【ROS】ros-noetic和anaconda联合使用【实操】
文章目录
- 【ROS】ros-noetic和anaconda联合使用【实操】
- 1. requirement
- 2. 新建ros包中的python脚本
- 3. SAC算法
- Reference
在介绍完基本的联合使用方式后(参考 这篇博客),笔者希望使用ros能完成
gym环境中强化学习算法的训练。
1. requirement
需要手动使用pip安装下列包
torch
gym
tqdm
matplotlib
例如pip install gym。
2. 新建ros包中的python脚本
roscd test_ros_python
cd scripts
touch test_python.py
chom +x ./test_python.py
并且记住在CMakeLists.txt文件中完成配置,这里就不再赘述。
3. SAC算法
在完成环境的配置之后,使用Hands on RL 之 Off-policy Maximum Entropy Actor-Critic (SAC)中的代码,放置在test_python.py脚本文件中,如下
#! /usr/bin/env python
# coding :utf-8
print('\n*****************************************\n\t[test libraries]:\n')
import rospy
import sys
sys.path.append('/home/sjh/anaconda3/envs/metaRL/lib/python3.8/site-packages')
print(' - rospy.__file__ = %s'%rospy.__file__)
import torch
import torch.nn as nn
import torch.nn.functional as F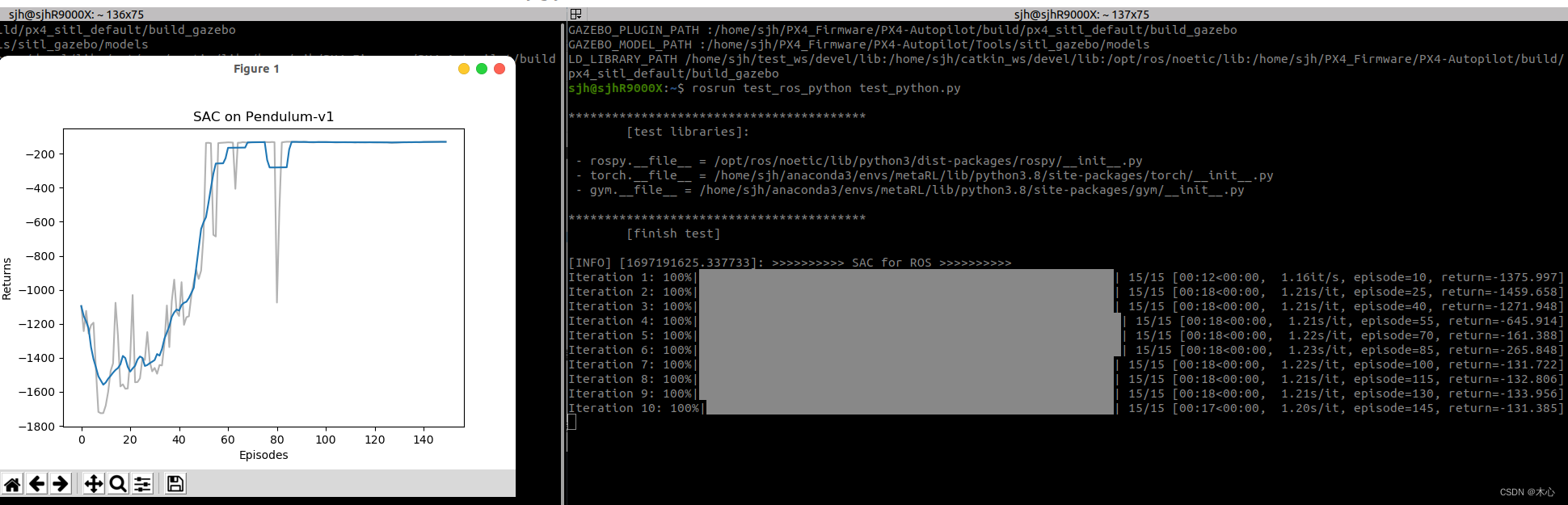
from torch.distributions import Normal
from tqdm import tqdm
import collections
import random
import numpy as np
import matplotlib.pyplot as plt
import gym
print(' - torch.__file__ = %s'%torch.__file__)
print(' - gym.__file__ = %s'%gym.__file__)
print('\n*****************************************\n\t[finish test]\n')
# replay buffer
class ReplayBuffer():
def __init__(self, capacity):
self.buffer = collections.deque(maxlen=capacity)
def add(self, s, r, a, s_, d):
self.buffer.append((s,r,a,s_,d))
def sample(self, batch_size):
transitions = random.sample(self.buffer, batch_size)
states, rewards, actions, next_states, dones = zip(*transitions)
return np.array(states), rewards, actions, np.array(next_states), dones
def size(self):
return len(self.buffer)
# Actor
class PolicyNet_Continuous(nn.Module):
"""动作空间符合高斯分布,输出动作空间的均值mu,和标准差std"""
def __init__(self, state_dim, hidden_dim, action_dim, action_bound):
super(PolicyNet_Continuous, self).__init__()
self.fc1 = nn.Sequential(
nn.Linear(in_features=state_dim, out_features=hidden_dim),
nn.ReLU()
)
self.fc_mu = nn.Linear(in_features=hidden_dim, out_features=action_dim)
self.fc_std = nn.Sequential(
