本文代码链接:https://download.csdn.net/download/shangjg03/88422633
1.消费者和消费者群组
在 Kafka 中,消费者通常是消费者群组的一部分,多个消费者群组共同读取同一个主题时,彼此之间互不影响。Kafka 之所以要引入消费者群组这个概念是因为 Kafka 消费者经常会做一些高延迟的操作,比如把数据写到数据库或 HDFS ,或者进行耗时的计算,在这些情况下,单个消费者无法跟上数据生成的速度。此时可以增加更多的消费者,让它们分担负载,分别处理部分分区的消息,这就是 Kafka 实现横向伸缩的主要手段。

需要注意的是:同一个分区只能被同一个消费者群组里面的一个消费者读取,不可能存在同一个分区被同一个消费者群里多个消费者共同读取的情况,如图:
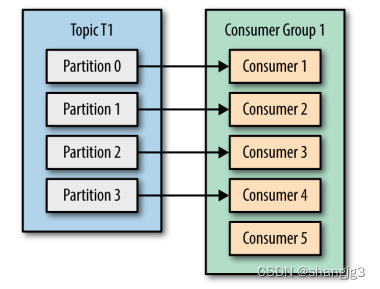
可以看到即便消费者 Consumer5 空闲了,但是也不会去读取任何一个分区的数据,这同时也提醒我们在使用时应该合理设置消费者的数量,以免造成闲置和额外开销。
2.分区再均衡
因为群组里的消费者共同读取主题的分区,所以当一个消费者被关闭或发生崩溃时,它就离开了群组,原本由它读取的分区将由群组里的其他消费者来读取。同时在主题发生变化时 , 比如添加了新的分区,也会发生分区与消费者的重新分配,分区的所有权从一个消费者转移到另一个消费者,这样的行为被称为再均衡。正是因为再均衡,所以消费费者群组才能保证高可用性和伸缩性。
消费者通过向群组协调器所在的 broker 发送心跳来维持它们和群组的从属关系以及它们对分区的所有权。只要消费者以正常的时间间隔发送心跳,就被认为是活跃的,说明它还在读取分区里的消息。消费者会在轮询消息或提交偏移量时发送心跳。如果消费者停止发送心跳的时间足够长,会话就会过期,群组协调器认为它已经死亡,就会触发再均衡。
3.创建Kafka消费者
在创建消费者的时候以下以下三个选项是必选的:
bootstrap.servers :指定 broker 的地址清单,清单里不需要包含所有的 broker 地址,生产者会从给定的 broker 里查找 broker 的信息。不过建议至少要提供两个 broker 的信息作为容错;
key.deserializer :指定键的反序列化器;
value.deserializer :指定值的反序列化器。
除此之外你还需要指明你需要想订阅的主题,可以使用如下两个 API :
consumer.subscribe(Collection\<String> topics) :指明需要订阅的主题的集合;
consumer.subscribe(Pattern pattern) :使用正则来匹配需要订阅的集合。
最后只需要通过轮询 API(`poll`) 向服务器定时请求数据。一旦消费者订阅了主题,轮询就会处理所有的细节,包括群组协调、分区再均衡、发送心跳和获取数据,这使得开发者只需要关注从分区返回的数据,然后进行业务处理。 示例如下:
String topic = "Hello-Kafka";
String group = "group1";
Properties props = new Properties();
props.put("bootstrap.servers", "hadoop001:9092");
/*指定分组 ID*/
props.put("group.id", group);
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
/*订阅主题 (s)*/
consumer.subscribe(Collections.singletonList(topic));
try {
while (true) {
/*轮询获取数据*/
ConsumerRecords<String, String> records = consumer.poll(Duration.of(100, ChronoUnit.MILLIS));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("topic = %s,partition = %d, key = %s, value = %s, offset = %d,\n",
record.topic(), record.partition(), record.key(), record.value(), record.offset());
}
}
} finally {
consumer.close();
}
4. 自动提交偏移量
4.1 偏移量的重要性
Kafka 的每一条消息都有一个偏移量属性,记录了其在分区中的位置,偏移量是一个单调递增的整数。消费者通过往一个叫作 `_consumer_offset` 的特殊主题发送消息,消息里包含每个分区的偏移量。 如果消费者一直处于运行状态,那么偏移量就没有
什么用处。不过,如果有消费者退出或者新分区加入,此时就会触发再均衡。完成再均衡之后,每个消费者可能分配到新的分区,而不是之前处理的那个。为了能够继续之前的工作,消费者需要读取每个分区最后一次提交的偏移量,然后从偏移量指定的地方继续处理。 因为这个原因,所以如果不能正确提交偏移量,就可能会导致数据丢失或者重复出现消费,比如下面情况:
如果提交的偏移量小于客户端处理的最后一个消息的偏移量 ,那么处于两个偏移量之间的消息就会被重复消费;
