什么是乐观锁?
乐观锁在实际开发过程中很常用,它没有加锁、没有阻塞,在多线程环境以及高并发的情况下 CPU 的利用率是最高的,吞吐量也是最大的。
而 Java Persistence API 协议也对乐观锁的操作做了规定:通过指定 @Version 字段对数据增加版本号控制,进而在更新的时候判断版本号是否有变化。如果没有变化就直接更新;如果有变化,就会更新失败并抛出“OptimisticLockException”异常。我们用 SQL 表示一下乐观锁的做法,代码如下:
复制代码
select uid,name,version from user where id=1;
update user set name='jack', version=version+1 where id=1 and version=1
假设本次查询的 version=1,在更新操作时,加上这次查出来的 Version,这样和我们上一个版本相同,就会更新成功,并且不会出现互相覆盖的问题,保证了数据的原子性。
这就是乐观锁在数据库里面的应用。那么在 Spring Data JPA 里面怎么做呢?我们通过用法来了解一下。
乐观锁的实现方法
JPA 协议规定,想要实现乐观锁可以通过 @Version 注解标注在某个字段上面,并且可以持久化到 DB 即可。其支持的类型有如下四种:
intorIntegershortorShortlongorLongjava.sql.Timestamp
这样就可以完成乐观锁的操作。我比较推荐使用 Integer 类型的字段,因为这样语义比较清晰、简单。
注意:Spring Data JPA 里面有两个 @Version 注解,请使用 @javax.persistence.Version,而不是 @org.springframework.data.annotation.Version。
我们通过如下几个步骤详细讲一下 @Version 的用法。
第一步:实体里面添加带 @Version 注解的持久化字段。
我在上一课时讲到了 BaseEntity,现在直接在这个基类里面添加 @Version 即可,当然也可以把这个字段放在 sub-class-entity 里面。我比较推荐你放在基类里面,因为这段逻辑是公共的字段。改动完之后我们看看会发生什么变化,如下所示:
复制代码
@Data
@MappedSuperclass
public class BaseEntity {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
@Version
private Integer version;
//......当然也可以用上一课时讲解的 auditing 字段,这里我们先省略
}
第二步:用 UserInfo 实体继承 BaseEntity,就可以实现 @Version 的效果,代码如下:
复制代码
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@ToString(callSuper = true)
public class UserInfo extends BaseEntity {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
private Integer ages;
private String telephone;
}
第三步:创建 UserInfoRepository,方便进行 DB 操作。
复制代码
public interface UserInfoRepository extends JpaRepository<UserInfo, Long> {}
第四步:创建 UserInfoService 和 UserInfoServiceImpl,用来模拟 Service 的复杂业务逻辑。
复制代码
public interface UserInfoService {
/**
* 根据 UserId 产生的一些业务计算逻辑
*/
UserInfo calculate(Long userId);
}
@Component
public class UserInfoServiceImpl implements UserInfoService {
@Autowired
private UserInfoRepository userInfoRepository;
/**
* 根据 UserId 产生的一些业务计算逻辑
* @param userId
* @return
*/
@Override @org.springframework.transaction.annotation.Transactional
public UserInfo calculate(Long userId) {
UserInfo userInfo = userInfoRepository.getOne(userId);
try {
//模拟复杂的业务计算逻辑耗时操作;
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