nn.Linear(in_features=hidden_dim, out_features=action_dim),
nn.Softplus()
)
self.action_bound = action_bound
def forward(self, s):
x = self.fc1(s)
mu = self.fc_mu(x)
std = self.fc_std(x)
distribution = Normal(mu, std)
normal_sample = distribution.rsample()
normal_log_prob = distribution.log_prob(normal_sample)
# get action limit to [-1,1]
action = torch.tanh(normal_sample)
# get tanh_normal log probability
tanh_log_prob = normal_log_prob - torch.log(1 - torch.tanh(action).pow(2) + 1e-7)
# get action bounded
action = action * self.action_bound
return action, tanh_log_prob
# Critic
class QValueNet_Continuous(nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim):
super(QValueNet_Continuous, self).__init__()
self.fc1 = nn.Sequential(
nn.Linear(in_features=state_dim + action_dim, out_features=hidden_dim),
nn.ReLU()
)
self.fc2 = nn.Sequential(
nn.Linear(in_features=hidden_dim, out_features=hidden_dim),
nn.ReLU()
)
self.fc_out = nn.Linear(in_features=hidden_dim, out_features=1)
def forward(self, s, a):
cat = torch.cat([s,a], dim=1)
x = self.fc1(cat)
x = self.fc2(x)
return self.fc_out(x)
# maximize entropy deep reinforcement learning SAC
class SAC_Continuous():
def __init__(self, state_dim, hidden_dim, action_dim, action_bound,
actor_lr, critic_lr, alpha_lr, target_entropy, tau, gamma,
device):
# actor
self.actor = PolicyNet_Continuous(state_dim, hidden_dim, action_dim, action_bound).to(device)
# two critics
self.critic1 = QValueNet_Continuous(state_dim, hidden_dim, action_dim).to(device)
self.critic2 = QValueNet_Continuous(state_dim, hidden_dim, action_dim).to(device)
# two target critics
self.target_critic1 = QValueNet_Continuous(state_dim, hidden_dim, action_dim).to(device)
self.target_critic2 = QValueNet_Continuous(state_dim, hidden_dim, action_dim).to(device)
# initialize with same parameters
self.target_critic1.load_state_dict(self.critic1.state_dict())
self.target_critic2.load_state_dict(self.critic2.state_dict())
# specify optimizers
self.optimizer_actor = torch.optim.Adam(self.actor.parameters(), lr=actor_lr)
