什么是关系数据库管理系统
关系数据库管理系统(RDBMS,relational database management system)是基于关系数据模型的数字数据库,由 E. F. Codd 于 1970 年提出。
许多关系数据库都提供使用结构化查询语言 SQL(Structured Query Language)进行查询和维护数据库的选项,例如:MySQL 和 PostgreSQL。
什么是索引
索引(indexes)是一种数据结构,可以减少请求数据的查找时间。索引通过额外的存储、内存和保持更新(写入速度较慢)的成本来实现这一目标,从而使我们能够跳过繁琐的检查每个表中的行
就像书籍后面的索引一样,它能帮助你快速找到正确的页面
为什么需要索引
少量的数据是可以管理的,但是当数据量增长后,就没那么容易了(想象一座大城市的出生登记)。想象你要在一页上找到某个东西和在成百上千页中找到它,你的策略会有什么不同。
无论你想出什么办法,某些数据库在某个时刻几乎都已经实施了你能想到的所有好策略。随着它们的发展,系统会收集和存储更多的数据,最终还会导致上述问题。
我们需要索引来帮助我们尽快获取我们所需的相关数据。
索引是如何工作的
什么是关系数据库管理系统
关系数据库管理系统(RDBMS,relational database management system)是基于关系数据模型的数字数据库,由 E. F. Codd 于 1970 年提出。
许多关系数据库都提供使用结构化查询语言 SQL(Structured Query Language)进行查询和维护数据库的选项,例如:MySQL 和 PostgreSQL。
什么是索引
索引(indexes)是一种数据结构,可以减少请求数据的查找时间。索引通过额外的存储、内存和保持更新(写入速度较慢)的成本来实现这一目标,从而使我们能够跳过繁琐的检查每个表中的行
就像书籍后面的索引一样,它能帮助你快速找到正确的页面
为什么需要索引
少量的数据是可以管理的,但是当数据量增长后,就没那么容易了(想象一座大城市的出生登记)。想象你要在一页上找到某个东西和在成百上千页中找到它,你的策略会有什么不同。
无论你想出什么办法,某些数据库在某个时刻几乎都已经实施了你能想到的所有好策略。随着它们的发展,系统会收集和存储更多的数据,最终还会导致上述问题。
我们需要索引来帮助我们尽快获取我们所需的相关数据。
索引是如何工作的
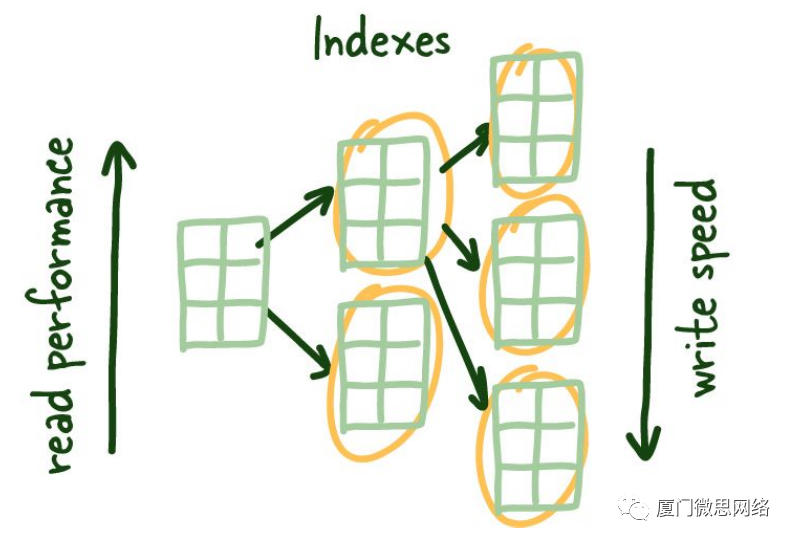
随着数据的索引,读取性能会提高,但这是以写入性能为代价的,因为您需要保持索引的最新状态
所以经常提出的解决方案之一是根据搜索方式逻辑地存储这些数据。也就是说,如果您想通过姓名搜索列表,您会按照名字的顺序对列表进行排序。
这种策略存在一些问题
1. 如果你想以多种方式搜索数据呢?
2. 你会如何处理向列表中添加新数据?这个过程快吗?
3. 你会如何处理更新?
4. 这些任务的算法时间/空间复杂度是多少?
