(1)运行期优化-逃逸分析

 在运行期间java虚拟机会对我们代码做一些优化,时间会变短:
在运行期间java虚拟机会对我们代码做一些优化,时间会变短:


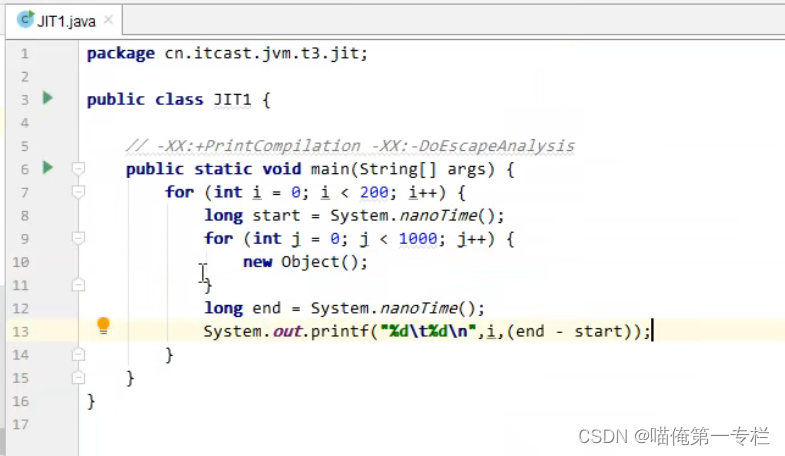
字节码反复调用,到达一定的阈值,会启用编译器对自己饿吗编译执行,从0层上升为1层C1
C1和C2他俩的区别是解释程度不一样 ,C2执行更特殊的优化



