前几课时我为你介绍了 Repository 的用法,其中我经常会提到“实体类”(即我们前面的 User 类),它是对我们数据库中表的 Metadata 映射,那么具体如何映射呢?这一课时我们来讲解。
我们先看一下 Java Persistence API 里面都有哪些重要规定;再通过讲解基本注解,重点介绍一下联合主键和实体之间的继承关系,然后你就会知道 JPA 的实体里面常见的注解有哪些。话不多说,看一下 Entity 的相关规定。
JPA 协议中关于 Entity 的相关规定
我们先看一下 JPA 协议里面关于实体做了哪些规定。(这里推荐一个查看 JPA 协议的官方地址:https://download.oracle.com/otn-pub/jcp/persistence-2_2-mrel-spec/JavaPersistence.pdf)
- 实体是直接进行数据库持久化操作的领域对象(即一个简单的 POJO,可以按照业务领域划分),必须通过 @Entity 注解进行标示。
- 实体必须有一个 public 或者 protected 的无参数构造方法。
- 持久化映射的注解可以标示在 Entity 的字段 field 上,如下所示:
复制代码
@Column(length = 20, nullable = false)
private String userName;
除此之外,也可以将持久化注解运用在 Entity 里面的 get/set 方法上,通常我们是放在 get 方法中,如下所示:
复制代码
@Column(length = 20, nullable = false)
public String getUserName(){
return userName;
}
概括起来,就是 Entity 里面的注解生效只有两种方式:将注解写在字段上或者将注解写在方法上(JPA 里面称 Property)。
但是需要注意的是,在同一个 Entity 里面只能有一种方式生效,也就是说,注解要么全部写在 field 上面,要么就全部写在 Property 上面,因为我经常会看到有的同事分别在两种方式中加了注解后说:“哎呀,我的注解怎么没有生效呀!”因此这一点需要特别注意。
- 只要是在 @Entity 的实体里面被注解标注的字段,都会被映射到数据库中,除了使用 @Transient 注解的字段之外。
- 实体里面必须要有一个主键,主键标示的字段可以是单个字段,也可以是复合主键字段。
以上我只挑选了最关键的几条进行了介绍,如果你有兴趣可以读一读 Java Persistence API 协议,这样我们在做 JPA 开发的时候就会顺手很多,可以理解很多 Hibernate 里面实现方法。
这也为你提供了一条解决疑难杂症的思路,也就是当我们遇到解决不了的问题时,就去看协议、阅读官方文档,深入挖掘一下,可能就会找到答案。那么接下来我们看看实例里面常用的注解有哪些。
详细的注解都有哪些?
我们先通过源码看看 JPA 里面支持的注解有哪些。
首先,我们利用 IEDA 工具,打开 @Entity 所在的包,就可以看到 JPA 里面支持的注解有哪些。如下所示:
我们可以看到,在 jakarta.persistence-api 的包路径下面大概有一百多个注解,你在没事的时候可以到这里面一个一个地看,也可以到 JPA 的协议里面对照查看文档。
我在这里只提及一些最常见的,包括 @Entity、@Table、@Access、@Id、@GeneratedValue、@Enumerated、@Basic、@Column、@Transient、@Lob、@Temporal 等。
1.@Entity 用于定义对象将会成为被 JPA 管理的实体,必填,将字段映射到指定的数据库表中,使用起来很简单,直接用在实体类上面即可,通过源码表达的语法如下:
复制代码
@Target(TYPE) //表示此注解只能用在class上面
public @interface Entity {
//可选,默认是实体类的名字,整个应用里面全局唯一。
String name() default "";
}
2.@Table 用于指定数据库的表名,表示此实体对应的数据库里面的表名,非必填,默认表名和 entity 名字一样。
复制代码
@Target(TYPE) //一样只能用在类上面
public @interface Table {
//表的名字,可选。如果不填写,系统认为好实体的名字一样为表名。
String name() default "";
//此表所在schema,可选
String schema() default "";
//唯一性约束,在创建表的时候有用,表创建之后后面就不需要了。
UniqueConstraint[] uniqueConstraints() default { };
//索引,在创建表的时候使用,表创建之后后面就不需要了。
Index[] indexes() default {};
}
3.@Access 用于指定 entity 里面的注解是写在字段上面,还是 get/set 方法上面生效,非必填。在默认不填写的情况下,当实体里面的第一个注解出现在字段上或者 get/set 方法上面,就以第一次出现的方式为准;也就是说,一个实体里面的注解既有用在 field 上面,又有用在 properties 上面的时候,看下面的代码你就会明白。
