❤️作者简介:2022新星计划第三季云原生与云计算赛道Top5🏅、华为云享专家🏅、云原生领域潜力新星🏅
💛博客首页:C站个人主页🌞
💗作者目的:如有错误请指正,将来会不断的完善笔记,帮助更多的Java爱好者入门,共同进步!
文章目录
- 基本理论介绍
- 什么是云原生
- 什么是kubernetes
- kubernetes核心功能
- k8s数据存储(volume)
- 概述
- k8s的基本存储(Volume)
- emptyDir(数据存储在Pod)
- 概述
- emptyDir的实战⭐
- hostPath(数据存储在当前node节点⭐)
- 概述
- hostPath资源清单
- hostPath的实战⭐
- NFS(最可靠,数据存储在NFS服务器⭐)
- 概述
- NFS的实战⭐
- k8s的高级存储
- PV和PVC的概述
- PV(管理员维护⭐)
- PV的资源清单
- 准备工作(准备NFS环境,只在NFS服务器上执行)
- 创建PV
- 查看PV
- PVC(用户维护⭐)
- PVC的资源清单
- 创建PVC
- 查看PVC
- 创建Pod使用PVC
- 创建Pod使用PVC后查看Pod
- 创建Pod使用PVC后查看PVC
- 创建Pod使用PVC后查看PV
- 查看NFS中的文件存储
- PV和PVC的生命周期
- 为什么PVC一直绑定不了PV?⭐
- k8s的配置存储
- ConfigMap(cm)
- 概述
- ConfigMap的资源清单
- 创建ConfigMap
- 创建Pod
- 进入容器查看配置⭐
- Secret
- 概述
- Secret的资源清单
- 准备案例演示数据
- 创建Secret
- 查看Secret详情
- 创建Pod
- 进入容器查看配置⭐
基本理论介绍
什么是云原生
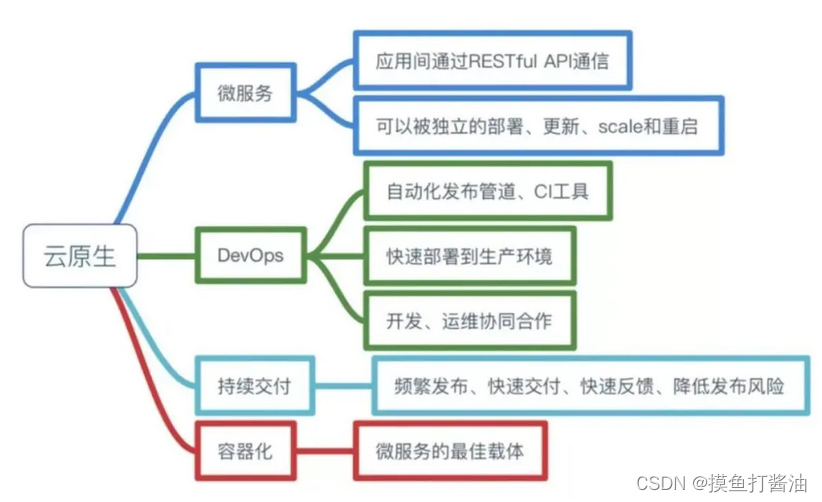
Pivotal公司的Matt Stine于2013年首次提出云原生(Cloud-Native)的概念;2015年,云原生刚推广时,Matt Stine在《迁移到云原生架构》一书中定义了符合云原生架构的几个特征:12因素、微服务、自敏捷架构、基于API协作、扛脆弱性;到了2017年,Matt Stine在接受InfoQ采访时又改了口风,将云原生架构归纳为模块化、可观察、可部署、可测试、可替换、可处理6特质;而Pivotal最新官网对云原生概括为4个要点:DevOps+持续交付+微服务+容器。
总而言之,符合云原生架构的应用程序应该是:采用开源堆栈(K8S+Docker)进行容器化,基于微服务架构提高灵活性和可维护性,借助敏捷方法、DevOps支持持续迭代和运维自动化,利用云平台设施实现弹性伸缩、动态调度、优化资源利用率。
(此处摘选自《知乎-华为云官方帐号》)
什么是kubernetes
kubernetes,简称K8s,是用8代替8个字符"ubernete"而成的缩写。是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes的目标是让部署容器化的应用简单并且高效,Kubernetes提供了应用部署,规划,更新,维护的一种机制。
传统的应用部署方式:是通过插件或脚本来安装应用。这样做的缺点是应用的运行、配置、管理、所有生存周期将与当前操作系统绑定,这样做并不利于应用的升级更新/回滚等操作,当然也可以通过创建虚拟机的方式来实现某些功能,但是虚拟机非常重,并不利于可移植性。
新的部署方式:是通过部署容器方式实现,每个容器之间互相隔离,每个容器有自己的文件系统 ,容器之间进程不会相互影响,能区分计算资源。相对于虚拟机,容器能快速部署,由于容器与底层设施、机器文件系统解耦的,所以它能在不同云、不同版本操作系统间进行迁移。
容器占用资源少、部署快,每个应用可以被打包成一个容器镜像,每个应用与容器间成一对一关系也使容器有更大优势,使用容器可以在build或release 的阶段,为应用创建容器镜像,因为每个应用不需要与其余的应用堆栈组合,也不依赖于生产环境基础结构,这使得从研发到测试、生产能提供一致环境。类似地,容器比虚拟机轻量、更"透明",这更便于监控和管理。
Kubernetes是Google开源的一个容器编排引擎,它支持自动化部署、大规模可伸缩、应用容器化管理。在生产环境中部署一个应用程序时,通常要部署该应用的多个实例以便对应用请求进行负载均衡。
在Kubernetes中,我们可以创建多个容器,每个容器里面运行一个应用实例,然后通过内置的负载均衡策略,实现对这一组应用实例的管理、发现、访问,而这些细节都不需要运维人员去进行复杂的手工配置和处理。
(此处摘选自《百度百科》)
kubernetes核心功能
- 存储系统挂载(数据卷):pod中容器之间共享数据,可以使用数据卷
- 应用健康检测:容器内服务可能进程阻塞无法处理请求,可以设置监控检查策略保证应用健壮性
- 应用实例的复制(实现pod的高可用):pod控制器(deployment)维护着pod副本数量(可以自己进行设置,默认为1),保证一个pod或一组同类的pod数量始终可用,如果pod控制器deployment当前维护的pod数量少于deployment设置的pod数量,则会自动生成一个新的pod,以便数量符合pod控制器,形成高可用。
- Pod的弹性伸缩:根据设定的指标(比如:cpu利用率)自动缩放pod副本数。
- 服务发现:使用环境变量或者DNS插件保证容器中程序发现pod入口访问地址
- 负载均衡:一组pod副本分配一个私有的集群IP地址,负载均衡转发请求到后端容器。在集群内部其他pod可通过这个clusterIP访问应用
- 滚动更新:更新服务不会发生中断,一次更新一个pod,而不是同时删除整个服务。
- 容器编排:通过文件来部署服务,使得应用程序部署变得更高效
- 资源监控:node节点组件集成cAdvisor资源收集工具,可通过Heapster汇总整个集群节点资源数据,然后存储到InfluxDb时序数据库,再由Grafana展示。
- 提供认证和授权:支持角色访问控制(RBAC)认证授权等策略
k8s数据存储(volume)
概述
-
为什么kubernetes会引入数据存储(volume)这个概念呢?
