podomatic播客上的音频,怎么批量下载呢?
以这个播客为例:https://nosycrow.podomatic.com/rss2.xml
右边有一个RSS Feed的黄色图标,点击打开:
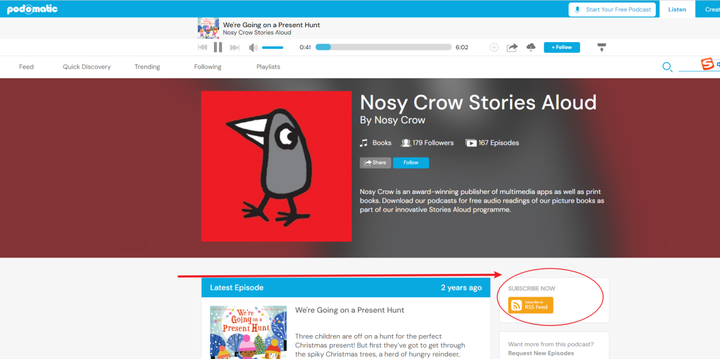
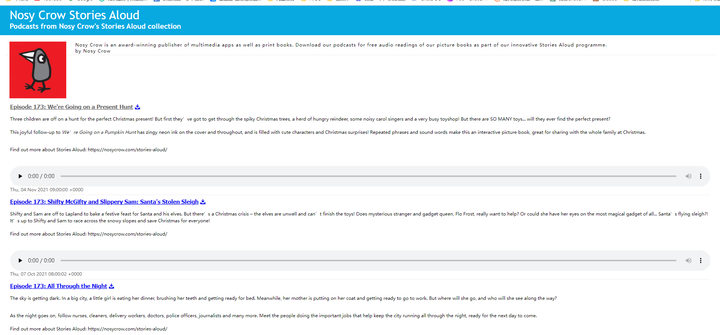
可以看到所有的音频和标题:
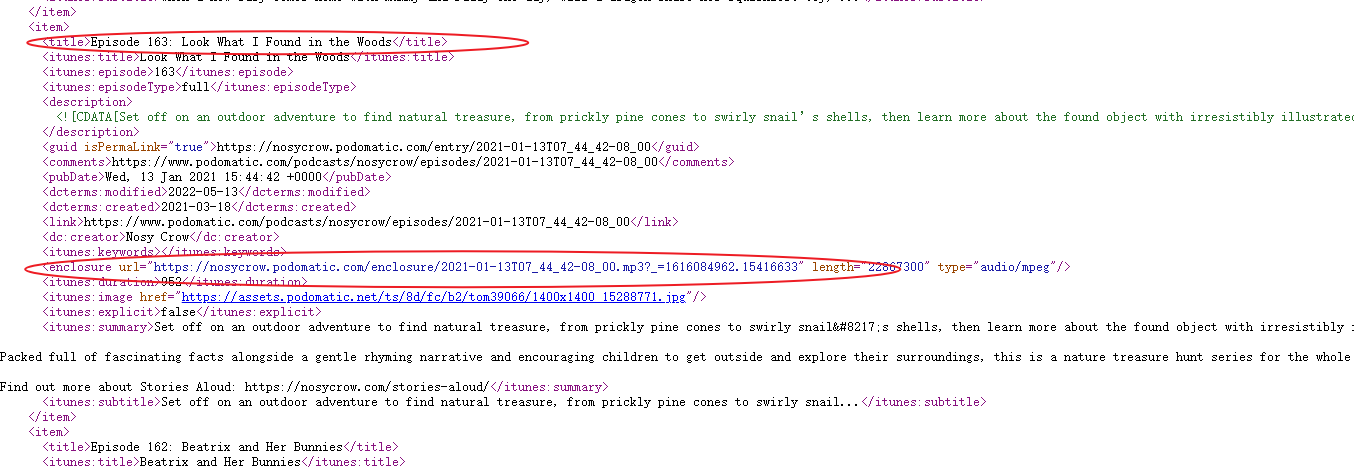
查看源代码,音频标题在title标签里,mp3音频文件在enclosure标签里:
在ChatGPT中输入提示词:
你是一个Python编程专家,要完成一个批量下载网页中音频文件的任务,具体步骤如下:
在本地电脑E盘,创建nosycrow文件夹;
打开网页https://nosycrow.podomatic.com/rss2.xml,解析源代码;
定位所有<item>标签;
定位<item>中的<title>,提取其内容,删除其中的“: ”,作为音频文件标题名;
定位<item>中的<enclosure>,提取其中url值,删除url值中的“?”和“?”以后的字符,作为音频文件URL;
下载这个音频文件,保存到E盘的nosycrow文件夹;
注意:每一步都要输出相关信息
ChatGPT给出的Python源代码:
import os
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor
# RSS源的URL
rss_url = "https://nosycrow.podomatic.com/rss2.xml"
# 输出信息:开始下载RSS源
print(f"Downloading RSS feed from {rss_url}...")
# 下载RSS源
response = requests.get(rss_url)
rss = response.text
# 输出信息:开始解析RSS源
print(f"Parsing RSS feed...")
# 解析RSS源
soup = BeautifulSoup(rss, "xml")
items = soup.find_all('item')
# 定义一个函数来下载音频
def download_audio(item):
# 提取音频标题和URL,并进行处理
audio_title = item.title.text.replace(": ", "")
audio_url = item.enclosure['url'].split("?")[0]
# 输出信息:开始下载音频
print(f"Downloading audio '{audio_title}' from {audio_url}...")
# 下载音频
audio_response = requests.get(audio_url)
# 保存音频到本地文件
audio_file_path = os.path.join("E:\\nosycrow", f"{audio_title}.mp3")
with open(audio_file_path, 'wb') as f:
f.write(audio_response.content)
# 输出信息:音频下载完成
print(f"Audio '{audio_title}' downloaded successfully.")
# 创建一个线程池
with ThreadPoolExecutor() as executor:
# 启动多线程下载
executor.map(download_audio, items)
# 输出信息:所有音频下载完成
print("All audios downloaded successfully.")
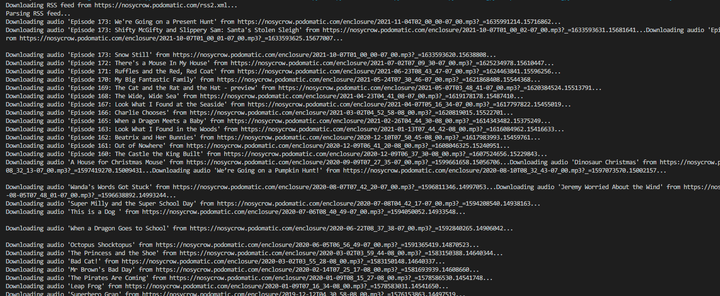
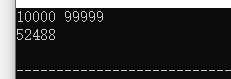
程序运行,很快上百个音频就下载完成了: