Kafka进阶
Kafka事务
kafka的事务机制是指kafka支持跨多个主题和分区的原子性写入,即在一个事务中发送的所有消息要么全部成功,要么全部失败。
kafka的事务机制涉及到以下几个方面:
- 事务生产者(transactional producer):可以在一个事务中发送多个消息到不同的主题和分区,也可以从其他主题消费消息并发送到新的主题(实现流处理)。事务生产者需要指定一个唯一的transactional.id,用于标识不同的事务。
- 事务消费者(transactional consumer):可以消费事务生产者发送的消息,并且只有当事务提交后才能看到这些消息。事务消费者需要设置isolation.level为read_committed,以过滤掉未提交或中止的事务消息。
- 事务协调器(transaction coordinator):是运行在每个kafka broker上的一个模块,负责管理和分配ProducerID,维护每个transactional.id对应的事务状态,以及处理事务的提交或中止。
- 事务日志(transaction log):是kafka的一个内部主题,用于存储每个transactional.id对应的事务元数据,包括ProducerID、epoch、分区列表、状态等。¹²
kafka的事务机制大致流程如下:
- 事务生产者调用initTransactions方法,向集群请求一个ProducerID,并找到对应的事务协调器。
- 事务生产者调用beginTransaction方法,向事务协调器发送开始事务的请求,并递增epoch。
- 事务生产者调用send方法,向目标主题和分区发送消息,并将这些分区注册到事务协调器。
- 事务生产者调用commitTransaction或abortTransaction方法,向事务协调器发送提交或中止事务的请求,并将控制消息写入到已注册的分区中。
- 事务协调器根据控制消息和事务状态,决定是否将该事务标记为已提交或已中止,并更新事务日志。