复制代码
@Id
private Long id;
@Column(length = 20, nullable = false)
public String getUserName(){
return userName;
}
那么由于 @Id 是实体里面第一个出现的注解,并且作用在字段上面,所以所有写在 get/set 方法上面的注解就会失效。而 @Access 可以干预默认值,指定是在 fileds 上面生效还是在 properties 上面生效。我们通过源码看下语法:
复制代码
@Target( { TYPE, METHOD, FIELD })//表示此注解可以运用在class上(那么这个时候就可以指定此实体的默认注解生效策略了),也可以用在方法上或者字段上(表示可以独立设置某一个字段或者方法的生效策略);
@Retention(RUNTIME)
public @interface Access {
//指定是字段上面生效还是方法上面生效
AccessType value();
}
public enum AccessType {
FIELD,
PROPERTY
}
4.@Id 定义属性为数据库的主键,一个实体里面必须有一个主键,但不一定是这个注解,可以和 @GeneratedValue 配合使用或成对出现。
5.@GeneratedValue 主键生成策略,如下所示:
复制代码
public @interface GeneratedValue {
//Id的生成策略
GenerationType strategy() default AUTO;
//通过Sequences生成Id,常见的是Orcale数据库ID生成规则,这个时候需要配合@SequenceGenerator使用
String generator() default "";
}
其中,GenerationType 一共有以下四个值:
复制代码
public enum GenerationType {
//通过表产生主键,框架借由表模拟序列产生主键,使用该策略可以使应用更易于数据库移植。
TABLE,
//通过序列产生主键,通过 @SequenceGenerator 注解指定序列名, MySql 不支持这种方式;
SEQUENCE,
//采用数据库ID自增长, 一般用于mysql数据库
IDENTITY,
//JPA 自动选择合适的策略,是默认选项;
AUTO
}
6.@Enumerated 这个注解很好用,因为它对 enum 提供了下标和 name 两种方式,用法直接映射在 enum 枚举类型的字段上。请看下面源码。
复制代码
@Target({METHOD, FIELD}) //作用在方法和字段上
public @interface Enumerated {
//枚举映射的类型,默认是ORDINAL(即枚举字段的下标)。
EnumType value() default ORDINAL;
}
public enum EnumType {
//映射枚举字段的下标
ORDINAL,
//映射枚举的Name
STRING
}
再来看一个 User 里面关于性别枚举的例子,你就会知道 @Enumerated 在这里没什么作用了,如下所示:
复制代码
//有一个枚举类,用户的性别
public enum Gender {
MAIL("男性"), FMAIL("女性");
private String value;
private Gender(String value) {
this.value = value;
}
}
//实体类@Enumerated的写法如下
@Entity
@Table(name = "tb_user")
public class User implements Serializable {
@Enumerated(EnumType.STRING)
@Column(name = "user_gender")
private Gender gender;
.......................
}
这时候插入两条数据,数据库里面的值会变成 MAIL/FMAIL,而不是“男性” / 女性。
经验分享: 如果我们用 @Enumerated(EnumType.ORDINAL),这时候数据库里面的值是 0、1。但是实际工作中,不建议用数字下标,因为枚举里面的属性值是会不断新增的,如果新增一个,位置变化了就惨了。并且 0、1、2 这种下标在数据库里面看着非常痛苦,时间长了就会一点也看不懂了。
7.@Basic 表示属性是到数据库表的字段的映射。如果实体的字段上没有任何注解,默认即为 @Basic。也就是说默认所有的字段肯定是和数据库进行映射的,并且默认为 Eager 类型。
复制代码
public @interface Basic {
//可选,EAGER(默认):立即加载;LAZY:延迟加载。(LAZY主要应用在大字段上面)
FetchType fetch() default EAGER;
//可选。这个字段是否可以为null,默认是true。
boolean optional() default true;
}