让我们看下面的小型表格,可以快速从磁盘读取
+─────+─────────+──────────────+
| id | name | city |
+─────+─────────+──────────────+
| 1 | Mahdi | Ottawa |
| 2 | Elon | Mars |
| 3 | Jeff | Orbit |
| 4 | Klay | Oakland |
| 5 | Lebron| Los Angeles |
+─────+─────────+──────────────+
这些数据被无序且分散的存放在存储空间(硬盘)中。但由于表格数据较少,实际上整个表格的数据都会被保存在内存中。
再看下面的大型表格,无法完全放入内存,数据又分布在磁盘中
+──────────+─────────+───────────────────+
| id | name | city |
+──────────+─────────+───────────────────+
| 1 | Mahdi | Ottawa |
| 2 | Elon | Mars |
| 3 | Jeff | Orbit |
| 4 | Klay | Oakland |
| 5 | Lebron | Los Angeles |
| ... | ... | ... |
| 1000000 | Steph | San Francisco |
| 1001000 | Linus | Portland |
+───────+─────────+──────────────────────+开发者在面临这种问题时的常见思路是:如何在不进行完整的磁盘扫描(通常很慢且需要读取大量数据块)情况下,快速找到数据库中特定的行。许多开发者会使用字典(哈希映射 hash map)这种数据结构来实现快速查找。
对于数据库而言,使用一种被称为 "索引叶节点 index leaf nodes" 的技术。索引叶节点是索引的一部分,它们被分配一个特定的列来创建索引。这些节点可以存储与特定列值匹配的行的位置信息。
通过索引叶节点,可以快速定位到包含特定值的行,而无需扫描整个表。
