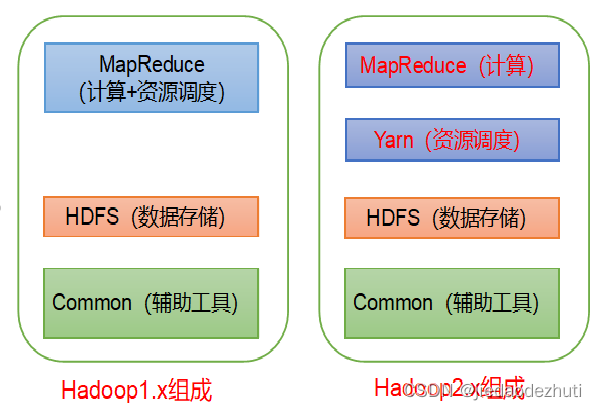
自 2017 年推出以来,Transformer 已成为机器学习领域的一支重要力量,彻底改变了翻译和自动完成服务的功能。
最近,随着 OpenAI 的 ChatGPT、GPT-4 和 Meta 的 LLama 等大型语言模型的出现,Transformer 的受欢迎程度进一步飙升。这些引起了巨大关注和兴奋的模型都是建立在 Transformer 架构的基础上的。通过利用 Transformer 的力量,这些模型在自然语言理解和生成方面取得了显着的突破。
尽管有很多很好的资源可以解释Transformer的工作原理,但我发现自己处于这样的境地:我理解其机制如何在数学上工作,但发现很难直观地解释Transformer如何工作。
在这篇博文[1]中,我的目标是在不依赖代码或数学的情况下提供Transformer如何工作的高级解释。我的目标是避免混淆技术术语以及与以前的架构进行比较。虽然我会尽量让事情变得简单,但这并不容易,因为Transformer相当复杂,但我希望它能让人们更好地直观地了解它们的作用以及如何做到这一点。
什么是Transformer?
Transformer 是一种神经网络架构,非常适合涉及处理序列作为输入的任务。也许在这种情况下,序列最常见的例子是句子,我们可以将其视为有序的单词集。
这些模型的目的是为序列中的每个元素创建数字表示;封装有关元素及其相邻上下文的基本信息。然后,所得的数字表示可以传递到下游网络,下游网络可以利用这些信息来执行各种任务,包括生成和分类。
通过创建如此丰富的表示,这些模型使下游网络能够更好地理解输入序列中的底层模式和关系,从而增强它们生成连贯且上下文相关的输出的能力。
Transformer 的主要优势在于它们能够处理序列内的远程依赖关系,并且效率很高;能够并行处理序列。这对于机器翻译、情感分析和文本生成等任务特别有用。

什么是注意力 ?
也许 Transformer 架构使用的最重要的机制被称为注意力,它使网络能够理解输入序列的哪些部分与给定任务最相关。对于序列中的每个标记,注意力机制会识别哪些其他标记对于理解给定上下文中的当前标记很重要。在我们探索如何在变压器中实现这一点之前,让我们先从简单的开始,尝试理解注意力机制试图从概念上实现什么,以建立我们的直觉。
理解注意力的一种方法是将其视为一种用包含有关其相邻标记信息的嵌入替换每个标记嵌入的方法;而不是对每个标记使用相同的嵌入,而不管其上下文如何。如果我们知道哪些标记与当前标记相关,捕获此上下文的一种方法是创建这些嵌入的加权平均值,或者更一般地说,创建线性组合。
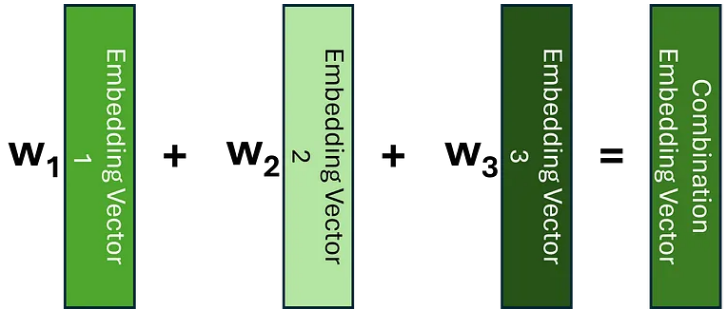
让我们考虑一个简单的例子,说明如何查找我们之前看到的句子之一。在应用注意力之前,序列中的嵌入没有其邻居的上下文。因此,我们可以将单词 light 的嵌入可视化为以下线性组合。

在这里,我们可以看到我们的权重只是单位矩阵。应用我们的注意力机制后,我们希望学习一个权重矩阵,以便我们可以用类似于以下的方式表达我们的光嵌入。

这次,我们为与我们选择的标记序列中最相关的部分相对应的嵌入赋予了更大的权重;这应该确保在新的嵌入向量中捕获最重要的上下文。包含当前上下文信息的嵌入有时被称为上下文嵌入,这就是我们最终想要创建的。
注意力是如何计算的?
