目录
一、C语言标准和编译器
二、指定初始化
三、宏构造“利器”:语句表达式
四、typeof与container_of宏
五、零长度数组
六、属性声明:section
七、属性声明:aligned
一、C语言标准和编译器
C语言标准的发展过程:
● K&R C.
● ANSI C.
● C99.
● C11.
二、指定初始化
指定初始化结构体成员:
和数组类似,在C语言标准中,初始化结构体变量也要按照固定的顺序,但在GNU C中我们可以通过结构域来指定初始化某个成员。

在程序中,我们定义一个结构体类型student,然后分别定义两个结构体变量stu1和stu2。初始化stu1时,我们采用C语言标准的初始化方式,即按照固定顺序直接初始化。初始化stu2时,我们采用GNU C的初始化方式,通过结构域名.name和.age,就可以给结构体变量的某一个指定成员直接赋值。当结构体的成员很多时,使用第二种初始化方式会更加方便。
Linux内核驱动注册:
在Linux内核驱动中,大量使用GNU C的这种指定初始化方式,通过结构体成员来初始化结构体变量。如在字符驱动程序中,我们经常见到下面这样的初始化。

指定初始化的好处:
如果采用C标准按照固定顺序赋值,当file_operations结构体类型发生变化时,如添加了一个成员、删除了一个成员、调整了成员顺序,那么使用该结构体类型定义变量的大量C文件都需要重新调整初始化顺序,牵一发而动全身。
通过指定初始化方式,就可以避免这个问题。无论file_operations结构体类型如何变化,添加成员也好、删除成员也好、调整成员顺序也好,都不会影响其他文件的使用。
三、宏构造“利器”:语句表达式
什么是表达式、操作符、操作数?
表达式就是由一系列操作符和操作数构成的式子。操作符可以是C语言标准规定的各种算术运算符、逻辑运算符、赋值运算符、比较运算符。操作数可以是一个常量,也可以是一个变量。
语句表达式:
GNU C对C语言标准作了扩展,允许在一个表达式里内嵌语句,允许在表达式内部使用局部变量、for循环和goto跳转语句。这种类型的表达式,我们称为语句表达式。语句表达式的格式如下。
![]()
和一般表达式一样,语句表达式也有自己的值。语句表达式的值为内嵌语句中最后一个表达式的值。
在宏定义中使用语句表达式:请定义一个宏,求两个数的最大值。
合格:
#define MAX(x,y) x > y ? x : y中等:
#define MAX(x,y) (x) > (y) ? (x) : (y)良好:
#define MAX(x,y) ((x) > (y) ? (x) : (y))更良好:
#define MAX(x,y)({ \
int _x = x; \
int _y = y; \
_x > _y ? _x : _y; \
})优秀:
#define MAX(type,x,y)({ \
type _x = x; \
type _y = y; \
_x > _y ? _x : _y; \
})更优秀:
#define MAX(x,y)({ \
typeof(x) _x = (x); \
typeof(y) _y = (y); \
(void) (&_x == &_y); \
_x > _y ? _x : _y; \
})在这个宏定义中,我们使用了typeof关键字来自动获取宏的两个参数类型。比较难理解的是(void)(&x==&y);这句话,看起来很多余,仔细分析一下,你会发现这条语句很有意思。它的作用有两个:一是用来给用户提示一个警告,对于不同类型的指针比较,编译器会发出一个警告,提示两种数据的类型不同。
![]()
二是两个数进行比较运算,运算的结果却没有用到,有些编译器可能会给出一个warning,加一个(void)后,就可以消除这个警告。
四、typeof与container_of宏
typeof关键字:
ANSI C定义了sizeof关键字,用来获取一个变量或数据类型在内存中所占的字节数。GNU C扩展了一个关键字typeof,用来获取一个变量或表达式的类型。
使用typeof可以获取一个变量或表达式的类型。typeof的参数有两种形式:表达式或类型。

在上面的代码中,因为变量i的类型为int,所以typeof(i)就等于int,typeof(i) j=20就相当于int j=20,typeof(int*) a;相当于int*a,f()函数的返回值类型是int,所以typeof(f()) k;就相当于int k;
Linux内核中的container_of宏:

它的主要作用就是,根据结构体某一成员的地址,获取这个结构体的首地址。根据宏定义,我们可以看到,这个宏有三个参数:type为结构体类型,member为结构体内的成员,ptr为结构体内成员member的地址。也就是说,如果我们知道了一个结构体的类型和结构体内某一成员的地址,就可以获得这个结构体的首地址。container_of宏返回的就是这个结构体的首地址。
结构体作为一个复合类型数据,它里面可以有多个成员。当我们定义一个结构体变量时,编译器要给这个变量在内存中分配存储空间。根据每个成员的数据类型和字节对齐方式,编译器会按照结构体中各个成员的顺序,在内存中分配一片连续的空间来存储它们。

在这个程序中,我们定义一个结构体,里面有3个int型数据成员。我们定义一个变量stu,分别打印这个变量stu的地址、各个成员变量的地址,程序运行结果如下。

从运行结果可以看到,结构体中的每个成员变量,从结构体首地址开始依次存放,每个成员变量相对于结构体首地址,都有一个固定偏移。如num相对于结构体首地址偏移了4字节。math的存储地址相对于结构体首地址偏移了8字节。
一个结构体数据类型,在同一个编译环境下,各个成员相对于结构体首地址的偏移是固定不变的。我们可以修改一下上面的程序:当结构体的首地址为0时,结构体中各个成员的地址在数值上等于结构体各成员相对于结构体首地址的偏移。

在上面的程序中,我们没有直接定义结构体变量,而是将数字0通过强制类型转换,转换为一个指向结构体类型为student的常量指针,然后分别打印这个常量指针指向的各成员地址。运行结果如下。

从语法角度来看,container_of宏的实现由一个语句表达式构成。语句表达式的值即最后一个表达式的值。
![]()
最后一句的意义就是,取结构体某个成员member的地址,减去这个成员在结构体type中的偏移,运算结果就是结构体type的首地址。因为语句表达式的值等于最后一个表达式的值,所以这个结果也是整个语句表达式的值,container_of最后会返回这个地址值给宏的调用者。
计算结构体某个成员在结构体内的偏移,内核中定义了offset宏来实现这个功能.
![]()
这个宏有两个参数,一个是结构体类型TYPE,一个是结构体TYPE的成员MEMBER,它使用的技巧和我们上面计算零地址常量指针的偏移是一样的。将0强制转换为一个指向TYPE类型的结构体常量指针,然后通过这个常量指针访问成员,获取成员MEMBER的地址,其大小在数值上等于MEMBER成员在结构体TYPE中的偏移。
结构体的成员数据类型可以是任意数据类型,为了让这个宏兼容各种数据类型,我们定义了一个临时指针变量__mptr,该变量用来存储结构体成员MEMBER的地址,即存储宏中的参数ptr的值。如何获取ptr指针类型呢,可以通过下面的方式。
![]()
宏的参数ptr代表的是一个结构体成员变量MEMBER的地址,所以ptr的类型是一个指向MEMBER数据类型的指针,当我们使用临时指针变量__mptr来存储ptr的值时,必须确保__mptr的指针类型和ptr一样,是一个指向MEMBER类型的指针变量。typeof(((type*)0)->member)表达式使用typeof关键字,用来获取结构体成员MEMBER的数据类型,然后使用该类型,通过typeof(((type*)0)->member)*__mptr这条程序语句,就可以定义一个指向该类型的指针变量了。
在语句表达式的最后,因为返回的是结构体的首地址,所以整个地址还必须强制转换一下,转换为TYPE*,即返回一个指向TYPE结构体类型的指针,所以你会在最后一个表达式中看到一个强制类型转换(TYPE*)。
五、零长度数组
顾名思义,零长度数组就是长度为0的数组。ANSI C标准规定:定义一个数组时,数组的长度必须是一个常数,即数组的长度在编译的时候是确定的。在ANSI C中定义一个数组的方法如下。
![]()
数组的长度在编译时是未确定的,在程序运行的时候才确定,甚至可以由用户指定大小。
指针与零长度数组:
数组名在作为参数传递时,传递的确实是一个地址,但数组名绝不是指针,两者不是同一个东西。数组名用来表征一块连续内存空间的地址,而指针是一个变量,编译器要给它单独分配一个内存空间,用来存放它指向的变量的地址。我们看下面的程序。

