关联更新顾名思义就是指,更新的数据从关联的表中获取并update到目标表。并且该SQL将会是一个天然的嵌套循环。有两种优化思路解决:
1、PLSQL 根据rowid更新
是否需要加order by rowid的考量:
如果buffer cache足够大,能够放得下要被更新的表,就不需要order by rowid,因为这个过程只需要将这张表读一次进buffer cache就可以了。
如果buffer cache不够大,就需要order by rowid了。因为假如由于buffer cache不够了,导致只能page部分该表的数据到磁盘,但可能块上部分都没有更新完,就又要读回去,这样一来一回甚至需要读到内存的量远大于该表的大小;如果加了rowid排序,即时被刷出去了,也能按顺序读回去。
2、merge into
更推荐merge into,因为他不仅是多块读,而且也可以做到并行更新,缺点是消耗undo多,如果更新过程中down机了,死事务恢复会很慢。
下面通过实验来举例优化:
create table a as select * from dba_objects;
create table b as select * from dba_objects;
insert into b select * from b; ----插入到60w左右数据
----实验数据构造----
SQL> create table a as select * from dba_objects;
表已创建。
SQL> create table b as select * from dba_objects;
表已创建。
SQL> insert into b select * from b;
已创建 86081 行。
SQL> /
已创建 172162 行。
SQL> /
已创建 344324 行。
SQL> select count(*) from b;
COUNT(*)
----------
688648
现在假设有如下关联更新语句:
update b set b.object_name=(select a.object_name from a where a.object_id=b.object_id);
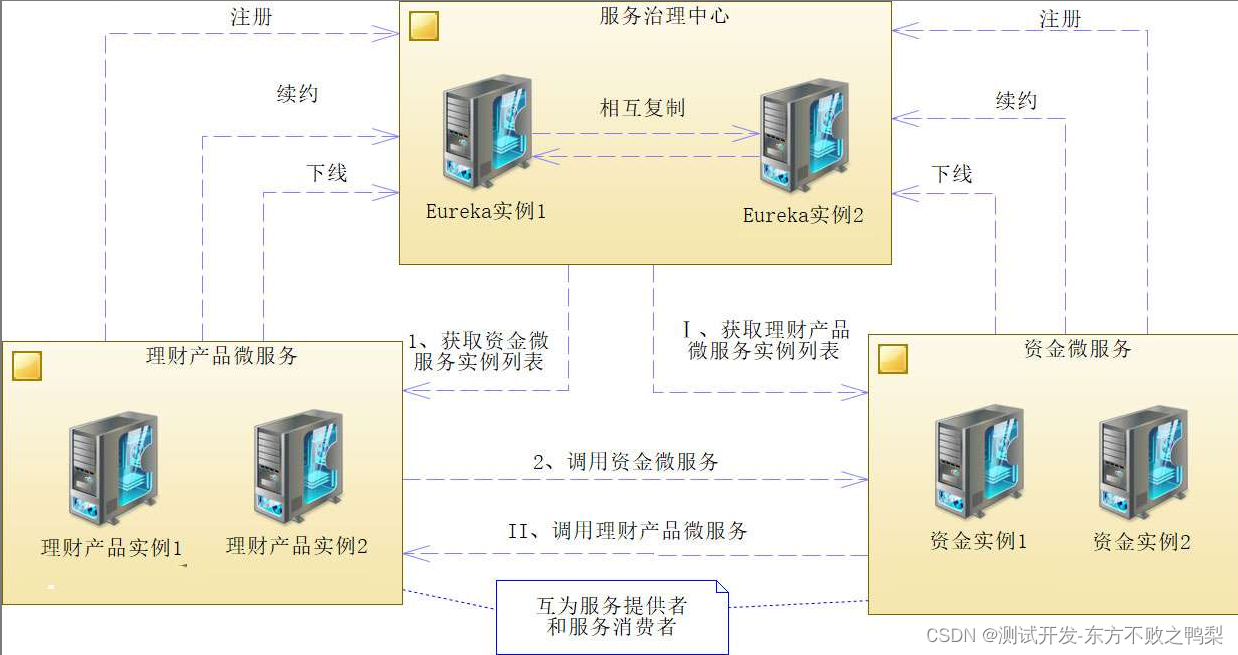
SQL> explain plan for update b set b.object_name=(select a.object_name from a where a.object_id=b.object_id);
已解释。
SQL> set lines 300 pages 300
SQL> select * from table(dbms_xplan.display);
可以看到id=3有:B1,这个情况之前文章也说过了,SQL语句中本身没绑定变量,但是执行计划中出现了,说明被驱动表已经被干了n次了。
------merge into优化,使用merge into一定要注意确保merge into的表走全表扫描
alter session set db_file_multiblock_read_count=128;
如果更新的表很大可以开启并行,手动设置sort区和hash区:
alter session set enable parallel dml;
alter session set workarea_size_policy=manual;
alter session set sort_area_size=xxx;
alter session set hash_area_size=xxx;
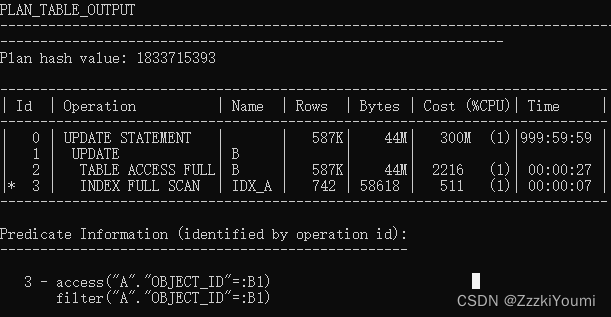
下面是使用merge into优化该关联更新语句:
merge /*+ use_hash(a,b) parallel(a,4) paraller(b,4)*/ into b using a on (a.object_id=b.object_id) when matched then update set b.object_name=a.object_name;
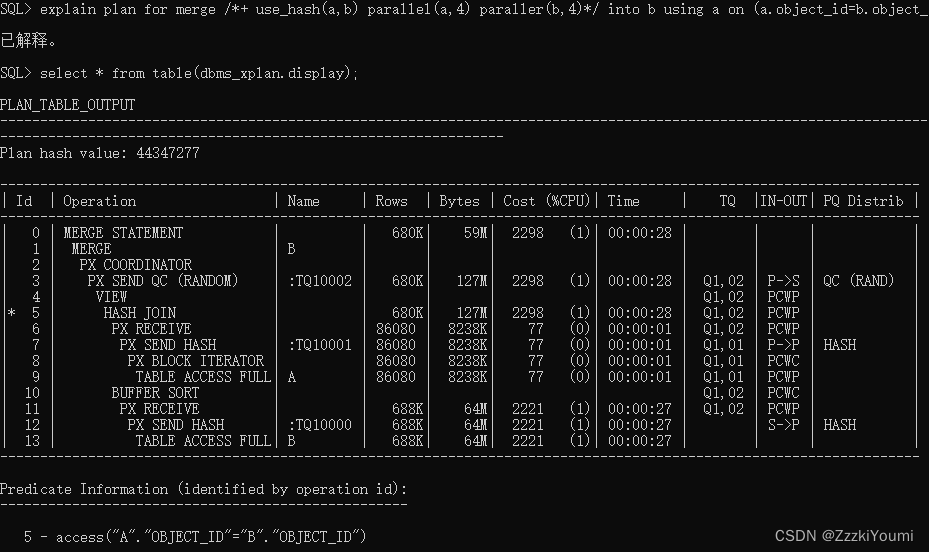
09:22:42 SQL> merge /*+ use_hash(a,b) parallel(a,4) paraller(b,4)*/ into b using a on (a.object_id=b.object_id) when matched then update set b.object_name=a.object_name;
688640 行已合并。
09:22:54 SQL>
实测用了12s更新完成原先跑不完的update SQL。
------PLSQL,根据rowid优化
DECLARE
CURSOR cur_b IS
SELECT
a.object_id,
a.object_name,
b.rowid row_id
FROM
a,
b
WHERE
a.object_id = b.object_id
ORDER BY
b.rowid;
v_counter NUMBER;
BEGIN
v_counter := 0;
FOR row_b IN cur_b LOOP
UPDATE b
SET
object_name = row_b.object_name
WHERE
ROWID = row_b.row_id;
v_counter := v_counter + 1;
IF ( v_counter >= 10000 ) THEN
COMMIT;
dbms_output.put_line('Update:'
|| v_counter
|| 'lines.');
v_counter := 0;
END IF;
END LOOP;
COMMIT;
END;
/
实测用了15s更新完成
------PLSQL,根据rowid优化,并且批量游标处理
DECLARE
maxrows NUMBER DEFAULT 100000;
row_id_table dbms_sql.urowid_table;
--currecount_table dbms_sql.number_Table;
object_name_table dbms_sql.varchar2_table;
CURSOR cur_b IS
SELECT /*use_hash(a,b)*/
a.object_name,
b.rowid row_id
FROM
a,
b
WHERE
a.object_id = b.object_id
ORDER BY
b.rowid;
v_counter NUMBER;
BEGIN
v_counter := 0;
OPEN cur_b;
LOOP
EXIT WHEN cur_b%notfound;
FETCH cur_b BULK COLLECT INTO
object_name_table,
row_id_table
LIMIT maxrows;
FORALL i IN 1..row_id_table.count
UPDATE b
SET
object_name = object_name_table(i)
WHERE
ROWID = row_id_table(i);
COMMIT;
END LOOP;
END;
/
实测10s更新完成
以上就是关于对关联更新优化的几种方法,最推荐使用merge into的方法,当数据量不是特别大时,也可以用批量游标的方法去更新。





![[软考中级]软件设计师-uml](https://img-blog.csdnimg.cn/img_convert/02c3758dfeda5118e36a9fa2bd53e40c.png)