8.@Transient 表示该属性并非一个到数据库表的字段的映射,表示非持久化属性。JPA 映射数据库的时候忽略它,与 @Basic 有相反的作用。也就是每个字段上面 @Transient 和 @Basic 必须二选一,而什么都不指定的话,默认是 @Basic。
9.@Column 定义该属性对应数据库中的列名。
复制代码
public @interface Column {
//数据库中的表的列名;可选,如果不填写认为字段名和实体属性名一样。
String name() default "";
//是否唯一。默认flase,可选。
boolean unique() default false;
//数据字段是否允许空。可选,默认true。
boolean nullable() default true;
//执行insert操作的时候是否包含此字段,默认,true,可选。
boolean insertable() default true;
//执行update的时候是否包含此字段,默认,true,可选。
boolean updatable() default true;
//表示该字段在数据库中的实际类型。
String columnDefinition() default "";
//数据库字段的长度,可选,默认255
int length() default 255;
}
10.@Temporal 用来设置 Date 类型的属性映射到对应精度的字段,存在以下三种情况:
- @Temporal(TemporalType.DATE)映射为日期 // date (只有日期)
- @Temporal(TemporalType.TIME)映射为日期 // time (只有时间)
- @Temporal(TemporalType.TIMESTAMP)映射为日期 // date time (日期+时间)
我们看一个完整的例子,感受一下上面提到的注解的完整用法,如下:
复制代码
package com.example.jpa.example1;
import lombok.Data;
import javax.persistence.*;
import java.util.Date;
@Entity
@Table(name = "user_topic")
@Access(AccessType.FIELD)
@Data
public class UserTopic {
@Id
@Column(name = "id", nullable = false)
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
@Column(name = "title", nullable = true, length = 200)
private String title;
@Basic
@Column(name = "create_user_id", nullable = true)
private Integer createUserId;
@Basic(fetch = FetchType.LAZY)
@Column(name = "content", nullable = true, length = -1)
@Lob
private String content;
@Basic(fetch = FetchType.LAZY)
@Column(name = "image", nullable = true)
@Lob
private byte[] image;
@Basic
@Column(name = "create_time", nullable = true)
@Temporal(TemporalType.TIMESTAMP)
private Date createTime;
@Basic
@Column(name = "create_date", nullable = true)
@Temporal(TemporalType.DATE)
private Date createDate;
@Enumerated(EnumType.STRING)
@Column(name = "topic_type")
private Type type;
@Transient
private String transientSimple;
//非数据库映射字段,业务类型的字段
public String getTransientSimple() {
return title + "auto:jack" + type;
}
//有一个枚举类,主题的类型
public enum Type {
EN("英文"), CN("中文");
private final String des;
Type(String des) {
this.des = des;
}
}
}
细心的同学就会发现,我们在一开始的 demo 里面没有这么多注解呀,其实这里面的很多注解都可以省略,直接使用默认的就可以。如 @Basic、@Column 名字有一定的映射策略(我们在第 17 课时讲 DataSource 的时候会详细讲解映射策略),所以可以省略。
此外,@Access 也可以省略,我们只要在这些类里面保持一致就可以了。可能你会有疑问了,这么多注解都要手动一个一个配置吗?老师介绍一种简单的做法——利用工具去生成 Entity 类,将会节省很多时间。