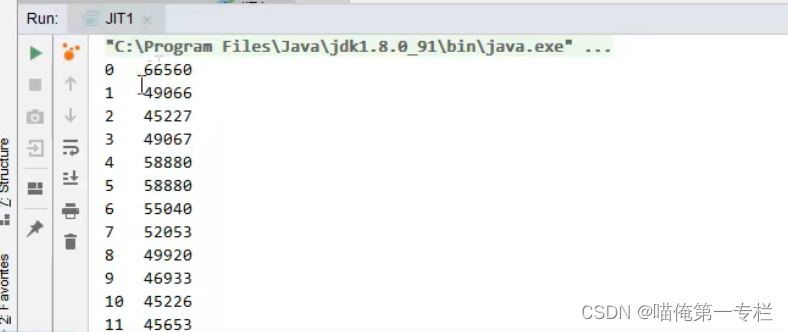
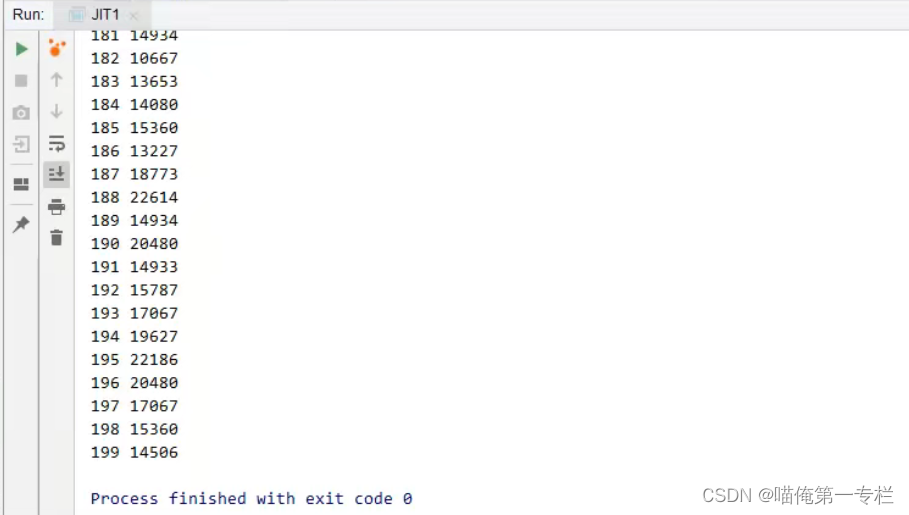
逃逸分析回去分析new Object对象会不会在循环外用到,被其他方法所引用,发现创建对象不会被逃逸,逃逸分析后在C2里做了优化后,会把对象的创建的字节码替换掉,干脆不会创建对象了,速度会提升很快

关闭逃逸分析后时间没有降到3位数,关闭逃逸分析,它就没有达到c2的编译器编译了
