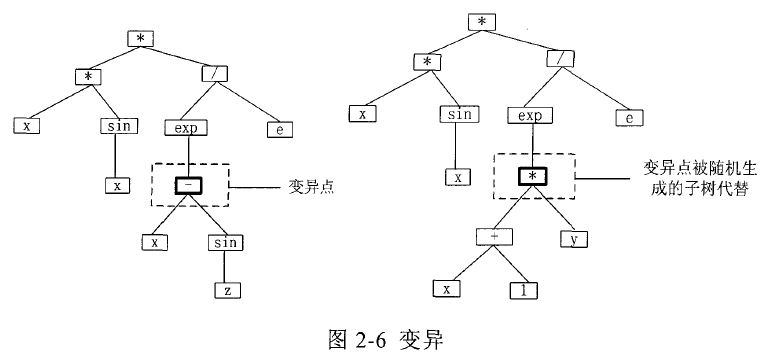
1. 环境规划:
| 主机名 | IP地址 | 角色 |
| node1 | 192.168.56.111 | ElasticSearch(master) Zookeeper Kafka |
| node2 | 192.168.56.112 | ElasticSearch(slave) Kibana Zookeeper Kafka |
| node3 | 192.168.56.113 | ElasticSearch(slave) Zookeeper Kafka |
| node4 | 192.168.56.114 | Logstash Filebeat |
2. node4节点已经安装jdk:
[root@node4 ~]# java -version
java version "1.8.0_202"
Java(TM) SE Runtime Environment (build 1.8.0_202-b08)
Java HotSpot(TM) 64-Bit Server VM (build 25.202-b08, mixed mode)
3. 安装LogStash和Filebeat:
[root@node4 ~]# yum localinstall -y logstash-7.2.0.rpm
[root@node4 ~]# yum localinstall -y filebeat-7.2.0-x86_64.rpm4. 配置Filebeat:
[root@node4 ~]# cd /etc/filebeat/
[root@node4 filebeat]# cp filebeat.yml{,.bak}
##配置filebeat,从日志文件输入,输出到kafka
[root@node4 filebeat]# vim filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/httpd/access_log
fields:
type: httpd-access
multiline.pattern: ^\[
multiline.negate: true
multiline.match: after
- type: log
enabled: true
paths:
- /var/log/httpd/error_log
fields:
type: httpd-error
multiline.pattern: ^\[
multiline.negate: true
multiline.match: after
- type: log
enabled: true
paths:
- /var/log/mariadb/mariadb.log
fields:
type: mariadb
multiline.pattern: ^\[
multiline.negate: true
multiline.match: after
output.kafka:
hosts: ["192.168.56.111:9092","192.168.56.112:9092","192.168.56.113:9092"] ##kafka集群节点
topic: "%{[fields][type]}" ##kafka的标题
multiline参数解析:1. " multiline.type ":默认值是pattern。
2. " multiline.pattern ":匹配日志的正则,一般情况下会配置为从行首开始匹配。
3. " multiline.match,multiline.negate ":multiline.match追加的位置, multiline.negate是否为否定模式。
multiline.match为after,multiline.negate为true的意思就是从匹配的位置开始,只要是不满足匹配条件的,全部追加到匹配的那一行,直到再次遇到匹配条件的位置。
5. 配置logstash:
[root@node4 ~]# cd /etc/logstash/conf.d
##配置logstash:输入为kafka,输出为elasticsearch。
