SImilarity 搜索是一个问题,给定一个查询的目标是在所有数据库文档中找到与其最相似的文档。
一、介绍
在数据科学中,相似性搜索经常出现在NLP领域,搜索引擎或推荐系统中,其中需要检索最相关的文档或项目以进行查询。在大量数据中,有各种不同的方法可以提高搜索性能。
分层可导航小世界 (HNSW) 是一种最先进的算法,用于近似搜索最近的邻居。在后台,HNSW 构造了优化的图形结构,使其与本系列文章前面部分中讨论的其他方法非常不同。
HNSW的主要思想是构建这样一个图,其中任何一对顶点之间的路径都可以在少量步骤中遍历。
关于著名的六次握手规则的一个众所周知的类比与这种方法有关:
所有人之间的社交关系都相距六或更少。
在继续讨论 HNSW 的内部工作原理之前,让我们首先讨论跳过列表和可导航的小词——HNSW 实现中使用的关键数据结构。
二、跳过列表
跳过列表是一种概率数据结构,允许在排序列表中平均插入和搜索 O(logn) 的元素。跳过列表由几层链表构成。最低层具有原始链表,其中包含所有元素。当移动到更高级别时,跳过的元素数会增加,从而减少连接数。
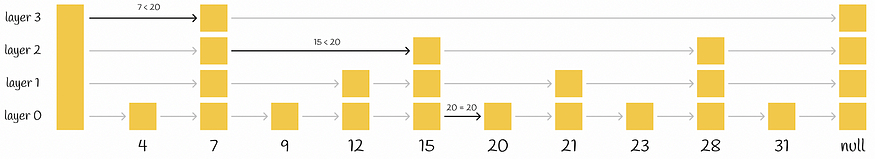
在跳过列表中查找元素 20
特定值的搜索过程从最高级别开始,并将其下一个元素与该值进行比较。如果该值小于或等于该元素,则算法将继续执行其下一个元素。否则,搜索过程将下降到具有更多连接的较低层,并重复相同的过程。最后,算法下降到最低层并找到所需的节点。
根据来自维基百科的信息,跳过列表具有主参数p,它定义了元素出现在多个列表中的概率。如果一个元素出现在层 i 中,那么它出现在层 i + 1 中的概率等于 p(p 通常设置为 0.5 或 0.25)。平均而言,每个元素都显示在1 / (1 - p)列表中。
正如我们所看到的,这个过程比链表中的正常线性搜索要快得多。事实上,HNSW继承了同样的想法,但它不是链表,而是使用图表。
三、可导航的小世界