- 事务消费者根据isolation.level设置,只消费已提交的事务消息,并忽略未提交或已中止的事务消息。
Kafka生产者幂等性
幂等性介绍
Kafka的幂等性是指生产者在发送消息时,可以保证同一个消息不会被重复写入到同一个分区中,即使发生了网络错误或者重试;
幂等性原理
Kafka的幂等性是基于生产者的ID和序号来实现的,每个生产者都有一个唯一的ID和一个递增的序号,当生产者发送消息时,会把这两个信息附加到消息中,当分区收到消息时,会根据这两个信息来判断是否是重复的消息。
Kafka的幂等性只能保证单个分区内的消息不重复,不能保证跨分区或跨主题的消息不重复。如果要实现更强的事务保证,需要使用Kafka的事务机制。
分区机制
分区的文件存储形式
Kafka分区中的文件是按照一定的规则进行存储的,主要有以下几个特点:
- 每个分区对应一个日志文件夹(log file),日志文件中存储的是生产者发送的消息。
- 日志文件又被分成多个段文件(segment file),每个段文件都有固定的大小限制,当达到限制时,就会关闭当前段文件,创建新的段文件。
- 段文件由两部分组成:一个是存储消息内容的“.log”文件,另一个是存储消息位置信息的“.index”文件。
- “.index”文件是稀疏索引文件,它记录了消息的偏移量(offset)和物理位置(position)之间的映射关系,方便消费者快速定位消息。
- 消息在日志文件中是顺序追加的,消息在分区中也是有序的,每个消息都有一个递增的偏移量,偏移量在分区内是唯一的。
- Kafka会定期删除过期的或者超过大小限制的段文件,以回收磁盘空间。删除策略可以根据时间或者大小来配置。
消费者如何消费分区
- 消费者消费数据时,首先需要知道自己要消费的分区和偏移量
- 分区是由消费者组(Consumer Group)内部的分区分配策略(Partition Assignor)来决定的,不同的策略会有不同的分配逻辑
- 偏移量是由消费者自己维护的,每次消费完一批消息后,消费者会把当前的偏移量提交到 Kafka 或者其他存储中,下次消费时会从上次提交的偏移量开始继续消费