生成这些注解的小技巧
有时候老的 Table 非常多,我们一个一个去写 entity 会特别累,因此我们可以利用 IEDA 工具直接帮我们生成 Entity 类。关键步骤如下。
首先,打开 Persistence 视图,点击 Generate Persistence Mapping>,接着点击选中数据源,如下图所示:
然后,选择表和字段,并点击 OK。
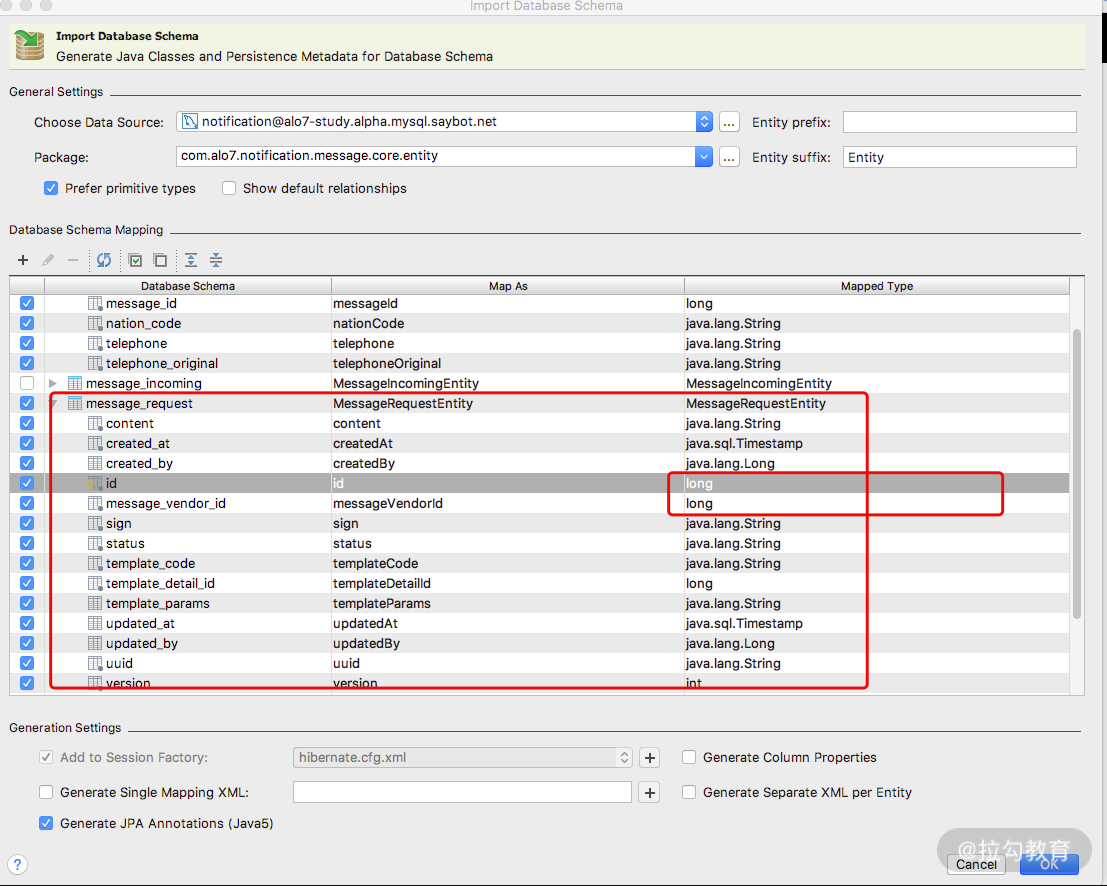
这样就可以生成我们想要的实体了,多简单。如果是新库、新表,我们也可以先定义好实体,通过实体配置JPA的spring.jpa.generate-ddl=true,反向直接生成 DDL 操作数据库生成表结构。
但是需要注意的是,在生产环境中我们要把外间关联关系关闭,不然会出现意想不到的 ERROR,毕竟生产环境不同开发环境,我们可以通过在开发环境生成的表导出 DDL 到生产执行。我经常会利用生成 DDL 来做测试和写案例, 这样省去了创建表的时间,只需要关注我的代码就行了。
接下来我们再把工作中最常见的联合 ID 字段的场景详细讲解一下。
联合主键
在实际的工作中,我们会经常遇到联合主键的情况。所以在这里我们详细讲解一下,可以通过 javax.persistence.EmbeddedId 和 javax.persistence.IdClass 两个注解实现联合主键的效果。
如何通过 @IdClass 做到联合主键?
我们先看一下怎么通过 @IdClass 做到联合主键。
第一步:新建一个 UserInfoID 类里面是联合主键。
复制代码
package com.example.jpa.example1;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class UserInfoID implements Serializable {
private String name,telephone;
}
第二步:再新建一个 UserInfo 的实体,采用 @IdClass 引用联合主键类。
复制代码
@Entity
@Data
@Builder
@IdClass(UserInfoID.class)
@AllArgsConstructor
@NoArgsConstructor
public class UserInfo {
private Integer ages;
@Id
private String name;
@Id
private String telephone;
}
第三步:新增一个 UserInfoReposito 类来做 CRUD 操作。
复制代码
package com.example.jpa.example1;
import org.springframework.data.jpa.repository.JpaRepository;
public interface UserInfoRepository extends JpaRepository<UserInfo,UserInfoID> {
}
第四步:写一个测试用例,测试一下。
复制代码
package com.example.jpa.example1;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.autoconfigure.orm.jpa.DataJpaTest;
import java.util.Optional;
@DataJpaTest
public class UserInfoRepositoryTest {
@Autowired
private UserInfoRepository userInfoRepository;
@Test
public void testIdClass() {
userInfoRepository.save(UserInfo.builder().ages(1).name("jack").telephone("123456789").build());
Optional<UserInfo> userInfo = userInfoRepository.findById(UserInfoID.builder().name("jack").telephone("123456789").build());
System.out.println(userInfo.get());
}
}
Hibernate: create table user_info (name varchar(255) not null, telephone varchar(255) not null, ages integer, primary key (name, telephone))
Hibernate: select userinfo0_.name as name1_3_0_, userinfo0_.telephone as telephon2_3_0_, userinfo0_.ages as ages3_3_0_ from user_info userinfo0_ where userinfo0_.name=? and userinfo0_.telephone=?