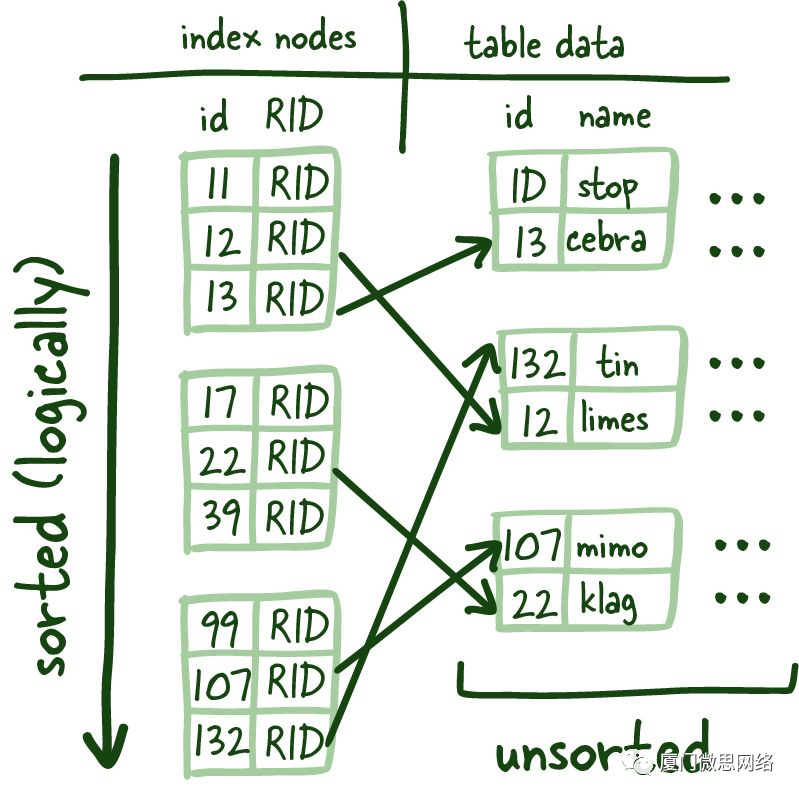
可以看到 RID(RowID)索引映射到表数据
解释
没有索引的情况下,数据库在查找特定记录的时候会进行全表扫描。这在数据量大的情况下会非常耗时。
而有了索引,且 RID 与原表 id 相同,就可以精确指向表中的特定行,从而避免全表扫描。
Balanced trees B树
数据规模往往对你不利,而B树是你对抗它的第一道利器。
索引叶节点的大小是统一的,数据库管理系统会尽可能的存储这些叶节点在块(Blocks)中,并且对其进行排序(逻辑上的排序,而不是物理磁盘上的排序)。排序的操作必然会涉及到快速添加数据和删除数据,而双向链表(doubly linked list)可以很好的胜任这份工作。
当新数据插入或现有数据被删除时,索引需要能够快速更新以保持这种逻辑顺序。使用链表结构可以使这些更新操作更加高效,因为链表允许快速地插入和删除节点,而不需要移动大量的其他节点。
使用双向链表,每个索引节点都会有指向其前后节点的指针。这样,在插入或删除节点时,只需要更新相邻节点的指针,而不需要重新排列整个索引结构

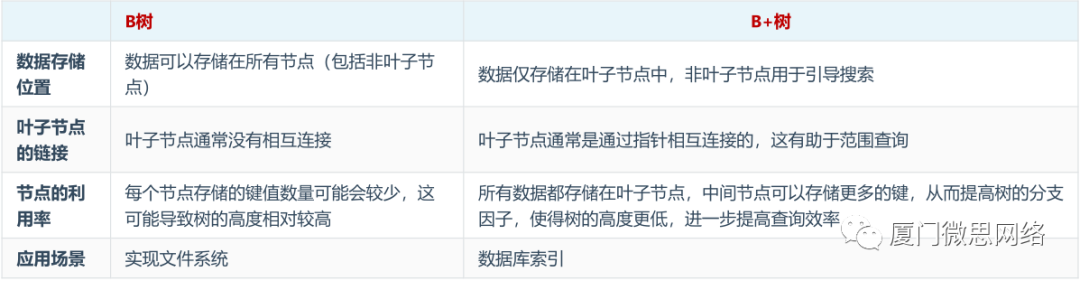
B+树在关系数据库中的应用:
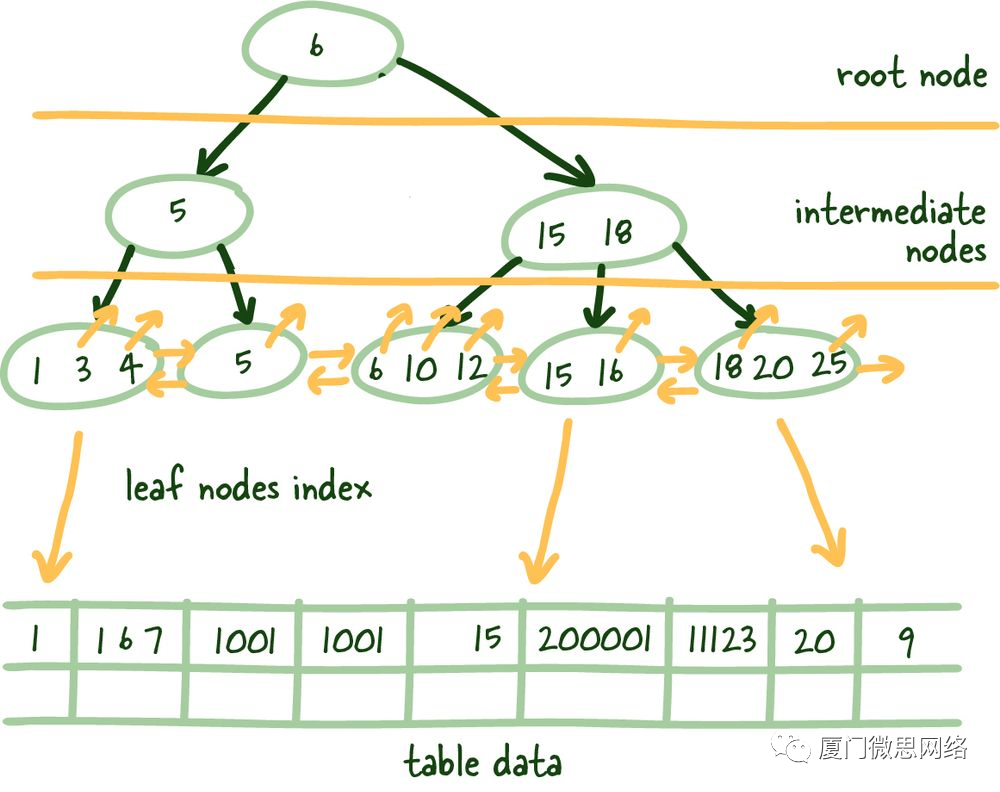
对数可扩展性(Logarithmic Scalability)
平衡树可以作为对抗数据规模增长的有效工具。通过平衡树,根据中间节点可以引用的项数(M)和树的总深度(N),我们可以引用 M 的 N 次方个对象,有效管理和引用大量数据。
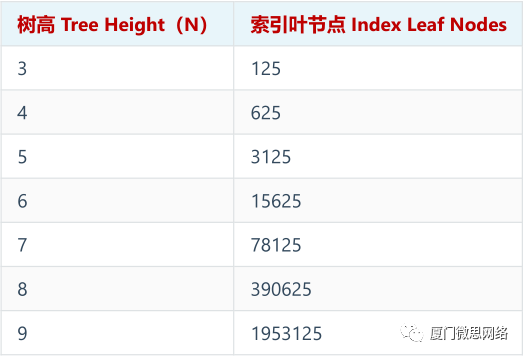
随着索引叶节点数量的指数增长,树的高度相对于索引叶节点数量增长得非常缓慢(对数级别)
什么是事务 transaction
事务是你希望作为一个整体来处理的工作单元。因此,它要么完全发生,要么完全不发生
大多数系统不需要手动管理事务,但在某些情况下,增加的灵活性对于实现所需的效果至关重要。事务主要处理 ACID 中的 I,即隔离性
手动创建事务的例子:
-- Manual transaction with commit.
