高并发内存池项目第一讲
- 一、高并内存池概念
- 二、项目介绍
- 三、项目细节
- 四.哈系统结构设计
一、高并内存池概念
内存池(Memory Pool) 是一种动态内存分配与管理技术。 通常情况下,程序员习惯直接使用 new、delete、malloc、free 等API申请分配和释放内存,这样导致的后果是:当程序长时间运行时,由于所申请内存块的大小不定,频繁使用时会造成大量的内存碎片从而降低程序和操作系统的性能。内存池则是在真正使用内存之前,先申请分配一大块内存(内存池)留作备用,当程序员申请内存时,从池中取出一块动态分配,当程序员释放内存时,将释放的内存再放入池内,再次申请池可以 再取出来使用,并尽量与周边的空闲内存块合并。若内存池不够时,则自动扩大内存池,从操作系统中申请更大的内存池。
- 由于现在硬件条件已经很成熟,大多数运行环境都是多核的,为了提高效率,则高并发这一情况应运而生,对于高并发内存池,则是基于多线程并发申请使用的一个内存池称为高并发内存池。
二、项目介绍
本项目参考了谷歌 tcmalloc 设计模式,设计实现了高并发的内存池。基于 win10 环境 VS2013,采用 C++进行编程,池化技术、多线程、TLS、单例模式、互斥锁、链表、哈希等数据结构。该项目利用了 thread cache、central、cache、page cache 三级缓存结构,基于多线程申请释放内存的场景,最大程度提高了效率,解决了绝大部分内存碎片问题。

三、项目细节
(一)项目设计目标
现代很多的开发环境都是多核多线程,在申请内存的场景下,必然存在激烈的锁竞争问题。所以这次我们实现的内存池需要考虑以下几方面的问题。
- 内存碎片问题。
- 性能问题。
- 多核多线程环境下,锁竞争问题。

(二)项目结构
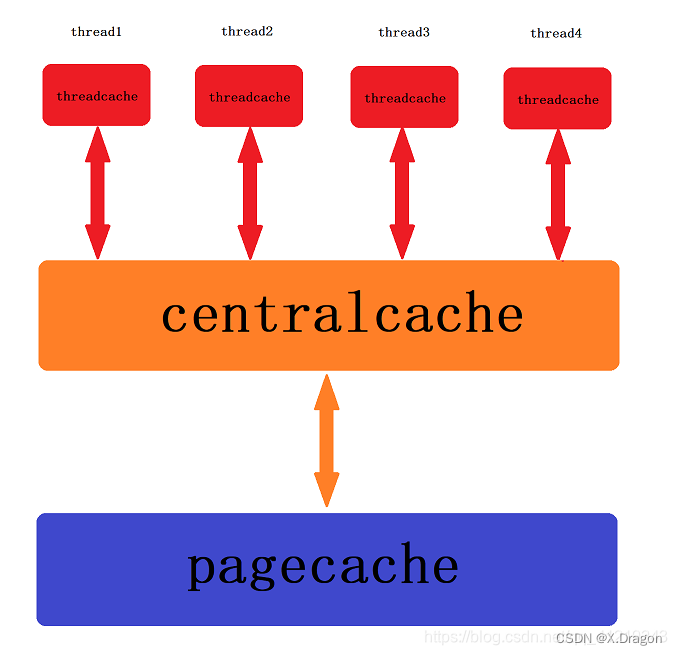
concurrent memory pool主要由线程缓存(threadcache)、中心缓存(centralcache)、页缓存(pagecache)3个部分构成,如下图
四.哈系统结构设计
-
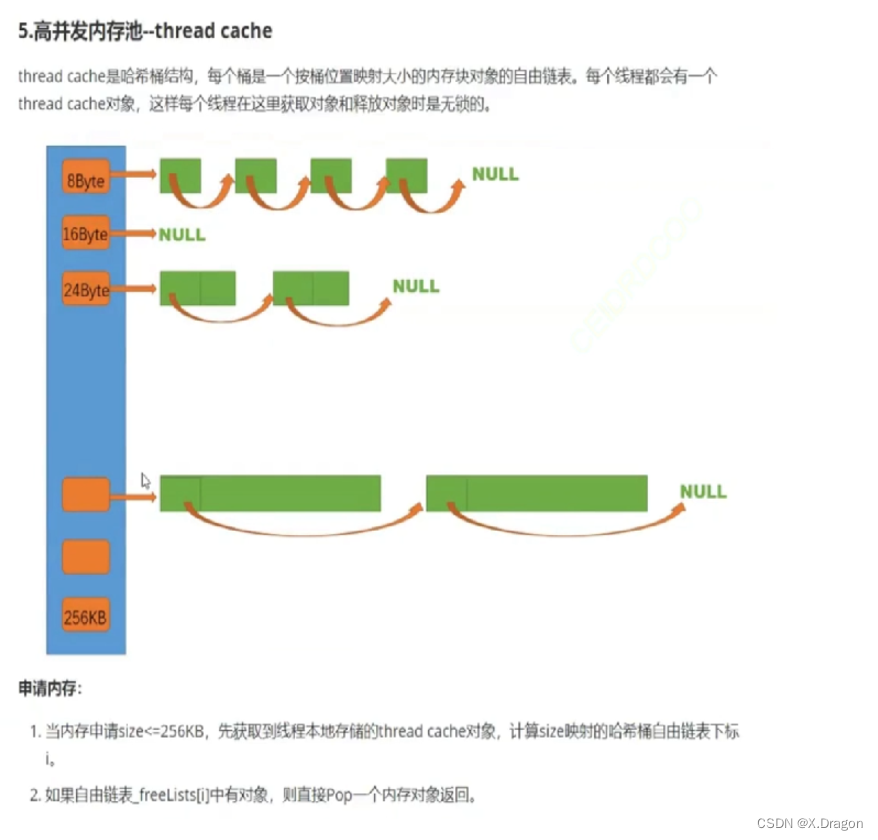
自由链表结构:
-
内存对齐规则
这是目前比较优化的算法 内存最多浪费在10%左右
/*
* [1,128] 8byte对齐 freelist[0,16)
[128 + 1, 1024] 16byte对齐 freelist[16, 72)
[1024 + 1, 8 * 1024] 128byte对齐 freelist[72, 128)
[8 * 1024 + 1, 64 * 1024] 1024byte对齐 freelist[128, 184)
[64 * 1024 + 1, 256 * 1024] 8 * 1024byte对齐 freelist[184, 208)
