👑作者主页:@进击的安度因
🏠学习社区:进击的安度因(个人社区)
📖专栏链接:有营养的算法笔记
文章目录
- 一、一维前缀和
- 1、算法推导
- 2、代码实现
- 二、二维前缀和
- 1、算法推导
- 2、代码实现
- 三、一维差分
- 1、算法推导
- 2、代码实现
- 四、二维差分
- 1、算法推导
- 2、代码实现
Hello,小伙伴们,好几天没有更新了,今天更了一篇比较“硬核的文章”。
主要内容为前缀和与差分算法的推导证明和代码实现。这篇文章博主还是画了不少心思的hh,自我感觉这是算法笔记专栏中写的最好的一篇。
话不多说,我们开始今天的算法学习~
一、一维前缀和
1、算法推导
前缀和,从名字上看,我们就大概能知道算法的作用。前缀,就是某位置之前的所有数,为该数的前缀,前缀和,就是对该位置前缀的元素进行求和。
前缀和的模板其实非常简单,它更像是一种思想。
前缀和思想可以快速地解决问题,看个例子:
假如给定一段序列,需要你求出 [ l , r ] [l, r] [l,r] 区间的和,该如何求?
- 最简单的方式就是通过
for循环遍历一遍,时间复杂度为 O ( N ) O(N) O(N) - 而 前缀和算法 ,能在 O ( 1 ) O(1) O(1) 的时间复杂度完成
接下来我们来看,前缀和算法是如何在 O ( 1 ) O(1) O(1) 的时间复杂度求出和的:
前缀和算法主要分为两步,预处理 和 查询 :假设 a , S a, S a,S 分别为 原数组 和 前缀和数组。
预处理 :
预处理就是求 前缀和数组 。对于前缀和数组 s s s ,其中元素满足 S [ i ] = a [ 1 ] + a [ 2 ] + a [ 3 ] . . . a [ i ] S[i] = a[1] + a[2] + a[3] ... a[i] S[i]=a[1]+a[2]+a[3]...a[i]
求前缀和时,下标从 1 1 1 开始。
大体过程如下:
for (int i = 1; i <= n; i++) {
s[i] = s[i - 1] + q[i];
}
前缀和数组每项 s [ i ] s[i] s[i] 是它的前一项 s [ i − 1 ] s[i - 1] s[i−1] 加上原数组 a [ i ] a[i] a[i] 。
因为前缀和数组的前一项 s [ i − 1 ] s[i - 1] s[i−1] ,是 a a a 数组中前 i − 1 i - 1 i−1 中前 i − 1 i - 1 i−1 项的值嘛,所以求 s [ i ] s[i] s[i] 时只要加上 a [ i ] a[i] a[i] 就可以计算出来前 i i i 项的前缀和了。
查询:
查询就是求给定区间 [ l , r ] [l, r] [l,r] 的值。现在由于求出了前缀和数组,那么查询时只要一步 S [ r ] − S [ l − 1 ] S[r] - S[l - 1] S[r]−S[l−1] ,就可以求出结果。
下面讲一下原理:
S
S
S 是前缀和数组,那么
S
S
S 中每一个位置元素都是
a
a
a 数组的前缀和,由此可得:
S
[
r
]
=
a
[
1
]
+
a
[
2
]
+
a
[
3
]
+
.
.
.
+
a
[
l
−
1
]
+
a
[
l
]
+
.
.
.
+
a
[
r
]
S
[
l
−
1
]
=
a
[
1
]
+
a
[
2
]
+
a
[
3
]
+
.
.
.
+
a
[
l
−
1
]
S
[
r
]
−
S
[
l
−
1
]
=
(
a
[
r
]
+
.
.
.
+
a
[
l
]
+
a
[
l
−
1
]
+
.
.
.
+
a
[
3
]
+
a
[
2
]
+
a
[
1
]
)
−
(
a
[
1
]
+
a
[
2
]
+
a
[
3
]
+
.
.
+
a
[
l
−
1
]
)
S
[
r
]
−
S
[
l
−
1
]
=
a
[
r
]
+
.
.
.
+
a
[
l
]
\begin{align} &S[r] \ \ \ \ \ \ = a[1] + a[2] + a[3] + ... + a[l - 1] + a[l] + ... + a[r] \newline \newline &S[l - 1] = \color{red}a[1] + a[2] + a[3] + ... + a[l - 1] \newline \newline &S[r] - S[l - 1] = (a[r] + ... +a[l] + {\color{red}a[l - 1] + ... +a[3] + a[2] + a[1]}) - ({\color{red}a[1] + a[2] + a[3] + .. + a[l - 1]}) \newline \newline &S[r] - S[l - 1] = a[r] + ... +a[l] \end{align}
S[r] =a[1]+a[2]+a[3]+...+a[l−1]+a[l]+...+a[r]S[l−1]=a[1]+a[2]+a[3]+...+a[l−1]S[r]−S[l−1]=(a[r]+...+a[l]+a[l−1]+...+a[3]+a[2]+a[1])−(a[1]+a[2]+a[3]+..+a[l−1])S[r]−S[l−1]=a[r]+...+a[l]
通过这一步骤,它们相同的元素被 抵消 ,最终结果就是 区间 [ l , r ] [l, r] [l,r] 的值 。
所以,我们发现,前缀和多开了一个数组,以达到优化计算时间的效果,是典型的 以空间换时间 的算法。
2、代码实现
接下来做道前缀和例题练练手。
链接:795. 前缀和
描述:
输入一个长度为 n n n 的整数序列。