可导航小世界是一个具有多对数 T = O(logkn) 搜索复杂性的图,它使用贪婪路由。路由是指从低度顶点开始搜索过程,以高度顶点结束的过程。由于低度顶点的连接很少,因此算法可以在它们之间快速移动,以有效地导航到最近邻居可能所在的区域。然后,算法逐渐放大并切换到高度顶点,以查找该区域顶点中的最近邻。
顶点有时也称为节点。
3.1 搜索
首先,通过选择入口点进行搜索。为了确定算法移动到的下一个顶点(或多个顶点),它会计算从查询向量到当前顶点的相邻顶点的距离,并移动到最近的顶点。在某些时候,当算法找不到比当前节点本身更靠近查询的邻居节点时,它会终止搜索过程。此节点作为对查询的响应返回。
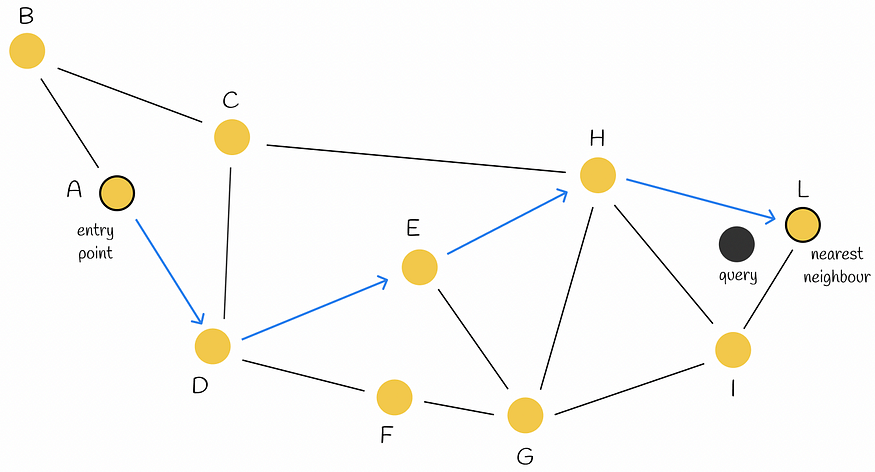
在可导航的小世界中贪婪的搜索过程。节点 A 用作入口点。它有两个邻居 B 和 D.节点 D 比 B 更接近查询。节点 D 有三个邻居 C、E 和 F.E 是离查询最近的邻居,所以我们移动到 E。最后,搜索过程将指向节点 L。由于 L 的所有邻居都比 L 本身离查询更远,因此我们停止算法并返回 L 作为查询的答案。
这种贪婪的策略并不能保证它会找到确切的最近邻,因为该方法在当前步骤中仅使用本地信息来做出决定。提前停止是算法的问题之一。特别是在搜索过程开始时,当没有比当前节点更好的相邻节点时,它就会发生。在大多数情况下,当起始区域具有太多低度顶点时,可能会发生这种情况。
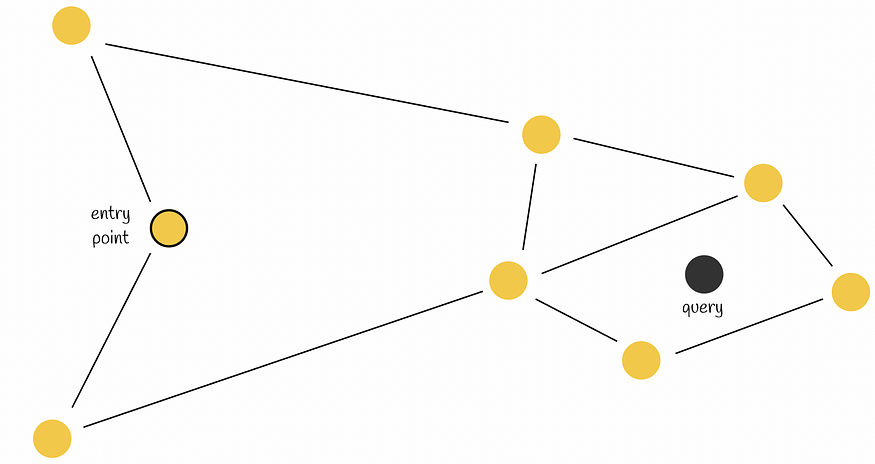
提早停止。当前节点的两个邻居都离查询更远。因此,该算法返回当前节点作为响应,尽管存在更接近查询的节点。
通过使用多个入口点可以提高搜索准确性。
3.2 建设
NSW 图是通过随机排列数据集点并将其逐个插入到当前图中来构建的。插入新节点时,该节点将通过边链接到离该节点最近的 M 个顶点。
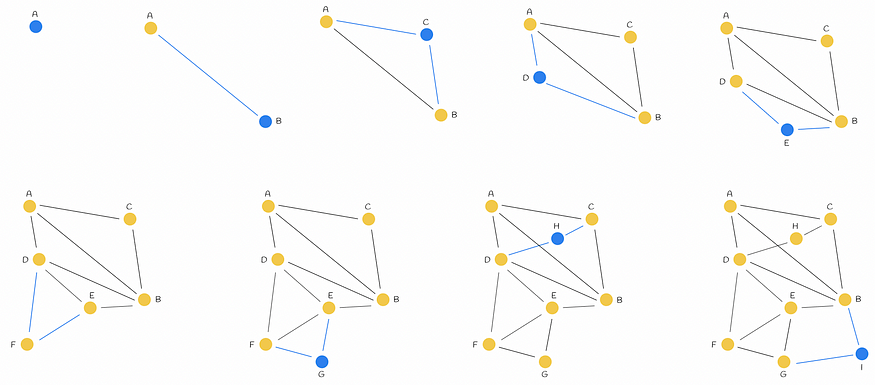
