1.概述
1.1 Zookeeper是什么?
Zookeeper: 直译过来是动物园管理员的意思,这里的动物表示的就是当下主流的众多框架组件(ps:现在的框架组件都喜欢用动物当图标),而Zookeeper的图标如下图所示,是一个人拿着一个铲子(铲屎官),生动形象地说明了Zookeeper就是为一众中间件服务的,特别是大数据方向的组件比如说:kafka, Hbase...等等

ZooKeeper 是一个开放源码的分布式协调服务,它是集群的管理者,监视着集群中各个节点的状态根据节点提交的反馈进行下一步合理操作。最终,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
分布式应用程序可以基于 Zookeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
1.2 Zookeeper设计实现
Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。
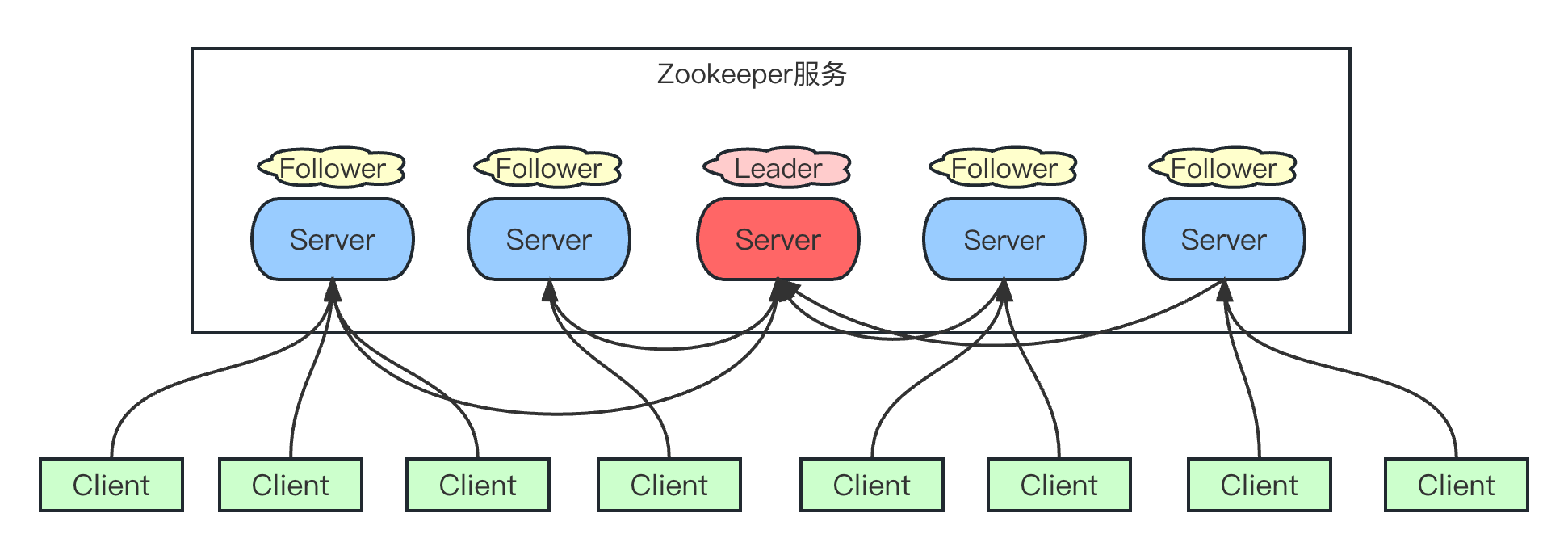
1)Zookeeper:一个领导者(Leader),多个跟随者(Follower)组成的集群。
2)集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。所以Zookeeper适合安装奇数台服务器。
3)全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。
4)更新请求顺序执行,来自同一个Client的更新请求按其发送顺序依次执行。
5)数据更新原子性,一次数据更新要么成功,要么失败。
6)实时性,在一定时间范围内,Client能读到最新数据。
数据模型
Zookeeper=文件系统+通知机制。Zookeeper提供基于类似于文件系统的目录节点树方式的数据存储,但是Zookeeper并不是用来专门存储数据的,它的作用主要是用来维护和监控你存储的数据的状态变化。通过监控这些数据状态的变化,从而可以达到基于数据的集群管理。ZooKeeper 数据模型的结构与 Unix 文件系统很类似,整体上可以看作是一棵树,每个节点称做一个 ZNode。每一个ZNode默认能够存储 1MB 的数据,可见Zookeeper并不适合用于存储大量数据,只适用于存储关键的配置数据和集群数据。每个 ZNode 都可以通过其路径唯一标识。

2.Zookeeper安装部署
安装zookeeper很简单,直接去官网下载安装包:https://zookeeper.apache.org/,这里我们下载企业大量使用的版本:3.5.7
首先拷贝 apache-zookeeper-3.5.7-bin.tar.gz 安装包到 Linux 系统下,注意安装之前系统一定要先安装JDK环境,这对于Java开发人员来说小菜一碟,安装之后使用下面命令检查一下:
[root@shepherd-master ~]# java -version
openjdk version "1.8.0_302"
OpenJDK Runtime Environment (build 1.8.0_302-b08)
OpenJDK 64-Bit Server VM (build 25.302-b08, mixed mode)
使用命令对安装包解压:
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz
解压之后的文件夹文件如下:
bin conf docs lib LICENSE.txt NOTICE.txt README.md README_packaging.txt
我们只需要调整下conf目录下的配置文件,进行重命名:
mv zoo_sample.cfg zoo.cfg
修改配置文件zoo.cfg内容里的dataDir 路径:
dataDir=/zookeeper/zookeeper-3.5.7/zkData
在/zookeeper/zookeeper-3.5.7目录下创建zkData文件夹:
cd /zookeeper/zookeeper-3.5.7
mkdir zkData
启动zookeeper服务:
bin/zkServer.sh start
我们知道zookeeper是java实现的,这也是为什么要求安装zookeeper之前要先安装jdk的原因,所以我们可以通过查看java进程来判断zookeeper服务是否成功启动