运行结果如下。

对于一个指针变量,编译器要为这个指针变量单独分配一个存储空间,然后在这个存储空间上存放另一个变量的地址,我们就说这个指针指向这个变量。而对于数组名,编译器不会再给它分配一个单独的存储空间,它仅仅是一个符号,和函数名一样,用来表示一个地址。如下代码:
#include <stdio.h>
int array1[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9};
int array2[0];
int *p = &array1[5];
int main(void)
{
return 0;
}在这个程序中,我们分别定义一个普通数组、一个零长度数组和一个指针变量。其中这个指针变量p的值为array1[5]这个数组元素的地址,也就是说,指针p指向arraay1[5]。我们接着对这个程序使用ARM交叉编译器进行编译,并进行反汇编。

从反汇编生成的汇编代码中,我们找到array1和指针变量p的汇编代码。
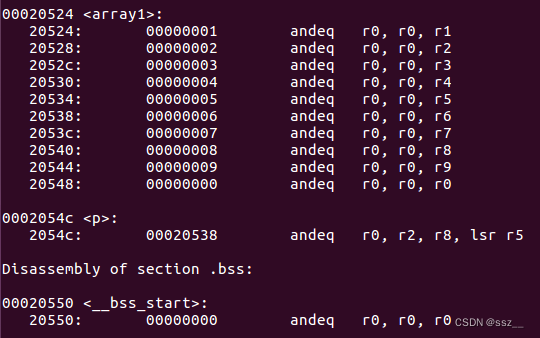
从汇编代码中,可以看到,对于长度为10的数组array1[10],编译器给它分配了从0x20524~0x20548共40字节的存储空间,但并没有给数组名array1单独分配存储空间,数组名array1仅仅表示这40个连续存储空间的首地址,即数组元素array1[0]的地址。对于指针变量p,编译器给它分配了0x20538这个存储空间,在这个存储空间上存储的是数组元素array1[5]的地址:0x20538。
而对于array2[0]这个零长度数组,编译器并没有为它分配存储空间,此时的array2仅仅是一个符号,用来表示内存中的某个地址,我们可以通过查看可执行文件a.out的符号表来找到这个地址值。
readelf -s a.out
从符号表可以看到,array2的地址为0x21054,在BSS段的后面。array2符号表示的默认地址是一片未使用的内存空间,仅此而已,编译器绝不会单独再给其分配一个存储空间来存储数组名。
数组名和指针并不是一回事,数组名虽然在作为函数参数时,可以当作一个地址使用,但是两者不能画等号。
六、属性声明:section
GNU C编译器扩展关键字:__attribute__
__attribute__的使用非常简单,当我们定义一个函数、变量或类型时,直接在它们名字旁边添加下面的属性声明即可。
![]()
使用__atttribute__这个属性声明,就相当于告诉编译器:按照我们指定的边界对齐方式去给这个变量分配存储空间。

