列存储(CU)
- 概述
- cstore 存储单元结构(CU)
- CU 类
- CU 的构造函数
- Reset 函数
- CU::CheckCrc 函数
- CU::GenerateCrc 函数
- CU::AppendValue 函数
- CU::AppendCuData 函数
声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了 OpenGauss1.1.0 的开源代码和《OpenGauss数据库源码解析》一书以及OpenGauss社区学习文档和一些学习资料
概述
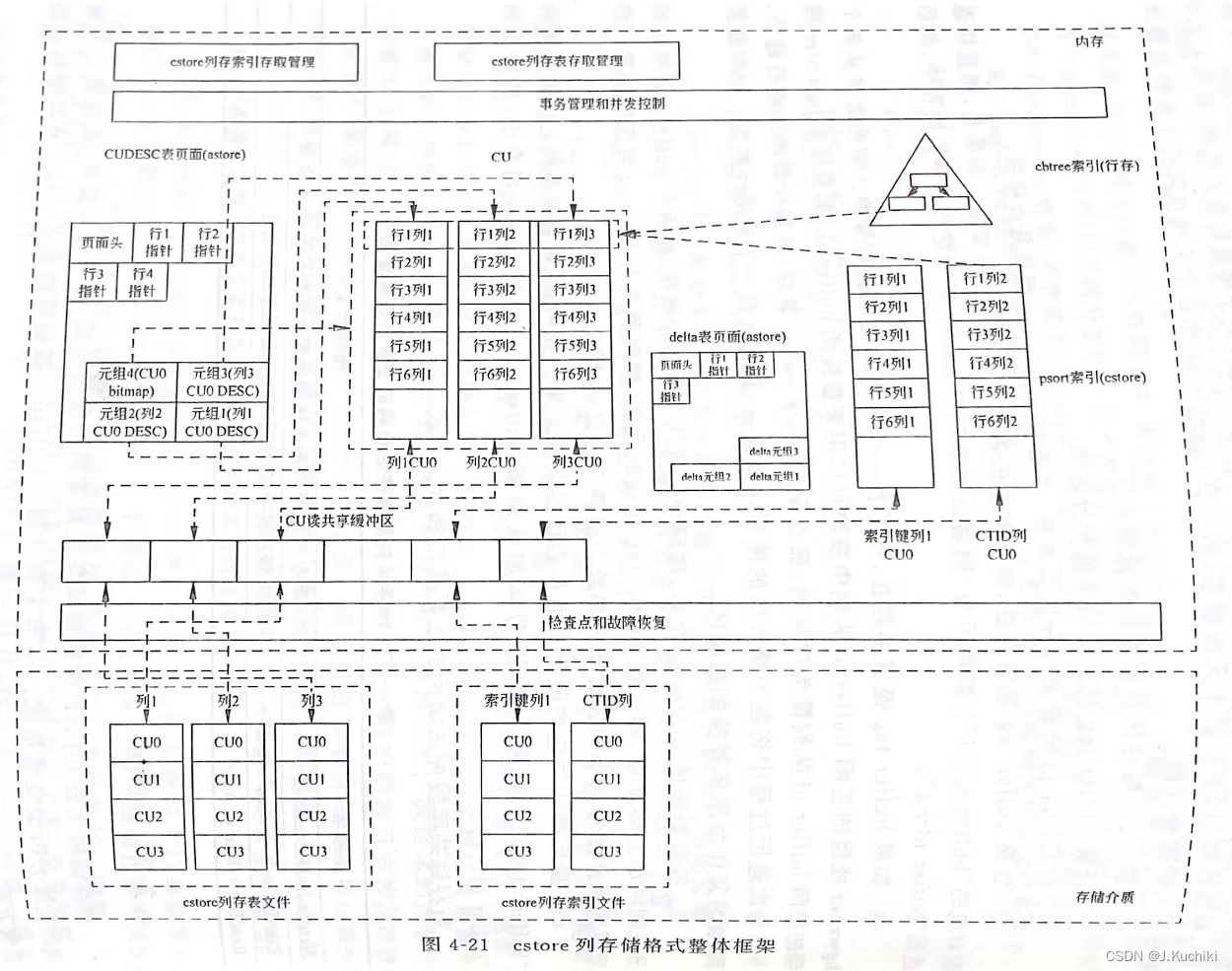
列存储格式是 OLAP 类数据库系统最常用的数据格式,适合复杂查询、范围统计类查询的在线分析型处理系统。(OLAP,全称 Online Analytical Processing,是一种用于数据分析和报表生成的计算机处理方法。它主要用于处理多维数据,帮助用户以交互方式探索和分析数据,以便获取洞察和支持决策。)
列存储格式整体框架如图 4-21 所示。与行存储格式不同,cstore 列存储的主题数据文件以 CU 为 I/O 单元,只支持追加写操作,因此 cstore 只有读共享缓冲区。CU 间和 CU 内的可见性由对应的 CUDESE 表(astore 表)决定,因此其可见性和并发控制原理与行存储 astore 基本相同。
cstore 存储单元结构(CU)
列存储引擎的存储基本单位是 CU,即 Compression Unit(压缩单元)。列存储数据库系统通常用于数据仓库和分析型数据库,因为它们在数据检索和分析方面具有优势。下图显示了 CU 的结构示意图。
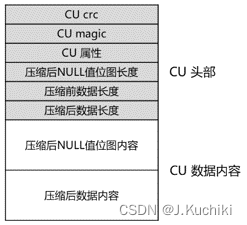
其中每一部分的解释如下所示:
(1) CU 的 crc 值,为 CU 结构中除 crc 成员外,其他所有字节计算出的32位 crc 值。
(2)CU 的 magic 值,为插入 CU 的事务号。
(3)CU 的属性值,为16位标志值,包括 CU 是否包含 NULL 行、CU 使用的压缩算法等 CU 粒度属性信息。
(4)压缩后 NULL 值位图长度,如果属性值中标识该 CU 包含 NULL 行,则本 CU 在实际数据内容开始处包含 NULL 值位图,此处存储该位图的字节长度,如果该 CU 不包含 NULL 行,则无该成员。
(5)压缩前数据长度,即 CU 数据内容在压缩前的字节长度,用于读取 CU 时进行内存申请和校验。
(6)压缩后数据长度,即 CU 数据内容在压缩后的字节长度,用于插入 CU 时进行内存申请和校验。
(7)压缩后 NULL 值位图内容,如果属性值中表示该 CU 包含 NULL 行,则该成员即为每行的 NULL 值位图,否则五该成员。
(8)压缩后数据内容,即实际写入磁盘的 CU 主体数据内容。
每个 CU 最多保存对应字段的 MAX_BATCH_ROWS 行(默认 60000 行)数据。相邻 CU 之间按 8KB 对齐。
CU 类
了解了 CU 的概念,我们紧接着来看看 CU 的代码实现吧。“CU” 类定义了用于处理数据库中的数据存储和压缩的功能。它包括函数来检查和生成 CRC 校验码,追加数据值和空值,执行数据的压缩和解压缩,以及将数据转换为向量等操作,同时提供一些用于管理内存和数据一致性的方法。该类是数据库存储引擎中的一个核心组件,用于管理和操作压缩的数据块。
CU 类的定义如下:(路径:src/include/storage/cu.h)
/* CU 结构:
* 描述 CU 结构的组成,包括头信息、空值位图、源数据和压缩数据等部分
*/
class CU : public BaseObject {
public:
/* 源缓冲区:空值位图 + 源数据。 */
char* m_srcBuf; // 源缓冲区,包括空值位图和源数据
/* 空值位图在 m_srcBuf 中的指针。 */
unsigned char* m_nulls; // 空值位图的指针
/* 源数据在 m_srcBuf 中的指针。 */
char* m_srcData; // 源数据的指针
/* 压缩缓冲区:压缩头信息 + 压缩数据 */
char* m_compressedBuf; // 压缩缓冲区,包括压缩头信息和压缩数据
/* 支持在加载 CU 数据后随机访问数据的偏移量。 */
int32* m_offset; // 支持随机访问数据的偏移量
/* 有关 CU 压缩的临时信息。 */
cu_tmp_compress_info* m_tmpinfo; // 临时压缩信息