[root@shepherd-master ~]# jps
110384 QuorumPeerMain
18270 Jps
可以看到进程QuorumPeerMain,说明zookeeper已经成功启动,当然你可以下面查看:
ps -ef | grep zookeeper
启动客户端
bin/zkCli.sh
进入客户端之后可以执行相关命令,比如说查看根结点信息
[zk: localhost:2181(CONNECTED) 1] ls /
[admin, brokers, cluster, config, consumers, controller_epoch, isr_change_notification, latest_producer_id_block, servers, shepherd, zookeeper]
退出客户端:
[zk: localhost:2181(CONNECTED) 2] quit
停止 Zookeeper
bin/zkServer.sh stop
集群安装
Zookeeper的集群模式安装非常简单,首先按照上面所说的zookeeper遵从只要有半数以上节点存活,Zookeeper集群就能正常服务的原则,所以Zookeeper适合安装奇数台服务器,偶数台机器并不会加强集群的高可用性,反而白白浪费一台机器资源,3台和4台服务器是一样滴,由此我们选择使用3台服务器构建集群,这也是在生产环境中比较合适常见的集群配比了。我这里3台服务器的ip分别为:10.10.0.10, 10.10.0.22, 10.10.0.26
集群安装和上面单机安装步骤是一样的,需要将安装包分别拷贝到集群的3个机器上,然后修改配置文件名zoo_sample.cfg为zoo.cfg,并配置存储数据路径为dataDir=/zookeeper/zookeeper-3.5.7/zkData,与单机部署不一样的是,集群需在创建好zkData目录之后,在该目录需要创建一个 myid 的文件,在文件中添加与 server 对应的编号(注意:上下不要有空行,左右不要有空格),这里按照上面3台服务器的顺序对应的编号为1,2,3,接下来在配置文件zoo.cfg中添加集群的服务器信息如下:
#######################cluster##########################
server.1=10.10.0.10:2888:3888
server.2=10.10.0.22:2888:3888
server.3=10.10.0.26:2888:3888
格式为:server.A=B:C:D
A 是一个数字,表示这个是第几号服务器;集群模式下配置一个文件 myid,这个文件在 dataDir 目录下,这个文件里面有一个数据
就是 A 的值,Zookeeper 启动时读取此文件,拿到里面的数据与 zoo.cfg 里面的配置信息比较从而判断到底是哪个 server。
B 是这个服务器的地址;
C 是这个服务器 Follower 与集群中的 Leader 服务器交换信息的端口;
D 是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
最后在集群的每台机器上分别启动zookeeper服务即可:
bin/zkServer.sh start
既然是集群模式,就涉及到主从节点选举,下面就来看看zookeeper的选举机制
leader选举机制
Leader选举是保证分布式数据一致性的关键所在。当Zookeeper集群中的一台服务器出现以下两种情况之一时,需要进入Leader选举。
- 服务器初始化启动。
- 服务器运行期间无法和Leader保持连接
对于集群中已经存在Leader而言,此种情况一般都是某台机器启动得较晚,在其启动之前,集群已经在正常工作,对这种情况,该机器试图去选举Leader时,会被告知当前服务器的Leader信息,对于该机器而言,仅仅需要和Leader机器建立起连接,并进行状态同步即可。
对于集群中不存在Leader情况相对复杂,大概分为两种情况:
- 集群服务是第一次启动,这里我们以5台机器组成集群来讲解

(1)服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING;
(2)服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的myid比自己目前投票推举的(服务器1) 大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING
(3)服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING;
(4)服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING;
(5)服务器5启动,同4一样当小弟。
- 集群服务非第一次启动,但是集群中不存在leader,这种一般情况是某一时刻leader机器发生故障,因此重新开始进行Leader选举
按照前面所说的5台机器集群组成集群,加入某个时刻leader服务3和服务器5发生了故障,这时候集群就没有leader,就会重新选举leader,
SID:服务器ID。用来唯一标识一台ZooKeeper集群中的机器,每台机器不能重复,和myid一致。
ZXID:事务ID。ZXID是一个事务ID,用来标识一次服务器状态的变更。在某一时刻,集群中的每台机器的ZXID值不一定完全一
致,这和ZooKeeper服务器对于客户端“更新请求”的处理逻辑有关。
Epoch:每个Leader任期的代号。没有Leader时同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加
假设ZooKeeper由5台服务器组成,SID分别为1、2、3、4、5,ZXID分别为8、8、8、7、7,并且此时SID为3的服务器是Leader。某一时刻,3和5服务器出现故障,因此开始进行Leader选举。
SID为1、2、4的机器投票情况(EPOCH,ZXID,SID )分别为:(1,8,1) (1,8,2) (1,7,4)
选举Leader规则: ①EPOCH大的直接胜出 ②EPOCH相同,事务id大的胜出 ③事务id相同,服务器id大的胜出
由此规则服务器2会在新的选举中成功当下leader
zookeeper客户端操作命令
| 命令 | 功能描述 |
|---|---|
| help | 显示所有操作命令 |
| ls path | 使用 ls 命令来查看当前 znode 的子节点 [可监听] -w 监听子节点变化 -s 附加次级信息 |
| create | 创建znode节点 -s 含有序列 -e 临时(重启或者超时消失) |
| get path | 获得节点的值 [可监听] -w 监听节点内容变化 -s 附加次级信息 |
| set | 设置节点的值 |
| stat | 查看节点状态 |
| delete | 删除节点 |
| deleteall | 删除节点及下级子节点 |
接下来我们就来看看这些命令的使用案例,首先我们需要先进入客户端:
bin/zkCli.sh
使用ls查看节点信息:这里ls接的路径path一定是绝对路径,也就是从根路径开头/,这也说明了zookeeper是没有cd命令的
[zk: localhost:2181(CONNECTED) 4] ls -s /
[admin, brokers, cluster, config, consumers, controller_epoch, isr_change_notification, latest_producer_id_block, sanguo, servers, shepherd, shuihu, zookeeper]cZxid = 0x0
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x0
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x333
cversion = 39
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 13
create创建节点:节点分为:持久/临时/有序号/无序号
持久(Persistent):客户端和服务器端断开连接后,创建的节点不删除
短暂(Ephemeral):客户端和服务器端断开连接后,创建的节点自己删除
有序号:创建znode时设置顺序标识,znode名称后会附加一个值,顺序号是一个单调递增的计数器,由父节点维护。注意:在分布式系统中,顺序号可以被用于为所有的事件进行全局排序,这样客户端可以通过顺序号推断事件的顺序
创建一个持久无序号节点和下级节点
[zk: localhost:2181(CONNECTED) 6] create /car "car"
Created /car
[zk: localhost:2181(CONNECTED) 7] create /car/tesla "mask"
