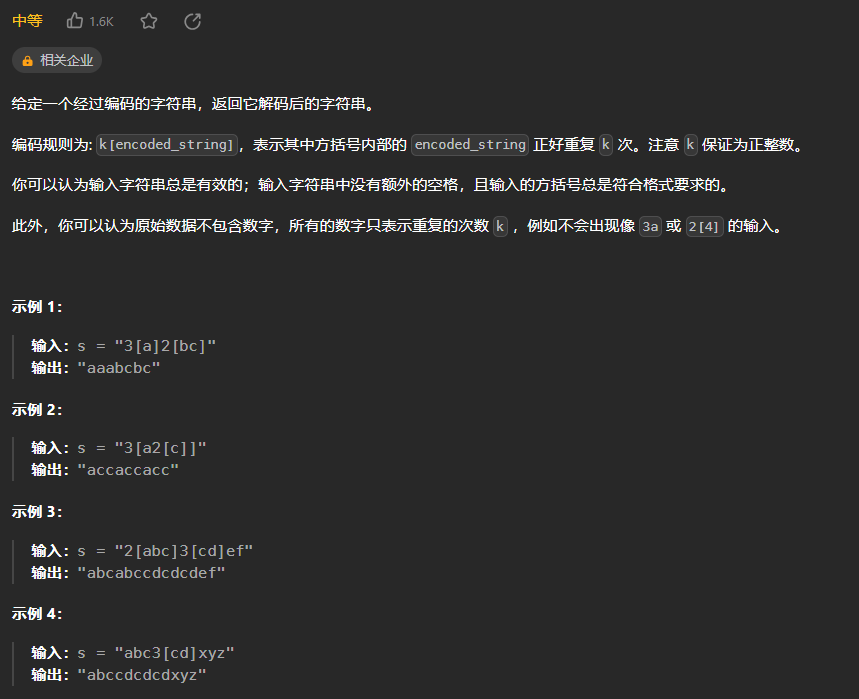
现在您已经探讨了使用LLM构建应用程序的基础知识,我想向您展示一项名为Amazon Sagemaker JumpStart的AWS服务,它可以帮助您快速进入生产并进行大规模操作。
以下是您在先前视频中探讨的应用程序堆栈。正如您所看到的,构建一个LLM驱动的应用程序需要多个组件。
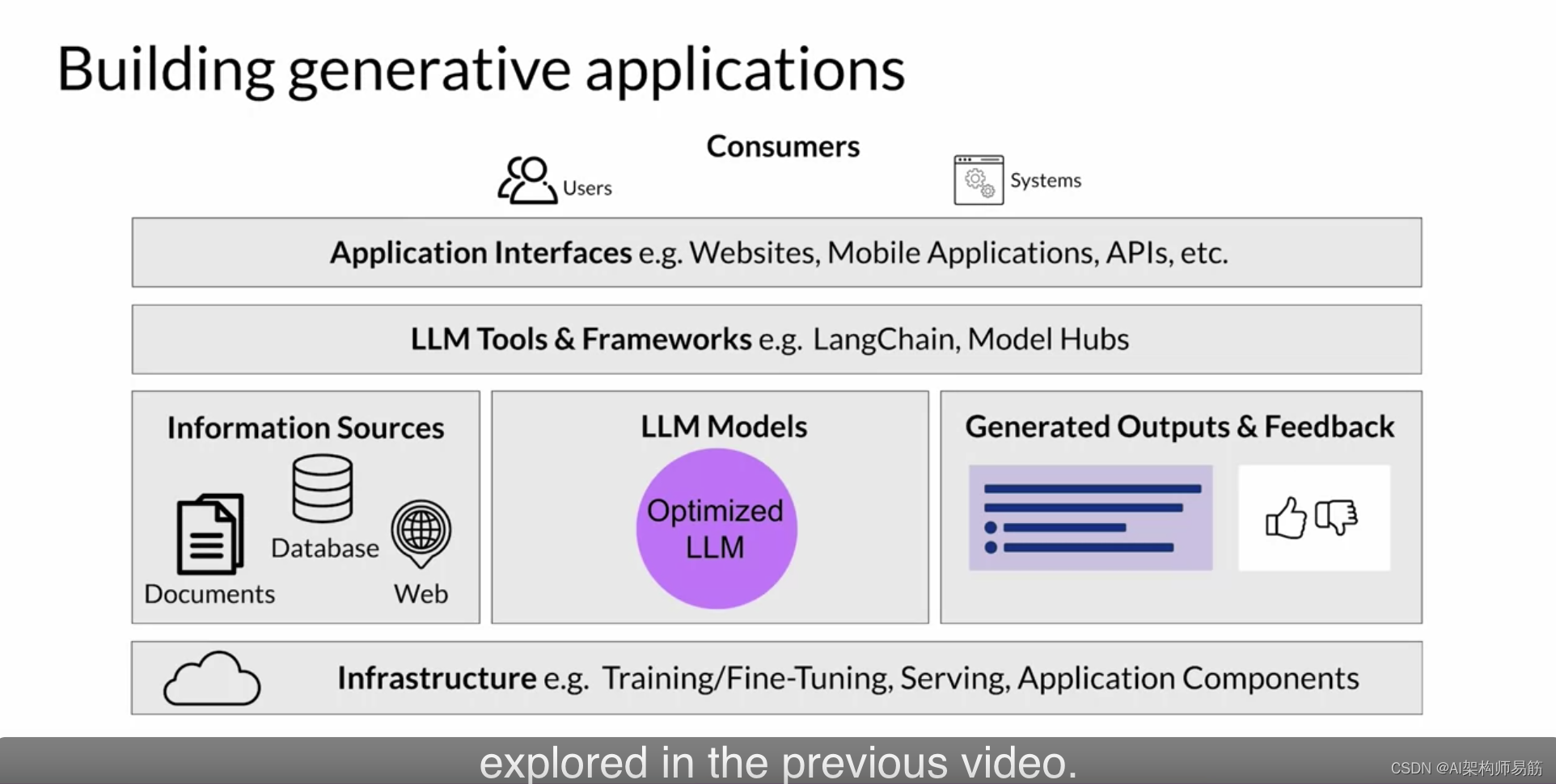
Sagemaker JumpStart是一个模型中心,它允许您快速部署该服务中提供的基础模型,并将它们集成到您自己的应用程序中。JumpStart服务还提供了一种简便的方式来微调和部署模型。