注意力有多种类型,主要区别在于用于执行线性组合的权重的计算方式。在这里,我们将考虑原始论文中介绍的缩放点积注意力,因为这是最常见的方法。在本节中,假设我们所有的嵌入都已进行位置编码。
回想一下,我们的目标是使用原始嵌入的线性组合来创建上下文嵌入,让我们从简单开始,假设我们可以将所需的所有必要信息编码到我们学习的嵌入向量中,而我们需要计算的只是权重。
为了计算权重,我们必须首先确定哪些标记彼此相关。为了实现这一点,我们需要建立两个嵌入之间的相似性概念。表示这种相似性的一种方法是使用点积,我们希望学习嵌入,以便较高的分数表明两个单词更相似。
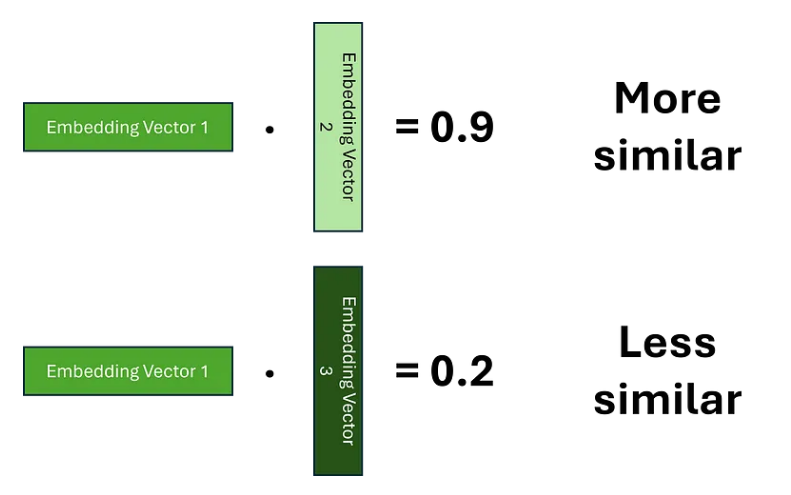
由于对于每个标记,我们需要计算其与序列中每个其他标记的相关性,因此我们可以将其概括为矩阵乘法,这为我们提供了权重矩阵;这通常被称为注意力分数。为了确保权重总和为 1,我们还应用了 SoftMax 函数。然而,由于矩阵乘法可以产生任意大的数字,这可能会导致 SoftMax 函数针对较大的注意力分数返回非常小的梯度;这可能会导致训练过程中梯度消失的问题。为了解决这个问题,在应用 SoftMax 之前,将注意力分数乘以缩放因子。