接下来再输入 m m m 个询问,每个询问输入一对 l , r l, r l,r。
对于每个询问,输出原序列中从第 l l l 个数到第 r r r 个数的和。
输入格式:
第一行包含两个整数 n n n 和 m m m 。
第二行包含 n n n 个整数,表示整数数列。
接下来 m m m 行,每行包含两个整数 l l l 和 r r r ,表示一个询问的区间范围。
输出格式:
共 m m m 行,每行输出一个询问的结果。
数据范围:
- 1 ≤ l ≤ r ≤ n 1≤l≤r≤n 1≤l≤r≤n
- 1 ≤ n , m ≤ 100000 1≤n,m≤100000 1≤n,m≤100000
- − 1000 ≤ 数列中元素的值 ≤ 1000 −1000 ≤ 数列中元素的值 ≤ 1000 −1000≤数列中元素的值≤1000
输入样例:
5 3
2 1 3 6 4
1 2
1 3
2 4
输出样例:
3
6
10
思路 :典型的前缀和例题,思路我们上面已经讲过一遍了,直接开始写代码:

二、二维前缀和
二维前缀和是一维前缀和的加强。
从前只能求一维序列的前缀和,现在能求二维,也就是矩阵的前缀和。
1、算法推导
接下来看 二维前缀和数组 是如何构造的:

假设给定二维矩阵 a 和 s a 和 s a和s , s s s 为前缀和矩阵,这里我们设定一个前提:竖直方向我们统一称为长,横平的边我们统一称为宽,以便我们描述图形。
假如要求 点 ( i , j ) (i, j) (i,j) 的前缀和,那么对于图中,以 i , j i, j i,j 为长和宽的矩阵就是 点 ( i , j ) (i, j) (i,j) 的前缀和。
观察上图,可以得到面积公式:
一整块矩形面积
=
紫色面积
+
绿色面积
+
蓝色面积
+
红色面积
一整块矩形面积 = 紫色面积 + 绿色面积 + 蓝色面积 + 红色面积
一整块矩形面积=紫色面积+绿色面积+蓝色面积+红色面积
但是,对于矩阵的面积,有些地方是无法单独计算的,比如绿色区域,只能算以
i
−
1
i - 1
i−1 为长,
j
j
j 为高的面积。
所以,我们实际计算时,真正的计算公式 为:
一整块矩形面积
=
以
i
−
1
为长以
j
为高的矩形面积
+
以
i
为长以
j
−
1
为高的矩形面积
−
紫色面积
+
红色面积
一整块矩形面积 = 以\ i - 1 \ 为长以 \ j \ 为高的矩形面积 + 以\ i \ 为长以 \ j - 1 \ 为高的矩形面积 - 紫色面积 \ + \ 红色面积
一整块矩形面积=以 i−1 为长以 j 为高的矩形面积+以 i 为长以 j−1 为高的矩形面积−紫色面积 + 红色面积
以图表示:
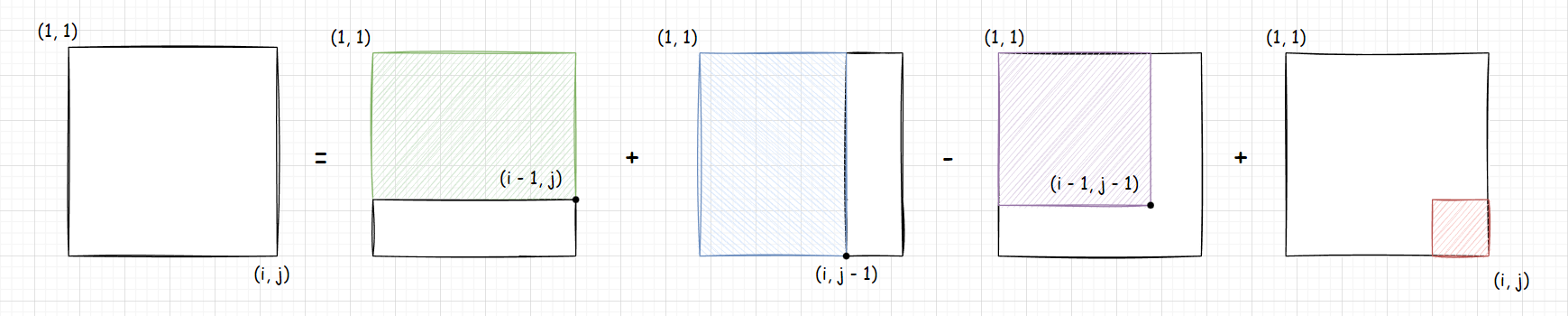
至于为什么要加 紫色区域 呢?这是因为在加绿色矩阵和蓝色矩阵的时候,加了两次 紫色区域 ,所以需要去掉重复的这一块。
而这里的每一个与长和宽有直接关联的区域其实就是这一块区域的 前缀和 ,在
s
s
s 矩阵中都可以表示出来,而 红色小方格的面积 则是
a
a
a 矩阵当前位置的元素,所以我们可以得到 二维矩阵前缀和预处理公式 :
s
[
i
]
[
j
]
=
s
[
i
−
1
]
[
j
]
+
s
[
i
]
[
j
−
1
]
−
s
[
i
−
1
]
[
j
−
1
]
+
a
[
i
]
[
j
]
s[i][j] = s[i - 1][j] + s[i][j - 1] - s[i - 1][j - 1] + a[i][j]
s[i][j]=s[i−1][j]+s[i][j−1]−s[i−1][j−1]+a[i][j]
那么我们构造过程的代码也就可以写出来了:
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
s[i][j] = s[i - 1][j] + s[i][j - 1] - s[i - 1][j - 1] + a[i][j];
}
}
而对于二维前缀和,我们的题型通常是求 子矩阵的和 ,比如:

以我们平常的思维方式,就是 两层循环遍历一下 ,时间复杂度为 O ( N × M ) O(N \times M) O(N×M)。
但是如果我们使用 前缀和 呢?实际上只需要 O ( 1 ) O(1) O(1) 的时间复杂度,是非常快的,但是前提得有公式,所以我们得先把公式推导出来。
推导过程 :
我们再进行严格的区域划分,画一张较为详细的图:
同样的这里设定前提:竖直方向的边统一称为长,横平方向的边统一称为宽,以便我们描述图形。
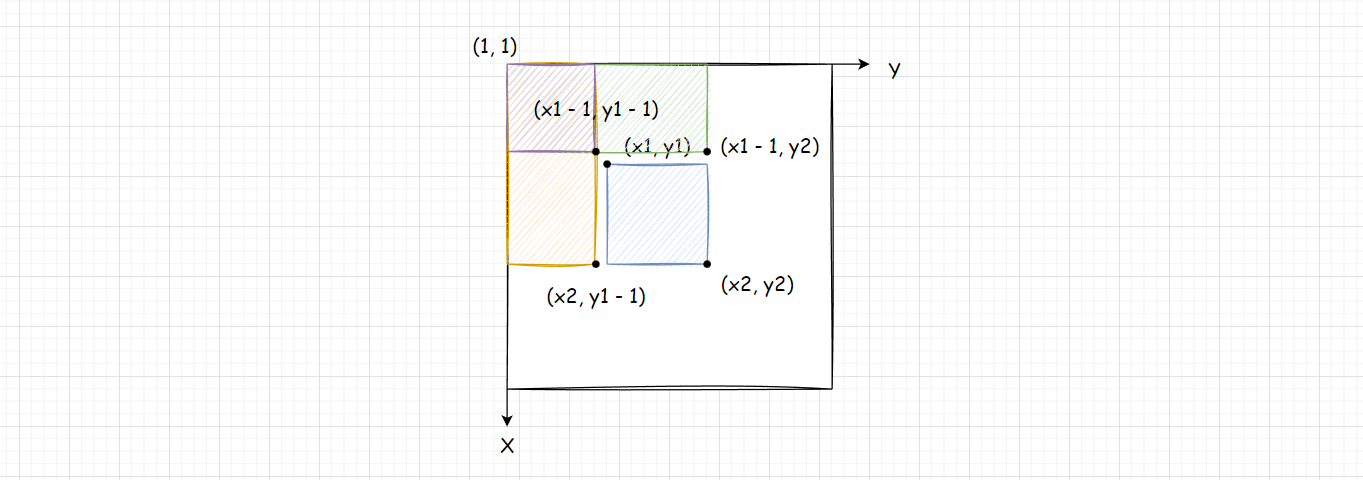
根据上图,我们可以得出公式:
蓝色面积
=
以
x
2
为长,
y
2
为宽的区域面积
−
黄色面积
−
绿色面积
−
紫色面积
蓝色面积 = 以 \ x2 \ 为长,\ y2 \ 为宽的区域面积 - 黄色面积 - 绿色面积 - 紫色面积
蓝色面积=以 x2 为长, y2 为宽的区域面积−黄色面积−绿色面积−紫色面积
但是这里的区域面积也是不好算一小块的,区域的面积的长和宽要从
(
1
,
1
)
(1, 1)
(1,1) 出发,所以我们 真正的公式 为:
蓝色面积
=
以
x
2
为长
y
2
为宽的区域面积
−
以
x
1
−
1
为长
y
2
为宽的区域面积
−
以
x
2
为长
y
1
−
1
为宽的区域面积
+
紫色面积
蓝色面积 = 以 \ x2 \ 为长 \ y2 \ 为宽的区域面积 - 以 \ x1 - 1 为长\ y2 \ 为宽的区域面积 - 以 \ x2 \ 为长 \ y1 - 1 \ 为宽的区域面积 + 紫色面积
蓝色面积=以 x2 为长 y2 为宽的区域面积−以 x1−1为长 y2 为宽的区域面积−以 x2 为长 y1−1 为宽的区域面积+紫色面积
加上 紫色面积 的原因是,我们减去了两块 紫色面积 ,需要补上一个。
同样的,这里每块区域的面积,实际上就是 前缀和 ,比如 紫色面积就是 a a a 矩阵中以 x 1 − 1 x1- 1 x1−1 为长, y 1 − 1 y1 - 1 y1−1 的区域面积,前缀和形式就直接为 s [ x 1 − 1 ] [ y 1 − 1 ] s[x1 -1][y1 - 1] s[x1−1][y1−1]。
所以这里写出我们的 查询公式 :
蓝色面积
=
s
[
x
2
]
[
y
2
]
−
s
[
x
1
−
1
]
[
y
2
]
−
s
[
x
2
]
[
y
1
−
1
]
+
s
[
x
1
−
1
]
[
y
1
−
1
]
蓝色面积 = s[x2][y2] - s[x1 - 1][y2] - s[x2][y1 - 1] + s[x1 - 1][y1 - 1]
蓝色面积=s[x2][y2]−s[x1−1][y2]−s[x2][y1−1]+s[x1−1][y1−1]
到这里,我们的前缀和的核心公式都已经推导出来了,在做题目是就很方便了,只需要:预处理 + 查询 。
2、代码实现
链接:796. 子矩阵的和
描述:
输入一个 n n n 行 m m m 列的整数矩阵,再输入 q q q 个询问,每个询问包含四个整数 x 1 , y 1 , x 2 , y 2 x1,y1,x2,y2 x1,y1,x2,y2,表示一个子矩阵的左上角坐标和右下角坐标。
对于每个询问输出子矩阵中所有数的和。
输入格式:
第一行包含三个整数 n n n, m m m, q q q 。
接下来 n n n 行,每行包含 m m m 个整数,表示整数矩阵。
接下来 q q q 行,每行包含四个整数 x 1 , y 1 , x 2 , y 2 x1,y1,x2,y2 x1,y1,x2,y2 ,表示一组询问。
输出格式:
共 q q q 行,每行输出一个询问的结果。
数据范围:
- 1 ≤ n , m ≤ 1000 1≤n,m≤1000 1≤n,m≤1000
- 1 ≤ q ≤ 200000 1≤q≤200000 1≤q≤200000
- 1 ≤ x 1 ≤ x 2 ≤ n 1≤x1≤x2≤n 1≤x1≤x2≤n
- 1 ≤ y 1 ≤ y 2 ≤ m 1≤y1≤y2≤m 1≤y1≤y2≤m
- − 1000 ≤ 矩阵内元素的值 ≤ 1000 −1000≤矩阵内元素的值≤1000 −1000≤矩阵内元素的值≤1000
输入样例:
3 4 3
1 7 2 4
3 6 2 8
2 1 2 3
1 1 2 2
2 1 3 4
1 3 3 4
输出样例:
17
27
21
思路:
上面公式我们推导过了,直接预处理 + 查询即可:
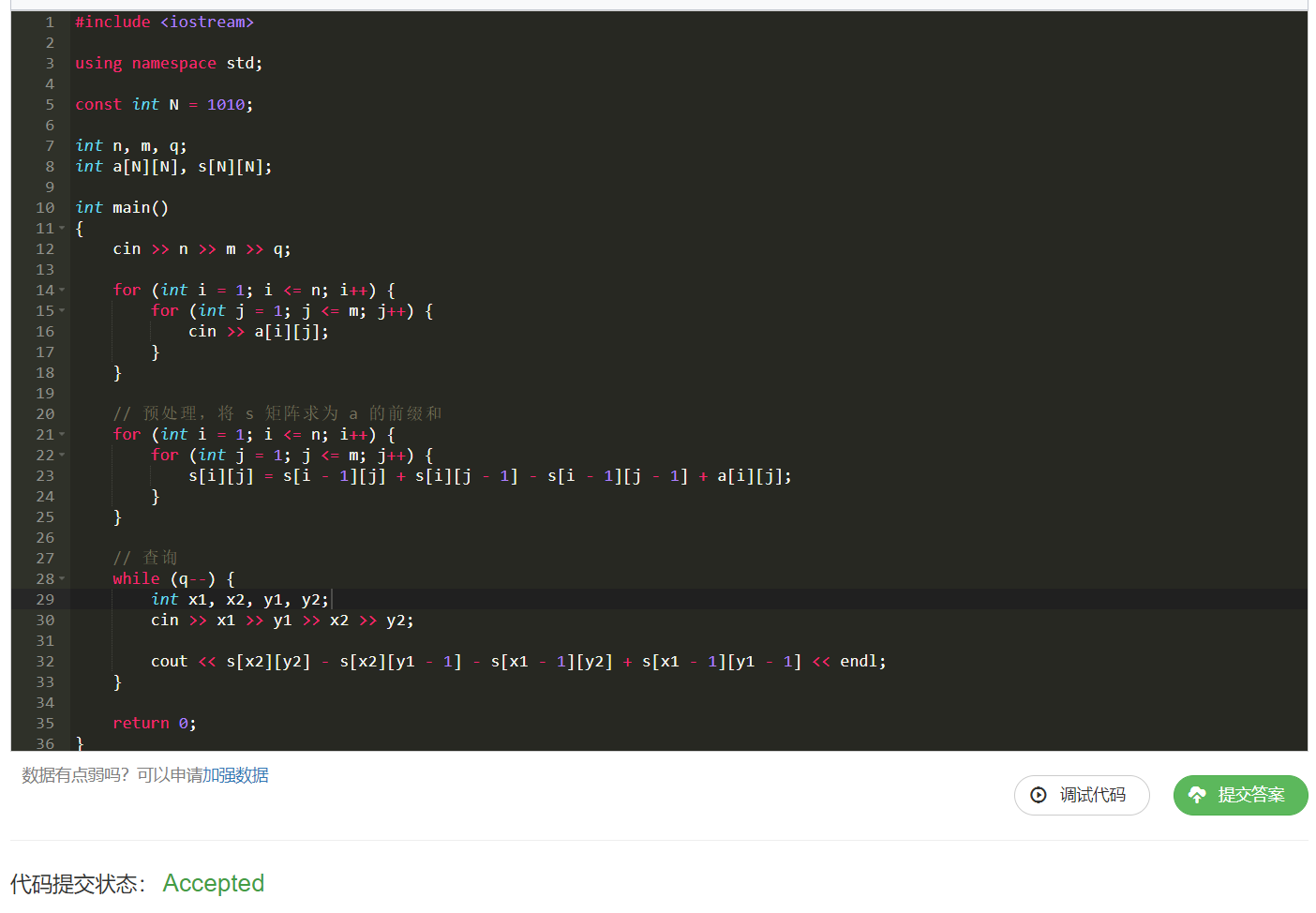
三、一维差分
其实博主觉得差分是一个很抽象的算法,我们可以构造差分数组算,同样的也可以通过另一种方式不构造数组求出结果。
至于为什么我会这么觉得,别急,我们慢慢来,先讲差分的思想再说~
1、算法推导
前面我们学了前缀和,现在又要学差分,它们之间有联系吗?
实际上可以简单推测一下,一个是求 ”和“ ,一个是求 ”差“ ,那 差分是不是就是前缀和的逆运算 ?答案是正确的,差分其实就是前缀和的一个反推。
对于差分算法我们一般得先 构造差分数组 ,假设现在有两个数组 a 和 b a 和\ b a和 b :
我们需要构造 b b b 为差分数组,使得 a a a 数组是 b b b 的前缀和数组 ,也就是说 a a a 中每一个数据,都是 b b b 中在包括这个位置之前所有的数据的和。这时 b b b 被称为 a a a 的差分。
所以 b b b 数组每个元素无非就是 a a a 数组的每一个元素与其前一个元素的差嘛!
为什么这么说?我们来算一下就知道了:
a
[
i
]
=
b
[
1
]
+
b
[
2
]
+
.
.
.
+
b
[
i
]
a
[
i
−
1
]
=
b
[
1
]
+
b
[
2
]
+
.
.
.
+
b
[
i
−
1
]
a
[
i
]
−
a
[
i
−
1
]
=
(
b
[
i
]
+
b
[
i
−
1
]
+
.
.
.
+
b
[
2
]
+
b
[
1
]
)
−
(
b
[
i
−
1
]
+
.
.
.
+
b
[
2
]
+
b
[
1
]
)
=
b
[
i
]
\begin{align} & a[i] \ \ \ \ \ \ \ = b[1] + b[2] + ... + b[i] \newline \newline & a[i - 1] = b[1] + b[2] + ... + b[i - 1] \newline \newline & a[i] - a[i - 1] = ({\color{red}b[i]} + b[i - 1] + ... + b[2] + b[1]) - (b[i - 1] + ... + b[2] + b[1]) = {\color{red}b[i]} \end{align}
a[i] =b[1]+b[2]+...+b[i]a[i−1]=b[1]+b[2]+...+b[i−1]a[i]−a[i−1]=(b[i]+b[i−1]+...+b[2]+b[1])−(b[i−1]+...+b[2]+b[1])=b[i]
所以 差分数组
b
b
b 的构造方式如下 :
一维差分数组构造方式:
{
b
[
1
]
=
a
[
1
]
b
[
2
]
=
a
[
2
]
−
a
[
1
]
b
[
3
]
=
a
[
3
]
−
a
[
2
]
.
.
.
b
[
n
]
=
a
[
n
]
−
a
[
n
−
1
]
一维差分数组构造方式: \begin{cases} b[1] = a[1]\\\\ b[2] = a[2] - a[1]\\\\ b[3] = a[3] - a[2]\\\\ ...\\\\ b[n] = a[n] - a[n - 1] \end{cases}
一维差分数组构造方式:⎩
⎨
⎧b[1]=a[1]b[2]=a[2]−a[1]b[3]=a[3]−a[2]...b[n]=a[n]−a[n−1]
那么这里的 构造过程 实际上就是遍历一遍 a a a 数组,就可以构造出 b b b ,时间复杂度为 O ( N ) O(N) O(N) 。我们再看看代码怎么写:
for (int i = 1; i <= n; i++) {
b[i] = a[i] - a[i - 1];
}
讲完了构造,我们再看看差分这个算法为了解决什么问题:
差分算法是为了解决让 序列中某段区间 [ l , r ] [l, r] [l,r] 加上一个 常数 c c c 的问题。
放到平时,那么我们肯定是遍历一遍,然后把数据 c c c 加上,时间复杂度为 O ( N ) O(N) O(N) ,但是如果使用差分呢?
假设现在 a a a 是原数组,差分数组 b b b 已经求好了,此时要让 a a a 数组 [ l , r ] [l, r] [l,r] 区间内 + c +c +c,只需要让 b [ l ] + = c ,让 b [ r + 1 ] − = c \color{red}b[l] += c,让 b[r + 1] -=c b[l]+=c,让b[r+1]−=c 即可,时间复杂度为 O ( 1 ) O(1) O(1) 。
如下图:

但是为什么这样就可以了,它的原理是什么?我们还得继续探究:
由于
a
a
a 数组是
b
b
b 数组的前缀和,所以让
b
[
l
]
+
=
c
\color{red}b[l] += c
b[l]+=c ,就会造成如下结果:
b
加上
c
后:
b
[
l
]
=
b
[
l
]
′
+
c
a
[
l
]
′
=
b
[
1
]
+
b
[
2
]
+
.
.
.
+
b
[
l
]
′
↓
a
[
l
]
=
b
[
1
]
+
b
[
2
]
+
.
.
.
+
b
[
l
]
′
+
c
↓
当前
a
[
l
]
已经发生了改变:
a
[
l
]
=
a
[
l
]
′
+
c
↓
所以接下来的
a
数组中的元素都会加上
c
!
↓
a
[
l
+
1
]
=
a
[
l
]
′
+
c
+
b
[
l
+
1
]
↓
.
.
.
↓
a
[
n
]
=
a
[
n
−
1
]
′
+
c
+
b
[
n
]
\begin{align} &b \ 加上 \ c \ 后:b[l] = b[l]' + c \\\\ &a[l]' = b[1] + b[2] + ... + b[l]' \\ &\downarrow \\ &a[l] = b[1] + b[2] + ... + \color{red}b[l]' + c \\ &\downarrow \\ &当前 a[l] 已经发生了改变:\color{red}a[l] = a[l]' + c \\ &\downarrow \\ &所以接下来的 a 数组中的元素都会加上 c ! \\ &\downarrow \\ &a[l + 1] = {\color{red}a[l]' + c} + b[l + 1] \\ &\downarrow \\ &... \\ &\downarrow \\ &a[n] = {\color{red}a[n - 1]' + c} + b[n] \end{align}
b 加上 c 后:b[l]=b[l]′+ca[l]′=b[1]+b[2]+...+b[l]′↓a[l]=b[1]+b[2]+...+b[l]′+c↓当前a[l]已经发生了改变:a[l]=a[l]′+c↓所以接下来的a数组中的元素都会加上c!↓a[l+1]=a[l]′+c+b[l+1]↓...↓a[n]=a[n−1]′+c+b[n]
同理,对于
b
[
r
+
1
]
−
=
c
\color{red}b[r + 1] -= c
b[r+1]−=c 也可以推导,下面我就简写一下了:
b
[
r
+
1
]
=
b
[
r
+
1
]
′
−
c
a
[
r
+
1
]
=
a
[
r
]
+
b
[
r
+
1
]
′
−
c
↓
a
[
r
+
1
]
=
a
[
r
+
1
]
′
−
c
↓
a
[
r
+
2
]
=
a
[
r
+
1
]
′
−
c
+
b
[
r
+
2
]
↓
.
.
.
↓
a
[
n
]
=
a
[
n
−
1
]
′
−
c