userInfo.setAges(userInfo.getAges()+1);
return userInfoRepository.saveAndFlush(userInfo);
}
}
其中,我们通过 @Transactional 开启事务,并且在查询方法后面模拟复杂业务逻辑,用来呈现多线程的并发问题。
第五步:按照惯例写个测试用例测试一下。
复制代码
@ExtendWith(SpringExtension.class)
@DataJpaTest
@ComponentScan(basePackageClasses=UserInfoServiceImpl.class)
public class UserInfoServiceTest {
@Autowired
private UserInfoService userInfoService;
@Autowired
private UserInfoRepository userInfoRepository;
@Test
public void testVersion() {
//加一条数据
UserInfo userInfo = userInfoRepository.save(UserInfo.builder().ages(20).telephone("1233456").build());
//验证一下数据库里面的值
Assertions.assertEquals(0,userInfo.getVersion());
Assertions.assertEquals(20,userInfo.getAges());
userInfoService.calculate(1L);
//验证一下更新成功的值
UserInfo u2 = userInfoRepository.getOne(1L);
Assertions.assertEquals(1,u2.getVersion());
Assertions.assertEquals(21,u2.getAges());
}
@Test
@Rollback(false)
@Transactional(propagation = Propagation.NEVER)
public void testVersionException() {
//加一条数据
userInfoRepository.saveAndFlush(UserInfo.builder().ages(20).telephone("1233456").build());
//模拟多线程执行两次
new Thread(() -> userInfoService.calculate(1L)).start();
try {
Thread.sleep(10L);//
} catch (InterruptedException e) {
e.printStackTrace();
}
//如果两个线程同时执行会发生乐观锁异常;
Exception exception = Assertions.assertThrows(ObjectOptimisticLockingFailureException.class, () -> {
userInfoService.calculate(1L);
//模拟多线程执行两次
});
System.out.println(exception);
}
}
从上面的测试得到的结果中,我们执行 testVersion(),会发现在 save 的时候, Version 会自动 +1,第一次初始化为 0;update 的时候也会附带 Version 条件。我们通过下图的 SQL,也可以看到 Version 的变化。

而当面我们调用 testVersionException() 测试方法的时候,利用多线程模拟两个并发情况,会发现两个线程同时取到了历史数据,并在稍后都对历史数据进行了更新。
由此你会发现,第二次测试的结果是乐观锁异常,更新不成功。请看一下测试的日志。
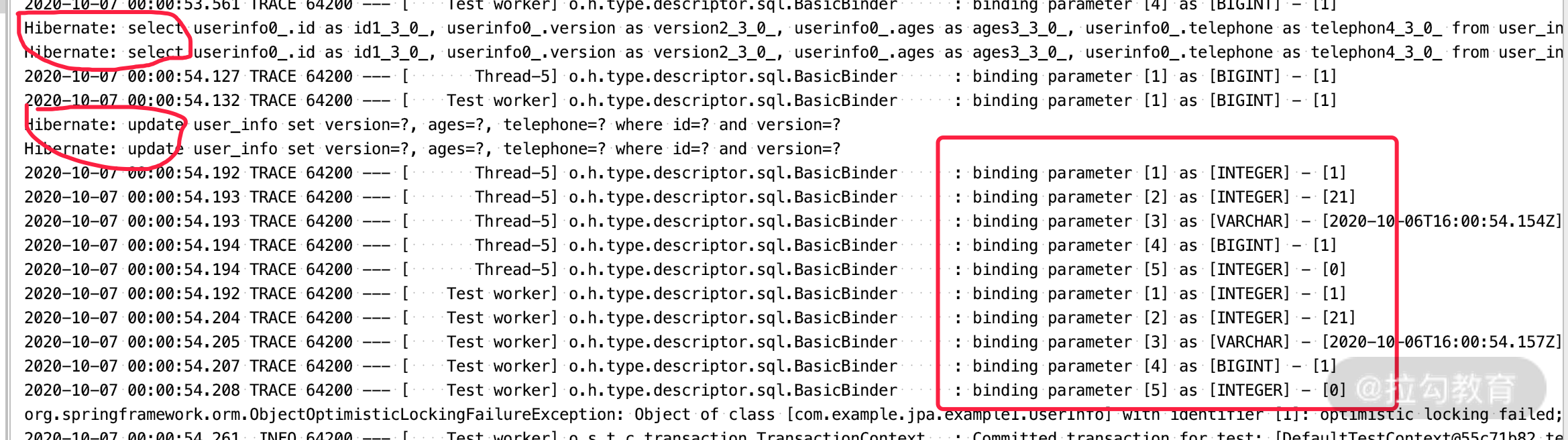
通过日志又会发现,两个 SQL 同时更新的时候,Version 是一样的,是它导致了乐观锁异常。
注意:乐观锁异常不仅仅是同一个方法多线程才会出现的问题,我们只是为了方便测试而采用同一个方法;不同的方法、不同的项目,都有可能导致乐观锁异常。乐观锁的本质是 SQL 层面发生的,和使用的框架、技术没有关系。
那么我们分析一下,@Version 对 save 的影响是什么,怎么判断对象是新增还是 update?
@Version 对 Save 方法的影响
通过上面的实例,你不难发现,@Version 底层实现逻辑和 @EntityListeners 一点关系没有,底层是通过 Hibernate 判断实体里面是否有 @Version 的持久化字段,利用乐观锁机制来创建和使用 Version 的值。
因此,还是那句话:Java Persistence API 负责制定协议,Hibernate 负责实现逻辑,Spring Data JPA 负责封装和使用。那么我们来看下 Save 对象的时候,如何判断是新增的还是 merge 的逻辑呢?
