天猫用户重复购买预测(二)
- 模型训练
- 分类相关模型
- 1、逻辑回归分类模型
- 2、K近邻分类模型
- 3、高斯贝叶斯分类模型
- 4、决策树分类模型
- 5、集成学习分类模型
- 模型验证
- 模型验证指标
- 特征优化
- 特征选择技巧
- 1、搜索算法
- 2、特征选择方法
模型训练
分类相关模型
1、逻辑回归分类模型

from sklearn.linear_model import LinearRegression
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
stdScaler = StandardScaler()
X = stdScaler.fit_transform(train)
# Split the data into a training set and a test set
X_train, X_test, y_train, y_test = train_test_split(X, target, random_state=0)
clf = LogisticRegression(random_state=0, solver='lbfgs', multi_class='multinomial').fit(X_train, y_train)
clf.score(X_test, y_test)
2、K近邻分类模型

from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
stdScaler = StandardScaler()
X = stdScaler.fit_transform(train)
# Split the data into a training set and a test set
X_train, X_test, y_train, y_test = train_test_split(X, target, random_state=0)
clf = KNeighborsClassifier(n_neighbors=3).fit(X_train, y_train)
clf.score(X_test, y_test)
3、高斯贝叶斯分类模型

4、决策树分类模型
from sklearn import tree
# Split the data into a training set and a test set
X_train, X_test, y_train, y_test = train_test_split(train, target, random_state=0)
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X_train, y_train)
clf.score(X_test, y_test)
5、集成学习分类模型
集成学习分类模型主要包括Bagging、Boosting、 集成学习投票法、随机森林、LightGBM、极端随机树(ExtraTree, ET) 等常用方法和模型。
Bagging:

from sklearn.ensemble import BaggingClassifier
from sklearn.neighbors import KNeighborsClassifier
# Split the data into a training set and a test set
X_train, X_test, y_train, y_test = train_test_split(train, target, random_state=0)
clf = BaggingClassifier(KNeighborsClassifier(), max_samples=0.5, max_features=0.5)
clf = clf.fit(X_train, y_train)
clf.score(X_test, y_test)
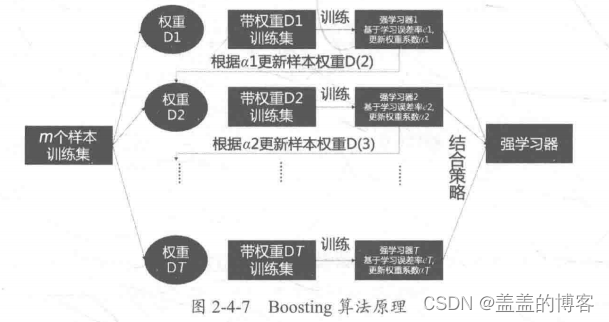
Boosting:
from sklearn.ensemble import GradientBoostingClassifier
# Split the data into a training set and a test set
X_train, X_test, y_train, y_test = train_test_split(train, target, random_state=0)
clf = GradientBoostingClassifier(n_estimators=10, learning_rate=1.0, max_depth=1, random_state=0)
clf = clf.fit(X_train, y_train)
clf.score(X_test, y_test)
集成学习投票法:
集成学习投票法的特点:
●绝对多数投票法:某标记超过半数。
●相对多数投票法:预测为得票最多的标记,若同时有多个标记的票最高,则从中随机选取一个。
●加权投票法: 提供了预测结果,与加权平均法类似。
from sklearn import datasets
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.preprocessing import StandardScaler
stdScaler = StandardScaler()
X = stdScaler.fit_transform(train)
y = target
clf1 = LogisticRegression(solver='lbfgs', multi_class='multinomial', random_state=1)
clf2 = RandomForestClassifier(n_estimators=50, random_state=1)
clf3 = GaussianNB()
eclf = VotingClassifier(estimators=[('lr', clf1), ('rf', clf2), ('gnb', clf3)], voting='hard')
for clf, label in zip([clf1, clf2, clf3, eclf], ['Logistic Regression', 'Random Forest', 'naive Bayes', 'Ensemble']):
scores = cross_val_score(clf, X, y, cv=5, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))
随机森林:
from sklearn.ensemble import RandomForestClassifier
# Split the data into a training set and a test set
X_train, X_test, y_train, y_test = train_test_split(train, target, random_state=0)
clf = clf = RandomForestClassifier(n_estimators=10, max_depth=3, min_samples_split=12, random_state=0)
clf = clf.fit(X_train, y_train)
clf.score(X_test, y_test)
LightGBM:
LightGBM分类模型和前面介绍过的LightGBM回归模型相似,它可以支持高效率的并行训练,具有更快的训练速度、更低的内存消耗、更好的准确率、分布式支持、可以快速。
import lightgbm
X_train, X_test, y_train, y_test = train_test_split(train, target, test_size=0.4, random_state=0)
X_test, X_valid, y_test, y_valid = train_test_split(X_test, y_test, test_size=0.5, random_state=0)
clf = lightgbm
train_matrix = clf.Dataset(X_train, label=y_train)
test_matrix = clf.Dataset(X_test, label=y_test)
params = {
'boosting_type': 'gbdt',
#'boosting_type': 'dart',
'objective': 'multiclass',
'metric': 'multi_logloss',
'min_child_weight': 1.5,
'num_leaves': 2**5,
'lambda_l2': 10,
'subsample': 0.7,
'colsample_bytree': 0.7,
'colsample_bylevel': 0.7,
'learning_rate': 0.03,
'tree_method': 'exact',
'seed': 2017,
"num_class": 2,
'silent': True,
}
num_round = 10000
early_stopping_rounds = 100
model = clf.train(params,
train_matrix,
num_round,
valid_sets=test_matrix,
early_stopping_rounds=early_stopping_rounds)
pre= model.predict(X_valid,num_iteration=model.best_iteration)
print('score : ', np.mean((pre[:,1]>0.5)==y_valid))
极端随机树:
也称ET或Extra-Trees,与随机森林算法非常类似,由许多决策树构成。
极端随机树模型与随机森林模型的主要区别:随机森林应用的是Bagging 模型,极端随机树使用所有的训练样本计算每棵决策树。随机森林是在一个随机子集内得到最佳的分叉属性,而极端随机树模型是依靠完全随机得到分叉值,进而实现对决策树进行分叉。
from sklearn.ensemble import ExtraTreesClassifier
# Split the data into a training set and a test set
X_train, X_test, y_train, y_test = train_test_split(train, target, random_state=0)
clf = ExtraTreesClassifier(n_estimators=10, max_depth=None, min_samples_split=2, random_state=0)
clf = clf.fit(X_train, y_train)
clf.score(X_test, y_test)
clf.n_features_
clf.feature_importances_[:10]
AdaBoost模型:
from sklearn.ensemble import AdaBoostClassifier
# Split the data into a training set and a test set
X_train, X_test, y_train, y_test = train_test_split(train, target, random_state=0)
clf = AdaBoostClassifier(n_estimators=10)
clf = clf.fit(X_train, y_train)
clf.score(X_test, y_test)
GDBT模型:
from sklearn.ensemble import GradientBoostingClassifier
# Split the data into a training set and a test set
X_train, X_test, y_train, y_test = train_test_split(train, target, random_state=0)
clf = GradientBoostingClassifier(n_estimators=10, learning_rate=1.0, max_depth=1, random_state=0)
clf = clf.fit(X_train, y_train)
clf.score(X_test, y_test)
XGB模型:
import xgboost
X_train, X_test, y_train, y_test = train_test_split(train, target, test_size=0.4, random_state=0)
X_test, X_valid, y_test, y_valid = train_test_split(X_test, y_test, test_size=0.5, random_state=0)
clf = xgboost
train_matrix = clf.DMatrix(X_train, label=y_train, missing=-1)
test_matrix = clf.DMatrix(X_test, label=y_test, missing=-1)
z = clf.DMatrix(X_valid, label=y_valid, missing=-1)
params = {'booster': 'gbtree',
'objective': 'multi:softprob',
'eval_metric': 'mlogloss',
'gamma': 1,
'min_child_weight': 1.5,
'max_depth': 5,
'lambda': 100,
'subsample': 0.7,
'colsample_bytree': 0.7,
'colsample_bylevel': 0.7,
'eta': 0.03,
'tree_method': 'exact',
'seed': 2017,
"num_class": 2
}
num_round = 10000
early_stopping_rounds = 100
watchlist = [(train_matrix, 'train'),
(test_matrix, 'eval')
]
model = clf.train(params,
train_matrix,
num_boost_round=num_round,
evals=watchlist,
early_stopping_rounds=early_stopping_rounds
)
pre = model.predict(z,ntree_limit=model.best_ntree_limit)
print('score : ', np.mean((pre[:,1]>0.3)==y_valid))
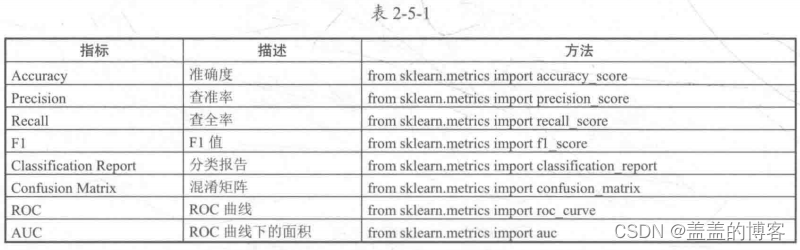
模型验证
模型验证指标
特征优化
特征选择技巧
1、搜索算法
当特征数量较多时,常用如下方法:
穷举法(Exhaustive): 暴力穷尽。
贪心法(Greedy Selection);线性时间。
模拟退火( Simulated Annealing):随机尝试找最优。
基因算法(Genetic Algorithm):组合深度优先尝试。
邻居搜索(Variable Neighbor Search);利用相近关系搜索。
2、特征选择方法
特征选择的方法主要有过滤法(Filter)、 包装法(Wrapper) 和嵌入法( Embedded )。