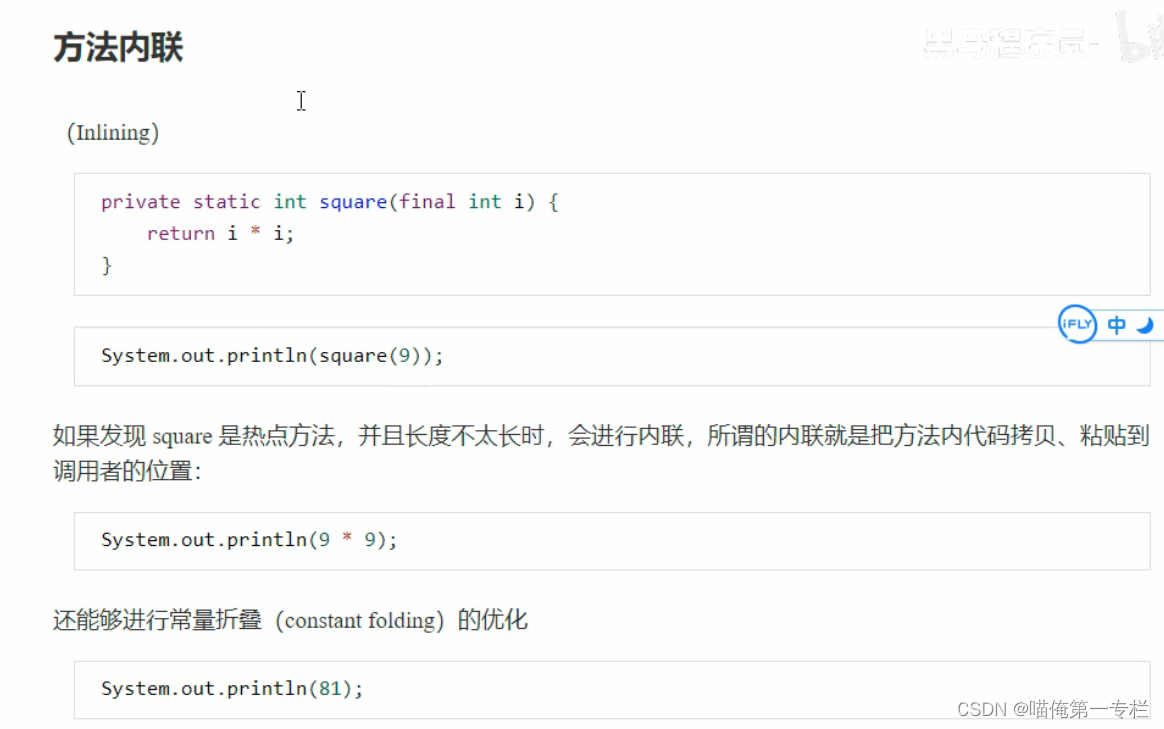
(2)运行期优化-方法内联
方法内联属于及时编译器的一种
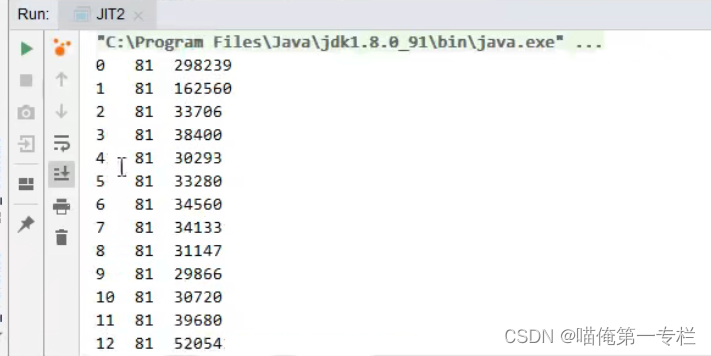
七十多次变成4位数,两百多次变为0秒了,因为他已经内联了,内联之后呢根本就没有方法调用了,第一次计算出来是81,第二次计算出来还是81,就会认为是常量,没有必要在计算了为0了

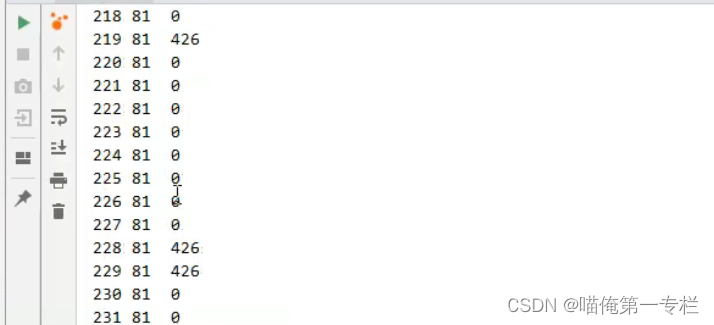
