什么是Docker?
假设现在有一个服务场景,你是一个程序猿,你编写代码实现一个机器人喝水的功能,然后你需要将这份代码部署到每个机器人身上,你部署的时候需要一个个安装代码所需的依赖包,然后运行测试你的代码是否能够在这台机器上跑起来,当然不同的机器人可能环境不一样,可能安装的依赖包也不一样(包括版本差异、网络不好甚至可能出现功能缺失的情况),你为了保证功能正常,采用了统一的版本,这样部署的时间长、效率也很低。
随着业务的扩展,你开发了运动功能、跳舞功能等。你将这些功能部署到机器人上时,又需要单独部署三个不同的服务,部署的时间成本更高了,或者是你将几个小的服务合成一个大的服务,如此一来,导致服务之间发生冲突的可能性更大了,使得机器人整体的性能和稳定性下降。这个时候你可能咬咬牙还能承受,但是随着业务做大,你又不得不引入数据库、中间件、更多的子模块.......
这时候你就需要借助Docker了!Docker是什么?正如logo所示,集装箱。在Docker中把集装箱叫做容器,用户把服务的代码放到容器里面运行,因为集装箱有着坚实的箱壁,所以每个容器之间被隔离开,容器之间再也不会相互干扰了。当然,Docker也提供了相应的措施供容器之间做一些必要的通信(数据交互、服务请求等)

了解k8s首先从整体架构入手,k8s是一个比较典型的分布式系统例子,主要包含控制节点和用户的工作节点。其中控制节点可以理解为k8s的内置节点,是整个k8s的核心,负责整个系统的管理和控制。在控制节点中k8s集成了一些核心的组件,
用户通过命令行工具kubectl或者Web UI接入k8s集群,发送指令控制工作节点的创建、删除、更新等。实际上命令行工具并不是直接操作工作节点的,而是通过与api server通信,通过api server去操作工作节点。

控制节点中提供了ApiServer、Scheduler、ControllerManager、ETCD以及其他很多辅助组件
- ETCD:k8s的状态存储数据库(高可用键值存储),包括集群的配置、Pod和容器的状态、服务和端点的状态、控制器的状态都存在ETCD的一个实例中,确保了集群的状态在节点故障或重新启动后仍然可用。
- ApiServer:资源操作的唯一入口,用于接受用户的指令。主要的功能有:提供对外接口、省份认证及授权、资源验证及默认值设置、ETCD访问入口、控制的触发与调度、服务发现和负载等功能。其他组件或工作节点必须通过ApiServer访问ETCD
- Scheduler:资源调度(通过ApiServer通过Watch接口监听Pod信息,将新创建的Pod分配到合适的工作节点上)。主要功能:节点选择、资源分配、亲和性和反亲和性等
- ControllerManager:包含多个控制器,每个控制器负责监控和维护集群中的一类资源的状态,以确保集群的期望状态和实际状态保持一致。
工作节点是用户建立的,每个node也都会被控制节点Master分配一些工作负载,当这个node宕机时,其上的工作负载会被Master自动转到其他工作节点node上。
解释:工作负载指的是k8s集群中运行的容器化程序或服务,node1宕机时节点内运行的Pod会被Master自动转移到可用节点node2上。这里转移的其实是Pod!
工作节点中有以下组件:
- Kubelet:负责维护容器的生命周期,Kubelet可以通过Docker控制Pod的创建、启动、监控、重启、销毁等工作,处理Master节点下发到本节点的任务。
- KubeProxy:负责制定数据转发策略,并以守护进程的模式对各个节点Pod信息实时监控并更新转发规则。说白了就是给各个Pod直接通过通信。
- Docker:提供容器及容器的各种操作。
一些需要知道的东西
1. Pod
k8s集群都是以Pod在运行,master节点中的组件也是以Pod的形式运行


