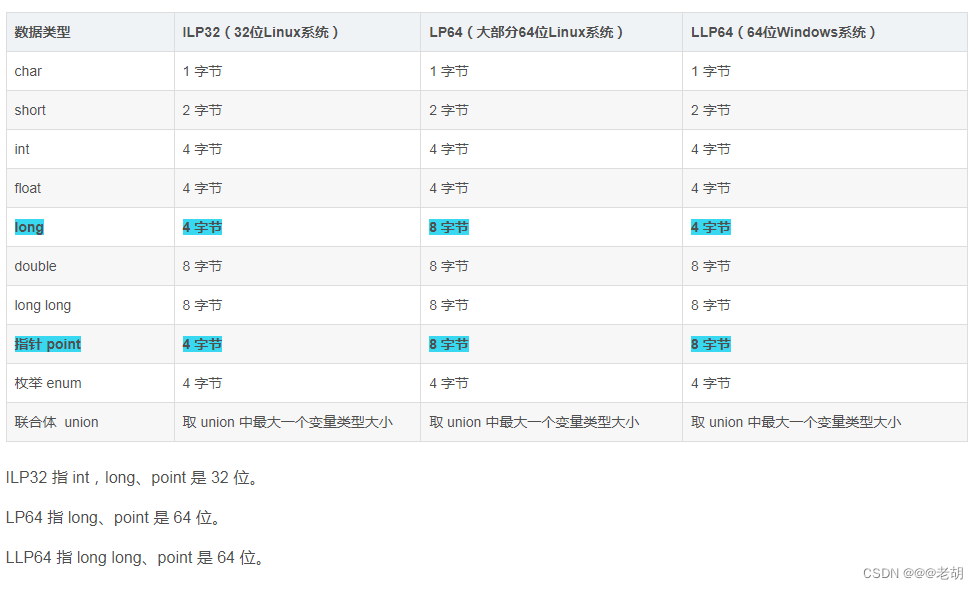
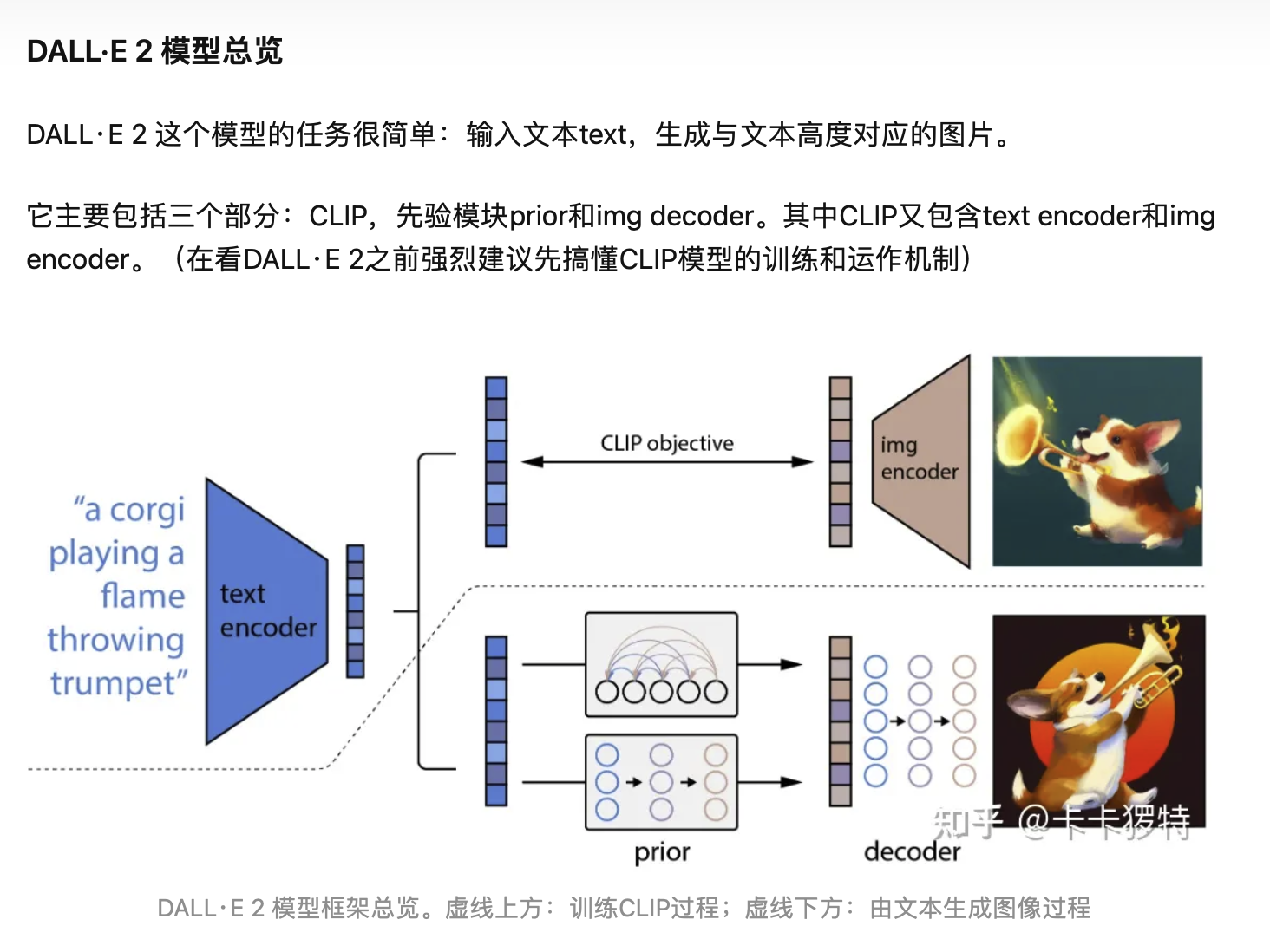
接上篇《38、selenium关于Chrome handless的基本使用》
上一篇我们介绍了selenium中有关Chrome的无头版浏览器Chrome Handless的使用。本篇我们使用selenium做一些常见的复杂验证功能,首先我们来讲解如何进行滑块自动验证的操作。
一、测试用例介绍
我们要通过selenium来实现目前常见的滑块验证码的验证,以豆瓣的登录页面为例: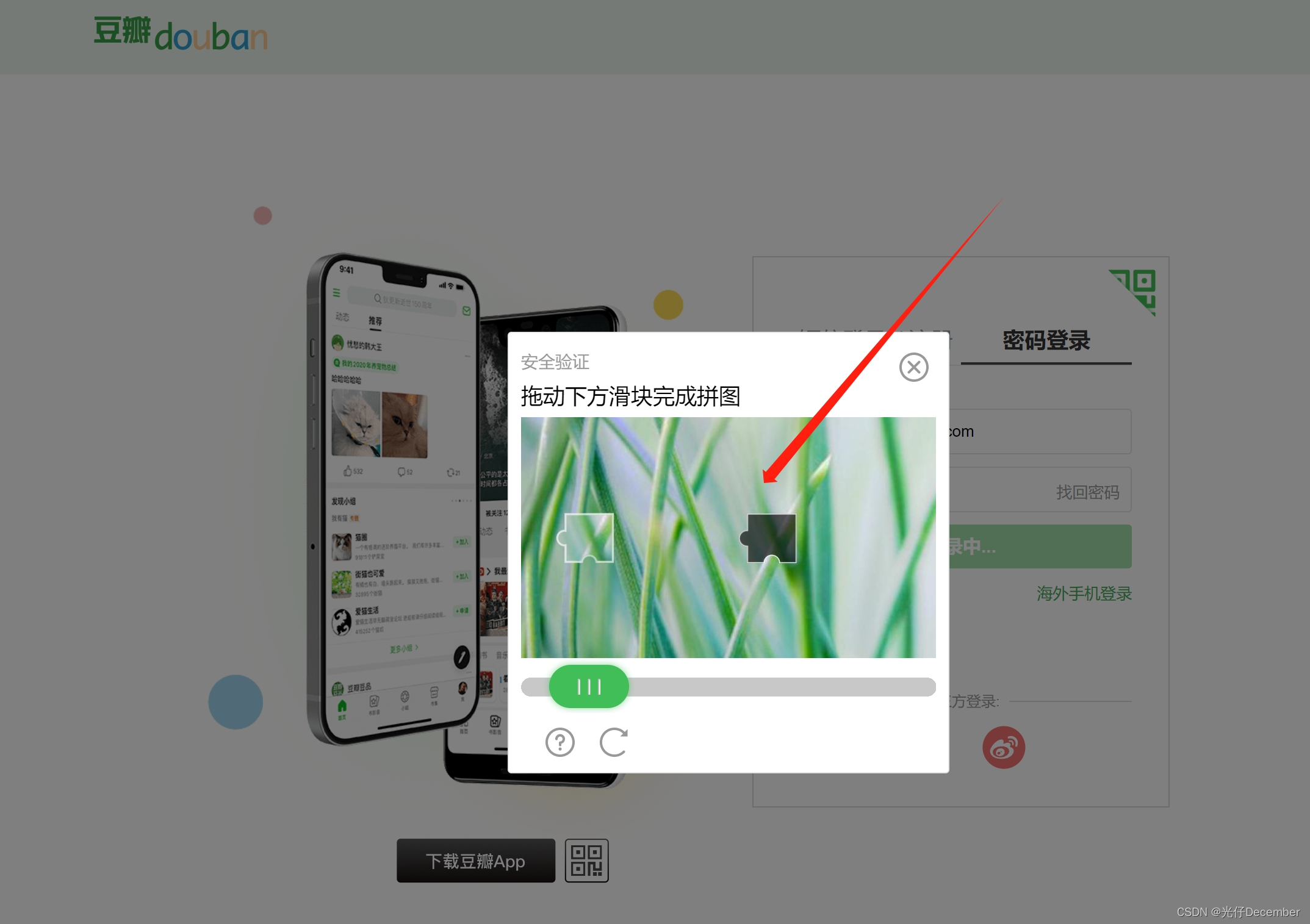
其操作步骤就是:
(1)打开登录页面https://accounts.douban.com/passport/login:
(2)点击页面上的“密码登录”: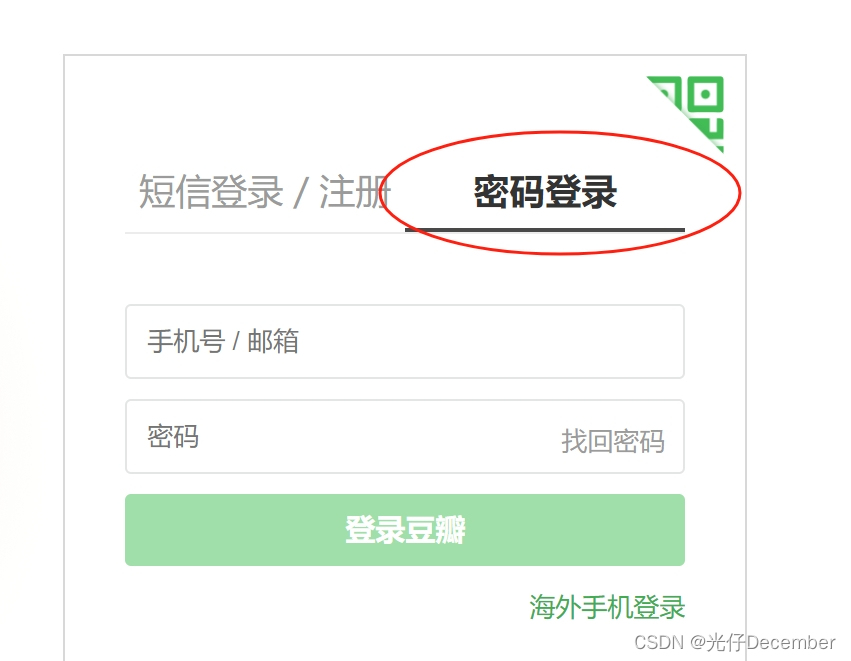
(3)输入账号密码之后,点击“登录豆瓣”按钮:
(4)拼接好弹出的滑块进行登录验证: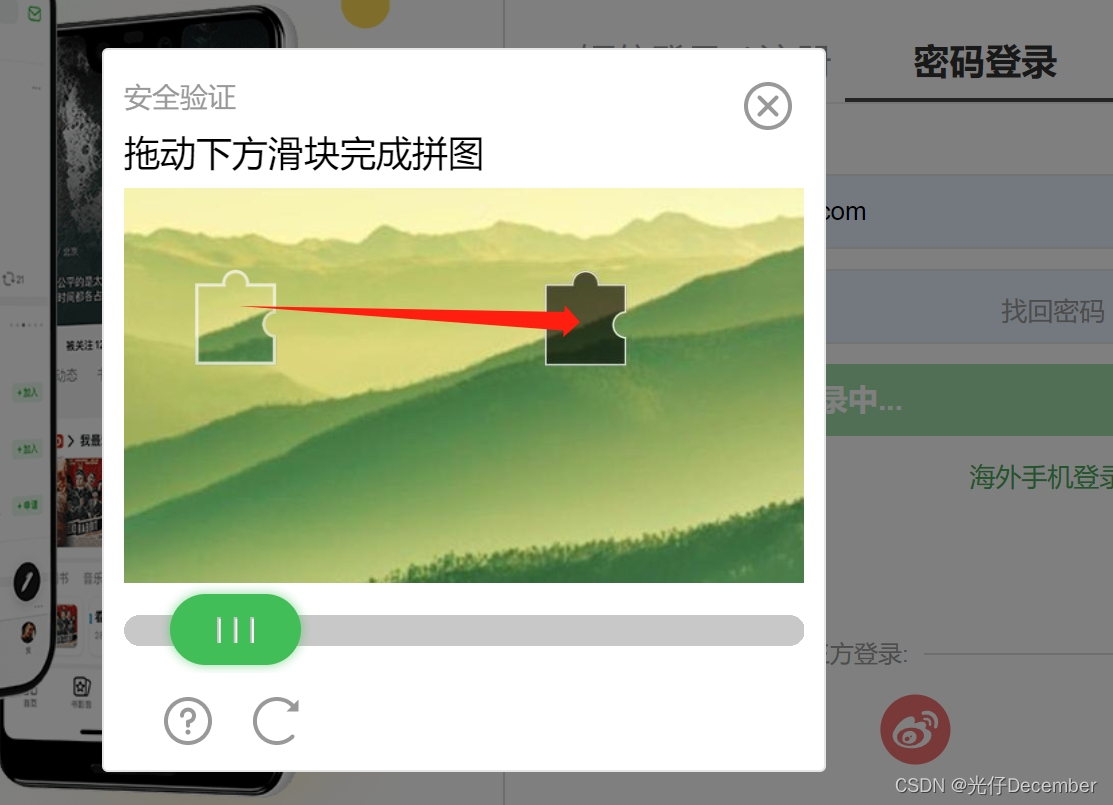
二、需要用到的技术
1、python语言
这里不再赘述,本篇主要还是使用python技术来实现。
2、selenium库
selenium是一个用于测试Web应用程序的Python库。它可以模拟用户在浏览器中的操作,例如点击、填写表单等。Selenium可以与各种浏览器交互,并提供了丰富的API来控制浏览器行为和获取网页内容。
3、urllib库
urllib是Python标准库之一,用于处理URL相关的操作。它包含多个子模块,例如urllib.request用于发送HTTP请求并获取响应,urllib.parse用于解析和构建URL,urllib.error用于处理URL相关的错误等。urllib常用于网络数据抓取、访问API等任务。
4、cv2库
cv2是OpenCV(Open Source Computer Vision)库的Python绑定。OpenCV是一个广泛使用的计算机视觉库,提供了丰富的图像处理和计算机视觉算法。cv2库为Python开发者提供了对OpenCV功能的访问,可以进行图像加载、处理、分析以及计算机视觉任务,如人脸识别、目标检测等。
安装注意事项:
如果直接通过pip install cv2安装报错的话,请使用下面的语句安装:
pip install opencv-python
5、random库
random是Python的随机数生成库。它提供了多种随机数生成函数,包括生成伪随机数的函数和从序列中随机选择元素的函数。random库可用于模拟、游戏开发、密码学等领域,以及各种需要随机性的应用程序。
6、re库
re是Python的正则表达式模块,用于对字符串进行模式匹配和处理。正则表达式是一种强大的文本匹配工具,可以用来搜索、替换、提取特定模式的字符串。re库提供了函数和方法来编译正则表达式、执行匹配操作,并返回匹配结果,使得处理文本数据更加灵活和高效。
