LVGL-TLSF学前预备知识点
TLSF内存池管理结构示意图:
TLSF控制器支持对多内存池的管理,但LVGL只使用一个内存池
内存池存储结构示意图
+-------------------+
| lv_tlsf_t | - control_t TLSF分配器
+-------------------+
| Free Block 1 |
+-------------------+
| Used Block 1 |
+-------------------+
| Free Block 2 |
+-------------------+
| Used Block 2 |
+-------------------+
| Free Block 3 |
+-------------------+
| ... |
+-------------------+
| Sentinel Block | - 哨兵块
+-------------------+TLSF一二级索引表:
FL为一级索引,SL为二级索引
通常一级索引值都指的是2的指数级数,例如2^7这一级索引管理的是2^7 ~ 2^8范围内的内存块。
二级索引是在一级索引这个大范围下进一步细分各级内存块,细分程度称为二级颗粒度,颗粒度通常为2的指数级,例如颗粒度为5指的是将2^7 ~ 2^8范围内的内存块细分为32(2^5)级,每一级范围大小为2^7/2^5 = 2^2,这里只是举例2^7这个一级索引范围内,具体可以查看下表中详细描述。
在这里最核心的是计算一二级索引值,索引值通常为2的指数级。
TLSF一二级索引表
\SL 0 1 2 3 4 ... (MAXn = 2^(SL_INDEX_COUNT_LOG2-1))(二级颗粒度:SL_INDEX_COUNT_LOG2)
FL\-----------------------------------------------------------------------------------------------------
31|2^31+0*2^25 | 2^31+1*2^25 | 2^31+2*2^25 | 2^31+3*2^25 | 2^31+4*2^25 | 2^31+9*2^25 | 2^31+n*2^25 | 0000 0000 0000 0000B = 无空闲块
.| |
.| ... | ... | ... | ... | ... | ... | ... | ......
.| |
16|2^16+0*2^11 | 2^16+1*2^11 | 2^16+2*2^11 | 2^16+3*2^11 | 2^16+4*2^11 | 2^16+9*2^11 | 2^16+n*2^11 | 0000 0000 0000 0000B = 无空闲块
.| |
.| ... | ... | ... | ... | ... | ... | ... | ......
.| |
9| 512 | 528 | 544 | 560 | 576 | ... | 2^6+n*2^4 | 0100 0000 0000 0000B = 528-544 区间有空闲块
8| 256 | 264 | 272 | 280 | 288 | ... | 2^6+n*2^3 | 0001 0100 0000 0000B = 280-288 & 296-304 区间有空闲块
7| 128 | 132 | 136 | 140 | 144 | ... | 2^7+n*2^2 | 1100 0100 0000 0000B = 128-132 & 132-136 & 148-152 区间有空闲块
2^n| MAXn = FL_INDEX_MAX; MINn = FL_INDEX_SHIFT;(一级索引数量: FL_INDEX_COUNT = FL_INDEX_MAX - FL_INDEX_SHIFT + 1)
| Ex:when LV_MEM_SIZE == 48K
| FL_INDEX_MAX = 16
| FL_INDEX_SHIFT = ((SL_INDEX_COUNT_LOG2 = 5) + (ALIGN_SIZE_LOG2 = 2));
上表中:各级取值范围例似2^7+n*2^2式子中,2^7是该二级区间范围的起始值,
n*2^2表明各个区间,n最大为MAXn = (2^SL_INDEX_COUNT_LOG2)-1,
SL_INDEX_COUNT_LOG2为二级链表的颗粒度,既把二级整级范围划分为多少等分,其取值是一个经验值,32位MCU中通常取4/5,既16份/32份
以SL_INDEX_COUNT_LOG2 = 5为例,划分为32等份,一级索引2^7范围128-256,每份为128/32 = 4,既2^2
一级索引: fl_bitmap = fl_bitmap中的每个bit记录每级二级链表中是否有空闲块,1=对应二级列表中有空闲块,0=对应整个二级列表范围内都被使用
Ex:基于上述LV_MEM_SIZE = 48K时的参数举例,fl_bitmap = 00 0000 1010B
表明在2^8 & 2^9两个二级链表中有空闲块
二级索引: sl_bitmap[FL_INDEX_COUNT] = sl_bitmap[n]记录二级链表中哪个区间有空闲块, n的最大值MAXn = FL_INDEX_COUNT - 1, n = 0时sl_bitmap[0]表述2^FL_INDEX_SHIFT这一级
Ex:基于上述LV_MEM_SIZE = 48K时的参数举例,sl_bitmap[1] = 0000 0000 0000 0000 0000 0000 0010 0010B
表明在2^8这一级链表中有两个细分区间上有空闲块分别是528-544区间和592-608区间
根据内存块大小将内存块插入对应链表中,计算一二级索引Index(fl,sl):
1.计算内存块大小size的最高位1所在index
2.index 右移 FL_INDEX_SHIFT 既得一级链表索引
3.计算二级链表索引的公式: (((size - 2^fl)*2^SL_INDEX_COUNT_LOG2) / 2^fl) = (size - 2^fl)/(2^fl/2^SL_INDEX_COUNT_LOG2)、
= (size - 2^fl)/2(fl-SL_INDEX_COUNT_LOG2)
创建并初始化动态内存池
宏设置及LVGL初始化内置动态内存流程
lv_init() -> lv_mem_init_builtin() ->
/* LVGL动态内存池:分配一个大数组来存储动态分配的数据
* #define LV_USE_BUILTIN_MALLOC 1
