C语言程序编译过程
多个源文件生成一个可执行文件的过程
预处理阶段主要是将带 # 号的类似于 #include #define #ifdef等进行处理替换
gcc -S
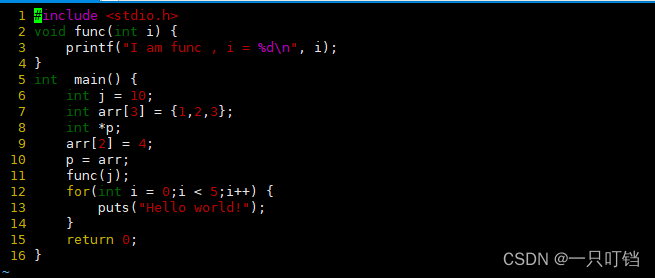
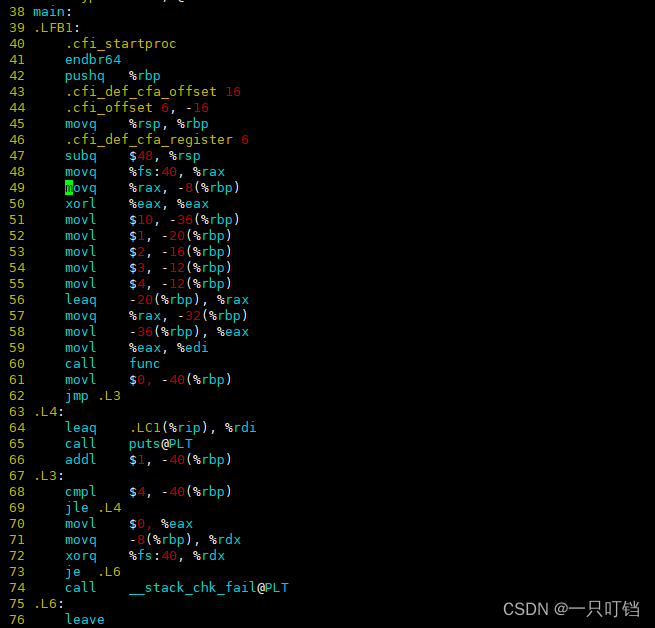
下面讲解C语言源代码编译成汇编语言之后,之间的对应情况
源代码
使用gcc -S test15.c -o test15.s指令让源代码进行编译
其中gcc -S是表示生成汇编代码文件-o test5.s是指定生成的汇编文件的文件名
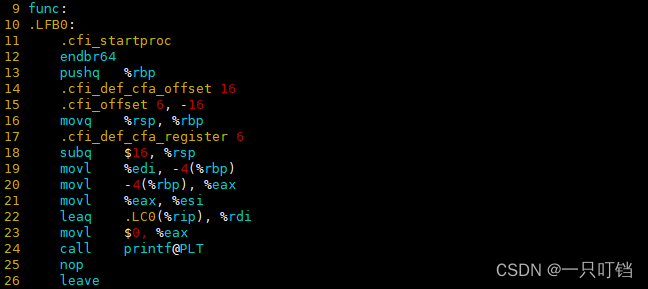
main函数
func函数
总结:
(1)调用一个函数首先是要使用 push 然后 pop ,调用一个函数是用call,调用完之后要用ret,拷贝命令是mov, 加的命令是add ,减的命令是sub, lea是取地址,xor异或,关于跳转的 jmp , je, jlem,每个汇编指令都会有一个后缀,q(8字节)或者 l(4字节)
(2)所有变量,所有数组元素,*p在汇编语言中都是一样的,都是变成地址 + 长度
(3)循环 for , while , 和goto 本质是一样的
(4)函数调用,每个函数的栈帧都是独立的,传递参数值传递
汇编(assembler)
将 .s的汇编文件生成目标文件
as test.s -o test.o
这条指令就可以帮我们将汇编文件生成目标文件,但是此时的目标文件还不能执行,还需要经过链接
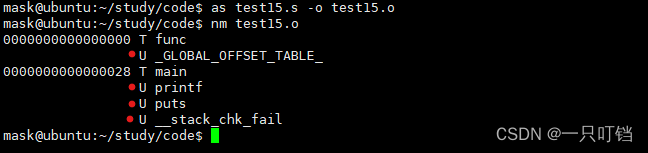
然后可以通过nm指令查看是否有未连接的函数
nm test.o
我们可以看到途中红点标注的显示U的函数表示我们还不知道其地址是多少,所以如果直接运行的话就会找不到这些函数,所以就不能直接运行
gcc -c test.c -o test.o指令可以直接从*.c文件直接生成*.o文件
汇编命令可以用objdump -d test.o命令执行反编译,直接将汇编文件转为*.c文件
链接所做的事情,把调用函数的名字转换成地址
可以使用 ld命令进行链接,但是我们一般不会直接使用ld命令进行连接,因为我们使用ld命令进行连接二进制的文件,可能里面又会调用其它的文件,这样给我们进行连接就提高难度,因此一般都是用gcc命令去间接调用