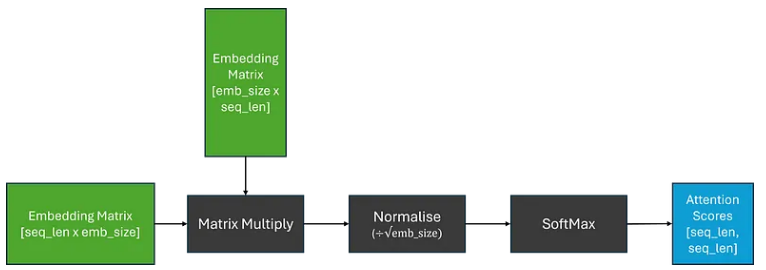
现在,为了获得上下文嵌入矩阵,我们可以将注意力分数乘以原始嵌入矩阵;这相当于对我们的嵌入进行线性组合。
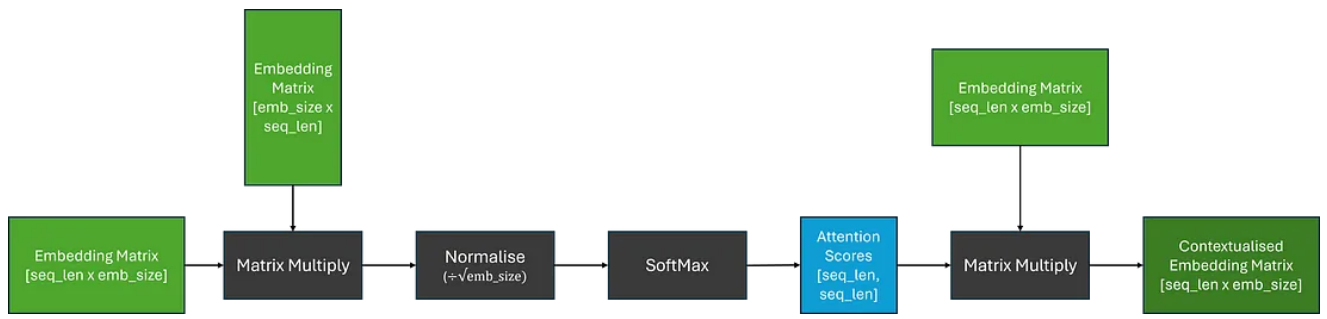
虽然模型有可能学习足够复杂的嵌入来生成注意力分数和随后的上下文嵌入;我们试图将大量信息压缩到通常很小的嵌入维度中。
因此,为了让模型学习任务稍微容易一些,让我们引入一些更容易学习的参数!我们不直接使用嵌入矩阵,而是通过三个独立的线性层(矩阵乘法);这应该使模型能够“关注”嵌入的不同部分。如下图所示:
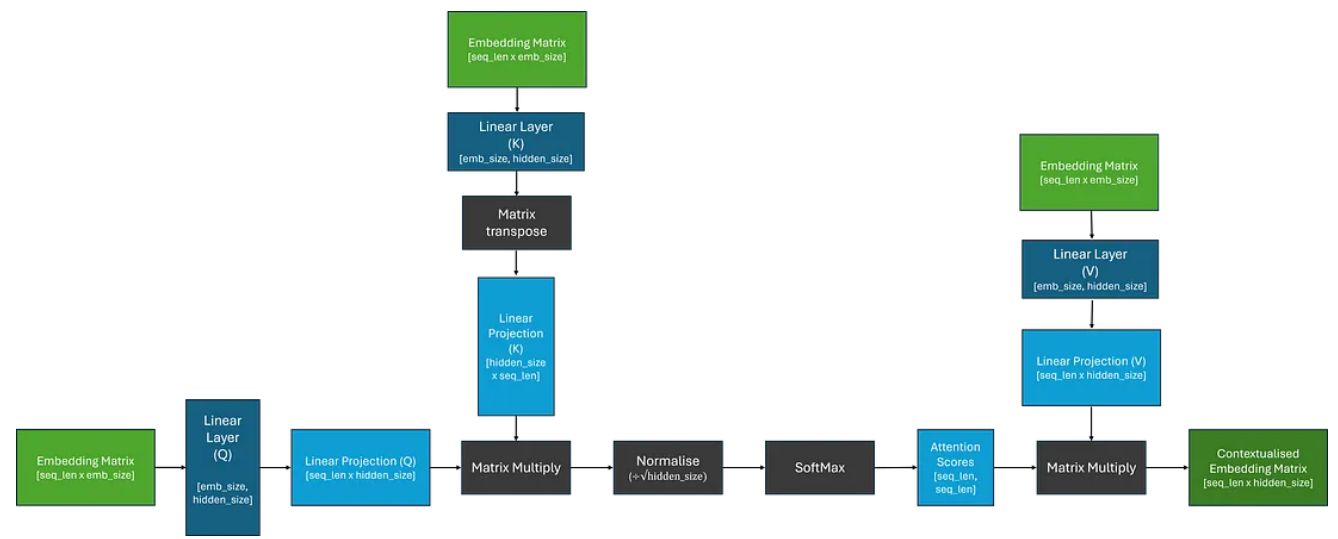
从图像中,我们可以看到线性投影被标记为 Q、K 和 V。在原始论文中,这些投影被命名为 Query、Key 和 Value,据说是受到信息检索的启发。就我个人而言,我从未发现这个类比有助于我的理解,所以我倾向于不关注这一点;我遵循此处的术语是为了与文献保持一致,并明确这些线性层是不同的。
