-
我们用 Spring Boot 里面默认集成的 fasterxml.jackson 加以说明,这看似和 JPA 没什么关系,但是一旦我们和 @Entity 一起使用的时候,就会遇到一些问题,特别是新手同学,我们这一课时详细介绍一下用法。先来跟着我了解一下 Jackson 的基本语法。
Jackson 基本语法
我们先看一下我们项目里面的依赖。
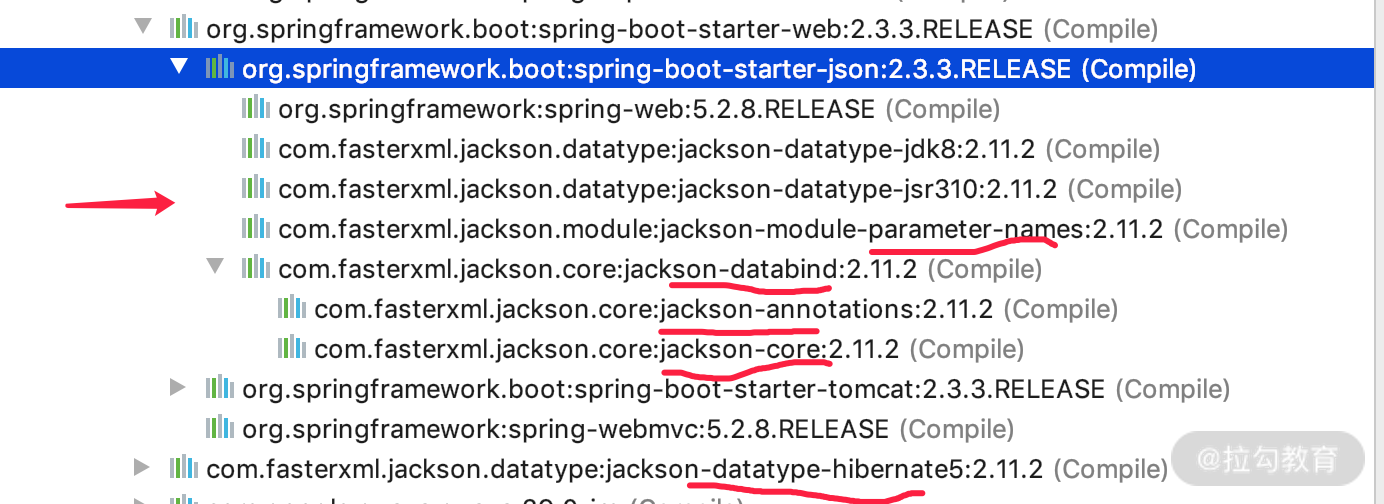
从中可以看到,当我们用 spring boot starter 的时候就会默认加载 fasterxml 相关的 jar 包模块,包括核心模块以及 jackson 提供的一些扩展 jar 包,下面详细介绍。
核心模块有三个
- jackson-core:核心包,提供基于“流模式”解析的相关 API,它包括 JsonPaser 和 JsonGenerator。Jackson 内部实现正是通过高性能的流模式 API 的 JsonGenerator 和 JsonParser 来生成和解析 json。
- jackson-annotations:注解包,提供标准注解功能,这是我们必须要掌握的基础语法。
- jackson-databind:数据绑定包,提供基于“对象绑定”解析的相关 API( ObjectMapper ) 和“树模型”解析的相关 API(JsonNode);基于“对象绑定”解析的 API 和“树模型”解析的 API 依赖基于“流模式”解析的 API。如下图中一些标准的类型转换:
jackson 提供了一些扩展 jar
- jackson-module-parameter-names:对原来的 jackson 进行了扩展,支持了构造方法和方法基本的参数支持。
- jackson-datatype:是对字段类型的支持做的一些扩展,包括下述几个部分。
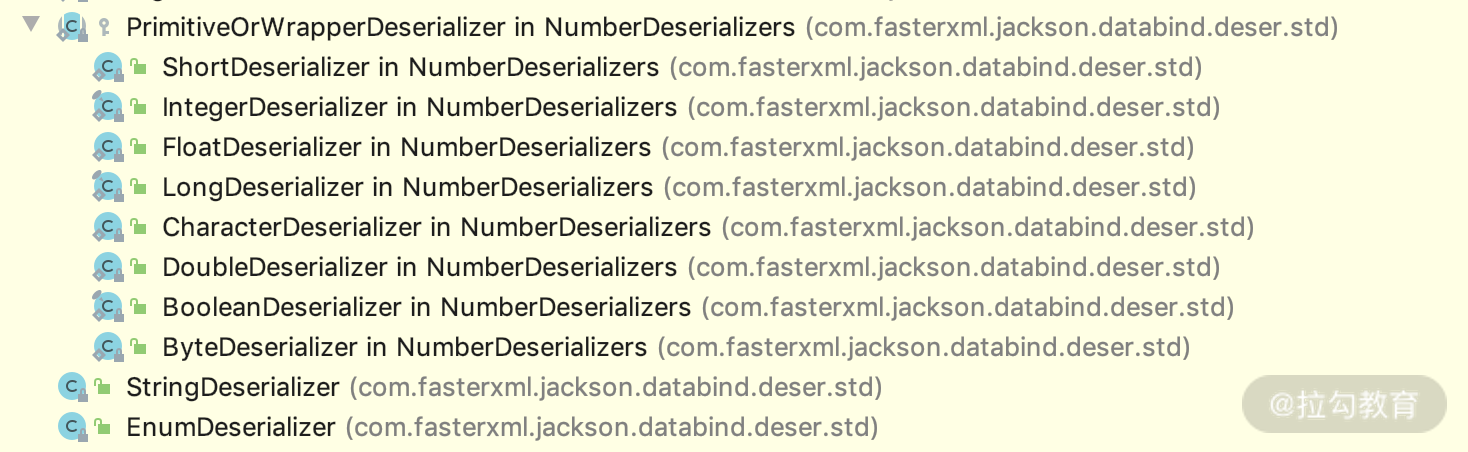
a. jackson-datatype-jdk8:是对 jdk8 语法里面的一些 Optional、Stream 等一些新的类型做的一些支持,如下图展示的一些类:

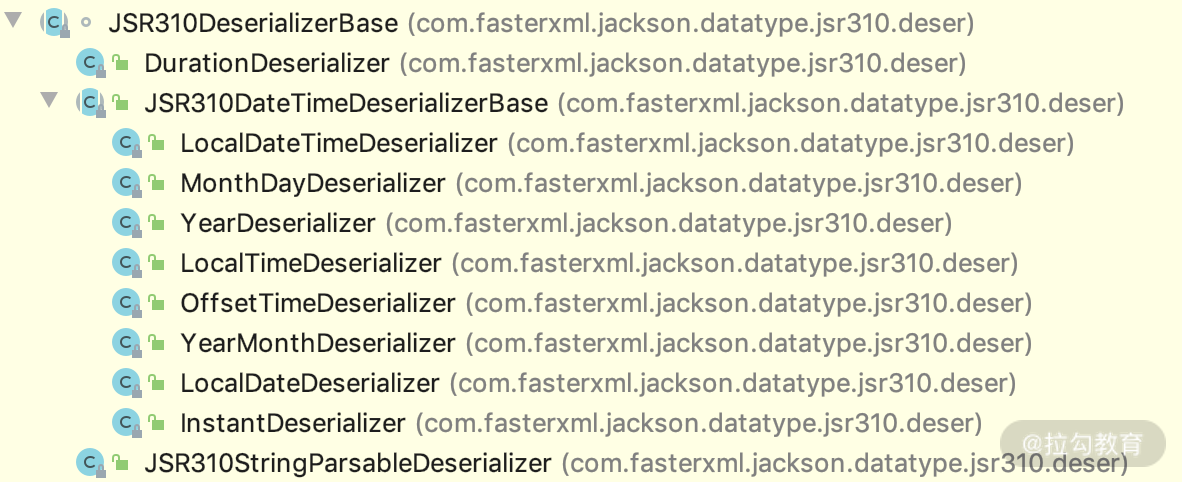
b.jackson-datatype-jsr310:是对 jdk8 中的 JSR310 时间协议做了支持,如 Duration、Instant、LocalDate、Clock 等时间类型的序列化、反序列化,如下图展示的一些类:
c.jackson-datatype-hibernate5:是对Hibernate的里面的一些数据类型的序列化、反序列化,如HibernateProxy 等。
剩下不常见的咱们就不说了,jackson-datatype 其实就是对一些常见的数据类型做序列化、反序列化,省去了我们自己写序列化、反序列化的过程。所以在我们工作中,如果需要自定义序列化的时候,可以参考这些源码。
知道了这些脉络之后,剩下的就是我们要掌握的注解有哪些了,下面我来介绍一下。
常用的一些注解
正如上面所说,我们打开 jackson-annotations,就可以看到有哪些注解了,一目了然,闲着没事的时候就可以到这里面看看,这样你会越来越熟悉。下面我们挑选一些常用的介绍一下。
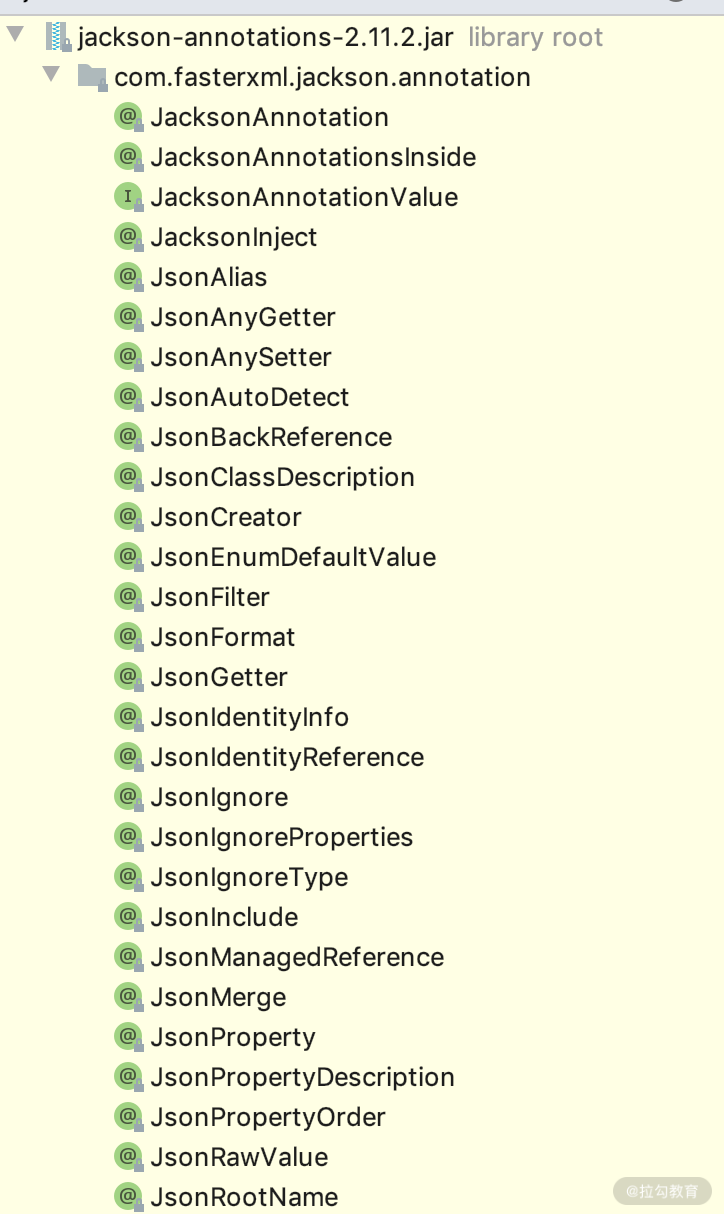
Jackson 里面常用的注解如下表格所示:
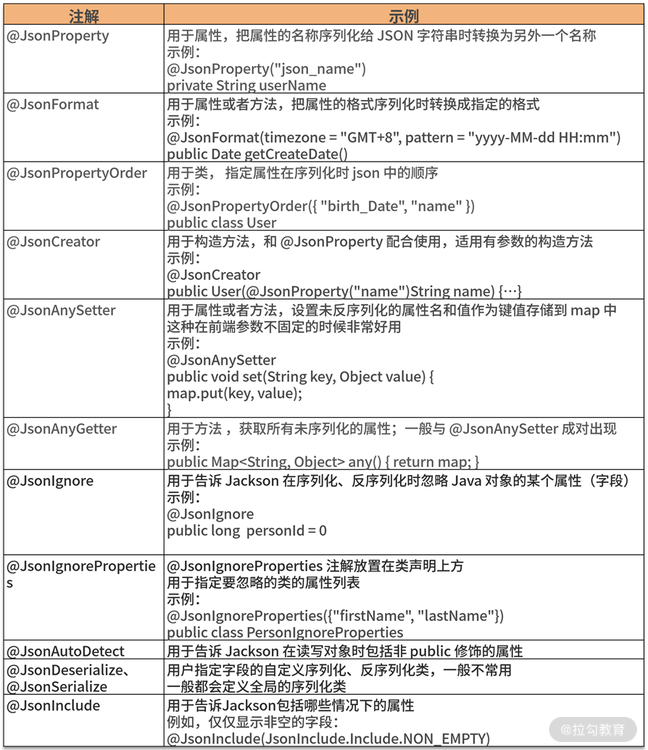
我们看个实例感受一下
接下来我们写个测试用例看一下。
首先,新建一个 UserJson 实体对象,将它转成 Json 对象,如下所示:
复制代码