顺序插入节点(从左到右),M = 2。在每次迭代中,都会向图形中添加一个新顶点,并链接到其 M = 2 个最近邻。蓝线表示连接到新插入节点的边。
在大多数情况下,可能会在图形构建的开始阶段创建远程边缘。它们在图形导航中起着重要作用。
与在构造开始时插入的元素的最近邻居的链接稍后成为网络集线器之间的桥梁,这些网络集线器保持整体图形连接,并允许在贪婪路由期间对跃点数进行对数缩放。——俞.A.马尔科夫,D.A.亚舒宁
从上图中的例子中,我们可以看到一开始添加的远程边缘AB的重要性。假设一个查询需要从相对遥远的节点 A 和 I 遍历路径。拥有边缘 AB 可以通过直接从图形的一侧导航到另一侧来快速完成此操作。
随着图中顶点数量的增加,新连接到新节点的边的长度将减小的可能性也会增加。
四、高净值
HNSW基于与跳过列表和可导航小世界相同的原则。它的结构表示一个多层图,顶层的连接较少,底层区域更密集。
4.1 搜索
搜索从最高层开始,每次在层节点中贪婪地找到本地最近邻时,搜索都会进行到下面的一个级别。最终,在最低层找到的最近邻是查询的答案。
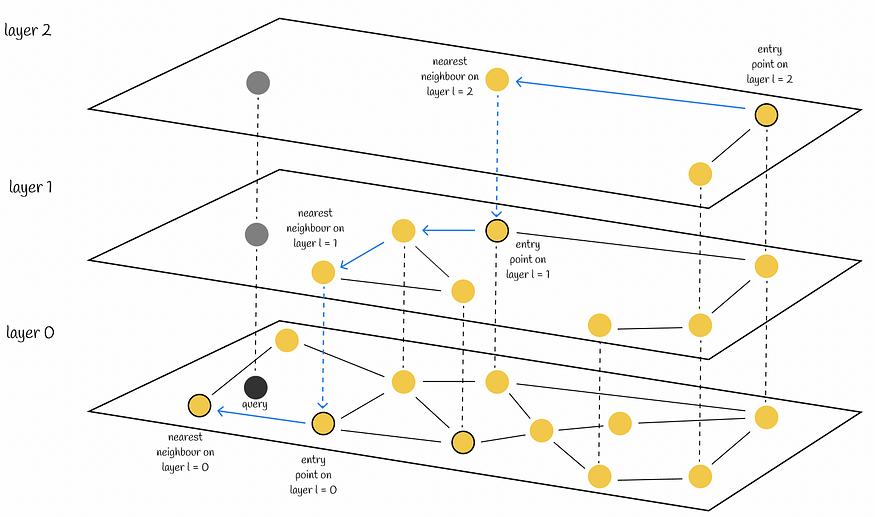
在HNSW中搜索
与新南威尔士州类似,HNSW的搜索质量可以通过使用多个入口点来提高。不是在每个层上只找到一个最近邻,而是找到与查询向量最近的 efSearch(超参数),并且这些邻域中的每一个都用作下一层的入口点。
4.2 复杂性
原始论文的作者声称,在任何层上找到最近邻所需的操作次数由一个常数限制。考虑到图中所有层的数量都是对数的,我们得到的总搜索复杂度为 O(logn)。
五、 HNSW建设
5.1 选择最大图层
HNSW 中的节点按顺序逐个插入。每个节点都被随机分配一个整数 l,指示该节点可以在图形中呈现的最大层。例如,如果 l = 1,则节点只能在第 0 层和第 1 层上找到。作者为每个节点随机选择l,其指数衰减概率分布由非零乘数mL归一化(mL = 0导致HNSW中的单层和非优化的搜索复杂性)。通常,大多数 l 值应等于 0,因此大多数节点仅存在于最低级别。mL 值越大,节点出现在较高层上的概率就越大。