isNew 判断的逻辑
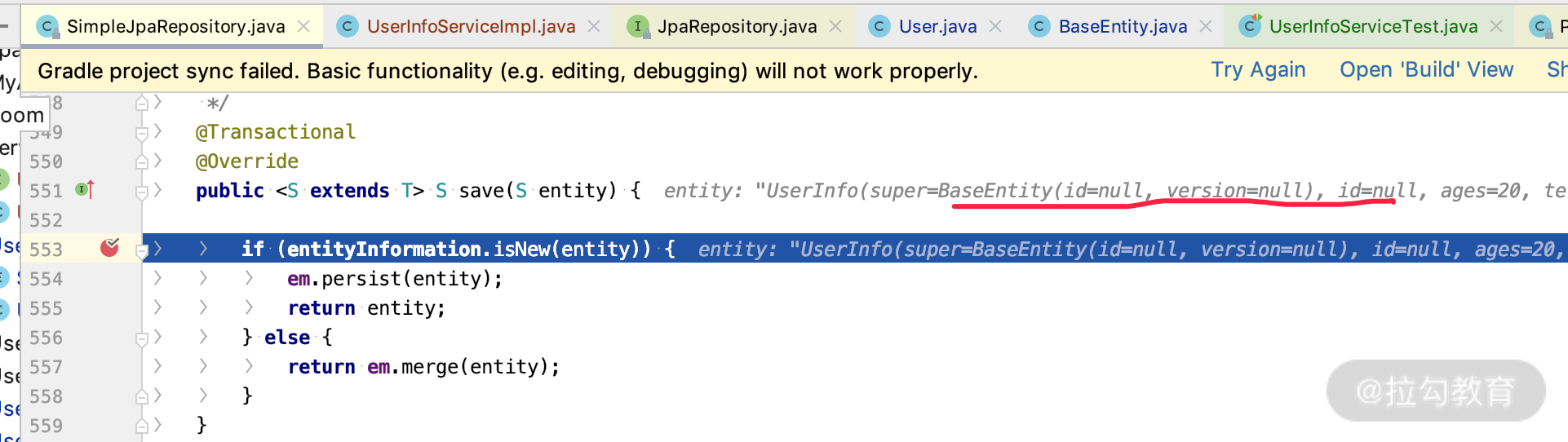
通过断点,我们可以进入SimpleJpaRepository.class 的 Save 方法中,看到如下图显示的界面:
然后,我们进入JpaMetamodelEntityInformation.class 的 isNew 方法中,又会看到下图显示的界面:

其中,我们先看第一段逻辑,判断其中是否有 @Version 标注的属性,并且该属性是否为基础类型。如果不满足条件,调用 super.isNew(entity) 方法,而 super.isNew 里面只判断了 ID 字段是否有值。
第二段逻辑表达的是,如果有 @Version 字段,那么看看这个字段是否有值,如果没有就返回 true,如果有值则返回 false。
由此可以得出结论:如果我们有 @Version 注解的字段,就以 @Version 字段来判断新增 / update;如果没有,那么就以 @ID 字段是否有值来判断新增 / update。
需要注意的是:虽然我们看到的是 merge 方法,但是不一定会执行 update 操作,里面还有很多逻辑,有兴趣的话你可以再 debug 进去看看。
我直接说一下结论,merge 方法会判断对象是否为游离状态,以及有无 ID 值。它会先触发一条 select 语句,并根据 ID 查一下这条记录是否存在,如果不存在,虽然 ID 和 Version 字段都有值,但也只是执行 insert 语句;如果本条 ID 记录存在,才会执行 update 的 sql。至于这个具体的 insert 和 update 的 sql、传递的参数是什么,你可以通过控制台研究一下。
总之,如果我们使用纯粹的 saveOrUpdate方法,那么完全不需要自己写这一段逻辑,只要保证 ID 和 Version 存在该有的值就可以了,JPA 会帮我们实现剩下的逻辑。
实际工作中,特别是分布式更新的时候,很容易碰到乐观锁,这时候还要结合重试机制才能完美解决我们的问题,接下来看看具体该怎么做。
乐观锁机制和重试机制在实战中应该怎么用?