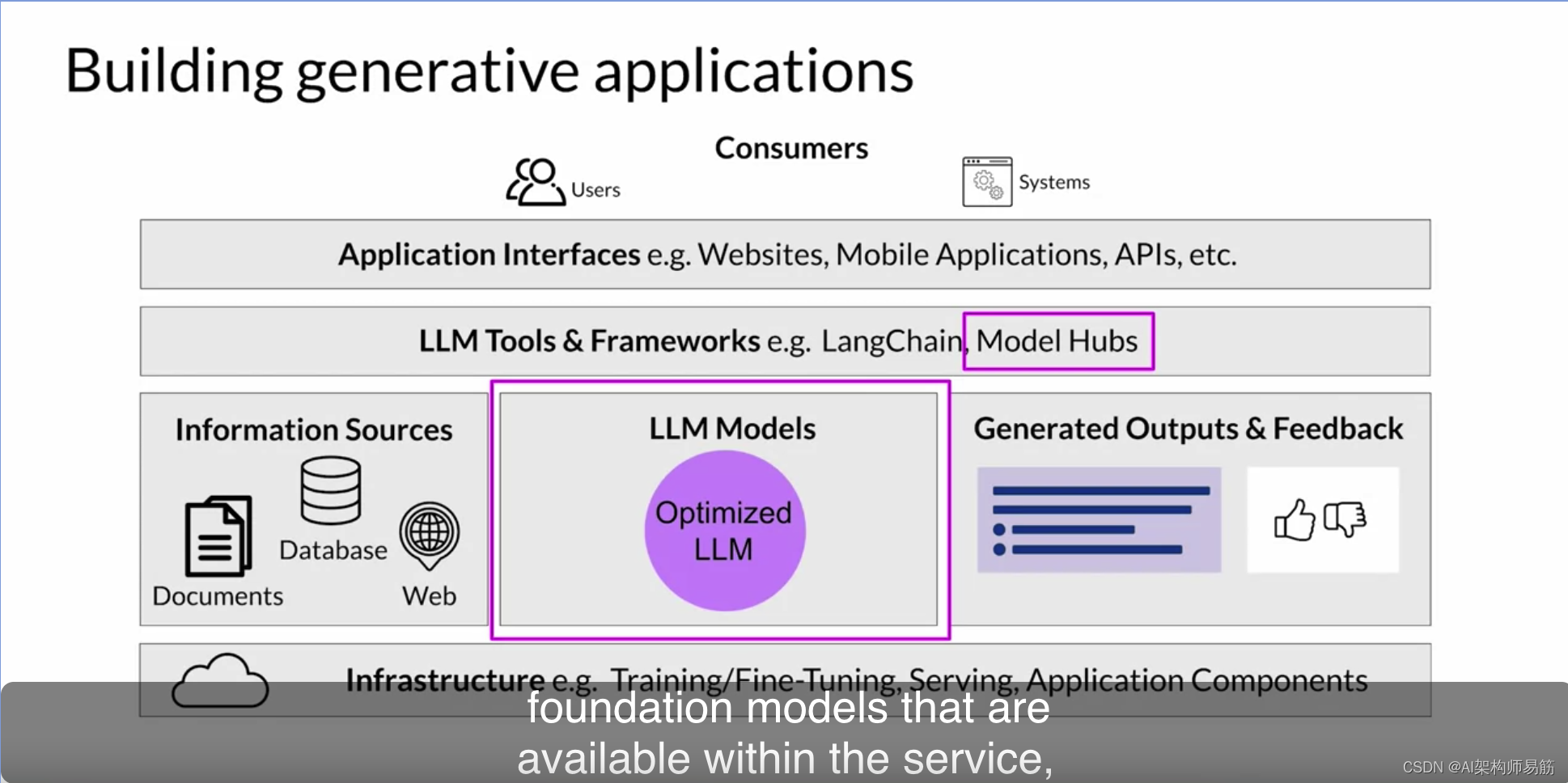
JumpStart涵盖了这个图表的许多部分,包括基础设施、LLM本身、工具和框架,甚至可以调用模型的API。
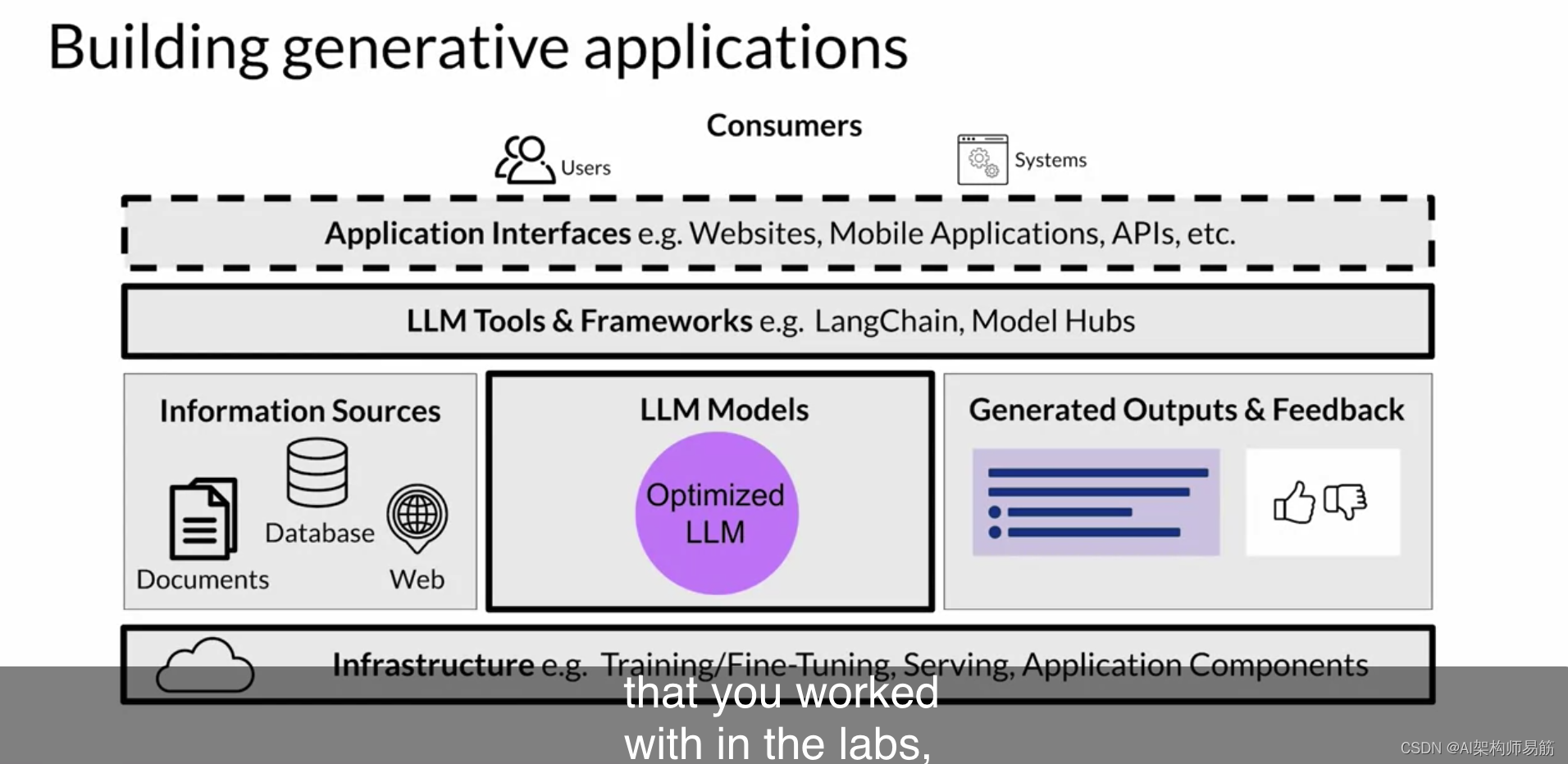
与您在实验室中使用的模型相比,JumpStart模型需要GPU来进行微调和部署。请记住,这些GPU按需定价,并在选择要使用的计算之前,请参阅Sagemaker定价页面。此外,请确保在不使用时删除Sagemaker模型端点,并遵循成本监控最佳实践以优化成本。