如果提交的偏移量大于客户端处理的最后一个消息的偏移量,那么处于两个偏移量之间的消息将会丢失。
4.2 自动提交偏移量
Kafka 支持自动提交和手动提交偏移量两种方式。这里先介绍比较简单的自动提交:
只需要将消费者的 `enable.auto.commit` 属性配置为 `true` 即可完成自动提交的配置。 此时每隔固定的时间,消费者就会把 `poll()` 方法接收到的最大偏移量进行提交,提交间隔由 `auto.commit.interval.ms` 属性进行配置,默认值是 5s。
使用自动提交是存在隐患的,假设我们使用默认的 5s 提交时间间隔,在最近一次提交之后的 3s 发生了再均衡,再均衡之后,消费者从最后一次提交的偏移量位置开始读取消息。这个时候偏移量已经落后了 3s ,所以在这 3s 内到达的消息会被重复处理。可以通过修改提交时间间隔来更频繁地提交偏移量,减小可能出现重复消息的时间窗,不过这种情况是无法完全避免的。基于这个原因,Kafka 也提供了手动提交偏移量的 API,使得用户可以更为灵活的提交偏移量。
5.手动提交偏移量
用户可以通过将 `enable.auto.commit` 设为 `false`,然后手动提交偏移量。基于用户需求手动提交偏移量可以分为两大类:
手动提交当前偏移量:即手动提交当前轮询的最大偏移量;
手动提交固定偏移量:即按照业务需求,提交某一个固定的偏移量。
而按照 Kafka API,手动提交偏移量又可以分为同步提交和异步提交。
5.1 同步提交
通过调用 `consumer.commitSync()` 来进行同步提交,不传递任何参数时提交的是当前轮询的最大偏移量。
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.of(100, ChronoUnit.MILLIS));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record);
}
/*同步提交*/
consumer.commitSync();
}
如果某个提交失败,同步提交还会进行重试,这可以保证数据能够最大限度提交成功,但是同时也会降低程序的吞吐量。基于这个原因,Kafka 还提供了异步提交的 API。
5.2 异步提交
异步提交可以提高程序的吞吐量,因为此时你可以尽管请求数据,而不用等待 Broker 的响应。代码如下:
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.of(100, ChronoUnit.MILLIS));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record);
}
/*异步提交并定义回调*/
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {
if (exception != null) {
System.out.println("错误处理");
offsets.forEach((x, y) -> System.out.printf("topic = %s,partition = %d, offset = %s \n",
x.topic(), x.partition(), y.offset()));
}
}
});
}
异步提交存在的问题是,在提交失败的时候不会进行自动重试,实际上也不能进行自动重试。假设程序同时提交了 200 和 300 的偏移量,此时 200 的偏移量失败的,但是紧随其后的 300 的偏移量成功了,此时如果重试就会存在 200 覆盖 300 偏移量的可能。同步提交就不存在这个问题,因为在同步提交的情况下,300 的提交请求必须等待服务器返回 200 提交请求的成功反馈后才会发出。基于这个原因,某些情况下,需要同时组合同步和异步两种提交方式。
注:虽然程序不能在失败时候进行自动重试,但是我们是可以手动进行重试的,你可以通过一个 Map<TopicPartition, Integer> offsets 来维护你提交的每个分区的偏移量,然后当失败时候,你可以判断失败的偏移量是否小于你维护的同主题同分区的最后提交的偏移量,如果小于则代表你已经提交了更大的偏移量请求,此时不需要重试,否则就可以进行手动重试。
5.3 同步加异步提交
下面这种情况,在正常的轮询中使用异步提交来保证吞吐量,但是因为在最后即将要关闭消费者了,所以此时需要用同步提交来保证最大限度的提交成功。
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.of(100, ChronoUnit.MILLIS));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record);
}
// 异步提交
consumer.commitAsync();
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
// 因为即将要关闭消费者,所以要用同步提交保证提交成功
consumer.commitSync();
} finally {
consumer.close();
}
}
5.4 提交特定偏移量
在上面同步和异步提交的 API 中,实际上我们都没有对 commit 方法传递参数,此时默认提交的是当前轮询的最大偏移量,如果你需要提交特定的偏移量,可以调用它们的重载方法。
