欢迎访问个人网络日志🌹🌹知行空间🌹🌹
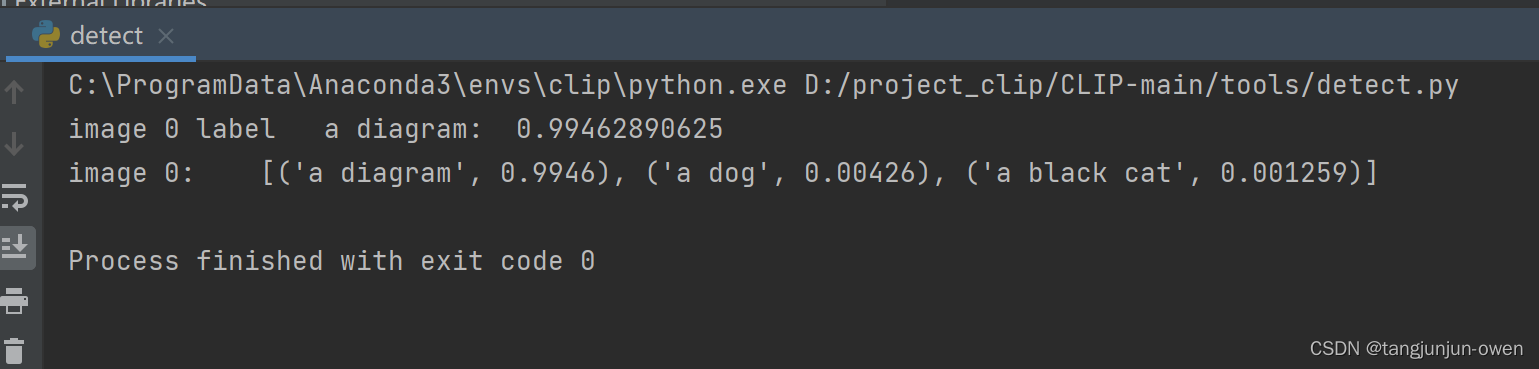
Mask R-CNN/YOLOV8/RTMDET三种实例分割方法推理逻辑对比
实例分割是同时检测与分割,即在检测出检测框的同时分割出检测中的对象。这样,不仅实现了语义分割,同时区分出了同类别的不同的对象。
以human这个类别为例,
检测任务:

分割任务:

实例分割:

从上面这个例子可以看出,检测任务定位了对象的包围框,语义分割分割出了人这个类别,不过把所有的人一起分割了,实例分割区分出了每个人,并分别进行了分割。
实际在做实例分割时,通常同时输出对象的检测框,并给出对象的分割结果。下面介绍三种常见的实例分割算法。
Mask R-CNN
首先是Mask R-CNN,在目标检测中有介绍过Mask RCNN是FAIR的何凯明等于2017年03月提交的论文Mask R-CNN中提出的,该算法同时支持目标检测\实例分割\关键点检测的任务。
论文:Mask R-CNN
代码:detectron2
在这里,不再介绍Mask RCNN的backbone和neck部分,关于RPN和ROI Pooling的介绍可以参考之前的文章:
1.ROI Pooling 与 ROI Align
2.Region Proposal Network
这里只讨论RoI Pooling后的Head部分,

Mask R-CNN同时支持输出检测框,实例分割结果,关键点,这里我们只讨论Mask Head部分,即上图中的右侧绿色分支。