三、实现步骤
下面我们使用代码来实现滑块的验证。
1、打开登录页切换密码登录
第一步,打开登录页面,并点击页面上的“密码登录”: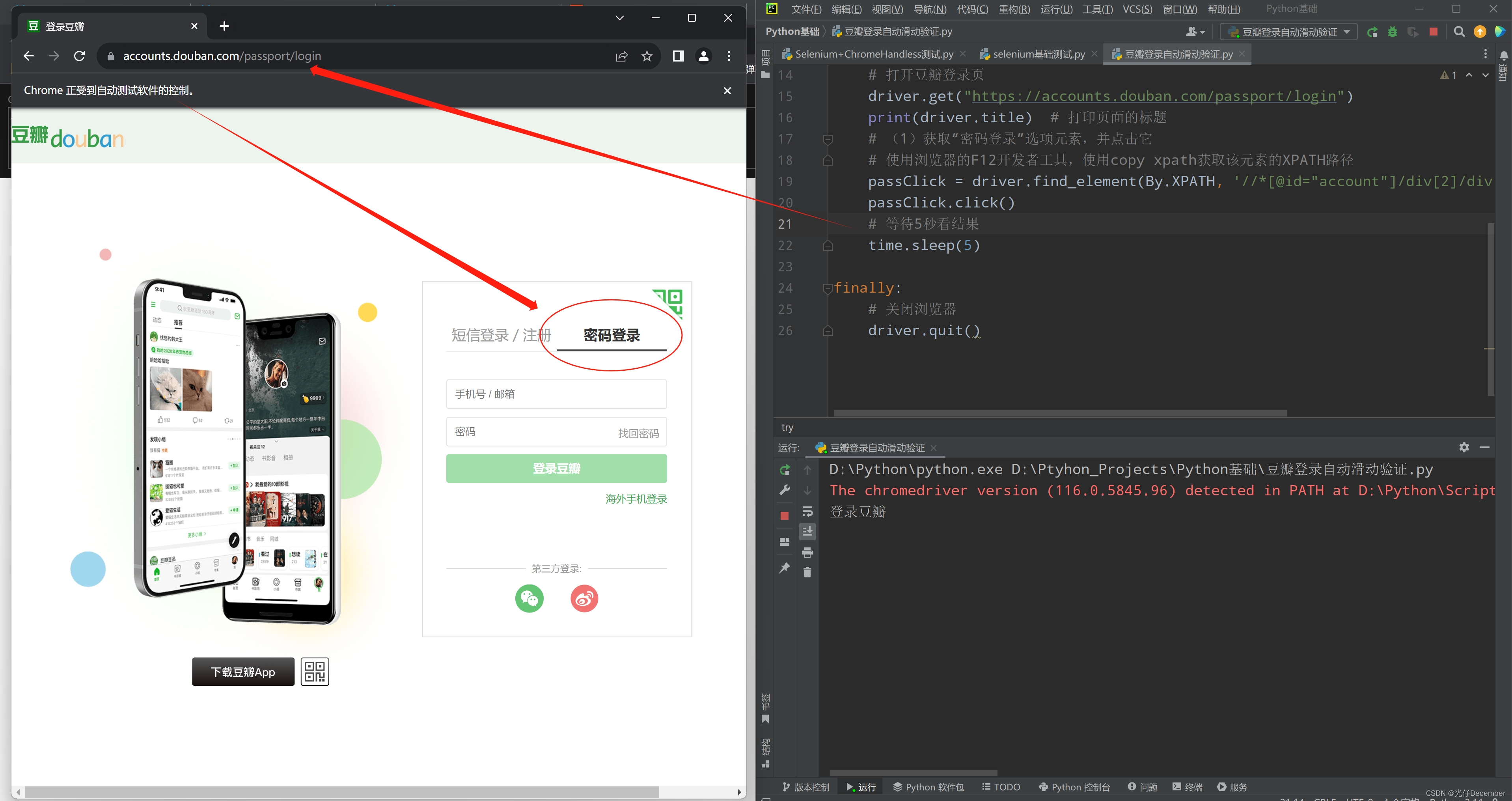 代码:
代码:
import time # 事件库,用于硬性等待
from selenium import webdriver # 导入selenium的webdriver模块
from selenium.webdriver.common.by import By # 引入By类选择器
# 创建Chrome WebDriver对象
driver = webdriver.Chrome()
try:
# 打开豆瓣登录页
driver.get("https://accounts.douban.com/passport/login")
print(driver.title) # 打印页面的标题
# (1)获取“密码登录”选项元素,并点击它
# 使用浏览器的F12开发者工具,使用copy xpath获取该元素的XPATH路径
passClick = driver.find_element(By.XPATH, '//*[@id="account"]/div[2]/div[2]/div/div[1]/ul[1]/li[2]')
passClick.click()
# 整体等待5秒看结果
time.sleep(5)
finally:
# 关闭浏览器
driver.quit()效果:
值得注意的是,这里的“密码登录”的CSS选择器路径,是通过浏览器F12打开开发者选项,使用“copy xpath”功能复制的。
效果: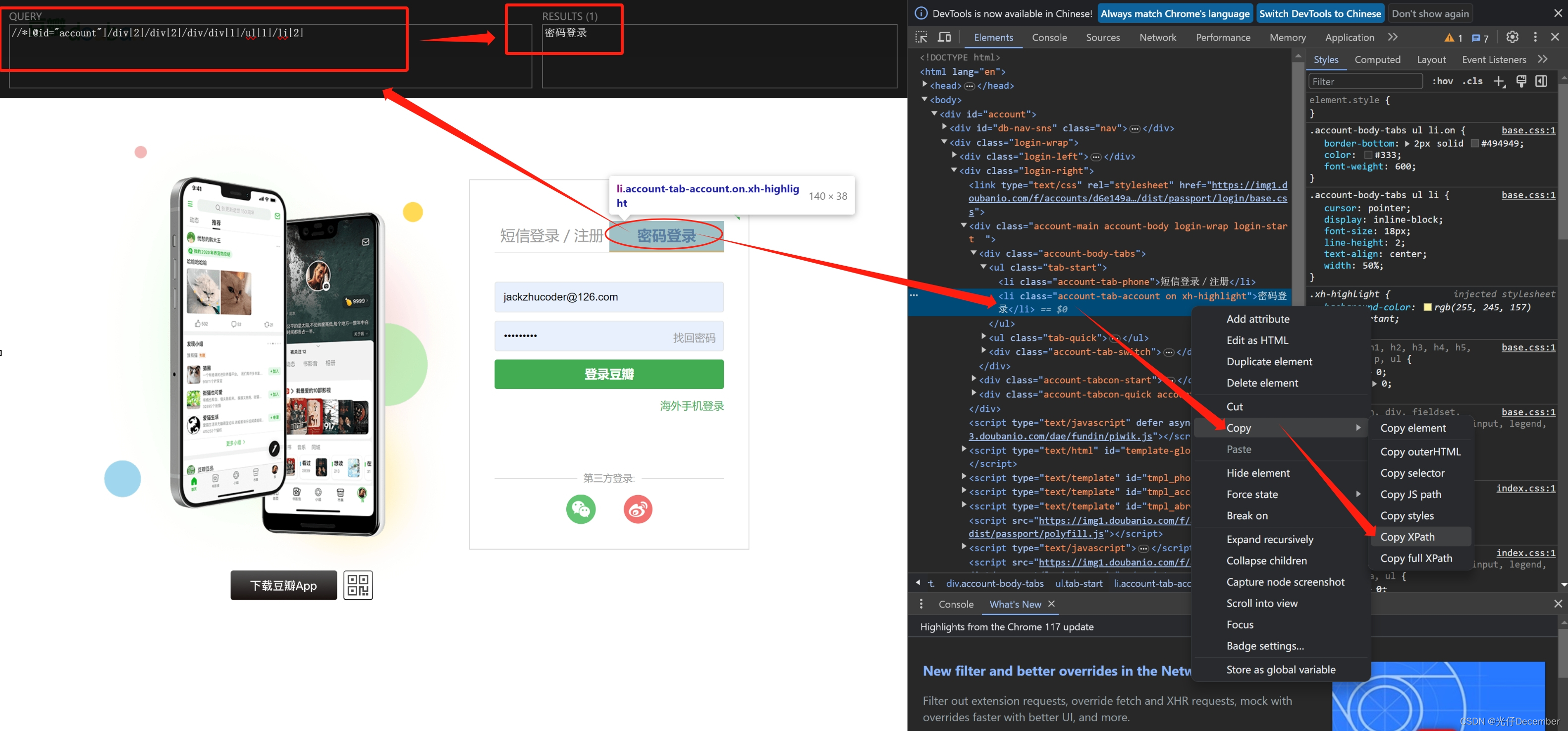
2、输账密点击登录
第二步,输入账号密码,并点击“登录豆瓣”按钮:
# 使用浏览器隐式等待3秒
driver.implicitly_wait(3)
# 获取账号密码组件并赋值
userInput = driver.find_element(By.ID, "username")
userInput.send_keys("jackzhucoder@126.com")
passInput = driver.find_element(By.ID, "password")
passInput.send_keys("123456")
# 获取登录按钮并点击登录
loginButton = driver.find_element(By.XPATH, '//*[@id="account"]/div[2]/div[2]/div/div[2]/div[1]/div[4]/a')
loginButton.click()这里的登录按钮的xpath路径,也是使用开发者选项的“copy xpath”功能复制。
效果: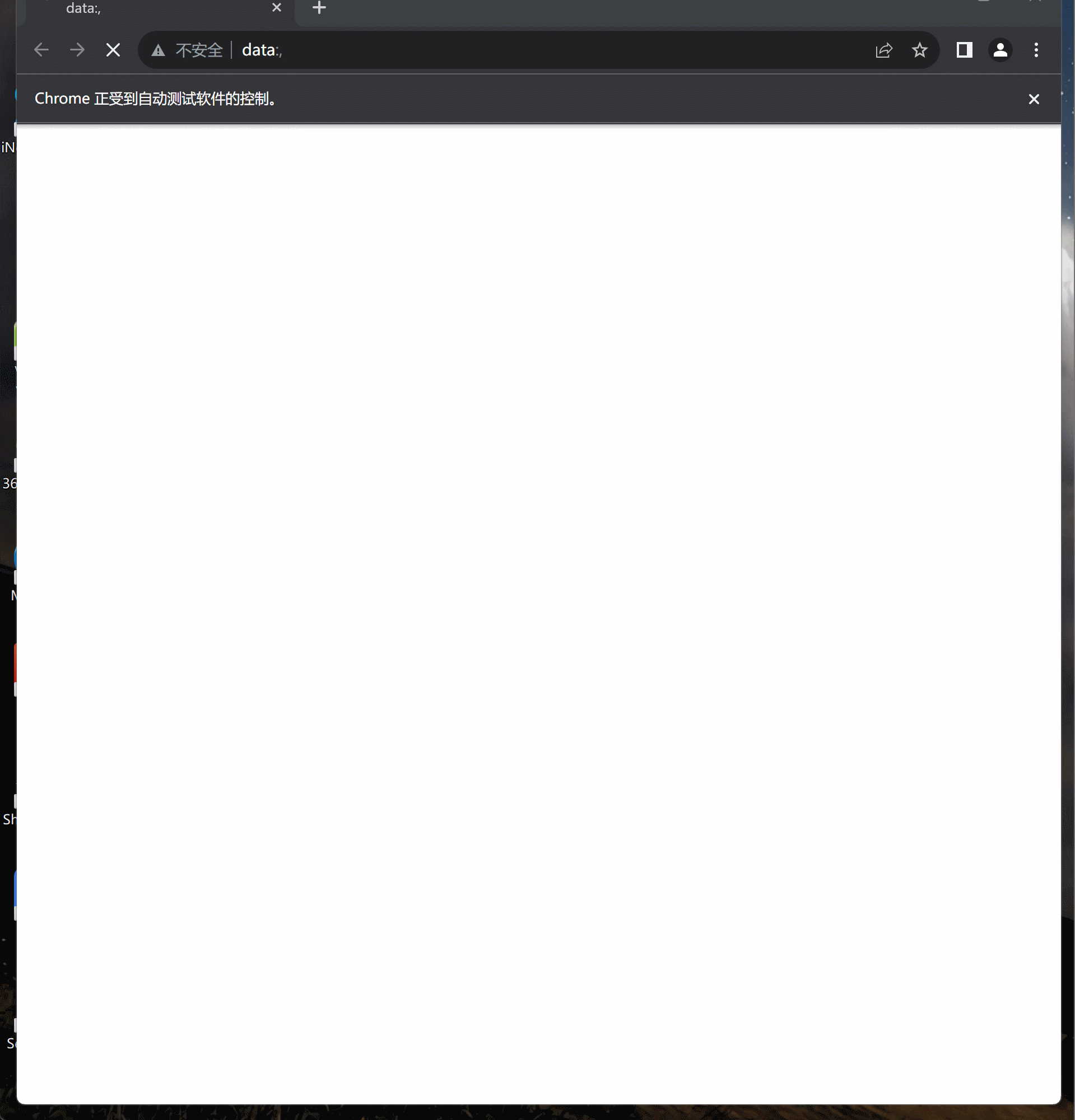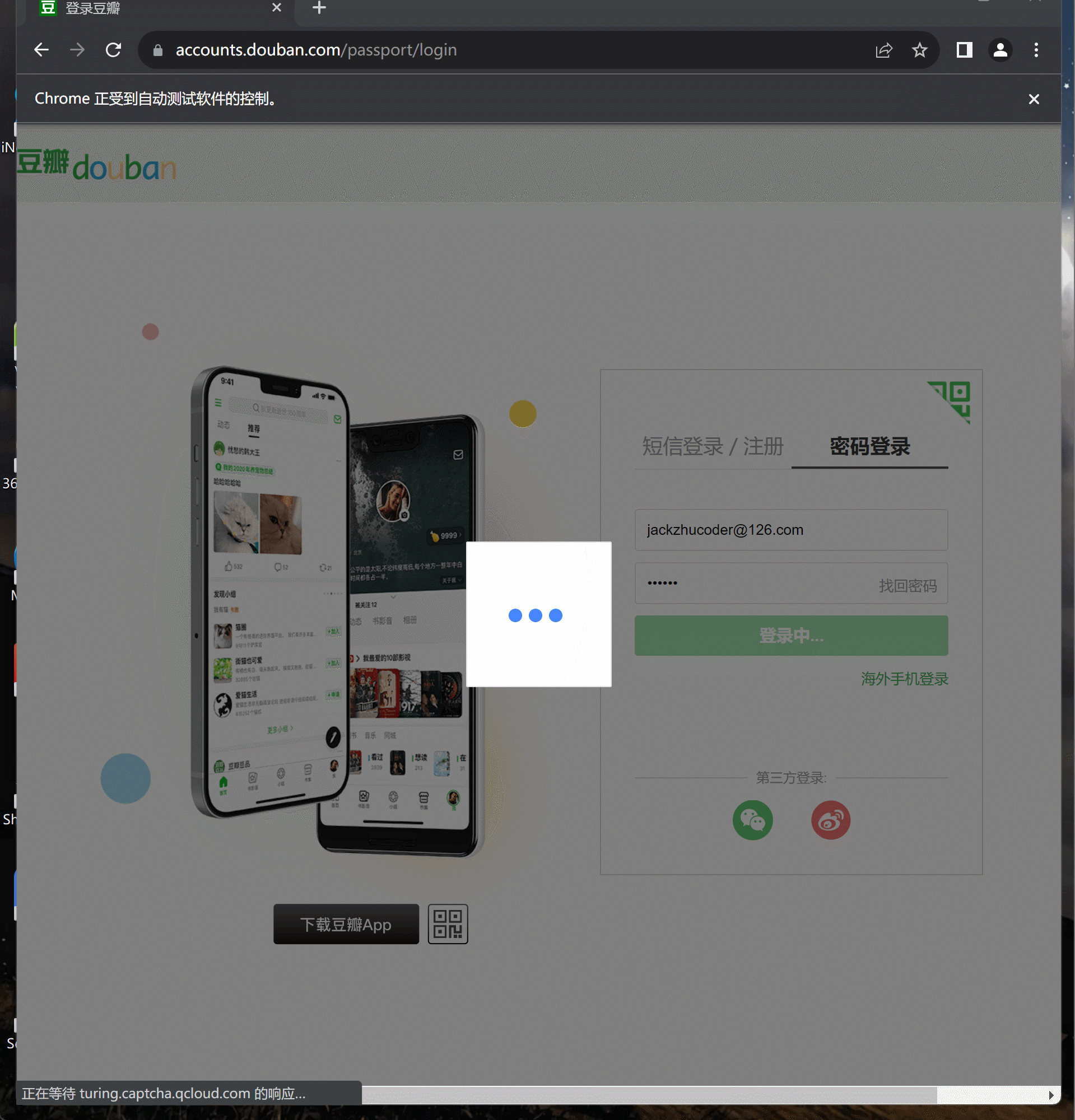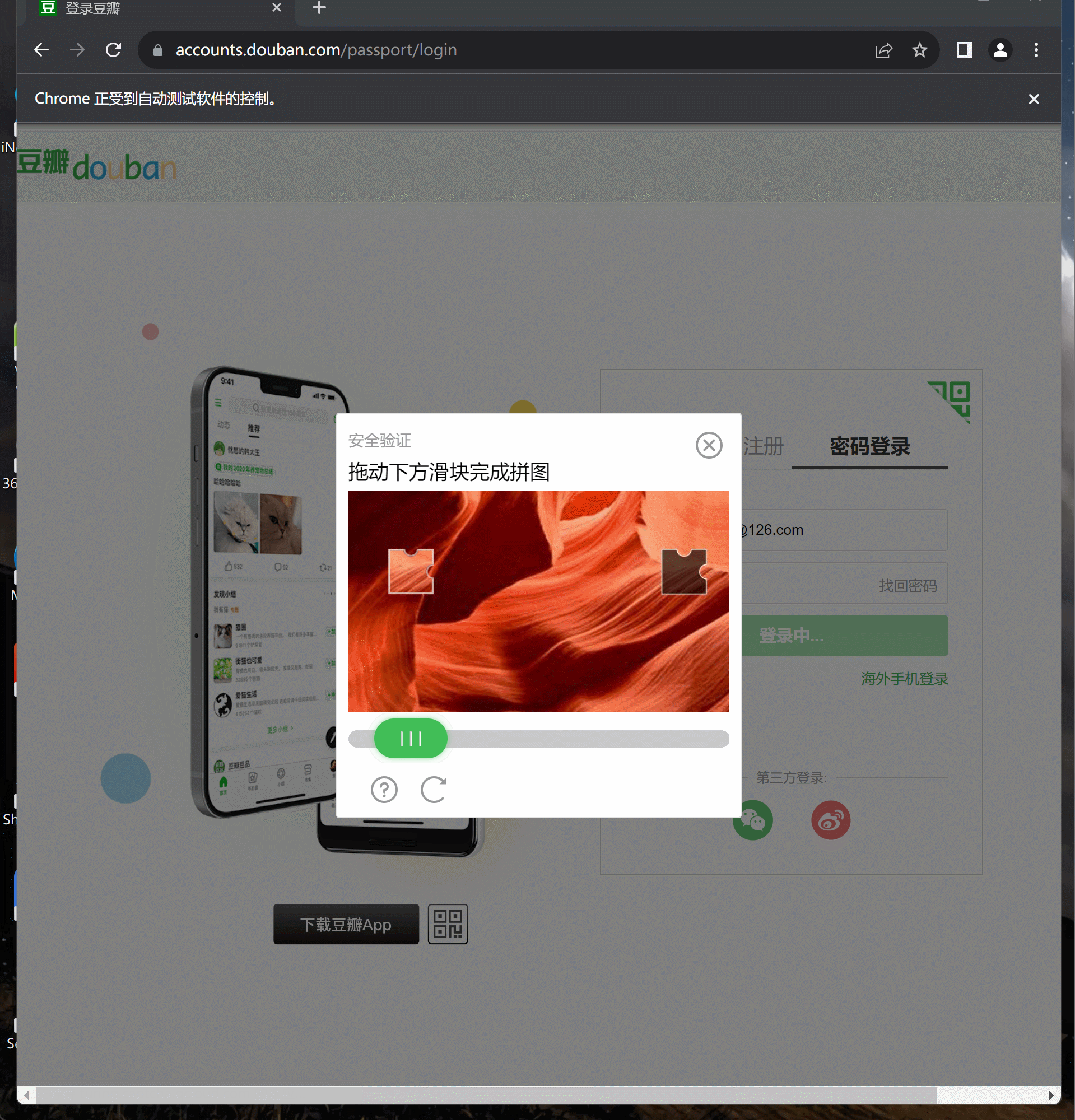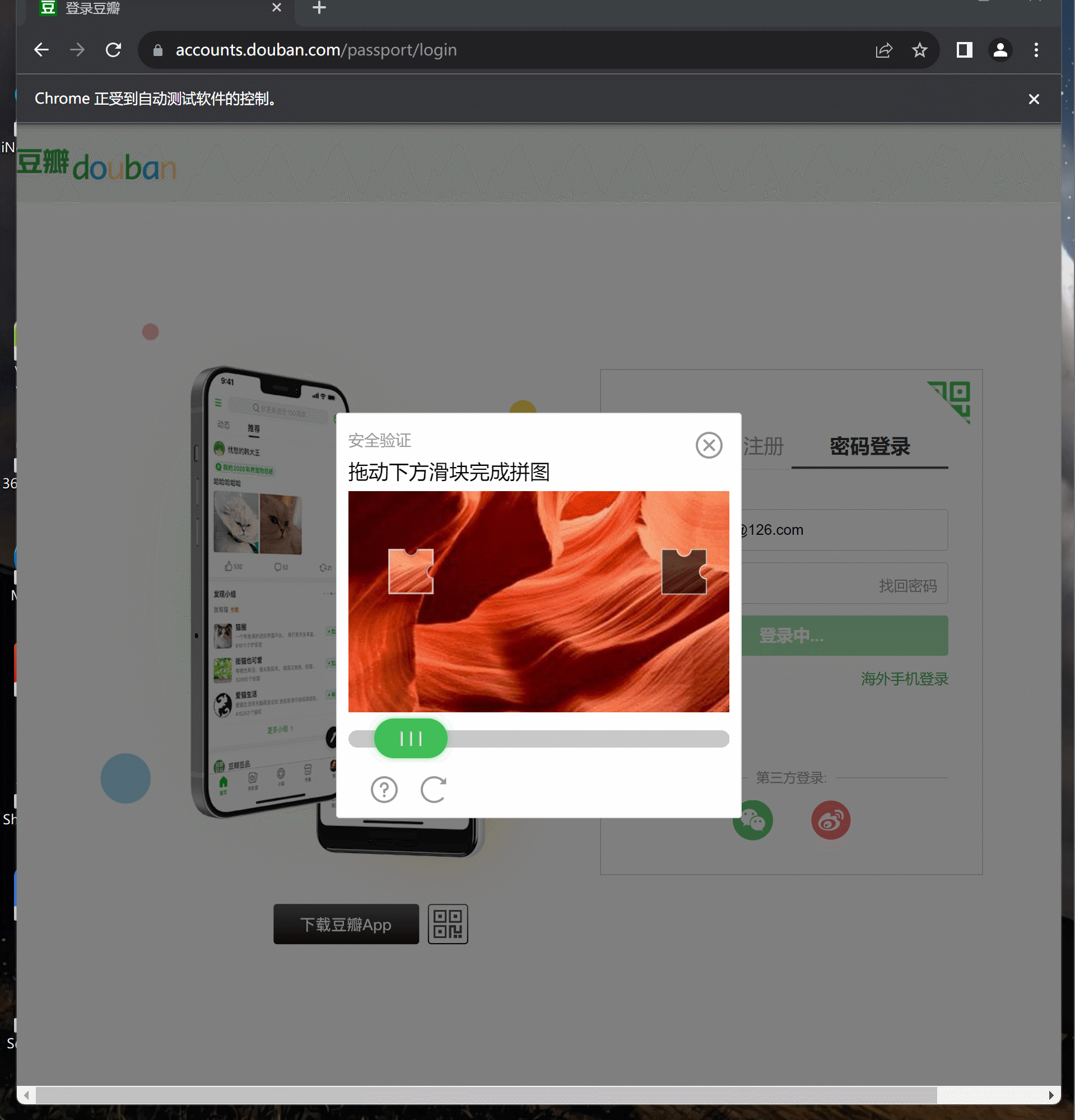