/*同步提交特定偏移量*/
commitSync(Map<TopicPartition, OffsetAndMetadata> offsets)
/*异步提交特定偏移量*/
commitAsync(Map<TopicPartition, OffsetAndMetadata> offsets, OffsetCommitCallback callback)
需要注意的是,因为你可以订阅多个主题,所以 `offsets` 中必须要包含所有主题的每个分区的偏移量,示例代码如下:
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.of(100, ChronoUnit.MILLIS));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record);
/*记录每个主题的每个分区的偏移量*/
TopicPartition topicPartition = new TopicPartition(record.topic(), record.partition());
OffsetAndMetadata offsetAndMetadata = new OffsetAndMetadata(record.offset()+1, "no metaData");
/*TopicPartition 重写过 hashCode 和 equals 方法,所以能够保证同一主题和分区的实例不会被重复添加*/
offsets.put(topicPartition, offsetAndMetadata);
}
/*提交特定偏移量*/
consumer.commitAsync(offsets, null);
}
} finally {
consumer.close();
}
6.监听分区再均衡
因为分区再均衡会导致分区与消费者的重新划分,有时候你可能希望在再均衡前执行一些操作:比如提交已经处理但是尚未提交的偏移量,关闭数据库连接等。此时可以在订阅主题时候,调用 `subscribe` 的重载方法传入自定义的分区再均衡监听器。
/*订阅指定集合内的所有主题*/
subscribe(Collection<String> topics, ConsumerRebalanceListener listener)
/*使用正则匹配需要订阅的主题*/
subscribe(Pattern pattern, ConsumerRebalanceListener listener)
代码示例如下:
Map<TopicPartition, OffsetAndMetadata> offsets = new HashMap<>();
consumer.subscribe(Collections.singletonList(topic), new ConsumerRebalanceListener() {
/*该方法会在消费者停止读取消息之后,再均衡开始之前就调用*/
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
System.out.println("再均衡即将触发");
// 提交已经处理的偏移量
consumer.commitSync(offsets);
}
/*该方法会在重新分配分区之后,消费者开始读取消息之前被调用*/
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
}
});
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.of(100, ChronoUnit.MILLIS));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record);
TopicPartition topicPartition = new TopicPartition(record.topic(), record.partition());
OffsetAndMetadata offsetAndMetadata = new OffsetAndMetadata(record.offset() + 1, "no metaData");
/*TopicPartition 重写过 hashCode 和 equals 方法,所以能够保证同一主题和分区的实例不会被重复添加*/
offsets.put(topicPartition, offsetAndMetadata);
}
consumer.commitAsync(offsets, null);
}
} finally {
consumer.close();
}
7.退出轮询
Kafka 提供了 `consumer.wakeup()` 方法用于退出轮询,它通过抛出 `WakeupException` 异常来跳出循环。需要注意的是,在退出线程时最好显示的调用 `consumer.close()` , 此时消费者会提交任何还没有提交的东西,并向群组协调器发送消息,告知自己要离开群组,接下来就会触发再均衡 ,而不需要等待会话超时。
下面的示例代码为监听控制台输出,当输入 `exit` 时结束轮询,关闭消费者并退出程序:
/*调用 wakeup 优雅的退出*/
final Thread mainThread = Thread.currentThread();
new Thread(() -> {
