文章目录
- 前言
- 用4KB内存寻找重复数
- 总结
前言
提示:并不是所有黑暗的地方,都需要光明。 --珍妮特·温特森《句子不是唯一的水果》
在大部分算法中,默认给点给的数据量都是很小的,例如只有几个或者十几个元素,但是如果遇到了相当大的数据量高达百万乃至十亿,那么处理逻辑就会发生很大差异,也就是说算法中常考的,这个很重要。
这里的题目重点是理解怎么处理,面试的时候遇上可以不用慌张,做到心中有数,这一半也不会写代码。这里做如下演示:
在海量数据中,此时普通的数组、链表、Hash、树等等结构这里就没有什么效果了,因为内存空间肯定是放不下的。而常规的递归、排序、回溯、贪心甚至动态规划等思想在大量数据面前也是不顶用的。因为执行超时,必然要另寻他法。这类问题我们要如何下手呢?这里又三种比较今典的思路:
- 使用位存储,使用存储最大的好处是占用空间是简单存储整数的 1/8 。例如一个 40亿的整数数组,如果用整数存储需要 16GB 左右的空间,而如果使用位存储,就可以仅用 0.5GB 的空间,这样很多问题就能够解决了。
- 如果文件实在太大,无法在能存中存放,则需要考虑将大文件分成若干小块,先处理每块的,最后支部得到想要的结果,这种方式也叫做 外部排序。 这样需要遍历全部遍历至少两次,是经典的用时间换空间的方法。
- 堆。 在处理超大数据中找第K大,第K小,K个最大,K个最小。则特别使用堆来做。而且将超大数据换成流数据也是可以的,而且几乎是唯一的方式,口诀就是“查小用大堆,查大用小堆”。
用4KB内存寻找重复数
题目要求:给定一个数组,包含1到N的整数,N最大为32_000,数组可能还有重复值,且N的值取值不定,若只有4KB的内存可用,该如何打印数组中所有重复的元素。
分析:本身是一道海量数据问题的热身题目,如果去掉只用“4KB”的要求,我们可以先创建一个大小为N的数组,然后将这些数据放进去,但是整数最大为32_000。如果直接才用数组,则需要使用32_000 * 4B = 128KB的空间,而题目只有4kb 的内存限制,我们就必须先解决该如何存放的问题。
如果是只有4KB,那么考虑寻值,只能有 8 * 4 * 2 ^10 个比特。这个值要比32_000要大的多,因此我们可以创建一个32_000比特的维向量(比特数组),其中一个比特位位置就代表一个整数。利用这个位相量,就可以遍历整个数组,如果返现数组元素是v 那么将这个位置的v设置为1,碰到重复元素,就输出一下。
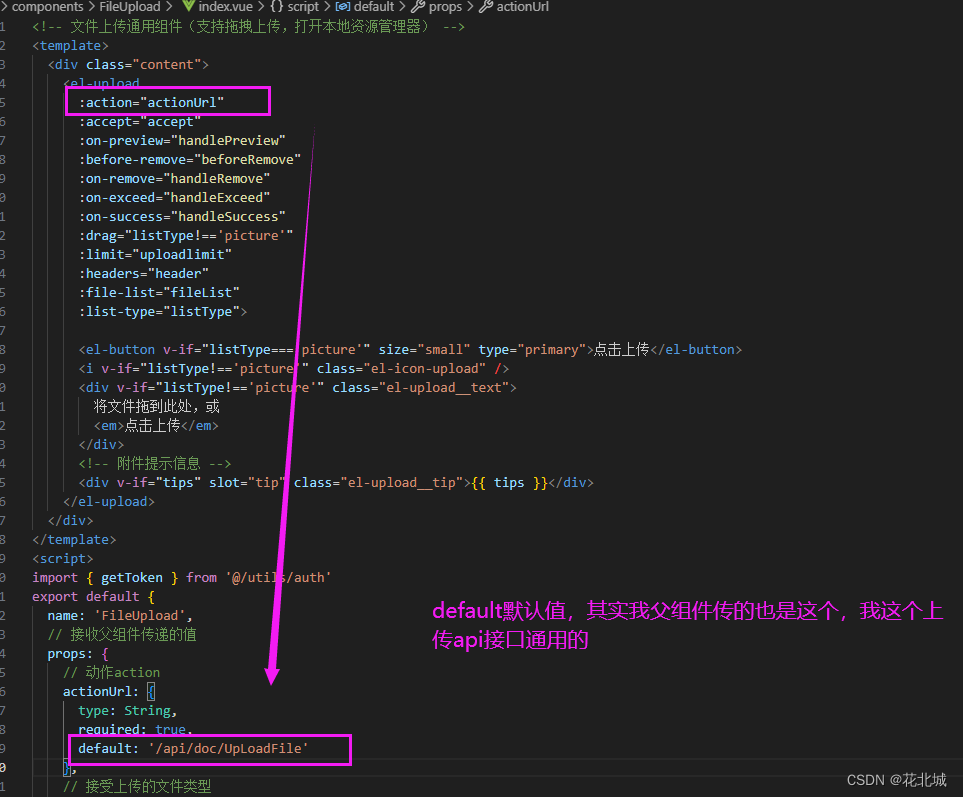
/**
* 检查重复项
* @param array
*/
public void checkDuplicates(int[] array){
BitSet bs = new BitSet(32_000);
for (int i = 0; i < array.length; i++) {
int num = array[i];
int num0 = num - 1;
if(bs.get(num0)){
System.out.println(num);
}else{
bs.set(num0);
}
}
}
class BitSet {
int[] bitSet;
public BitSet(int size){
// 做数据压缩
this.bitSet = new int[size >> 5];
}
public boolean get(int pos){
int wordNumber = (pos >> 5); // 除以32
int bitNumber = (pos & 0x1F); // 除以32
return (bitSet[bitNumber] & (1 << bitNumber)) != 0;
}
public void set(int pos){
int wordNumber = (pos >> 5); // 除以32
int bitNumber = (pos & 0x1F); // 除以32
bitSet[wordNumber] |= 1 << bitNumber;
}
}
总结
提示:海量数据去重;大数据筛选;海量找数;流数据过滤;堆的应用

如果有帮助到你,请给题解点个赞和收藏,让更多的人看到 ~ ("▔□▔)/
如有不理解的地方,欢迎你在评论区给我留言,我都会逐一回复 ~
也欢迎你 关注我 ,喜欢交朋友,喜欢一起探讨问题。