现在我们了解了这个过程是如何工作的,我们可以将注意力计算视为具有三个输入的单个块,这将被传递到 Q、K 和 V。

当我们将相同的嵌入矩阵传递给 Q、K 和 V 时,这称为自注意力。
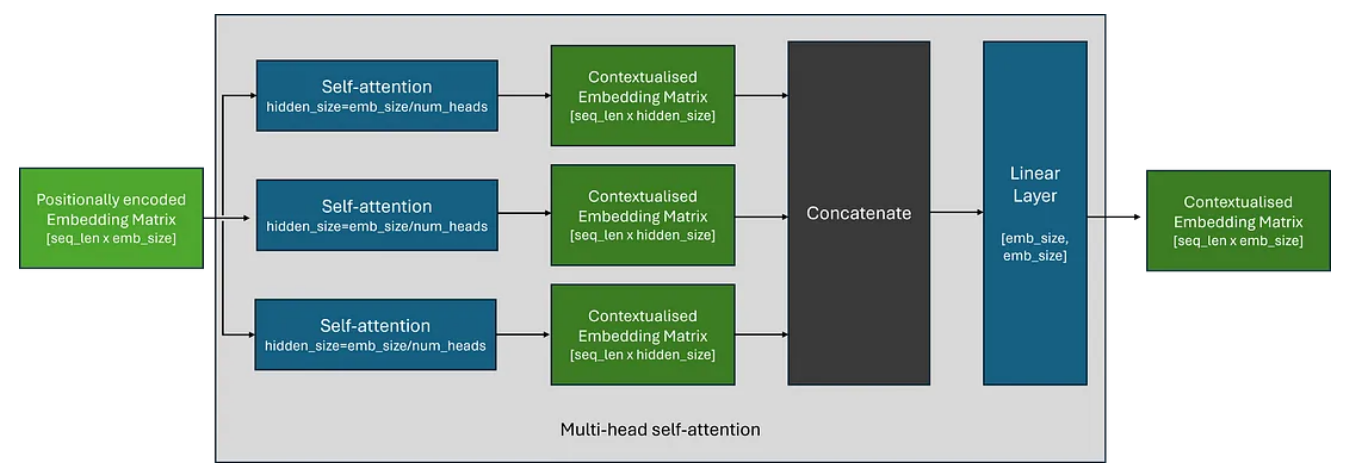
什么是多头注意力?
在实践中,我们经常并行使用多个自注意力模块,以使 Transformer 能够同时关注输入序列的不同部分——这称为多头注意力。
多头注意力背后的想法非常简单,多个独立自注意力块的输出连接在一起,然后通过线性层。该线性层使模型能够学习组合来自每个注意力头的上下文信息。
在实践中,每个自注意力块中使用的隐藏维度大小通常选择为原始嵌入大小除以注意力头的数量;保留嵌入矩阵的形状。
Transformer 还由什么组成?
尽管介绍 Transformer 的论文被命名为“Attention is all you need”,但这有点令人困惑,因为 Transformer 的组件不仅仅是 Attention!