Created /car/tesla
创建一个持久有序号节点
[zk: localhost:2181(CONNECTED) 11] create -s /car/tesla/model_y "yyyyy"
Created /car/tesla/model_y0000000000
[zk: localhost:2181(CONNECTED) 12] create -s /car/tesla/model_y "ypppp"
Created /car/tesla/model_y0000000001
[zk: localhost:2181(CONNECTED) 13] ls /car/tesla
[model_y0000000000, model_y0000000001]
创建一个临时有序号的节点,客户端与服务器断开连接后,节点就会删除
[zk: localhost:2181(CONNECTED) 14] create -e -s /car/tesla/model_3 "33333"
Created /car/tesla/model_30000000002
[zk: localhost:2181(CONNECTED) 15] create -e -s /car/tesla/model_3 "3_new"
Created /car/tesla/model_30000000003
[zk: localhost:2181(CONNECTED) 17] ls /car/tesla
[model_30000000002, model_30000000003, model_y0000000000, model_y0000000001]
获取节点的值:
[zk: localhost:2181(CONNECTED) 18] get -s /car/tesla
mask
cZxid = 0x340
ctime = Thu Sep 28 17:35:46 CST 2023
mZxid = 0x340
mtime = Thu Sep 28 17:35:46 CST 2023
pZxid = 0x344
cversion = 4
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 4
numChildren = 4
设置节点的值:
[zk: localhost:2181(CONNECTED) 19] set /car/tesla "mask-1111"
[zk: localhost:2181(CONNECTED) 20] get /car/tesla
mask-1111
项目推荐:基于SpringBoot2.x、SpringCloud和SpringCloudAlibaba企业级系统架构底层框架封装,解决业务开发时常见的非功能性需求,防止重复造轮子,方便业务快速开发和企业技术栈框架统一管理。引入组件化的思想实现高内聚低耦合并且高度可配置化,做到可插拔。严格控制包依赖和统一版本管理,做到最少化依赖。注重代码规范和注释,非常适合个人学习和企业使用
Github地址:https://github.com/plasticene/plasticene-boot-starter-parent
Gitee地址:https://gitee.com/plasticene3/plasticene-boot-starter-parent
微信公众号:Shepherd进阶笔记
交流探讨qun:Shepherd_126
3.Zookeeper监听watcher机制
Zookeeper使用Watcher机制实现分布式数据的发布/订阅功能。Watcher(事件监听器)是Zookeeper中的一个很重要的特性。Zookeeper允许用户在指定节点上注册一些Watcher,并且在一些特定事件触发的时候,ZooKeeper服务端会将事件通知到感兴趣的客户端上去,该机制是Zookeeper实现分布式协调服务的重要特性。
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、节点删除、子目录节点增加删除)时,ZooKeeper 会通知客户端。监听机制保证 ZooKeeper 保存的任何的数据的任何改变都能快速的响应到监听了该节点的应用程序。
我们分别启动两个客户端,客户端1对节点值进行监听,客户端2对节点进行编辑,命令示例如下:
[zk: localhost:2181(CONNECTED) 5] get -w /shepherd # 开启对节点/shepherd的内容监听
MeiYing