值得注意的是,上图是粗略表示,关于proposal在Head中的使用和Mask/Box/KeyPoint Head之间的关系可以参考下面两个图。
在训练时,Mask/KeyPoint Head都使用proposal框来当作检测box框选对象,如下图蓝色线流所示:
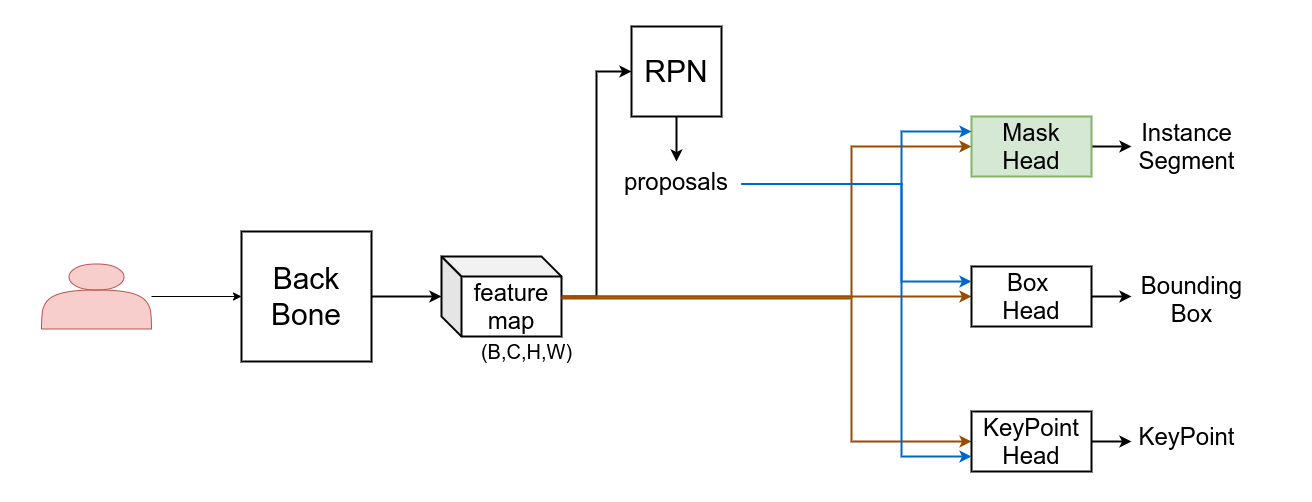
在预测时,Mask/KeyPoint Head不再使用proposals转而使用Box Head预测的检测框来框选对象,因此Mask/KeyPoint Head依赖检测框的输出,如下图紫色线流所示意,
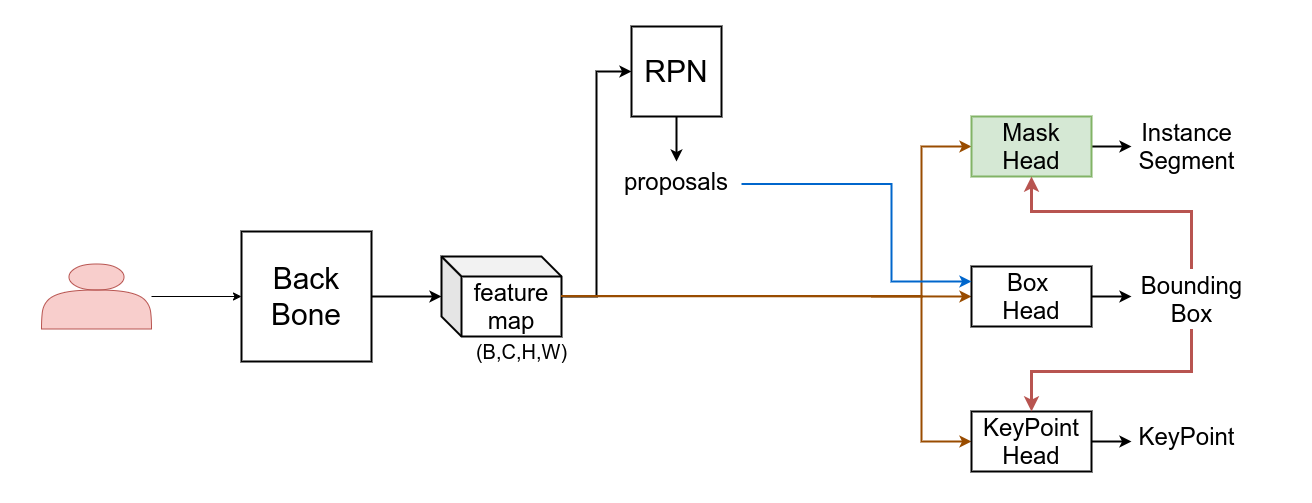
Mask R-CNN的Mask Head分析如下,整理自detectron2代码库:

Mask Head的输入有两个,一个是bounding boxes或者proposals(测试推理时使用boxes,训练时使用RPN给出的proposals),另一个是backbone提取的feature map。
Mask Head的结构如上图,先是对feature map根据bounding boxes做ROI Pooling,得到每个ROI的特征图,然后是连续几层常规卷积,最后再跟一层转置卷积进行X2上采样,同时卷积输出通道变成num_class,得到的输出shape=(B*N,num_class, 28, 