Transformer 还包含以下内容:
-
前馈神经网络(FFN):一种两层神经网络,独立应用于批次和序列中的每个标记嵌入。 FFN 块的目的是将额外的可学习参数引入到转换器中,这些参数负责确保上下文嵌入是不同的且分散的。原始论文使用了 GeLU 激活函数,但 FFN 的组件可能会根据架构的不同而有所不同。 -
层归一化:有助于稳定深度神经网络(包括 Transformer)的训练。它标准化每个序列的激活,防止它们在训练过程中变得太大或太小;这可能会导致与梯度相关的问题,例如梯度消失或爆炸。这种稳定性对于有效训练非常深的 Transformer 模型至关重要。 -
跳过连接:与 ResNet 架构一样,残差连接用于缓解梯度消失问题并提高训练稳定性。
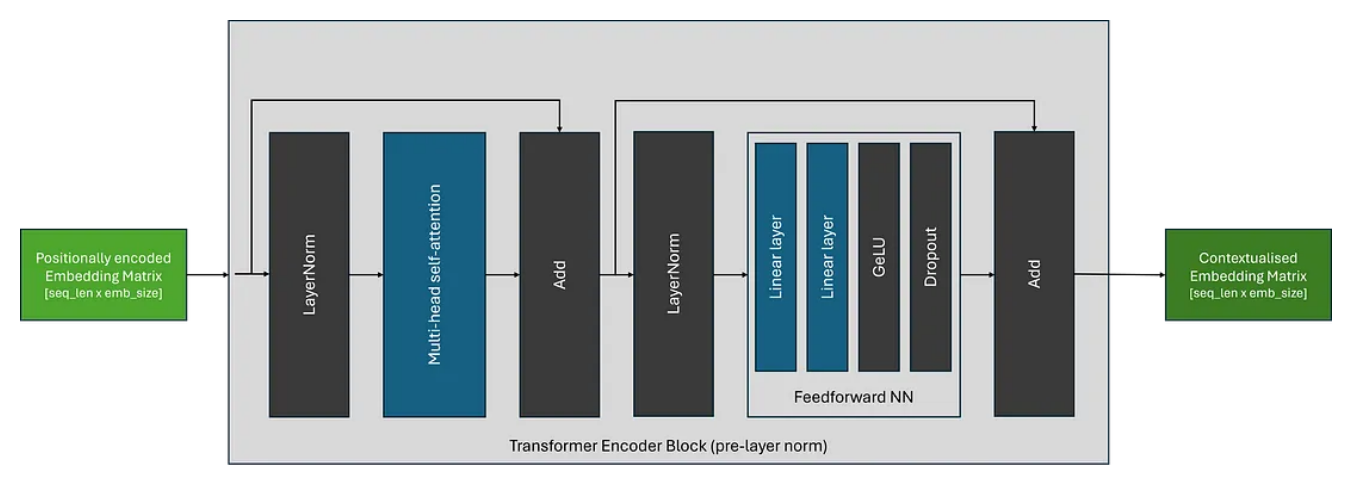
虽然 Transformer 架构自推出以来一直保持相当稳定,但层归一化块的位置可能会根据 Transformer 架构而变化。原始架构(现在称为后层规范)如下所示:

如下图所示,最近架构中最常见的放置是预层规范,它将规范化块放置在跳跃连接内的自注意力和 FFN 块之前。
Transformer 有哪些不同类型?
虽然现在有许多不同的Transformer 架构,但大多数可以分为三种主要类型。
编码器架构
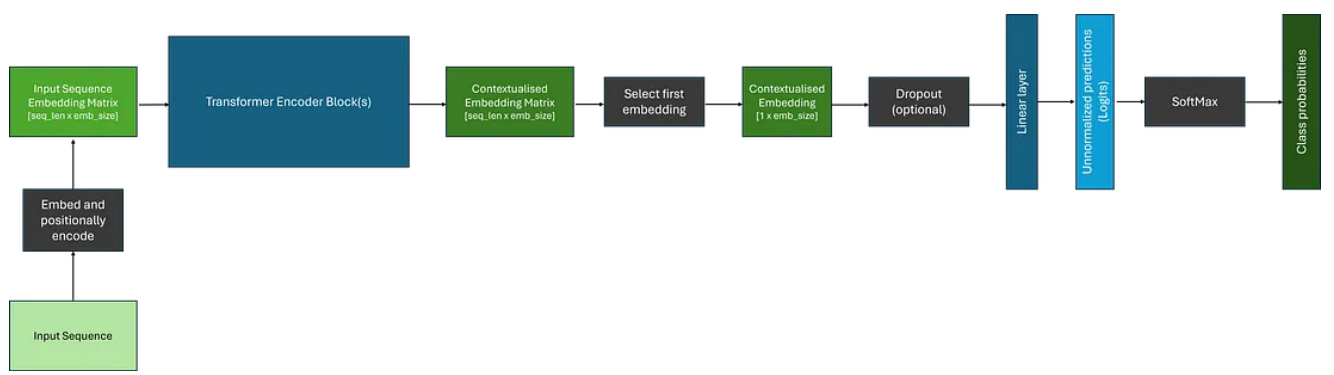
