Web和HTTP
一个新型应用即万维网(World Wide Web)Web。
HTTP概况
Web的应用层协议是超文本传输协议(HTPP),它是Web的核心。
HTTP由两个程序实现:一个用户程序和一个服务器程序。
Web页面(Web Page)(也叫文档)是由对象组成的。
一个对象只是一个文件,诸如一个HTML文件、一个JPG图形等等。
并且它们可以通过一个URL地址寻址。
多数Web页面含有一个HTML基本文件以及几个引用对象。
每个URL地址由两部分组成:存放对象的服务器主机名和对象的路径名。
例如,URL地址:http://www.someSchool.edu/someDepartment/picture.gif,其中的www.someSchool.edu就是主机名,/somDepartment/picture.gif就是路径名。
因为Web浏览器实现了HTTP的客户端,Web服务器实现了HTTP的服务器端,用于存储Web对象。
HTTP定义了Web客户向Web服务器请求Web页面的方式,以及服务器向客户发送Web页面的方式。

HTTP使用TCP作为它的支撑运输协议(而不是在UDP上运行)。
客户端的套接字接口是客户进程与TCP连接之间的门,在服务器端的套接字接口则是服务器进程与TCP连接之间的门。
客户向它的套接字接口发送HTTP请求报文并从套接字接口接受HTTP响应报文。
服务器也同理。
因此HTTP协议不用担心数据丢失,也不关注TCP从网络的数据丢失和乱序故障中恢复的细节,那是TCP的工作。
HTTP也是一个无状态协议,因为HTTP服务器并不保存关于客户的任何信息,因此某个客户短短几秒内两次请求同一个对象,服务器不会因为刚刚为客户端提供了一次对象就不做出反应了,而是重新发送对象。
非持续连接和持续连接
持续连接非:所有的请求/响应对是经过一个相同的、单独的TCP连接发送。
持续连接:每个请求/响应对分别有一个不同于其它的、单独的TCP连接发送,并且在完成一次请求/响应后,会关闭该TCP连接。
HTTP默认方式下使用持续连接,但是也可以配置成为非持续连接。
采用非持续链接的HTTP

1.HTTP客户进程在端口号80发起一个到服务器www.someSchool.edu的TCP连接。
该端口号是HTTP的默认端口。
2.HTTP客户经它的套接字向该服务器发送一个HTTP请求报文。(报文中包含了路径名/someDepartment/home.index)
3.HTTP服务器进程经它的套接字接受请求报文,并从存储器(RAM或磁盘)中检索出对象(home.index),随后在一个HTTP响应报文中封装对象,并通过其套接字向客户端发送响应报文。
4.HTTP服务器进程通知TCP断开该TCP连接,但是实际到客户端接收到响应报文后,该TCP连接才会关闭。
5.HTTP客户接受响应报文,TCP连接关闭。
6.对每个引用的JPEG图形对象重复前四个步骤。
往返时间的定义(RTT):
该时间是指一个短分组从客户端到服务器端再到客户端的时间。
RTT包括:分组传播时延、分组在中间路由器和交换机上的排队时延、处理时延。
采用持续连接的HTTP
在持续连接下,服务器在发送响应报文后保持TCP连接的打开。
在后续相同的客户与服务器之间,后续的请求和响应报文可以继续在该TCP连接中进行。
如果一条连接经过一定时间间隔仍未被使用,HTTP服务器会被关闭该TCP连接。
HTTP报文格式
HTTP报文有两种:
请求报文和响应报文
HTTP请求报文

HTTP请求报文的第一行叫请求行,其后继的所有行都被称为首部行。
请求行有三个字段:方法字段、URL字段、HTTP协议版本字段。
方法字段可以取不同的值,包括GET、POST、HEAD、PUT、DELETE
绝大部分的HTTP请求报文使用GET方法。
意思是请求一个对象。
下面是一个请求报文的通用格式:

此处的实体体(entity body)在POST方法时会用到该实体,在GET中用不到。
当用户提交表单时,HTTP客户常常使用POST方法。
当然,用户提交表单的时候也可以不用POST方法,转用GET方法,此时的表单字段中所请求的URL中包括了输入的数据。
例如:一个表单使用GET方法,它有两个字段:“monkeys”和“bananas”这样,该URL结构为:
www.somsites.com/animalsearch? monkey&bananas
HEAD方法类似于GET方法,使用HEAD方法,服务器仅仅返回一个HTTP报文进行响应,并不返回请求对象,因此常常被程序开发者用来测试跟踪。
PUT方法常常与Web发行工具联合使用,它允许用户上传对象到指定的Web服务器上的指定目录。
DELETE方法允许用户删除Web服务器指定对象。
HTTP响应报文
下面是一个典型的HTTP响应报文。

它包含了三个部分:
初始状态行、首部行、实体体。
实体体在响应报文中是主要组成部分,即它包含了所请求的对象本身。
Connetction : clost代表发送报文后将关闭TCP连接。
下面是一个HTTP响应报文的通用格式。

