文章目录
- 1. 缓冲区理解
- 1.1 缓冲区在哪里
- 1.2 刷新策略
- 2. 标准输出和标准错误
- 2.1 模拟perror
1. 缓冲区理解
什么是缓冲区呢?
缓冲区的本质:就是一段内存
为什么要有缓冲区呢?
大家在日常生活中,如果我们想寄东西给朋友,我们会先到快递站去寄。如果没有快递站,我们自己去寄,那么就会耽误自己的时间。那么这个缓冲区就相当于快递站,我们就相当于进程,你的朋友就是外设。缓冲区第一个作用:为了解放使用缓冲区的进程的时间。
缓冲区第二个作用:可以集中处理数据刷新,减少IO的次数,从而达到提高整机的效率的目的。
1.1 缓冲区在哪里
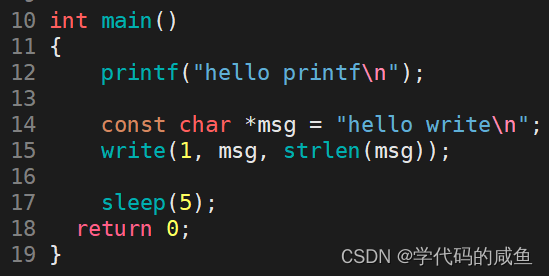
看下面的例子:
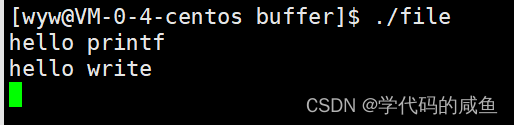
运行结果如下:
然后我们再看这样的:
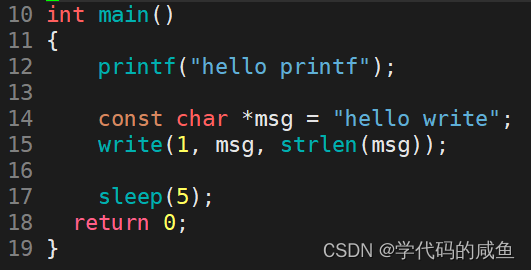
运行结果如下:


为什么会是这个现象,printf为什么一开始不显示了?
我们知道:printf里面的数据没有立即打印出来,是这些数据在缓冲区里了。
但是write是立即刷新了,printf没有立即刷新。而printf里面是封装了write,所以这个缓冲区一定不在write内部,不是内核级别的。那么这个缓冲区只能是C语言提供。
我们知道:在stdout中,它是FILE*的,所以是一个结构体。它里面就封装了语言级别的缓冲区。

我们在使用这些C库里面的函数时,首先并不是直接调用write函数。而是先存到FILE里的缓冲区,然后当这个缓冲区满了的时候,再去调用write函数。
1.2 刷新策略
如果在刷新之前,关闭了fd会有什么问题?
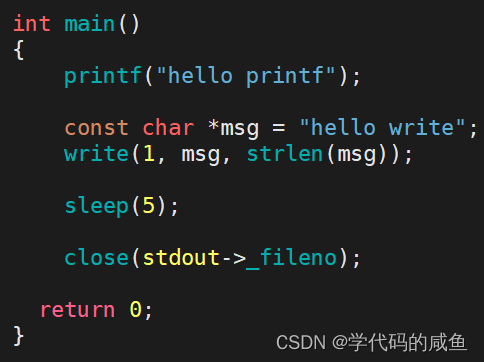
我们把stdout里的fd关上,看一下运行什么情况?

这个情况就说明了,我们在使用C库里面的函数时,并没有及时调用write,而是先存到缓冲区里。我们把fd关上了,write就不能使用了,所以就不会刷新出来。
既然缓冲区在FILE内部,在C语言中,每打开一次文件,就会有一个FILE*返回。那就说明,每一个文件都有一个fd和属于它自己的语言级别的缓冲区。
刷新的几种常见情况:
常规:
1.无缓冲(立即刷新)。
2.行缓冲(逐行刷新),一般是显示器文件。
3.全缓冲(缓冲区满,刷新),一般是块设备对应的文件,也就是磁盘文件。
特殊:
1.进程退出
2.用户强制刷新
看下面的例子:
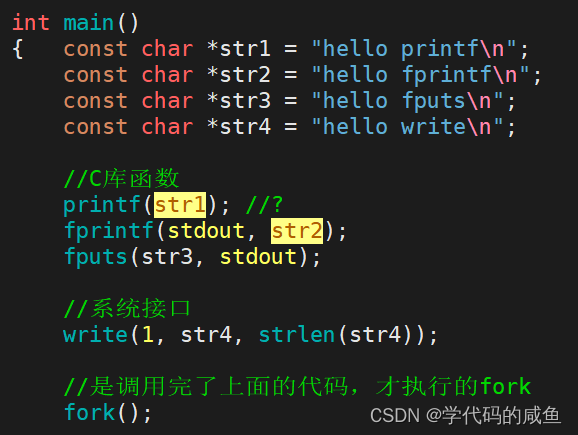
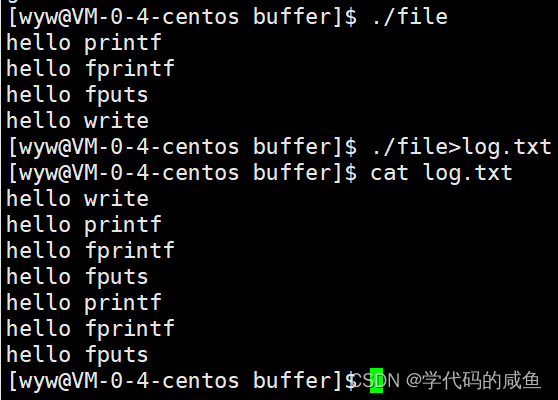
这里第一个很好解释,write不用解释了,因为它直接刷新出来。而三个C库函数是往显示器打印,所以是行刷新,而这三个都带了\n,所以直接刷新出来了。
第二个是什么情况呢?write不用解释,直接刷新。但C库函数都打印了两次,是为什么?
因为我们重定向到了log.txt,是磁盘文件。所以是全刷新。所以这些C库函数并没有刷新,而是先保留在缓冲区里。然后fork之后,进程结束,父子进程开始刷新缓冲区。
缓冲区,是自己的FILE内部维护的,属于父进程内部的数据区域。而刷新的本质,是把缓冲区的数据write到OS内部,清空缓冲区。所以,当任意一方试图写入,便以写时拷贝的方式各自一份副本。
所以会打印两次。
2. 标准输出和标准错误
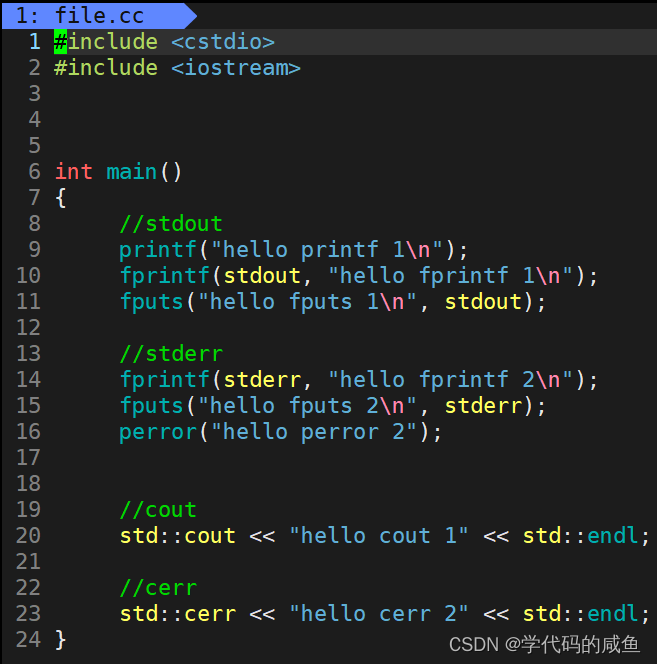
这里C++的命名方式可以有.cpp,.cc,.cxx三种方式。
我们看一下运行结果:
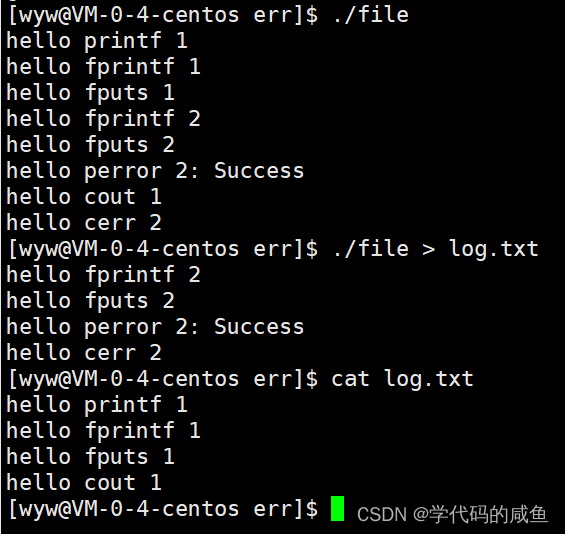
这是为什么呢?我们知道:标准输出是1,标准错误是2。虽然它们都指向通一个硬件,但是不同的fd,所以它们互不影响。在这里,只是对1号文件符重定向,和2号没有关系。
如果我们想把二者重定向到各自文件,怎么办呢?