- 当消费者知道了要消费的分区和偏移量后,它会向分区的 Leader Broker 发送拉取请求,请求从指定的偏移量开始拉取一批消息。
- Leader Broker 收到请求后,会根据偏移量在“.index”文件中查找对应的物理位置(Position),然后从“.log”文件中读取一批消息返回给消费者。
这样,消费者就可以在多个段文件中找到自己要消费的数据了。
生产者分区写入策略
按key分配策略(默认)
它会根据消息的键(key)来计算一个哈希值,并根据哈希值对分区数取模,得到目标分区的编号。如果消息没有键,或者键为空,它会随机选择一个可用的分区。
轮询策略
轮询的分区写入策略,它会按照分区的顺序依次将消息发送到每个分区上,不考虑消息的键或者值。这种策略可以实现消息的均匀分布。
自定义分区策略
自行实现Partitioner接口,自定义分区策略。
指定分区(与写入策略无关)
手动指定写入哪个分区。
随机策略(较早版本)
随机写入某个分区。
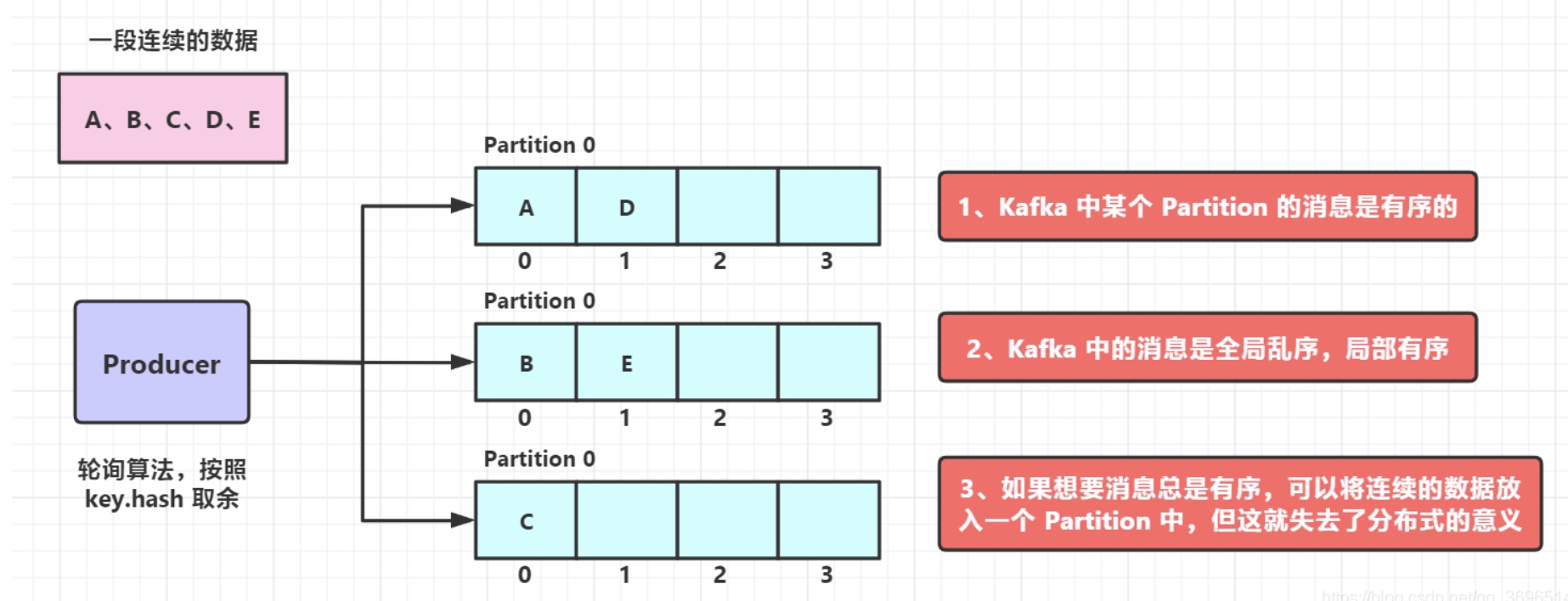
消息乱序问题
- 轮询策略和随机策略,造成kafka中的数据是乱序存储的
- 按 key 分区,一定程度上可以实现数据的有序存储——局部有序,但是又可能会造成数据倾斜
Producer的ACKs参数
producer配置的acks参数了,acks参数表示当生产者生产消息的时候,写入到副本的要求严格程度。它决定了生产者如何在性能和可靠性之间做取舍。
acks有3个值可选 0、1和-1(或者all),默认值为1,值为字符串类型,不是整数类型
-
0:producer发送后即为成功,无需分区partition的leader确认写入成功,性能最高
-
1:producer发送后需要接收到partition的leader发送确认收到的回复,性能中等
-
-1或者all:producer发送后,需要ISR中所有副本都成功写入成功才能收到成功响应,性能最慢
分区的leader与follower机制
AR、ISR、OSR