+
b
[
n
]
\begin{align} &b[r + 1] = b[r + 1]' -c \\\\ &a[r + 1] = a[r] + b[r + 1]' - c \\ &\downarrow \\ &a[r + 1] = a[r + 1]' - c \\ &\downarrow \\ &a[r + 2] = a[r + 1]' - c + b[r + 2] \\ &\downarrow \\ &... \\ &\downarrow \\ &a[n] = a[n - 1]' - c + b[n] \end{align}
b[r+1]=b[r+1]′−ca[r+1]=a[r]+b[r+1]′−c↓a[r+1]=a[r+1]′−c↓a[r+2]=a[r+1]′−c+b[r+2]↓...↓a[n]=a[n−1]′−c+b[n]
由此,得证只要让
b
[
l
]
+
=
c
,让
b
[
r
+
1
]
−
=
c
\color{red}b[l] += c,让 b[r + 1] -=c
b[l]+=c,让b[r+1]−=c,就可以使
a
a
a 数组中
[
l
.
r
]
[l. r]
[l.r] 区间内元素加上 常数
c
c
c 。
2、代码实现
高能预警,代码实现这块就是博主觉得比较抽象,但很神奇的地方。
先上题目 ~
链接:797.差分
描述:
输入一个长度为 n n n 的整数序列。
接下来输入 m m m 个操作,每个操作包含三个整数 l , r , c l,r,c l,r,c 表示将序列中 [ l , r ] [l,r] [l,r] 之间的每个数加上 c c c 。
请你输出进行完所有操作后的序列。
输入格式:
第一行包含两个整数 n n n 和 m m m 。
第二行包含 n n n 个整数,表示整数序列。
接下来 m m m 行,每行包含三个整数 l , r , c l,r,c l,r,c 表示一个操作。
输出格式:
共一行,包含 n n n 个整数,表示最终序列。
数据范围:
- 1 ≤ n , m ≤ 100000 1≤n,m≤100000 1≤n,m≤100000
- 1 ≤ l ≤ r ≤ n 1≤l≤r≤n 1≤l≤r≤n
- − 1000 ≤ c ≤ 1000 −1000≤c≤1000 −1000≤c≤1000
- − 1000 ≤ 整数序列中元素的值 ≤ 1000 −1000≤整数序列中元素的值≤1000 −1000≤整数序列中元素的值≤1000
输入样例:
6 3
1 2 2 1 2 1
1 3 1
3 5 1
1 6 1
输出样例:
3 4 5 3 4 2
代码1:
这段代码就是我们上方 算法推导的完全复刻 ,先构造差分矩阵 b b b ,再根据方法对区间进行操作。
对 b b b 数组完成计算之后,对齐求一下 前缀和 ,将数据存到 a a a 数组中。
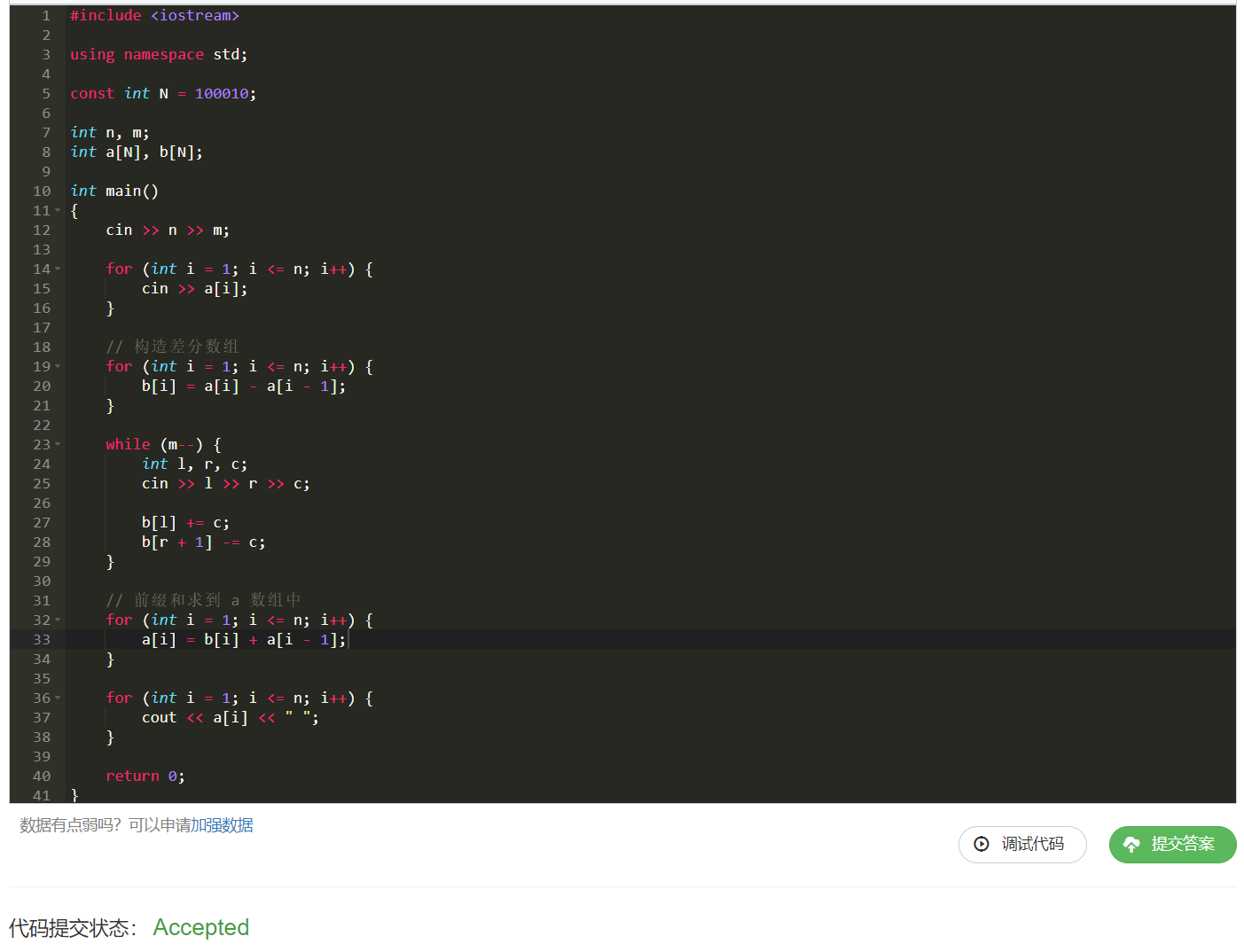
代码2:
但是其实 y 老师讲的其实不是这种方法,他用了更加巧妙的一个方式。
y 老师的思路,是将
a
a
a 数组的所有元素全部假定为 0 ,用了一个 insert 函数,不考虑构造,通过对小区间的插入,和对
[
l
,
r
]
[l, r]
[l,r] 区间的处理,直接完成了对区间
[
l
,
r
]
\color{red}[l, r]
[l,r] 的运算。
它的思路是 单个小区间,也可以说是相同区间 进行数据之间的增加,比如:
a
1
a
2
a
3
.
.
.
a
n
↓
[
1
,
1
]
+
a
[
1
]
[
2
,
2
]
+
a
[
2
]
.
.
.
[
n
,
n
]
+
a
[
n
]
a1 \ a2 \ a3 \ ... an \\ \downarrow \\ [1, 1] + a[1] \ \ \ \ [2, 2] + a[2] \ \ \ \ ... \ \ \ \ [n, n] + a[n]
a1 a2 a3 ...an↓[1,1]+a[1] [2,2]+a[2] ... [n,n]+a[n]
每个数据一开始看做 0 ,这样子就像对每个值进行 +c ,再进行之后
[
l
,
r
]
[l, r]
[l,r] 区间的操作,直接求出结果。
这样就忽略了 构建差分数组 ,直接从结果上求解,运用了 差分的特性:对差分数组求前缀和就算得原数组 ,从而直接求得结果。
先来看一眼代码:
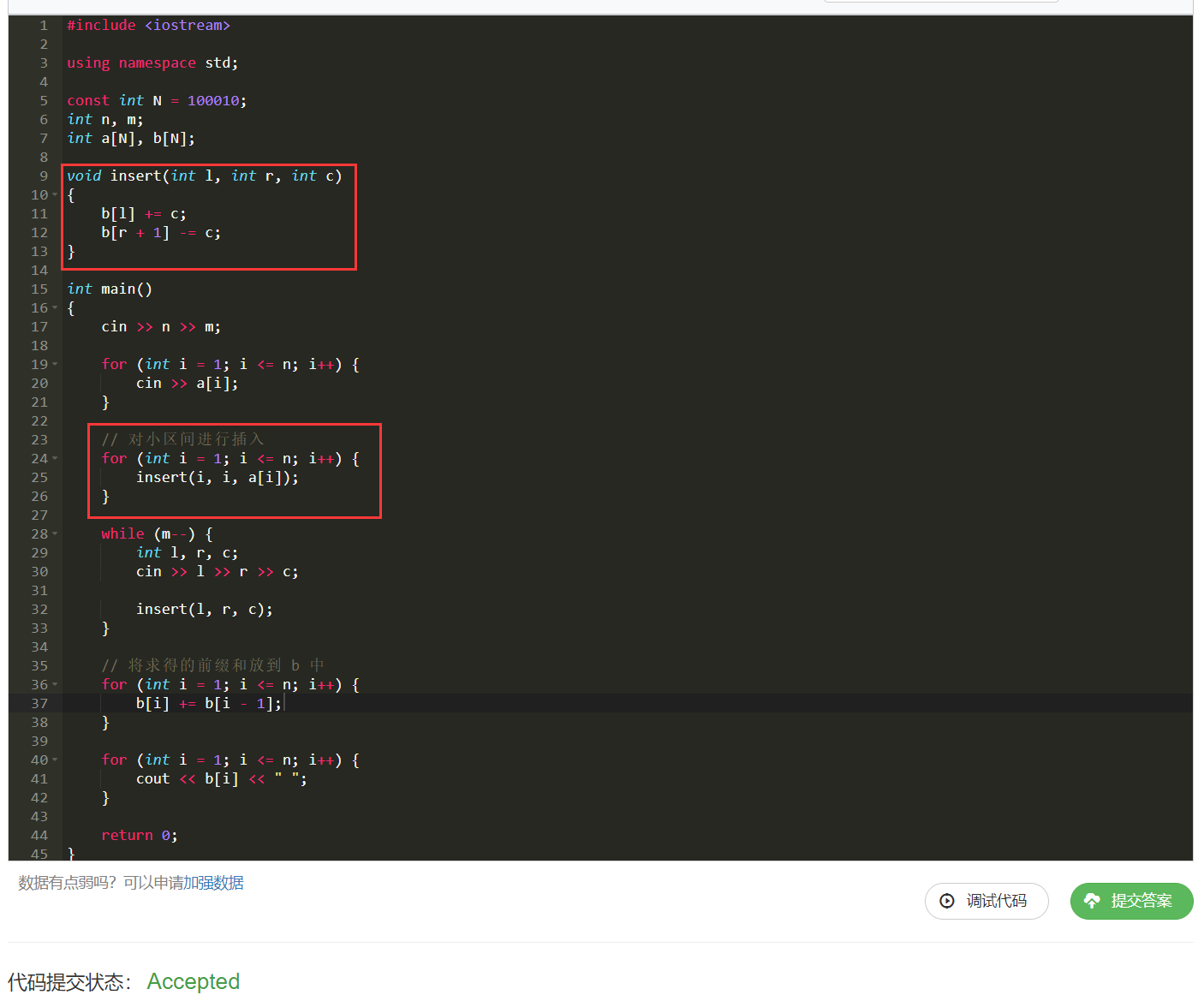
我第一眼看到这个代码我就觉得很惊艳,这是一个很巧妙的做法,但是过一会我就十分疑惑 :
如果我不从最终结果上来看,我就是要看 过程 呢?差分之前说过,第一步就要构建 差分数组 ,之后才能进行求解,但是这里没有构建是怎么算的?