UserInfo(ages=1, name=jack, telephone=123456789)
通过上面的例子我们可以发现,我们的表的主键是 primary key (name, telephone),而 Entity 里面不再是一个 @Id 字段了。那么我来介绍另外一个注解 @Embeddable,也能做到这一点。
@Embeddable 与 @EmbeddedId 注解使用
第一步:在我们上面例子中的 UserInfoID 里面添加 @Embeddable 注解。
复制代码
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@Embeddable
public class UserInfoID implements Serializable {
private String name,telephone;
}
第二步:改一下我们刚才的 User 对象,删除 @IdClass,添加 @EmbeddedId 注解,如下:
复制代码
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class UserInfo {
private Integer ages;
@EmbeddedId
private UserInfoID userInfoID;
@Column(unique = true)
private String uniqueNumber;
}
第三步:UserInfoRepository 不变,我们直接修改一下测试用例。
复制代码
@Test
public void testIdClass() {
userInfoRepository.save(UserInfo.builder().ages(1).userInfoID(UserInfoID.builder().name("jack").telephone("123456789").build()).build());
Optional<UserInfo> userInfo = userInfoRepository.findById(UserInfoID.builder().name("jack").telephone("123456789").build());
System.out.println(userInfo.get());
}
运行完之后,你可以得到相同的结果。那么 @IdClass 和 @EmbeddedId 的区别是什么?有以下两个方面:
- 如上面测试用例,在使用的时候,Embedded 用的是对象,而 IdClass 用的是具体的某一个字段;
- 二者的JPQL 也会不一样:
① 用 @IdClass JPQL 的写法:SELECT u.name FROM UserInfo u
② 用 @EmbeddedId 的 JPQL 的写法:select u.userInfoId.name FROM UserInfo u
联合主键还有需要注意的就是,它与唯一性索引约束的区别是写法不同,如上面所讲,唯一性索引的写法如下:
复制代码
@Column(unique = true)
private String uniqueNumber;
到这里,联合主键我们讲完了,那么在遇到联合主键的时候,利用 @IdClass、@EmbeddedId,你就可以应对联合主键了。
此外,Java 是面向对象的,肯定会用到多态的使用场景,那么场景都有哪些?公共父类又该如何写?我们来学习一下。
实体之间的继承关系如何实现?
在 Java 面向对象的语言环境中,@Entity 之间的关系多种多样,而根据 JPA 的规范,我们大致可以将其分为以下几种:
- 纯粹的继承,和表没关系,对象之间的字段共享。利用注解 @MappedSuperclass,协议规定父类不能是 @Entity。
- 单表多态问题,同一张 Table,表示了不同的对象,通过一个字段来进行区分。利用
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)注解完成,只有父类有 @Table。 - 多表多态,每一个子类一张表,父类的表拥有所有公用字段。通过
@Inheritance(strategy = InheritanceType.JOINED)注解完成,父类和子类都是表,有公用的字段在父表里面。 - Object 的继承,数据库里面每一张表是分开的,相互独立不受影响。通过
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)注解完成,父类(可以是一张表,也可以不是)和子类都是表,相互之间没有关系。
其中,第一种 @MappedSuperclass,我们暂时不多介绍,在第 12 课时讲解“JPA 的审计功能”时,再做详细介绍,我们先看一下第二种SINGLE_TABLE。
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
父类实体对象与各个子实体对象共用一张表,通过一个字段的不同值代表不同的对象,我们看一个例子。
我们抽象一个 Book 对象,如下所示:
复制代码
package com.example.jpa.example1.book;
import lombok.Data;
import javax.persistence.*;
@Entity(name="book")
@Data
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name="color", discriminatorType = DiscriminatorType.STRING)
public class Book {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
private String title;
}
再新建一个 BlueBook 对象,作为 Book 的子对象。
复制代码
package com.example.jpa.example1.book;
import lombok.Data;
import lombok.EqualsAndHashCode;
import javax.persistence.DiscriminatorValue;
import javax.persistence.Entity;
@Entity
@Data
@EqualsAndHashCode(callSuper=false)
@DiscriminatorValue("blue")
public class BlueBook extends Book{
private String blueMark;
}
再新建一个 RedBook 对象,作为 Book 的另一子对象。
复制代码
//红皮书
@Entity
@DiscriminatorValue("red")
@Data
@EqualsAndHashCode(callSuper=false)
public class RedBook extends Book {
private String redMark;
}
这时,我们一共新建了三个 Entity 对象,其实都是指 book 这一张表,通过 book 表里面的 color 字段来区分红书还是绿书。我们继续做一下测试看看结果。
我们再新建一个 RedBookRepositor 类,操作一下 RedBook 会看到如下结果:
复制代码
package com.example.jpa.example1.book;
import org.springframework.data.jpa.repository.JpaRepository;