package com.example.jpa.example1; import com.fasterxml.jackson.annotation.*; import lombok.*; import javax.persistence.*; import java.time.Instant; import java.util.*; @Entity @Data @Builder @AllArgsConstructor @NoArgsConstructor @JsonPropertyOrder({"createDate","email"}) public class UserJson { @Id @GeneratedValue(strategy= GenerationType.AUTO) private Long id; @JsonProperty("my_name") private String name; private Instant createDate; @JsonFormat(timezone ="GMT+8", pattern = "yyyy-MM-dd HH:mm") private Date updateDate; private String email; @JsonIgnore private String sex; @JsonCreator public UserJson(@JsonProperty("email") String email) { System.out.println("其他业务逻辑"); this.email = email; } @Transient @JsonAnySetter private Map<String,Object> other = new HashMap<>(); @JsonAnyGetter public Map<String, Object> getOther() { return other; } }然后,我们写一个测试用例,看一下运行结果。
复制代码
package com.example.jpa.example1; import com.fasterxml.jackson.core.JsonProcessingException; import com.fasterxml.jackson.databind.ObjectMapper; import org.assertj.core.util.Maps; import org.junit.jupiter.api.BeforeAll; import org.junit.jupiter.api.Test; import org.junit.jupiter.api.TestInstance; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.autoconfigure.orm.jpa.DataJpaTest; import org.springframework.test.annotation.Rollback; import javax.transaction.Transactional; import java.time.Instant; import java.util.Date; @DataJpaTest @TestInstance(TestInstance.Lifecycle.PER_CLASS) public class UserJsonRepositoryTest { @Autowired private UserJsonRepository userJsonRepository; @BeforeAll @Rollback(false) @Transactional void init() { UserJson user = UserJson.builder() .name("jackxx").createDate(Instant.now()).updateDate(new Date()).sex("men").email("123456@126.com").build(); userJsonRepository.saveAndFlush(user); } /** * 测试用User关联关系操作 * */ @Test @Rollback(false) public