编码器模型旨在产生可用于下游任务(例如分类或命名实体识别)的上下文嵌入,因为注意力机制能够关注整个输入序列;这是本文到目前为止所探讨的架构类型。最流行的纯编码器Transformer系列是 BERT 及其变体。
将数据传递给一个或多个Transformer块后,我们得到了一个复杂的上下文嵌入矩阵,表示序列中每个标记的嵌入。然而,要将其用于分类等下游任务,我们只需要做出一个预测。传统上,第一个标记被取出并通过分类头;通常包含 Dropout 和 Linear 层。这些层的输出可以通过 SoftMax 函数传递,将其转换为类概率。下面描述了一个示例。
解码器架构
与编码器架构几乎相同,主要区别在于解码器架构采用屏蔽(或因果)自注意力层,因此注意力机制只能关注输入序列的当前和先前元素;这意味着生成的上下文嵌入仅考虑之前的上下文。流行的仅解码器型号包括 GPT 系列。
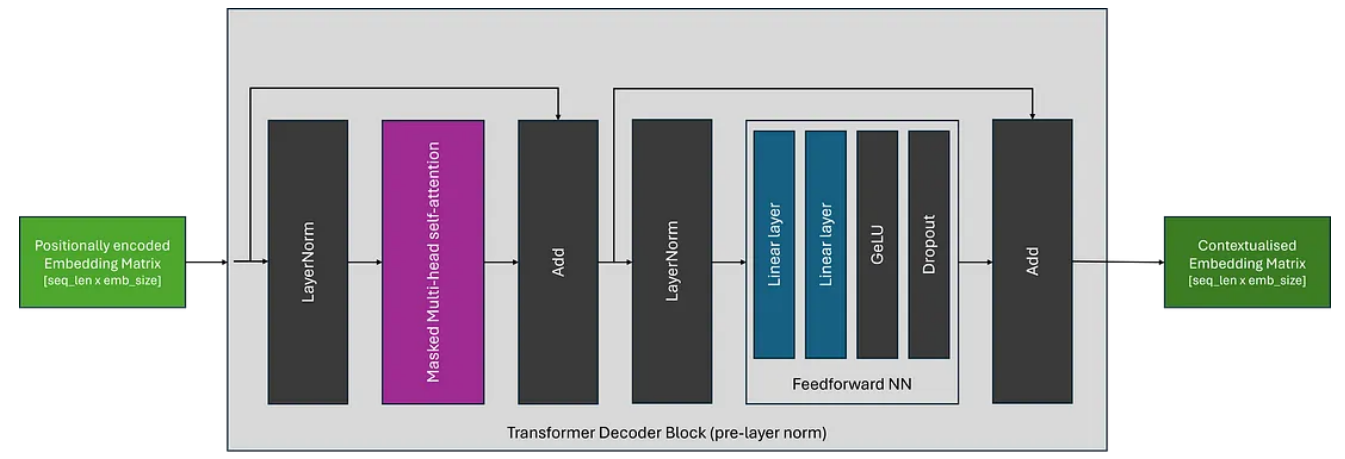
这通常是通过用二元下三角矩阵屏蔽注意力分数并用负无穷大替换非屏蔽元素来实现的;当通过下面的 SoftMax 操作时,这将确保这些位置的注意力分数等于 0。我们可以更新之前的自注意力图,将其包括在内,如下所示。
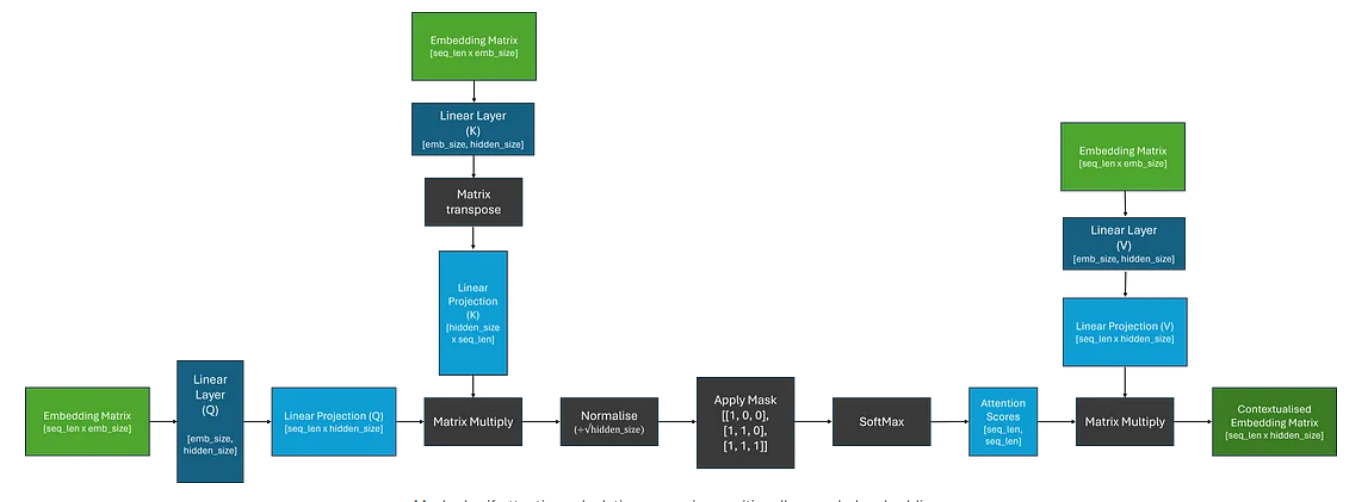
由于它们只能从当前位置和向后进行,因此解码器架构通常用于自回归任务,例如序列生成。然而,当使用上下文嵌入来生成序列时,与使用编码器相比,还有一些额外的考虑因素。下面显示了一个示例。
