) s(i,t),即标准适应度总是表现为数值越小适应性越好。于是有两种情况发生
\quad\quad
(1)对于原始适应度愈大愈好(如人工蚂蚁问题,若使人工蚂蚁吃掉的食物块数越多越好,则原始适应度越大越好),则按下式计算:
s
(
i
,
t
)
=
r
m
a
x
−
r
(
i
,
t
)
s(i, t) = r_{max} - r(i, t)
s(i,t)=rmax−r(i,t)
式中:
s
(
i
,
t
)
s(i,t)
s(i,t) 为第
t
t
t 代第
i
i
i 个体标准适应度;
~\quad\quad
r
(
i
,
t
)
r(i, t)
r(i,t) 为第
t
t
t 代第
i
i
i 个体原始适应度;
~\quad\quad
r
m
a
x
r_{max}
rmax 为原始适应度所能达到的最大值。
\quad\quad
(2)对于原始适应度为越小越好(如对于最优控制问题,若使控制成本越小越好,则原始适应度越小越好),则标准适应度等于原始适应度,即:
s
(
i
,
t
)
=
r
(
i
,
t
)
s(i,t ) = r(i,t)
s(i,t)=r(i,t)
4.3 调整适应度(adjusted fitness)
子代
t
t
t 中个体的调和适应度
a
(
i
,
t
)
a(i, t)
a(i,t) 由标准适应度计算而得。其计算公式:
a
(
i
,
t
)
=
1
1
+
s
(
i
,
t
)
a(i, t) = \frac{1}{1 + s(i, t)}
a(i,t)=1+s(i,t)1
式中:
a
(
i
,
t
)
a(i,t)
a(i,t) 为第
t
t
t 代第
i
i
i 个体调和适应度;
~~\quad\quad
r
(
i
,
t
)
r(i,t)
r(i,t) 为第
t
t
t 代第
i
i
i 个体原始适应度;
\quad\quad 通常 s ( i , t ) > 0 s(i,t)>0 s(i,t)>0,则 a ( i , t ) ∈ [ 0 , 1 ] a(i, t) \in [0,1] a(i,t)∈[0,1],且调和适应度越大,个体越优良。当标准适应度接近于 0 时,调和适应度具有扩大标准适应度微小差别的好处。这一情况常常出现在进化的最后几代中。随着群体的不断进化,重点就将逐渐放在区分好的和更好的个体上,它们的差别往往很小,特别是当接近一个正确答案时,标准适应度接近。这时调和适应度的扩张能力就显得特别有效。例如,当标准适应度取值介于 0 (最佳)和 64 (最差)之间时,标准适应度为 64,63 的两个较差个体的调和适应度分别为 0.0154, 0.0156,其差别为0.0002。但是,标准适应度为 4,3 的两个优良个体的调和适应度分别为 0.20,0.25,其差别为 0.05。
4.4 归一化适应度(normalized fitness)
个体的归一化适应度
n
(
i
,
t
)
n(i, t)
n(i,t) 采用下式进行计算:
n
(
i
,
t
)
=
a
(
i
,
t
)
∑
k
=
1
M
a
(
k
,
t
)
n(i, t) = \frac{a(i, t)}{\sum_{k=1}^M a(k, t)}
n(i,t)=∑k=1Ma(k,t)a(i,t)
式中:
n
(
i
,
t
)
n(i, t)
n(i,t) 为第
t
t
t 代第
i
i
i个体归一化适应度;
~~\quad\quad
r
(
i
,
t
)
r(i, t)