void testUserJson() throws JsonProcessingException { UserJson userJson = userJsonRepository.findById(1L).get(); userJson.setOther(Maps.newHashMap("address","shanghai")); ObjectMapper objectMapper = new ObjectMapper(); System.out.println(objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(userJson)); } }最后,运行一下可以看到如下结果。
复制代码
{ "createDate" : { "epochSecond" : 1600530086, "nano" : 588000000 }, "email" : "123456@126.com", "id" : 1, "updateDate" : "2020-09-19 23:41", "my_name" : "jackxx", "address" : "shanghai" }这里可以和上面的注解列表对比一下,其中我们看到了 HashMap 被平铺开了。我们通过例子可以很容易想到使用场景是 SpringMvc 的情况下,在 get 请求的时候我们要用到序列化;在 post 请求的时候我们要用到反序列化,将 json 字符串反向转化成实体对象。
那么在 Spring 里面 Jackson 都有哪些应用场景呢?我们来看一下。
Jackson 和 Spring 的关系
我们先看一下 Jackson 在 Spring 中常见的四个应用场景,来了解一下 Spring 在这些情况下的应用,带你详细掌握 Jackson 并知道它的重要性。
应用场景一
在Spring MVC中,我们需要知道Mvc的JSON视图的加载原理。我们看一下源码,mvc 对象的转化类:HttpMessageConvertersAutoConfiguration,里面要利用JacksonHttpMessageConvertersConfiguration,如下所示:
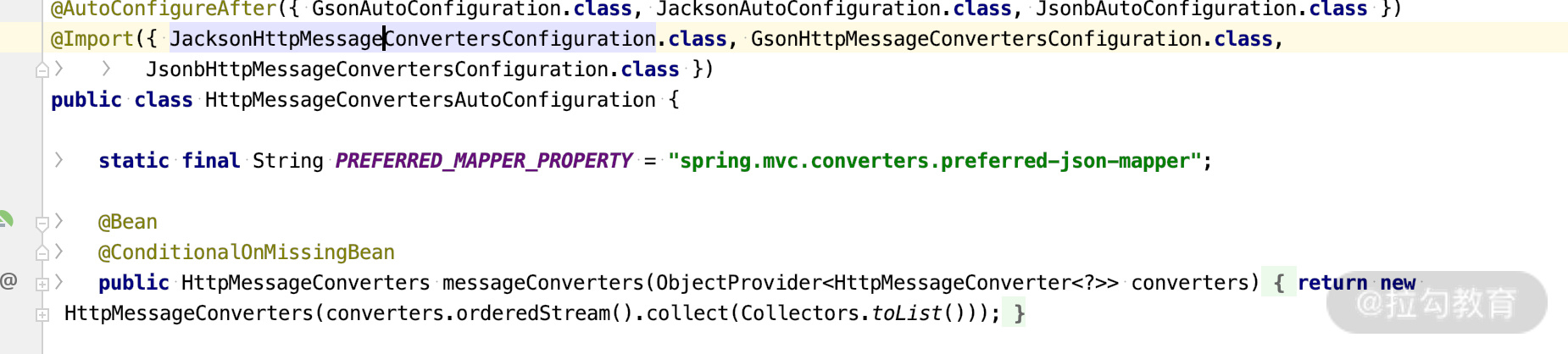
而里面的MappingJackson2HttpMessageConverter 正是采用 fasterxml.jackson 进行转化的,看下面的图片。
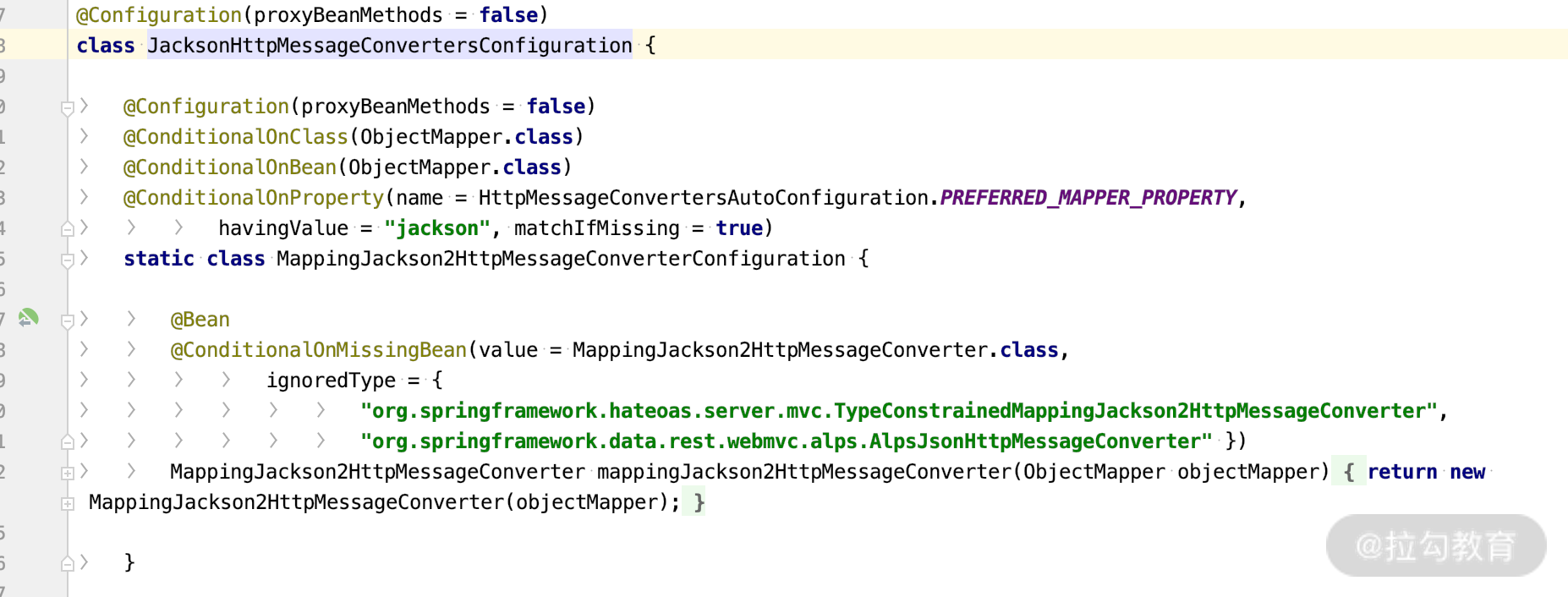
应用场景二
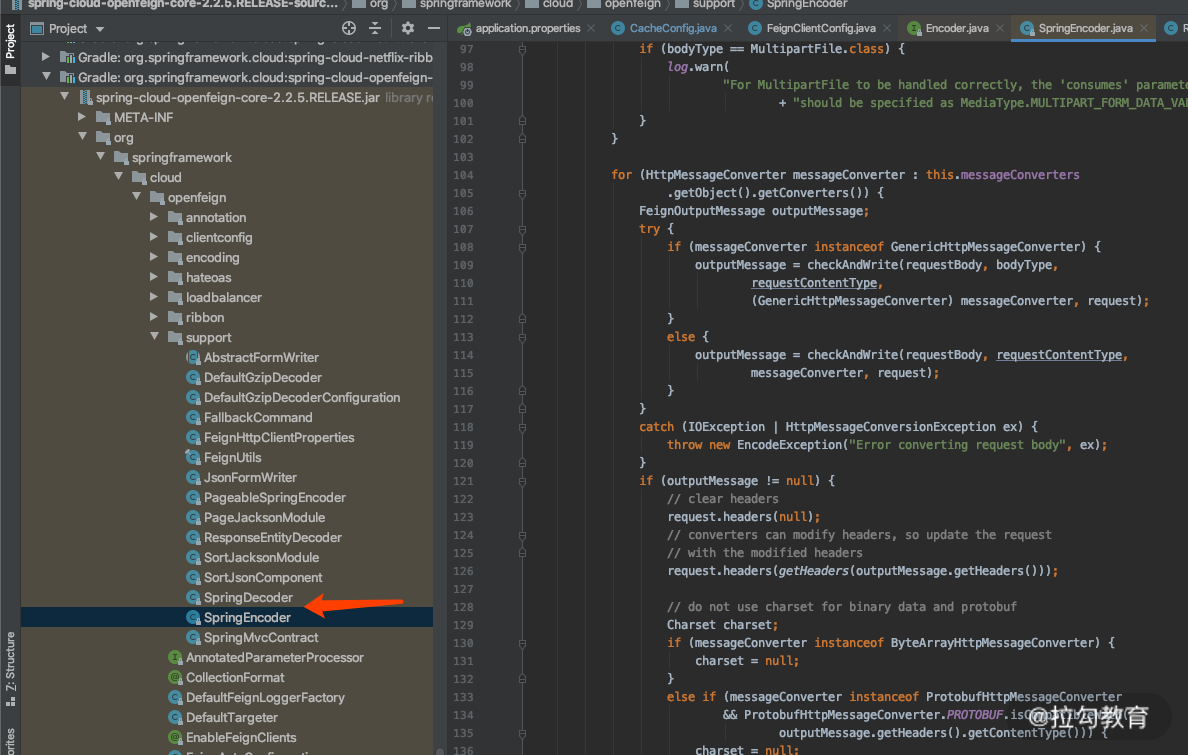
我们在微服务之间相互调用的时候,都会用到 HttpMessageConverter 里面的 JacksonHttpMessageConverter 进行转化。特别是在用 open-feign 里面的 Encode 和 Decode 的时候,我们就可以看到如下应用场景:
应用场景三
redis、cacheable 都会用到 value 的序列化,都离不开 JSON 的序列化,看下面的 redis 里面的关键配置文件。
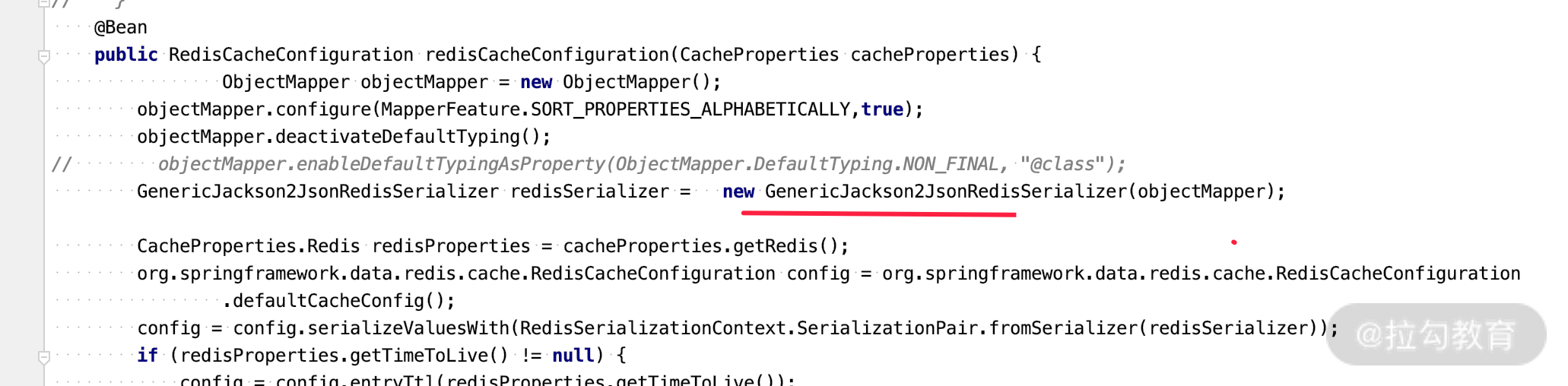
应用场景四
当我们项目之间解耦用到消息队列的时候,可能会基于 JMS消息协议发送消息,其也是基于 JSON 的序列化机制来继续converter的,它在用JmsTemplate 的时候也会遇到同样情况,我们看一下 JMS 里面相关代码。
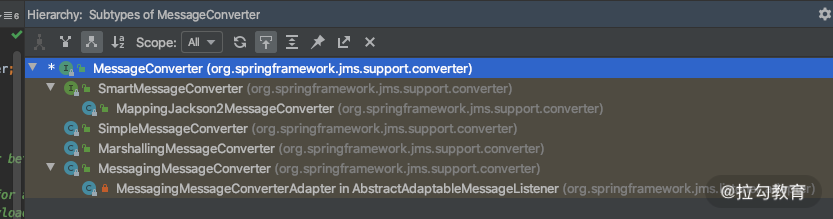
综上四个场景所述,我们是经常和 Entity 打交道的,而 @Entity 又要在各种场景转化成 JSONString,所以 Jackson 的原理我们还是要掌握一些的,下面来分析几个比较重要的。
Jackson 原理分析
Jackson 的可见性原理分析