每个节点的层数l是随机选择的,概率分布呈指数衰减。
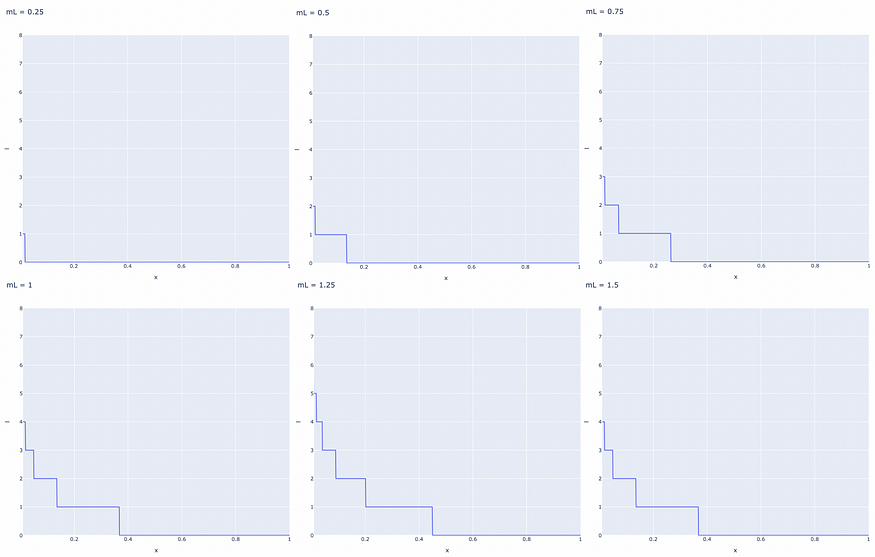
基于归一化因子mL的层数分布。水平轴表示均匀 (0, 1) 分布的值。
为了实现可控层次结构的最佳性能优势,不同层上的相邻元素之间的重叠(即也属于其他层的元素相邻元素的百分比)必须很小。——俞.A.马尔科夫,D.A.亚舒宁。
减少重叠的方法之一是减少毫升。但重要的是要记住,在对每层进行贪婪搜索期间,减少mL也会导致平均更多的遍历。这就是为什么必须选择这样一个 mL 值来平衡重叠和遍历次数的原因。
该论文的作者建议选择等于1 / ln(M)的mL的最佳值。该值对应于跳过列表的参数p = 1 / M,是层之间的平均单个元素重叠。
5.2 插入
为节点分配值 l 后,其插入有两个阶段:
- 算法从上层开始,贪婪地找到最近的节点。然后,找到的节点用作下一层的入口点,搜索过程继续。到达l层后,插入进入第二步。
- 从第 l 层开始,算法将新节点插入当前层。然后它的行为与之前在步骤 1 中相同,但它不是只找到一个最近的邻居,而是贪婪地搜索 efConstruction(超参数)最近的邻居。然后从 efConstruction 中选择 M 个相邻节点,并构建从插入节点到它们的边。之后,算法下降到下一层,每个找到的 efConstruction 节点充当入口点。算法在新节点及其边插入到最低层 0 后终止。
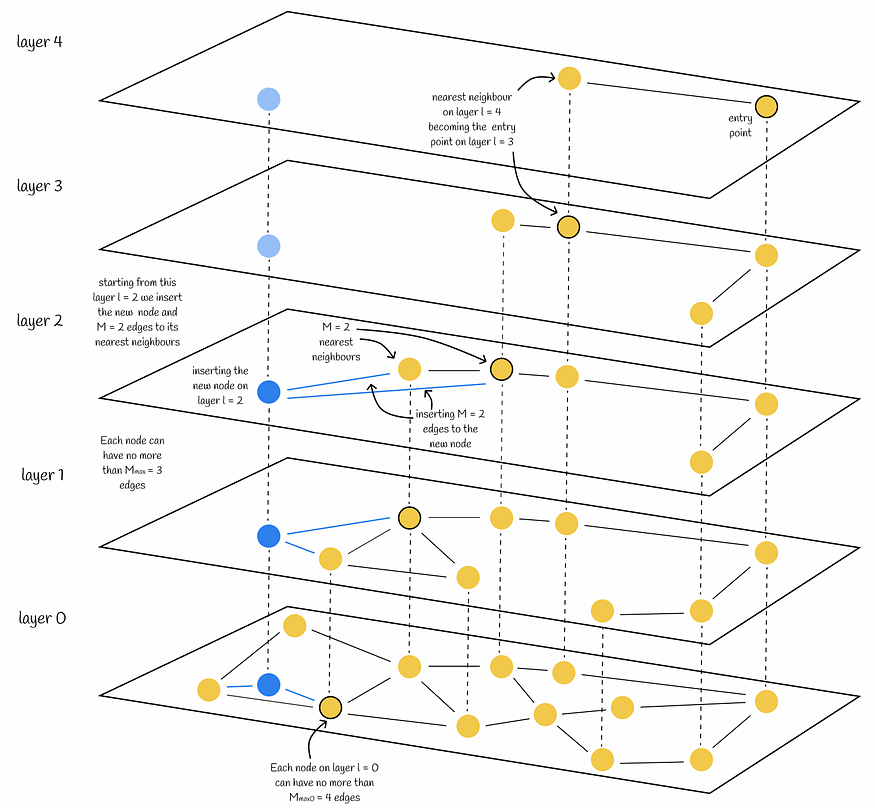
在 HNSW 中插入节点(蓝色)。新节点的最大层被随机选择为 l = 2。因此,节点将插入第 2、1 和 0 层。在这些层中的每一层上,节点将连接到其 M = 2 个最近的邻居。
5.3 选择构造参数的值
原始论文提供了有关如何选择超参数的几个有用的见解:
- 根据模拟,M 的良好值介于 5 和 48 之间。较小的 M 值往往更适合低召回率或低维数据,而较高的 M 值更适合高召回率或高维数据。
- 更高的 efConstruction 值意味着随着更多候选者的探索,搜索更深入。但是,它需要更多的计算。作者建议选择这样的 efConstruction 值,在训练期间导致召回率接近 0.95-1。
- 此外,还有另一个重要参数 Mmₐₓ — 顶点可以具有的最大边数。除此之外,存在相同的参数 Mmₐₓ₀,但分别用于最低层。建议为 Mmₐₓ 选择一个接近 2 * M 的值。大于 2 * M 的值可能会导致性能下降和内存使用过多。同时,Mmₐₓ = M 会导致高召回率下性能不佳。
5.4 候选人选择启发式
上面已经指出,在节点插入过程中,从 efConstruction 中选择 M 个候选者来构建它们的边。让我们讨论选择这些 M 节点的可能方法。
天真的方法将M视为最接近的候选人。然而,它并不总是最佳选择。下面是一个演示它的示例。
想象一个如下图所示结构的图表。如您所见,有三个区域,其中两个区域未相互连接(左侧和顶部)。因此,例如,从A点到B点需要通过另一个区域的长路径。以某种方式连接这两个区域以获得更好的导航是合乎逻辑的。
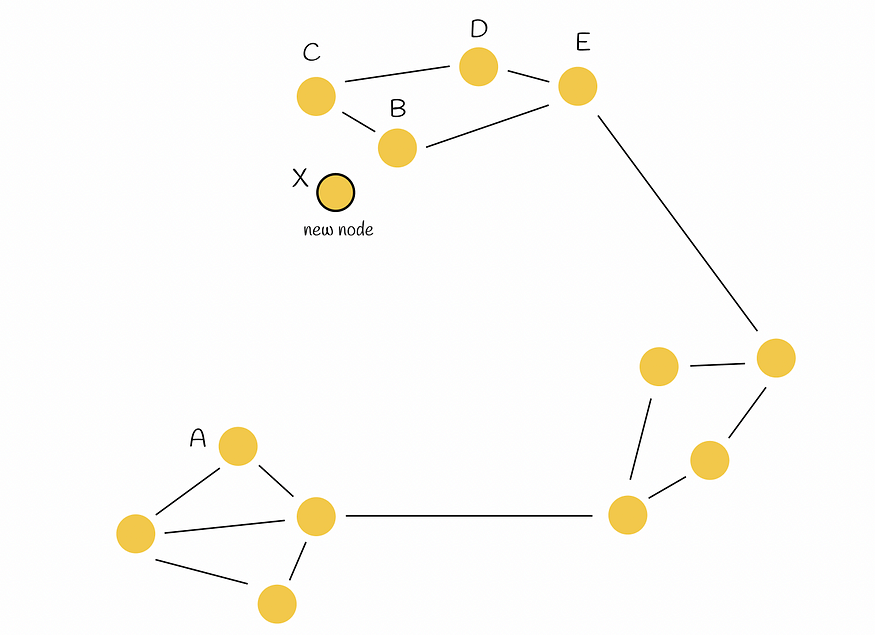
节点 X 将插入到图形中。目标是以最佳方式将其连接到其他 M = 2 点。
然后将节点 X 插入到图中,并需要链接到 M = 2 个其他顶点。
在这种情况下,朴素方法直接采用 M = 2 个最近的邻居(B 和 C)并将 X 连接到它们。虽然X连接到它真正的最近邻居,但它并不能解决问题。让我们看看作者发明的启发式方法。
启发式不仅考虑节点之间的最近距离,还考虑图上不同区域的连通性。