有些属性可能还有自己的参数。如aligned(8)表示这个变量按8字节地址对齐,属性的参数也要使用小括号括起来,如果属性的参数是一个字符串,则小括号里的参数还要用双引号引起来。
我们可以使用__attribute__来声明一个section属性,section属性的主要作用是:在程序编译时,将一个函数或变量放到指定的段,即放到指定的section中。
一个可执行文件主要由代码段、数据段、BSS段构成。代码段主要存放编译生成的可执行指令代码,数据段和BSS段用来存放全局变量、未初始化的全局变量。代码段、数据段和BSS段构成了一个可执行文件的主要部分。
除了这三个段,可执行文件中还包含其他一些段。用编译器的专业术语讲,还包含其他一些section,如只读数据段、符号表等。我们可以使用下面的readelf命令,去查看一个可执行文件中各个section的信息。
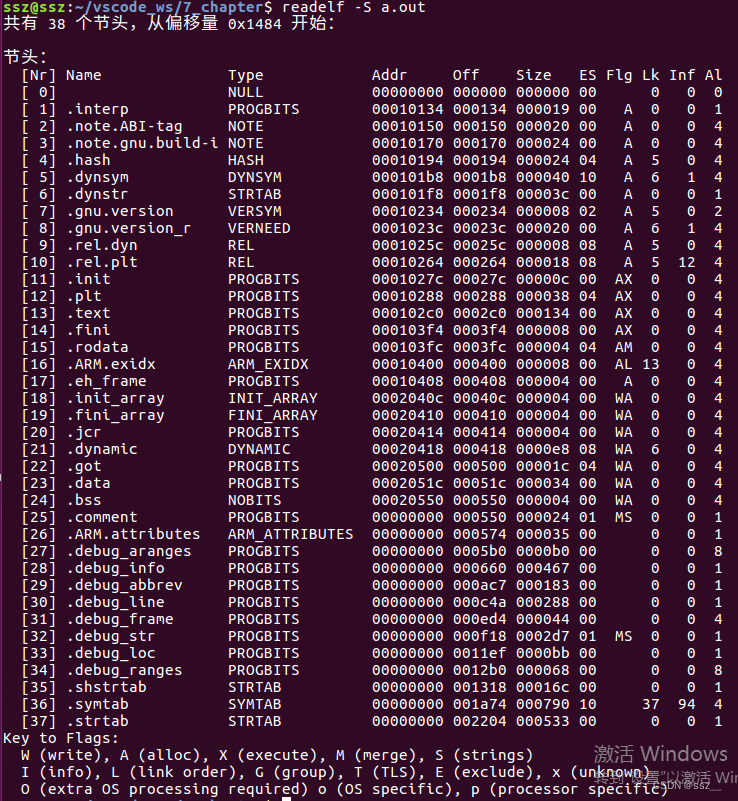