- 主要是因为:容器的生命周期可能很短,它会被频繁的创建和删除。那么容器在删除的时候,保存在容器中的数据也会被清除(且无法找回)。对于企业来说,数据是十分重要的,如果因为容器被删除而导致数据丢失,那可能是一个灾难。为了持久化保存容器中的数据,kubernetes引入了volume这个概念,并且提供了很多种数据持久化方案供用户使用。
-
Volume是Pod中能够被多个容器访问的共享目录,它被定义在Pod上,然后被一个Pod里面的多个容器挂载到具体的文件目录下,kubernetes通过Volume实现同一个Pod中不同容器之间的数据共享以及数据的持久化存储。Volume的生命周期不和Pod中的单个容器的生命周期有关,当容器终止或者重启的时候,Volume中的数据也不会丢失。
-
kubernetes的Volume支持多种类型,比较常见的有下面的几个:
-
简单存储:EmptyDir、HostPath、NFS。(最好的就是NFS,最差的就是EmptyDir)
-
高级存储:PV、PVC。(可以自定义需要多大的存储空间)
-
配置存储:ConfigMap(存储不需要加密的数据)、Secret(存储需要加密的数据,比如密码)
k8s的基本存储(Volume)
- 创建新的目录并跳转进去
[root@k8s-master ~]# mkdir volume && cd volume/
emptyDir(数据存储在Pod)
概述
-
emptyDir是最基础的Volume类型,一个emptyDir就是宿主机上的一个空目录。
-
emptyDir是在Pod被分配到Node时创建的,它的初始内容为空,并且无须指定宿主机上对应的目录文件,因为kubernetes会自动分配一个目录,当Pod销毁时,EmptyDir中的数据也会被永久删除。(所以这种Volume类型不安全,无法保证数据的不丢失,因为当Pod被删除后数据全都会丢失且无法找回。)
-
emptyDir的用途如下:
-
作为临时空间使用,或者里面存储的数据即使丢失了也不会造成影响即可使用,否则不要使用这种类型。例如用于某些应用程序运行时所需的临时目录,且无须永久保留。
-
一个容器需要从另一个容器中获取数据的目录(多容器共享目录)。
emptyDir的实战⭐
案例过程:
1:在一个Pod中准备两个容器nginx和Ubuntu,然后声明一个emptyDir类型volume分别挂载到两个容器的目录中;
2:然后通过访问nginx而产生访问日志信息到/var/log/nginx目录下,通过emptyDir的volume将其日志文件access.log同步到Ubuntu容器的/logs目录下;
3:查看这个Ubuntu容器中的日志文件信息(/logs/access.log),发现有日志数据;
4:然后删除这个Pod,重新使用apply创建Pod;
5:再次进入Ubuntu容器中查看日志文件信息(/logs/access.log),发现日志文件丢失了(说明EmptyDir是将数据存储在Pod中的,当Pod被删除则数据丢失)。
- 1:编辑配置文件:
vim volume-emptydir.yaml
- 内容如下:
- 简单来说,下面的配置相当于(/var/log/nginx和/logs)这两个目录下不管是对哪一个目录进行“写入”的操作,则另外一个目录也会自动进行相同的写入操作(也就是同步)。
apiVersion: v1
kind: Namespace
metadata:
name: test
---
apiVersion: v1
kind: Pod
metadata:
name: volume-emptydir
namespace: test
spec:
containers:
- name: nginx-container
image: nginx:1.22
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
volumeMounts: # 将logs-volume挂载到nginx容器中对应的目录,该目录为/var/log/nginx
- name: volume-logs
mountPath: /var/log/nginx
- name: ubuntu-container
image: ubuntu:22.10
imagePullPolicy: IfNotPresent
command: ["/bin/sh","-c","tail -f /logs/access.log"] # 动态读取从Nginx同步到Ubuntu容器中的log日志文件。
volumeMounts: # 将logs-volume挂载到Ubuntu容器中的对应目录,该目录为/logs
- name: volume-logs
mountPath: /logs
volumes: # 声明volume,name为logs-volume,类型为emptyDir
- name: volume-logs
emptyDir: {} #对应宿主机的空目录,所以当Pod被删除数据将不会存在。
- 2:执行配置文件:
[root@k8s-master volume]# kubectl apply -f volume-emptydir.yaml
namespace/test created
pod/volume-emptydir created
- 3:查看Pod:
[root@k8s-master ~]# kubectl get pods -n test -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
volume-emptydir 2/2 Running 2 3h45m 10.244.232.105 k8s-slave01 <none> <none>
- 4:访问Pod中的Nginx
curl 10.244.232.105
curl 10.244.232.105
- 4:查看指定Pod中的容器的日志:
- volume-emptydir:Pod名称。
- -f:功能类似于tail -f ,都是动态输出日志。
- -c:容器名。
[root@k8s-master ~]# kubectl logs -f volume-emptydir -n test -c ubuntu-container
10.244.235.192 - - [30/Jun/2022:14:37:07 +0000] "GET / HTTP/1.1" 200 615 "-" "curl/7.29.0" "-"
10.244.235.192 - - [30/Jun/2022:14:37:23 +0000] "GET / HTTP/1.1" 200 615 "-" "curl/7.29.0" "-"
- 5:进入Ubuntu容器,并查看从nginx同步过来的日志,目录为/logs/access.log。
[root@k8s-master ~]# kubectl exec -it volume-emptydir -c ubuntu-container -n test /bin/sh
[Ubuntu容器 ~]# cat /logs/access.log
10.244.235.192 - - [30/Jun/2022:14:32:49 +0000] "GET / HTTP/1.1" 200 615 "-" "curl/7.29.0" "-"
10.244.235.192 - - [30/Jun/2022:14:37:07 +0000] "GET / HTTP/1.1" 200 615 "-" "curl/7.29.0" "-"
10.244.235.192 - - [30/Jun/2022:14:37:23 +0000] "GET / HTTP/1.1" 200 615 "-" "curl/7.29.0" "-"
10.244.235.192 - - [30/Jun/2022:14:37:51 +0000] "GET / HTTP/1.1" 200 615 "-" "curl/7.29.0" "-"
10.244.235.192 - - [30/Jun/2022:14:37:52 +0000] "GET / HTTP/1.1" 200 615 "-" "curl/7.29.0" "-"
- 6:删除名称为volume-emptydir的Pod:(测试刚刚volume的数据是否会丢失!)