self.optimizer_critic1 = torch.optim.Adam(self.critic1.parameters(), lr=critic_lr)
self.optimizer_critic2 = torch.optim.Adam(self.critic2.parameters(), lr=critic_lr)
# 使用alpha的log值可以使训练稳定
self.log_alpha = torch.tensor(np.log(0.01), dtype=torch.float, requires_grad = True)
self.optimizer_log_alpha = torch.optim.Adam([self.log_alpha], lr=alpha_lr)
self.target_entropy = target_entropy
self.gamma = gamma
self.tau = tau
self.device = device
def take_action(self, state):
state = torch.tensor(np.array([state]), dtype=torch.float).to(self.device)
action, _ = self.actor(state)
return [action.item()]
# calculate td target
def calc_target(self, rewards, next_states, dones):
next_action, log_prob = self.actor(next_states)
entropy = -log_prob
q1_values = self.target_critic1(next_states, next_action)
q2_values = self.target_critic2(next_states, next_action)
next_values = torch.min(q1_values, q2_values) + self.log_alpha.exp() * entropy
td_target = rewards + self.gamma * next_values * (1-dones)
return td_target
# soft update method
def soft_update(self, net, target_net):
for param_target, param in zip(target_net.parameters(), net.parameters()):
param_target.data.copy_(param_target.data * (1.0-self.tau) + param.data * self.tau)
def update(self, transition_dict):
states = torch.tensor(transition_dict['states'], dtype=torch.float).to(self.device)
rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1,1).to(self.device)
actions = torch.tensor(transition_dict['actions'], dtype=torch.float).view(-1,1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'], dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'], dtype=torch.float).view(-1,1).to(self.device)
rewards = (rewards + 8.0) / 8.0 #对倒立摆环境的奖励进行重塑,方便训练
# update two Q-value network
td_target = self.calc_target(rewards, next_states, dones).detach()
critic1_loss = torch.mean(F.mse_loss(td_target, self.critic1(states, actions)))
critic2_loss = torch.mean(F.mse_loss(td_target, self.critic2(states, actions)))
self.optimizer_critic1.zero_grad()
critic1_loss.backward()
self.optimizer_critic1.step()
