目录
补充进程知识:
是什么触发了进程的切换?
进程切换时要做什么?
切换进程的时机分为主动和被动。
进程上下文指的是什么?
线程篇:
以进程创建子进程为例引入线程:
线程定义:
Motivation:
进程区别:
多线程优点:
定义:
多线程模型:
多核编程:
ULT(用户级线程):
KLT(内核线程):
组合方式:
多对一模型:
一对一模型(主流):
多对多模型:
多线程实验:
实验一代码:
Monte Carlo技术计算Π值:
非多线程的计算方法:
补充进程知识:
在上篇文章中的一张图提到:
是什么触发了进程的切换?
是中断触发了进程的切换
进程切换时要做什么?
进程的切换类似于中断,也需要进行模式切换,如:
p1进程正在执行,在某点要被切换,就会被中断,进而模式切换到操作系统的内核态,调用中断处理程序(switch--专门处理进程切换的中断处理程序)

切换进程的时机分为主动和被动。
主动:启动IO设备
被动:高优先级进程的调度、cpu时间片到期
进程上下文指的是什么?
其实就是就进程在内存中所包含的内容:

线程篇:

以进程创建子进程为例引入线程:
通过fork函数创建了子进程,由上一篇文章可知会把父进程的数据以及代码全部进行克隆。
创建子进程的好处是什么?
得到了两个不同的(通过利用fork在父子进程中的返回值不同使用if分支语句进行区分)、并发的执行流。
创建子进程的坏处是什么?
资源浪费(内存空间)
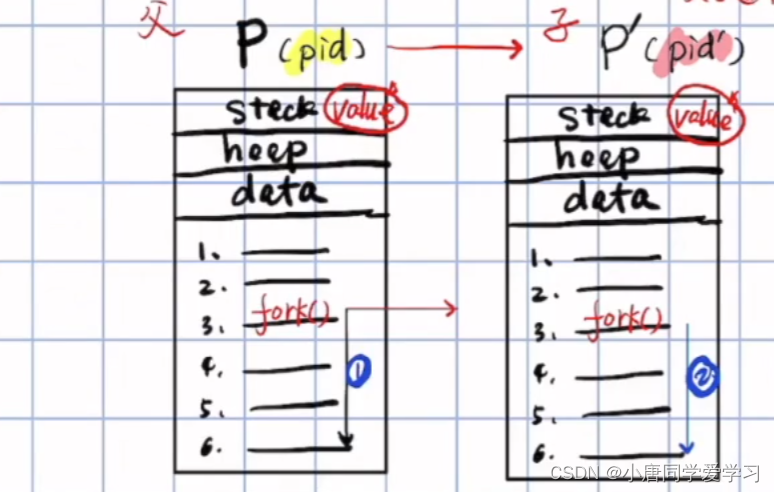
有了缺点那本章的问题就来了,就是如何解决坏处,而且保留好处,即两条执行流且不浪费资源,我们可以叫它Thread---线程
对线程直观的定义可以认为线程是进程中的执行流
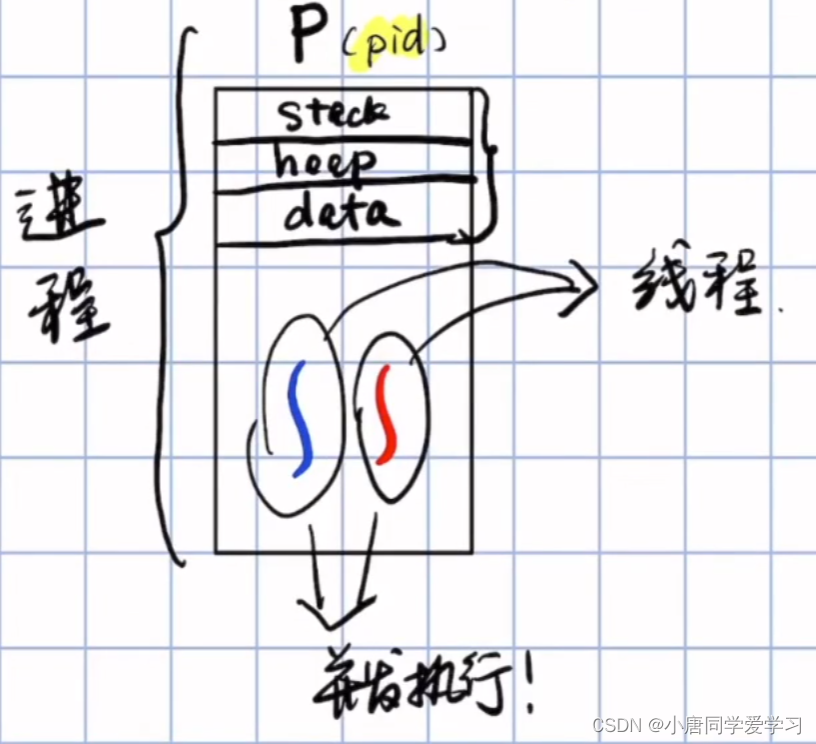
线程定义:
Motivation:
一个应用通常要处理很多任务,比如一个Web浏览器,可能需要同时处理文 字和图片,这些同时执行的任务可称为 “执行流” ,我们不希望它们是顺序执行的。在web中我们不能说让上述任务处理完文字再处理图片吧,这是不符合用户的使用的。因此需要多任务并发执行,早期每个执行流就是创建子进程,但是进程的切换是要消耗巨大的时空资源的,所以把一个应用装进进程中,进程内部的执行流就是线程。
进程区别:

多线程优点:
响应性:当一个服务器负责监听进程(Listen process)一个用户发出请求,则在进程中创建一条执行流(线程)来响应请求,当另一个用户发出请求,服务器在进程中新创建一个线程作为响应,两个用户所访问的是同一个数据,如果是在单线程进程中,就需要创建新的进程,这开销是巨大的,引入多线程进程后,只需要消耗小部分资源,从上个线程中复制处理。
资源共享:进程间的资源共享是靠进程间的通信来完成的,但是线程间的资源共享,同属于一个进程的线程是可以直接访问的。
经济:相比进程的创建,线程的消耗是很小的。
可伸缩性:在多处理机系统中,有多个cpu,一个多线程进程可以将多个线程进行分配到多个处理机上,让他们并行执行。可以根据系统的环境来调整所占处理机的数量。
定义:
---- 一个传统的进程有一个单线程控制流,如果一个进程有多线程控制流,同一时间它能运行不止一个任务。
多线程模型:
多核编程:
多核编程与前边的多线程的优点中的可伸缩性相似,在多处理器系统中,多核编程机制让应用程序可以更有效地将自身的多个执行任务(并发的线程)分散到不同的处理器上运行,以实现并行计算。

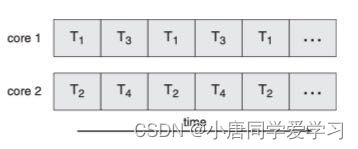
ULT(用户级线程):
ULT在user mode下运行,它的管理无需内核支持。用户级线程一个系统中可以有很多个,但是设置用户级线程的的系统的调度单位是进程
优点:
1)对于同一个进程的线程,线程的切换是不需要切换到内核空间
2)用户级线程的实现与OS平台无关,对于线程管理的的代码是属于用户程序的一部分,应用程序是共享的。
缺点:
1)系统调用引起的阻塞问题,大多系统调用都会使系统阻塞,当用户线程系统调用的时候也会使整个进程阻塞。而内核支持线程,是只有该线程阻塞。
2)用户级线程是不具有伸缩性的,每个进程还是只会分到一个cpu,则只有一个线程拥有使用权。(设置用户级线程的OS的调度单位是进程)
KLT(内核线程):
KLT在kernel mode下运行,由操作系统支持与管理。是在内核空间实现的,内核空间给每个内核线程设置了一个线程控制块(TCB),设置KLT的操作系统的调度单位是线程。
优点:
1)在多处理机系统中,可以调度同一个进程中的多个线程同时使用CPU(并行工作)
2)如果某个进程被阻塞,则内核可以调度该进程的其他线程使用CPU,也可以调度其他进程的其他线程使用CPU。
3)KTL具有很小的数据结构与堆栈,进程切换较快,开销较小。
4)内核本身可以采用多线程技术,可以提高运行速度和效率。
缺点:
对于用户级线程来说,线程调度的时候需要进行模式切换(用户--内核),开销较大。
由于上边两者都有优缺点,因此采用他们组合的方式进行互补。
组合方式:
多对一模型:

组合方式即将用户级别线程对内核线程进行绑定,在多对一的模型中这里的多是多个用户线程(一般属于一个进程),一 指的是一个内核线程,虽然多对一,但是每次只能一个用户线程对内核线程进行映射,即同一时刻只有一个用户线程可以访问内核,当发生阻塞时,整个进程都会阻塞。
一对一模型(主流):

一对一模型是为每一个用户进程都绑定一个核心进程进行映射,并发性较好,当线程阻塞时,其他线程依然可以访问内核。但是系统开销较大,每设一个用户线程都要创建一个内核线程,因此需要控制线程数量。
多对多模型:
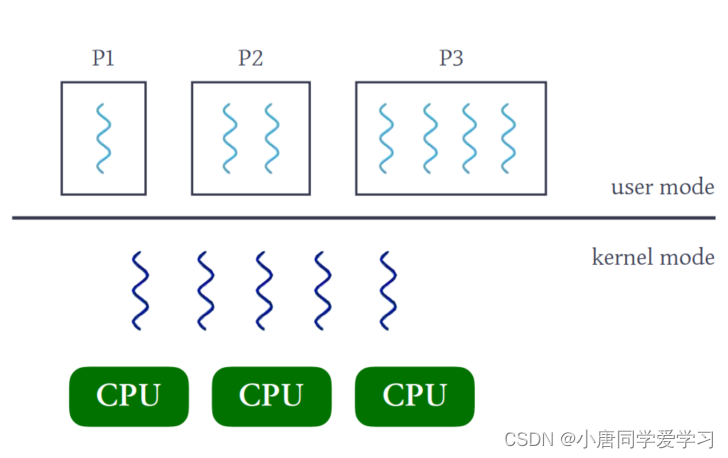
多对多模型,即将许多用户线程映射到同样数量或更少数量的内核线程上。内核控制线程的数目可以根据应用进程和系统的不同而变化,可以比用户线程少,也可以与之相同。该模型结合上述两种模型的优点, 它可以像一对一模型那样,使一个进程的多个线程并行地运行在多处理机系统上,也可像多对一模型那样,减少线程的管理开销和提高效率。 节省了内核开销,但是实现复杂,中间需要多了一层分配器。
多线程实验:
(1)使用Pthreads库创建多个线程,并观察线程的并发执行现象以及数据共享关系
(2)Monte Carlo技术计算Π值(多线程)
π = 4 *(圆内点数) /(总的点数)
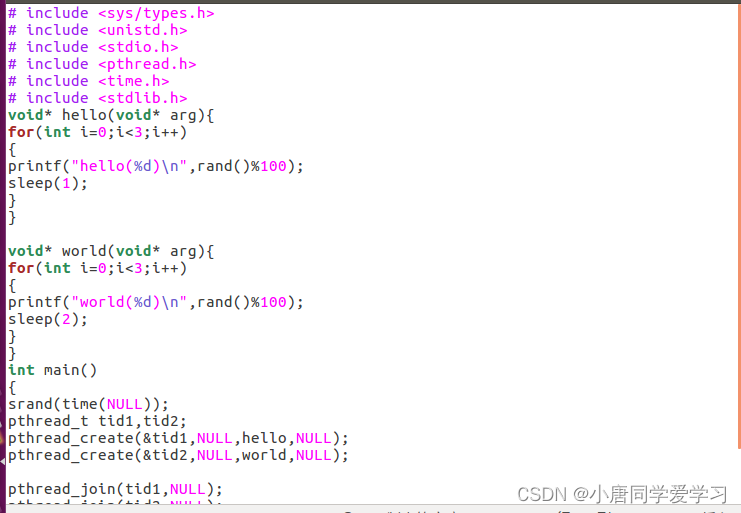
创建线程代码及解释:
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
#include <pthread.h>
void* threadFunc(void* arg){ //线程函数
printf("In NEW thread\n");
}
int main()
{
pthread_t tid;
pthread_create(&tid, NULL, threadFunc, NULL);
pthread_join(tid, NULL);
printf("In main thread\n");
return 0;
}pthread_create(&tid, NULL, threadFunc, NULL)函数讲解:
第一个参数:第一个参数是用来存储新创建的线程的线程id的地址
第二个参数:第二个参数是指定线程的属性地址
第三个参数:第三个参数是线程执行任务函数的地址(函数执行的起始地址)
第四个参数:第四个参数是传给线程函数参数的地址
该函数结束之后会立即返回,继续执行。
pthread_join(tid, NULL);函数讲解:
它是等待函数,等待指定线程结束后才结束。
执行结果:
![]()
将 pthread_join(tid, NULL)注释后执行结果:
![]()
造成这种结果的原因是主线程没有等待子线程结束后再结束,main线程结束后会回收所有资源。
实验一代码:
 运行结果:
运行结果:
结果可知两个线程是并发执行的
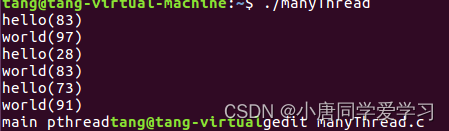
上图是解决的线程并发问题,下边是解决的数据共享问题:
代码:

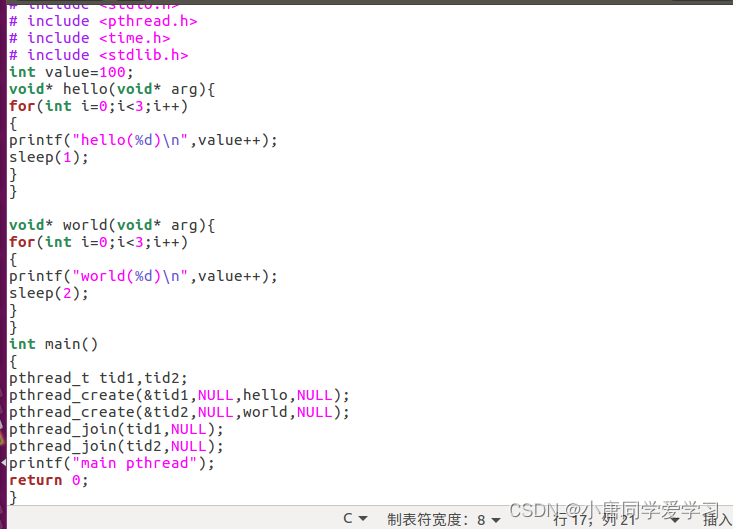 在代码中添加了一个全局变量,通过打印全局变量来进行分析
在代码中添加了一个全局变量,通过打印全局变量来进行分析
运行结果:
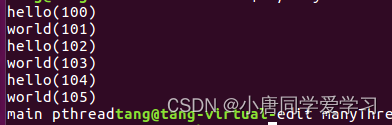
这里与父子进程的数据就产生了差别。
Monte Carlo技术计算Π值:
intervals变量是随机产生的点的数量
rand_x是随机产生点的横坐标
rand_y是随机生成点的纵坐标
随机生成点是通过rand函数生成,生成的数是在[0,RAND_MAX],每个系统都有自己的RAND_MAX,根据表达式,最后生成的x,y的坐标在单位圆中。
circle_points是落入圆内的点数
square_point是总共的点数
非多线程的计算方法:
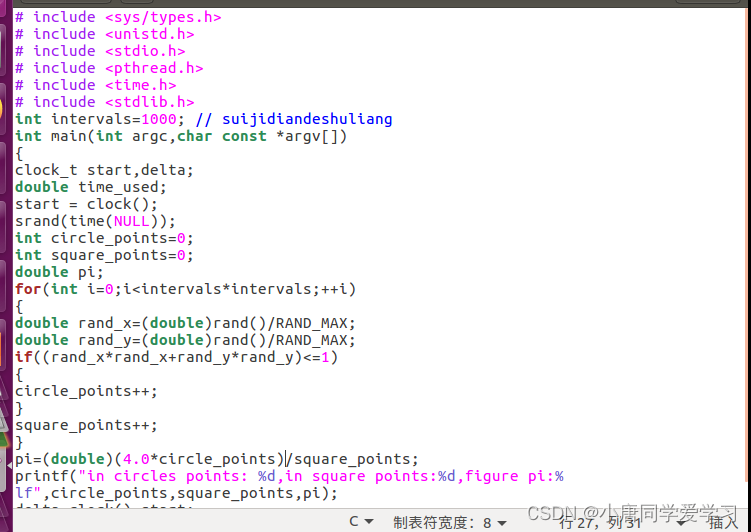