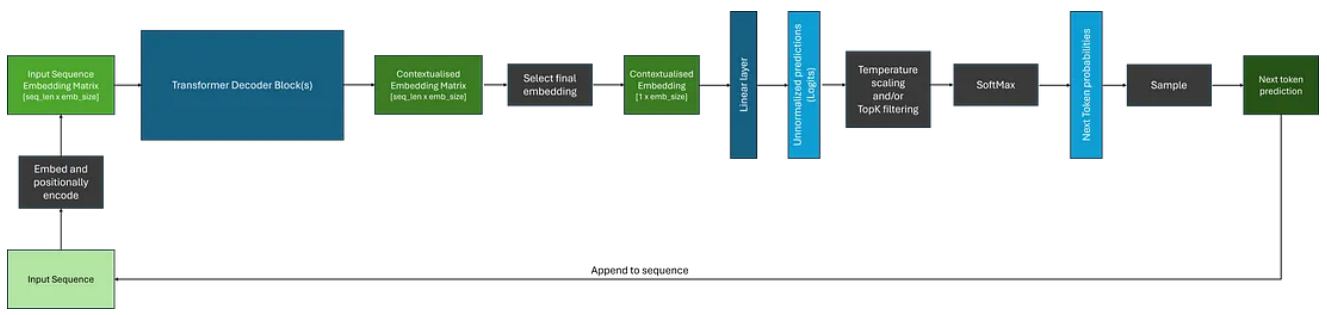
我们可以注意到,虽然解码器为输入序列中的每个标记生成上下文嵌入,但在生成序列时,我们通常使用与最终标记相对应的嵌入作为后续层的输入。
此外,将 SoftMax 函数应用于 logits 后,如果不应用过滤,我们将收到模型词汇表中每个标记的概率分布;这可能非常大!通常,我们希望使用各种过滤策略来减少潜在选项的数量,一些最常见的方法是:
-
Temperature调整:Temperature是一个应用于 SoftMax 操作内部的参数,它会影响生成文本的随机性。它通过改变输出词的概率分布来确定模型输出的创造性或集中度。较高的Temperature使分布变得平坦,使输出更加多样化。 -
Top-P 采样:此方法根据给定的概率阈值过滤下一个标记的潜在候选者数量,并根据高于此阈值的候选者重新分配概率分布。 -
Top-K 采样:此方法根据 Logit 或概率得分(取决于实现)将潜在候选者的数量限制为 K 个最有可能的标记
一旦我们改变或减少了下一个标记的潜在候选者的概率分布,我们就可以从中采样以获得我们的预测——这只是从多项分布中采样。然后将预测的标记附加到输入序列并反馈到模型中,直到生成所需数量的标记,或者模型生成停止标记;表示序列结束的特殊标记。
编码器-解码器架构
