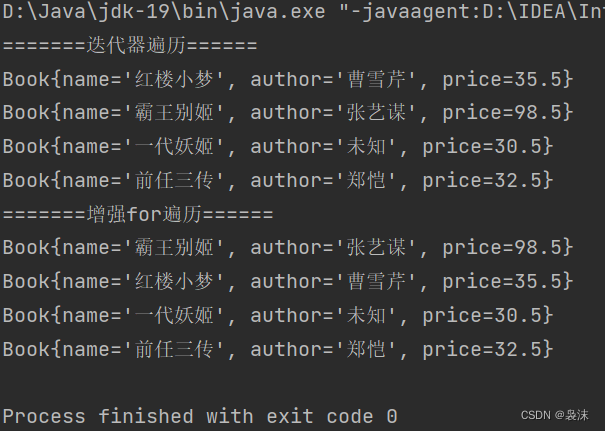
以下是一个使用HTTP:Tiny和www.weibo.com的音频爬虫程序的示例。这个示例使用了https://www.duoip.cn/get_proxy来获取爬虫IP。请注意,这个示例可能需要根据你的实际需求进行调整。

#!/usr/bin/perl
use strict;
use warnings;
use HTTP::Tiny;
use LWP::UserAgent;
use JSON;
my $ua = LWP::UserAgent->new();
$ua->timeout(30);
# 获取爬虫IP
my $proxy_ip = get_proxy();
# 设置代理
$ua->proxy('http', $proxy_ip);
# 目标网站的URL
my $target_url = 'http://www.weibo.com';
# 请求目标网站
my $response = $ua->get($target_url);
# 检查请求是否成功
if ($response->is_success) {
# 解析JSON回复
my $data = JSON->new->decode($response->content);
# 处理音频数据
my @audio_data = @{$data->{data}};
foreach my $audio (@audio_data) {
print "音频标题: " . $audio->{title} . "\n";
print "音频链接: " . $audio->{url} . "\n";
print "音频描述: " . $audio->{description} . "\n\n";
}
} else {
print "请求失败: " . $response->status_line . "\n";
}
sub get_proxy {
# 使用HTTP::Tiny发送请求到https://www.duoip.cn/get_proxy
my $response = $ua->get('https://www.duoip.cn/get_proxy');
# 检查请求是否成功
if ($response->is_success) {
# 解析JSON回复
my $data = JSON->new->decode($response->content);
# 返回爬虫IP
return $data->{ip};
} else {
print "获取爬虫IP失败: " . $response->status_line . "\n";
return undef;
}
}
这个程序首先获取一个爬虫IP地址,然后使用这个爬虫IP发送请求到www.weibo.com。接下来,程序解析JSON回复,提取音频数据,并输出音频标题、链接和描述。请注意,这个示例仅供参考,你可能需要根据实际需求进行调整。


![2023年中国求职招聘类APP行业现状及市场格局分析[图]](https://img-blog.csdnimg.cn/img_convert/ade91c0658d69229b4bc91471eb346d2.png)