让我向您展示一下JumpStart的简短介绍以及如何从您自己的AWS账户中访问它。您可以从AWS控制台或通过Sagemaker Studio访问Sagemaker JumpStart。在这次简短的介绍中,我将从Sagemaker Studio开始,然后从主屏幕中选择JumpStart。我还可以选择左侧菜单中的JumpStart,然后选择模型、笔记本和解决方案。
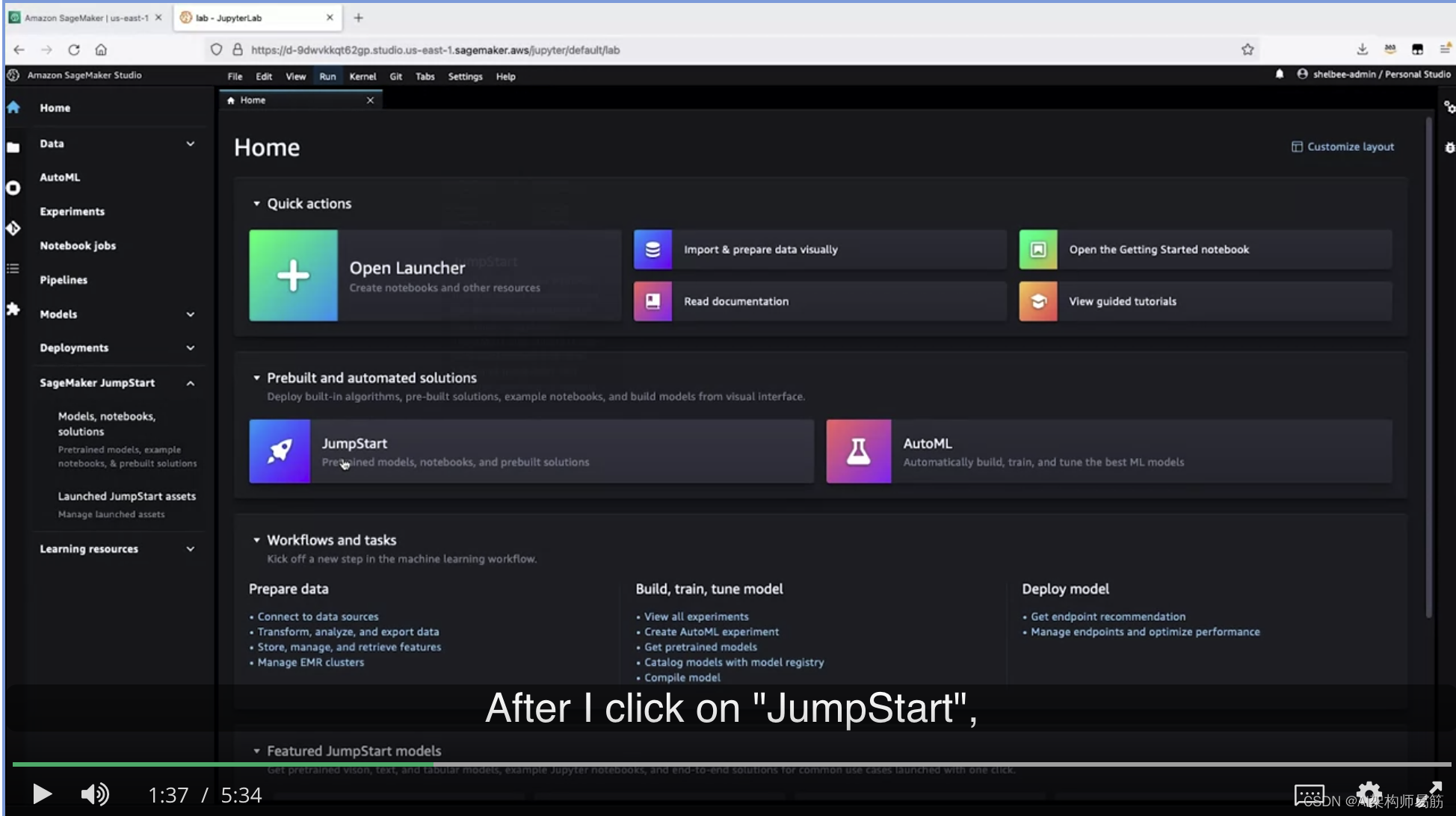
点击“JumpStart”后,您将看到不同的类别,包括不同用例的端到端解决方案,
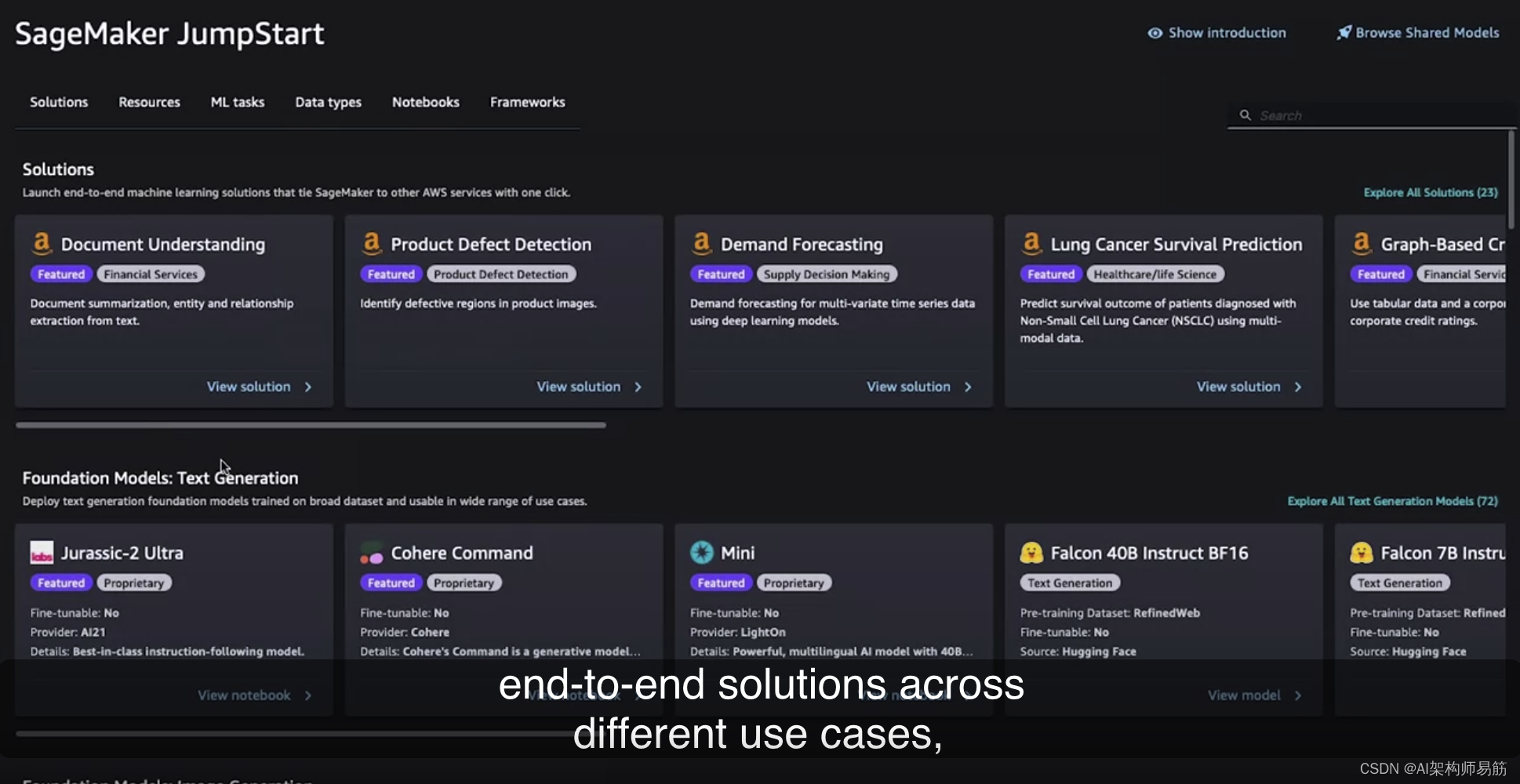