[root@k8s-master volume]# kubectl delete -f volume-emptydir.yaml
namespace "test" deleted
pod "volume-emptydir" deleted
- 7:重新执行配置文件:
[root@k8s-master volume]# kubectl apply -f volume-emptydir.yaml
namespace/test created
pod/volume-emptydir created
- 8:再次进入Ubuntu容器查看/logs/access.log文件:(执行cat /logs/access.log命令可以看到我们之前的日志信息全部没有了,所以可以知道EmptyDir是将数据存储在Pod中的,当Pod被删除则数据丢失。)
[root@k8s-master volume]# kubectl exec -it volume-emptydir -c ubuntu-container -n test /bin/sh
[Ubuntu容器 ~]# cat /logs/access.log
hostPath(数据存储在当前node节点⭐)
概述
-
emptyDir类型的volume不会持久化数据,当这个Pod被删除了,数据全部都会丢失且无法找回。如果想要数据可以持久化存储,又想要操作简单的话,可以选择hostPath类型的volume,hostPath的特性是会持久化数据到主机上,即便Pod被删除,数据依然存在,相对于emptyDir会更为强大,但是生产环境下还是不建议使用这种hostPath类型的volume的。
-
HostPath就是将Node主机(也就是Pod被调度到的那个宿主机)中的一个实际目录挂载到Pod中,以供容器使用,这样的设计就可以保证Pod销毁了,但是数据依旧可以保存在Node主机上。
-
为什么生产环境下不建议使用这种hostPath类型的volume的?
- 因为我们的数据是持久化存储到主机上(也就是Pod被调度到的那个宿主机)的,如果主机宕机了或者主机炸了,那么数据一样也会丢失,在这种情况下,我们更加建议使用后面将会讲到的NFS,我们把数据持久化到NFS服务器上即可,NFS是会做集群高可用的,所以不用担心数据的丢失问题。
hostPath资源清单
[root@k8s-master ~]# kubectl explain pod.spec.volumes.hostPath
KIND: Pod
VERSION: v1
RESOURCE: hostPath <Object>
DESCRIPTION:
HostPath represents a pre-existing file or directory on the host machine
that is directly exposed to the container. This is generally used for
system agents or other privileged things that are allowed to see the host
machine. Most containers will NOT need this. More info:
https://kubernetes.io/docs/concepts/storage/volumes#hostpath
Represents a host path mapped into a pod. Host path volumes do not support
ownership management or SELinux relabeling.
FIELDS:
path <string> -required-
Path of the directory on the host. If the path is a symlink, it will follow
the link to the real path. More info:
https://kubernetes.io/docs/concepts/storage/volumes#hostpath
type <string>
Type for HostPath Volume Defaults to "" More info:
https://kubernetes.io/docs/concepts/storage/volumes#hostpath
type的值的说明:
-
DirectoryOrCreate:目录存在就使用,不存在就先创建后使用。
-
Directory:目录必须存在。
-
FileOrCreate:文件存在就使用,不存在就先创建后使用。
-
File:文件必须存在。
-
Socket:unix套接字必须存在。
-
CharDevice:字符设备必须存在。
-
BlockDevice:块设备必须存在。
hostPath的实战⭐
案例过程:
1:在一个Pod中准备两个容器nginx和Ubuntu,然后声明一个hostPath类型volume(type为DirectoryOrCreate)分别挂载到两个容器目录➕一个宿主机(也就是Pod被调度到的那个宿主机)目录(/root/volume/logs)上;
2:然后通过访问nginx而产生访问日志信息到/var/log/nginx目录下,通过hostPath的volume将其日志文件access.log同步到Ubuntu容器的/logs目录➕宿主机目录(/root/volume/logs)上;
3:查看这个Ubuntu容器中的日志文件信息(/logs/access.log),发现有日志数据;
4:查看宿主机目录中的nginx日志文件(/root/volume/logs/access.log),发现有日志数据;
5:然后删除这个Pod,重新使用apply创建Pod;
6:再次进入Ubuntu容器中查看日志文件信息(/logs/access.log);
7:再次查看宿主机目录中的nginx日志文件(/root/volume/logs/access.log),发现日志数据存在,说明持久化数据成功。
- 1:创建Pod:
vim volume-hostpath.yaml
- 内容如下:
- 简单来说,下面的配置相当于(/var/log/nginx和/logs和/root/volume/logs)这三个目录下不管是对哪一个目录进行“写入”的操作,则另外两个目录也会自动进行相同的写入操作(也就是同步)。
apiVersion: v1
kind: Namespace
metadata:
name: test
---
apiVersion: v1
kind: Pod
metadata:
name: volume-hostpath
namespace: test
spec:
containers:
- name: nginx-container
image: nginx:1.22
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
volumeMounts: # 将logs-volume挂载到nginx容器中对应的目录,该目录为/var/log/nginx
- name: volume-logs
mountPath: /var/log/nginx
- name: ubuntu-container
image: ubuntu:22.10
imagePullPolicy: IfNotPresent
command: ["/bin/sh","-c","tail -f /logs/access.log"] # 动态读取从Nginx同步到Ubuntu容器中的log日志文件。
volumeMounts: # 将logs-volume挂载到Ubuntu容器中的对应目录,该目录为/logs
- name: volume-logs
mountPath: /logs
volumes: # 声明类型为hostPath的volume,name为volume-logs,对应宿主机目录为/root/volume/logs,并且目录存在就使用,不存在就先创建再使用
- name: volume-logs
hostPath:
path: /root/volume/logs
type: DirectoryOrCreate # 目录存在就使用,不存在就先创建再使用
- 2:执行配置文件:
[root@k8s-master volume]# kubectl apply -f volume-hostpath.yaml
namespace/test created
pod/volume-hostpath created
- 3:查看Pod:
- 注意:可以看到我们的Pod被调度到了k8s-slave01这个宿主机上,也就意味着我们hostPath持久化的数据是存储在k8s-slave01宿主机的/root/volume/logs目录上的。
[root@k8s-master volume]# kubectl get pod volume-hostpath -n test -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
volume-hostpath 2/2 Running 0 32s 10.244.232.111 k8s-slave01 <none> <none>
- 4:访问Pod中的Nginx:
curl 10.244.232.111
curl 10.244.232.111
- 5:进入Ubuntu容器,并查看从nginx同步过来的日志,目录为/logs/access.log。
[root@k8s-master ~]# kubectl exec -it volume-hostpath -c ubuntu-container -n test /bin/sh
[Ubuntu容器 ~]# cat /logs/access.log
192.168.184.101 - - [01/Jul/2022:02:31:59 +0000] "GET / HTTP/1.1" 200 615 "-" "curl/7.29.0" "-"
10.244.235.192 - - [01/Jul/2022:02:32:03 +0000] "GET / HTTP/1.1" 200 615 "-" "curl/7.29.0" "-"
- 6:去node节点(也就是该Pod被调度到的那个宿主机,这里的宿主机就是k8s-slave01)找到hostPath映射的目录中的文件:
[root@k8s-slave01 logs]# cat access.log
192.168.184.101 - - [01/Jul/2022:02:31:59 +0000] "GET / HTTP/1.1" 200 615 "-" "curl/7.29.0" "-"
10.244.235.192 - - [01/Jul/2022:02:32:03 +0000] "GET / HTTP/1.1" 200 615 "-" "curl/7.29.0" "-"
- 7:删除名称为volume-hostpath的Pod:(测试刚刚volume的数据是否会丢失!)