public interface RedBookRepository extends JpaRepository<RedBook,Long>{
}
然后再新建一个测试用例。
复制代码
package com.example.jpa.example1;
import com.example.jpa.example1.book.RedBook;
import com.example.jpa.example1.book.RedBookRepository;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.autoconfigure.orm.jpa.DataJpaTest;
@DataJpaTest
public class RedBookRepositoryTest {
@Autowired
private RedBookRepository redBookRepository;
@Test
public void testRedBook() {
RedBook redBook = new RedBook();
redBook.setTitle("redbook");
redBook.setRedMark("redmark");
redBook.setId(1L);
redBookRepository.saveAndFlush(redBook);
RedBook r = redBookRepository.findById(1L).get();
System.out.println(r.getId()+":"+r.getTitle()+":"+r.getRedMark());
}
}
最后看一下执行结果。
复制代码
Hibernate: create table book (color varchar(31) not null, id bigint not null, title varchar(255), blue_mark varchar(255), red_mark varchar(255), primary key (id))
你会发现,我们只创建了一张表,insert 了一条数据,但是我们发现 color 字段默认给的是 red。
复制代码
Hibernate: insert into book (title, red_mark, color, id) values (?, ?, 'red', ?)
那么再看一下打印结果。
复制代码
1:redbook:redmark
结果完全和预期的一样,这说明了 RedBook、BlueBook、Book,都是一张表,通过字段 color 的值不一样,来区分不同的实体。
那么接下来我们看一下 InheritanceType.JOINED,它的每个实体都是独立的表。
@Inheritance(strategy = InheritanceType.JOINED)
在这种映射策略里面,继承结构中的每一个实体(entity)类都会映射到数据库里一个单独的表中。也就是说,每个实体(entity)都会被映射到数据库中,一个实体(entity)类对应数据库中的一个表。
其中根实体(root entity)对应的表中定义了主键(primary key),所有的子类对应的数据库表都要共同使用 Book 里面的 @ID 这个主键。
首先,我们改一下上面的三个实体,测试一下InheritanceType.JOINED,改动如下:
复制代码
package com.example.jpa.example1.book;
import lombok.Data;
import javax.persistence.*;
@Entity(name="book")
@Data
@Inheritance(strategy = InheritanceType.JOINED)
public class Book {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
private String title;
}
其次,我们 Book 父类、改变 Inheritance 策略、删除 DiscriminatorColumn,你会看到如下结果。
复制代码
package com.example.jpa.example1.book;
import lombok.Data;
import lombok.EqualsAndHashCode;
import javax.persistence.Entity;
import javax.persistence.PrimaryKeyJoinColumn;
@Entity
@Data
@EqualsAndHashCode(callSuper=false)
@PrimaryKeyJoinColumn(name = "book_id", referencedColumnName = "id")
public class BlueBook extends Book{
private String blueMark;
}
package com.example.jpa.example1.book;
import lombok.Data;
import lombok.EqualsAndHashCode;
import javax.persistence.Entity;
import javax.persistence.PrimaryKeyJoinColumn;
@Entity
@PrimaryKeyJoinColumn(name = "book_id", referencedColumnName = "id")
@Data
@EqualsAndHashCode(callSuper=false)
public class RedBook extends Book {
private String redMark;
}
然后,BlueBook和RedBook也删除DiscriminatorColumn,新增@PrimaryKeyJoinColumn(name = “book_id”, referencedColumnName = “id”),和 book 父类共用一个主键值,而 RedBookRepository 和测试用例不变,我们执行看一下结果。
复制代码
Hibernate: create table blue_book (blue_mark varchar(255), book_id bigint not null, primary key (book_id))
Hibernate: create table book (id bigint not null, title varchar(255), primary key (id))
Hibernate: create table red_book (red_mark varchar(255), book_id bigint not null, primary key (book_id))
Hibernate: alter table blue_book add constraint FK9uuwgq7a924vtnys1rgiyrlk7 foreign key (book_id) references book
Hibernate: alter table red_book add constraint FKk8rvl61bjy9lgsr9nhxn5soq5 foreign key (book_id) references book
上述代码可以看到,我们一共创建了三张表,并且新增了两个外键约束;而我们 save 的时候也生成了两个 insert 语句,如下:
复制代码
Hibernate: insert into book (title, id) values (?, ?)