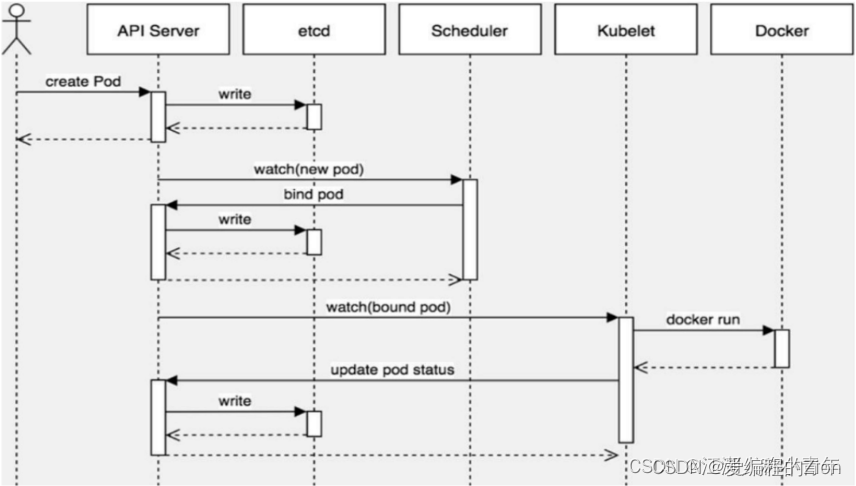
Pod创建流程
- 客户端通过请求ApiServer通过的Restful API(支持的数据类型有JSON和YAML)或者使用命令行工具kubectl
- 客户端发起请求后,会被ApiServer处理,并将Pod的配置信息等存储到ETCD中
- 资源调度:这个过程包括过滤主机-主机打分-主机选择。首先会根据一些Pod指定所需资源量或者标签需求过滤掉一些资源不够的主机(调度预算),然后根据优化策略给主机打分,最后选择评分最高的主机进行binding绑定。(这里的主机指的是工作节点,最后会在真实的主机部署该工作节点)
- 执行Pod创建:确定好主机后,Scheduler会调用ApiServer的API创建一个boundpod对象,描述在一个工作上绑定运行的所有Pod的信息。(运行在每个工作节点中的kubelet会定期与ETCD同步自己的boundpod信息)一旦发现该工作节点上运行的boundpod对象没有更新,则调用Docker 的API创建、(下载、)启动Pod内的容器
Pod的状态
在整个生命周期中,Pod会出现5种状态:
- 挂起(Pending): ApiServer已经创建了Pod资源对象,但它尚未被调度完成或者仍处于下载镜像的过程中
- 运行中(Running): Pod已经被调度至某节点,并且所有容器都已经被kubelet创建完成
- 成功(Succeeded): Pod中的所有容器都已经成功终止并且不会被重启
- 失败(Failed): 所有容器都已经终止,但至少有一个容器终止失败,即容器返回了非0值的退出状态
- 未知(Unknown): ApiServer无法正常获取到Pod对象的状态信息,通常由网络通信失败所导致
创建并运行Pod:kubectl run podname --image=nginx:1.17.1 --port=80 [--namespace dev] 老版本的k8s中run是创建一个Pod控制器,通过控制器运行Pod,现在是直接创建Pod
查询Pod:kubectl get pods -n [namespace] [-o wide] #指定命名空间,加上-o wide参数后可以看到该Pod所在的节点,ip地址等,当然通过describe更详细
访问Pod,通过查询Pod的ip和暴露的端口可以访问到Pod
Pod删除:kubectl delete pod [pod name]
但是往往这样删除是不正确的,因为master节点的控制器会监听Pod的状态,一旦发现Pod死亡,会立即重建,这种情况下需要删除Pod控制器之后才能删除Pod,当然,如果是更高的版本就不会重新创建
首先查询namespace下的控制器:kubectl get deploy -n dev
删除该Pod控制器:kubectl delete deploy [deploy-name] -n dev
删除控制器后Pod也自动被删除了
2. NameSpace:
命名空间,是k8s中的一种资源类型,用来隔离Pod运行的环境,k8s集群启动后会默认创建几个namespace。

一些namespace的解读

master节点会分配到kube-systm中。
创建namespace:kubectl create ns [ns name]
查询namespace:kubectl get ns
删除namespace:kubectl delete ns [ns name] #会先进入一个“删除中”的状态
通过配置文件创建:kubectl create -f xxx.yaml
通过配置文件删除:kubectl delete -f xxx.yaml
3. Label
- 以key value的形式附加在各种对象上 :Node、Pod、Service
- 一个资源对象可以定义多个标签
- 标签通常在资源对象定义时确定(yaml文件),也可以在对象创建后创建或删除(命令行)

打标签:kubectl label pod podname -n dev key=value
可以通过:kubectl get pod -n pod --show-labels 查看标签信息
标签更新:kubectl label pod podname -n dev key=value --overwrite
标签选择器:基于等式的、基于集合的
基于等式的:kubectl get pods -l "key=value" -n dev --show-labels
基于集合的:kubectl get pods -l 'key in (value1,value2)'
标签删除:lunectl label pod podname -n dev label_name- 减号
ps:可以通过逗号分隔key=value来一次创建、筛选标签
4. Deployment
Pod控制器:k8s中很少直接控制Pod,一般通过Pod控制器来操作。(k8s中有很多中pod控制)
创建控制器:kubectl create deployment deploy-pod --image=xxx --port=80 --replicas=3
replicase表示副本数量(新版本已弃用),deployment和pod之间的管理关系通过标签来实现
配置文件创建:

查看deploymenyt:kubectl get deploy -n dev -o wide
删除deployment:kubectl delete deploy deployname -n namespace_name
5. Service
问:如果一个Pod宕机了,k8s会自动生成一个新的Pod,那么原来的Pod的ip地址还能访问吗?
答:ip地址会改变。
ps:这里的ip是k8s集群内部的虚拟ip,外部无法访问
Service 提供了同一类(标签一样)Pod的对外访问接口,借助Pod,应用也可以实现服务发现和负载均衡(也就是端口暴露)
创建一个Service(通过Service来进行端口映射)
对内端口暴露:kubectl expose deploy container --name=SreviceName --type=ClusterIP --port=80 --target-port=80 -n namespace
对外端口暴露:kubectl expose deploy container --name=SreviceName --type=Nodeport --port=80 --target-port=80 -n namespace
但是最后对外访问时用的还不是80端口

常用的命令:
| ##查看Pod、node、Service、endpoint等信息 kubectl get [组件名] eg:kubectl get pods #查看有哪些Pod eg:kubectl get pods -n [namespace] [-o wide] #指定命名空间,加上-o wide参数后可以看到该Pod所在的节点,ip地址等,当然通过describe更详细 ##查看资源状态,一般用于Pod调度过程中的问题排查 kubectl describe pod [Pod name] kubectl describe ns default #查看ns详情 #查看节点或者Pod资源(cpu、内存)使用情况 kubectl top [组件名] #进入Pod内部 kubectl exec -it [Pod name] /bin/bash #删除Pod kubectl delete pod [Pod name] #查看容器日志 kubectl logs -f [Pod name] #根据yaml文件创建资源 kubectl apply -f xxx.yaml |