[root@k8s-master volume]# kubectl delete -f volume-hostpath.yaml
namespace "test" deleted
pod "volume-hostpath" deleted
- 8:重新执行配置文件:
[root@k8s-master volume]# kubectl apply -f volume-hostpath.yaml
namespace/test created
pod/volume-hostpath created
- 9:再次进入Ubuntu容器查看/logs/access.log文件:(执行cat /logs/access.log命令可以看到我们数据没有丢失,全部都依然存在,所以可以证明hostPath类型的volume可以持久化数据!)
[root@k8s-master volume]# kubectl exec -it volume-hostpath -c ubuntu-container -n test /bin/sh
[Ubuntu容器 ~]# cat /logs/access.log
192.168.184.101 - - [01/Jul/2022:02:31:59 +0000] "GET / HTTP/1.1" 200 615 "-" "curl/7.29.0" "-"
10.244.235.192 - - [01/Jul/2022:02:32:03 +0000] "GET / HTTP/1.1" 200 615 "-" "curl/7.29.0" "-"
- 10:再次进入node节点(也就是该Pod被调度到的那个宿主机,这里的宿主机就是k8s-slave01)找到hostPath映射的目录中的文件:(数据依然存在,所以可以证明hostPath类型的volume可以持久化数据)
[root@k8s-slave01 logs]# cat access.log
192.168.184.101 - - [01/Jul/2022:02:31:59 +0000] "GET / HTTP/1.1" 200 615 "-" "curl/7.29.0" "-"
10.244.235.192 - - [01/Jul/2022:02:32:03 +0000] "GET / HTTP/1.1" 200 615 "-" "curl/7.29.0" "-"
NFS(最可靠,数据存储在NFS服务器⭐)
概述
-
hostPath虽然可以解决数据持久化的问题,但是一旦Node节点故障或者被删除了,Pod如果转移到别的Node节点上,又会出现问题,此时需要准备单独的网络存储系统,比较常用的是NFS和CIFS。
-
NFS是一个网络文件存储系统,可以搭建一台NFS服务器,然后将Pod中的存储直接连接到NFS系统上,这样,无论Pod在节点上怎么转移,只要Node和NFS的对接没有问题,数据就可以成功访问。
NFS的实战⭐
案例过程:
1:为了方便演示,这里不重新新建一个单独的服务器作NFS,我们把Master节点所在的服务器作为NFS服务器!(也就是搭建NFS服务器);----->如果已经搭建了NFS服务器的话可以跳过这一步!!!!!
2:在一个Pod中准备两个容器nginx和Ubuntu,然后声明一个nfs类型volume分别挂载到两个容器目录➕一个nfs服务器的共享目录(/root/data/nfs)上;
3:然后通过访问nginx而产生访问日志信息到/var/log/nginx目录下,通过nfs的volume将其日志文件access.log同步到Ubuntu容器的/logs目录➕nfs服务器的共享目录(/root/data/nfs)上;
4:查看这个Ubuntu容器中的日志文件信息(/logs/access.log),发现有日志数据;
5:查看nfs服务器的共享目录(/root/data/nfs)上,发现有日志数据;
6:然后删除这个Pod,重新使用apply创建Pod;
7:再次进入Ubuntu容器中查看日志文件信息(/logs/access.log);
8:再次查看nfs服务器的共享目录(/root/data/nfs)上,发现日志数据存在,说明持久化数据成功。
- 1:搭建NFS服务器:(为了方便演示,这里不重新新建一个单独的服务器,我们把Master节点所在的服务器作为NFS服务器!)
注意:这里的命令都在NFS服务器(这里也就是在Master节点)上执行!!
- 在Master节点上安装NFS服务器:
yum install -y nfs-utils rpcbind
- 在NFS服务器(这里我们的NFS服务器就是Master节点服务器)上创建一个共享目录:
[root@k8s-master volume]# mkdir -pv /root/data/nfs
mkdir: 已创建目录 "/root/data"
mkdir: 已创建目录 "/root/data/nfs"
- 因为我们的k8s的IP地址就是192.168.184.xxx,所以在Master节点将共享目录以读写权限暴露给192.168.184.0/24网段中的所有主机:
- 192.168.184.0/24:允许其访问的NFS服务端的客户端地址,可以是客户端IP地址,也可以是一个网段(192.168.184.0/24),或者是*表示所有客户端IP都可以访问
vim /etc/exports
添加内容如下:(记得修改成自己服务器的网段!!!)
/root/data/nfs 192.168.184.0/24(rw,no_root_squash)
- 在Master节点给共享目录修改权限:
chmod 777 -R /root/data/nfs
- 在Master节点加载配置:
exportfs -r
- 在Master节点上启动NFS服务(此时的Master节点才正式变成一个NFS服务器!):
systemctl start rpcbind
systemctl enable rpcbind
systemctl start nfs
systemctl enable nfs
- 在Master节点测试是否挂载成功:(如果不执行上面的命令,这里会提示命令未找到)
[root@k8s-master volume]# showmount -e 192.168.184.100
Export list for 192.168.184.100:
/root/data/nfs 192.168.184.0/24
注意:这里的命令都在slave/node节点(也就是在NFS之外的节点)上执行!!