通过参数设置打印哪些方法进行了内联 :包含很多jdk方法的内联,和我们定义方法的内联

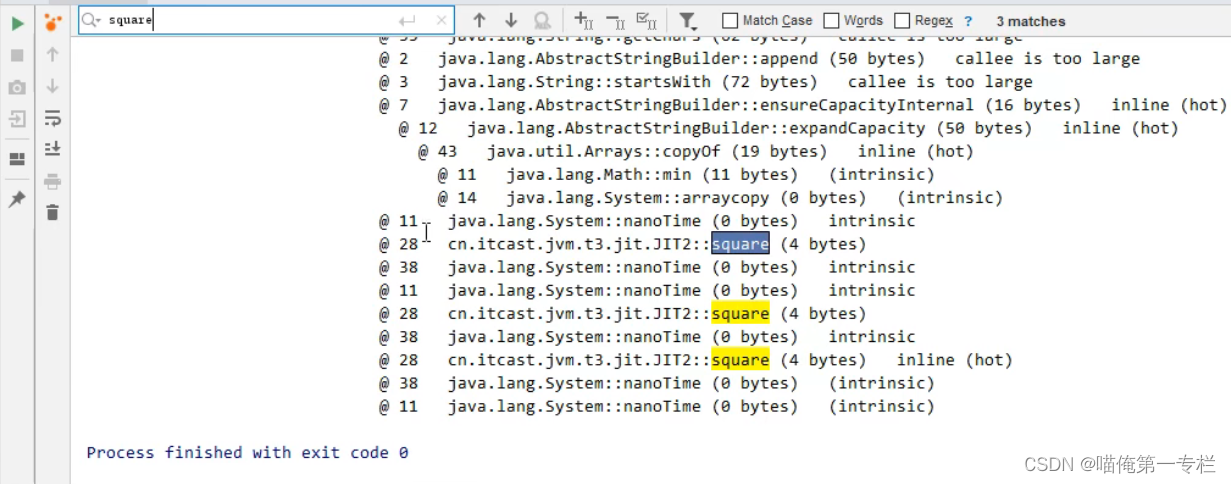
还可以禁用某个内联:
关闭之后不会下降到0了
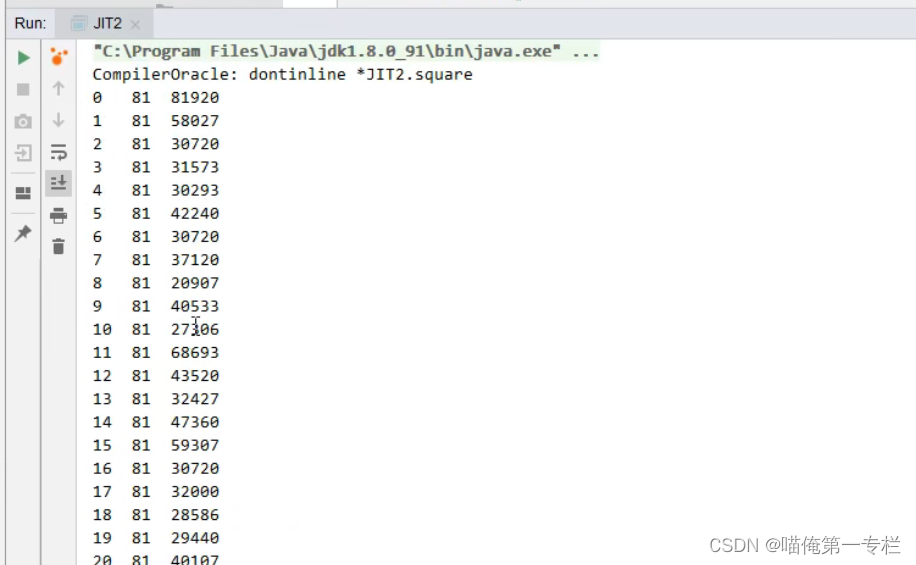
(3)运行期优化-字段优化
字段优化是针对成员变量,静态成员变量读写操作的优化
我们使用JMH