*/
-
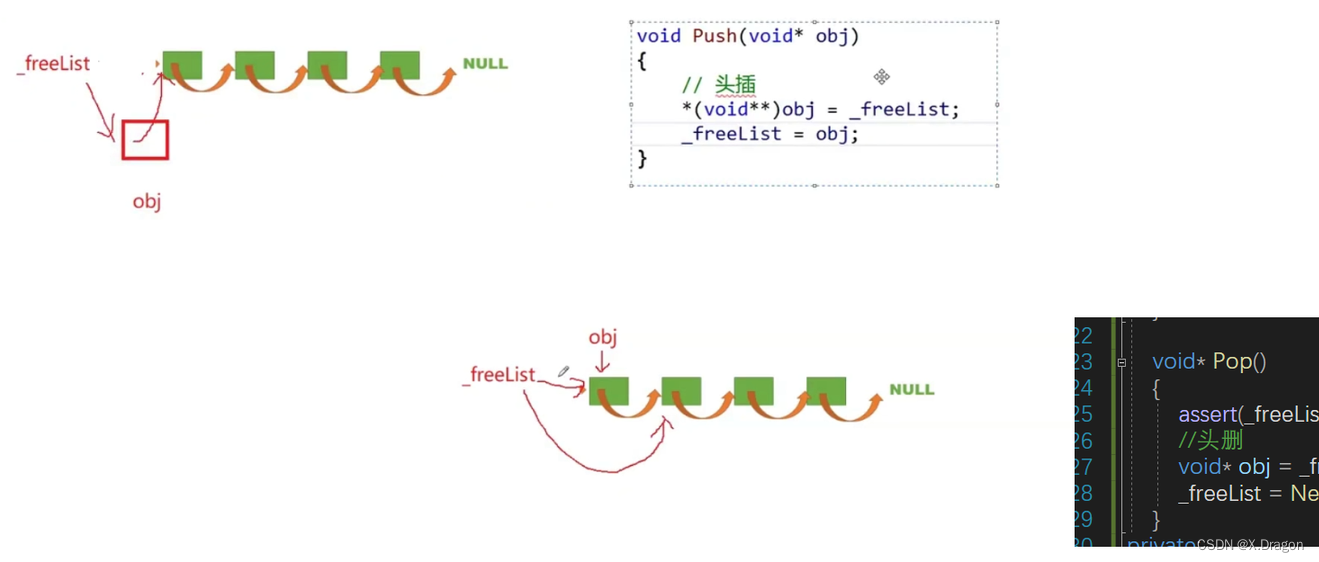
头删和头插结构
-
代码:
#pragma once
#include<vector>
#include<iostream>
#include<time.h>
#include<assert.h>
static const size_t MAX_BYTES = 1024 * 256;//设置最大可以申请的内存数
void*& NextObj(void* obj)
{
return *(void**)obj;//取到这块内存的前4或8字节的位置 存放freeList指针
}
//管理切分好的小对象内存块
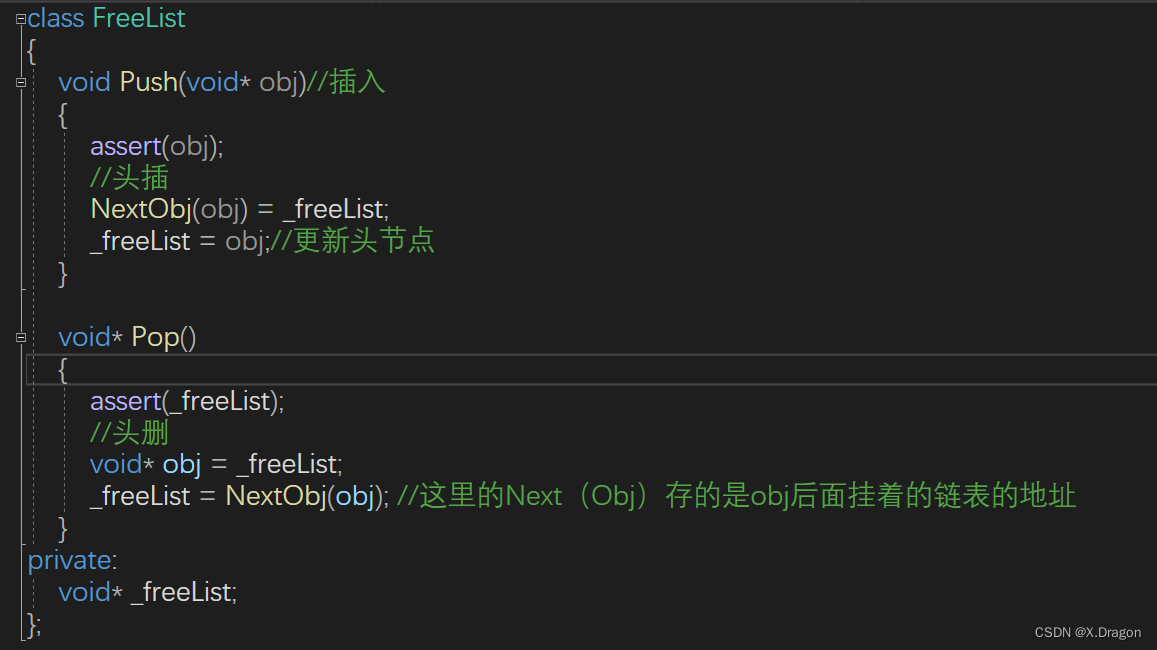
class FreeList
{
void Push(void* obj)//插入
{
assert(obj);
//头插
NextObj(obj) = _freeList;
_freeList = obj;//更新头节点
}
void* Pop()
{
assert(_freeList);
//头删
void* obj = _freeList;
_freeList = NextObj(obj); //这里的Next(Obj)存的是obj后面挂着的链表的地址
}
private:
void* _freeList;
};
//计算对象大小的对齐规则
class SizeClass
{
//优化算法:
//整体控制在最多10%左右的内碎片浪费// [1,128]
/*
* [1,128] 8byte对齐 freelist[0,16)
[128 + 1, 1024] 16byte对齐 freelist[16, 72)
[1024 + 1, 8 * 1024] 128byte对齐 freelist[72, 128)
[8 * 1024 + 1, 64 * 1024] 1024byte对齐 freelist[128, 184)
[64 * 1024 + 1, 256 * 1024] 8 * 1024byte对齐 freelist[184, 208)
*/
//内联函数:调用频繁,因此写成内联函数
static inline size_t _RoundUp(size_t size, size_t AlignNum)
{
size_t AlignSize = 0;
if (size % AlignNum == 0) //所申请的内存数刚好和对齐数整除
{
AlignSize = size;
}
else
{
AlignSize = ((size / AlignNum + 1) * AlignNum); //对齐 假设size=7 alignNum=8,这里就是返回8
}