- 在Node节点上都安装NFS服务器,目的是为了Node节点可以驱动NFS设备:
# 在Node节点上安装NFS服务,不需要启动
yum -y install nfs-utils
- 在Node节点测试是否挂载成功:
[root@k8s-slave01 ~]# showmount -e 192.168.184.100
Export list for 192.168.184.100:
/root/data/nfs 192.168.184.0/24
注意:这里的命令在所有节点上(包括NFS和NFS之外的node节点上)都要执行!!
- 高可用备份方式,在所有节点执行如下的命令:(记得修改成自己的NFS服务器的IP地址)
mount -t nfs 192.168.184.100:/root/data/nfs /mnt
⭐现在我们的NFS服务器就正式搭建好了,下面我们就来使用这个NFS进行持久化数据!!!⭐
- 2:创建Pod:
vim volume-nfs.yaml
- 内容如下:
- 简单来说,下面的配置相当于(/var/log/nginx和/logs和nfs服务器的/root/data/nfs)这三个目录下不管是对哪一个目录进行“写入”的操作,则另外两个目录也会自动进行相同的写入操作(也就是同步)。
apiVersion: v1
kind: Namespace
metadata:
name: test
---
apiVersion: v1
kind: Pod
metadata:
name: volume-nfs
namespace: test
spec:
containers:
- name: nginx-container
image: nginx:1.22
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
volumeMounts: # 将logs-volume挂载到nginx容器中对应的目录,该目录为/var/log/nginx
- name: volume-logs
mountPath: /var/log/nginx
- name: ubuntu-container
image: ubuntu:22.10
imagePullPolicy: IfNotPresent
command: ["/bin/sh","-c","tail -f /logs/access.log"] # 动态读取从Nginx同步到Ubuntu容器中的log日志文件。
volumeMounts: # 将logs-volume挂载到Ubuntu容器中的对应目录,该目录为/logs
- name: volume-logs
mountPath: /logs
volumes: # 声明类型为nfs的volume,name为volume-logs,对应nfs服务器的ip地址为192.168.184.100,nfs共享目录为/root/data/nfs。
- name: volume-logs
nfs:
server: 192.168.184.100 # NFS服务器地址
path: /root/data/nfs # 共享文件路径
- 3:执行配置文件:
[root@k8s-master volume]# kubectl apply -f volume-nfs.yaml
namespace/test created
pod/volume-nfs created
- 4:查看Pod:
[root@k8s-master volume]# kubectl get pod volume-nfs -n test -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
volume-nfs 2/2 Running 0 3m22s 10.244.232.113 k8s-slave01 <none> <none>
- 5:访问Pod中的Nginx:
curl 10.244.232.113
curl 10.244.232.113
- 6:进入Ubuntu容器,并查看从nginx同步过来的日志,目录为/logs/access.log。
[root@k8s-master ~]# kubectl exec -it volume-nfs -c ubuntu-container -n test /bin/sh
[Ubuntu容器 ~]# cat /logs/access.log
10.244.235.192 - - [01/Jul/2022:09:44:23 +0000] "GET / HTTP/1.1" 200 615 "-" "curl/7.29.0" "-"
10.244.235.192 - - [01/Jul/2022:09:44:24 +0000] "GET / HTTP/1.1" 200 615 "-" "curl/7.29.0" "-"
- 7:切换到NFS服务器(我们设置的是192.168.184.100这个服务器)中的共享目录(/root/data/nfs)找access.log:
[root@k8s-master ~]# cat /root/data/nfs/access.log
10.244.235.192 - - [01/Jul/2022:09:44:23 +0000] "GET / HTTP/1.1" 200 615 "-" "curl/7.29.0" "-"
10.244.235.192 - - [01/Jul/2022:09:44:24 +0000] "GET / HTTP/1.1" 200 615 "-" "curl/7.29.0" "-"
- 8:删除名称为volume-hostpath的Pod:(测试刚刚volume的数据是否会丢失!)
[root@k8s-master ~]# kubectl delete -f /root/volume/volume-nfs.yaml
namespace "test" deleted
pod "volume-nfs" deleted
- 9:重新执行配置文件:
[root@k8s-master ~]# kubectl apply -f /root/volume/volume-nfs.yaml
namespace/test created
pod/volume-nfs created
- 10:再次进入Ubuntu容器查看/logs/access.log文件:
[root@k8s-master volume]# kubectl exec -it volume-nfs -c ubuntu-container -n test /bin/sh
[Ubuntu容器 ~]# cat /logs/access.log
10.244.235.192 - - [01/Jul/2022:09:44:23 +0000] "GET / HTTP/1.1" 200 615 "-" "curl/7.29.0" "-"
10.244.235.192 - - [01/Jul/2022:09:44:24 +0000] "GET / HTTP/1.1" 200 615 "-" "curl/7.29.0" "-"
- 11:再次切换到NFS服务器(我们设置的是192.168.184.100这个服务器)中的共享目录(/root/data/nfs)找access.log:
[root@k8s-master ~]# cat /root/data/nfs/access.log
10.244.235.192 - - [01/Jul/2022:09:44:23 +0000] "GET / HTTP/1.1" 200 615 "-" "curl/7.29.0" "-"
10.244.235.192 - - [01/Jul/2022:09:44:24 +0000] "GET / HTTP/1.1" 200 615 "-" "curl/7.29.0" "-"
k8s的高级存储
PV和PVC的概述
-
为什么会出现PV和PVC这个东西?它们能够为我们解决什么问题?