r(i,t) 为第
t
t
t 代第
i
i
i 个体原始适应度;
~~\quad\quad
M
M
M 为群体中的个体数目。
它具有下述三个理想特征:
~~\quad\quad
(1)
n
(
i
,
t
)
∈
[
0
,
1
]
n(i, t) \in [0, 1]
n(i,t)∈[0,1]
~~\quad\quad
(2)
n
(
i
,
t
)
n(i, t)
n(i,t) 愈大,个体愈优良
~~\quad\quad
(3)
∑
k
=
1
M
n
(
k
,
t
)
=
1
{\sum_{k=1}^M n(k, t)} = 1
∑k=1Mn(k,t)=1
如果个体选择方法是基于比例适应度原则,那么归一化适应度直接可作为个体选择的概率。
5. 基本算子
5.1 复制
\quad\quad 当复制发生时,一个父代个体繁殖一个后代个体,复制过程由两部分组成;首先,根据适应度从群体中选出一个父代个体:其次,被选出的父代个体在未经任何变化的条件下从当前代复制到新一代。根据适应度,一般有以下几种方法:
(1)比例选择法: 该选择方法是一种常用的选择方法,其含义是适应度越高,被选中的概率越大,即:(同轮盘赌)
P
i
=
f
i
∑
k
=
1
M
f
k
P_i = \frac{f_i}{\sum_{k=1}^{M} f_k}
Pi=∑k=1Mfkfi
式中:
P
i
P_i
Pi 为个体
i
i
i 被选中的概率;
~~\quad\quad
f
i
f_i
fi 为个体
i
i
i 的适应度
~~\quad\quad
M
M
M 为群体中个体的总数
(2)分级选择法: 将个体按适应度的大小分成许多级别,然后按照个体的级别而不是适应度进行选择,从而降低适应度特高的个体被优先选择的可能性。与此同时,分级选择法可扩大适应度相差不大的个体间的差别,利用分级可使适应度不很高的较优个体仍能被选中。
~~\quad\quad
对于线性分级,个体
i
i
i 被选中的概率
P
i
P_i
Pi 为:
P
i
=
1
M
[
η
+
−
(
η
+
−
η
−
)
i
−
1
M
−
1
]
P_i = \frac{1}{M} [\eta^+ - (\eta^+ - \eta^-) \frac{i-1}{M-1}]
Pi=M1[η+−(η+−η−)M−1i−1]
式中: η + M \frac{\eta^+}{M} Mη+ 为最优个体被选中的概率;
~~\quad\quad η − M \frac{\eta^-}{M} Mη− 为最差个体被选中的概率;
~~\quad\quad
M
M
M 为群体中个体的总数。而且为使
M
M
M 保持常数,要求
1
≤
η
+
≤
2
1 ≤ \eta^+ ≤ 2
1≤η+≤2 及
η
+
+
η
−
=
2
\eta^+ + \eta^- = 2
η++η−=2。对于指数分级,则上式变为:
P
i
=
C
−
1
C
M
−
1
C
M
−
1
P_i = \frac{C^{-1}}{C^{M -1}}C^{M-1}
Pi=CM−1C−1CM−1
式中 C C C 为选择偏好系数, 0 < C < 1 0 < C < 1 0<C<1
(3)竞争选择法: 它是每次从群体中随机选出一组包含 K K K 个个体的小群体,然后从中挑选出适应度最高的个体作为复制的对象。被选中的个体经复制后,仍保留在父代群体中,有可能再次进入下一次随机选取的 K K K 个个体的小群体中。通过调整 K K K 的大小,可以改变选择的力度。 K K K 值越大,被选中的个体越优。反之被选出的个体只是相对较优而己。它是近几年主要的选择方法。