28),这里28x28就是ROI区域对应的mask,这里对每个对象预测了num_class个mask,在Mask R-CNN中,直接使用Box Head预测的label id来取对应的mask并sigmoid以作为最终当前实例的分割结果。
转置卷积的介绍参考这里转置卷积。
得到28X28的实例ROI分割结果后,要将其变换到原图像上,这里使用了grid_sample方法,使用grid_sample变换,会根据box坐标将ROI Mask变换到原图像box所处的区域。变换后再根据超参数阈值对mask做二值化即可得到最后的分割结果。
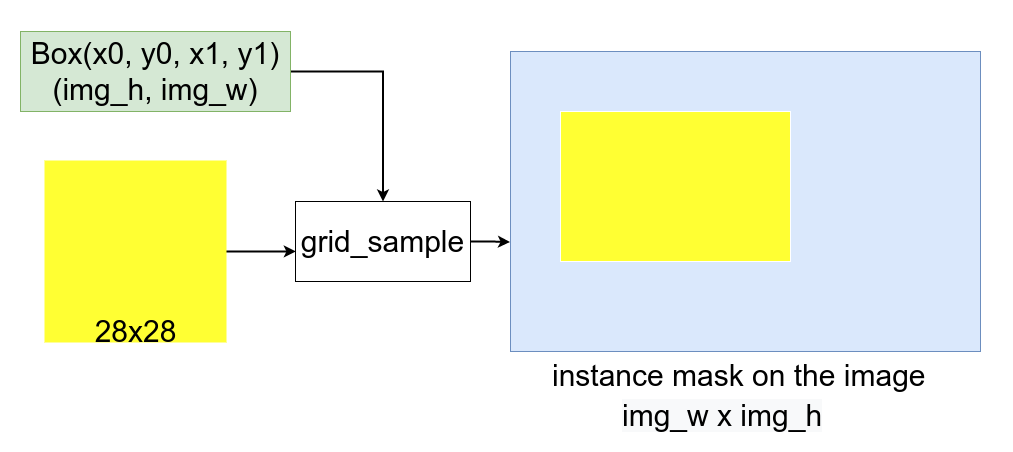
后记: 这里有个疑问,所有的ROI无论大小都使用了同样大小尺寸的ROI Feature Map都是28x28,但是正常难道不应该对大目标使用大尺寸,小目标使用小尺寸吗?
YOLOV5/8实例分割方法
YOLOV5/8中使用的Instance分割方法和Mask RCNN中区别比较大,
其利用Head1中尺寸最大的特征图作为Mask分支的输入,经过proto_pred卷积层的处理得到shape:(B, mask_channel, H, W)的mask_feature。
检测框的预测分支和目标检测中的YoloV5 Head基本相同,除了对于feature_map的通道上增加了计算每个实例掩码用的参数,参数的数量同proto_pred输出的mask_channel,所以对于80X80/40X40/20X20的feature_map,其通道数为: 4 + 1 + num_classes + mask_channel