/* ADIO 加载的 CU 数据,包括压缩缓冲和填充数据。 */
char* m_compressedLoadBuf; // ADIO 加载的 CU 数据,包括压缩缓冲和填充数据
int m_head_padding_size; // 头部填充数据的大小
/* m_offset 数组的元素数量。 */
int32 m_offsetSize; // m_offset 数组的元素数量
/* 源缓冲区的大小。 */
uint32 m_srcBufSize; // 源缓冲区的大小
/* 源数据的大小。 */
uint32 m_srcDataSize; // 源数据的大小
/* 压缩缓冲区的大小。 */
uint32 m_compressedBufSize; // 压缩缓冲区的大小
/* CU 的大小,包括填充数据。 */
uint32 m_cuSize; // CU 的大小,包括填充数据
/* 压缩后的 CU 大小,不包括填充数据。 */
uint32 m_cuSizeExcludePadding; // 压缩后的 CU 大小,不包括填充数据
/* CRC 校验码。 */
uint32 m_crc; // CRC 校验码
/* 用于验证 CU 数据的魔术数。 */
uint32 m_magic; // 用于验证 CU 数据的魔术数
/* 一些关于压缩整数类型的信息。 */
int m_eachValSize; // 整数类型数据的大小
int m_typeMode; // 从属性的 typmode 获取的类型模式,对于 numeric 数据包括精度和标度信息
/* 有关压缩和未压缩的空值位图大小。 */
uint16 m_bpNullRawSize; // 未压缩和压缩时的空值位图大小
uint16 m_bpNullCompressedSize; // 压缩后的空值位图大小
/* 一些信息,如是否有 NULL 值、压缩模式等。 */
uint16 m_infoMode; // 一些信息,如是否有 NULL 值、压缩模式等
/* 用于区分 char 和 varchar 的列类型 ID。 */
uint32 m_atttypid; // 用于区分 char 和 varchar 的列类型 ID
bool m_adio_error; /* ADIO 模式下是否发生错误 */
bool m_cache_compressed; /* 描述 CU 是否在 CU 缓存中被压缩,
* ADIO 加载 CU 数据时是已压缩的,
* 扫描使用 CU 时需要先进行压缩。
*/
bool m_inCUCache; /* 是否在 CU 缓存中 */
bool m_numericIntLike; /* numeric CU 中的所有数据是否可以转换为 Int64 */
public:
CU();
CU(int typeLen, int typeMode, uint32 atttypid);
~CU();
void Destroy();
/*
* 检查 CRC 校验码。
*/
bool CheckCrc();
/*
* 生成 CRC 校验码。
*/
uint32 GenerateCrc(uint16 info_mode) const;
/*
* 追加数值。
*/
void AppendValue(Datum val, int size);
/*
* 追加数值。
*/
void AppendValue(const char* val, int size);
/*
* 追加空值。
*/
void AppendNullValue(int row);
static void AppendCuData(_in_ Datum value, _in_ int repeat, _in_ Form_pg_attribute attr, __inout CU* cu);
// 压缩数据
//
int16 GetCUHeaderSize(void) const;
void Compress(int valCount, int16 compress_modes, int align_size);
void FillCompressBufHeader(void);
char* CompressNullBitmapIfNeed(_in_ char* buf);
bool CompressData(_out_ char* outBuf, _in_ int nVals, _in_ int16 compressOption, int align_size);
// 解压数据
//
char* UnCompressHeader(_in_ uint32 magic, int align_size);