3、切换焦点并下载验证图片
将焦点切换至滑块验证区域,并下载加载好的滑块验证背景图片。
点击登录按钮后,就会出现滑块验证区域,这是一个新增的frame区域,此时我们需要将切换的焦点从主页面转换到这个frame区域上: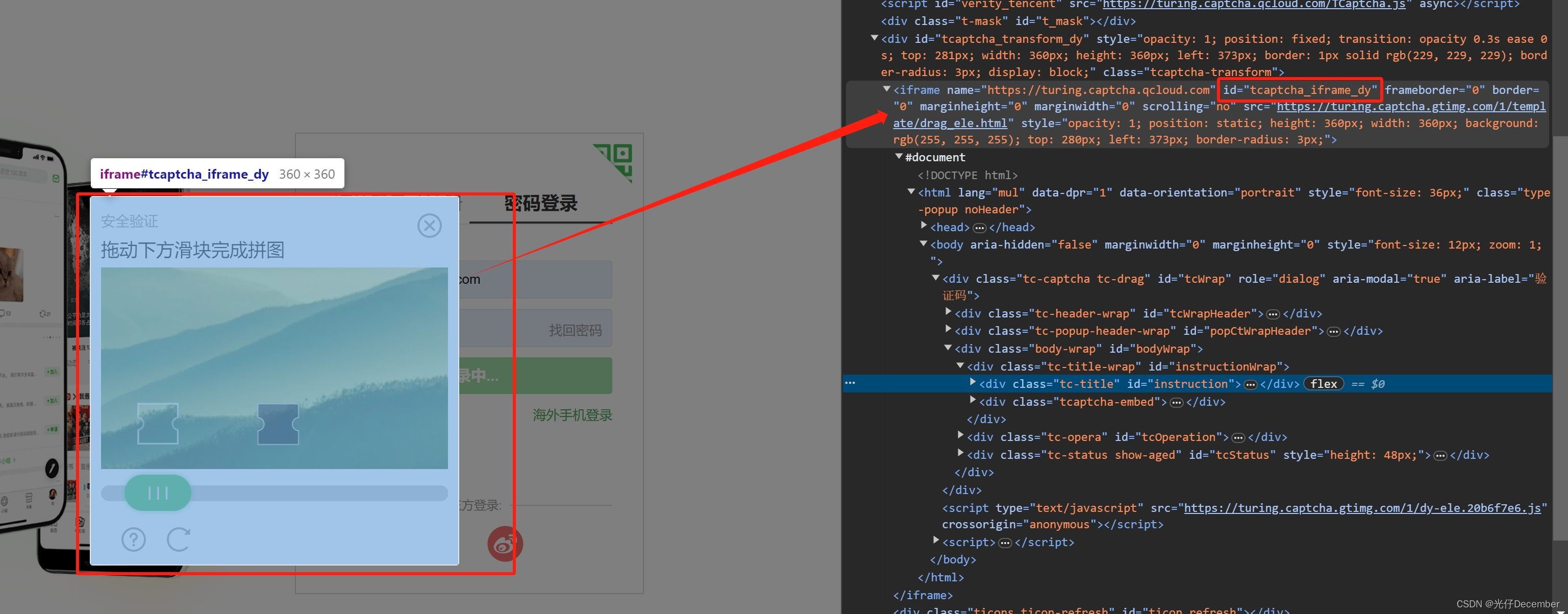
代码上我们使用WebDriver的switch_to.frame方法即可,参数就是frame区域的id名“tcaptcha_iframe_dy”。
然后我们需要获取整个需要对其的大图片,获取其路径并下载到本地,准备进行读取验证: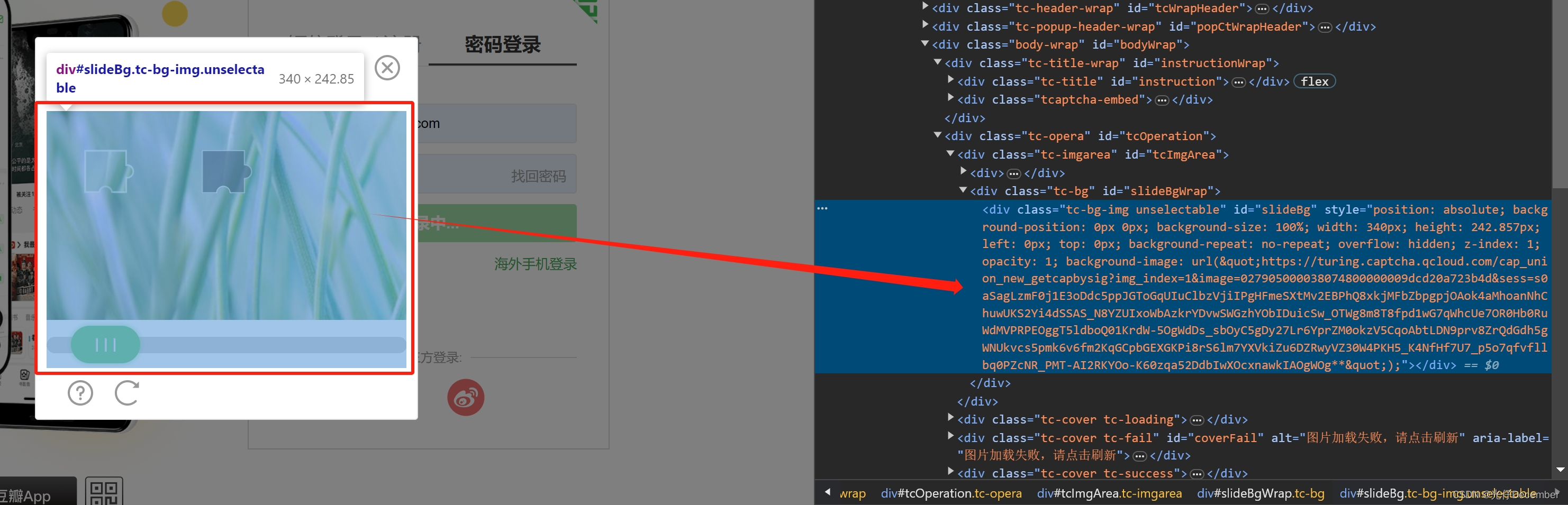
这里图片元素获取比较简单,通过ID名“slideBg”获取即可,但是图片路径需要分析其style属性中的css参数,通过正则表达式将图片src地址解析出来,然后通过urllib访问这个路径将图片下载下来。
解析图片前,一定一定要等待图片元素加载完成之后再获取,否则会什么也解析不到。
代码:
driver.implicitly_wait(5) # 使用浏览器隐式等待5秒
# 此时需要切换到弹出的滑块区域,需要切换frame窗口
driver.switch_to.frame("tcaptcha_iframe_dy")
# 等待滑块验证图片加载后,再做后面的操作
WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.ID, 'slideBg')))
# 获取滑块验证图片下载路径,并下载到本地
bigImage = driver.find_element(By.ID, "slideBg")
s = bigImage.get_attribute("style") # 获取图片的style属性
# 设置能匹配出图片路径的正则表达式
p = 'background-image: url\(\"(.*?)\"\);'
# 进行正则表达式匹配,找出匹配的字符串并截取出来
bigImageSrc = re.findall(p, s, re.S)[0] # re.S表示点号匹配任意字符,包括换行符
print("滑块验证图片下载路径:", bigImageSrc)
# 下载图片至本地
urllib.request.urlretrieve(bigImageSrc, 'bigImage.png')下载图片的效果:
4、拖动滑块至缺口处
我们接下来要做的,是将小拼图图片,移动到缺口处:
我们需要获取小图片到缺口处的实际距离,一般用到两种方法。
第一种方法是模板匹配,通过openCV分析两个图片的相似度,获取两个相似度很高图片的坐标,从而计算两个图片的距离。
第二种方法是轮廓检测,通过openCV进行轮廓检测,即在大图片中找到缺口位置的坐标,然后计算小图片到缺口位置的距离。
这里因为我们无法单独获取小拼图的单独图片,所以不好使用模板匹配的方法,所以我们选择使用第二种轮廓检测的方法。