拿到解码后的检测框,经过nms处理后得到最后的检测框,取对应的mask_channel个coeffs和mask_feature相乘加权即可得到最后的实例分割结果,完整过程如下图:
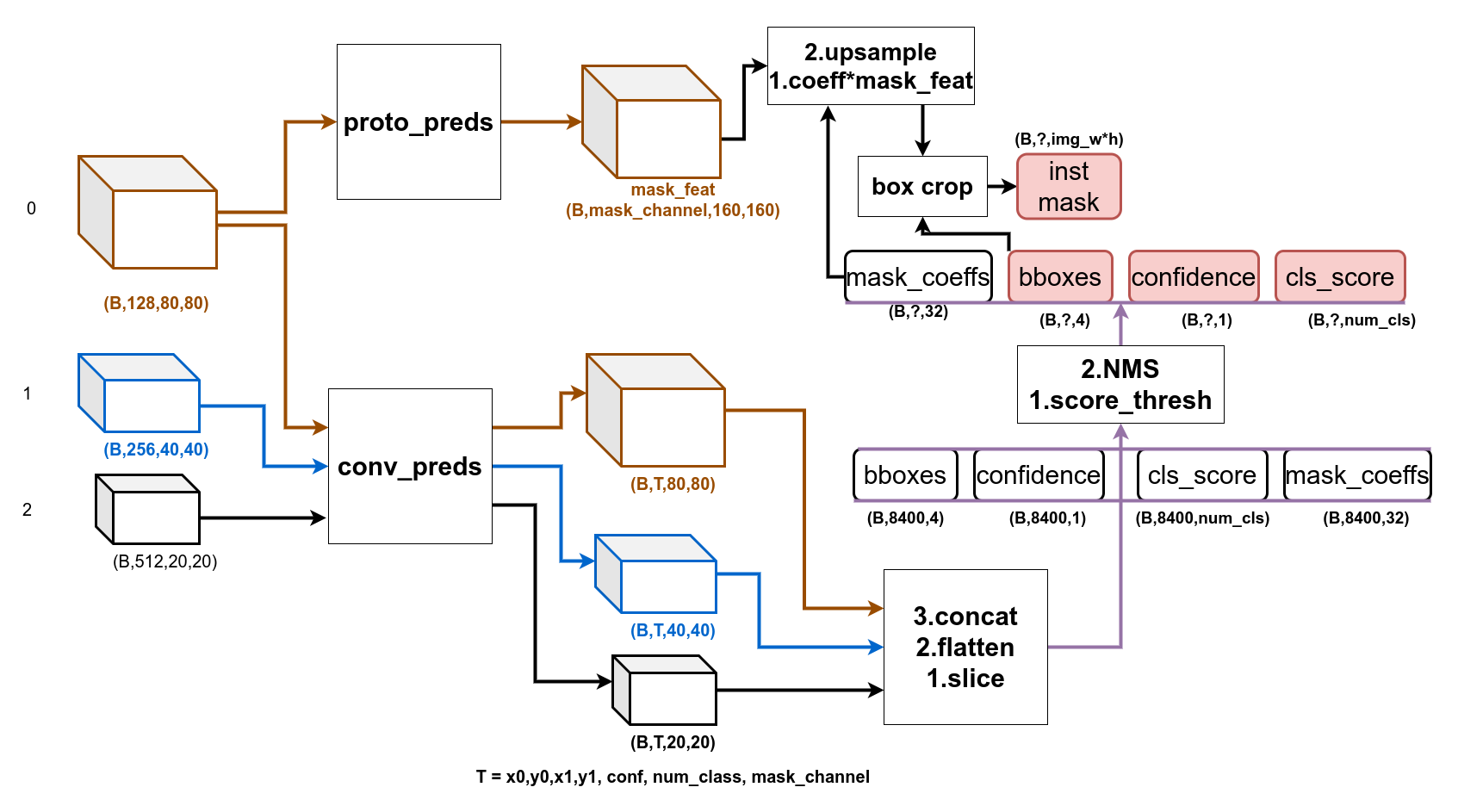
RTMDet中的实例分割
RTMDet中和YOLOV5处理方式很相似,都是对每个检测框实例计算坐标时同时给出预测mask所需的权重参数,区别在与YOLOV5/8中直接用参数和mask_feature进行加权求和,而RTMDET预测了169个参数,构造了3层卷积,来和mask_feature运算得到分割mask。
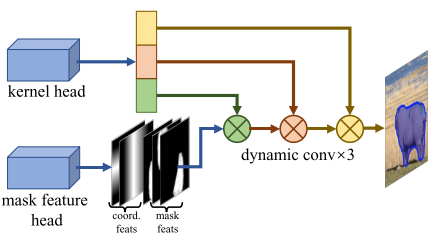
还有一点RTMDet中mask_feature 并非只使用了80X80的feature map,它还将其余两个头上的特征图上采样后与其进行concatenate,输入mask_feature分支后得到Batch_SizeX8X80X80的mask特征图。特征图并不能直接用来和predicted kernel卷积得到Instance Mask,RTMDet算法使用的mask feat先重复了检测实例的个数次,然后合并了检测框在特征图上的坐标,最后与predicted kernel做卷积的输入mask特征图变成了(N,10,80,80)。