void UnCompress(_in_ int rowCount, _in_ uint32 magic, int align_size);
char* UnCompressNullBitmapIfNeed(const char* buf, int rowCount);
void UnCompressData(_in_ char* buf, _in_ int rowCount);
template <bool DscaleFlag>
void UncompressNumeric(char* inBuf, int nNotNulls, int typmode);
// 在 CU 中随机访问数据
//
template <bool hasNull>
void FormValuesOffset(int rows);
template <int attlen, bool hasNull>
ScalarValue GetValue(int rowIdx);
/*
* CU 转换为向量
*/
template <int attlen, bool hasDeadRow>
int ToVector(_out_ ScalarVector* vec, _in_ int leftRows, _in_ int rowCursorInCU, __inout int& curScanPos,
_out_ int& deadRows, _in_ uint8* cuDelMask;
/*
* CU 转换为向量
*/
template <int attlen, bool hasNull, bool hasDeadRow>
int ToVectorT(_out_ ScalarVector* vec, _in_ int leftRows, _in_ int rowCursorInCU, __inout int& curScanPos,
_out_ int& deadRows, _in_ uint8* cuDelMask;
template <int attlen, bool hasNull>
int ToVectorLateRead(_in_ ScalarVector* tids, _out_ ScalarVector* vec);
// GET 方法用于在压缩 CU 后设置 CUDesc 信息。
// SET 方法用于在解压缩 CU 数据期间设置 CU 信息。
//
int GetCUSize() const;
void SetCUSize(int cuSize);
int GetCompressBufSize() const;
int GetUncompressBufSize() const;
bool CheckMagic(uint32 magic) const;
void SetMagic(uint32 magic);
uint32 GetMagic() const;
bool IsVerified(uint32 magic);
/*
* 是否为空值。
*/
bool IsNull(uint32 row) const;
/*
* 在指定行之前的 NULL 值数量。
*/
int CountNullValuesBefore(int rows) const;
void FreeCompressBuf();
void FreeSrcBuf();
void Reset();
void SetTypeLen(int typeLen);
void SetTypeMode(int typeMode);
void SetAttTypeId(uint32 atttypid);
void SetAttInfo(int typeLen, int typeMode, uint32 atttypid);
bool HasNullValue() const;
void InitMem(uint32 initialSize, int rowCount, bool hasNull);
void ReallocMem(Size size;
template <bool freeByCUCacheMgr>
void FreeMem();
/* 时序函数 */
void copy_nullbuf_to_cu(const char* bitmap, uint16 null_size);
uint32 init_field_mem(const int reserved_cu_byte);
uint32 init_time_mem(const int reserved_cu_byte);