(1)得到缺口轮廓位置信息
首先我们计算一下缺口的坐标及面积大概有多大,使用PhotoShop打开下载的图片,单独将缺口按照正方形的尺寸抠出来,发现其长宽各是80像素: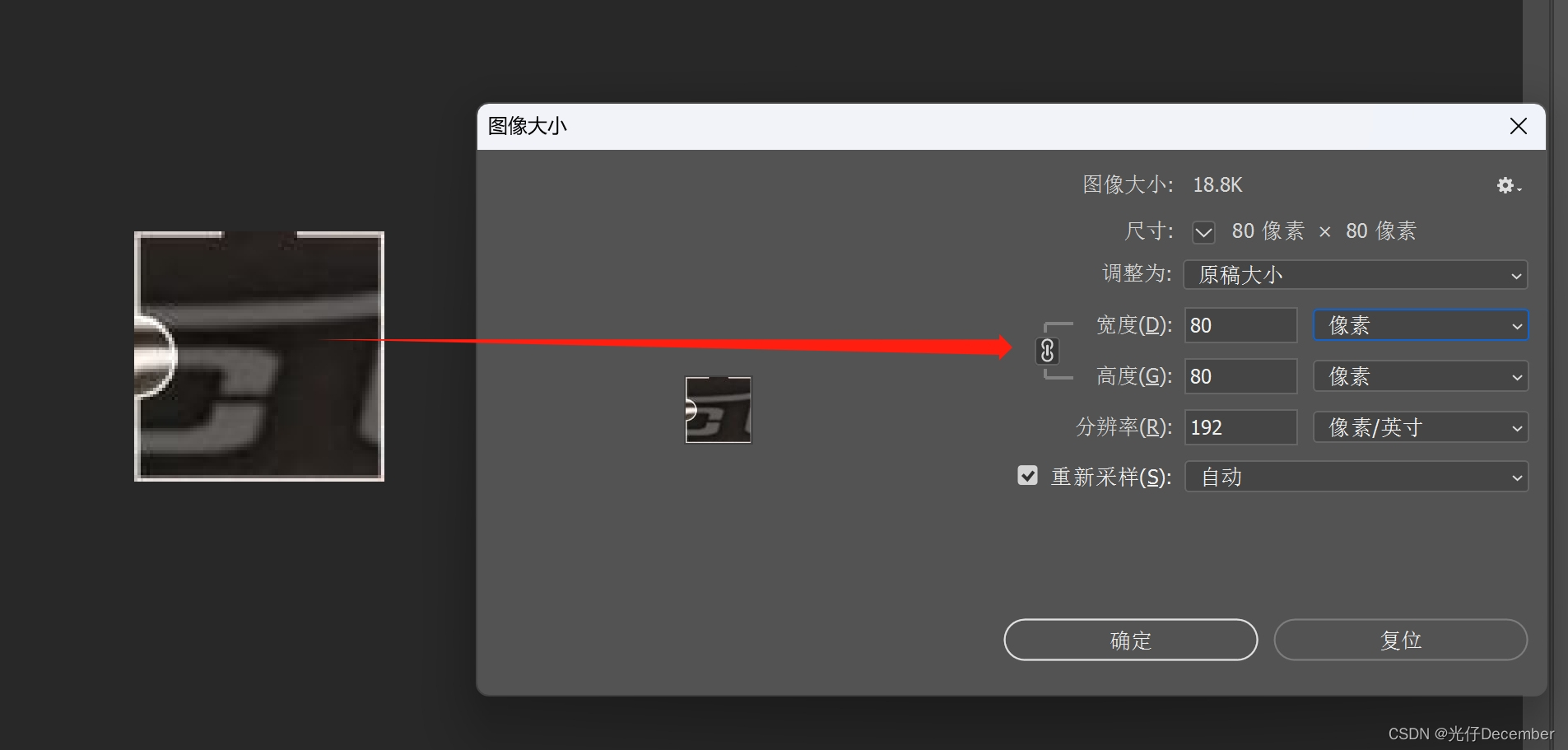
所以这个封闭矩形的面积范围大概是在80*80=6400像素左右。周长是80*4=320像素。但是现实中这里是有缺口的,不是一个完整的图片,所以我们需要给它一定的误差范围,这里我们暂定目标区域面积为5025-7225,周长为300-380。
然后我们将计算距离的逻辑封装为一个方法:
# 封装的计算图片距离的算法
def get_pos(imageSrc):
# 读取图像文件并返回一个image数组表示的图像对象
image = cv2.imread(imageSrc)
# GaussianBlur方法进行图像模糊化/降噪操作。
# 它基于高斯函数(也称为正态分布)创建一个卷积核(或称为滤波器),该卷积核应用于图像上的每个像素点。
blurred = cv2.GaussianBlur(image, (5, 5), 0, 0)
# Canny方法进行图像边缘检测
# image: 输入的单通道灰度图像。
# threshold1: 第一个阈值,用于边缘链接。一般设置为较小的值。
# threshold2: 第二个阈值,用于边缘链接和强边缘的筛选。一般设置为较大的值
canny = cv2.Canny(blurred, 0, 100) # 轮廓
# findContours方法用于检测图像中的轮廓,并返回一个包含所有检测到轮廓的列表。
# contours(可选): 输出的轮廓列表。每个轮廓都表示为一个点集。
# hierarchy(可选): 输出的轮廓层次结构信息。它描述了轮廓之间的关系,例如父子关系等。
contours, hierarchy = cv2.findContours(canny, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# 遍历检测到的所有轮廓的列表
for contour in contours:
# contourArea方法用于计算轮廓的面积
area = cv2.contourArea(contour)
# arcLength方法用于计算轮廓的周长或弧长
length = cv2.arcLength(contour, True)
# 如果检测区域面积在5025-7225之间,周长在300-380之间,则是目标区域
if 5025 < area < 7225 and 300 < length < 380:
# 计算轮廓的边界矩形,得到坐标和宽高
# x, y: 边界矩形左上角点的坐标。
# w, h: 边界矩形的宽度和高度。
x, y, w, h = cv2.boundingRect(contour)
print("计算出目标区域的坐标及宽高:", x, y, w, h)