例如下面的程序,我们分别定义一个函数、一个全局变量和一个未初始化的全局变量。
#include <stdio.h>
int global_val = 8;
int global_val;
void print_star(void)
{
printf("****\n");
}
int main(void)
{
print_star();
return 0;
}
readelf是一个用于查看和分析可执行文件、共享库和目标文件的工具。它提供了多种选项来显示不同类型的信息。其中,-s选项和-S选项用于显示不同的符号表和节表信息。
-s选项:-s选项用于显示符号表(Symbol Table)的信息。符号表是一个记录了程序中各种符号(如函数、变量、常量等)的表格,它包含了符号的名称、类型、大小、地址等信息。使用-s选项可以查看符号表中的符号列表以及相关的属性。示例命令:
readelf -s <file>
-S选项:-S选项用于显示节表(Section Table)的信息。节表是一个记录了程序各个节(Section)的表格,它包含了每个节的名称、类型、大小、偏移量等信息。节表描述了程序的不同部分,如代码段、数据段、BSS段、符号表等。示例命令:
readelf -S <file>总结:
-s选项用于显示符号表的信息,包括符号的名称、类型、大小、地址等。-S选项用于显示节表的信息,包括节的名称、类型、大小、偏移量等。
查看可执行文件的符号表信息:
![]()
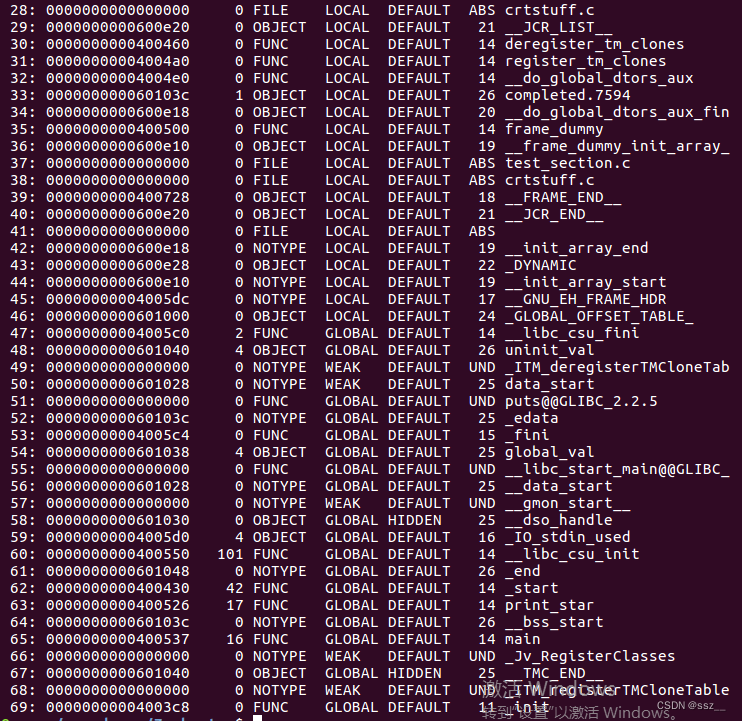
对应的section header表信息如下。
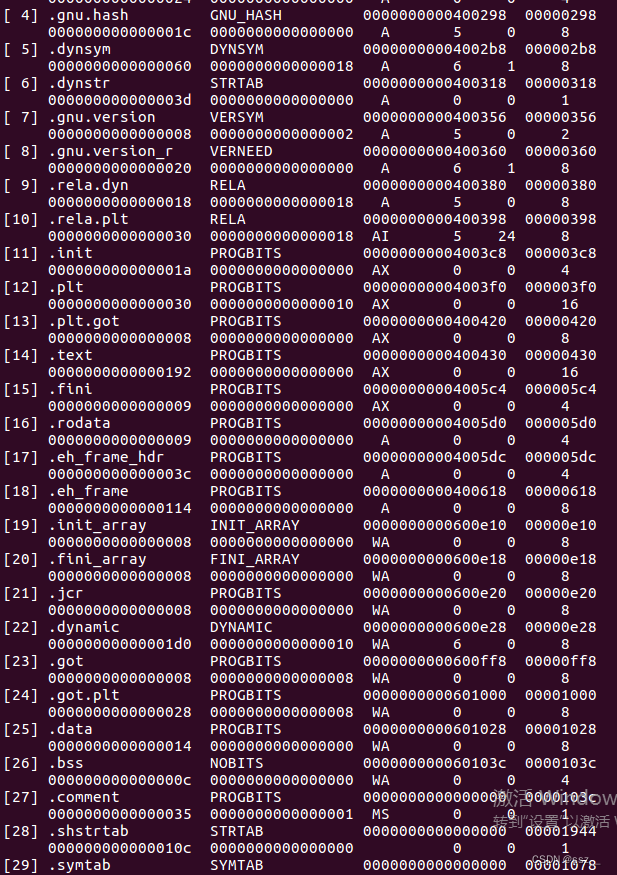
通过符号表和section header表信息,我们可以看到,函数print_star(400526)被放在可执行文件中的.text section(400430),即代码段;初始化的全局变量global_val(601038)被放在了a.out的.data section(601028),即数据段;而未初始化的全局变量uninit_val(601040)则被放在了.bss section(60103c),即BSS段。
编译器在编译程序时,以源文件为单位,将一个个源文件编译生成一个个目标文件。在编译过程中,编译器都会按照这个默认规则,将函数、变量分别放在不同的section中,最后将各个section组成一个目标文件。编译过程结束后,链接器会将各个目标文件组装合并、重定位,生成一个可执行文件。
在GNU C中,我们可以通过__attribute__的section属性,显式指定一个函数或变量,在编译时放到指定的section里面。通过上面的程序我们知道,未初始化的全局变量默认是放在.bss section中的,即默认放在BSS段中。现在我们就可以通过section属性声明,把这个未初始化的全局变量放到数据段.data中。