RTMDet实例分割推理的完整过程可参考下图,
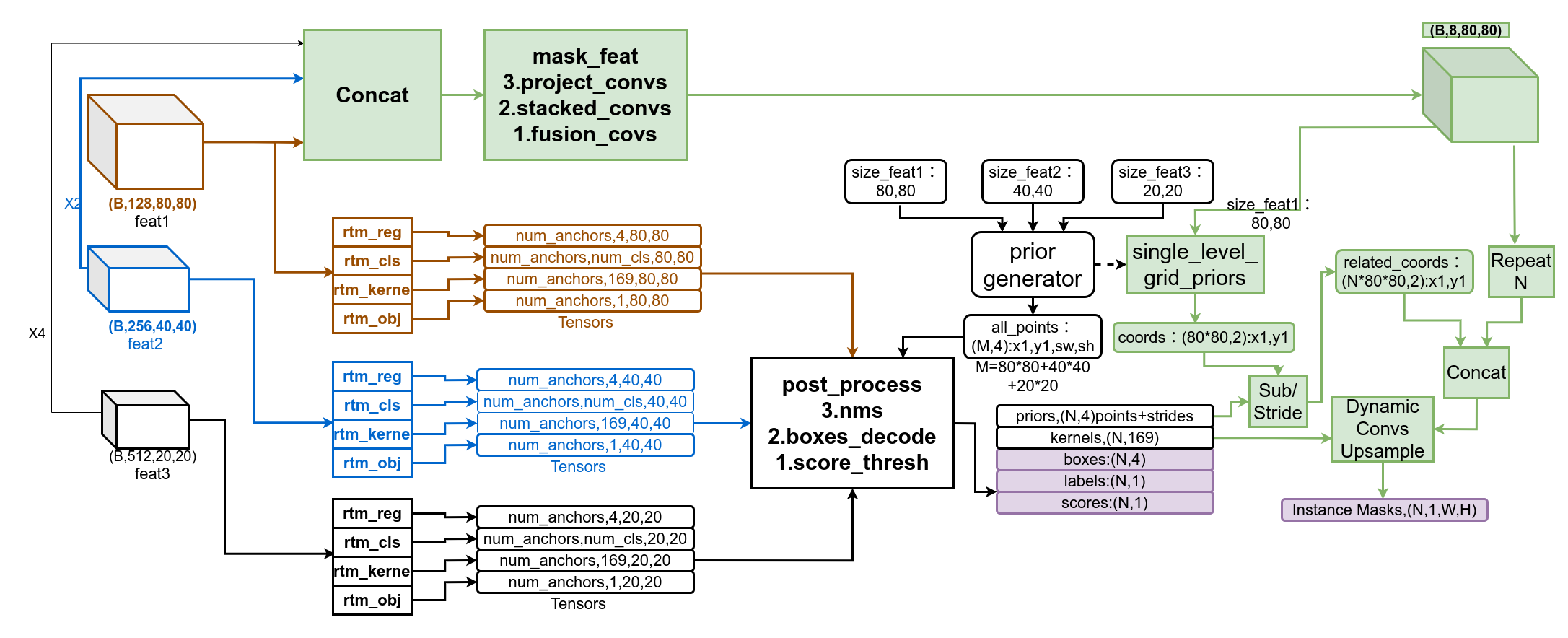
RTMDet根据predicted_kernel升成卷积的方法被称为动态卷积Dynamic Convolution,如下图,
欢迎访问个人网络日志🌹🌹知行空间🌹🌹
如上,就是Mask R-CNN/YOLOV8/RTMDet三种实例分割的方法,总结来看,YOLOV8/RTMDet方法相似,RTMDet处理mask预测的方法更复杂一些,YOLOV8中的加权求和变成了三层卷积,输入的特征图重复了num_instance次,并合并了mask_feature上对应的priors和num_instance对应点的相对坐标。YOLOV8/RTMDet输出Instance Mask的分辨率比Mask RCNN要大,Mask RCNN经过转置卷积上采样后输出的RoI分割图的大小是28X28,经过GridSample后还原到原分辨率上。不过Mask R-CNN输出的是RoI的分割图,而YOLOV8/RTMDet输出的是在整幅图像上的分割图。
1.https://github.com/ultralytics/ultralytics.git
2.https://arxiv.org/abs/2212.07784
3.https://github.com/facebookresearch/detectron2.git