void check_cu_consistence(const CUDesc* cudesc) const;
private:
template <bool char_type>
void DeFormNumberStringCU();
bool IsNumericDscaleCompress() const;
// 加密 CU 数据
void CUDataEncrypt(char* buf);
// 解密 CU 数据
void CUDataDecrypt(char* buf);
};
CU 的构造函数
类 CU 的构造函数包括两个版本:CU::CU(int typeLen, int typeMode, uint32 atttypid) 和 CU::CU()。以下是它们的作用:
- CU::CU(int typeLen, int typeMode, uint32 atttypid) 构造函数:
- 这是一个参数化的构造函数,用于创建 CU 类的新对象,同时接受类型长度(typeLen)、类型模式(typeMode)和属性类型ID(atttypid)作为参数。
- Reset() 函数被调用,以初始化对象的成员变量。
- 然后,成员变量 m_eachValSize 被设置为 typeLen 的值, m_typeMode 被设置为 typeMode 的值, m_atttypid 被设置为 atttypid 的值。
- 该构造函数的目的是创建 CU 对象并根据提供的参数进行初始化,以确保对象处于合适的状态。
- CU::CU() 构造函数:
- 这是无参数的构造函数,用于创建 CU 类的新对象。
- Reset() 函数被调用,以初始化对象的成员变量。
- 该构造函数的目的是创建 CU 对象并在没有提供特定参数的情况下进行初始化,以确保对象处于合适的状态。
这两个构造函数提供了不同的初始化选项,以根据具体需求创建 CU 对象。
函数源码如下:(路径:src/gausskernel/storage/cstore/cu.cpp)
CU::CU(int typeLen, int typeMode, uint32 atttypid)
{
// 重置 CU 对象的初始状态
Reset();
// 设置 CU 对象的类型长度
m_eachValSize = typeLen;
// 设置 CU 对象的类型模式
m_typeMode = typeMode;
// 设置 CU 对象的属性类型 ID
m_atttypid = atttypid;
}
CU::CU()
{
// 重置 CU 对象的初始状态
Reset();
}
Reset 函数
其中,Reset 函数的作用是将 CU 类的各个成员变量初始化为其初始状态,以确保在创建或重用 CU 对象时,对象的属性都处于正确的状态。
函数源码如下:(路径:src/gausskernel/storage/cstore/cu.cpp)
FORCE_INLINE
void CU::Reset()
{
// 重置 CU 对象的各个成员变量到初始状态
// CRC 校验码初始化为 0
m_crc = 0;
// 源数据缓冲初始化为 NULL
m_srcData = NULL;
// 信息模式初始化为 0
m_infoMode = 0;
// 压缩缓冲初始化为 NULL
m_compressedBuf = NULL;
// 压缩缓冲大小初始化为 0
m_compressedBufSize = 0;
// 压缩缓冲加载缓冲初始化为 NULL
m_compressedLoadBuf = NULL;
// 头部填充大小初始化为 0
m_head_padding_size = 0;
// 源缓冲初始化为 NULL
m_srcBuf = NULL;
// 源缓冲大小初始化为 0
m_srcBufSize = 0;
// 源数据大小初始化为 0
m_srcDataSize = 0;
// 空值标记缓冲初始化为 NULL
m_nulls = NULL;
// CU 大小初始化为 0
m_cuSize = 0;
// 压缩的 NULL 值标记原始大小初始化为 0
m_bpNullRawSize = 0;
// 压缩的 NULL 值标记压缩大小初始化为 0
m_bpNullCompressedSize = 0;
// 偏移量数组初始化为 NULL
m_offset = NULL;
// 偏移量数组大小初始化为 0
m_offsetSize = 0;
// 压缩后的 CU 大小(不包括填充数据)初始化为 0
m_cuSizeExcludePadding = 0;
// 临时压缩信息初始化为 NULL
m_tmpinfo = NULL;