函数/全局变量 定义0次或者超过2次会报链接错误
缺了main函数也会报链接错误
如果编译器提示第几行出错,那就是编译错误
如果编译器找不到第几行出错,那就是链接错误
报错信息里面出现ld时也是链接错误
执行可执行程序
执行可执行程序一定要加 ./ 这是为了避免和内置命令发生冲突
库文件
库文件(*.o-->*.a/*.so)也被称为轮子,公用工具;其本质就是特殊的*.o文件,他人写好的公开发行的
静态库和动态库
轮子打包到产品中,静态库
轮子在运行时加入到产品中,动态库
特点:静态路的大小更大,动态库更小;部署难度,静态库容易,动态库难;升级静态库难,动态库容易
生成静态库


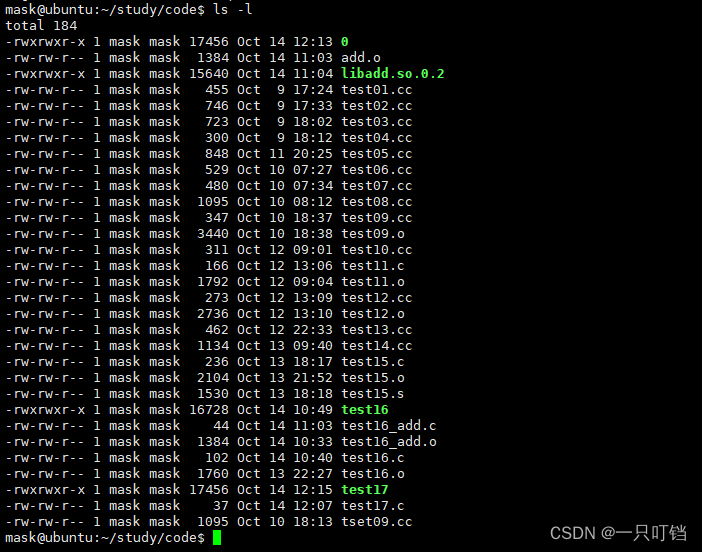
我们这样单独运行某个文件都是不能成功运行的,但是我们将两个文件在一进行编译就可以成功运行

生成静态库的第一个不步骤
(1)生成目标文件
gcc -c test16_add.c -o test16_add.o
test16_add.c方法源文件
(2)打包成静态 库文件
ar crsv myAdd.a test16_add.o
myAdd.a库名字
(3)移动到系统搜索目录下/usr/lib
sudo cp myAdd.a /usr/lib
(4)链接的时候加上 -lmyAdd
如果不加-l那么是默认链接目标文件,如果有了-l会链接我们的库文件

动态库进行链接
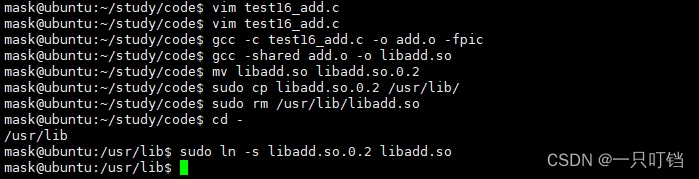
生成动态库
(1)编译成目标文件
动态库是加载在栈和堆中件的共享库映射区
生成的地址都是相对地址 ---->生成的代买为位置无关代码
gcc -c test16_add.c -o add.o -fpic在编译的时候加上-fpic就可以实现动态链接
(2)打包,生成动态库文件
gcc -shared add.o -o libadd.so
(3)移动到系统库目录
sudo cp myAdd.so /usr/lib
(4)链接加上-myAdd
gcc test.o -o test -myAdd
(5)编译之后可以通过ldd test查看动态链接库信息