# 在目标区域上画一个红框看看效果
cv2.rectangle(image, (x, y), (x+w, y+h), (0, 0, 255), 2)
cv2.imwrite("111.jpg", image)
return x
return 0然后在下载图片后调用该方法:
# 下载图片至本地
urllib.request.urlretrieve(bigImageSrc, 'bigImage.png')
# 计算缺口图像的x轴位置
dis = get_pos('bigImage.png')
# 整体等待5秒看结果
time.sleep(5)效果:
生成的目标区域画红框的计算图片:
好了,到此为止我们获取到了一个重要的数据,就是缺口的位置信息。
(2)匹配小滑块元素
得到小滑块元素,让其移动位置到上面计算的距离。
这里我们移动的位置,并不是直接拿刚刚我们得到的图片上的x1减去小滑块的x2坐标,因为我们打开F12开发者界面,可以看到整体图片的宽度是小于原来下载下来的图片的(网页开发者为其固定了长宽),所以我们要重新计算一下缺口的x1位置相对于更小的这块图片的位置:
计算的方法就是拿原来的坐标乘以新画布的宽度,再除以原画布的宽度:
新缺口坐标=原缺口坐标*新画布宽度/原画布宽度
原理就是小学数字(见图):
下面开始写代码。
首先获取小滑块的xpath地址,用于获取该元素: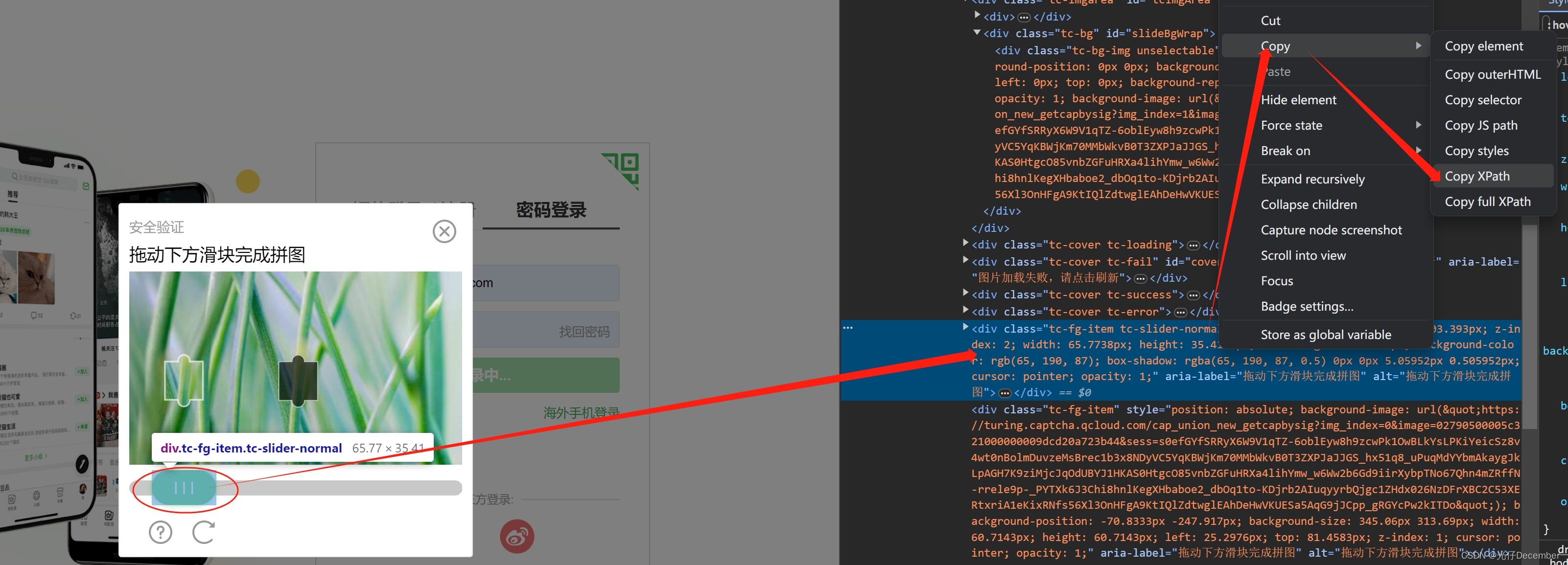
代码:
# 计算缺口图像的x轴位置
dis = get_pos('bigImage.png')
# 获取小滑块元素,并移动它到上面的位置
smallImage = driver.find_element(By.XPATH, '//*[@id="tcOperation"]/div[6]')
# 小滑块到目标区域的移动距离(缺口坐标的水平位置距离小滑块的水平坐标相减的差)
# 新缺口坐标=原缺口坐标*新画布宽度/原画布宽度
newDis = int(dis*340/672-smallImage.location['x'])
driver.implicitly_wait(5) # 使用浏览器隐式等待5秒
# 按下小滑块按钮不动
ActionChains(driver).click_and_hold(smallImage).perform()
# 移动小滑块,模拟人的操作,一次次移动一点点
i = 0
moved = 0
while moved < newDis:
x = random.randint(3, 10) # 每次移动3到10像素
moved += x
ActionChains(driver).move_by_offset(xoffset=x, yoffset=0).perform()
print("第{}次移动后,位置为{}".format(i, smallImage.location['x']))
i += 1
# 移动完之后,松开鼠标
ActionChains(driver).release().perform()