-
原因是:上面我们讲解了NFS类型的volume,这个时候就会出现一个至关重要的问题,那就是需要我们用户要会搭建NFS环境,并且会在yaml配置文件使用NFS(说白了就是分工不够明确。),如果用户不想使用NFS而想使用其他类型的volume的话,又需要重新学习这个类型的volume使用方法,而kubernetes提供的存储类型有很多,想要用户全部掌握,显然这是不现实。为了能够屏蔽底层存储实现的细节,方便用户使用,kubernetes引入了PV和PVC两种资源对象。
-
PV和PVC能够为我们解决一个问题,就是分工合作,专业的人干专业的事,用户只管使用,剩下的底层技术均由k8s管理员实现:
-
存储:存储工程师维护。
-
PV:kubernetes管理员维护。
-
PVC:kubernetes用户维护。
-
-
PV(Persistent Volume)是持久化卷的意思,是对底层的共享存储的一种抽象。一般情况下PV由kubernetes管理员进行创建和配置,它和底层具体的共享存储技术有关,并通过插件完成和共享存储的对接。
-
PVC(Persistent Volume Claim)是持久化卷声明的意思,是用户对于存储需求的一种声明。换言之,PVC其实就是用户向kubernetes系统发出的一种资源需求申请。
PV(管理员维护⭐)
PV的资源清单
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv1
spec:
nfs: # 存储类型,和底层正则的存储对应
path:
server:
capacity: # 存储能力,目前只支持存储空间的设置
storage: 2Gi
accessModes: # 访问模式
- xxx
storageClassName: # 存储类别
persistentVolumeReclaimPolicy: # 回收策略
pv的关键配置参数说明:
-
存储类型:底层实际存储的类型,kubernetes支持多种存储类型,每种存储类型的配置有所不同(比如nfs等等)。
-
存储能力(capacity):目前只支持存储空间的设置(storage=1Gi)。
-
访问模式(accessModes):
-
用来描述用户对存储资源的访问权限,访问权限包括下面几种方式:
-
ReadWriteOnce(RWO):读写权限,但是只能被单个节点挂载。
- ReadOnlyMany(ROX):只读权限,可以被多个节点挂载。
- ReadWriteMany(RWX):读写权限,可以被多个节点挂载。
-
需要注意的是,底层不同的存储类型可能支持的访问模式不同。
-
回收策略( persistentVolumeReclaimPolicy):
-
-当PV不再被使用之后,对其的处理方式,目前支持三种策略:
-
Retain(保留):保留数据,需要管理员手动清理数据。
-
Recycle(回收):清除PV中的数据,效果相当于
rm -rf /volume/*。 -
Delete(删除):和PV相连的后端存储完成volume的删除操作,常见于云服务器厂商的存储服务。
-
需要注意的是,底层不同的存储类型可能支持的回收策略不同。
-
存储类别(storageClassName):PV可以通过storageClassName参数指定一个存储类别。
-
具有特定类型的PV只能和请求了该类别的PVC进行绑定。
-
未设定类别的PV只能和不请求任何类别的PVC进行绑定。
-
状态(status):一个PV的生命周期,可能会处于4种不同的阶段。
-
Available(可用,未绑定):表示可用状态,还未被任何PVC绑定。
-
Bound(已绑定):表示PV已经被PVC绑定。
-
Released(已释放):表示PVC被删除,但是资源还没有被集群重新释放。
-
Failed(失败):表示该PV的自动回收失败。
准备工作(准备NFS环境,只在NFS服务器上执行)
在NFS服务器(这里也就是Master节点)上执行
- 1:创建共享目录:
[root@k8s-master ~]# mkdir -pv /root/data/{pv1,pv2,pv3}
mkdir: 已创建目录 "/root/data/pv1"
mkdir: 已创建目录 "/root/data/pv2"
mkdir: 已创建目录 "/root/data/pv3"
- 2:给共享目录分配权限:
chmod 777 -R /root/data
- 3:修改/etc/exports文件:
vim /etc/exports
添加内容如下:(记住网段要写成你自己服务器的网段,我们这里的网段是192.168.184.0/24)
192.168.184.0/24:允许其访问的NFS服务端的客户端地址,可以是客户端IP地址,也可以是一个网段(192.168.184.0/24),或者是*表示所有客户端IP都可以访问
/root/data/pv1 192.168.184.0/24(rw,no_root_squash)
/root/data/pv2 192.168.184.0/24(rw,no_root_squash)
/root/data/pv3 192.168.184.0/24(rw,no_root_squash)
- 4:重启NFS服务:
systemctl restart nfs
创建PV
- 1:创建配置文件:
vim pv.yaml
- 内容如下:
- pv1:对应存储空间是1Gi;
- pv2:对应存储空间是2Gi;
- pv3:对应存储空间是3Gi;
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv1
spec:
nfs: # 指定存储类型为nfs,并进行nfs的配置
path: /root/data/pv1 #nfs服务器共享目录
server: 192.168.184.100 #nfs服务器ip
capacity: # 存储能力,目前只支持存储空间的设置
storage: 1Gi
accessModes: # 访问模式
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain # 回收策略
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv2
spec:
nfs: # 指定存储类型为nfs,并进行nfs的配置
path: /root/data/pv2 #nfs服务器共享目录
server: 192.168.184.100 #nfs服务器ip
capacity: # 存储能力,目前只支持存储空间的设置
storage: 2Gi
accessModes: # 访问模式
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain # 回收策略
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv3
spec:
nfs: # 指定存储类型为nfs,并进行nfs的配置
path: /root/data/pv3 #nfs服务器共享目录
server: 192.168.184.100 #nfs服务器ip
capacity: # 存储能力,目前只支持存储空间的设置
storage: 3Gi
accessModes: # 访问模式
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain # 回收策略
- 2:执行配置文件:
[root@k8s-master ~]# kubectl apply -f pv.yaml
persistentvolume/pv1 created
persistentvolume/pv2 created
persistentvolume/pv3 created
查看PV
[root@k8s-master ~]# kubectl get pv -o wide
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE VOLUMEMODE
pv1 1Gi RWX Retain Available 28s Filesystem
pv2 2Gi RWX Retain Available 28s Filesystem
pv3 3Gi RWX Retain Available 28s Filesystem
PVC(用户维护⭐)
- PVC是资源的申请(PVC申请PV),用来声明对存储空间、访问模式、存储类别等信息。
PVC的资源清单
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc
namespace: test
spec:
accessModes: # 访问模式
-
selector: # 采用标签对PV选择
storageClassName: # 存储类别
resources: # 申请存储空间
requests:
storage: 5Gi
PVC的关键配置参数说明:
-
访问模式(accessModes):用于描述用户应用对存储资源的访问权限。
-
用于描述用户对存储资源的访问权限:
-
选择条件(selector):通过Label Selector的设置,可使PVC对于系统中已存在的PV进行筛选。
-
存储类别(storageClassName):PVC在定义时可以设定需要的后端存储的类别,只有设置了该class的pv才能被系统选出。
-
资源请求(resources):用于指定申请多大的存储空间
创建PVC
- 1:创建配置文件:
vim pvc.yaml
- 内容如下:
apiVersion: v1
kind: Namespace
metadata:
name: test
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc1
namespace: test
spec:
accessModes: # 访问模式
- ReadWriteMany
resources: # 申请存储空间
requests:
storage: 1Gi