以及多种不同模态的基础模型,您可以轻松部署和微调,如果在微调选项下有“是”的话。让我们看一个您在课程中熟悉的示例,即Flan-T5模型。
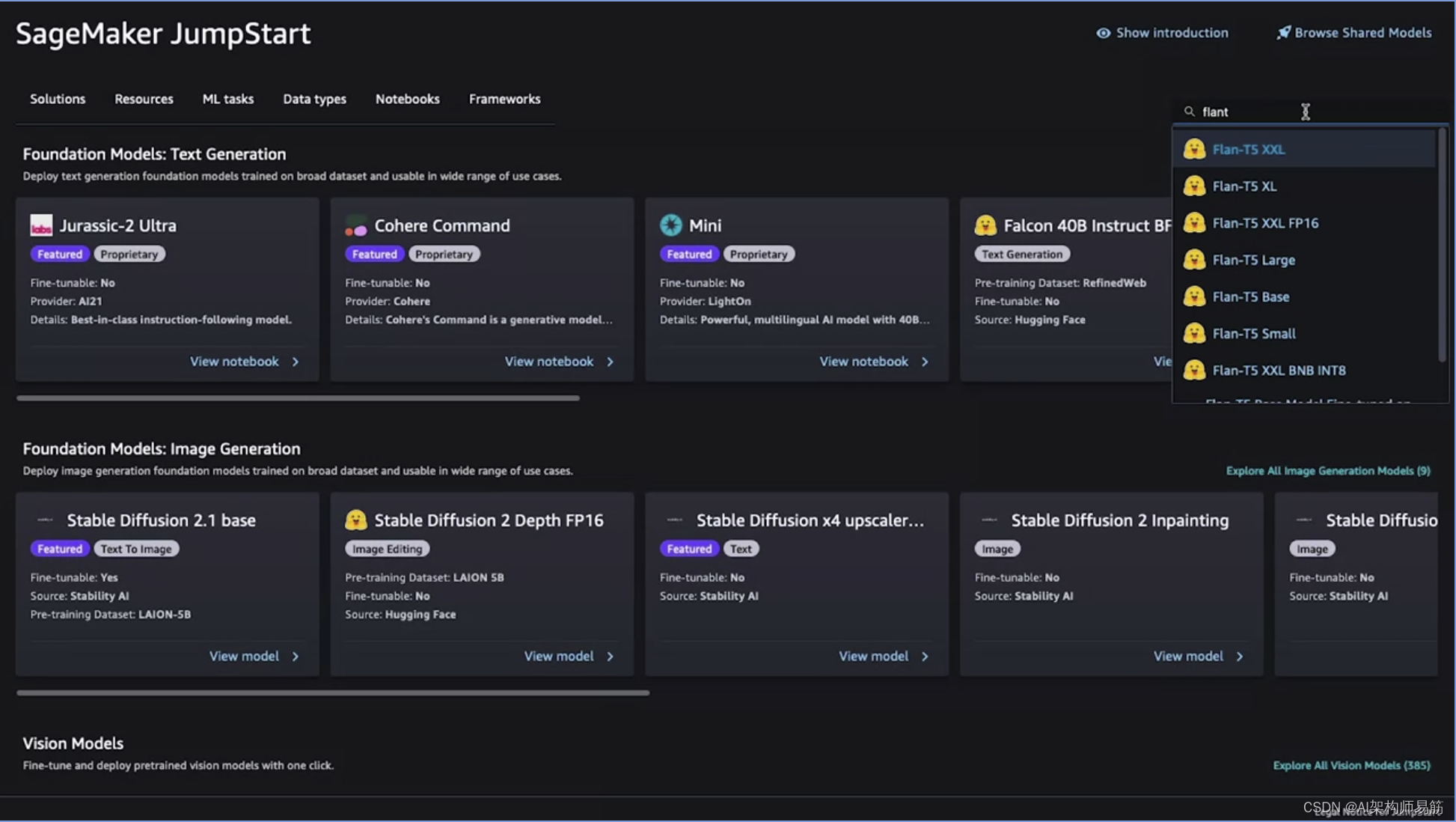
您在课程中一直使用的是基础变体,以减少实验室环境所需的资源。但是,如您在这里所见,您还可以根据需要通过JumpStart使用Flan-T5的其他变体。您还会注意到这里有Hugging Face的标志,这意味着它们实际上是直接来自Hugging Face。AWS已与Hugging Face合作,以使您可以仅需几次点击即可部署或微调模型。如果选择Flan-T5 Base,您将看到有几个选项。