可能是博主比较无聊,就想了好一会,看着代码没想明白,后来把这个过程推了一遍,发现,这一过程真的十分妙!
在上图中,我给出 红色 方框的部分既可以看做对小区间进行数据插入,又可以看做是在构建差分数组。
为什么这么说?下面我们进行一下推导证明:
之间我们推导过如何构造
差分矩阵
b
差分矩阵 b
差分矩阵b ,这里再提一下,这里是 关键 :
一维差分数组构造方式:
{
b
[
1
]
=
a
[
1
]
b
[
2
]
=
a
[
2
]
−
a
[
1
]
b
[
3
]
=
a
[
3
]
−
a
[
2
]
.
.
.
b
[
n
]
=
a
[
n
]
−
a
[
n
−
1
]
一维差分数组构造方式: \begin{cases} b[1] = a[1]\\\\ b[2] = a[2] - a[1]\\\\ b[3] = a[3] - a[2]\\\\ ...\\\\ b[n] = a[n] - a[n - 1] \end{cases}
一维差分数组构造方式:⎩
⎨
⎧b[1]=a[1]b[2]=a[2]−a[1]b[3]=a[3]−a[2]...b[n]=a[n]−a[n−1]
由于
b
b
b 是全局数组,所以一开始元素都是为 0 的。
所以
b
\color{red}b
b 初始状态为:
0
0
0
0
0
0
1
2
3
4
5
6
\begin{align} &\ 0 \ \ \ \ 0 \ \ \ \ 0 \ \ \ \ 0 \ \ \ \ 0 \ \ \ \ 0 \\ \\ & \ 1 \ \ \ \ 2 \ \ \ \ 3 \ \ \ \ 4 \ \ \ \ 5 \ \ \ \ 6 \end{align}
0 0 0 0 0 0 1 2 3 4 5 6
注:这里第一行为
b
b
b 数组,第二行为 下标 ,由于 LaTeX 我用的还不是很熟练,所以还不能很好的控制对齐和缩进,加上标识这个就不对齐了,效果不太好,所以就省略了~大家看到这条之后委屈一下hh,我会尽量说明白的。
现在开始模拟这一过程:
- 第一次循环,
insert(1, 1, a[1]),对 [ 1 , 1 ] [1, 1] [1,1] 进行 a [ 1 ] a[1] a[1] 元素的插入,插入之后结果:
a [ 1 ] − a [ 1 ] 0 0 0 0 1 2 3 4 5 6 \begin{align} & \ {\color{red}a[1]} {\color{blue}-a[1]} \ \ \ \ 0 \ \ \ \ 0 \ \ \ \ 0 \ \ \ \ 0 \\ \\ & \ 1 \ \ \ \ 2 \ \ \ \ 3 \ \ \ \ 4 \ \ \ \ 5 \ \ \ \ 6 \end{align} a[1]−a[1] 0 0 0 0 1 2 3 4 5 6
由于插入过程为:b[l] += c ,b[r + 1] -= c。而我们
l
=
r
=
a
[
1
]
l = r = a[1]
l=r=a[1] ,所以这边就相当于对
b
[
1
]
+
=
a
[
1
]
b[1] += a[1]
b[1]+=a[1],对
b
[
2
]
−
=
a
[
1
]
b[2] -= a[1]
b[2]−=a[1] ,这里还不能看出什么,继续模拟:
- 第二次循环,
insert(2, 2, a[2]),对 [ 2 , 2 ] [2, 2] [2,2] 进行 a [ 2 ] a[2] a[2] 元素的插入,插入之后结果:
a [ 1 ] a [ 2 ] − a [ 1 ] − a [ 2 ] 0 0 0 1 2 3 4 5 6 \begin{align} & \ a[1] \ \ {\color{red}a[2]-a[1]} \ \ {\color{blue}-a[2]} \ \ \ \ 0 \ \ \ \ 0 \ \ \ \ 0 \\ \\ & \ 1 \ \ \ \ 2 \ \ \ \ 3 \ \ \ \ 4 \ \ \ \ 5 \ \ \ \ 6 \end{align} a[1] a[2]−a[1] −a[2] 0 0 0 1 2 3 4 5 6
进行第二次插入后,对 b [ 2 ] + = a [ 2 ] b[2] += a[2] b[2]+=a[2] ,对 b [ 3 ] − = a [ 2 ] b[3] -= a[2] b[3]−=a[2],我们再回顾一下刚刚提到的 如何构造差分数组 b b b 有些不可思议的发现?先别急,我们把这一过程推完再下结论。
- 博主之前已经推过一遍了,这次我们直接跳到最后一次:
a [ 1 ] a [ 2 ] − a [ 1 ] a [ 3 ] − a [ 2 ] a [ 4 ] − a [ 3 ] a [ 5 ] − a [ 4 ] a [ 6 ] − a [ 5 ] 1 2 3 4 5 6 \begin{align} & {\color{green}\ a[1] \ \ a[2]-a[1] \ \ a[3] - a[2] \ \ a[4] - a[3] \ \ a[5] - a[4] \ \ a[6] - a[5]} \\ \\ & \ 1 \ \ \ \ 2 \ \ \ \ 3 \ \ \ \ 4 \ \ \ \ 5 \ \ \ \ 6 \end{align} a[1] a[2]−a[1] a[3]−a[2] a[4]−a[3] a[5]−a[4] a[6]−a[5] 1 2 3 4 5 6
最后这一循环结束的时候的结果是这样的,实际上,这就已经完成了对差分数组的构建 。
再回头看看我们上方画出的重点:如何构造差分矩阵
b
b
b,现在其实就都可以想通了,实际上这一过程就是变相的构造出来了 差分数组。
虽然从表面上是对 小区间插入数据 ,但实际上就是在 构建 ,hhh。
其实就单单从结果上来看还是很简单的,但是往里看点,可能就会陷进去,博主就是其中之一,但是博主比较轴,还是给它推了一下,满足一下自己的好奇心,也是为了下面讲二维做一下铺垫。
到这里,我只能说 y 老师 nb !