我们先了解一下 Spring 支持的重试机制是什么样的。
重试机制详解
Spring 全家桶里面提供了@Retryable 的注解,会帮我们进行重试。下面看一个 @Retryable 的例子。
第一步:利用 gradle 引入 spring-retry 的依赖 jar,如下所示:
复制代码
implementation 'org.springframework.retry:spring-retry'
第二步:在 UserInfoserviceImpl 的方法中添加 @Retryable 注解,就可以实现重试的机制了,代码如下:
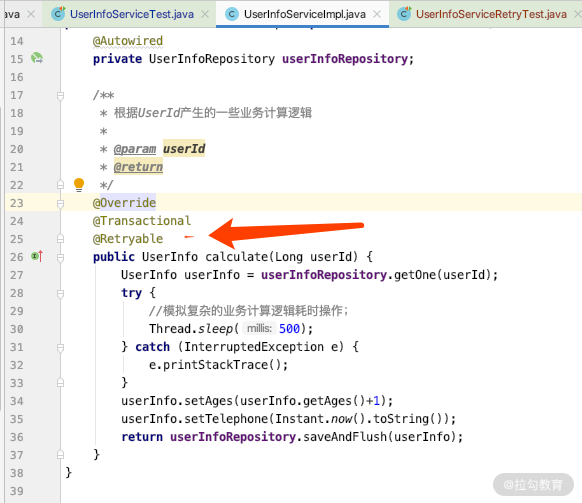
第三步:新增一个RetryConfiguration并添加@EnableRetry 注解,是为了开启重试机制,使 @Retryable 生效。
复制代码
@EnableRetry
@Configuration
public class RetryConfiguration {
}
第四步:新建一个测试用例测试一下。
复制代码
@ExtendWith(SpringExtension.class)
@DataJpaTest
@ComponentScan(basePackageClasses=UserInfoServiceImpl.class)
@Import(RetryConfiguration.class)
public class UserInfoServiceRetryTest {
@Autowired
private UserInfoService userInfoService;
@Autowired
private UserInfoRepository userInfoRepository;
@Test
@Rollback(false)
@Transactional(propagation = Propagation.NEVER)
public void testRetryable() {
//加一条数据
userInfoRepository.saveAndFlush(UserInfo.builder().ages(20).telephone("1233456").build());
//模拟多线程执行两次
new Thread(() -> userInfoService.calculate(1L)).start();
try {
Thread.sleep(10L);//
} catch (InterruptedException e) {
e.printStackTrace();
}
//模拟多线程执行两次,由于加了@EnableRetry,所以这次也会成功
UserInfo userInfo = userInfoService.calculate(1L);
//经过了两次计算,年龄变成了 22
Assertions.assertEquals(22,userInfo.getAges());
Assertions.assertEquals(2,userInfo.getVersion());
}
}
这里要说的是,我们在测试用例里面执行 @Import(RetryConfiguration.class),这样就开启了重试机制,然后继续在里面模拟了两次线程调用,发现第二次发生了乐观锁异常之后依然成功了。为什么呢?我们通过日志可以看到,它是失败了一次之后又进行了重试,所以第二次成功了。
通过案例你会发现 Retry 的逻辑其实很简单,只需要利用 @Retryable 注解即可,那么我们看一下这个注解的详细用法。
@Retryable 详细用法
其源码里面提供了很多方法,看下面这个图片。

下面对常用的 @Retryable 注解中的参数做一下说明:
- maxAttempts:最大重试次数,默认为 3,如果要设置的重试次数为 3,可以不写;
- value:抛出指定异常才会重试;
- include:和 value 一样,默认为空,当 exclude 也为空时,默认异常;
- exclude:指定不处理的异常;
- backoff:重试等待策略,默认使用 @Backoff@Backoff 的 value,默认为 1s,请看下面这个图。

其中:
- value=delay:隔多少毫秒后重试,默认为 1000L,单位是毫秒;
- multiplier(指定延迟倍数)默认为 0,表示固定暂停 1 秒后进行重试,如果把 multiplier 设置为 1.5,则第一次重试为 2 秒,第二次为 3 秒,第三次为 4.5 秒。
下面是一个关于 @Retryable 扩展的使用例子,具体看一下代码:
复制代码
@Service
public interface MyService {
@Retryable( value = SQLException.class,
maxAttempts = 2, backoff = @Backoff(delay = 100))
void retryServiceWithCustomization(String sql) throws SQLException;
}
可以看到,这里明确指定 SQLException.class 异常的时候需要重试两次,每次中间间隔 100 毫秒。
复制代码
@Service
public interface MyService {
@Retryable( value = SQLException.class, maxAttemptsExpression = "${retry.maxAttempts}",
backoff = @Backoff(delayExpression = "${retry.maxDelay}"))
void retryServiceWithExternalizedConfiguration(String sql) throws SQLException;
}
此外,你也可以利用 SpEL 表达式读取配置文件里面的值。
关于 Retryable 的语法就介绍到这里,常用的基本就这些,如果你遇到更复杂的场景,可以到 GitHub 中看一下官方的 Retryable 文档:https://github.com/spring-projects/spring-retry。下面再给你分享一个我在使用乐观锁+重试机制中的最佳实践。
乐观锁+重试机制的最佳实践
我比较建议你使用如下配置:
复制代码
@Retryable(value = ObjectOptimisticLockingFailureException.class,backoff = @Backoff(multiplier = 1.5,random = true))
这里明确指定 ObjectOptimisticLockingFailureException.class 等乐观锁异常要进行重试,如果引起其他异常的话,重试会失败,没有意义;而 backoff 采用随机 +1.5 倍的系数,这样基本很少会出现连续 3 次乐观锁异常的情况,并且也很难发生重试风暴而引起系统重试崩溃的问题。
到这里讲的一直都是乐观锁相关内容,那么 JPA 也支持悲观锁吗?