Scanner sc = new Scanner(System.in);
while (sc.hasNext()) {
if ("exit".equals(sc.next())) {
consumer.wakeup();
try {
/*等待主线程完成提交偏移量、关闭消费者等操作*/
mainThread.join();
break;
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}).start();
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.of(100, ChronoUnit.MILLIS));
for (ConsumerRecord<String, String> rd : records) {
System.out.printf("topic = %s,partition = %d, key = %s, value = %s, offset = %d,\n",
rd.topic(), rd.partition(), rd.key(), rd.value(), rd.offset());
}
}
} catch (WakeupException e) {
//对于 wakeup() 调用引起的 WakeupException 异常可以不必处理
} finally {
consumer.close();
System.out.println("consumer 关闭");
}
8.独立的消费者
因为 Kafka 的设计目标是高吞吐和低延迟,所以在 Kafka 中,消费者通常都是从属于某个群组的,这是因为单个消费者的处理能力是有限的。但是某些时候你的需求可能很简单,比如可能只需要一个消费者从一个主题的所有分区或者某个特定的分区读取数据,这个时候就不需要消费者群组和再均衡了, 只需要把主题或者分区分配给消费者,然后开始读取消息井提交偏移量即可。
在这种情况下,就不需要订阅主题, 取而代之的是消费者为自己分配分区。 一个消费者可以订阅主题(井加入消费者群组),或者为自己分配分区,但不能同时做这两件事情。 分配分区的示例代码如下:
List<TopicPartition> partitions = new ArrayList<>();
List<PartitionInfo> partitionInfos = consumer.partitionsFor(topic);
/*可以指定读取哪些分区 如这里假设只读取主题的 0 分区*/
for (PartitionInfo partition : partitionInfos) {
if (partition.partition()==0){
partitions.add(new TopicPartition(partition.topic(), partition.partition()));
}
}
// 为消费者指定分区
consumer.assign(partitions);
while (true) {
ConsumerRecords<Integer, String> records = consumer.poll(Duration.of(100, ChronoUnit.MILLIS));
for (ConsumerRecord<Integer, String> record : records) {
System.out.printf("partition = %s, key = %d, value = %s\n",
record.partition(), record.key(), record.value());
}
consumer.commitSync();
}
9.Kafka消费者其他树形
1. fetch.min.byte
消费者从服务器获取记录的最小字节数。如果可用的数据量小于设置值,broker 会等待有足够的可用数据时才会把它返回给消费者。
2. fetch.max.wait.ms
broker 返回给消费者数据的等待时间,默认是 500ms。
3. max.partition.fetch.bytes
该属性指定了服务器从每个分区返回给消费者的最大字节数,默认为 1MB。
4. session.timeout.ms
消费者在被认为死亡之前可以与服务器断开连接的时间,默认是 3s。
5. auto.offset.reset
该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
- latest (默认值) :在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的最新记录);
- earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录。
6. enable.auto.commit
是否自动提交偏移量,默认值是 true。为了避免出现重复消费和数据丢失,可以把它设置为 false。
7. client.id
客户端 id,服务器用来识别消息的来源。
8. max.poll.records
单次调用 `poll()` 方法能够返回的记录数量。
9. receive.buffer.bytes & send.buffer.byte
这两个参数分别指定 TCP socket 接收和发送数据包缓冲区的大小,-1 代表使用操作系统的默认值。