首先,您可以选择部署模型,通过识别一些关键参数,如实例类型和大小,来部署该模型。这是用于托管模型的实例类型和大小。
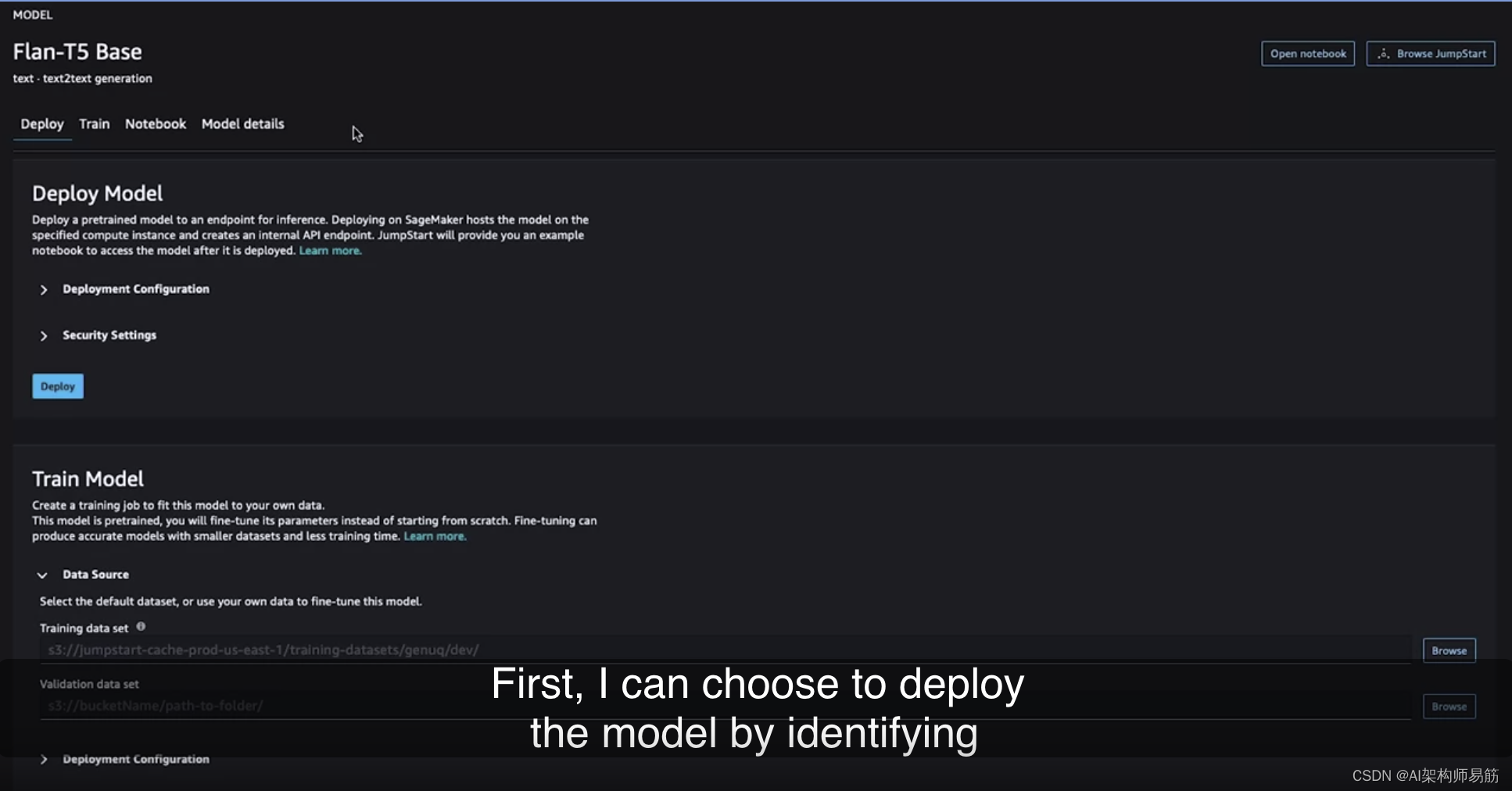
提醒一下,这会部署到一个实时的持久端点,价格取决于您在此处选择的托管实例。
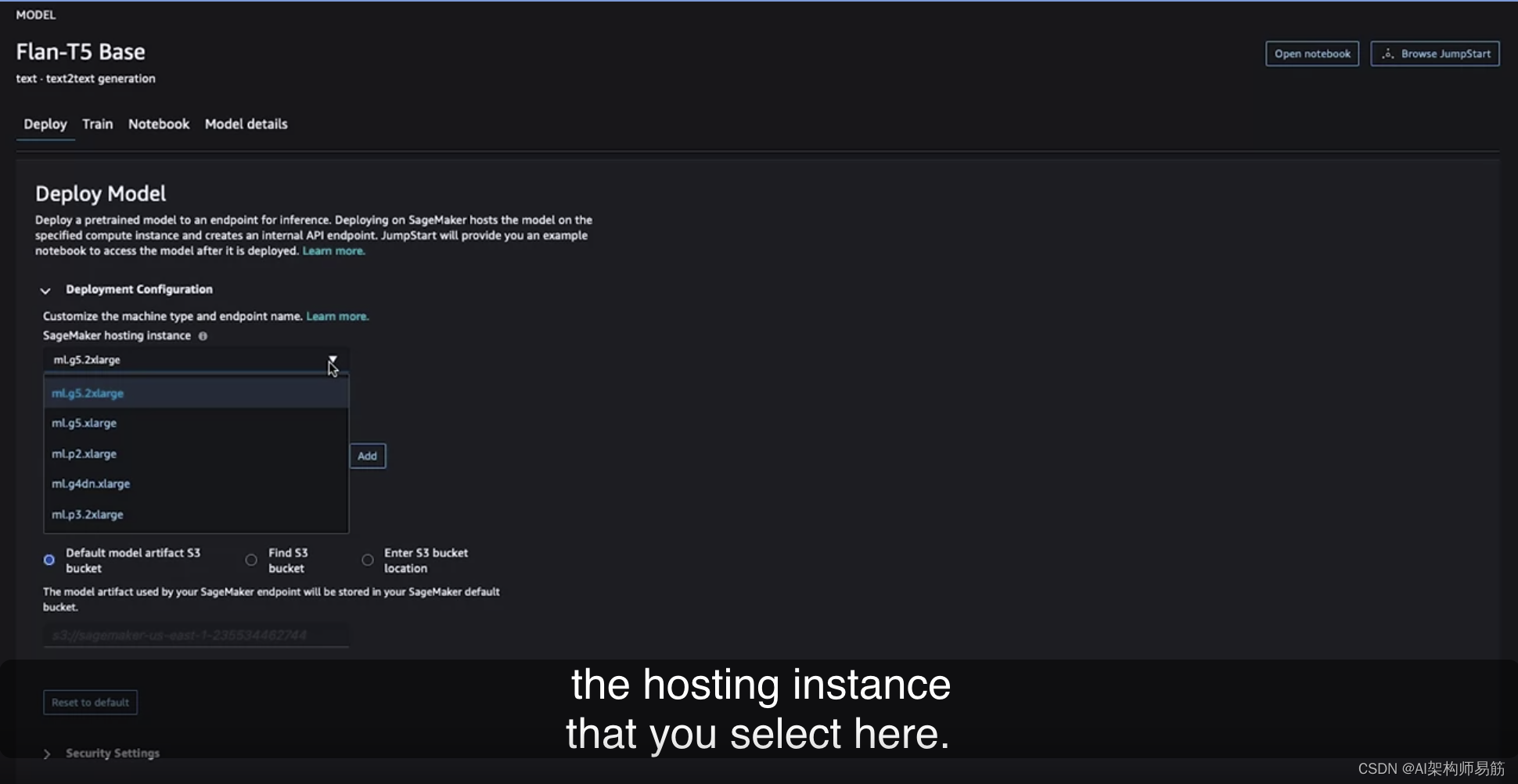
其中一些可能相当大,因此请始终记住删除不再使用的任何端点,以避免产生不必要的费用。您还可以指定一些安全设置,以满足您自己的安全要求。然后,您可以选择“部署”,这将自动使用您指定的基础设施部署Flan-T5 Base模型到端点。在第二个选项卡中,您将看到培训的选项。