// 魔术数字初始化为 0
m_magic = 0;
// 缓存中是否压缩的标志初始化为假
m_cache_compressed = false;
// ADIO 错误标志初始化为假
m_adio_error = false;
// 是否在 CU 缓存中的标志初始化为假
m_inCUCache = false;
// 每个值的大小初始化为 0
m_eachValSize = 0;
// 类型模式初始化为 0
m_typeMode = 0;
// 属性类型 ID 初始化为 0
m_atttypid = 0;
// 是否支持将数值类型转换为 Int64 的标志初始化为假
m_numericIntLike = false;
}
CU::CheckCrc 函数
CU::CheckCrc 函数的作用是检查 CU 对象的数据是否完整和一致。它从压缩缓冲中提取保存的 CRC 校验码和信息模式,然后重新生成 CRC 校验码,最后与提取的 CRC 校验码进行比较。如果校验失败,它可以发出警告并根据配置选择是否忽略校验失败。
CU::CheckCrc 函数源码如下所示(路径:src/gausskernel/storage/cstore/cu.cpp)
bool CU::CheckCrc()
{
// 从压缩缓冲中提取保存的 CRC 校验码
uint32 tmpCrc = *(uint32*)m_compressedBuf;
// 从压缩缓冲中提取保存的信息模式
uint16 tmpMode = *(uint16*)(m_compressedBuf + sizeof(m_crc) + sizeof(m_magic));
// 重新生成 CRC 校验码
m_crc = GenerateCrc(tmpMode);
// 使用 EQ_CRC32C 检查重新生成的 CRC 校验码与保存的 CRC 校验码是否一致
bool isSame = EQ_CRC32C(m_crc, tmpCrc);
// 如果校验失败
if (unlikely(!isSame)) {
// 发出警告,指示 CU 数据校验失败
ereport(WARNING,
(ERRCODE_DATA_CORRUPTED,
errmsg("CU verification failed, calculated checksum %u but expected %u", m_crc, tmpCrc)));
// 如果允许忽略校验失败,返回 true
if (u_sess->attr.attr_common.ignore_checksum_failure)
return true;
}
// 返回校验结果,true 表示校验通过,false 表示校验失败
return isSame;
}
以下是一个示例情景:
- 假设您正在运行一个数据库,并且数据文件存储在磁盘上,每个数据块都有一个 CRC 校验和。
- 当您执行读取操作时,DBMS会首先读取存储在磁盘上的数据块,包括数据和 CRC 校验和。
- 在读取数据之后,DBMS使用 CheckCrc 函数来验证数据块的完整性。
- CheckCrc 函数读取 CRC 校验和 tmpCrc 和数据块的模式 tmpMode。
- 然后,它使用 GenerateCrc 函数计算数据块的实际 CRC 校验和 m_crc。
- 接下来,它使用 EQ_CRC32C 函数来比较实际的 CRC 校验和 m_crc 与预期的 tmpCrc 是否相同。
- 如果 m_crc 与 tmpCrc 不匹配,意味着数据块已损坏。
- 此时,CheckCrc 函数会发出警告消息,指出 CRC 校验失败,实际 CRC 与预期 CRC 不匹配。
- 然后,根据数据库的配置,可能会采取不同的操作。如果 ignore_checksum_failure 设置为真,DBMS将继续运行并返回 true,允许忽略校验失败。否则,它将返回 false 表示数据损坏。
这个过程确保了数据块在读取时没有受到损坏,从而提高了数据库的可靠性。如果数据块受到损坏,DBMS 可以根据配置决定是继续运行还是停止并报告错误。这对于数据库系统中的数据完整性和可靠性至关重要。
CU::GenerateCrc 函数
CU::GenerateCrc 函数主要用于计算数据块的 CRC 校验和。其中 GenerateCrc 函数根据输入参数 info_mode 中的标志来决定使用哪种 CRC 算法,CRC32C 还是 PostgreSQL 的 CRC32。函数源码如下所示:(路径:src/gausskernel/storage/cstore/cu.cpp)