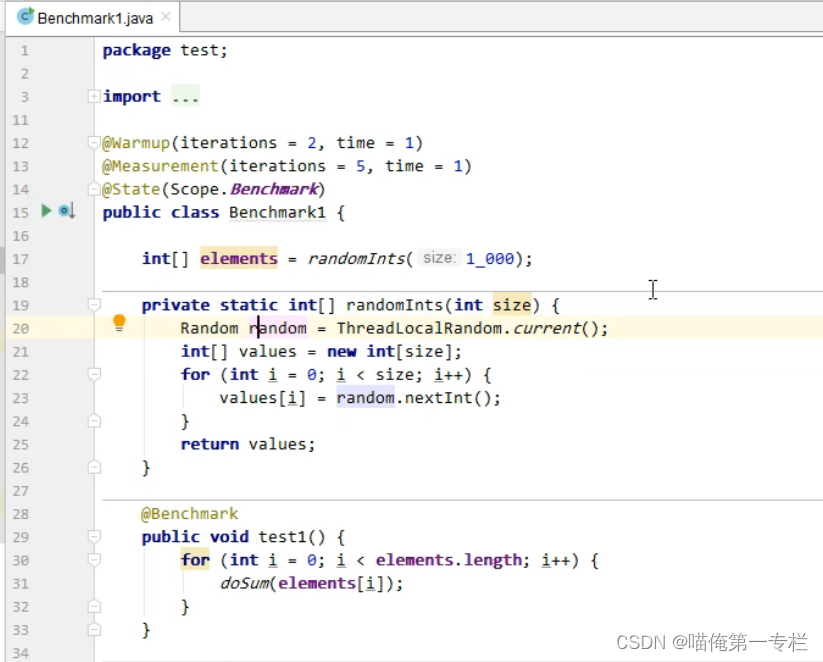
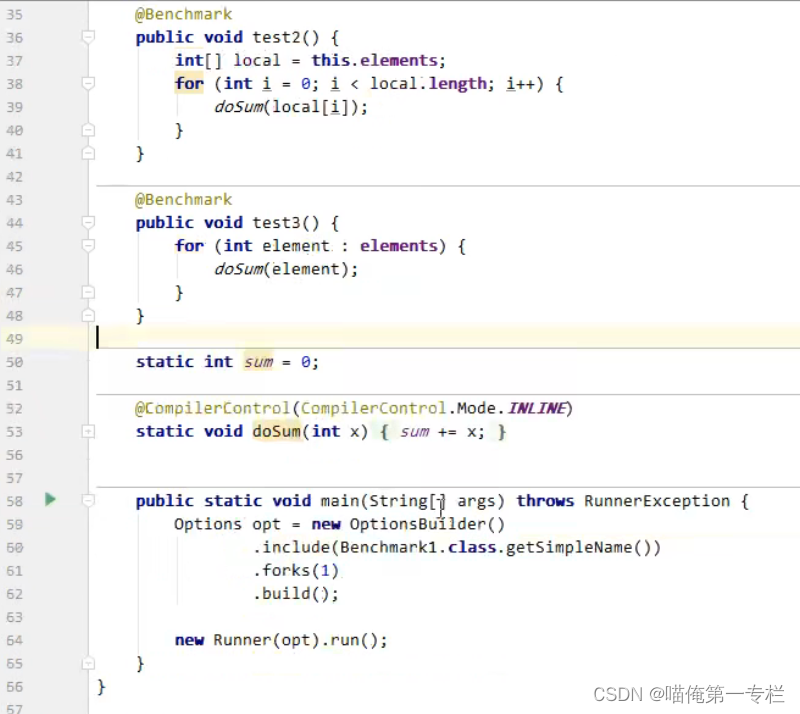
doSum方法上加注解,是否禁止方法内联

我们只要看Score吞吐量的得分,他们是差不多的
下面我们关闭方法内联修改注解:
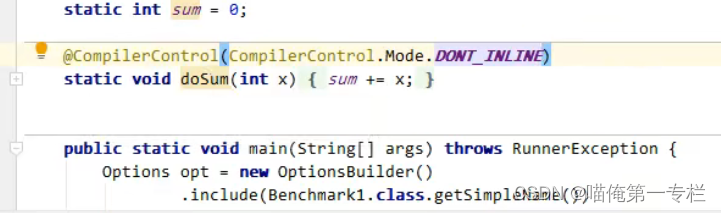
得分 下降了
test3根test2的字节码是等价的