因为此模型支持微调,所以您还可以设置微调作业,指定培训和验证数据集的位置,然后选择用于培训的计算的大小。通过此下拉菜单,轻松调整计算的大小,您可以轻松选择要用于培训作业的计算类型。再次请注意,根据用于培训模型所需的时间,您将按照底层计算进行计费,因此我们建议选择适用于您特定任务的最小实例。另一个功能是快速识别和修改此特定模型的可调超参数的能力,通过这些下拉菜单。
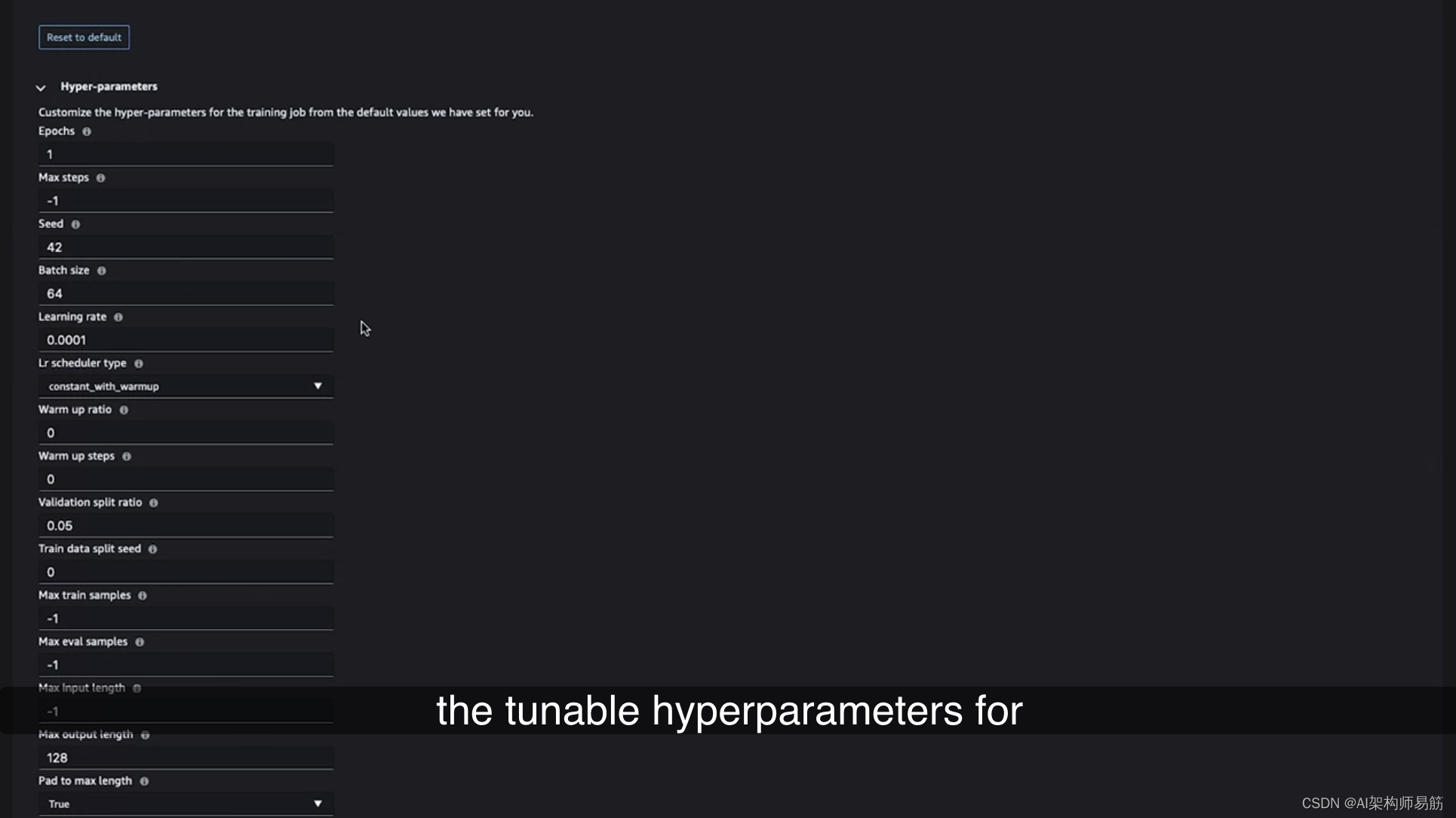
如果继续向下滚动到底部,您将看到一个称为PEFT(参数高效微调)的参数类型,您在第6课中了解过它。在这里,您可以通过简单的下拉菜单选择Laura,这使得您更容易实施您所学到的各种技术。