BEGIN;
SELECT * FROM people WHERE id =1;
COMMIT or ROLLBACK;
主要关注在 BEGIN 和 COMMIT 或 ROLLBACK 之间的时间以及其他对同一数据进行操作的事务所发生的情况。
什么是 ACID
在计算机科学中,ACID(原子性、一致性、隔离性、持久性)是一组数据库事务的属性,旨在确保数据的有效性,即使出现错误、断电和其他意外情况
-
原子性 Atomicity:原子性的保证防止数据库更新只发生部分,这可能比完全拒绝整个系列带来更严重的问题
-
一致性 Consistency:一致性保证了事务能够将数据库从一个有效状态移动到下一个,确保所有操作都符合定义的数据库规则,同时防止非法事务导致数据损坏
-
隔离性 Isolation:隔离决定了如何向其他并发系统用户展示特定的操作
-
持久性 Durability:耐久性是确保已经提交的交易将永久存留的属性
提交和回滚 COMMIT / ROLLBACK
所有手动事务要么成功提交(COMMIT)要么回滚(ROLLBACK)
COMMIT:持久化当前事务所做的更改
ROLLBACK:撤销当前事务所做的更改
当您不手动管理事务时,如果事务中的所有查询都成功完成,则它们将被提交。如果出现任何失败,该事务期间的更改将被回滚,以确保整个操作的原子性
读现象 Read Phenomena
在这些隔离中可能会发生几种读取现象,了解它们对于调试系统和真实理解系统能够容忍的不一致性是至关重要的
Non-repeatable reads 不可重复读取
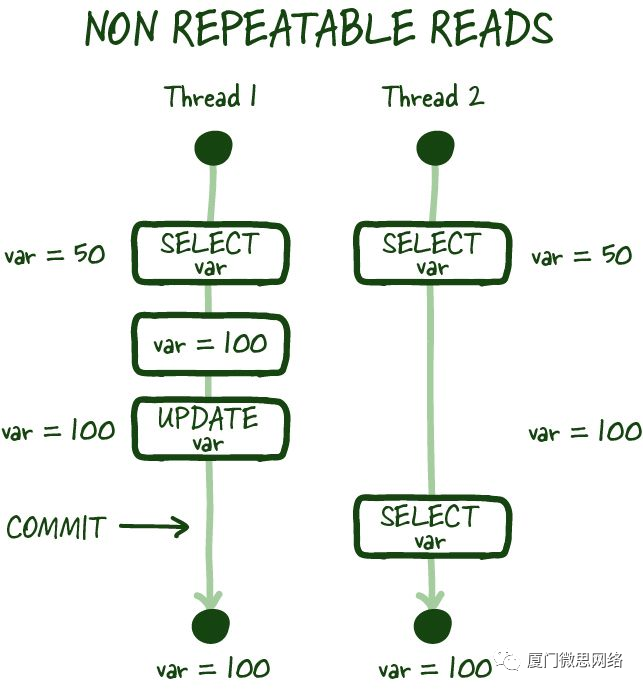
如果在事务期间的两次连续读取之间无法获得数据的一致视图,则会发生不可重复读取