![]()
![]()
通过readelf命令查看符号表,我们可以看到,uninit_val(601034)这个未初始化的全局变量,通过__attribute__((section(".data")))属性声明,就和初始化的全局变量一样,被编译器放在了数据段.data(601020)中。
U-boot镜像自复制分析:
有了section这个属性声明,我们就可以试着分析:U-boot在启动过程中,是如何将自身代码加载的RAM中的。U-boot的用途主要是加载Linux内核镜像到内存,给内核传递启动参数,然后引导Linux操作系统启动。U-boot一般存储在NOR Flash或NAND Flash上。无论从NOR Flash还是从NAND Flash启动,U-boot其本身在启动过程中,都会从Flash存储介质上加载自身代码到内存,然后进行重定位,跳到内存RAM中去执行。
char __image_copy_start[0] __attribute__((section(".__image_copy_start")));
char __image_copy_end[0] __attribute__((section(".__image_copy_end")));这两行代码定义在U-boot-2016.09中的arch/arm/lib/section.c文件中。在其他版本的U-boot中可能路径不同,这两行代码的作用是分别定义一个零长度数组,并指示编译器要分别放在.__image_copy_start和.__image_copy_end这两个section中。
链接器在链接各个目标文件时,会按照链接脚本里各个section的排列顺序,将各个section组装成一个可执行文件。U-boot的链接脚本Uboot.lds在U-boot源码的根目录下面。
OUTPUT_FORMAT("elf32-littlearm", "elf32-littlearm", "elf32-littlearm")
OUTPUT_ARCH(arm)
ENTRY(_start)
SECTIONS
{
. = 0x00000000;
. = ALIGN(4);
.text :
{
*(.__image_copy_start)
*(.vectors)
arch/arm/cpu/armv7/start.o (.text*)
*(.text*)
}
. = ALIGN(4);
.rodata : { *(SORT_BY_ALIGNMENT(SORT_BY_NAME(.rodata*))) }
. = ALIGN(4);
.data : {
*(.data*)
}
. = ALIGN(4);
. = .;
. = ALIGN(4);
.u_boot_list : {
KEEP(*(SORT(.u_boot_list*)));
}
. = ALIGN(4);
.image_copy_end :
{
*(.__image_copy_end)
}
.rel_dyn_start :
{
*(.__rel_dyn_start)
}
.rel.dyn : {
*(.rel*)
}
.rel_dyn_end :
{
*(.__rel_dyn_end)
}
.end :
{
*(.__end)
}
_image_binary_end = .;
. = ALIGN(4096);
.mmutable : {
*(.mmutable)
}
.bss_start __rel_dyn_start (OVERLAY) : {
KEEP(*(.__bss_start));
__bss_base = .;
}
.bss __bss_base (OVERLAY) : {
*(.bss*)
. = ALIGN(4);
__bss_limit = .;
}
.bss_end __bss_limit (OVERLAY) : {
KEEP(*(.__bss_end));
}
.dynsym _image_binary_end : { *(.dynsym) }
.dynbss : { *(.dynbss) }
.dynstr : { *(.dynstr*) }
.dynamic : { *(.dynamic*) }
.plt : { *(.plt*) }
.interp : { *(.interp*) }
.gnu.hash : { *(.gnu.hash) }
.gnu : { *(.gnu*) }
.ARM.exidx : { *(.ARM.exidx*) }
.gnu.linkonce.armexidx : { *(.gnu.linkonce.armexidx.*) }
}通过链接脚本我们可以看到,__image_copy_start和__image_copy_end这两个section,在链接的时候分别放在了代码段.text的前面、数据段.data的后面,作为U-boot复制自身代码的起始地址和结束地址。而在这两个section中,我们除了放两个零长度数组,并没有放其他变量。
在arch/arm/lib/relocate.S中,ENTRY(relocate_code)汇编代码主要完成代码复制的功能。
ENTRY(relocate_code)
ldr r1, =__image_copy_start /* r1 <- SRC &__image_copy_start */
subs r4, r0, r1 /* r4 <- relocation offset */
beq relocate_done /* skip relocation */
ldr r2, =__image_copy_end /* r2 <- SRC &__image_copy_end */
copy_loop:
ldmia r1!, {r10-r11} /* copy from source address [r1] */
stmia r0!, {r10-r11} /* copy to target address [r0] */
cmp r1, r2 /* until source end address [r2] */
blo copy_loop在这段汇编代码中,寄存器R1、R2分别表示要复制镜像的起始地址和结束地址,R0表示要复制到RAM中的地址,R4存放的是源地址和目的地址之间的偏移,在后面重定位过程中会用到这个偏移值。在汇编代码中:
ldr r1, =__image_copy_start通过ARM的LDR伪指令,直接获取要复制镜像的首地址,并保存在R1寄存器中。数组名本身其实就代表一个地址,通过这种方式,Uboot在嵌入式启动的初始阶段,就完成了自身代码的复制工作:从Flash复制自身镜像到内存中,然后进行重定位,最后跳到内存中执行。
七、属性声明:aligned
地址对齐:aligned
GNU C通过__attribute__来声明aligned和packed属性,指定一个变量或类型的对齐方式。这两个属性用来告诉编译器:在给变量分配存储空间时,要按指定的地址对齐方式给变量分配地址。如果你想定义一个变量,在内存中以8字节地址对齐,就可以这样定义。
![]()
通过aligned属性,我们可以显式地指定变量a在内存中的地址对齐方式。aligned有一个参数,表示要按几字节对齐,使用时要注意,地址对齐的字节数必须是2的幂次方,否则编译就会出错。
编译器一定会按照aligned指定的方式对齐吗?
通过aligned属性,我们可以显式指定一个变量的对齐方式,编译器就一定会按照我们指定的大小对齐吗?非也!我们通过这个属性声明,其实只是建议编译器按照这种大小地址对齐,但不能超过编译器允许的最大值。一个编译器,对每个基本数据类型都有默认的最大边界对齐字节数。如果超过了,则编译器只能按照它规定的最大对齐字节数来给变量分配地址。