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc2
namespace: test
spec:
accessModes: # 访问模式
- ReadWriteMany
resources: # 申请存储空间
requests:
storage: 1Gi
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc3
namespace: test
spec:
accessModes: # 访问模式
- ReadWriteMany
resources: # 申请存储空间
requests:
storage: 5Gi
- 2:执行配置文件:
[root@k8s-master ~]# kubectl apply -f pvc.yaml
namespace/test created
persistentvolumeclaim/pvc1 created
persistentvolumeclaim/pvc2 created
persistentvolumeclaim/pvc3 created
查看PVC
- 从上面PV的配置可以看出:
- pv1:存储大小是1Gi;
- pv2:存储大小是2Gi;
- pv3:存储大小是3Gi;
- 从下面PVC的配置可以看出:(可以看出PV和PVC的匹配。)
- pvc1:申请1Gi大小内存。—> 由于pvc1申请大小是1Gi,而pv1刚好是1Gi,所以两者绑定成功!pvc1==pv1;
- pvc2:申请1Gi大小内存。—> 由于pvc2申请大小是1Gi,且pv1已经被绑定,但是pv2的存储是2Gi(由于2Gi>1Gi),所以两者绑定成功!pvc2==pv2;
- pvc3:申请5Gi大小内存。—> 由于pvc3申请大小是5Gi,且pv1和pv2都已经被绑定,pv3提供的存储大小为3Gi(3Gi<5Gi,说白了就是pv3最多能提供的存储大小比pvc3申请的存储更小,所以绑定失败);
[root@k8s-master ~]# kubectl get pvc -n test -o wide
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE VOLUMEMODE
pvc1 Bound pv1 1Gi RWX 61s Filesystem
pvc2 Bound pv2 2Gi RWX 61s Filesystem
pvc3 Pending 61s Filesystem
- 查看PV:
[root@k8s-master ~]# kubectl get pv -o wide
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE VOLUMEMODE
pv1 1Gi RWX Retain Bound test/pvc1 6m15s Filesystem
pv2 2Gi RWX Retain Bound test/pvc2 6m15s Filesystem
pv3 3Gi RWX Retain Available 6m15s Filesystem
创建Pod使用PVC
- 1:编写配置文件:
vim pvc-pod.yaml
- 内容如下:
apiVersion: v1
kind: Namespace
metadata:
name: test
---
apiVersion: v1
kind: Pod
metadata:
name: pod1
namespace: test
spec:
containers:
- name: ubuntu
image: ubuntu:22.10
command: ["/bin/sh","-c","while true;do echo pod1 >> /root/out.txt; sleep 10; done;"]
volumeMounts:
- name: volume
mountPath: /root/
volumes:
- name: volume
persistentVolumeClaim:
claimName: pvc1
readOnly: false
---
apiVersion: v1
kind: Pod
metadata:
name: pod2
namespace: test
spec:
containers:
- name: ubuntu
image: ubuntu:22.10
command: ["/bin/sh","-c","while true;do echo pod2 >> /root/out.txt; sleep 10; done;"]
volumeMounts:
- name: volume
mountPath: /root/
volumes:
- name: volume
persistentVolumeClaim:
claimName: pvc2
readOnly: false
- 2:执行配置文件:
[root@k8s-master ~]# kubectl apply -f pvc-pod.yaml
namespace/test unchanged
pod/pod1 created
pod/pod2 created
创建Pod使用PVC后查看Pod
[root@k8s-master ~]# kubectl get pod -n test -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod1 1/1 Running 0 29s 10.244.232.68 k8s-slave01 <none> <none>
pod2 1/1 Running 0 29s 10.244.232.67 k8s-slave01 <none> <none>
创建Pod使用PVC后查看PVC
[root@k8s-master ~]# kubectl get pvc -n test -o wide
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE VOLUMEMODE
pvc1 Bound pv1 1Gi RWX 16h Filesystem
pvc2 Bound pv2 2Gi RWX 16h Filesystem
pvc3 Pending 16h Filesystem
创建Pod使用PVC后查看PV
[root@k8s-master ~]# kubectl get pv -n test -o wide
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE VOLUMEMODE
pv1 1Gi RWX Retain Bound test/pvc1 16h Filesystem
pv2 2Gi RWX Retain Bound test/pvc2 16h Filesystem
pv3 3Gi RWX Retain Available 16h Filesystem
查看NFS中的文件存储
[root@k8s-master ~]# cat /root/data/pv1/out.txt
pod1
pod1
pod1
[root@k8s-master ~]# cat /root/data/pv2/out.txt
pod2
pod2
pod2
PV和PVC的生命周期
-
1:PVC和PV是一一对应的,PV和PVC之间的相互作用遵循如下的生命周期。
-
2:资源供应:管理员手动创建底层存储和PV。
-
3:资源绑定:⭐
-
用户创建PVC,kubernetes负责根据PVC声明去寻找PV,并绑定在用户定义好PVC之后,系统将根据PVC对存储资源的请求在以存在的PV中选择一个满足条件的。
-
一旦找到,就将该PV和用户定义的PVC进行绑定,用户的应用就可以使用这个PVC了。
-
如果找不到,PVC就会无限期的处于Pending状态,直到系统管理员创建一个符合其要求的PV。
-
PV一旦绑定到某个PVC上,就会被这个PVC独占,不能再和其他的PVC进行绑定了。
-
4:资源使用:用户可以在Pod中像volume一样使用PVC,Pod使用Volume的定义,将PVC挂载到容器内的某个路径进行使用。
-
5:资源释放:
-
用户删除PVC来释放PV。
-
当存储资源使用完毕后,用户可以删除PVC,和该PVC绑定的PV将会标记为“已释放”,但是还不能立刻和其他的PVC进行绑定。通过之前PVC写入的数据可能还留在存储设备上,只有在清除之后该PV才能再次使用。
-
6:资源回收:
-
kubernetes根据PV设置的回收策略进行资源的回收。
-
对于PV,管理员可以设定回收策略,用于设置与之绑定的PVC释放资源之后如何处理遗留数据的问题。只有PV的存储空间完成回收,才能供新的PVC绑定和使用。
为什么PVC一直绑定不了PV?⭐
- 原因如下:
- 1:PVC申请的存储空间大小比PV的总空间要大。
- 2:PVC的storageClassName和PV的storageClassName不一致。
- 3:PVC的accessModes和PV的accessModes不一致。
k8s的配置存储
ConfigMap(cm)
概述
-
ConfigMap的作用是用来存储配置信息的(最好不包括密码之类的东西,密码要给Secret来存储)。
-
注意:ConfigMap中的key映射为一个文件,value映射为文件中的内容。如果更新了ConfigMap中的内容,容器中的值也会动态更新,也就是说使用kubectl edit可以动态更改configmap的配置信息
ConfigMap的资源清单
data下面每一个key就是一个单独的配置文件!!
注意configmap的data下面的配置不要key: value,而是key:value才正确
apiVersion: v1
kind: ConfigMap
metadata:
name: configMap
namespace: test
data: # <map[string]string>
配置信息
创建ConfigMap
- 1:编写配置文件:
vim configmap.yaml
- 内容如下:
- data下面每一个key就是一个单独的配置文件!!