在特定模式下,可以进行并发数据库修改,并且可能存在您刚刚读取的值被修改的情况,导致不可重复读取
Dirty reads 脏读
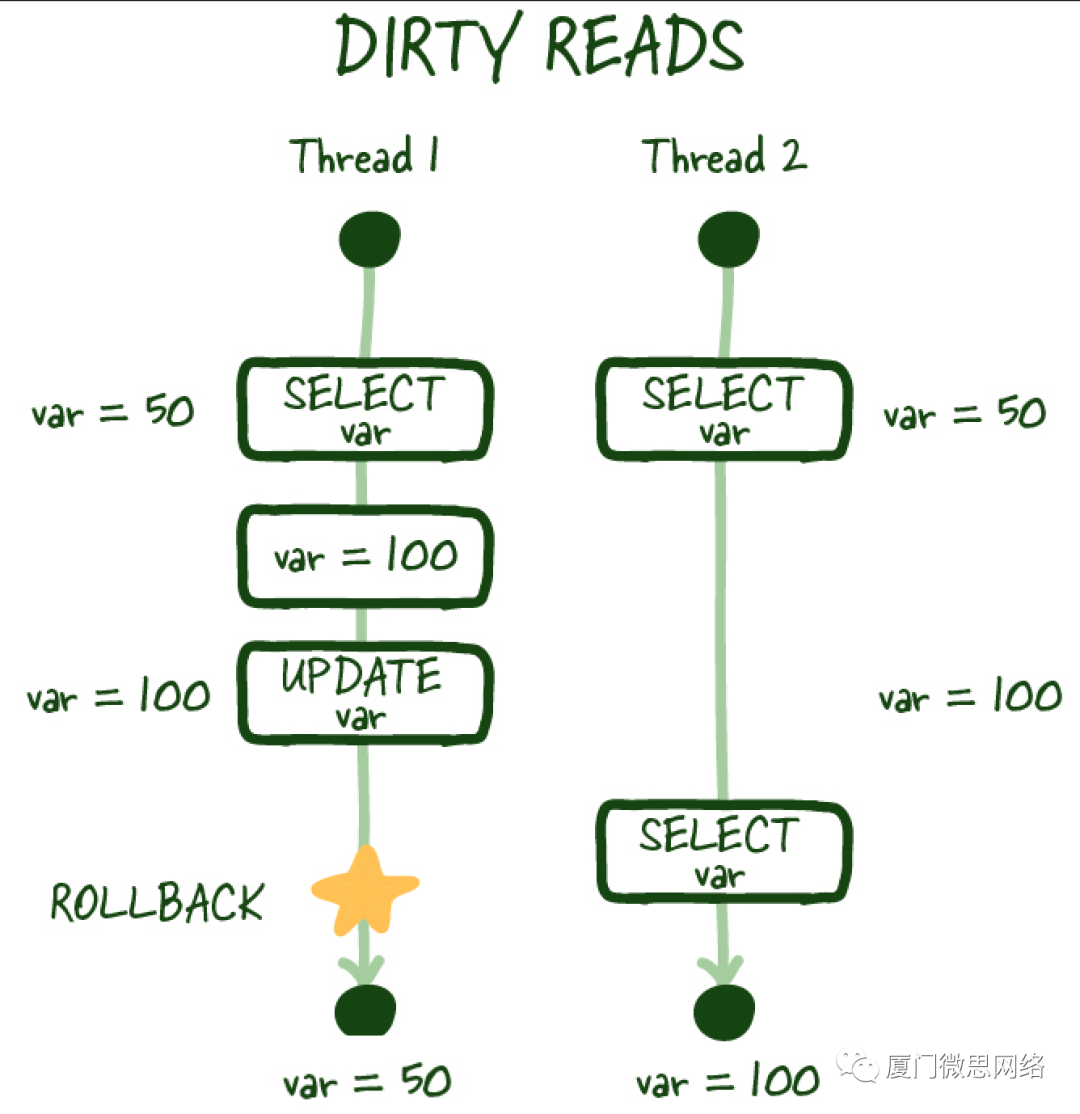
当你进行读取操作时,另一个事务更新了同一行但未提交工作,你再次进行读取操作时,你可以访问到未提交(脏)的值,这不是一个持久的状态改变,并且与数据库的状态不一致
Phantom reads 幻读
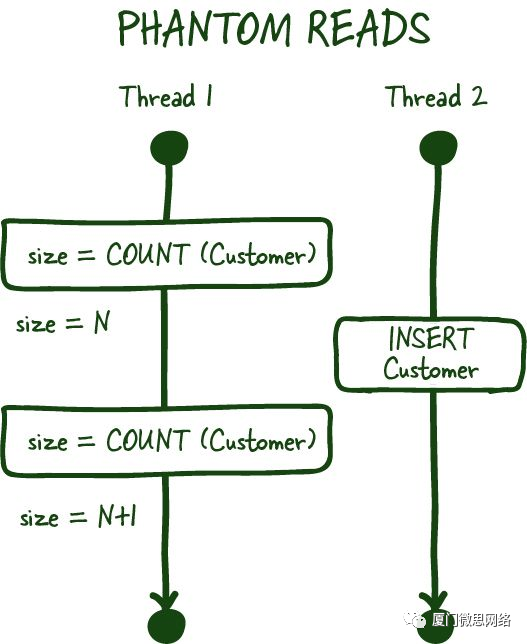
幻读是另一种常见的读取现象,通常发生在处理聚合数据时。例如,你在特定事务中询问客户数量。
在两次连续的读取之间,另一个客户注册或删除他们的账户(已提交),如果你的数据库不支持这些事务的范围锁定,那么你将得到两个不同的值
范围锁 Range Locks
1. Serialized Database Access 序列化数据库访问:逐个运行查询——并发性差,但是拥有最高级别的一致性
2. Table Lock 表锁:锁定表以进行您的事务,具有稍微更好的并发性,但并发表写入仍会减慢速度
3. Row Lock 行锁:比表锁更好地锁定你正在操作的行,但如果多个事务需要这一行,它们将需要等待
范围锁位于最后两个级别的锁之间;它们锁定事务所捕获的值范围,并且不允许在事务所捕获的范围内进行插入或更新操作
隔离级别 Isolation Levels
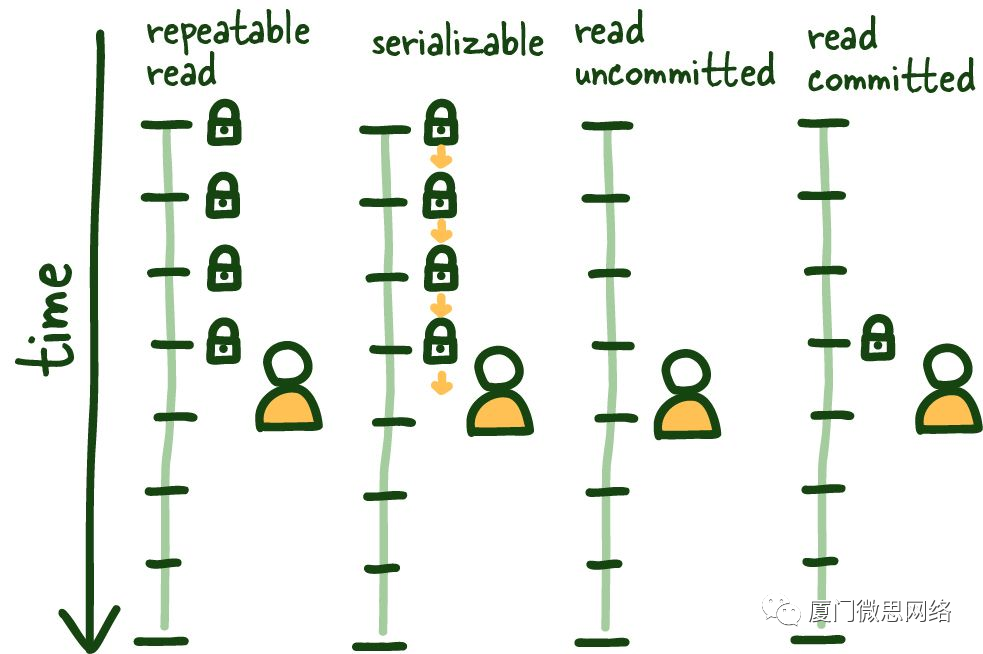
SQL标准定义了4个标准的隔离级别,这些级别可以和应该在全局范围内进行配置(如果我们无法可靠地推理隔离级别,那么可能会发生一些隐秘的问题)
REPEATABLE READ 可重复读