前面我们看到了注解@JsonAutoDetect JsonAutoDetect.Visibility 类包含与 Java 中的可见性级别匹配的常量,表示 ANY、DEFAULT、NON_PRIVATE、NONE、PROTECTED_AND_PRIVATE和PUBLIC_ONLY。
那么我们打开这个类,看一下源码:
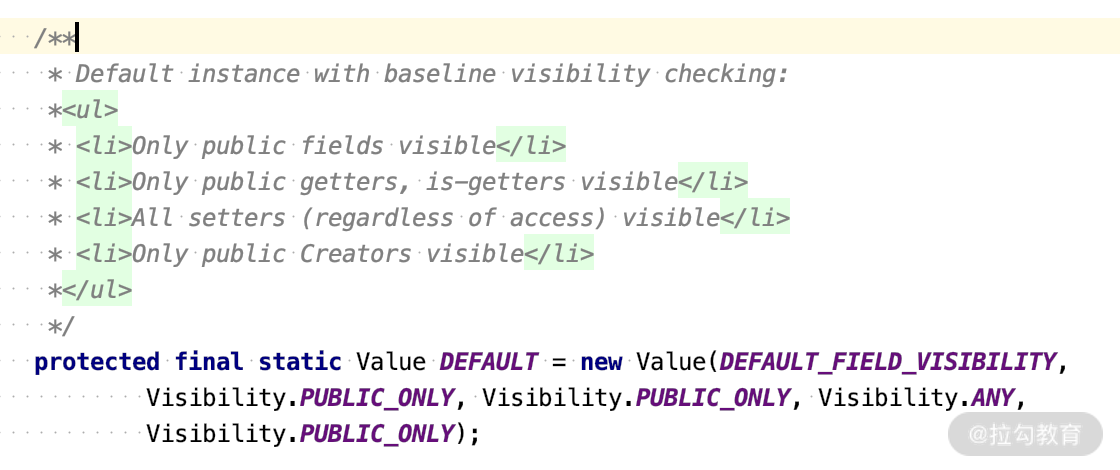
这里面的代码并不复杂,通过JsonAutoDetect 我们可以看到,Jackson 默认不是所有的属性都可以被序列化和反序列化。默认的属性可视化的规则如下:
- 若该属性修饰符是 public,该属性可序列化和反序列化。
- 若属性的修饰符不是 public,但是它的 getter 方法和 setter 方法是 public,该属性可序列化和反序列化。因为 getter 方法用于序列化,而 setter 方法用于反序列化。
- 若属性只有 public 的 setter 方法,而无 public 的 getter 方法,该属性只能用于反序列化。
所以我们可以通过私有字段的 public get 和 public set 方法控制是否可以序列化。这里可以和我们前面讲到的“JPA 实体里面的注解生效方式”做一下对比,也可以通过直接更改 ObjectMapper 设置可视化策略,如下所示:
复制代码
ObjectMapper mapper = new ObjectMapper(); // PropertyAccessor 支持的类型有 ALL,CREATOR,FIELD,GETTER,IS_GETTER,NONE,SETTER // Visibility 支持的类型有 ANY,DEFAULT,NON_PRIVATE,NONE,PROTECTED_AND_PUBLIC,PUBLIC_ONLY mapper.setVisibility(PropertyAccessor.FIELD, JsonAutoDetect.Visibility.ANY);这样,就可以直接看到所有字段了,包括私有字段。接着我们说一下反序列化相关方法。
反序列化最重要的方法
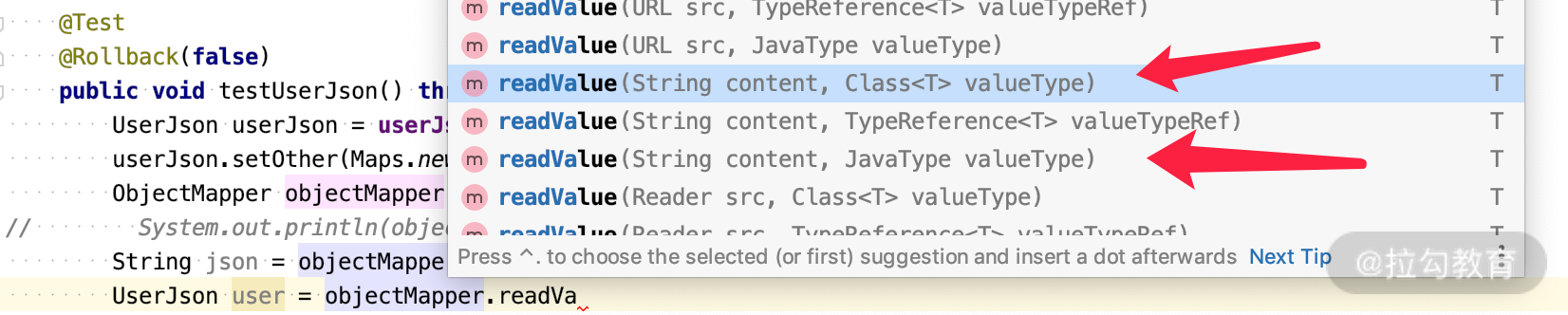
我们在做反序列化的时候要用到的三个重要方法如下所示。
复制代码
public <T> T readValue(String content, Class<T> valueType) public <T> T readValue(String content, TypeReference<T> valueTypeRef) public <T> T readValue(String content, JavaType valueType)可以看出,反序列化的时候要知道 java 的 Type 是很重要的,如下:
复制代码
String json = objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(userJson); //单个对象的写法: UserJson user = objectMapper.readValue(json,UserJson.class); //返回List的返回结果的写法: List<User> personList2 = mapper.readValue(jsonListString, new TypeReference<List<User>>(){});我们也可以根据 java 的反射,即万能的 JavaType 进行反序列化和转化,如下:

你也可以看一下 Jackson2HttpMessageConverter 里面的用法。
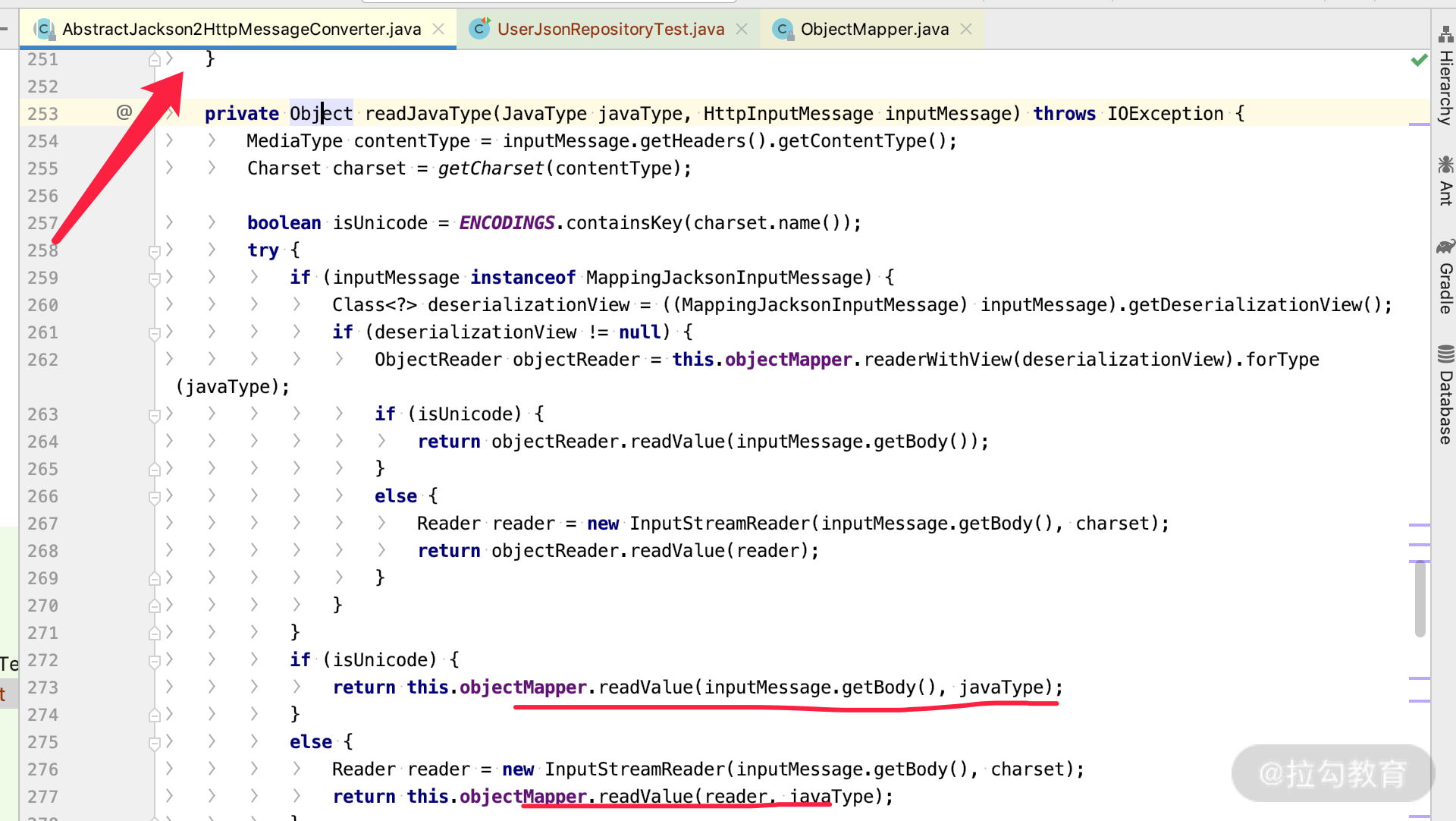
这个时候你应该很好奇,readValue 里面是如何判断 java 类型的呢?我们看下 ObjectMapper 的源码里面做了如下操作:
复制代码