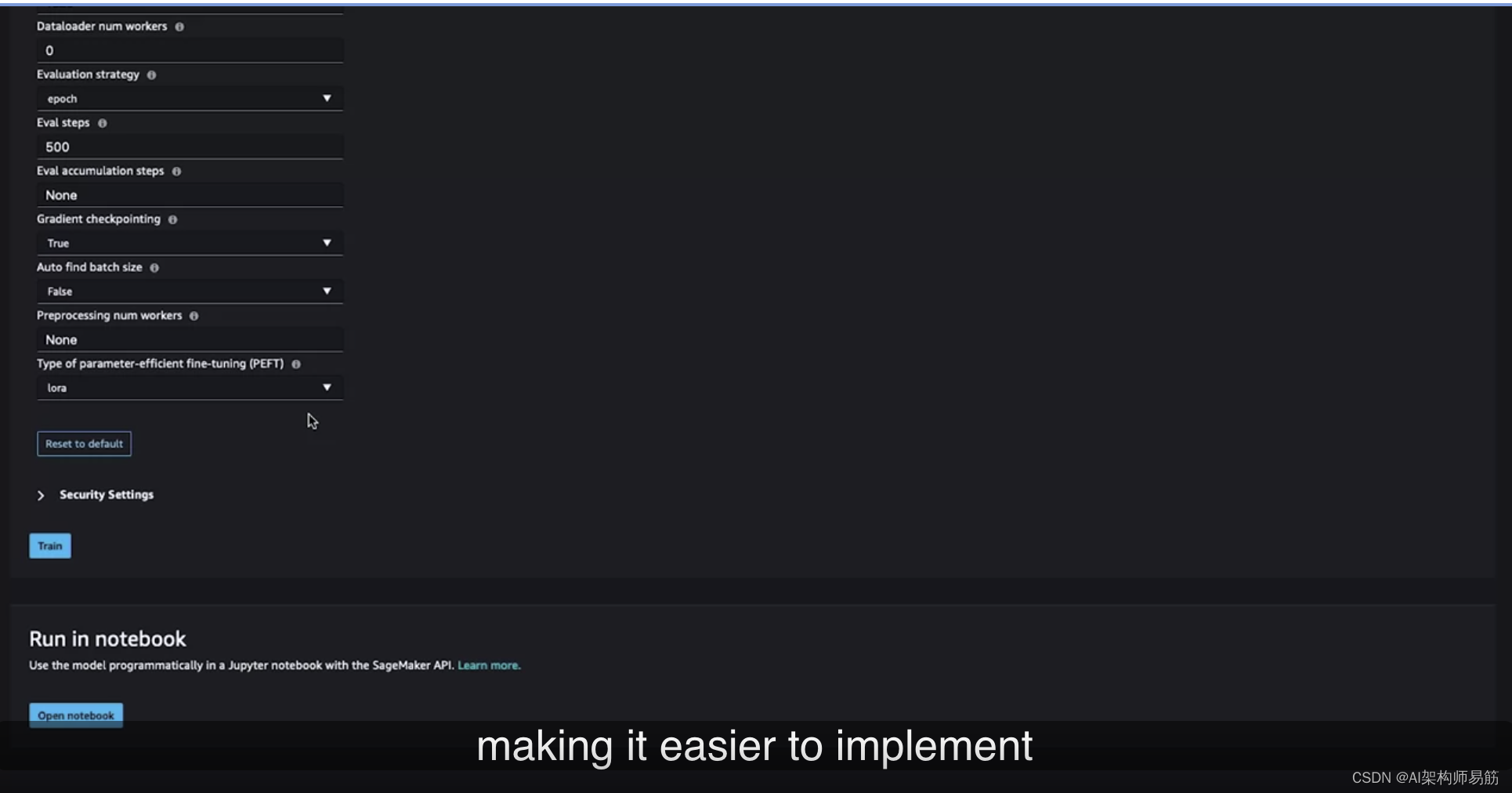
然后,您可以点击“培训”。这将启动一个培训作业,使用为您特定任务提供的输入来微调预训练的Flan-T5模型。最后,这里还有另一个选项,那就是让JumpStart自动生成一个笔记本。
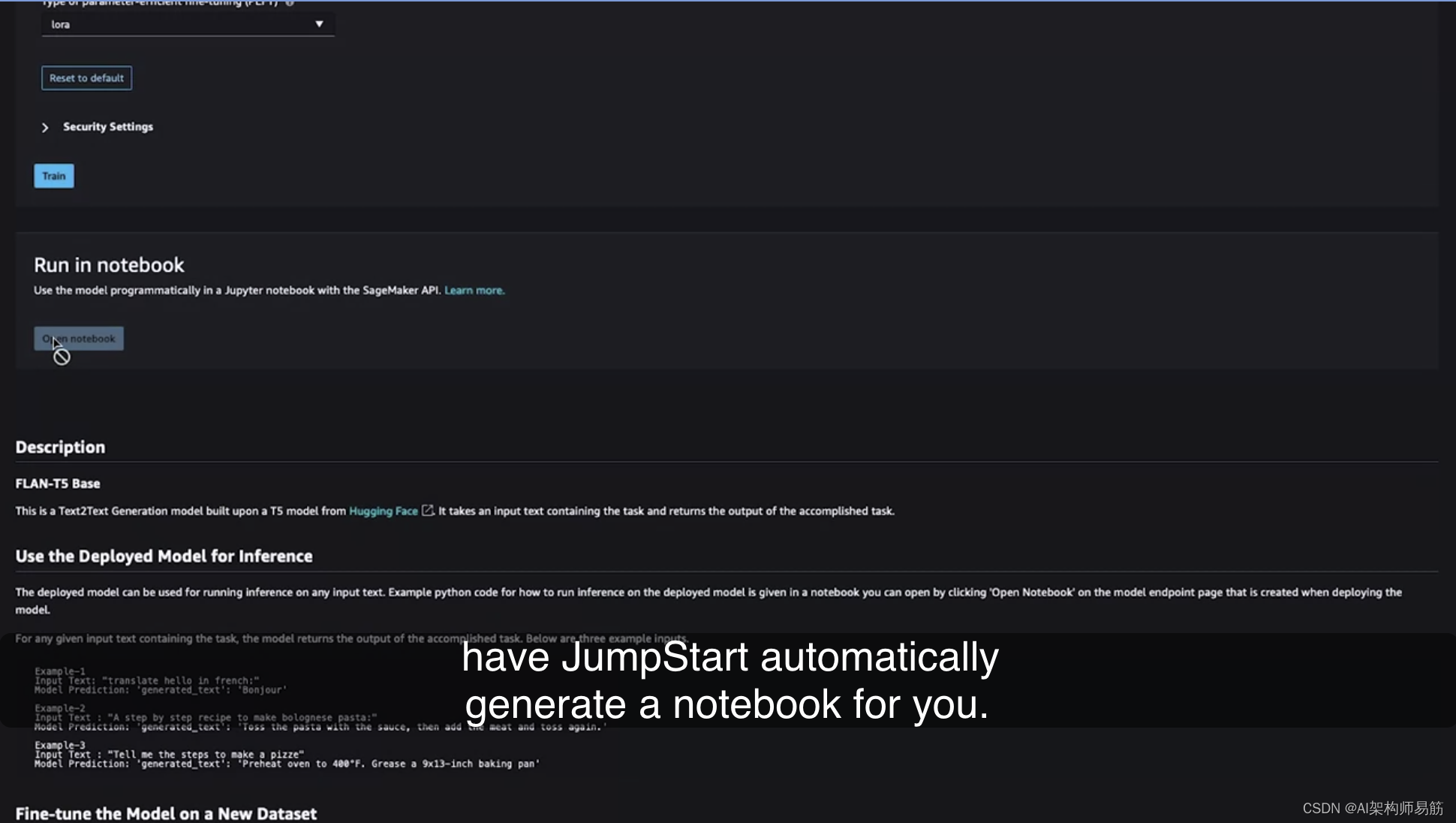
假设您不喜欢使用下拉菜单,更喜欢以编程方式处理这些模型。这个笔记本基本上为您提供了所有在前面介绍的选项中发生的代码。
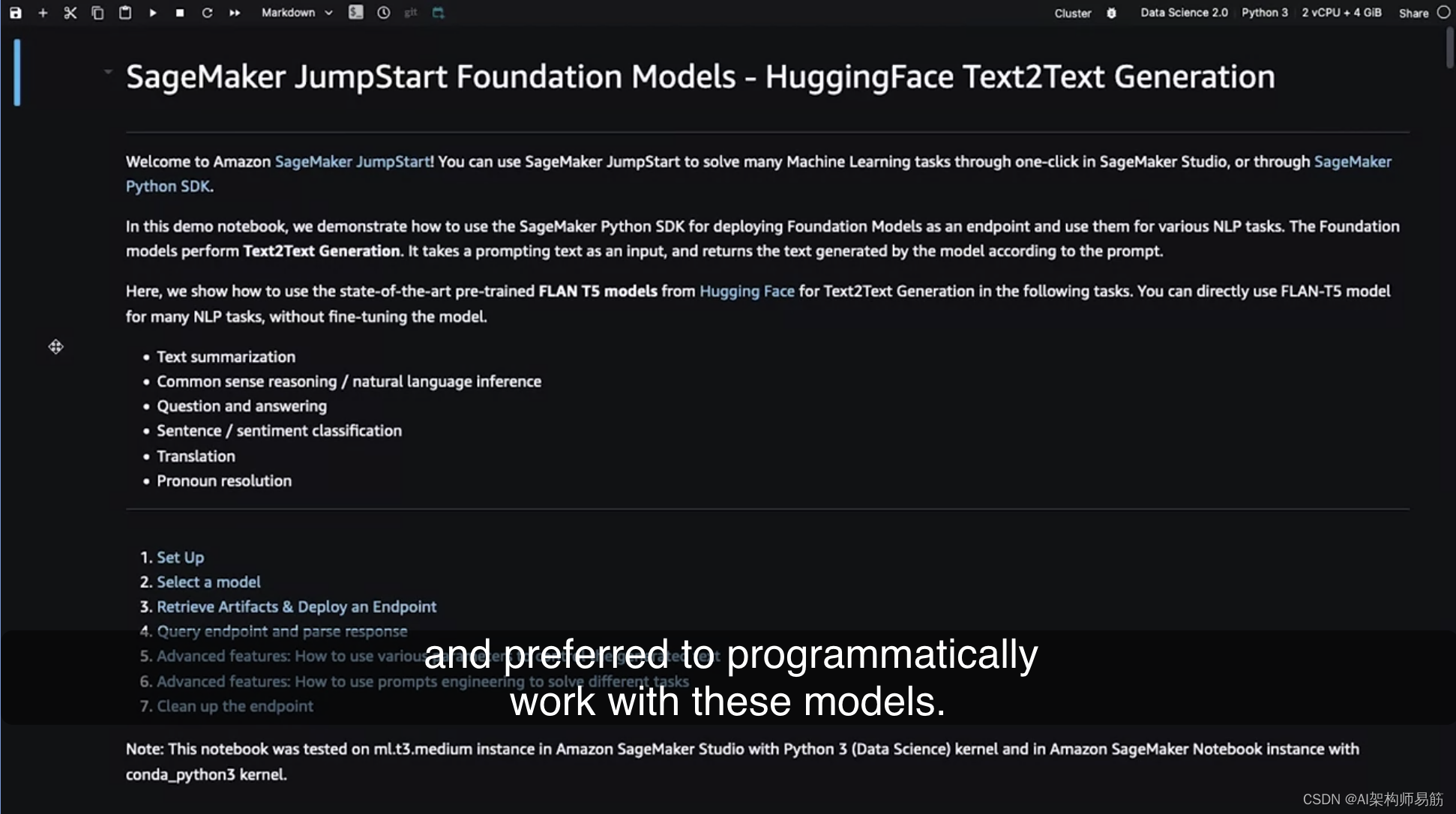