让我们从REPEATABLE READ开始。这个隔离级别相对容易理解,并为其他隔离级别奠定了基础。这个隔离级别确保在第一次读取建立的事务中进行一致的读取
这个观点以多种方式得到支持;其中一些方式会影响整个系统的性能,而其他方式则不会,但超出了本文的范围
请参考上方的图表;一旦我们进行第一次阅读,该视图将在整个交易期间被锁定,因此在此交易的上下文之外发生的任何事情都不会产生任何影响,无论是已提交还是未提交
这个隔离级别保护我们免受几个已知的隔离问题的影响,主要是非重复读(Non-repeatable reads)和脏读(Dirty reads)。在数据库锁定到特定视图时,它确实会有轻微的数据不一致性;在这里尽量使事务的生命周期尽可能短暂是有益的
SERIALIZABLE 可序列化
这种操作模式可能是最严格和一致的,因为它只允许一次运行一个查询
由于数据库逐个运行查询并从一个稳定状态过渡到下一个,所有类型的阅读现象都不再可能。这里有更多细微之处,但大体上是准确的
READ COMMITTED 读已提交
这种隔离模式与 REPEATABLE READ 不同,因为每次读取都会创建自己一致(已提交)的时间快照。因此,如果我们在同一事务中执行多次读取,这种隔离模式容易出现幻读
READ UNCOMMITTED 读未提交
不会维护任何事务锁定,并且可以实时查看未提交的数据,从而导致脏读。在某些系统中,这是噩梦的来源
随着数据的索引,读取性能会提高,但这是以写入性能为代价的,因为您需要保持索引的最新状态
所以经常提出的解决方案之一是根据搜索方式逻辑地存储这些数据。也就是说,如果您想通过姓名搜索列表,您会按照名字的顺序对列表进行排序。
这种策略存在一些问题
1. 如果你想以多种方式搜索数据呢?