public <T> T readValue(DataInput src, Class<T> valueType) throws IOException { _assertNotNull("src", src); return (T) _readMapAndClose(_jsonFactory.createParser(src), _typeFactory.constructType(valueType)); }到这里,我们看到 typeFactory 里面的 constructType 可以取到各种 type,那么点击进去看看。
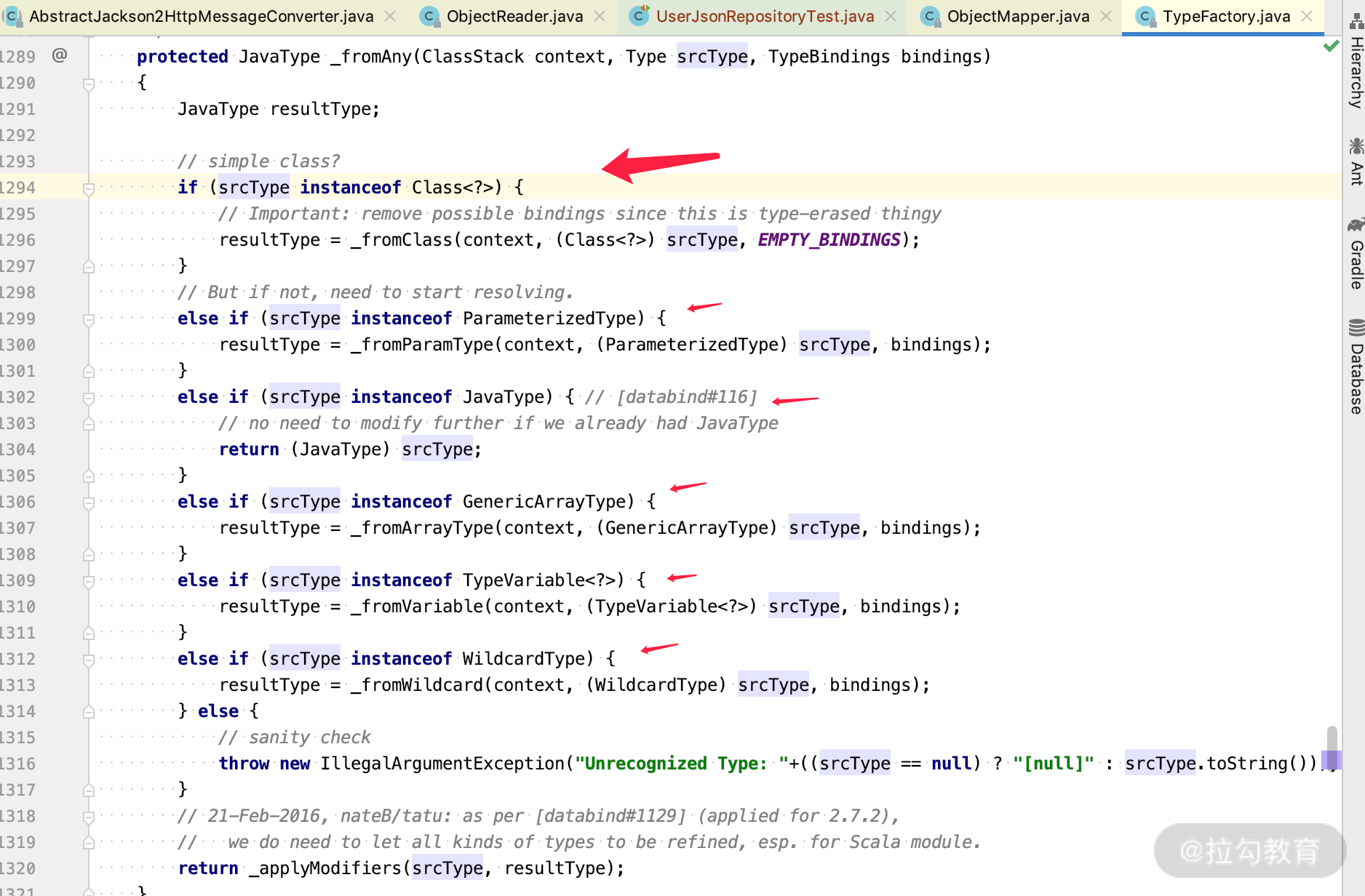
可以看到里面处理各种 java 类型和泛型的情况,当我们自己写反射代码的时候可以参考这一段,或者直接调用。此外,ObjectMapper 里面还一个重要的概念就是 Moduel,我们来看下。
Moduel 的加载机制
ObejctMapper 里面可以扩展很多 datatype,而不同的 datatype 封装到了不通的 modules 里面,我们可以 register 注册进去不同的 module,从而处理不同的数据类型。
目前 Modules 官方网站提供了很多内容,具体你可以查看这个网址:https://github.com/FasterXML/jackson#third-party-datatype-modules。这里我们重点说一下常用的加载机制。
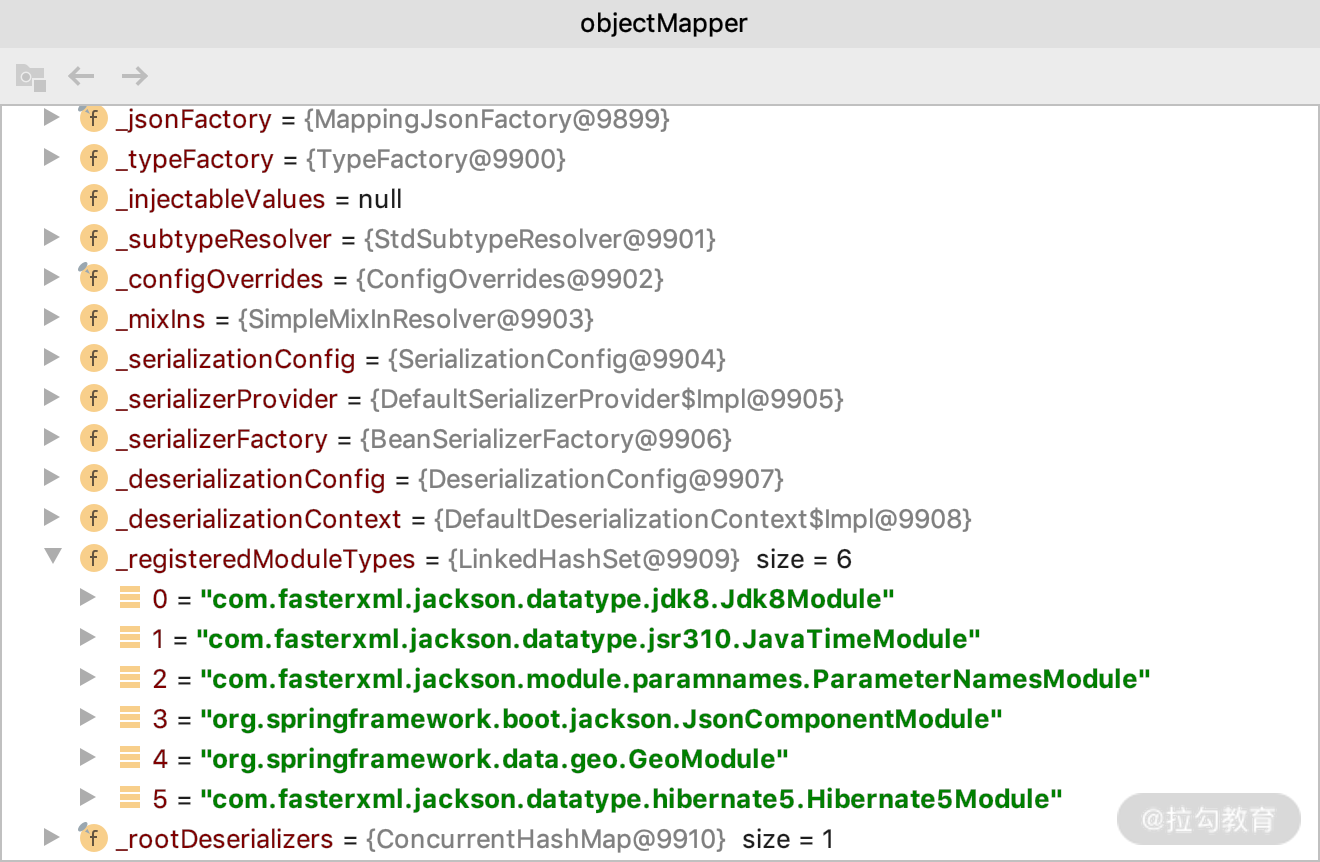
我们通过在代码里面设置一个断点,就可以很清楚地知道常用的 ModuleType 都有哪些,如 Jdk8、jsr310、Hibernate5 等。在MVC 里面默认的 Module 也是图上那些,Hibernate5 是我们自己引入的,具体解决什么问题和如何自定义的呢?我们接着往下看。
Jackson 与 JPA 常见的问题
我们用 JPA 的时候,特别是关联关系的时候,最常见的就是死循环了,你在使用时一定要注意。
死循环问题如何解决
第一种情况:我们在写 ToString 方法,特别是 JPA 的实体的时候,很容易陷入死循环,因为实体之间的关联关系配置是双向的,我们就需要 ToString 的时候把一方排除掉,如下所示:

第二种情况:在转化JSON的时候,双向关联也会死循环。按照我们上面讲的方法,这是时候我们要想到通过 @JsonIgnoreProperties(value={“address”})或者字段上面配置@JsonIgnore,如下:
复制代码
@JsonIgnore private List<UserAddress> address;此外,通过 @JsonBackReference 和 @JsonManagedReference 注解也可以解决死循环。
复制代码
public class UserAddress { @JsonManagedReference private User user; ....} public class User implements Serializable { @OneToMany(mappedBy = "user",fetch = FetchType.LAZY) @JsonBackReference private List<UserAddress> address; ...}如上述代码,也可以达到 @JsonIgnore 的效果,具体你可以自己操作一下试试,原理都是一样的,都是利用排除方法。那么接下来我们看下 HibernateModel5 是怎么使用的。
JPA 实体 JSON 序列化的常见报错
我们在实际跑之前讲过的 user 对象,或者是类似带有 lazy 对象关系的时候,经常会遇到下面的错误:
复制代码