在实际环境中,leader有可能会出现一些故障,所以Kafka一定会选举出新的leader。在讲解leader选举之前,我们先要明确几个概念。Kafka中,把follower可以按照不同状态分为三类——AR、ISR、OSR
- AR(Assigned Replicas) 分区的所有副本
- ISR(In-Sync Replicas) 所有与leader副本保持一定程度同步的副本(包括 leader 副本)
- OSR(Out-of-Sync Replias) 由于follower副本同步滞后过多的副本(不包括 leader 副本)
AR = ISR + OSR, 正常情况下,所有的follower副本都应该与leader副本保持同步,即AR = ISR,OSR集合为空。
Leader选举
-
kafka启动时,会在所有的broker中选择一个controller,controller的选举由broker竞争决定。controller会负责创建topic、或者添加分区、修改副本数量之类的管理任务,包括leader的选举。controller也是高可用的,一旦某个broker崩溃,其他的broker会重新注册为controller
-
controller读取到当前分区的ISR,只要有一个Replica还幸存,就选择其中一个作为leader否则,则任意选这个一个Replica作为leader
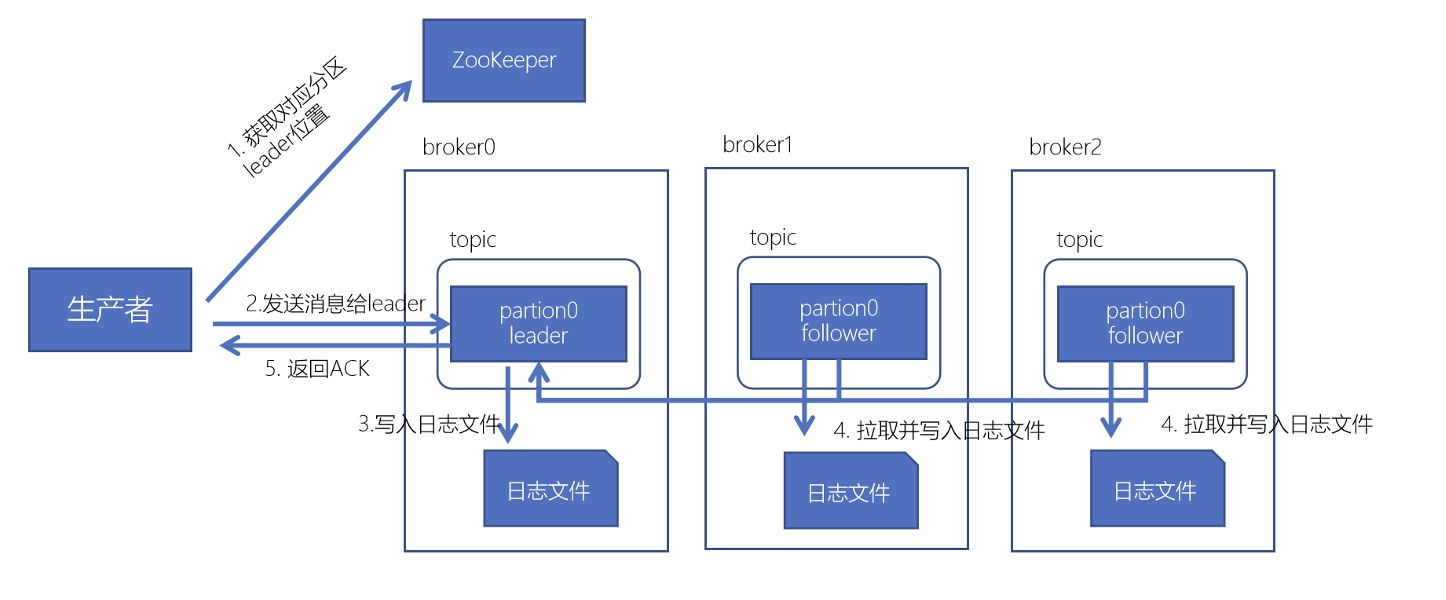
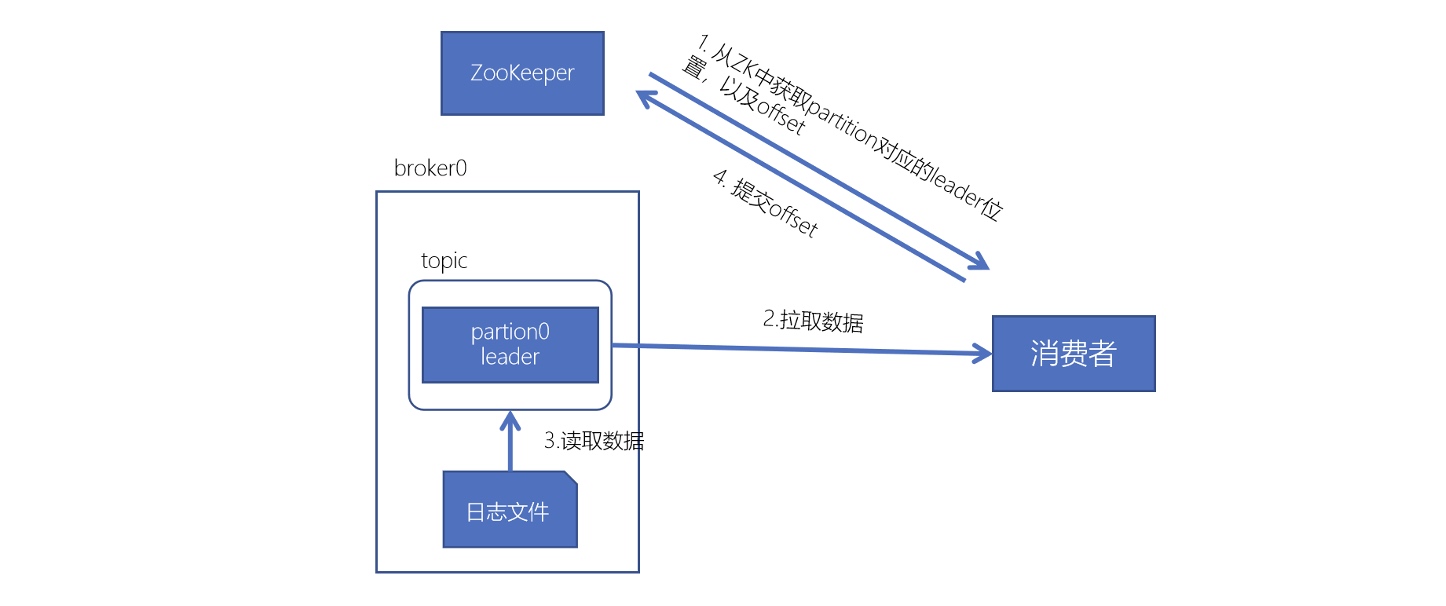
Kafka生产、消费数据工作流程
Kafka数据写入流程
Kafka数据消费流程
消息不丢失机制
broker数据不丢失
生产者通过分区的leader写入数据后,所有在ISR中follower都会从leader中复制数据,这样,可以确保即使leader崩溃了,其他的follower的数据仍然是可用的
生产者数据不丢失
通过ACK机制来确保数据已经成功写入。
消费者数据不丢失
在消费者消费数据的时候,只要每个消费者记录好offset值即可,就能保证数据不丢失。offset值记录在zk中。