紧接着客户端2对节点内容进行修改:
[zk: localhost:2181(CONNECTED) 0] set /shepherd "hello"
这时候查看客户端1,会发现收到监听事件的通知/shepherd的数据发生了变化type:NodeDataChanged
[zk: localhost:2181(CONNECTED) 5] get -w /shepherd
MeiYing
[zk: localhost:2181(CONNECTED) 6]
WATCHER::
WatchedEvent state:SyncConnected type:NodeDataChanged path:/shepherd
[zk: localhost:2181(CONNECTED) 6]
接下来为了论证一个重要细节点,我们在客户端2再次对节点进行值修改:
[zk: localhost:2181(CONNECTED) 0] set /shepherd "keep"
回到客户端1,发现并没有再次收到节点值变化的监听通知消息。这是因为注册一次,只能监听一次。想再次监听,需要再次注册
下面再来看看监听节点的子节点变化,和上面一样,客户端1开启监听:
[zk: localhost:2181(CONNECTED) 2] ls -w /shepherd
[]
接着在客户端2创建一个子节点:
[zk: localhost:2181(CONNECTED) 0] create /shepherd/car "tesla"
Created /shepherd/car
再次回到客户端1发现收到节点子节点的变化监听消息了:type:NodeChildrenChanged path:/shepherd
[zk: localhost:2181(CONNECTED) 3]
WATCHER::
WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/shepherd
同样地,对节点的子节点变化监听也是注册一次,只能监听一次
代码层面实现也非常简单,首先引入相关所需依赖
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.5.7</version>
</dependency>
编写代码,实现zookeeper客户端连接,进行相关操作:
package com.shepherd.zk.client;
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.util.List;
/**
* @author fjzheng
* @version 1.0
* @date 2023/10/9 14:21
*/
public class ZkClient {
// 注意:逗号左右不能有空格
// 连接集群 10.10.0.10:2181,10.10.0.22:2181,10.10.0.26:2181
// 这里连接单机版演示
private String connectString = "10.10.0.10:2181";
private int sessionTimeout = 10000;
private ZooKeeper zkClient;
/**
* 初始化,创建zk客户端
* @throws IOException
*/
@Before
public void init() throws IOException {
// 创建客户端
zkClient = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
// 指定默认监听器watcher
@Override
public void process(WatchedEvent watchedEvent) {
// 收到事件通知后的回调函数
System.out.println("默认监听器:" + watchedEvent.toString());
System.out.println("-------------------------------");
//持续监听 注册一次只能监听一次,下面循环注册监听
List<String> children = null;
try {
// 再次注册监听,
children = zkClient.getChildren("/shepherd", true);
for (String child : children) {
System.out.println(child);