No serializer found for class org.hibernate.proxy.pojo.bytebuddy.ByteBuddyInterceptor and no properties discovered to create BeanSerializer (to avoid exception, disable SerializationFeature.FAIL_ON_EMPTY_BEANS) (through reference chain: com.example.jpa.example1.User$HibernateProxy$MdjeSaTz["hibernateLazyInitializer"]) com.fasterxml.jackson.databind.exc.InvalidDefinitionException: No serializer found for class org.hibernate.proxy.pojo.bytebuddy.ByteBuddyInterceptor and no properties discovered to create BeanSerializer (to avoid exception, disable SerializationFeature.FAIL_ON_EMPTY_BEANS) (through reference chain: com.example.jpa.example1.User$HibernateProxy$MdjeSaTz["hibernateLazyInitializer"])这个时候该怎么办呢?下面介绍几个解决办法,第一个可以引入Hibernate5Module。
常见报错解决方法
解决方法一:引入 Hibernate5Module
代码如下:
复制代码
ObjectMapper objectMapper = new ObjectMapper(); objectMapper.registerModule(new Hibernate5Module()); String json = objectMapper.writeValueAsString(user); System.out.println(json);这样子就不会报错了。
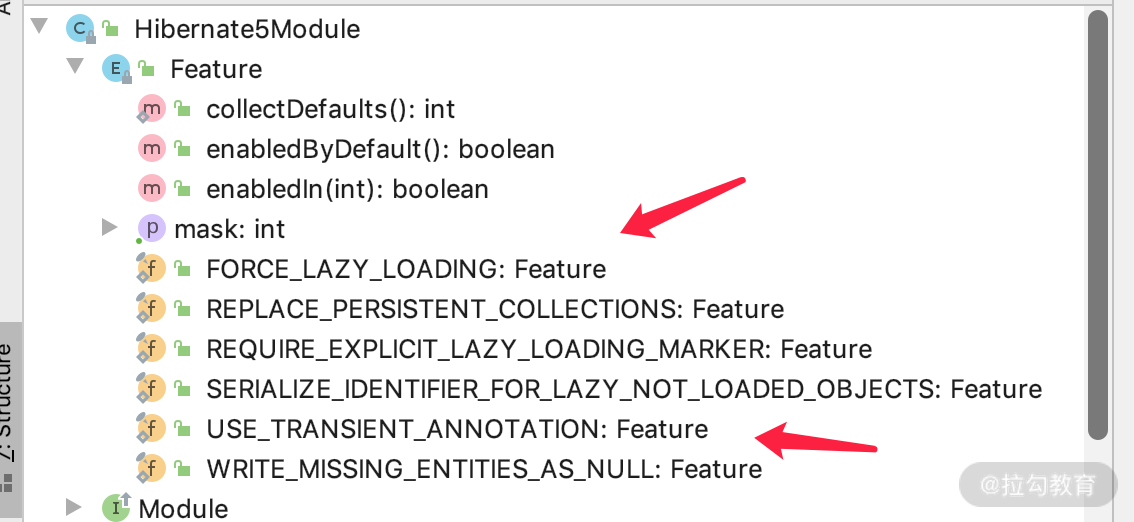
Hibernate5Module 里面还有很多 Feature 配置,例如FORCE_LAZY_LOADING,强制 lazy 里面加载就不会有上面的问题了。但是这个会有性能问题,我不建议使用。
还有 USE_TRANSIENT_ANNOTATION,利用 JPA 的 @Transient 注解配置,这个默认是开启的。所以基本上 feature 默认配置都是 ok 的,不需要我们动手,只要知道这回事就行了。
解决方法二:关闭 SerializationFeature.FAIL_ON_EMPTY_BEANS 的 feature
代码如下:
复制代码
ObjectMapper objectMapper = new ObjectMapper(); //直接关闭SerializationFeature.FAIL_ON_EMPTY_BEANS objectMapper.configure(SerializationFeature.FAIL_ON_EMPTY_BEANS,false); String json = objectMapper.writeValueAsString(user); System.out.println(json);因为是 lazy,所以 empty 的 bean 的时候不报错也可以。
解决方法三:对象上面排除“hibernateLazyInitializer”“handler”“fieldHandler”等代码如下:
复制代码
@JsonIgnoreProperties(value={"address","hibernateLazyInitializer","handler","fieldHandler"}) public class User implements Serializable {那有没有其他 ObjectMapper 的推荐配置了呢?