self.optimizer_critic2.zero_grad()
critic2_loss.backward()
self.optimizer_critic2.step()
# update policy network
new_actions, log_prob = self.actor(states)
entropy = - log_prob
q1_value = self.critic1(states, new_actions)
q2_value = self.critic2(states, new_actions)
actor_loss = torch.mean(-self.log_alpha.exp() * entropy - torch.min(q1_value, q2_value))
self.optimizer_actor.zero_grad()
actor_loss.backward()
self.optimizer_actor.step()
# update temperature alpha
alpha_loss = torch.mean((entropy - self.target_entropy).detach() * self.log_alpha.exp())
self.optimizer_log_alpha.zero_grad()
alpha_loss.backward()
self.optimizer_log_alpha.step()
# soft update target Q-value network
self.soft_update(self.critic1, self.target_critic1)
self.soft_update(self.critic2, self.target_critic2)
def train_off_policy_agent(env, agent, num_episodes, replay_buffer, minimal_size, batch_size, render, seed_number):
return_list = []
for i in range(10):
with tqdm(total=int(num_episodes/10), desc='Iteration %d'%(i+1)) as pbar:
for i_episode in range(int(num_episodes/10)):
observation, _ = env.reset(seed=seed_number)
done = False
episode_return = 0
while not done:
if render:
env.render()
action = agent.take_action(observation)
observation_, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
replay_buffer.add(observation, action, reward, observation_, done)
# swap states
observation = observation_
episode_return += reward
if replay_buffer.size() > minimal_size:
b_s, b_a, b_r, b_ns, b_d = replay_buffer.sample(batch_size)
transition_dict = {
'states': b_s,
'actions': b_a,
'rewards': b_r,
'next_states': b_ns,
'dones': b_d
}
agent.update(transition_dict)
return_list.append(episode_return)
if(i_episode+1) % 10 == 0:
pbar.set_postfix({
'episode': '%d'%(num_episodes/10 * i + i_episode + 1),
'return': "%.3f"%(np.mean(return_list[-10:]))
})
pbar.update(1)
env.close()
return return_list
def moving_average(a, window_size):
cumulative_sum = np.cumsum(np.insert(a, 0, 0))
middle = (cumulative_sum[window_size:] - cumulative_sum[:-window_size]) / window_size