最初,Transformer 是作为机器翻译的架构提出的,并使用编码器和解码器来实现这一目标;在使用解码器转换为所需的输出格式之前,使用编码器创建中间表示。虽然编码器-解码器转换器已经变得不太常见,但 T5 等架构演示了如何将问答、摘要和分类等任务构建为序列到序列问题并使用这种方法来解决。
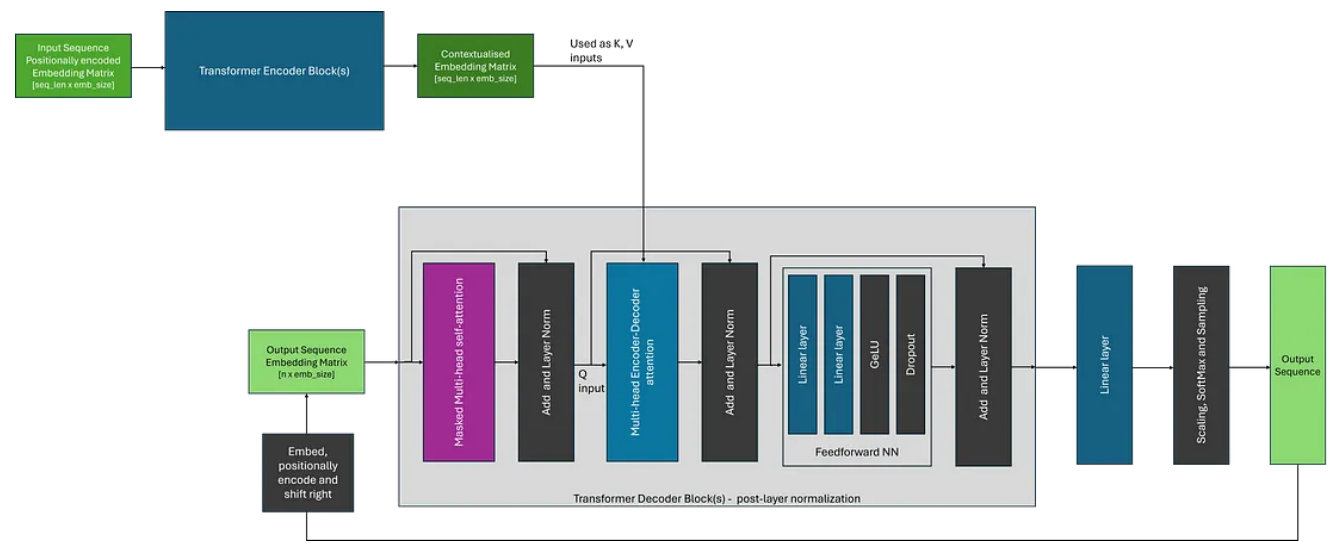
编码器-解码器架构的主要区别在于解码器使用编码器-解码器注意力,它在注意力计算期间同时使用编码器的输出(作为 K 和 V)和解码器块的输入(作为 Q)。这与自注意力形成对比,自注意力对于所有输入使用相同的输入嵌入矩阵。除此之外,整体生成过程与使用仅解码器架构非常相似。
我们可以将编码器-解码器架构可视化,如下图所示。在这里,为了简化图形,我选择描绘原始论文中所示的变压器的后层范数变体;其中层规范层位于注意块之后。
希望上面的描述对您理解 Transformer 有所帮助。
Reference
Source: https://towardsdatascience.com/de-coded-transformers-explained-in-plain-english-877814ba6429
本文由 mdnice 多平台发布



![【题解】[NOIP2015]扫雷游戏(Java C++)](https://img-blog.csdnimg.cn/0c95169617ff40349b44ab0ac1ac0381.png)