下面是常见的状态码和短语。

用户与服务器的交互:cookie
cookie用来让web服务器识别到用户身份。
cookie技术有四个组件:
1.在HTTP响应报文中的一个cookie首部行。
2.在HTTP请求报文中的一个cookie首部行。
3.在用户端系统中保留一个cookie文件,由浏览器管理。
4.位于Web站点的一个后端数据库中。
下图是一个cookie工作过程。

Web缓存
Web缓存器也叫代理服务器。

Web缓存器有自己的磁盘存储空间。
在请求对象经过Web缓存器一般是以下情况:
1.浏览器创建一个到Web缓存器的TCP连接,并且向该Web缓存器发送一个HTTP请求。
2.Web缓存器进行检查,如果有浏览器所请求的对象,那么直接返回,否则Web缓存器建立一个到Web服务器的TCP连接,并且向Web服务器发送一个HTTP请求。
3.Web服务器接收到HTTP请求,向Web缓存器发送响应报文,并且关闭TCP连接。
4.Web缓存器接收到响应报文,并把其中的对象保存到本地磁盘中,随后将对象发送给浏览器,并且关闭TCP连接。
值得注意的是,Web缓存器既是客户又是服务器。
下面我们通过一个例子来加深对于Web缓存器设立的必要性,以及好处
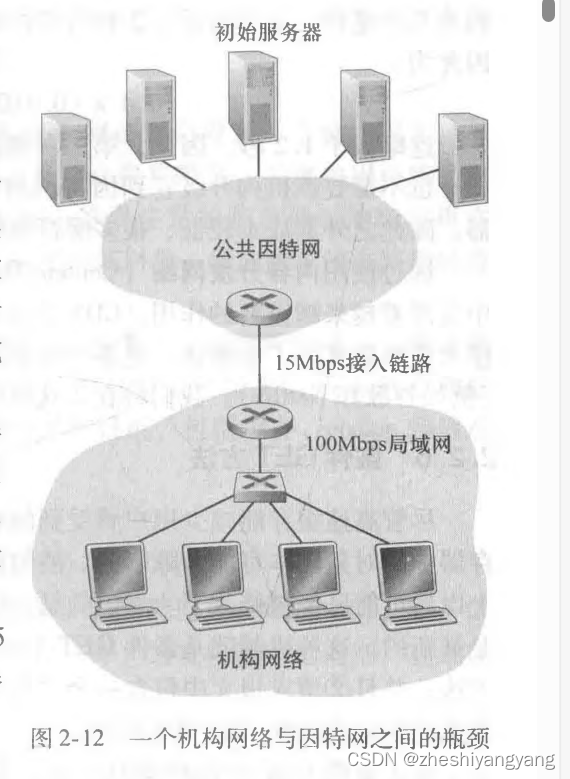
我们假设对象的平均长度为1Mb,浏览器每秒发送15个请求,在因特哇那个接入链路一侧的路由器转发HTTP请求报文开始,到它接收响应报文我们硬性规定为2s。
此时局域网上的流量强度为:

接入链路上的流量强度为:
![]()
流量强度接近1,链路上的时延就会变得非常大并且无穷大的增长。
为此有两个解决方法:
1.更换更快的接入链路,但是成本非常昂贵。
2.使用Web缓存器,我们下面讨论使用Web缓存器。
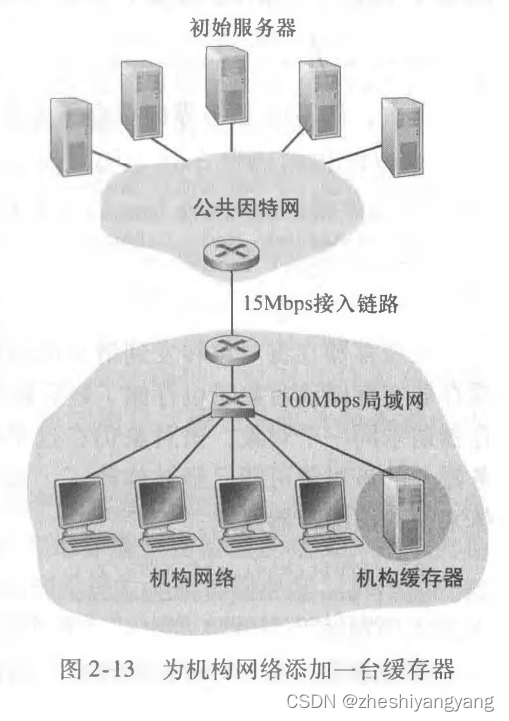
假设缓存器满足请求的比率为0.4。
则40%的请求会立即被缓存器返回,只剩下60%的请求会经过15Mbps接入链路。
流量强度为:
1 × 0.6 = 0.6
则平均时延为:

约等于1.2秒。
可以看到使用缓存器的时延大大降低,并且成本相较于换链路非常低!
条件GET方法
存放在缓存器中的对象副本可能是陈旧,为此HTTP有一种机制,允许缓存器证实它的对象是最新的。
这种机制就是条件GET方法。
下面是一个简单的请求报文:

这是一个返回的响应报文:
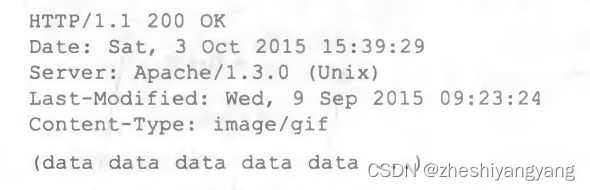
此时条件方法报文:

If-modified-since用来确定在Web缓存器修改对象的最后时间是否与Web服务器修改对象的最后时间是否一致,如果一致则Web缓存器直接返回对象。否则,Web缓存器先从Web服务器接收最新的对象,再返回给Web浏览器。
因特网中的电子邮件
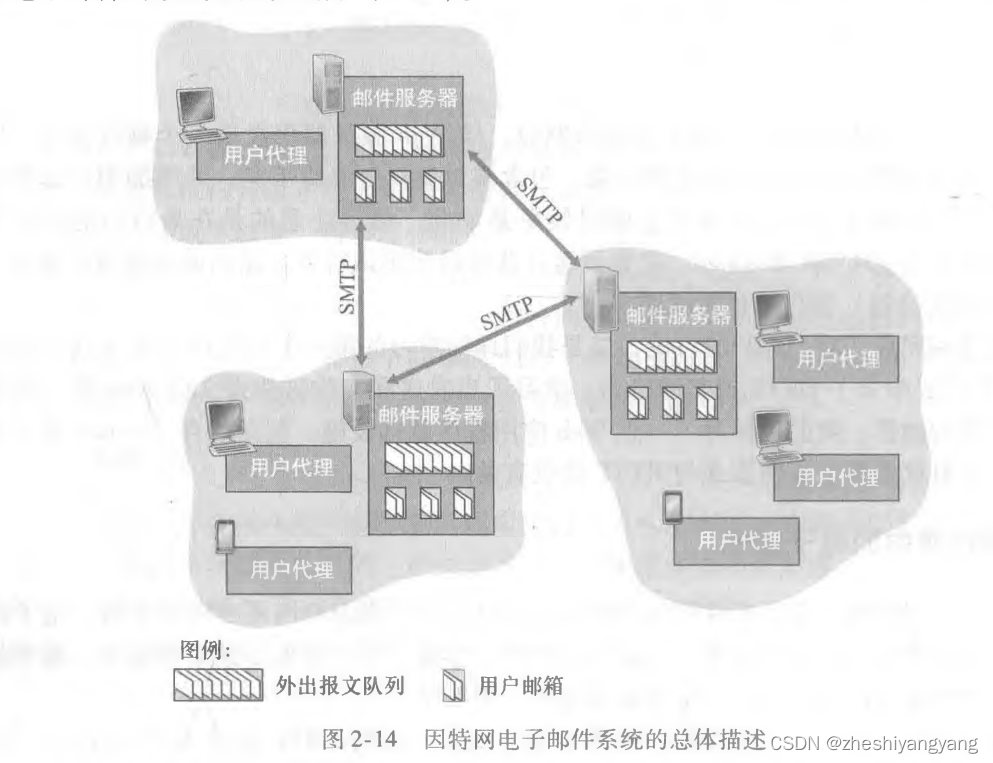
因特网电子邮件系统主要有三个组成部分:
用户代理、邮件服务器、简单邮件传输协议(SMTP)
SMTP协议
SMTP是电子邮件在应用层的协议,它依靠于TCP进行传输。

因此可以说:
SMTP一般不使用中间邮件服务器发送邮件,即使这两个邮件服务器位于地球的两端也是这样。
TCP连接可以是跨越很大的地理位置,并且建立TCP连接。
特别,如果Bob的邮件服务器没有开机,该报文会保留在Alice的邮件服务器上等待并进行新的尝试,这意味着邮件并不在中间的某个邮件服务器存留。
与HTTP的对比
HTTP主要是一个拉协议(pull protocol)
即主要是从服务器拉取信息
SMTP主要是一个推协议(push protocol)
即主要是向服务器推送信息
邮件访问协议
SMTP并不能使Bob从邮件服务器中拉取信息,因为SMTP是一个推协议。
因此人们发明了邮件访问协议,目前比较流行的访问协议:
1.第三版的邮局协议(POP3)
2.因特网的邮件访问协议(IMAP)
3.HTTP
POP3
POP3是一个极为简单的邮件访问协议,功能相当有限。
主要有三个阶段进行工作:
特许、事务处理以及更新
IMAP

基于Web的电子邮件
在这种服务中,用户代理就是普通的浏览器,用户和他远程邮箱之间的通信则通过HTTP进行。
当发件人(Alice)要发送一封电子邮件报文时,该电子邮件报文从Alice的浏览器发送到她的邮件服务器,使用的是HTTP而不是SMTP。
然后Alice的邮件服务器在与其他的邮件服务器之间发送和接收时,仍然使用的是SMTP。