在这个程序中,我们指定char型的变量c2以16字节对齐,编译运行结果如下。

我们可以看到,编译器给c2分配的地址是按16字节地址对齐的,如果我们继续修改c2变量按32字节对齐,你会发现程序的运行结果不再有变化,编译器仍然分配一个16字节对齐的地址,这是因为32字节的对齐方式已经超过编译器允许的最大值了。
属性声明:packed
aligned属性一般用来增大变量的地址对齐,元素之间因为地址对齐会造成一定的内存空洞。而packed属性则与之相反,一般用来减少地址对齐,指定变量或类型使用最可能小的地址对齐方式。

在上面的程序中,我们将结构体的成员b和c使用packed属性声明,就是告诉编译器,尽量使用最可能小的地址对齐给它们分配地址,尽可能地减少内存空洞。程序的运行结果如下。

通过结果我们看到,结构体内各个成员地址的分配,使用最小1字节的对齐方式,没有任何内存空间的浪费,导致整个结构体的大小只有7字节。
这个特性在底层驱动开发中还是非常有用的。例如,你想定义一个结构体,封装一个IP控制器的各种寄存器,在ARM芯片中,每一个控制器的寄存器地址空间一般都是连续存在的。如果考虑数据对齐,则结构体内就可能有空洞,就和实际连续的寄存器地址不一致。使用packed可以避免这个问题,结构体的每个成员都紧挨着,依次分配存储地址,这样就避免了各个成员因地址对齐而造成的内存空洞。

我们也可以对整个结构体添加packed属性,这和分别对每个成员添加packed属性效果是一样的。修改结构体后,重新编译程序,运行结果和上面程序的运行结果相同:结构体的大小为7,结构体内各成员地址相同。







![COM编程入门Part Ⅱ - 深入理解COM服务器[译]](https://img-blog.csdnimg.cn/img_convert/6707b432584b9488acb679a5ff03580b.gif)
![[入门一]C# webApi创建、与发布、部署、api调用](https://img-blog.csdnimg.cn/611709403ea74961a7ccd5e371c6a6cc.png)