}
System.out.println("-------------------------------");
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
/**
* 创建节点
* @throws KeeperException
* @throws InterruptedException
*/
@Test
public void create() throws KeeperException, InterruptedException {
// 参数1: 节点路径 参数2: 节点数据 参数3: 节点权限 参数4: 节点类型
String nodeCreated = zkClient.create("/shepherd", "MeiYing".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
/**
* 获取节点的子节点并注册监听,这里可以自己定义监听器watcher,但是注册一次,也只能监听一次,如下注释示例
* 当然也可以通过zkClient.getChildren("/shepherd", true)实现,此时会执行创建zkClient时声明的默认监听器可实现持续监听,
* 如上面初始化创建zkClient所示
* @throws KeeperException
* @throws InterruptedException
*/
@Test
public void getChildren() throws KeeperException, InterruptedException {
// List<String> children = zkClient.getChildren("/shepherd", new Watcher() {
// @Override
// public void process(WatchedEvent watchedEvent) {
// // 收到事件通知后的回调函数(用户的业务逻辑)
// System.out.println("监听信息:" + watchedEvent.toString());
// }
// });
// for (String child : children) {
// System.out.println(child);
// }
List<String> children = zkClient.getChildren("/shepherd", true);
// 延时 →watch为true,代表监听, 在zkClient的process()方法持续监听后续的节点变化
Thread.sleep(Long.MAX_VALUE);
}
/**
* 判断节点是否存储
* @throws KeeperException
* @throws InterruptedException
*/
@Test
public void exist() throws KeeperException, InterruptedException {
// 客户端不启动监听
Stat stat = zkClient.exists("/shepherd", false);
System.out.println(stat == null? "not exist " : "exist");
}
}
4.Zookeeper在Spring Boot业务系统的主要应用:注册中心和分布式锁
4.1 注册中心
**Zookeeper 一个最常用的使用场景就是用于担任服务生产者和服务消费者的注册中心。**在没有spring-cloud-alibaba组件之前,微服务的注册中心就是在eureka,zookeeper 两者中选择的,服务生产者将自己提供的服务注册到Zookeeper中心,服务的消费者在进行服务调用的时候先到Zookeeper中查找服务,获取到服务生产者的详细信息之后,再去调用服务生产者的内容与数据。如下图所示,在 Dubbo架构中 Zookeeper 就担任了注册中心这一角色。

这里先说说一个面试题:Zookeeper和eureka做注册中心的区别?Zookeeper保证CP,Eureka保证AP。
CAP理论,指的是在一个分布式系统中,Consistency(一致性)、Availability(可用性)、Partition Tolerance(分区容错性),不能同时成立。