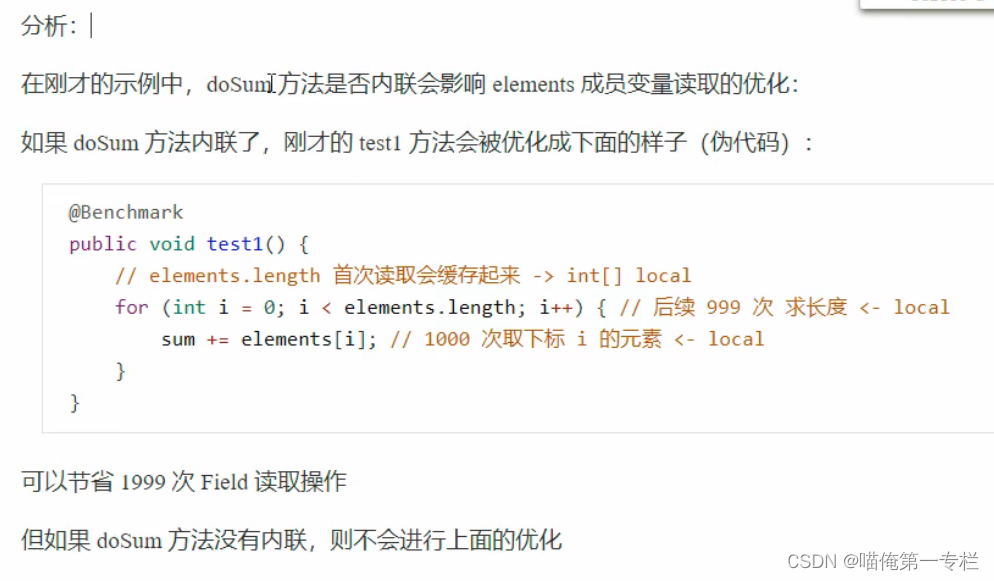
test2是手动做的优化,test1是由虚拟机帮祝我们优化,如果想要自己做优化的话尽可能使用局部变量,不要使用成员变量,静态变量
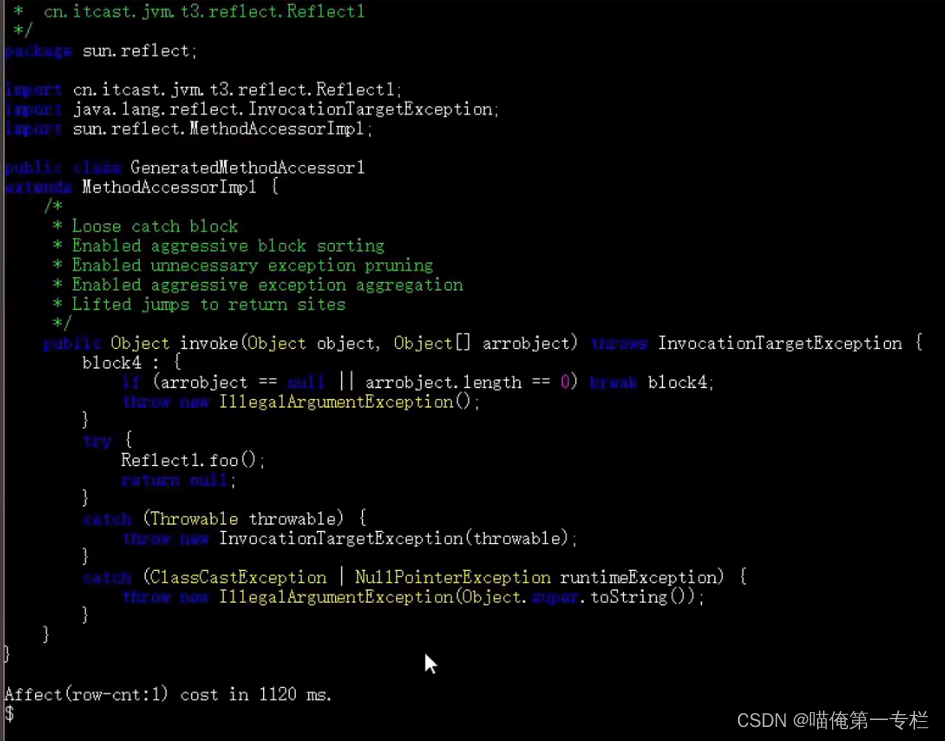
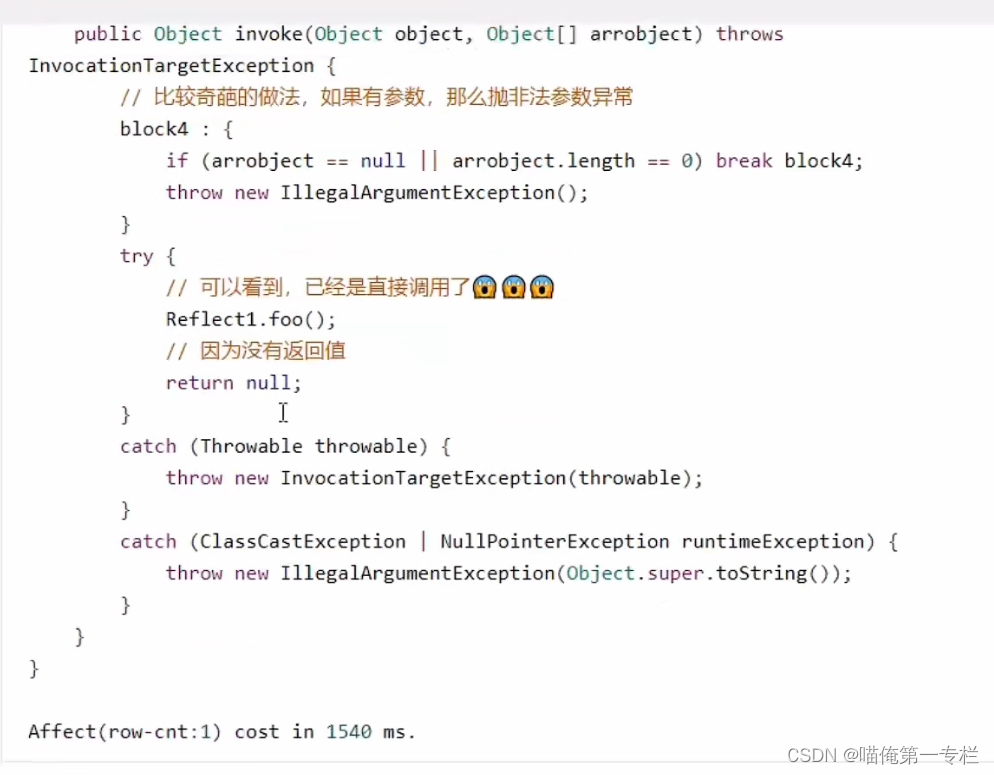
(4)反射优化
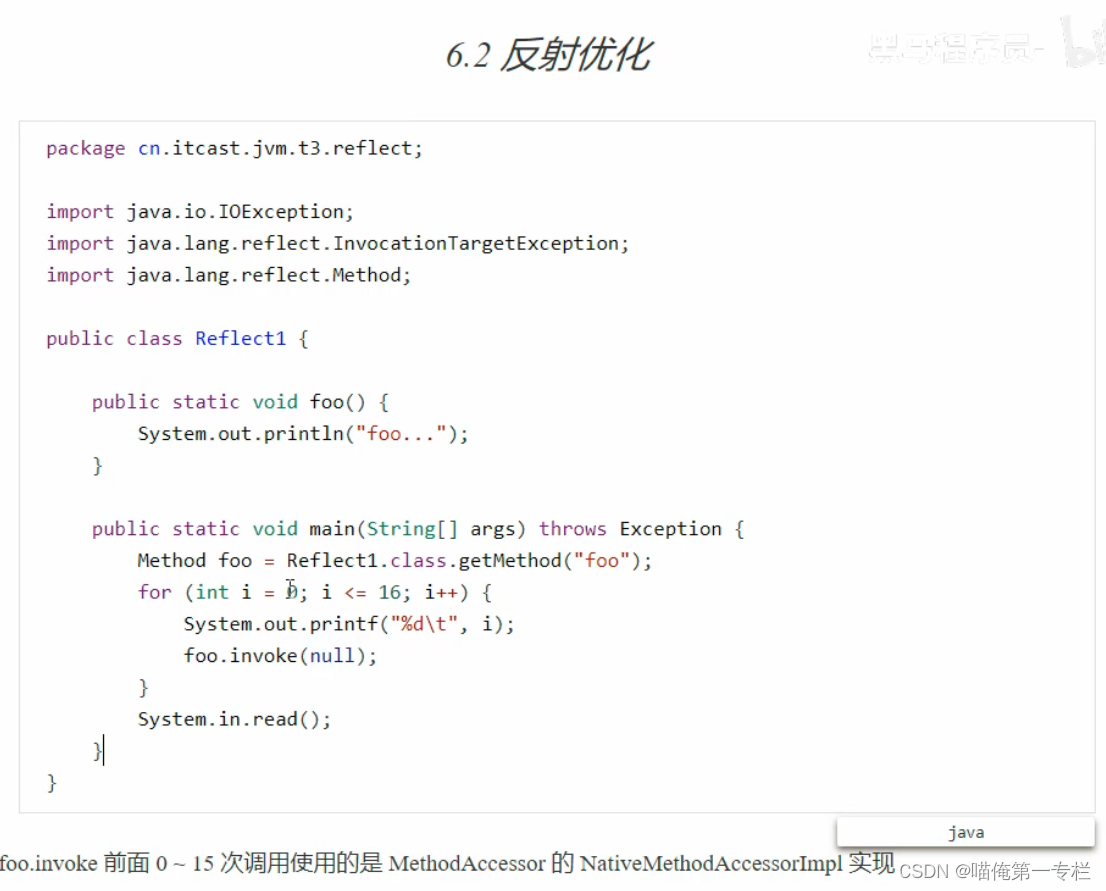