启发式选择第一个最近的邻居(在我们的例子中为 B)并将插入的节点 (X) 连接到它。然后,该算法按排序顺序 (C) 顺序获取另一个最近的最近邻,并且仅当从该相邻节点到新节点 (X) 的距离小于从该相邻节点到所有已连接的顶点 (B) 到新节点 (X) 的任何距离时,算法才会构建一条边。之后,算法继续到下一个最近的邻居,直到构建 M 条边。
回到示例,启发式过程如下图所示。启发式选择 B 作为 X 的最近邻,并构建边 BX。然后,该算法选择 C 作为下一个最近的最近邻。但是,这次BC<CX。这表明将边 CX 添加到图形中不是最佳选择,因为已经存在边 BX,并且节点 B 和 C 彼此非常接近。同样的类比在节点 D 和 E 上进行。之后,算法检查节点 A。这一次,它满足了自 BA > AX 以来的条件。因此,新的边 AX 和两个初始区域将相互连接。
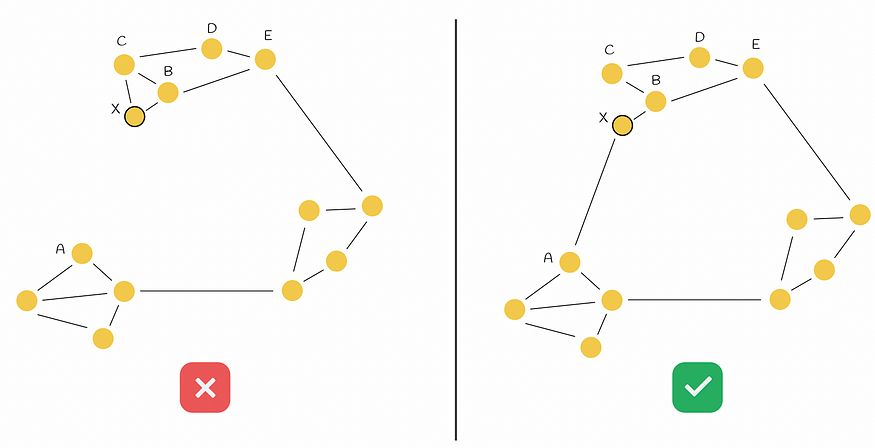
左边的例子使用了朴素的方法。右边的示例使用选择启发式,它导致两个初始不相交区域相互连接。
5.5 复杂性
与搜索过程相比,插入过程的工作方式非常相似,没有任何显着差异,可能需要非恒定数量的操作。因此,插入单个顶点会施加 O(logn) 的时间。要估计总复杂度,应考虑给定数据集中所有插入节点 n 的数量。最终,HNSW建设需要O(n * logn)时间。
六、将HNSW与其他方法相结合
HNSW 可以与其他相似性搜索方法一起使用,以提供更好的性能。最流行的方法之一是将其与倒排文件索引和产品量化 (IndexIVFPQ) 结合使用,本文系列的其他部分对此进行了介绍。
在此范式中,HNSW扮演IndexIVFPQ的粗量化器的角色,这意味着它将负责查找最近的Voronoi分区,因此可以缩小搜索范围。要做到这一点,必须在所有Voronoi质心上建立一个HNSW指数。当给定查询时,HNSW 用于查找最近的 Voronoi 质心(而不是像以前那样通过比较与每个质心的距离进行暴力搜索)。之后,在相应的Voronoi分区中量化查询向量,并使用PQ代码计算距离。
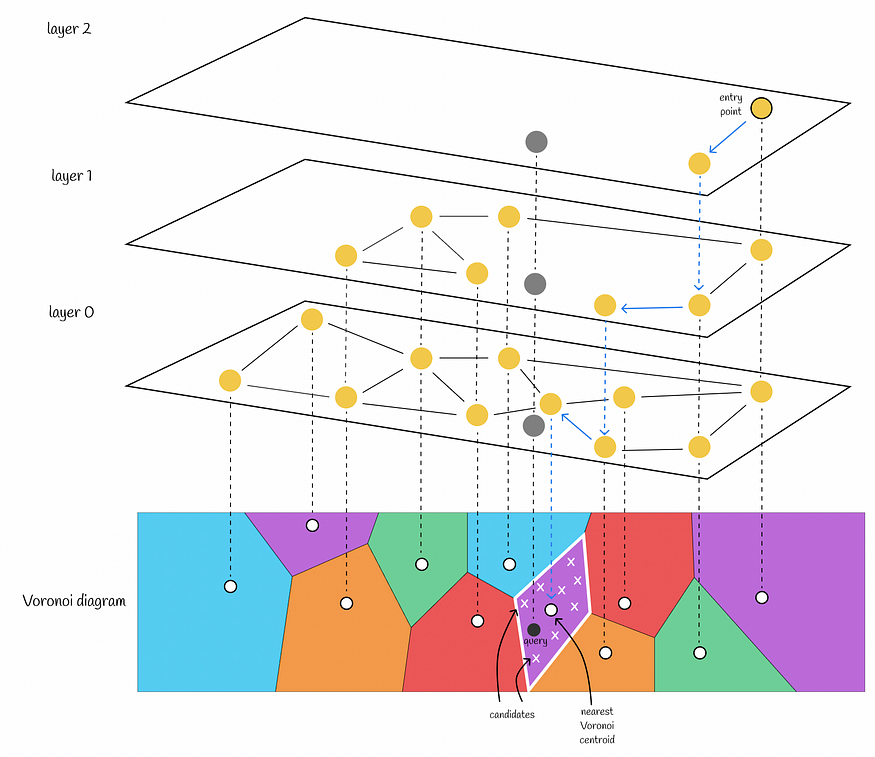