除了乐观锁,悲观锁的类型怎么实现?
Java Persistence API 2.0 协议里面有一个 LockModeType 枚举值,里面包含了所有它支持的乐观锁和悲观锁的值,我们看一下。
复制代码
public enum LockModeType
{
//等同于OPTIMISTIC,默认,用来兼容2.0之前的协议
READ,
//等同于OPTIMISTIC_FORCE_INCREMENT,用来兼容2.0之前的协议
WRITE,
//乐观锁,默认,2.0协议新增
OPTIMISTIC,
//乐观写锁,强制version加1,2.0协议新增
OPTIMISTIC_FORCE_INCREMENT,
//悲观读锁 2.0协议新增
PESSIMISTIC_READ,
//悲观写锁,version不变,2.0协议新增
PESSIMISTIC_WRITE,
//悲观写锁,version会新增,2.0协议新增
PESSIMISTIC_FORCE_INCREMENT,
//2.0协议新增无锁状态
NONE
}
悲观锁在 Spring Data JPA 里面是如何支持的呢?很简单,只需要在自己的 Repository 里面覆盖父类的 Repository 方法,然后添加 @Lock 注解并指定 LockModeType 即可,请看如下代码:
复制代码
public interface UserInfoRepository extends JpaRepository<UserInfo, Long> {
@Lock(LockModeType.PESSIMISTIC_WRITE)
Optional<UserInfo> findById(Long userId);
}
你可以看到,UserInfoRepository 里面覆盖了父类的 findById 方法,并指定锁的类型为悲观锁。如果我们将 service 改调用为悲观锁的方法,会发生什么变化呢?如下图所示:

然后再执行上面测试中 testRetryable 的方法,跑完测试用例的结果依然是通过的,我们看下日志。
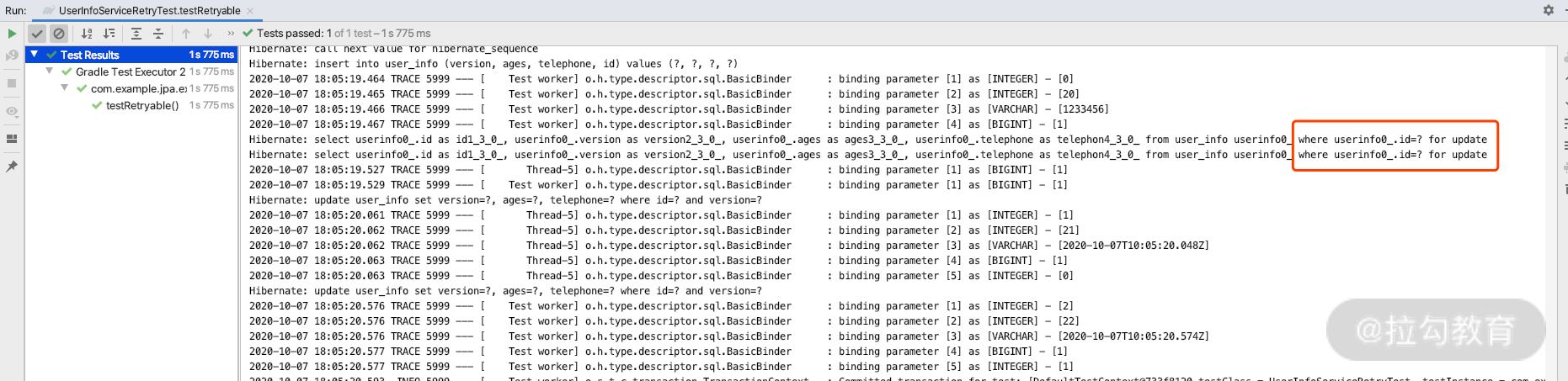
你会看到,刚才的串行操作完全变成了并行操作。所以少了一次 Retry 的过程,结果还是一样的。但是,你在生产环境中要慎用悲观锁,因为它是阻塞的,一旦发生服务异常,可能会造成死锁的现象。