ZooKeeper是个CP(一致性+分区容错性)的,即任何时刻对ZooKeeper的访问请求能得到一致的数据结果,同时系统对网络分割具备容错性;但是它不能保证每次服务请求的可用性。也就是在极端环境下,ZooKeeper可能会丢弃一些请求,消费者程序需要重新请求才能获得结果。ZooKeeper是分布式协调服务,它的职责是保证数据在其管辖下的所有服务之间保持同步、一致;所以就不难理解为什么ZooKeeper被设计成CP而不是AP特性的了
Spring Cloud ZooKeeper 提供的 spring-cloud-zookeeper-discovery 组件,基于 Spring Cloud 的编程模型,接入 ZooKeeper 作为注册中心,实现服务的注册与发现。使用方式和eureka差不多,对eureka不熟悉的,可以查看:注册中心:eureka
碍于文章篇幅问题,具体注册使用案例请参考:https://www.iocoder.cn/Spring-Cloud/ZooKeeper-Discovery/?self
4.2 分布式锁
关于分布式锁的实现,之前我们总结过通过redisson实现的方案:分布式锁王者实现:redisson
Zookeeper是通过上面提到的临时顺序节点实现的,所以这里再来说说Zookeeper的节点类型,加深一下印象
PERSISTENT:持久化ZNode节点,一旦创建这个ZNode点存储的数据不会主动消失,除非是客户端主动的delete。
EPHEMERAL:临时ZNode节点,Client连接到Zookeeper Service的时候会建立一个Session,之后用这个Zookeeper连接实例创建该类型的znode,一旦Client关闭了Zookeeper的连接,服务器就会清除Session,然后这个Session建立的ZNode节点都会从命名空间消失。总结就是,这个类型的znode的生命周期是和Client建立的连接一样的。
PERSISTENT_SEQUENTIAL:顺序自动编号的ZNode节点,这种znoe节点会根据当前已近存在的ZNode节点编号自动加 1,而且不会随Session断开而消失。
EPEMERAL_SEQUENTIAL:临时自动编号节点,ZNode节点编号会自动增加,但是会随Session消失而消失
简单来说,zookeeper就是直接在locks这个锁节点下,创建一个顺序节点,这个顺序节点有zk内部自行维护的一个节点序号。
比如说,第一个客户端来搞一个顺序节点,zk内部会给起个名字叫做:seq-00000000。然后第二个客户端来搞一个顺序节点,zk可能会起个名字叫做:seq-00000001。大家注意一下,最后一个数字都是依次递增的,从1开始逐次递增。zk会维护这个顺序。实现原理如下图所示:
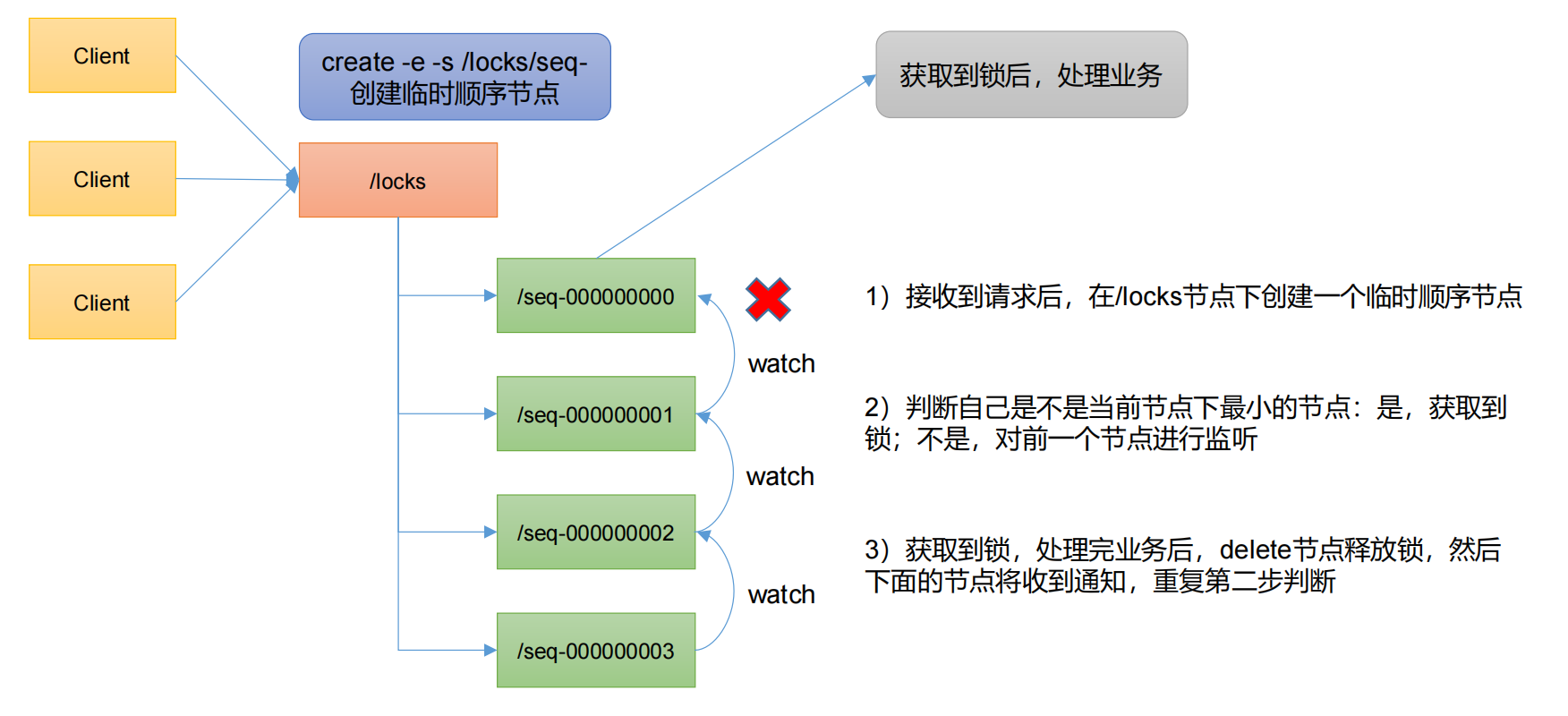
Apache Curator 是一个用于 Apache ZooKeeper 的 Java 客户端框架。ZooKeeper 是一个分布式协调服务,用于在分布式系统中进行协作和管理。Curator 提供了一组易于使用的API和工具,简化了与 ZooKeeper 的交互,同时提供了更高级别的抽象和功能。
Curator 的主要目标是简化分布式系统中的常见任务,例如选主(leader election)、分布式锁(distributed locking)、分布式队列(distributed queue)和缓存管理等。它提供了一些高级别的抽象,如分布式锁、分布式计数器、缓存等,使开发人员能够更轻松地构建可靠的分布式应用
接下来我们就看看Curator实现分布式锁的案例,首先肯定是先引入依赖:
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-client</artifactId>
<version>4.3.0</version>
</dependency>
代码示例,两个线程抢占一个锁:
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.locks.InterProcessLock;
import org.apache.curator.framework.recipes.locks.InterProcessMutex;
import org.apache.curator.retry.ExponentialBackoffRetry;
/**
* @author fjzheng
* @version 1.0
* @date 2023/10/9 16:45
*/
public class CuratorLock {