动态库的运行会受到系统库的影响
如果我们将打包好放在系统目录里面的动态库删除,在重新更改动态库源文件,在进动态库生成,在放入系统目录,只要我们动态库的名字不变,我们直接运行程序的目标文件也可以成功运行,并且运行结果会按照更新的动态库运行
软链接 符号链接
当我们进行动态库更新时,往往会出现我们在更新完动态库之后,程序整体运行会出BUG,这时候我们希望程序能够进行回滚,回到之前没有出BUG的动态库版本,但是我们链接的动态库名称都是一样的,如果我们给新的动态库使用新的名称然后重新链接这样会很麻烦,那么我们可以怎么做呢
使用软链接可以完美解决这个问题,一般我们在更新动态库的时候我们都会在动态库*.so文件末尾加上更新的版本号,这时我们可以将系统库中 myAdd文件用软链接的方式链接到新导入的动态库上,如果出现BUG,我们只需要修改myAdd文件的软链接指向,便能成功切换回原动态库
(1)将刚刚创建的动态库重新改名为其动态库名+版本号,此时在运行程序,程序找不到库
(2)通过软链接指令将刚刚改名的动态库链接到 libadd.so文件
sudo ln s libadd.so.0.1 libadd.so
这是在运行原目标文件又可以正常运行
(3)修改动态库源文件,重新生成动态库,将动态库命名为动态库名称+版本号,将动态库移动到系统库,删除原先的动态库 libadd.so的软链接 ,重新建立新链接指向新的动态库
(4)重新运行目标文件,目标文件按照更新的动态库执行结果返回
如果我们需要回滚,回到之前的动态库,那么在进行重新软链接就可以实现回滚






gcc的其它选项
-D在源文件中添加宏定义
gcc test.c -D DEBUG添加#define DEBUG
-I增加头文件搜索目录
gcc src/test.c I include/test.c源文件搜索头文件不仅仅是在当前目录下进行搜索,还会在include目录下进行搜索
-O编译优化
是由编译器作者实现的,这个指令会更具一定能的规则区修改指令执行的顺序和内存的位置
(1)结果不会变
(2)指令数量变少,执行速度变快
(3)但是会影响程序员进行调试,因为代码顺序会改变,因此调试就不会按照我们想象的步骤执行,因此给调试增加了难度
优化指令分0,1,2,3级,0一般就是不优化,1一般是普通产品进行优化,2一般是开源项目优化,3更深的优化
优化越大,C与汇编的对应就乱了
GDB
可以启动程序打断点进行单步调试,除了可以单步调试,如果当程序执行时报错,还会返回类似于黑匣子的记录信息,可以让我们更好的定位错误
GDB原理:
(1)不要开代码优化 -O 0就是不开优化
(2)补充调试信息添加 -g
gcc -c test.c -o test.o -o0 -g
gcc test.o -o test
或者一步到位gcc test.c -o test -o0 -g
(3)gdb test调试程序
GDB命令
list / l [文件名:][行号][函数]默认每次展示10行代码,也可以直接用 l 代替 list
run / r运行程序
break / b [行号][函数] 打断点
continue /c 继续运行,运行至下一个断点位置
step / s 单步调试,系统调用函数例如printf也会跳进函数一步一步执行,VS的F11
next / n 单步调试,不会跳进系统调用函数VS的F10
finish 跳出本次函数调用
info break / ib 查看断点信息
delete [编号] 删除断点
delete 删除所有断点 (不加参数删除所有,记得再输一个Y)
ignore [num] [count] 忽略num断点count次(对于循环有效)
print / p 表达式 可以查看数据,或者地址等信息
display 表达式 可以自动监视某个值或者表达式的结果,不用手动进行输出
info desplay 查看监视信息
undisplay 编号 删除指定编号的display
在gdb中查看内存
x/3tw arr
查看arr数组 查看3个单位,以字节形式查看 每次查看4字节