2. 你会如何处理向列表中添加新数据?这个过程快吗?
3. 你会如何处理更新?
4. 这些任务的算法时间/空间复杂度是多少?
让我们看下面的小型表格,可以快速从磁盘读取
+─────+─────────+──────────────+
| id | name | city |
+─────+─────────+──────────────+
| 1 | Mahdi | Ottawa |
| 2 | Elon | Mars |
| 3 | Jeff | Orbit |
| 4 | Klay | Oakland |
| 5 | Lebron| Los Angeles |
+─────+─────────+──────────────+
这些数据被无序且分散的存放在存储空间(硬盘)中。但由于表格数据较少,实际上整个表格的数据都会被保存在内存中。
再看下面的大型表格,无法完全放入内存,数据又分布在磁盘中
+──────────+─────────+───────────────────+
| id | name | city |
+──────────+─────────+───────────────────+
| 1 | Mahdi | Ottawa |
| 2 | Elon | Mars |
| 3 | Jeff | Orbit |
| 4 | Klay | Oakland |
| 5 | Lebron | Los Angeles |
| ... | ... | ... |
| 1000000 | Steph | San Francisco |
| 1001000 | Linus | Portland |
+───────+─────────+──────────────────────+开发者在面临这种问题时的常见思路是:如何在不进行完整的磁盘扫描(通常很慢且需要读取大量数据块)情况下,快速找到数据库中特定的行。许多开发者会使用字典(哈希映射 hash map)这种数据结构来实现快速查找。
对于数据库而言,使用一种被称为 "索引叶节点 index leaf nodes" 的技术。索引叶节点是索引的一部分,它们被分配一个特定的列来创建索引。这些节点可以存储与特定列值匹配的行的位置信息。
通过索引叶节点,可以快速定位到包含特定值的行,而无需扫描整个表。
可以看到 RID(RowID)索引映射到表数据
解释
没有索引的情况下,数据库在查找特定记录的时候会进行全表扫描。这在数据量大的情况下会非常耗时。
而有了索引,且 RID 与原表 id 相同,就可以精确指向表中的特定行,从而避免全表扫描。
Balanced trees B树
数据规模往往对你不利,而B树是你对抗它的第一道利器。
索引叶节点的大小是统一的,数据库管理系统会尽可能的存储这些叶节点在块(Blocks)中,并且对其进行排序(逻辑上的排序,而不是物理磁盘上的排序)。排序的操作必然会涉及到快速添加数据和删除数据,而双向链表(doubly linked list)可以很好的胜任这份工作。
当新数据插入或现有数据被删除时,索引需要能够快速更新以保持这种逻辑顺序。使用链表结构可以使这些更新操作更加高效,因为链表允许快速地插入和删除节点,而不需要移动大量的其他节点。
使用双向链表,每个索引节点都会有指向其前后节点的指针。这样,在插入或删除节点时,只需要更新相邻节点的指针,而不需要重新排列整个索引结构

B+树在关系数据库中的应用:
对数可扩展性(Logarithmic Scalability)
平衡树可以作为对抗数据规模增长的有效工具。通过平衡树,根据中间节点可以引用的项数(M)和树的总深度(N),我们可以引用 M 的 N 次方个对象,有效管理和引用大量数据。
随着索引叶节点数量的指数增长,树的高度相对于索引叶节点数量增长得非常缓慢(对数级别)
什么是事务 transaction
事务是你希望作为一个整体来处理的工作单元。因此,它要么完全发生,要么完全不发生
大多数系统不需要手动管理事务,但在某些情况下,增加的灵活性对于实现所需的效果至关重要。事务主要处理 ACID 中的 I,即隔离性
手动创建事务的例子:
-- Manual transaction with commit.