四、二维差分
1、算法推导
二维差分是一维差分的一个升级,二维差分,可以对二维数组中某块区域进行 + − +- +− 变换。
假定 a a a 为原二维数组, b b b 为二维差分数组,此时 b b b 为 a a a 的差分数组, a a a 为 b b b 的前缀和数组。
这里其实对于 二维差分数组的构建也是十分有意思的,我们待会再讲,先看如何让二维数组的子矩阵中每个元素的值 + c +c +c :
下图为 二维差分数组 b b b :
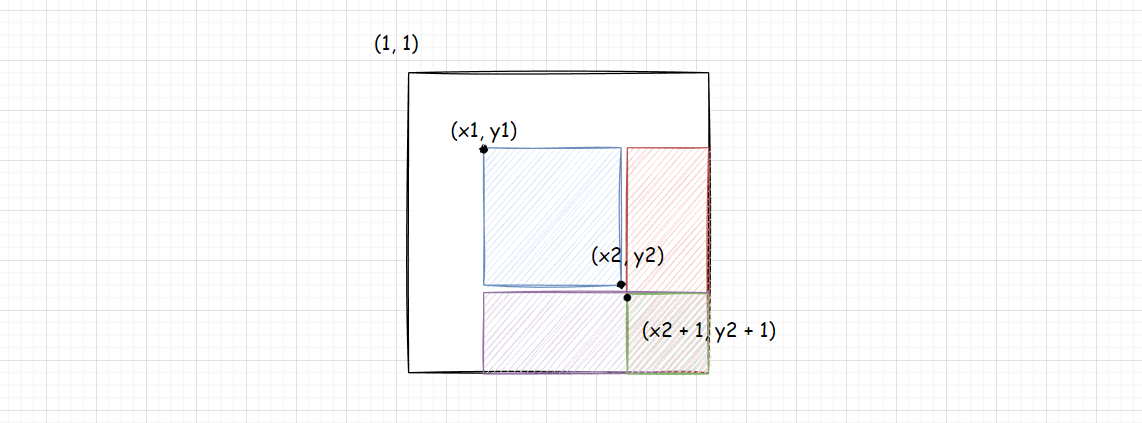
为了更好的理解这个过程,在讲之间,我再把 a a a 数组对应分块画出来:
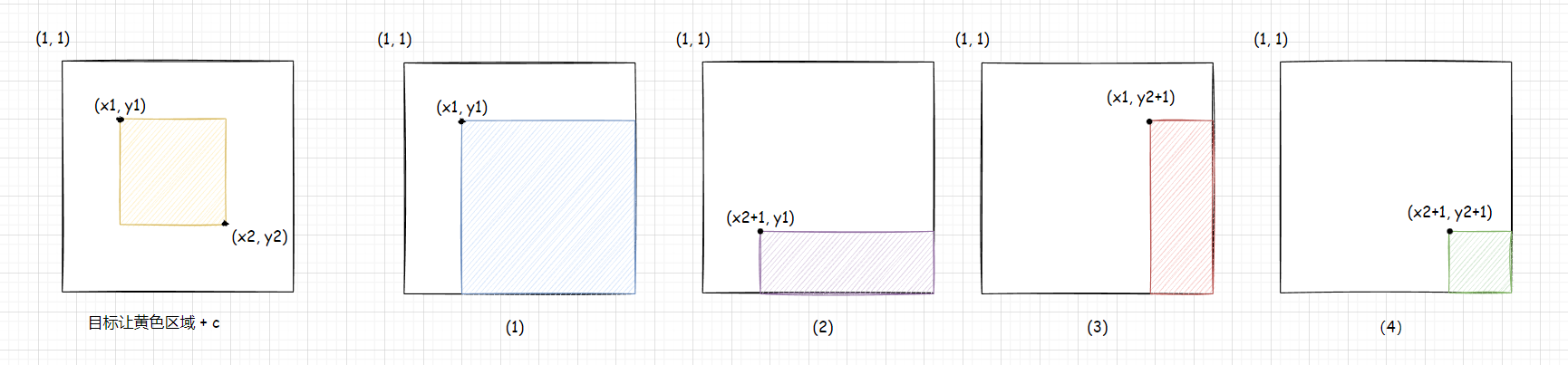
为了使得
a
a
a 数组中 黄色区域 +c ,一共需要对 差分数组
b
b
b 做如下操作:
- b [ x 1 ] [ y 1 ] + = c b[x1][y1] += c b[x1][y1]+=c:由于 a a a 是 b b b 的前缀和数组,所以只要对 b [ x 1 ] [ y 1 ] + = c b[x1][y1] += c b[x1][y1]+=c 就会使得图 ( 1 ) (1) (1) 蓝色面积的元素 + c +c +c,大概的推导我们在一维差分那边推导过,这边就不多赘述了。
- b [ x 2 + 1 ] [ y 1 ] − = c b[x2 + 1][y1] -= c b[x2+1][y1]−=c:使图 ( 2 ) (2) (2) 紫色面积的元素 − c -c −c
- b [ x 1 ] [ y 2 + 1 ] − = c b[x1][y2 + 1] -= c b[x1][y2+1]−=c:使图 ( 3 ) (3) (3) 红色面积的元素 − c -c −c:
- b [ x 2 + 1 ] [ y 2 + 1 ] + = c b[x2 + 1][y2 + 1] += c b[x2+1][y2+1]+=c :使图 ( 4 ) (4) (4) 绿色面积的元素 + c +c +c
至于为什么要让绿色面积加上 c c c 是因为,紫色面积和红色面积重叠部分为绿色面积,绿色面积被减了两次,得补上一次 c c c。
这里的思想其实和一维差分是很相似的,我们可以把一维差分的这些操作看做长度,即区间上的数据改变;
而这里则是通过面积,想要让子矩阵 + c +c +c 那么就让整体减去部分,得到子矩阵的区域,而上方我们减去的紫色和红色区域其实就是和一维差分中的多余部分是相似的。只不过原来在一维的操作扩展到了二维。
到这我们就把具体操作讲完了,接下来就该讲 如何构造二维差分数组 了:
其实讲一维差分的时候,把 y 老师的做法特意抽出来推导一遍就是为了这里。
上方我们证明了,其实在对小区间进行插入的过程中,就完成了对差分数组的构造,那么在这边我们对于二维差分数据的构建是比较麻烦的,这时使用y 老师的办法就显得 非常简单 :
同样的,我们把上方 操作 的代码 封装成 insert 函数 :
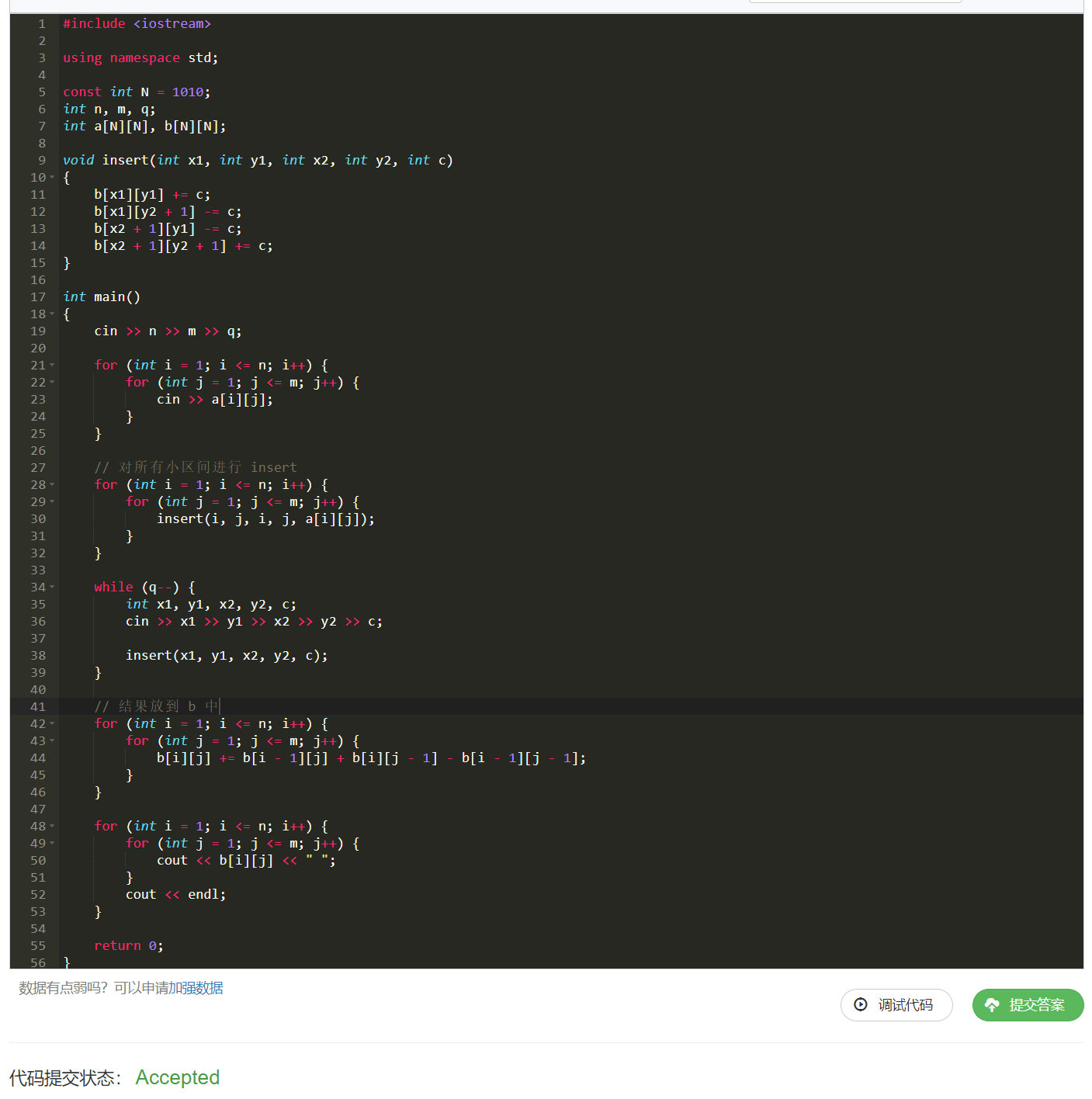
void insert(int x1, int y1, int x2, int y2, int c)
{
b[x1][y1] += c;
b[x1][y2 + 1] -= c;
b[x2 + 1][y1] -= c;
b[x2 + 1][y2 + 1] += c;
}
将 原始数组 a a a 的元素都假想为 0 ,然后把原始数组 a a a 的每个元素想象成一个一个的 小矩阵 ,然后对每个小矩阵进行插入操作,这一过程其实就已经构建出 二维差分数组 :

最后再对需要求的 子矩阵 进行操作就可以求得结果。
那么能不能用构造的方式,把差分数组构建一下,答案是可以的。
其实对于二维差分数组的构建我觉得还是挺麻烦的,所以博主用的是一个 反推 的方式:
之前讲过,
a
a
a 数组是
b
b
b 数组的前缀和,对
b
b
b 数组求前缀和就可以得到
a
a
a 数组的值,公式如下:
a
[
i
]
[
j
]
=
a
[
i
−
1
]
[
j
]
+
a
[
i
]
[
j
−
1
]
−
a
[
i
−
1
]
[
j
−
1
]
+
b
[
i
]
[
j
]
a[i][j] = a[i - 1][j] + a[i][j - 1] - a[i - 1][j - 1] + b[i][j]
a[i][j]=a[i−1][j]+a[i][j−1]−a[i−1][j−1]+b[i][j]
这是我们按照前缀和公式的角度去看的,现在
b
[
i
]
[
j
]
b[i][j]
b[i][j] 实际上就是求前缀和时,加上的小方块的面积,那么算出这个就只要交换一下等式两边的数据就可以:
b
[
i
]
[
j
]
=
a
[
i
]
[
j
]
−
a
[
i
−
1
]
[
j
]
−
a
[
i
]
[
j
−
1
]
+
a
[
i
−
1
]
[
j
−
1
]
;
b[i][j] = a[i][j] - a[i - 1][j] - a[i][j - 1] + a[i - 1][j - 1];
b[i][j]=a[i][j]−a[i−1][j]−a[i][j−1]+a[i−1][j−1];
这就非常简单地得到了 构建差分数组 的公式,比干巴巴地去想如何构建清晰很多。
2、代码实现
链接:798. 差分矩阵
描述:
输入一个 n n n 行 m m m 列的整数矩阵,再输入 q q q 个操作,每个操作包含五个整数 x 1 , y 1 , x 2 , y 2 , c x1,y1,x2,y2,c x1,y1,x2,y2,c 其中 ( x 1 , y 1 ) (x1,y1) (x1,y1) 和 ( x 2 , y 2 ) (x2,y2) (x2,y2)表示一个子矩阵的左上角坐标和右下角坐标。
每个操作都要将选中的子矩阵中的每个元素的值加上 c c c 。
请你将进行完所有操作后的矩阵输出。
输入格式:
第一行包含整数 n , m , q n,m,q n,m,q。
接下来 n n n 行,每行包含 m m m 个整数,表示整数矩阵。
接下来 q q q 行,每行包含 5 5 5 个整数 x 1 , y 1 , x 2 , y 2 , c x1,y1,x2,y2,c x1,y1,x2,y2,c 表示一个操作。
输出格式:
共 n n n 行,每行 m m m 个整数,表示所有操作进行完毕后的最终矩阵。
数据范围:
- 1 ≤ n , m ≤ 1000 1≤n,m≤1000 1≤n,m≤1000
- 1 ≤ q ≤ 100000 1≤q≤100000 1≤q≤100000
- 1 ≤ x 1 ≤ x 2 ≤ n 1≤x1≤x2≤n 1≤x1≤x2≤n
- 1 ≤ y 1 ≤ y 2 ≤ m 1≤y1≤y2≤m 1≤y1≤y2≤m
- − 1000 ≤ c ≤ 1000 −1000≤c≤1000 −1000≤c≤1000
- − 1000 ≤ 矩阵内元素的值 ≤ 1000 −1000≤矩阵内元素的值≤1000 −1000≤矩阵内元素的值≤1000
输入样例:
3 4 3
1 2 2 1
3 2 2 1
1 1 1 1
1 1 2 2 1
1 3 2 3 2
3 1 3 4 1
输出样例:
2 3 4 1
4 3 4 1
2 2 2 2
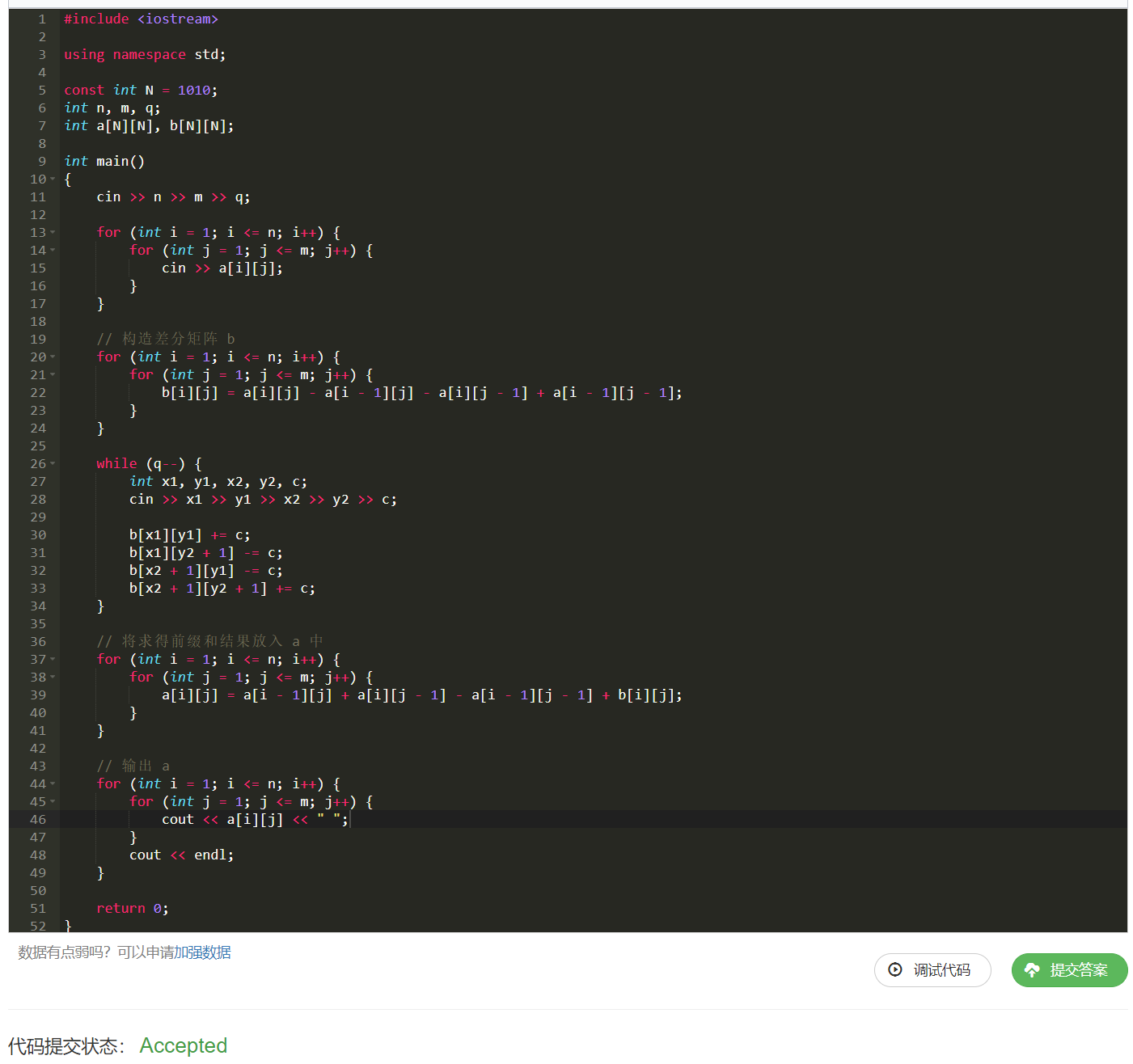
代码1:
常规构造,最终结果将求得结果放入 a a a 中。
代码2:
y 老师用的插入的方式,结果直接放在 b b b 中。
相信看到这里的小伙伴差不多已经对前缀和与差分算法有了一定的了解了。
希望我的文章对你有帮助!
如果觉得anduin写的还不错的话,还请一键三连!如有错误,还请指正!
我是anduin,一名C语言初学者,我们下期见!