// it's the caller that defines the action of CRC computation.
// it's decided by the input argument *force*.
uint32 CU::GenerateCrc(uint16 info_mode) const
{
// 根据输入参数 info_mode 的标志判断是否使用 CRC32C 算法
bool isCRC32C = (CU_CRC32C == (info_mode & CU_CRC32C));
// 断言检查数据块大小
ASSERT_CUSIZE(m_cuSize);
// 初始化 CRC 校验和临时变量
uint32 tmpCrc = 0;
// 如果使用 CRC32C 算法
if (likely(isCRC32C)) {
// 使用 CRC32C 初始化
INIT_CRC32C(tmpCrc);
// 计算 CRC32C 校验和
COMP_CRC32C(tmpCrc, m_compressedBuf + sizeof(tmpCrc), m_cuSize - sizeof(tmpCrc));
// 完成 CRC32C 计算
FIN_CRC32C(tmpCrc);
// 在 DEBUG 模式下,检查 SSE42 CRC32C 结果是否与 SB8 结果一致
#if defined(USE_SSE42_CRC32C_WITH_RUNTIME_CHECK)
if (pg_comp_crc32c == pg_comp_crc32c_sse42) {
uint32 sb8_crc32c = 0;
INIT_CRC32C(sb8_crc32c);
// 使用 SB8 CRC32C 初始化
sb8_crc32c = pg_comp_crc32c_sb8(sb8_crc32c, m_compressedBuf + sizeof(sb8_crc32c), m_cuSize - sizeof(sb8_crc32c));
// 完成 SB8 CRC32C 计算
FIN_CRC32C(sb8_crc32c);
// 检查 CRC32C 校验和是否一致
if (!EQ_CRC32C(tmpCrc, sb8_crc32c)) {
// 如果不一致,记录错误消息
ereport(ERROR, (errcode(ERRCODE_DATATYPE_MISMATCH),
errmsg("the CRC32C checksum are different between SSE42 (0x%x) and SB8 (0x%x).",
tmpCrc, sb8_crc32c)));
}
}
#endif
}
// 如果不使用 CRC32C 算法,使用 PostgreSQL 的标准 CRC32
else {
// 使用 PG 的 CRC32 初始化
INIT_CRC32(tmpCrc);
// 计算 CRC32 校验和
COMP_CRC32(tmpCrc, m_compressedBuf + sizeof(tmpCrc), m_cuSize - sizeof(tmpCrc));
// 完成 CRC32 计算
FIN_CRC32(tmpCrc);
}
// 返回计算得到的 CRC 校验和
return tmpCrc;
}
CU::AppendValue 函数
其中,AppendValue 函数有两个重载版本,这两个函数都执行相似的操作,它们检查是否有足够的空间来追加数据,如果没有,就扩展缓冲区的大小。然后,它们将数据存储到源数据缓冲区中,并更新源数据的大小。第一个函数用于 Datum 类型的数据,而第二个函数用于 const char* 类型的数据。函数源码如下所示:(路径:src/gausskernel/storage/cstore/cu.cpp)
void CU::AppendValue(Datum val, int size)
{
// 如果追加数据后的源数据位置超出了缓冲区的大小
if (unlikely(m_srcData + m_srcDataSize + size > m_srcBuf + m_srcBufSize)) {
// 最好逐步扩展内存,每次扩展 1MB
Assert(size >= 0);
// 调用 ReallocMem 函数来重新分配足够大的内存
ReallocMem((Size)m_srcBufSize + (uint32)size + 1024 * 1024);
}
// 将数据存储到源数据缓冲区中(以传值方式)
store_att_byval(m_srcData + m_srcDataSize, val, size);
// 更新源数据大小