ObjectMapper 实战经验推荐配置项
下面是我根据自己实战经验为你推荐的配置项。
复制代码
ObjectMapper objectMapper = new ObjectMapper(); //empty beans不需要报错,没有就是没有了 objectMapper.configure(SerializationFeature.FAIL_ON_EMPTY_BEANS,false); //遇到不可识别字段的时候不要报错,因为前端传进来的字段不可信,可以不要影响正常业务逻辑 objectMapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES,false); //遇到不可以识别的枚举的时候,为了保证服务的强壮性,建议也不要关心未知的,甚至给个默认的,特别是微服务大家的枚举值随时在变,但是老的服务是不需要跟着一起变的 objectMapper.configure(DeserializationFeature.READ_UNKNOWN_ENUM_VALUES_AS_NULL,true); objectMapper.configure(DeserializationFeature.READ_UNKNOWN_ENUM_VALUES_USING_DEFAULT_VALUE,true);时间类型的最佳实践,如何返回 ISO 格式的标准时间
有的时候我们会发现,默认的 ObjectMapper 里面的 module 提供的时间转化格式可能不能满足我们的要求,可能要进行扩展,老师提供一个自定义 module 返回 ISO 标准时间格式的一个案例,如下:
复制代码
@Test @Rollback(false) public void testUserJson() throws JsonProcessingException { UserJson userJson = userJsonRepository.findById(1L).get(); userJson.setOther(Maps.newHashMap("address","shanghai")); //自定义 myInstant解析序列化和反序列化DateTimeFormatter.ISO_ZONED_DATE_TIME这种格式 SimpleModule myInstant = new SimpleModule("instant", Version.unknownVersion()) .addSerializer(java.time.Instant.class, new JsonSerializer<Instant>() { @Override public void serialize(java.time.Instant instant, JsonGenerator jsonGenerator, SerializerProvider serializerProvider) throws IOException { if (instant == null) { jsonGenerator.writeNull(); } else { jsonGenerator.writeObject(instant.toString()); } } }) .addDeserializer(Instant.class, new JsonDeserializer<Instant>() { @Override public Instant deserialize(JsonParser jsonParser, DeserializationContext deserializationContext) throws IOException { Instant result = null; String text = jsonParser.getText(); if (!StringUtils.isEmpty(text)) { result = ZonedDateTime.parse(text, DateTimeFormatter.ISO_ZONED_DATE_TIME).toInstant(); } return result; } }); ObjectMapper objectMapper = new ObjectMapper(); //注册自定义的module objectMapper.registerModule(myInstant); String json = objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(userJson); System.out.println(json); }我们利用上面的UserJson案例,在测试用例里面自定义了myInstant来进行序列化和反序列化Instant这种类型,然后我们通过objectMapper.registerModule(myInstant); 注册进去。那么我们看一下运行结果:
复制代码
{ "createDate" : "2020-09-20T02:36:33.308Z", "email" : "123456@126.com", "id" : 1, "updateDate" : "2020-09-20 10:36", "my_name" : "jackxx", "address" : "shanghai" }这时你会发现 createDate 的格式发生了变化,这样子的话,任何人看到我们这样的 JSON 结构就不必问我们到底是哪个时区的问题了。
08 | Jackson 注解在实体里面如何应用?常见的死循环问题如何解决?
news2026/3/29 9:40:49
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1088706.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
C#调用C++类,托管C++方式实现(创建C++ CLR dll项目)
由于C#编写的是托管代码,编译生成微软中间语言,而C代码则编译生成本地机器码(这种C也有叫做本地C或者非托管C,VC6.0就是用于开发非托管C代码的平台),这两种语言进行混合编程就存在一定困难。比较常用的方法…

JWT的原理及实际使用
🎬 艳艳耶✌️:个人主页 🔥 个人专栏 :《Spring与Mybatis集成整合》《Vue.js使用》 ⛺️ 生活的理想,为了不断更新自己 !
目录
1.JWT是什么?
2. jwt工具类介绍