检查奔溃的程序
”黑匣子“ ----->core文件(记录程序奔溃时刻内存的堆栈情况)
(1)编译加上 -g -o0
gcc
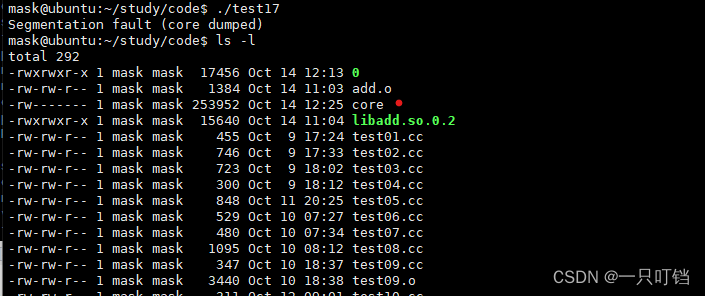
报错出现段错误,并且告诉我们core文件已经保存
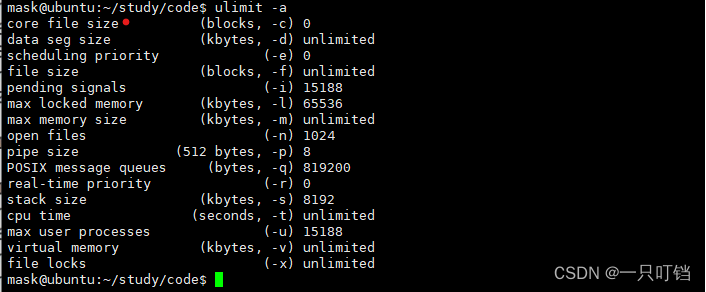
但是当我们查看文件内目录发现没有发现相应的core文件,这是因为系统会默认限制core文件的大小
我们可以看到系统将core的文件限制改为0,同时在这个文件中我们也可以看到其他文件的文件大小限制
ulimit -c unlimited执行指令将core文件大小限制改为无限大,这样的设置只能影响到当前终端,下次启动又会变成0
更改限制大小之后一般再进行编译一般都是可以看到core文件,如果看不到core文件执行一下操作
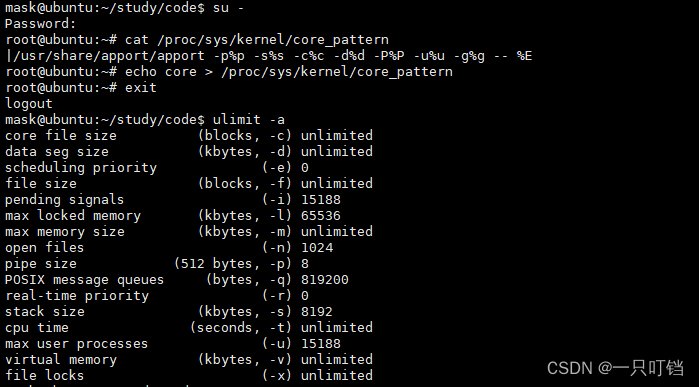
更改限制还看不到core文件操作:
进入root账户向文件/proc/sys/kernel/core_pattern中添加core
退出root账户,并且查看系统对core文件的限制
然后在运行
此刻就可容易看到core文件
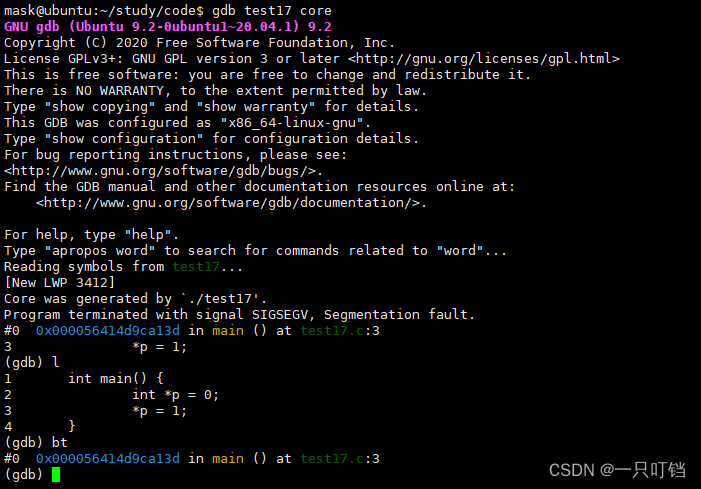
gdb test17 core查看core文件
在gdb中bt指令查看堆栈情况(以上错误空指针错误)

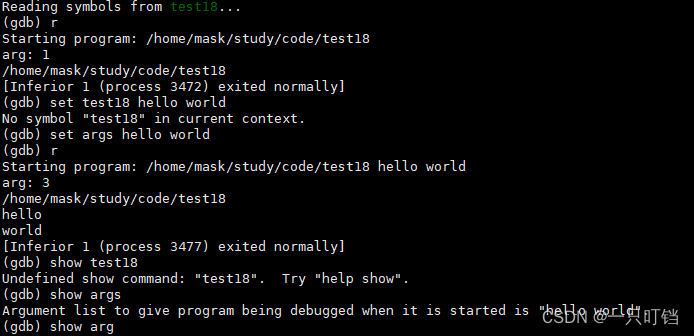
命令行参数(传递给main函数的参数)
没有参数只有main函数本身

有参数传递

gdb添加命令行参数