ChatGLM中的openai_api.py中的代码如下:
# coding=utf-8
# Implements API for ChatGLM2-6B in OpenAI's format. (https://platform.openai.com/docs/api-reference/chat)
# Usage: python openai_api.py
# Visit http://localhost:8000/docs for documents.
import time
import torch
import uvicorn
from pydantic import BaseModel, Field
from fastapi import FastAPI, HTTPException
from fastapi.middleware.cors import CORSMiddleware
from contextlib import asynccontextmanager
from typing import Any, Dict, List, Literal, Optional, Union
from transformers import AutoTokenizer, AutoModel
from sse_starlette.sse import ServerSentEvent, EventSourceResponse
@app.post("/v1/chat/completions", response_model=ChatCompletionResponse)
async def create_chat_completion(request: ChatCompletionRequest):
global model, tokenizer
if request.messages[-1].role != "user":
raise HTTPException(status_code=400, detail="Invalid request")
query = request.messages[-1].content
prev_messages = request.messages[:-1]
if len(prev_messages) > 0 and prev_messages[0].role == "system":
query = prev_messages.pop(0).content + query
history = []
if len(prev_messages) % 2 == 0:
for i in range(0, len(prev_messages), 2):
if prev_messages[i].role == "user" and prev_messages[i+1].role == "assistant":
history.append([prev_messages[i].content, prev_messages[i+1].content])
if request.stream:
generate = predict(query, history, request.model)
return EventSourceResponse(generate, media_type="text/event-stream")
response, _ = model.chat(tokenizer, query, history=history)
choice_data = ChatCompletionResponseChoice(
index=0,
message=ChatMessage(role="assistant", content=response),
finish_reason="stop"
)
return ChatCompletionResponse(model=request.model, choices=[choice_data], object="chat.completion")
async def predict(query: str, history: List[List[str]], model_id: str):
global model, tokenizer
choice_data = ChatCompletionResponseStreamChoice(
index=0,
delta=DeltaMessage(role="assistant"),
finish_reason=None
)
chunk = ChatCompletionResponse(model=model_id, choices=[choice_data], object="chat.completion.chunk")
yield "{}".format(chunk.json(exclude_unset=True, ensure_ascii=False))
current_length = 0
for new_response, _ in model.stream_chat(tokenizer, query, history):
if len(new_response) == current_length:
continue
new_text = new_response[current_length:]
current_length = len(new_response)
choice_data = ChatCompletionResponseStreamChoice(
index=0,
delta=DeltaMessage(content=new_text),
finish_reason=None
)
chunk = ChatCompletionResponse(model=model_id, choices=[choice_data], object="chat.completion.chunk")
yield "{}".format(chunk.json(exclude_unset=True, ensure_ascii=False))
choice_data = ChatCompletionResponseStreamChoice(
index=0,
delta=DeltaMessage(),
finish_reason="stop"
)
chunk = ChatCompletionResponse(model=model_id, choices=[choice_data], object="chat.completion.chunk")
yield "{}".format(chunk.json(exclude_unset=True, ensure_ascii=False))
yield '[DONE]'
if __name__ == "__main__":
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()
# 多显卡支持,使用下面两行代替上面一行,将num_gpus改为你实际的显卡数量
# from utils import load_model_on_gpus
# model = load_model_on_gpus("THUDM/chatglm2-6b", num_gpus=2)
model.eval()
uvicorn.run(app, host='0.0.0.0', port=8000, workers=1)
代码中使用了chunk.json,这个已经过时了,

测试代码:
import os
# import socket, socks
#
# socks.set_default_proxy(socks.SOCKS5, "127.0.0.1", 1080)
# socket.socket = socks.socksocket
import openai
openai.api_base = "http://localhost:8000/v1"
openai.api_key = "none"
response = openai.ChatCompletion.create(
model="chatglm2-6b",
messages=[
{"role": "user", "content": "你好"}
],
stream=True
)
for chunk in response:
if hasattr(chunk.choices[0].delta, "content"):
print(chunk.choices[0].delta.content, end="", flush=True)
运行会报错:
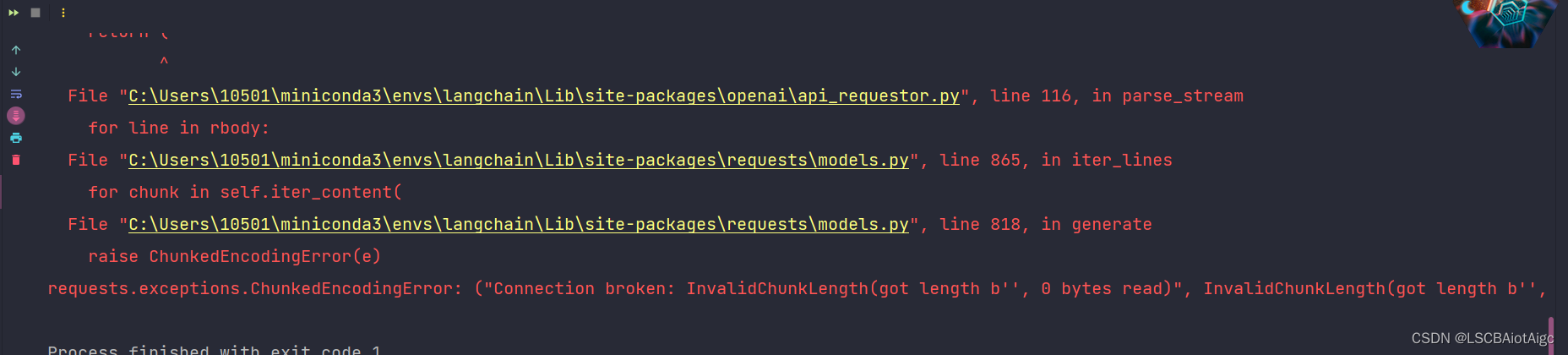 解决办法如下:
解决办法如下:
将所有的
chunk.json(exclude_unset=True, ensure_ascii=False)
改成
chunk.model_dump_json(exclude_unset=True)
再次启动,运行,则不会报错!!!







](https://img-blog.csdnimg.cn/img_convert/d43aa5113045366e6c66af1464688d1b.png)