# 整体等待5秒看结果
time.sleep(5)由于大部分网站有检测真人操作的逻辑,所以我们这里要模拟真人进行移动操作,不能一下移动到目标点,需要一点一点的移动。
效果:
selenium自动验证滑块效果
四、完整代码
以下是上面按照步骤编写完毕的完整代码(截止2023年10月6日),后期网站有更新或者元素布局有所变化,需要各位修改优化。
本代码仅供学习参考,切勿用于其他用途。
# _*_ coding : utf-8 _*_
# @Time : 2023-10-06 9:44
# @Author : 光仔December
# @File : 豆瓣登录自动滑动验证
# @Project : Python基础
import random
import re # 正则表达式匹配库
import time # 事件库,用于硬性等待
import urllib # 网络访问
import cv2 # opencv库
from selenium import webdriver # 导入selenium的webdriver模块
from selenium.webdriver.common.by import By # 引入By类选择器
from selenium.webdriver.support.wait import WebDriverWait # 等待类
from selenium.webdriver.support import expected_conditions as EC # 等待条件类
from selenium.webdriver.common.action_chains import ActionChains # 动作类
# 封装的计算图片距离的算法
def get_pos(imageSrc):
# 读取图像文件并返回一个image数组表示的图像对象
image = cv2.imread(imageSrc)
# GaussianBlur方法进行图像模糊化/降噪操作。
# 它基于高斯函数(也称为正态分布)创建一个卷积核(或称为滤波器),该卷积核应用于图像上的每个像素点。
blurred = cv2.GaussianBlur(image, (5, 5), 0, 0)
# Canny方法进行图像边缘检测
# image: 输入的单通道灰度图像。
# threshold1: 第一个阈值,用于边缘链接。一般设置为较小的值。
# threshold2: 第二个阈值,用于边缘链接和强边缘的筛选。一般设置为较大的值
canny = cv2.Canny(blurred, 0, 100) # 轮廓
# findContours方法用于检测图像中的轮廓,并返回一个包含所有检测到轮廓的列表。
# contours(可选): 输出的轮廓列表。每个轮廓都表示为一个点集。
# hierarchy(可选): 输出的轮廓层次结构信息。它描述了轮廓之间的关系,例如父子关系等。
contours, hierarchy = cv2.findContours(canny, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# 遍历检测到的所有轮廓的列表