[root@node4 conf.d]# vim all.conf
input{
kafka {
bootstrap_servers => "192.168.56.111:9092,192.168.56.112:9092,192.168.56.113:9092"
codec => json
topics => "httpd-access" ##匹配kafka中的主题
consumer_threads => 1
decorate_events => true
type => "httpd-access" ##用于输出时条件判断
}
kafka {
bootstrap_servers => "192.168.56.111:9092,192.168.56.112:9092,192.168.56.113:9092"
codec => json
topics => "httpd-error" ##匹配kafka中的主题
consumer_threads => 1
decorate_events => true
type => "httpd-error" ##用于输出时条件判断
}
kafka {
bootstrap_servers => "192.168.56.111:9092,192.168.56.112:9092,192.168.56.113:9092"
codec => json
topics => "mariadb" ##匹配kafka中的主题
consumer_threads => 1
decorate_events => true
type => "mariadb" ##用于输出时条件判断
}
}
##输出时如果满足type的判断条件,就按照指定索引输出到elasticsearch上。
output {
if [type] == "httpd-access" {
elasticsearch {
hosts => ["192.168.56.111:9200","192.168.56.112:9200","192.168.56.113:9200"]
index => "httpd-accesslog-%{+yyyy.MM.dd}"
}
}
if [type] == "httpd-error" {
elasticsearch {
hosts => ["192.168.56.111:9200","192.168.56.112:9200","192.168.56.113:9200"]
index => "httpd-errorlog-%{+yyyy.MM.dd}"
}
}
if [type] == "mariadb" {
elasticsearch {
hosts => ["192.168.56.111:9200","192.168.56.112:9200","192.168.56.113:9200"]
index => "mariadblog-%{+yyyy.MM.dd}"
}
}
}
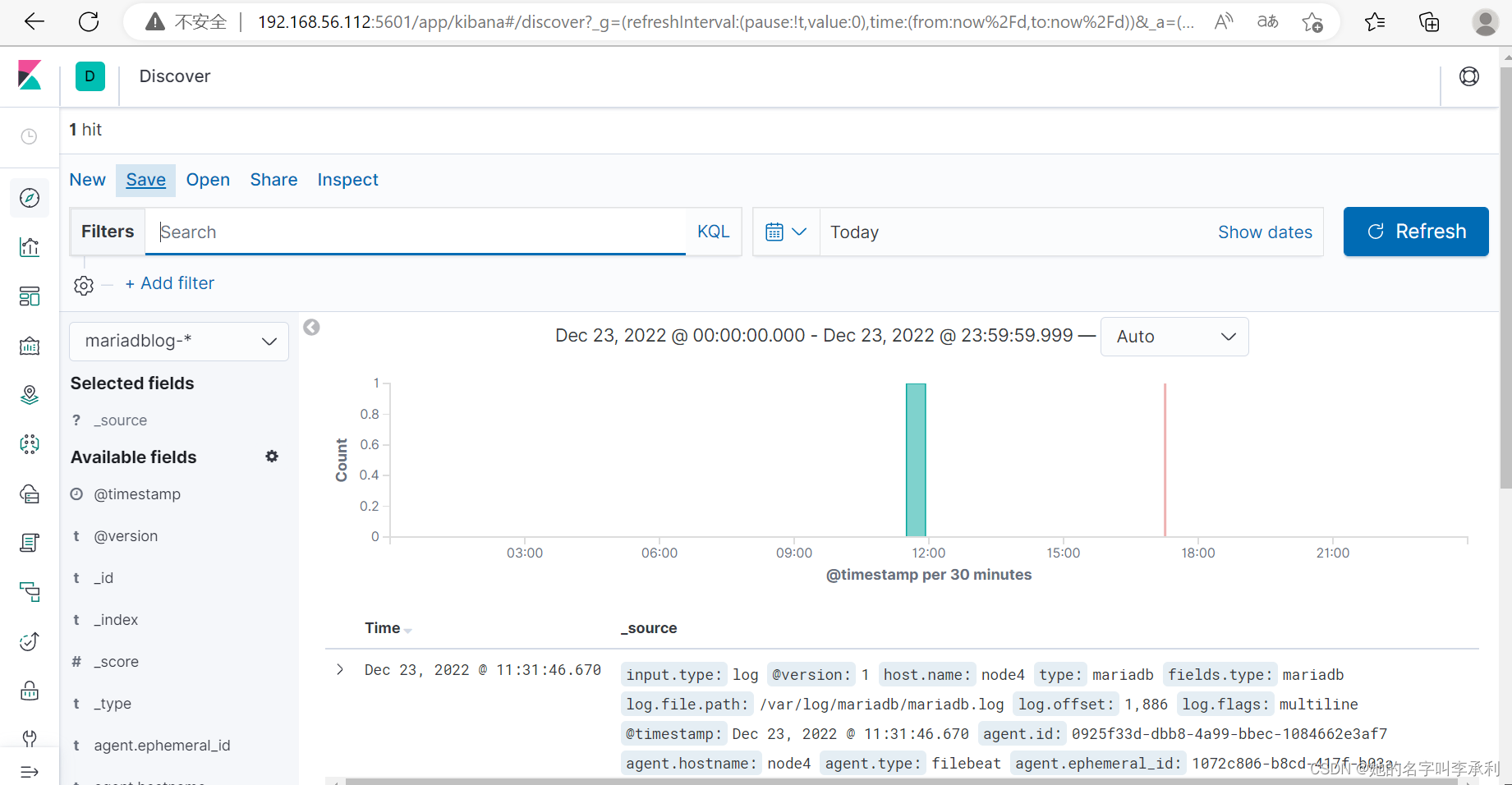
6. 测试Filebeat和LogStash是否可以成功采集到日志。
[root@node4 ~]# cd /etc/filebeat
[root@node4 filebeat]# filebeat -e -c filebeat.yml
另起一个终端启动logstash:
[root@node4 ~]# cd /etc/logstash/conf.d
[root@node4 conf.d]# logstash -f all.conf
访问apache http和登录mariadb,查看elasticsearch上是否采集到指定索引的日志。
如果想以服务方式启动filebeat和logstash,filebeat配置文件名就要是filebeat.yml;logstash配置文件必须要在/etc/filebeat/conf.d目录下,并且后缀为".conf"。
[root@node4 ~]# systemctl start filebeat.service
[root@node4 ~]# systemctl start logstash.service