Hibernate: insert into red_book (red_mark, book_id) values (?, ?)
而打印结果依然不变。
复制代码
1:redbook:redmark
这就是 InheritanceType.JOINED 的例子,这个方法和上面的 InheritanceType.SINGLE_TABLE 区别在于表的数量和关系不一样,这是表设计的另一种方式。
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
我们在使用 @MappedSuperClass 主键的时候,如果不指定 @Inhertance,默认就是此种TABLE_PER_CLASS模式。当然了,我们也显示指定,要求继承基类的都是一张表,而父类不是表,是 java 对象的抽象类。我们看一个例子。
首先,还是改一下上面的三个实体。
复制代码
package com.example.jpa.example1.book;
import lombok.Data;
import javax.persistence.*;
@Entity(name="book")
@Data
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
public class Book {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
private String title;
}
其次,Book 表采用 TABLE_PER_CLASS 策略,其子实体类都代表各自的表,实体代码如下:
复制代码
package com.example.jpa.example1.book;
import lombok.Data;
import lombok.EqualsAndHashCode;
import javax.persistence.Entity;
@Entity
@Data
@EqualsAndHashCode(callSuper=false)
public class RedBook extends Book {
private String redMark;
}
package com.example.jpa.example1.book;
import lombok.Data;
import lombok.EqualsAndHashCode;
import javax.persistence.Entity;
@Entity
@Data
@EqualsAndHashCode(callSuper=false)
public class BlueBook extends Book{
private String blueMark;
}
这时,从 RedBook 和 BlueBook 里面去掉 PrimaryKeyJoinColumn,而 RedBookRepository 和测试用例不变,我们执行看一下结果。
复制代码
Hibernate: create table blue_book (id bigint not null, title varchar(255), blue_mark varchar(255), primary key (id))
Hibernate: create table book (id bigint not null, title varchar(255), primary key (id))
Hibernate: create table red_book (id bigint not null, title varchar(255), red_mark varchar(255), primary key (id))
这里可以看到,我们还是创建了三张表,但三张表什么关系也没有。而 insert 语句也只有一条,如下:
复制代码
Hibernate: insert into red_book (title, red_mark, id) values (?, ?, ?)
打印结果还是不变。
复制代码
1:redbook:redmark
这个方法与上面两个相比较,语义更加清晰,是比较常用的一种做法。
以上就是实体之间继承关系的实现方法,可以在涉及 java 多态的时候加以应用,不过要注意区分三种方式所表达的表的意思,再加以运用。
关于继承关系的经验之谈
从我的个人经验来看,@Inheritance 的这种使用方式会逐渐被淘汰,因为这样的表的设计很复杂,本应该在业务层面做的事情(多态),而在 datasoure 的表级别做了。所以在 JPA 中使用这个的时候你就会想:“这么复杂的东西,我直接用 Mybatis 算了。”我想告诉你,其实它们是一样的,只是我们使用的思路不对。
那么为什么行业内都不建议使用了,还要介绍这么详细呢?因为,如果你遇到的是老一点的项目,如果不是用 Java 语言写的,不一定有面向对象的思想。这个时候如果让你迁移成 Java 怎么办?如果你可以想到这种用法,就不至于束手无措。
此外,在互联网项目中,一旦有关表的业务对象过多了之后,就可以拆表拆库了,这个时候我们要想到我们的@Table 注解指定表名和 schema。
关于上面提到的方法中,最常用的是第一种 @MappedSuperclass,这个我们将在第 12 课时“JPA 的审计功能解决了哪些问题?”中详细介绍,到时候你可以体验一下它的不同之处。