for contour in contours:
# contourArea方法用于计算轮廓的面积
area = cv2.contourArea(contour)
# arcLength方法用于计算轮廓的周长或弧长
length = cv2.arcLength(contour, True)
# 如果检测区域面积在5025-7225之间,周长在300-380之间,则是目标区域
if 5025 < area < 7225 and 300 < length < 380:
# 计算轮廓的边界矩形,得到坐标和宽高
# x, y: 边界矩形左上角点的坐标。
# w, h: 边界矩形的宽度和高度。
x, y, w, h = cv2.boundingRect(contour)
print("计算出目标区域的坐标及宽高:", x, y, w, h)
# 在目标区域上画一个红框看看效果
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 2)
cv2.imwrite("111.jpg", image)
return x
return 0
# 创建Chrome WebDriver对象
driver = webdriver.Chrome()
try:
# 打开豆瓣登录页
driver.get("https://accounts.douban.com/passport/login")
print(driver.title) # 打印页面的标题
# (1)获取“密码登录”选项元素,并点击它
# 使用浏览器的F12开发者工具,使用copy xpath获取该元素的XPATH路径
passClick = driver.find_element(By.XPATH, '//*[@id="account"]/div[2]/div[2]/div/div[1]/ul[1]/li[2]')
passClick.click()
driver.implicitly_wait(3) # 使用浏览器隐式等待3秒
# 获取账号密码组件并赋值
userInput = driver.find_element(By.ID, "username")
userInput.send_keys("jackzhucoder@126.com")
passInput = driver.find_element(By.ID, "password")
passInput.send_keys("123456")
# 获取登录按钮并点击登录
loginButton = driver.find_element(By.XPATH, '//*[@id="account"]/div[2]/div[2]/div/div[2]/div[1]/div[4]/a')
loginButton.click()
driver.implicitly_wait(5) # 使用浏览器隐式等待5秒
# 此时需要切换到弹出的滑块区域,需要切换frame窗口
driver.switch_to.frame("tcaptcha_iframe_dy")
