2023年数学建模竞赛
联合火力分配方案数学建模
不仅在人们的生产实践中,在多目标规划中经常会遇到如何利用现有资源来安排,以取得最大经济效益的问题。此类问题构成了运筹学的一个重要分支—数学规划,而线性规划则是数学规划的一个重要分支。自从提出求解线性规划的单纯形方法以来,线性规划在理论上趋向成熟,在实用中日益广泛与深入。特别是在计算机能处理成千上万个约束条件和决策变量的线性规划问题之后,线性 规划的适用领域更为广泛了,已成为现代管理中经常采用的基本方法之一。
线性规划的 Matlab 标准形式
线性规划的目标函数可以是求最大值,也可以是求最小值,约束条件的不等号可以是小于号也可以是大于号。为了避免这种形式多样性带来的不便,Matla中规定线性规划的标准形式为

其中c和 x为n 维列向量, A、 Aeq 为适当维数的矩阵,b 、beq为适当维数的列向量。
例如线性规划 的 Matlab 标准型为

一般线性规划问题的(数学)标准型为
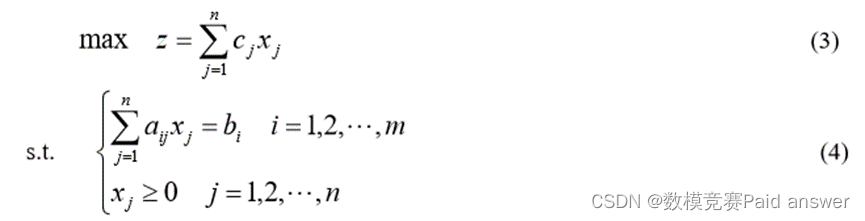
可行解:满足约束条件(4)的解x=(x1,x2,x3,…,xn),称为线性规划问题的可行解,而使目标函数(3)达到最大值的可行解叫最优解。
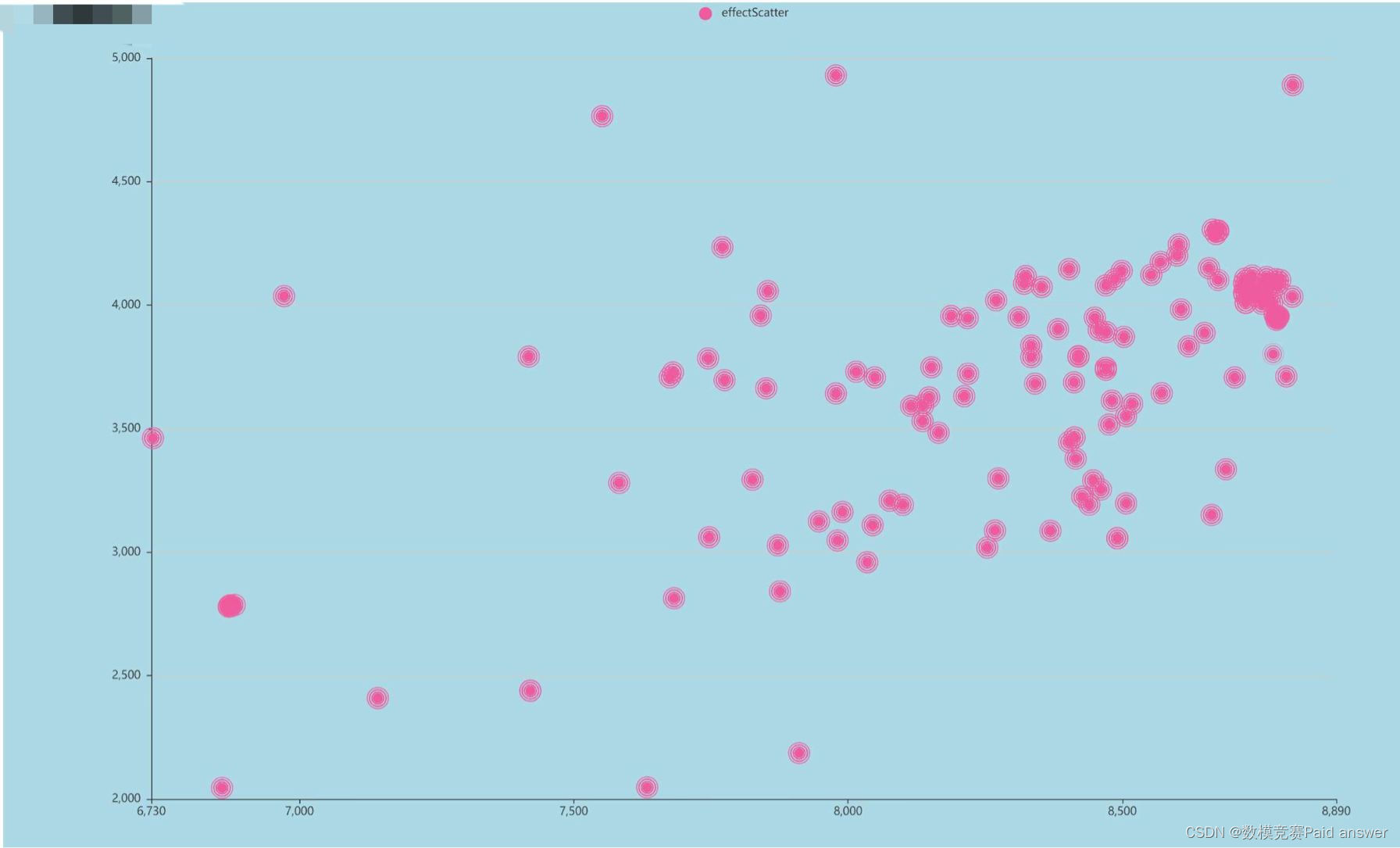
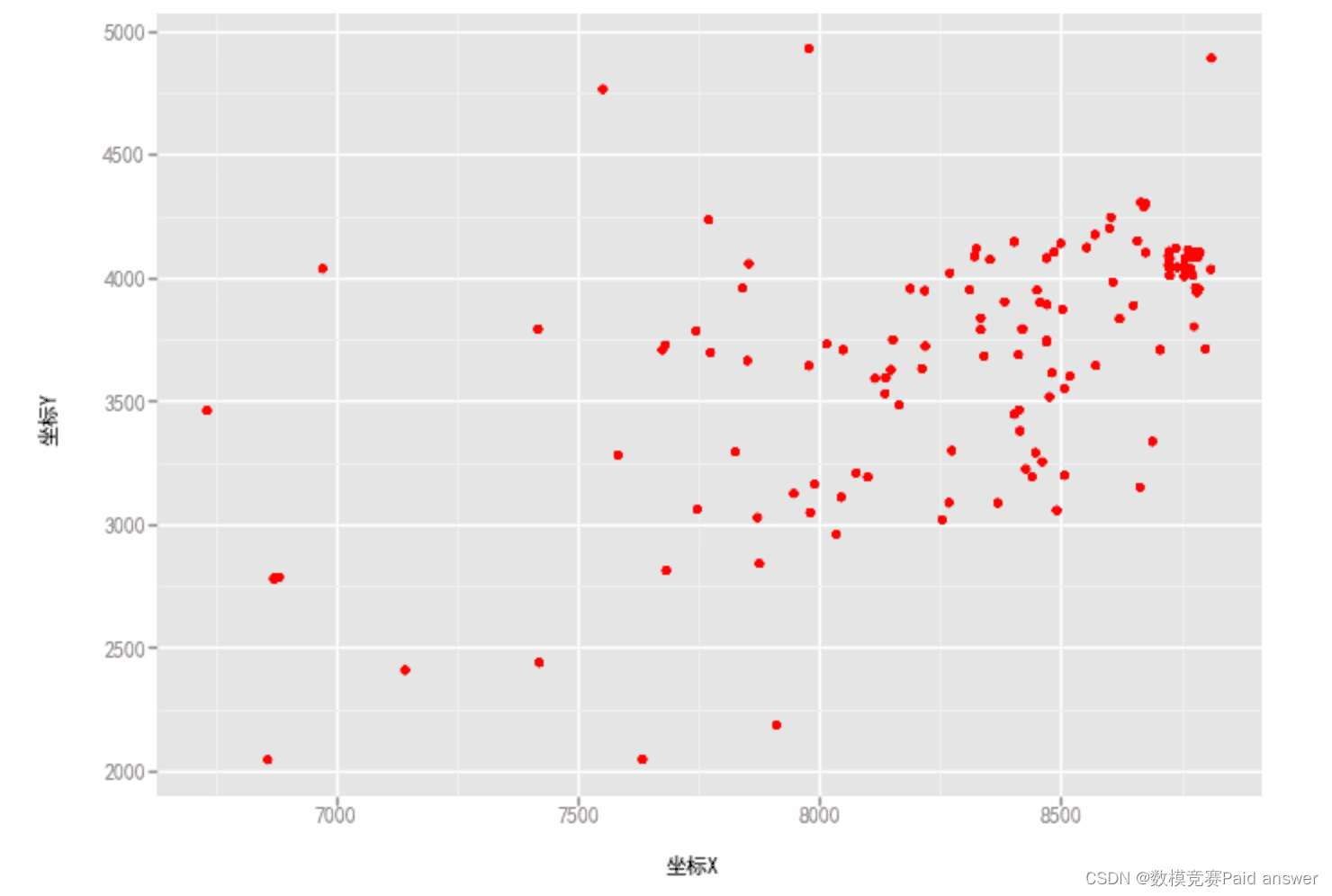
需要图的可自取
import os,math
from tensorflow.keras.layers import Dropout, Dense, SimpleRNN
from sklearn.preprocessing import MinMaxScaler
from sklearn import metrics
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
data = pd.read_csv('./datasets/SH600519.csv') # 读取股票文件