BEGIN;
SELECT * FROM people WHERE id =1;
COMMIT or ROLLBACK;
主要关注在 BEGIN 和 COMMIT 或 ROLLBACK 之间的时间以及其他对同一数据进行操作的事务所发生的情况。
什么是 ACID
在计算机科学中,ACID(原子性、一致性、隔离性、持久性)是一组数据库事务的属性,旨在确保数据的有效性,即使出现错误、断电和其他意外情况
-
原子性 Atomicity:原子性的保证防止数据库更新只发生部分,这可能比完全拒绝整个系列带来更严重的问题
-
一致性 Consistency:一致性保证了事务能够将数据库从一个有效状态移动到下一个,确保所有操作都符合定义的数据库规则,同时防止非法事务导致数据损坏
-
隔离性 Isolation:隔离决定了如何向其他并发系统用户展示特定的操作
-
持久性 Durability:耐久性是确保已经提交的交易将永久存留的属性
提交和回滚 COMMIT / ROLLBACK
所有手动事务要么成功提交(COMMIT)要么回滚(ROLLBACK)
COMMIT:持久化当前事务所做的更改
ROLLBACK:撤销当前事务所做的更改
当您不手动管理事务时,如果事务中的所有查询都成功完成,则它们将被提交。如果出现任何失败,该事务期间的更改将被回滚,以确保整个操作的原子性
读现象 Read Phenomena
在这些隔离中可能会发生几种读取现象,了解它们对于调试系统和真实理解系统能够容忍的不一致性是至关重要的
Non-repeatable reads 不可重复读取

如果在事务期间的两次连续读取之间无法获得数据的一致视图,则会发生不可重复读取
在特定模式下,可以进行并发数据库修改,并且可能存在您刚刚读取的值被修改的情况,导致不可重复读取
Dirty reads 脏读

当你进行读取操作时,另一个事务更新了同一行但未提交工作,你再次进行读取操作时,你可以访问到未提交(脏)的值,这不是一个持久的状态改变,并且与数据库的状态不一致
Phantom reads 幻读
幻读是另一种常见的读取现象,通常发生在处理聚合数据时。例如,你在特定事务中询问客户数量。
在两次连续的读取之间,另一个客户注册或删除他们的账户(已提交),如果你的数据库不支持这些事务的范围锁定,那么你将得到两个不同的值
范围锁 Range Locks
1. Serialized Database Access 序列化数据库访问:逐个运行查询——并发性差,但是拥有最高级别的一致性
2. Table Lock 表锁:锁定表以进行您的事务,具有稍微更好的并发性,但并发表写入仍会减慢速度
3. Row Lock 行锁:比表锁更好地锁定你正在操作的行,但如果多个事务需要这一行,它们将需要等待
范围锁位于最后两个级别的锁之间;它们锁定事务所捕获的值范围,并且不允许在事务所捕获的范围内进行插入或更新操作
隔离级别 Isolation Levels
SQL标准定义了4个标准的隔离级别,这些级别可以和应该在全局范围内进行配置(如果我们无法可靠地推理隔离级别,那么可能会发生一些隐秘的问题)
REPEATABLE READ 可重复读
让我们从REPEATABLE READ开始。这个隔离级别相对容易理解,并为其他隔离级别奠定了基础。这个隔离级别确保在第一次读取建立的事务中进行一致的读取
这个观点以多种方式得到支持;其中一些方式会影响整个系统的性能,而其他方式则不会,但超出了本文的范围
请参考上方的图表;一旦我们进行第一次阅读,该视图将在整个交易期间被锁定,因此在此交易的上下文之外发生的任何事情都不会产生任何影响,无论是已提交还是未提交
这个隔离级别保护我们免受几个已知的隔离问题的影响,主要是非重复读(Non-repeatable reads)和脏读(Dirty reads)。在数据库锁定到特定视图时,它确实会有轻微的数据不一致性;在这里尽量使事务的生命周期尽可能短暂是有益的
SERIALIZABLE 可序列化
这种操作模式可能是最严格和一致的,因为它只允许一次运行一个查询
由于数据库逐个运行查询并从一个稳定状态过渡到下一个,所有类型的阅读现象都不再可能。这里有更多细微之处,但大体上是准确的
READ COMMITTED 读已提交
这种隔离模式与 REPEATABLE READ 不同,因为每次读取都会创建自己一致(已提交)的时间快照。因此,如果我们在同一事务中执行多次读取,这种隔离模式容易出现幻读
READ UNCOMMITTED 读未提交
不会维护任何事务锁定,并且可以实时查看未提交的数据,从而导致脏读。在某些系统中,这是噩梦的来源
【微|信|公|众|号:厦门微思网络】
【微思网络www.xmws.cn,成立于2002年,专业培训21年,思科、华为、红帽、ORACLE、VMware等厂商认证及考试,以及其他认证PMP、CISP、ITIL等】