m_srcDataSize += size;
}
void CU::AppendValue(const char* val, int size)
{
errno_t rc;
// 如果追加数据后的源数据位置超出了缓冲区的大小
if (unlikely(m_srcData + m_srcDataSize + size > m_srcBuf + m_srcBufSize)) {
// 最好逐步扩展内存,每次扩展 1MB
Assert(size >= 0);
// 调用 ReallocMem 函数来重新分配足够大的内存
ReallocMem((Size)m_srcBufSize + (uint32)size + 1024 * 1024);
}
// 使用 memcpy_s 函数将数据复制到源数据缓冲区中
rc = memcpy_s(m_srcData + m_srcDataSize, size, val, size);
securec_check(rc, "\0", "\0");
// 更新源数据大小
m_srcDataSize += size;
}
CU::AppendCuData 函数
CU::AppendCuData 函数用于将值追加到 CU 对象中。这个函数根据值的属性(attr)和重复次数(repeat)将值追加到 CU 对象中。如果值的长度小于等于8,它会将值的内容传递给 AppendValue 函数,否则,它将值的指针传递给 AppendValue 函数。这允许它有效地处理不同类型和大小的值。函数源码如下所示:(路径:src/gausskernel/storage/cstore/cu.cpp)
// 向CU对象中追加一个值
// repeat 参数用于在CU中重复相同的值
void CU::AppendCuData(_in_ Datum value, _in_ int repeat, _in_ Form_pg_attribute attr, __inout CU* cu)
{
// 获取值的大小,使用 datumGetSize 函数,考虑了值的类型及长度
const int valSize = (int)datumGetSize(value, attr->attbyval, attr->attlen);
// 如果值的长度在大于0且小于等于8的范围内
if (attr->attlen > 0 && attr->attlen <= 8) {
// 重复 repeat 次,将值追加到 cu 中,使用 AppendValue 函数
for (int cnt = 0; cnt < repeat; ++cnt) {
cu->AppendValue(value, valSize);
}
} else {
// 否则,重复 repeat 次,将值的指针追加到 cu 中,使用 AppendValue 函数
for (int cnt = 0; cnt < repeat; ++cnt) {
cu->AppendValue(DatumGetPointer(value), valSize);
}
}
}
以下通过一个简单的案例来说明 CU::AppendCuData 函数的用法:
假设有一个数据库表,其中有一个名为 employees 的列,该列存储了员工的薪水(salary)。现在,我们希望创建一个"压缩单元"(CU)对象,用于批量插入员工的薪水数据。
对于这个任务,我们可以使用 CU::AppendCuData 函数来构建CU对象。以下是一个示例:
Form_pg_attribute attr; // 假设已定义合适的属性对象
CU cu; // 创建一个CU对象
// 假设员工薪水数据
int employeeSalaries[] = {50000, 60000, 75000, 55000};
for (int i = 0; i < 4; i++) {
int salary = employeeSalaries[i];
int repeat = 2; // 每个员工的薪水重复两次
// 使用CU::AppendCuData函数将员工薪水追加到CU对象中
cu.AppendCuData(Int32GetDatum(salary), repeat, attr, &cu);
}
# 现在CU对象cu包含了员工薪水数据
在这个示例中,我们创建了一个 CU 对象,并使用 CU::AppendCuData 函数将员工薪水数据插入到 CU 对象中。AppendCuData 函数基于属性的大小和类型来决定如何处理数据,并可以在 CU 对象中有效地存储这些数据。这有助于将大量数据批量插入数据库,减少了插入操作的开销。