training_set = data.iloc[0:2426 - 300, 2:3].values
test_set = data.iloc[2426 - 300:, 2:3].values
sc = MinMaxScaler(feature_range=(0, 1))
training_set = sc.fit_transform(training_set)
test_set = sc.transform(test_set)
x_train = []
y_train = []
x_test = []
y_test = []
"""
"""
for i in range(60, len(training_set)):
x_train.append(training_set[i - 60:i, 0])
y_train.append(training_set[i, 0])
for i in range(60, len(test_set)):
x_test.append(test_set[i - 60:i, 0])
y_test.append(test_set[i, 0])
# 对训练集进行打乱
np.random.seed(7)
np.random.shuffle(x_train)
np.random.seed(7)
np.random.shuffle(y_train)
tf.random.set_seed(7)
x_train, y_train = np.array(x_train), np.array(y_train) # x_train形状为:(2066, 60, 1)
x_test, y_test = np.array(x_test), np.array(y_test)
"""
输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]
"""
x_train = np.reshape(x_train, (x_train.shape[0], 60, 1))
x_test = np.reshape(x_test, (x_test.shape[0], 60, 1))
model = tf.keras.Sequential([
SimpleRNN(100, return_sequences=True), #布尔值。是返回输出序列中的最后一个输出,还是全部序列。
Dropout(0.1), #防止过拟合
SimpleRNN(100),
Dropout(0.1),
Dense(1)
])
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss='mean_squared_error') # 损失函数用均方误差
history = model.fit(x_train, y_train,
batch_size=64,
epochs=20,
validation_data=(x_test, y_test),
validation_freq=1) #测试的epoch间隔数
model.summary()
predicted_stock_price = model.predict(x_test) # 测试集输入模型进行预测
predicted_stock_price = sc.inverse_transform(predicted_stock_price) # 对预测数据还原---从(0,1)反归一化到原始范围
real_stock_price = sc.inverse_transform(test_set[60:]) # 对真实数据还原---从(0,1)反归一化到原始范围
# 画出真实数据和预测数据的对比曲线
plt.plot(real_stock_price, color='red', label='Stock Price')
plt.plot(predicted_stock_price, color='blue', label='Predicted Stock Price')
plt.title('Stock Price Prediction by K同学啊')
plt.xlabel('Time')
plt.ylabel('Stock Price')
plt.legend()
plt.show()