- 注意:configmap的data下面的配置不要key: value,而是key:value才正确
apiVersion: v1
kind: Namespace
metadata:
name: test
---
apiVersion: v1
kind: ConfigMap
metadata:
name: configmap
namespace: test
data: # 用configmap存储配置,然后通过pod的volume去拿到配置(注意configmap的data下面的配置不要key: value,而是key:value才正确)
application-dev.yml:
server.port:7200
spring.application.name:cloudmall-01
application-test.yml:
server.port:8122
spring.application.name:cloudmall-02
info:
username:root
password:123456
- 2:执行配置文件:
[root@k8s-master ~]# kubectl apply -f configmap.yaml
namespace/test created
configmap/configmap created
- 3:describe查看configmap:
[root@k8s-master ~]# kubectl describe configmap configmap -n test
Name: configmap
Namespace: test
Labels: <none>
Annotations: <none>
Data
====
application-dev.yml:
----
server.port:7200 spring.application.name:cloudmall-01
application-test.yml:
----
server.port:8122 spring.application.name:cloudmall-02
info:
----
username:root password:123456
Events: <none>
创建Pod
- 1:编写配置文件:
vim pod-configmap.yaml
- 内容如下:
- 由于这个目录(/configmap/config)挂载了configmap,所以这个configmap配置就会在这个目录生成。
apiVersion: v1
kind: Namespace
metadata:
name: test
---
apiVersion: v1
kind: Pod
metadata:
name: pod-configmap
namespace: test
spec:
containers:
- name: nginx
image: nginx:1.22
volumeMounts:
- mountPath: /configmap/config #由于这个目录挂载了configmap,所以这个configmap配置就会在这个目录生成
name: config
volumes:
- name: config #数据卷挂载名称
configMap:
name: configmap #指定configmap的name
- 2:执行配置文件:
[root@k8s-master ~]# kubectl apply -f pod-configmap.yaml
namespace/test unchanged
pod/pod-configmap created
进入容器查看配置⭐
- 1:进入容器中查看配置:
kubectl exec -it pod-configmap -n test /bin/sh
- 2:切换到刚刚容器指定的挂载目录中:(可以看到生成了三个配置文件)
[root@容器 ~]# cd /configmap/config
[root@容器 ~]# ls
application-dev.yml application-test.yml info
- 3:查看每一个文件的配置信息:
[root@容器 ~]# cat application-dev.yml
server.port:7200 spring.application.name:cloudmall-01
[root@容器 ~]# cat application-test.yml
server.port:8122 spring.application.name:cloudmall-02
[root@容器 ~]# cat info
username:root password:123456#
Secret
概述
- 在kubernetes中,还存在一种和ConfigMap非常相似的资源,称为Secret,它主要用来存储敏感信息,例如密码、密钥、证书等等。
Secret的资源清单
apiVersion: v1
kind: Secret
metadata:
name: secret
namespace: test
type: Opaque #data下面的数据要先加密成base64再进行存储。
data:
配置内容xx
Secret的type有三个类型:
- 1:Opaque:base64 编码格式的 Secret,用来存储密码、密钥等;但数据也可以通过base64 –decode解码得到原始数据,所有加密性很弱。
- 注意:像这样创建的 Secret 对象,它里面的内容仅仅是经过了转码,而并没有被加密。在真正的生产环境中,你需要在 Kubernetes 中开启 Secret 的加密插件,增强数据的安全性
- 2:Service Account:用来访问Kubernetes API,由Kubernetes自动创建,并且会自动挂载到Pod的 /run/secrets/kubernetes.io/serviceaccount 目录中。
- Service Account 对象的作用,就是 Kubernetes 系统内置的一种“服务账户”,它是 Kubernetes 进行权限分配的对象。比如, Service Account A,可以只被允许对 Kubernetes API 进行 GET 操作,而 Service Account B,则可以有 Kubernetes API 的所有操作权限。
- 3:kubernetes.io/dockerconfigjson : 用来存储私有docker registry的认证信息。
准备案例演示数据
- 使用base64加密算法对数据进行编码:
[root@k8s-master ~]# echo -n "admin" | base64
YWRtaW4=
[root@k8s-master ~]# echo -n "123456" | base64
MTIzNDU2
创建Secret
- 1:编写配置文件:
vim secret.yaml
- 内容如下:(下面的username和password一定要经过base64加密!)
apiVersion: v1
kind: Namespace
metadata:
name: test
---
apiVersion: v1
kind: Secret
metadata:
name: secret
namespace: test
type: Opaque # data下面的数据要先加密成base64再进行存储。
data:
username: YWRtaW4= # 为字符串admin的base64加密后数据
password: MTIzNDU2 # 为字符串123456的base64加密后数据
上面的配置文件相当于下面这个配置文件:
apiVersion: v1
kind: Namespace
metadata:
name: test
---
apiVersion: v1
kind: Secret
metadata:
name: secret
namespace: test
type: Opaque
stringData: #可以存储明文数据,由k8s自动转换成base64。
username: admin
password: 123456
- 2:执行配置文件:
[root@k8s-master ~]# kubectl apply -f secret.yaml
namespace/test unchanged
secret/secret created
查看Secret详情
- 使用describe查看secret信息,可以发现data里面的数据是不可见的。
[root@k8s-master ~]# kubectl describe secret secret -n test
Name: secret
Namespace: test
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
password: 6 bytes
username: 5 bytes
创建Pod
- 1:编写配置文件:
vim pod-secret.yaml
- 内容如下:
apiVersion: v1
kind: Namespace
metadata:
name: test
---
apiVersion: v1
kind: Pod
metadata:
name: pod-secret
namespace: test
spec:
containers:
- name: nginx
image: nginx:1.22
volumeMounts:
- mountPath: /secret/config #我们绑定的secret的data就会自动同步到这个目录上去。
name: config
volumes:
- name: config
secret:
secretName: secret #绑定一个secret的名称
- 2:执行配置文件:
[root@k8s-master ~]# kubectl apply -f pod-secret.yaml
namespace/test unchanged
pod/pod-secret created
进入容器查看配置⭐
- 进入容器,查看secret信息,我们会发现刚刚经过base64加密的数据自动帮我们解码了:
kubectl exec -it pod-secret -n test /bin/sh
[root@k8s-容器 ~]# cat /secret/config/username
admin
[root@k8s-容器 ~]# cat /secret/config/password
123456
❤️💛🧡本章结束,我们下一章见❤️💛🧡






![[Jdk版本不一致问题 ]终端查看jdk版本不一致](https://img-blog.csdnimg.cn/60e34f034ac1414084190b8da24673e2.png)