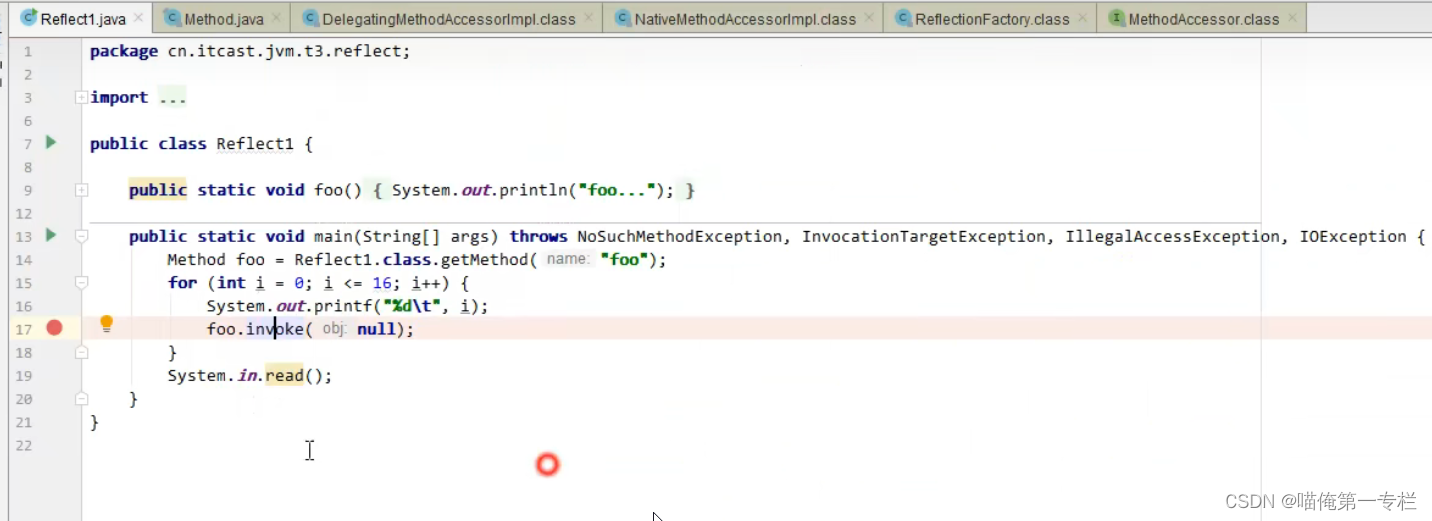
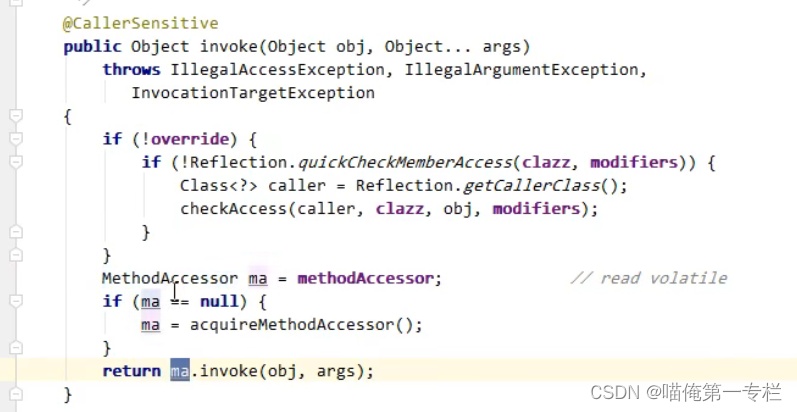

方法实现 :invoke0是native方法是本地方法它的实现代码是C++实现的java这边呢只是对它做了一个调用本地方法的性能调用起来是非常低的,前0-15次调用的都是本地方法,16次性能会变高
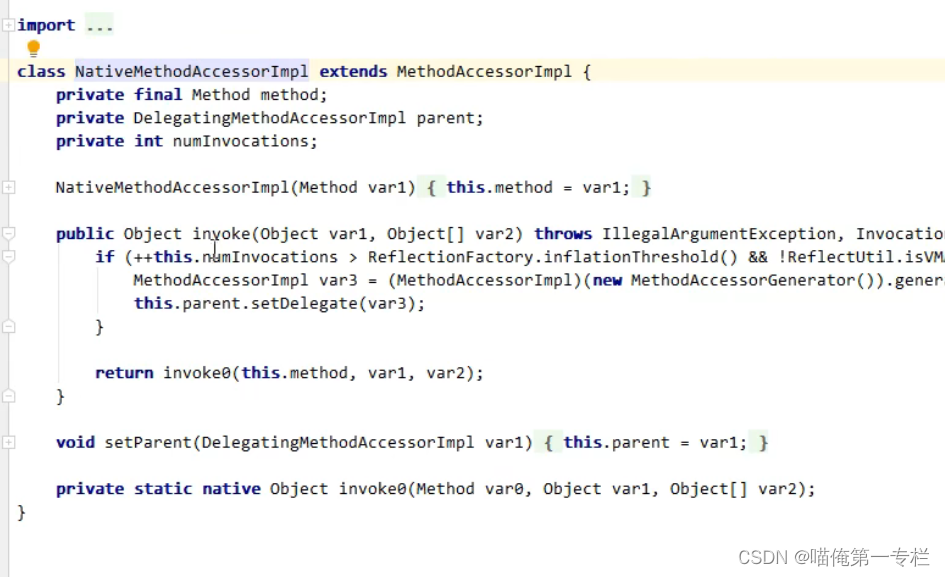