3. jwt集成spa项目 1.JWT是什么&#…
MS5611的ZYNQ驱动试验之二 控制器功能考虑
上一篇BLOG简单介绍了MS5611的基本情况。这里我们考虑一下如何在ZYNQ里面实现,也就是规划PS和PL如何分工实现。
一般这种有一定简单时序的外设控制器我们可以采用两个方式编写:
1,用PL构造时序,做成所谓的加速器。
2࿰…

鲜花植物配送商城小程序的作用是什么
鲜花植物的市场需求非常高,尤其节假日或装饰/采购等需求更大,除了线下经销商外,还有鲜花植物供应商批发等,但其市场高需求的同时,经营痛点也比较明显。 通过【雨科】平台搭建鲜花植物商城,实现全产品线上展…

CentOS 7系统安装配置Zabbix 5.0LTS 步骤
目录 一、查看Zabbix官方教程(重点)
二、安装 Docker 创建 Mysql 容器
安装 Docker 依赖包
添加 Docker 官方仓库
安装 Docker 引擎
启动 Docker 服务并设置开机自启
验证 Docker 是否成功安装
拉取 MySQL 镜像
查看本地镜像
运行容器
停止和启…
Linux进程概念(二)--进程状态进程优先级
继上回书Linux进程概念(一),我们初步了解了进程的一些相关概念以及如何创建和查看进程,对其原理和一些进程现象进行了分析和解释,那么今天,我们学习下一个进程知识-进程概念。 目录
1.操作系统的进程状态 …
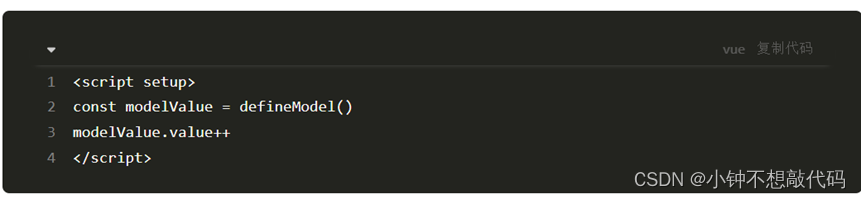
vue3 新特性(defineOptions defineModel)
Vue3.3 新特性-defineOptions 背景说明: 有 <script setup> 之前,如果要定义 props, emits 可以轻而易举地添加一个与 setup 平级的属性。 但是用了 <script setup> 后,就没法这么干了 setup 属性已经没有了,自然无法…
发布vue3组件到npm
目录
准备你的组件
创建项目
创建步骤
创建组件
封装我们要得组件
导出组件
打包 使用组件
发布包
创建npm账户
登录npm
切换npm源
发布到npm
package.json
package.json字段
确定版本号
版本号格式
版本号递增逻辑
vite 打包库模式
库模式配置
build配…
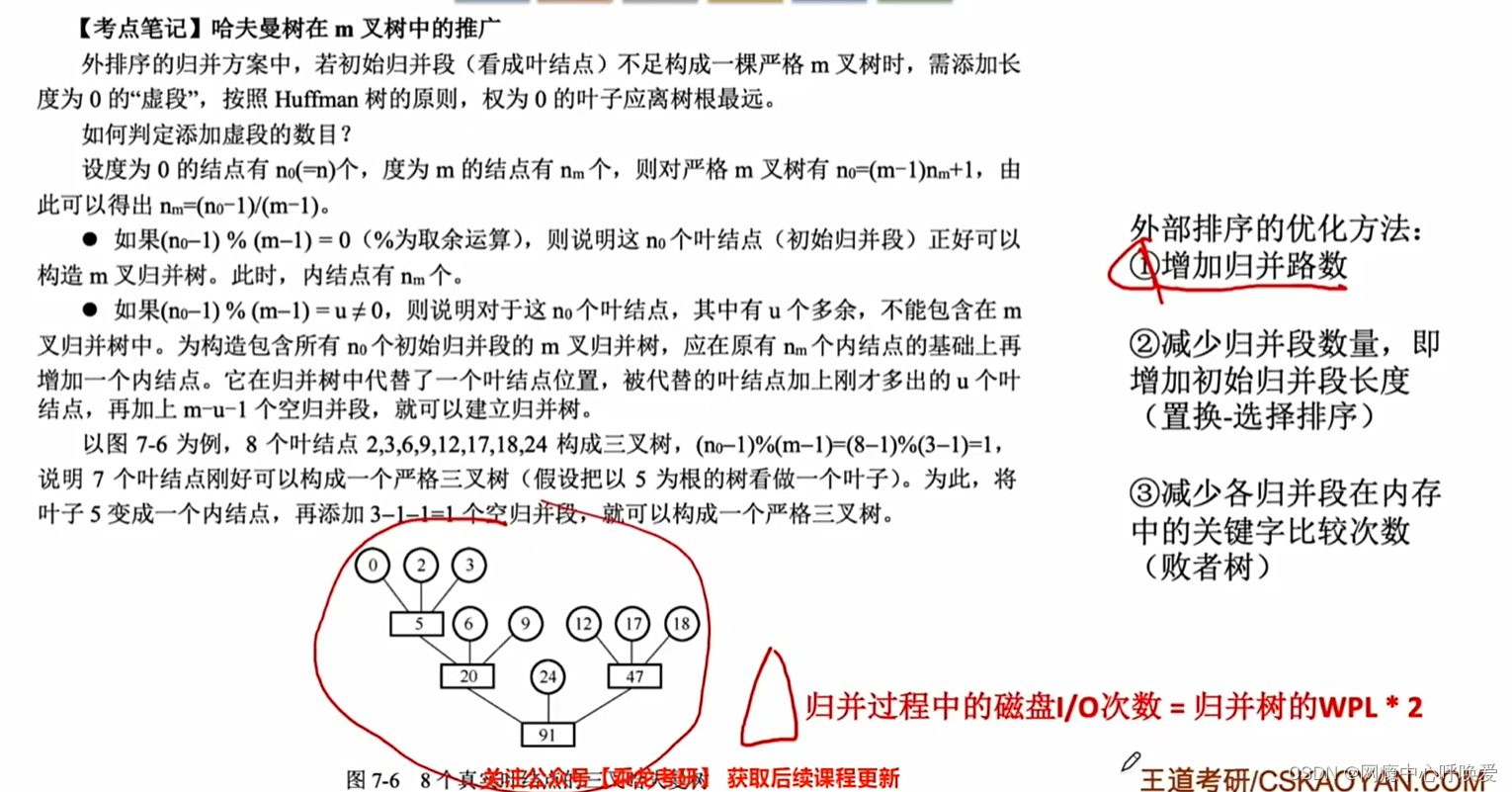
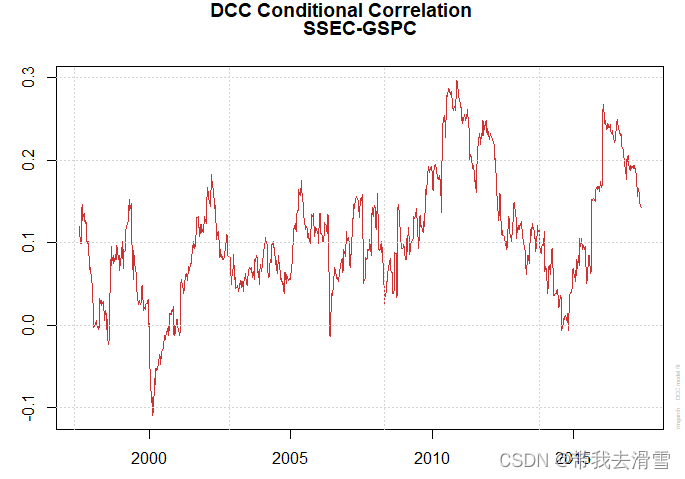
R实现动态条件相关模型与GARCH模型结合研究中美股市动态相关性(DCC-GARCH模型)
大家好,我是带我去滑雪! 中美两国是全球最大的经济体,其经济活动对全球产业链和贸易体系都具有巨大影响。中美之间的经济互动包括大规模的贸易、投资和金融往来。这些互动不仅仅反映在经济数据上,还体现在股市上。中美股市的联动关…

使用任务定时执行软件的定时关机功能,控制电脑可用时间段
目录
定时关机功能可以设置有效的时间段
控制电脑可用时间段的意义
定时执行软件介绍 - 定时执行专家 定时关机设置方法
不可用时间段设置方法
注意事项
总结 在现代社会,电脑已经成为人们生活和工作中不可或缺的一部分。但是,长时间使用电脑也会对…
展会预告丨中国海洋装备博览会盛大开幕!箱讯科技亮相1T18展位
2023年10月12日-15日
中国海洋装备博览会暨2023世界航海装备大会
即将在福州海峡国际会展中心盛大开幕
箱讯科技携手上海虹口区工商联航运商会
亮相本次博览会 添加图片注释,不超过 140 字(可选)
关于“中国海洋装备博览会”
中国海洋装…
DytanVO 代码复现(服务器端复现rtx3090)
源码地址
代码地址:https://github.com/castacks/DytanVO
环境配置
1.克隆github项目:
git clone https://github.com/castacks/DytanVO.git2.利用yaml创建conda 环境:
修改yaml文件
name: dytanvo
channels:- pytorch- conda-forge
de…
PDM篇 | SOLIDWORKS 2024新功能
改进的视觉内容 优点
重要数据和系统信息一目了然。
• 通过装配体可视化功能,在 SOLIDWORKS 中以图形方式查看零部件数据,如工作流程状态。
• 使用特定图标迅速识别焊件切割清单零部件。 增强的数据保护和跟踪功能 优点
通过附加的审计跟踪信息&am…

Handler-ThreadLocal分析
ThreadLocal 源码分析
在 Android 的 Handler 机制下,ThreadLocal 提供了对不同线程本地变量的副本的保存,并且实现了线程数据的隔离,不同线程的数据不会产生错乱。且在一个线程结束后,其对应在 ThreadLocal 内的数据会被释放&am…
Win10 系统中用户环境变量和系统环境变量是什么作用和区别?
环境:
Win10专业版
问题描述:
Win10 系统中用户环境变量和系统环境变量是什么作用和区别? 解答:
在Windows 10系统中,用户环境变量和系统环境变量是两个不同的环境变量,它们具有不同的作用和区别
1.用…

数字化转型的环境中,MES管理系统的发展趋势如何
近年来,随着数字化技术的飞速发展,数字化转型以及成为企业发展的必然趋势。在这个过程中,制造业作为国民经济的重要支柱,也面临这前所未有的挑战和机遇。数字化转型下,制造业需要什么样的MES管理系统来应对这些挑战和机…

Domain_audit是一款基于渗透测试角度的域审计工具
关于Domain_audit
该工具是PowerView、Impacket、PowerUpSQL、BloodHound、Ldaprelayscan和Crackmapexec的包装器,用于自动执行枚举和在On-Prem Active Directory渗透测试期间执行的大量检查。
检查项目
Invoke-AD CheckAll将按顺序执行以下操作:
收…
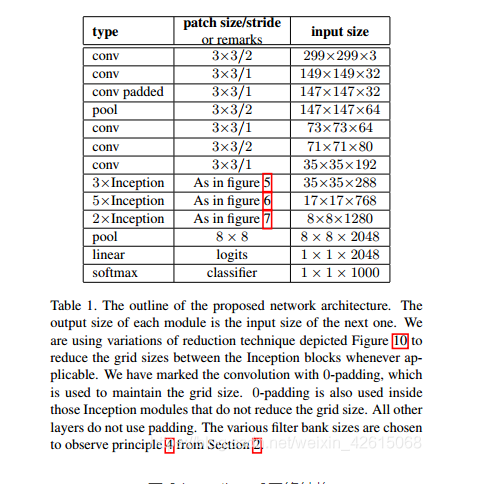
竞赛选题 深度学习+python+opencv实现动物识别 - 图像识别
文章目录 0 前言1 课题背景2 实现效果3 卷积神经网络3.1卷积层3.2 池化层3.3 激活函数:3.4 全连接层3.5 使用tensorflow中keras模块实现卷积神经网络 4 inception_v3网络5 最后 0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 *…