// 节点
private final String rootNode = "/locks";
// zookeeper server 列表
private final String connectString = "10.10.0.10:2181";
// connection 超时时间
private final int connectionTimeout = 2000;
// session 超时时间
private final int sessionTimeout = 2000;
public static void main(String[] args) {
new CuratorLock().test();
}
// 测试
private void test() {
// 创建分布式锁 1
final InterProcessLock lock1 = new
InterProcessMutex(getCuratorFramework(), rootNode);
// 创建分布式锁 2
final InterProcessLock lock2 = new
InterProcessMutex(getCuratorFramework(), rootNode);
new Thread(new Runnable() {
@Override
public void run() {
// 获取锁对象
try {
lock1.acquire();
System.out.println("线程 1 获取锁");
// 测试锁重入
lock1.acquire();
System.out.println("线程 1 再次获取锁");
Thread.sleep(5 * 1000);
lock1.release();
System.out.println("线程 1 释放锁");
lock1.release();
System.out.println("线程 1 再次释放锁");
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
// 获取锁对象
try {
lock2.acquire();
System.out.println("线程 2 获取锁");
// 测试锁重入
lock2.acquire();
System.out.println("线程 2 再次获取锁");
Thread.sleep(5 * 1000);
lock2.release();
System.out.println("线程 2 释放锁");
lock2.release();
System.out.println("线程 2 再次释放锁");
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
}
// 分布式锁初始化
public CuratorFramework getCuratorFramework (){
//重试策略,初试时间 3 秒,重试 3 次
RetryPolicy policy = new ExponentialBackoffRetry(3000, 3);
//通过工厂创建 Curator
CuratorFramework client =
CuratorFrameworkFactory.builder()
.connectString(connectString)
.connectionTimeoutMs(connectionTimeout)
.sessionTimeoutMs(sessionTimeout)
.retryPolicy(policy).build();
//开启连接
client.start();
System.out.println("zookeeper 初始化完成...");
return client;
}
}
运行结果如下:
zookeeper 初始化完成...
线程 2 获取锁
线程 2 再次获取锁
线程 2 释放锁
线程 2 再次释放锁
线程 1 获取锁
线程 1 再次获取锁
线程 1 释放锁
线程 1 再次释放锁
5.总结
Zookeeper在众多中间件广泛应用,可见其功能地位之重要性。所以我们需要认真掌握它。至此,行文结束,欢迎大家品读。









![2023年中国鸡蛋市场供需现状、市场规模及产品价格走势分析[图]](https://img-blog.csdnimg.cn/img_convert/f0f31525604669e6ac5336933bcbb06d.png)