(4)精英选择法: 又称 ( μ , λ ) (\mu,\lambda) (μ,λ) 选择法, μ \mu μ 代表父代群体拥有的个体总数(相当于 M M M ) , λ \lambda λ 是下一代需要产生的子代个体数(相当于 M M M 乘复制概率 P r P_r Pr)。执行选择时,从 μ \mu μ 个父代个体确定性的按适应度大小选择出 λ \lambda λ 个优良个体进入下一代群体。由于采用确定性选择,被选取的 λ \lambda λ 个个体都是名列前茅的优良个体,不会掺入个别不良个体。
\quad\quad 一般来说,对于一个具体的问题,以上几种方法可以混合使用,也可以根据问题的实际情况,自定义更合适的选择方法。
5.2 交叉
选择和复制出来的个体还要进行交叉,对每一对个体,产生一个随机数,如果这个数小于交叉概率 Pc,将对个体执行交叉操作。
交叉 (CrossOver) 模拟的是自然界中的遗传以及两性生殖过程,父代通过 DNA 重新组合,产生子代,子代继承了父代的一些基因,同时产生了新的基因。
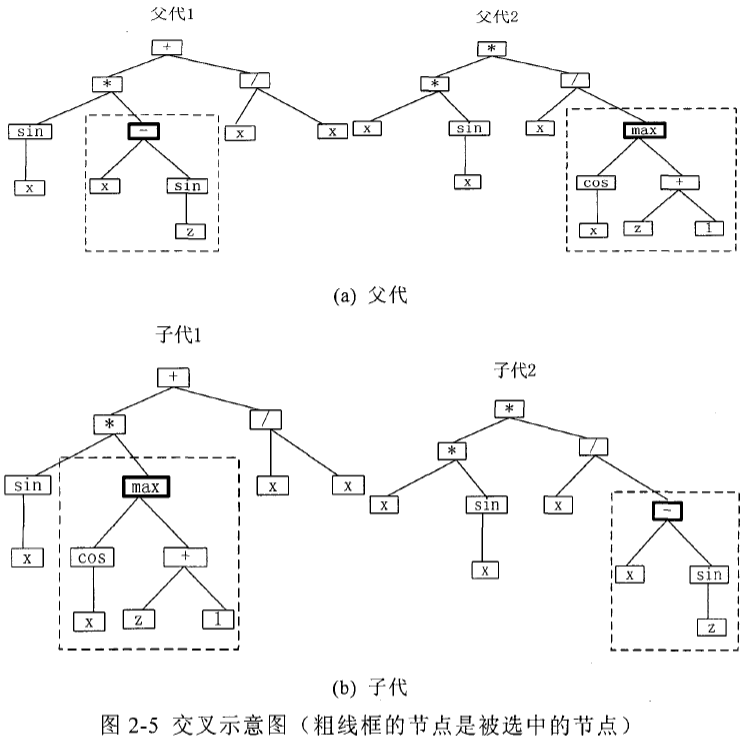
交叉操作的实现步骤如下:首先选择父代,然后,在每个父代个体中随机选取 某个结点作为交叉点,交换父代中以交叉点为根结点的相应子树得到两个后代。图 2-5 给出了交叉的一个例子。
5.3 变异
变异 (Mutation) 模拟的是生物界中基因突变。交叉只对现有的基因进行排列组合,产生不出新的基因材料,容易发生“早熟”现象,而变异有利于形成群体的多样性,使算法有机会从局部最优解中解脱出来。
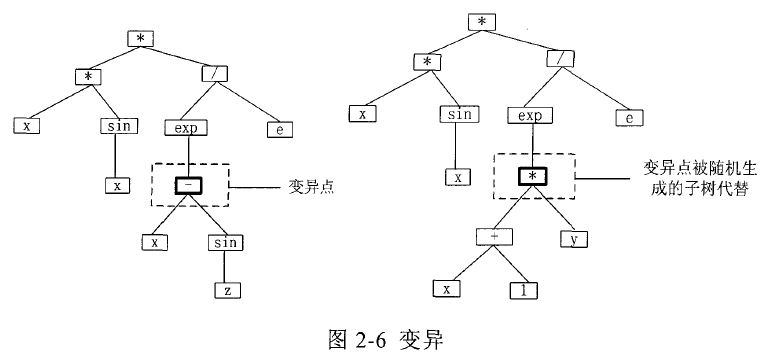
对于每一个个体,产生一个随机数,如果它小于变异概率 Pm,则对此个体执行变异操作。产生变异的一般的方法是:在个体上随机选定一个变异点,变异点一般选择除根之外的任意节点,删掉以变异点为根的子树,然后用随机方法产生新的子树(方法同初始个体的产生方法相同)插入到该变异点处,变异之后的个体树不能超出最大深度限制。图 2-6 给出了一个个体变异的例子。
Reference
[1] 夏炎. 遗传规划理论及其在符号回归中的应用[D].上海交通大学,2007.
[2] 潘小海. 遗传编程的改进及其在符号回归中的应用[D].长沙理工大学,2010.
[3] J. R. Koza. Genetic Programming: On the Programming of Computers by Means of Natural Selection. MIT Press, Cambridge, MA, USA, 1992. ISBN 0-262-11170-5.
[4] Poli, Riccardo, et al. A Field Guide to Genetic Programming. Lulu Press, 2008. The book may be freely downloaded in electronic form at http://www.gp-field-guide.org.uk. ↩︎




](https://img-blog.csdnimg.cn/img_convert/24784a20bb213fbb3a648c1d7cf51552.png)