# 等待滑块验证图片加载后,再做后面的操作
WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.ID, 'slideBg')))
# 获取滑块验证图片下载路径,并下载到本地
bigImage = driver.find_element(By.ID, "slideBg")
s = bigImage.get_attribute("style") # 获取图片的style属性
# 设置能匹配出图片路径的正则表达式
p = 'background-image: url\(\"(.*?)\"\);'
# 进行正则表达式匹配,找出匹配的字符串并截取出来
bigImageSrc = re.findall(p, s, re.S)[0] # re.S表示点号匹配任意字符,包括换行符
print("滑块验证图片下载路径:", bigImageSrc)
# 下载图片至本地
urllib.request.urlretrieve(bigImageSrc, 'bigImage.png')
# 计算缺口图像的x轴位置
dis = get_pos('bigImage.png')
# 获取小滑块元素,并移动它到上面的位置
smallImage = driver.find_element(By.XPATH, '//*[@id="tcOperation"]/div[6]')
# 小滑块到目标区域的移动距离(缺口坐标的水平坐标距离小滑块的水平坐标相减的差)
# 新缺口坐标=原缺口坐标*新画布宽度/原画布宽度
newDis = int(dis*340/672-smallImage.location['x'])
driver.implicitly_wait(5) # 使用浏览器隐式等待5秒
# 按下小滑块按钮不动
ActionChains(driver).click_and_hold(smallImage).perform()
# 移动小滑块,模拟人的操作,一次次移动一点点
i = 0
moved = 0
while moved < newDis:
x = random.randint(3, 10) # 每次移动3到10像素
moved += x
ActionChains(driver).move_by_offset(xoffset=x, yoffset=0).perform()
print("第{}次移动后,位置为{}".format(i, smallImage.location['x']))
i += 1
# 移动完之后,松开鼠标
ActionChains(driver).release().perform()
# 整体等待5秒看结果
time.sleep(5)
finally:
# 关闭浏览器
driver.quit()参考:小飞刀2018《Selenium验证码滑动登录》
转载请注明出处:https://guangzai.blog.csdn.net/article/details/133827764