第16次会动态生成新的方法访问器类,在运行期间动态生成的,没有源代码
我们通过一个工具查看

首先知道生成类的名字
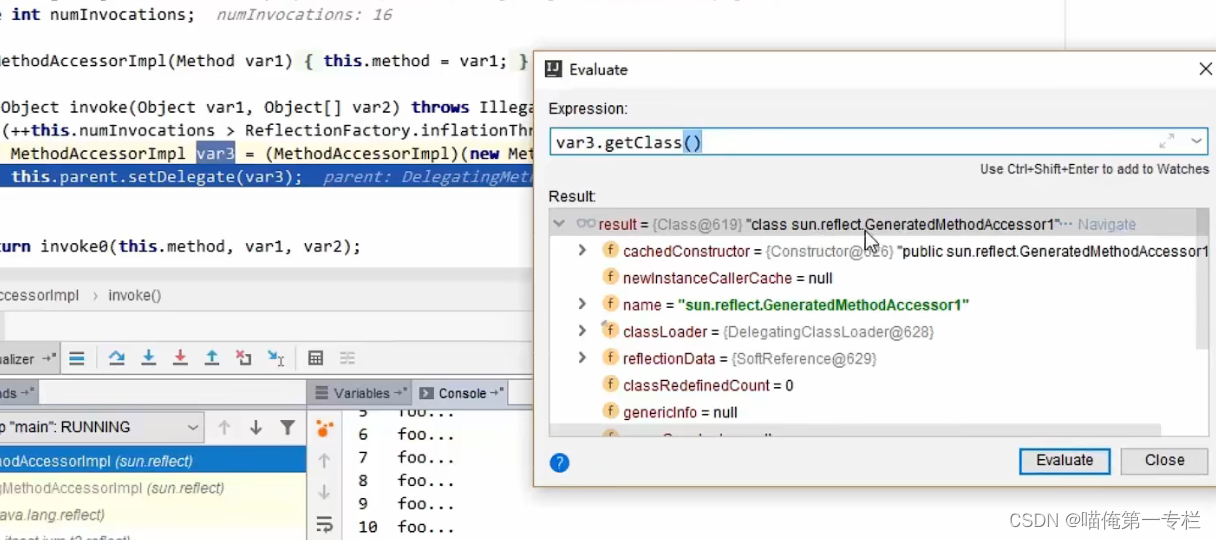
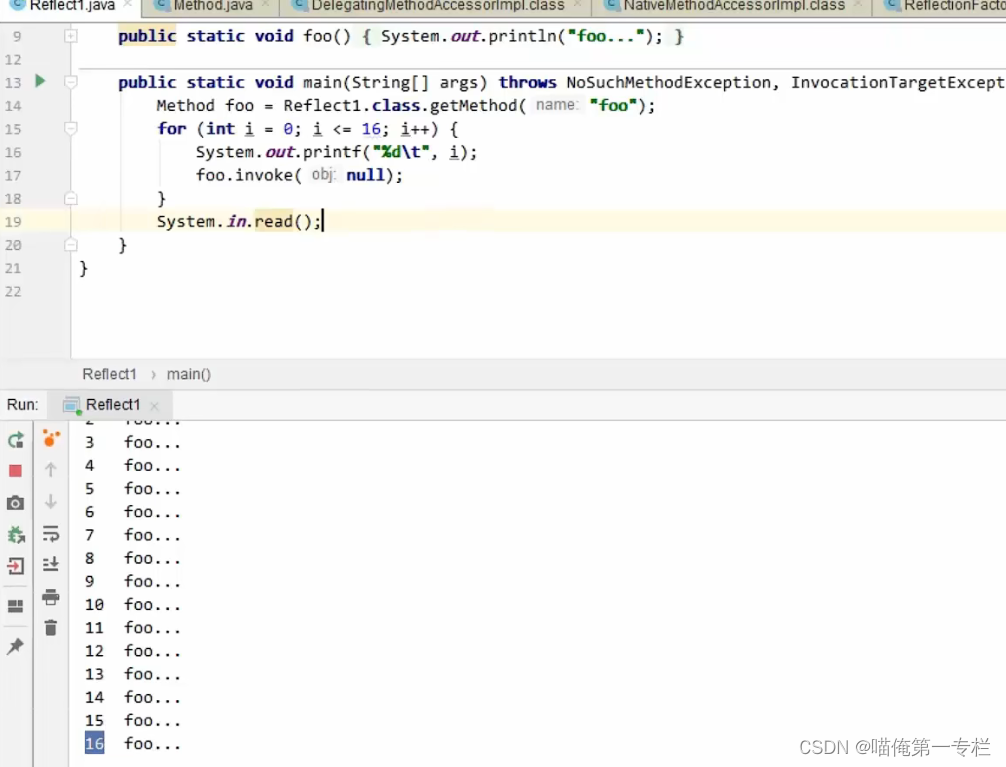
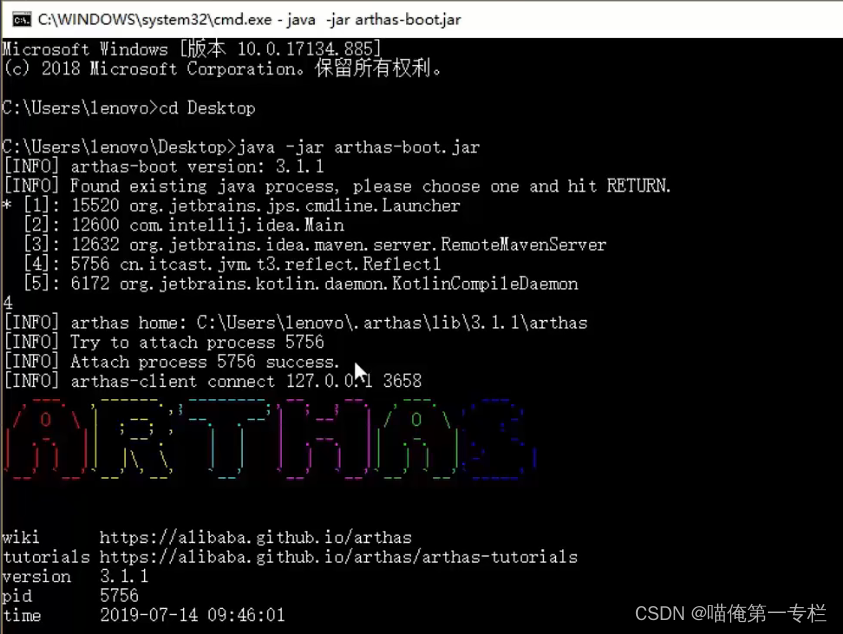
反编译动态生成的类:
第16次把方法反射调用转换成了正常方法调用