那么,这样的意义是什么呢?
可以区分哪些是程序日常输出,哪些是错误。方便我们去观察。
如果我们就想混在一起打印呢?
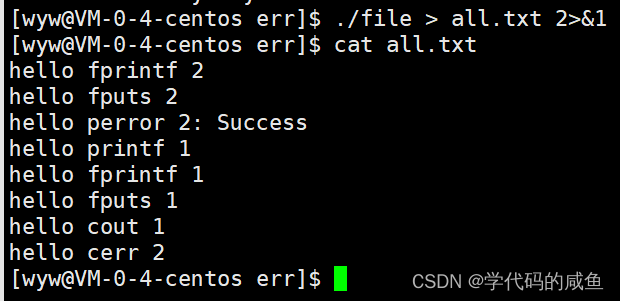
首先,重定向到新文件,说明1和3都指向了all.txt。然后2>&1的意思就是将1的内容拷贝到2,所以1,2,3,都指向了all.txt。

那么这个Success又是什么意思呢?
C语言有一个全局变量,记录最近一次C库函数调用失败的原因。这个变量就是errno。

2.1 模拟perror
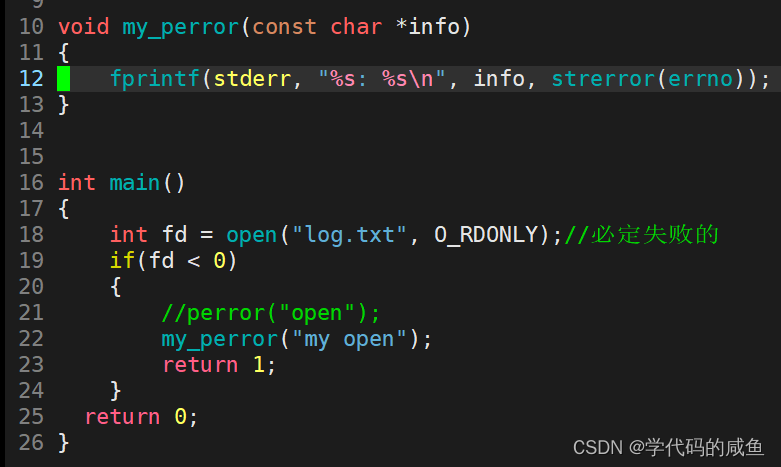
运行结果如下:

结果和perror是一样的。