r = np.arange(1, window_size-1, 2)
begin = np.cumsum(a[:window_size-1])[::2] / r
end = (np.cumsum(a[:-window_size:-1])[::2] / r)[::-1]
return np.concatenate((begin, middle, end))
def plot_curve(return_list, mv_return, algorithm_name, env_name):
episodes_list = list(range(len(return_list)))
plt.plot(episodes_list, return_list, c='gray', alpha=0.6)
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('{} on {}'.format(algorithm_name, env_name))
plt.show()
if __name__ == "__main__":
rospy.init_node('ros_sac')
rospy.loginfo(">>>>>>>>>> SAC for ROS >>>>>>>>>>")
# reproducible
seed_number = 0
random.seed(seed_number)
np.random.seed(seed_number)
torch.manual_seed(seed_number)
num_episodes = 150 # episodes length
hidden_dim = 128 # hidden layers dimension
gamma = 0.98 # discounted rate
actor_lr = 1e-4 # lr of actor
critic_lr = 1e-3 # lr of critic
alpha_lr = 1e-4
tau = 0.005 # soft update parameter
buffer_size = 10000
minimal_size = 1000
batch_size = 64
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
env_name = 'Pendulum-v1'
render = False
if render:
env = gym.make(id=env_name, render_mode='human')
else:
env = gym.make(id=env_name)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
action_bound = env.action_space.high[0]
# entropy初始化为动作空间维度的负数
target_entropy = - env.action_space.shape[0]
replaybuffer = ReplayBuffer(buffer_size)
agent = SAC_Continuous(state_dim, hidden_dim, action_dim, action_bound, actor_lr, critic_lr, alpha_lr, target_entropy, tau, gamma, device)
return_list = train_off_policy_agent(env, agent, num_episodes, replaybuffer, minimal_size, batch_size, render, seed_number)
mv_return = moving_average(return_list, 9)
plot_curve(return_list, mv_return, 'SAC', env_name)
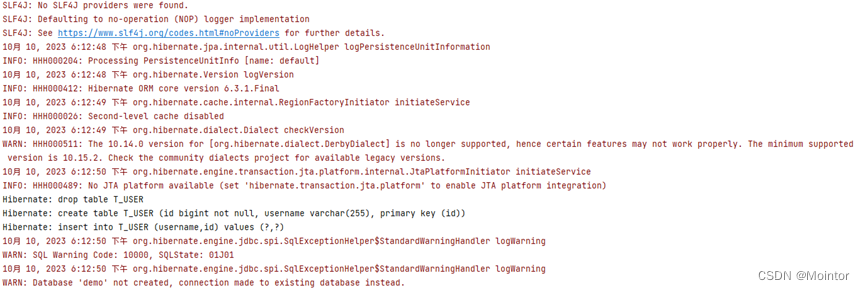
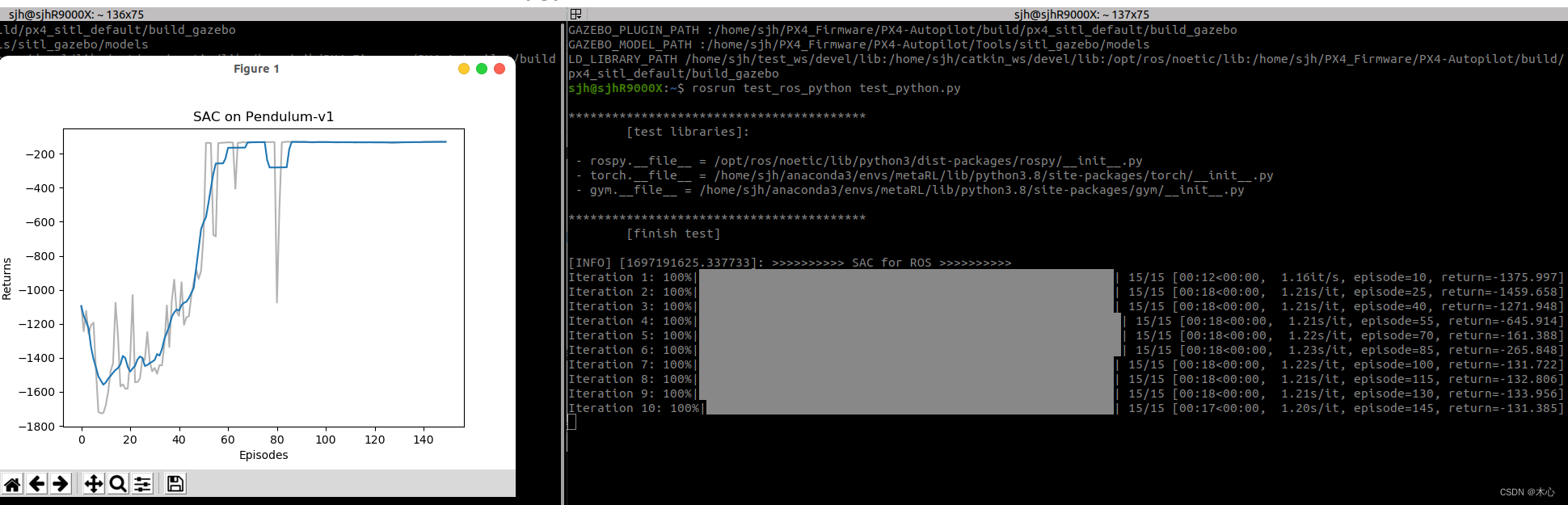
运行的结果如下所示
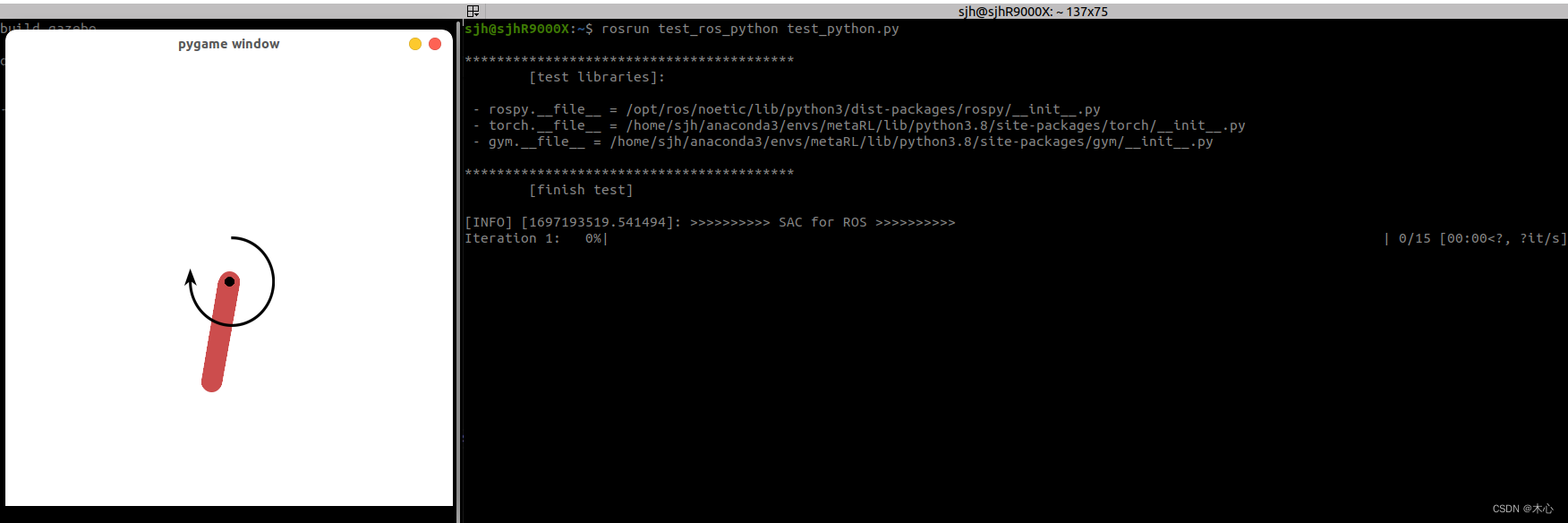
如果将代码中的render设置为True将会看到一个倒立摆,如下所示,但是这需要安装pygame,执行下面的语句即可
pip install gym[classic_control]
Reference
【ROS】ros-noetic和anaconda联合使用(1)
Hands on RL 之 Off-policy Maximum Entropy Actor-Critic (SAC)