return AlignSize;
}
static inline size_t RoundUp(size_t size) //对齐函数
{
if (size <= 128)
{
return _RoundUp(size, 8);
}
else if (size <= 1024)
{
return _RoundUp(size, 16);
}
else if (size <= 8 * 1024)
{
return _RoundUp(size, 128);
}
else if (size <= 64 * 1024)
{
return _RoundUp(size, 1024);
}
else if (size <= 256 * 1024)
{
return _RoundUp(size, 8 * 1024);
}
else
{
std::cout << "申请的内存数非法" << std::endl;
assert(false);
}
}
static inline size_t _Index(size_t bytes, size_t align_shift)
{
return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;
}
//计算映射的哪一个自由链表桶中
size_t Index(size_t bytes)
{
assert(bytes <= MAX_BYTES);
static int group_array[4] = { 16, 56, 56, 56 };
if (bytes <= 128)
{
return _Index(bytes, 3);
}
else if (bytes <= 1024)
{
return _Index(bytes - 128, 4) + group_array[0];
}
else if (bytes <= 8 * 1024)
{
return _Index(bytes - 1024, 7) + group_array[0] + group_array[1];
}
else if (bytes <= 64 * 1024)
{
return _Index(bytes - 8 * 1024, 10) + group_array[0] + group_array[1] + group_array[2];
}
else if (bytes <= 256 * 1024)
{
return _Index(bytes - 64 * 1024, 13) + group_array[0] + group_array[1] + group_array[2] + group_array[3];
}
else
{
assert(false);
return -1;
}
}
};
持续更新~
创作不易,点赞支持一下~