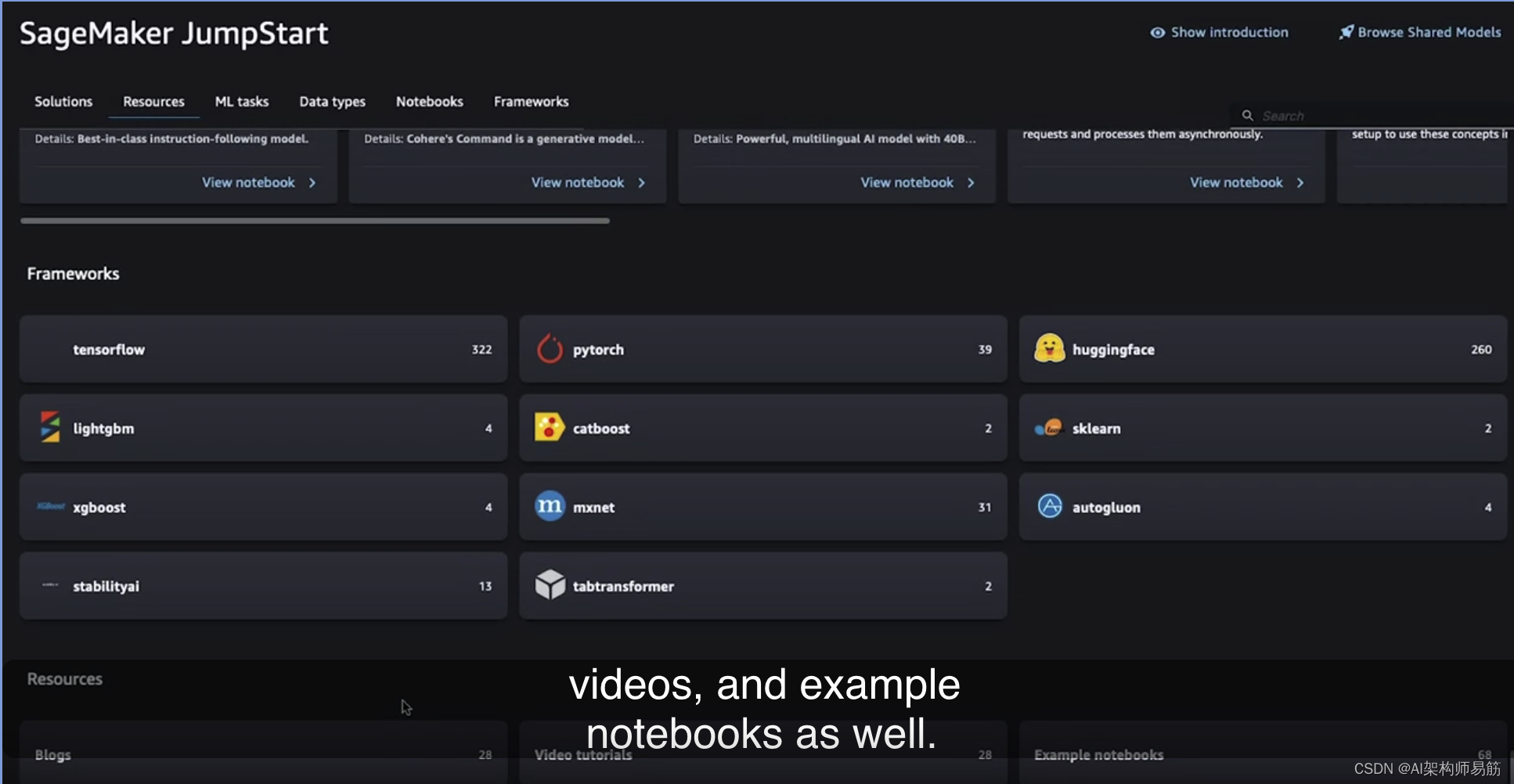
这是一个选项,如果您喜欢以最低级别以编程方式使用JumpStart。这只是一个JumpStart的快速介绍,以演示您在课程中所学的模型中心的实现。除了作为一个包括基础模型的模型中心,JumpStart还提供了许多关于博客、视频和示例笔记本的资源。我绝对鼓励您通过探索不同的基础模型及其变体来深入了解更多。帮助您快速入门。
Reference
https://www.coursera.org/learn/generative-ai-with-llms/lecture/WVsMi/optional-video-aws-sagemaker-jumpstart