通过在 HNSW 中找到建在 Voronoi 质心之上的最近邻居来选择最近的 Voronoi 质心。
当仅使用倒排文件索引时,最好将 Voronoi 分区的数量设置为不要太大(例如 256 或 1024),因为执行暴力搜索以查找最近的质心。通过选择少量的Voronoi分区,每个分区内的候选者数量变得相对较大。因此,该算法可以快速识别查询的最近质心,并且其大部分运行时都集中在查找 Voronoi 分区内的最近邻。
但是,将 HNSW 引入工作流程需要进行调整。考虑仅在少量质心(256 或 1024)上运行 HNSW:HNSW 不会带来任何显著的好处,因为对于少量的向量,HNSW 在执行时间方面的性能与朴素暴力搜索相对相同。此外,HNSW需要更多的内存来存储图形结构。
这就是为什么在合并 HNSW 和倒排文件索引时,建议将 Voronoi 质心的数量设置为比平时大得多。通过这样做,每个Voronoi分区内的候选人数量就会少得多。
范式的这种转变导致以下设置:
- HNSW在对数时间内快速识别最近的Voronoi质心。
- 之后,在各自的Voronoi分区内进行详尽的搜索。这应该不是麻烦,因为潜在候选人的数量很少。
七、费斯实施
Faiss(Facebook AI Search Similarity)是一个用C++编写的Python库,用于优化的相似性搜索。该库提供了不同类型的索引,这些索引是用于有效存储数据和执行查询的数据结构。
根据 Faiss 文档中的信息,我们将了解如何利用 HNSW 并将其与倒排文件索引和产品量化合并在一起。
7.1 IndexHNSWFlat
FAISS有一个实现HNSW结构的类IndexHNSWFlat。像往常一样,后缀“Flat”表示数据集向量完全存储在索引中。构造函数接受 2 个参数:
- D:数据维度。
- M:插入过程中需要添加到每个新节点的边数。
此外,通过hnsw字段,IndexHNSWFlat提供了几个有用的属性(可以修改)和方法:
- hnsw.efConstruction:施工期间要探索的最近邻居数量。
- hnsw.efSearch:搜索期间要探索的最近邻居的数量。
- hnsw.max_level:返回最大层数。
- hnsw.entry_point:返回入口点。
- faiss.vector_to_array(index.hnsw.levels):返回每个矢量的最大层数列表
- hnsw.set_default_probas(M:整数,level_mult:浮点):允许分别设置 M 和 mL 值。默认情况下,level_mult设置为 1 / ln(M)。
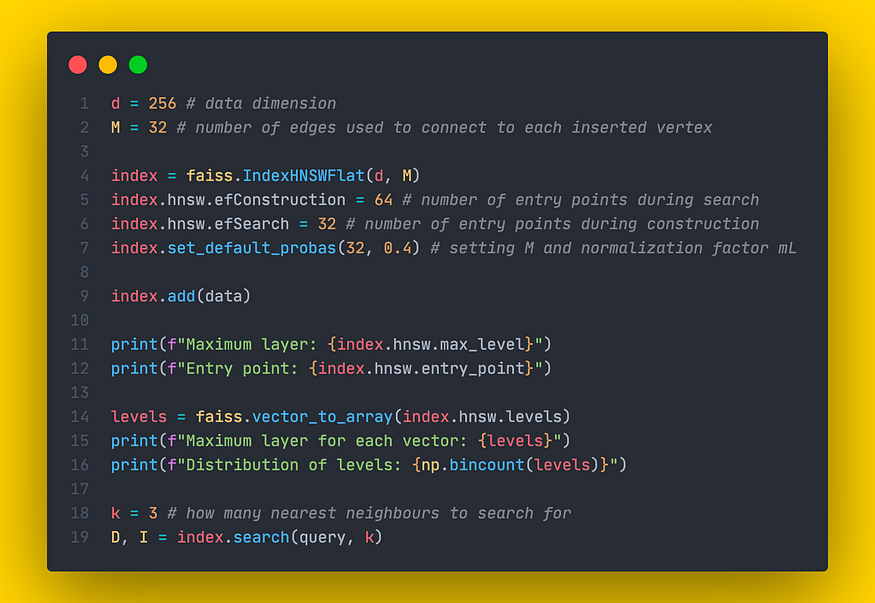
Faiss 实现 IndexHNSWFlat
IndexHNSWFlat 为 Mmₐₓ = M 和 Mmₐₓ ₀ = 2 * M 设置值。
7.2 IndexHNSWFlat + IndexIVFPQ
I ndexHNSWFlat 也可以与其他索引结合使用。其中一个例子是上一部分描述的IndexIVFPQ。此综合索引的创建分两个步骤进行:
- IndexHNSWFlat 初始化为粗量化器。
- 量化器作为参数传递给 IndexIVFPQ 的构造函数。
可以使用不同或相同的数据来完成训练和添加。

IndexHNSWFlat + IndexIVFPQ 的 FAISS 实现
八、结论
在本文中,我们研究了一种鲁棒算法,该算法特别适用于大型数据集向量。通过使用多层图表示和候选选择启发式,其搜索速度可以有效扩展,同时保持良好的预测精度。还值得注意的是,HNSW 可以与其他相似性搜索算法结合使用,使其非常灵活。
资源
- 六度分离 |维基百科
- 跳过列表 |维基百科
- 使用分层可导航小世界图进行高效而强大的近似最近邻搜索。禹。A.马尔科夫,D.A.亚舒宁
- 费斯文档
- 费斯存储库
- 费斯指数摘要
除非另有说明,否则所有图片均由作者提供。