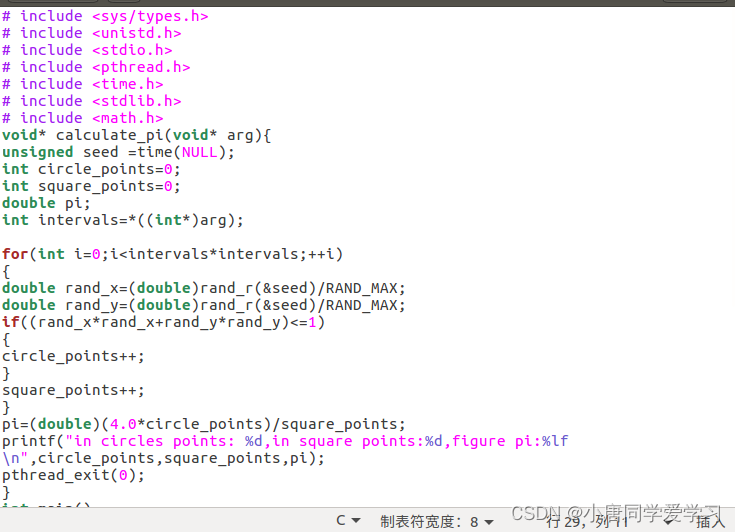
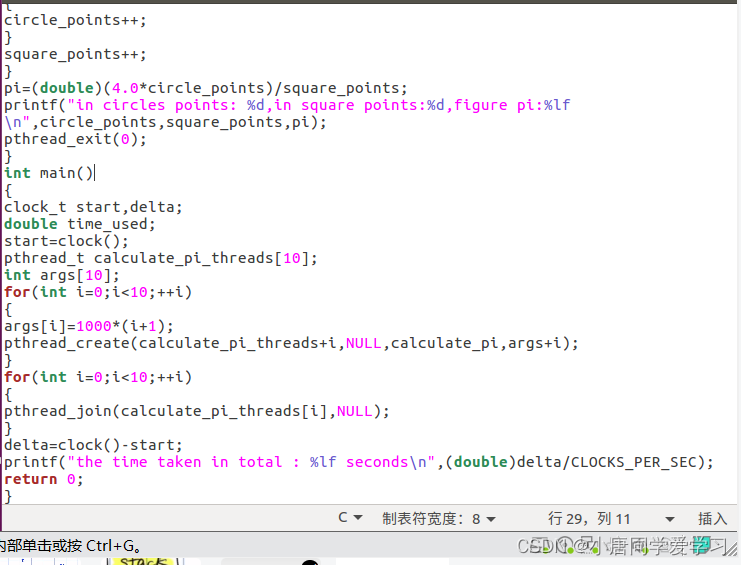
多线程实现:
通过多线程计算Π值,将线程函数单独实现,在main函数中调用。
在main函数中设置了两个数组,数组1存储线程号(跟随for循环的i值得变化而变化)、数组2存储得是调用函数得参数(该参数在线程中控制循环得次数,传入得是地址类型,在线程中转换成int*类型,再进行解引用)(值也是随for循环得i值而变化)
在mian函数中arg+i加的是一个int类型得地址(四个字节)(arg代表的是数组的首地址)。
 运行结果:
运行结果:
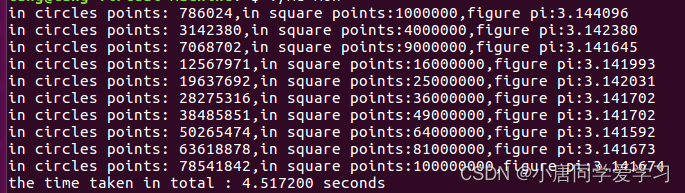
通过时间对比可知,单线程的开销比多线程的开销较小(线程的切换),当然这个是跟你给虚拟机所分配的cpu有关,在多个cpu实现多线程的时候,真正的消耗的时间是减小的,但是用户的时间是不变得,毕竟任务量是一定的。