* #define LV_MEM_SIZE (48U * 1024U)
* #define LV_ATTRIBUTE_LARGE_RAM_ARRAY __attribute__((section(".lvgl.mem")))
* #define MEM_UNIT uint32_t
* */
static LV_ATTRIBUTE_LARGE_RAM_ARRAY MEM_UNIT work_mem_int[LV_MEM_SIZE / sizeof(MEM_UNIT)];
memset(work_mem_int, 0, sizeof(work_mem_int));
static lv_tlsf_t tlsf = lv_tlsf_create_with_pool((void *)work_mem_int, LV_MEM_SIZE);
在lv_conf.h中使能了宏 LV_USE_BUILTIN_MALLOC 后,就可以使用LVGL内置动态内存了,注意必须要设置好宏 LV_MEM_SIZE ,其必须大于2kb。
LVGL-tlsf实现在lv_tlsf.c/lv_tlsf.h文件中
创建内存池
初始创建内存池,根据源码分析,大致分两步:
一、创建TLSF管理器也叫分配器并初始化(control_t),TLSF支持多内存池管理,但LVGL只使用一个内存池;
二、创建并初始化内存池管理器或叫块头(block_header_t),将块头以节点的形式插入TLSF管理器链表中,并更新一二级索引。
创建TLSF管理器
TLSF管理的主题就是下面结构体,其所占内存大小由 FL_INDEX_COUNT、SL_INDEX_COUNT 决定,这两值的具体定义详见下述枚举注释信息。
enum tlsf_public {
/*
* 块大小的线性细分数量的Log2值即(2^5=32bits)。更大的值在控制结构中需要更多的内存,典型的值4或5
*/
/*
`SL_INDEX_COUNT_LOG2` 表示二级索引的数量的对数。它的值决定了 TLSF 内存池中二级索引的数量。
在 TLSF 内存池中,内存块的大小是按照对齐大小递增的。每个一级索引 `fl` 对应一定范围的内存块大小,而每个二级索引 `sl` 则对应更细粒度的内存块大小范围。
二级索引的数量决定了内存块大小的粒度。较大的二级索引数量可以提供更细粒度的内存块大小范围,但会增加内存池的管理开销。较小的二级索引数量可以减少管理开销,但会限制内存块大小的粒度。
`SL_INDEX_COUNT_LOG2` 的值是根据具体的应用需求和性能考虑来设置的。一般来说,它的值应该选择一个合理的范围,以满足应用对内存块大小的需求,并在内存池的管理开销和性能之间做出权衡。
例如,如果 `SL_INDEX_COUNT_LOG2` 的值为 4,那么二级索引的数量就是 2^4 = 16。这意味着 TLSF 内存池将支持 16 种不同大小的内存块范围,从而提供更细粒度的内存块大小选择。
*/
SL_INDEX_COUNT_LOG2 = 5,
};
/* Private constants: do not modify. */
/**
* 常量,不得修改
* 这些枚举各成员的定义和计算是为了在TLSF分配器中对内存块进行分类和管理。
* 通过这些成员的值,分配器可以根据内存块的大小快速将其分配到相应的索引中,以提高内存分配的效率和利用率。
***/
enum tlsf_private {
/**
* 这个成员表示内存块的对齐大小的对数值。
* 在64位系统中,内存块的对齐大小为8字节,所以ALIGN_SIZE_LOG2等于3;
* 在32位系统中,内存块的对齐大小为4字节,所以ALIGN_SIZE_LOG2等于2
**/
#if defined (TLSF_64BIT)
/* All allocation sizes and addresses are aligned to 8 bytes. */
ALIGN_SIZE_LOG2 = 3,
#else
/* All allocation sizes and addresses are aligned to 4 bytes. */
/*所有分配大小和地址都对齐为4字节*/
ALIGN_SIZE_LOG2 = 2,
#endif
/*这个成员表示内存块的对齐大小。它的值等于2的ALIGN_SIZE_LOG2次方,也就是8字节或4字节,取决于系统位数,符合物理内存的擦写实际*/
ALIGN_SIZE = (1 << ALIGN_SIZE_LOG2),
/**
* 我们支持的内存分配大小最大为(1 << FL_INDEX_MAX)位。
* 然而,由于我们按线性方式细分第二级列表,并且我们的最小大小粒度为4字节,
* 因此对于小于SL_INDEX_COUNT * 4或(1 << (SL_INDEX_COUNT_LOG2 + 2))字节的大小,创建第一级列表是没有意义的,
* 因为我们将尝试将大小范围分割为比可用槽位更多的槽位。
* 相反,我们计算出最小阈值大小,并将所有小于该大小的块放入第0个第一级列表中。
**/
#if defined (TLSF_MAX_POOL_SIZE)
/**
* 这个成员表示最大的一级索引值。它决定了分配器能够处理的最大内存块大小。
* 在TLSF_MAX_POOL_SIZE被定义时,FL_INDEX_MAX等于TLSF_MAX_POOL_SIZE的对数(以2为底)的上限;
* 在64位系统中,FL_INDEX_MAX <= 32;在32位系统中,FL_INDEX_MAX <= 30。
*
**/
FL_INDEX_MAX = TLSF_LOG2_CEIL(TLSF_MAX_POOL_SIZE),
#elif defined (TLSF_64BIT)
/*
** TODO: We can increase this to support larger sizes, at the expense
** of more overhead in the TLSF structure.
*/
FL_INDEX_MAX = 32,
#else
FL_INDEX_MAX = 30,
#endif
/**
* 这个成员表示二级索引的数量。
* 二级索引用于将内存块按照大小进行分类和管理。
* SL_INDEX_COUNT的值等于2的SL_INDEX_COUNT_LOG2次方。
**/
SL_INDEX_COUNT = (1 << SL_INDEX_COUNT_LOG2),
/**
* 这个成员表示一级索引的偏移量。
* 用于通过内存块大小换算对应的一级索引时右移偏移
* 假设 SL_INDEX_COUNT_LOG2 的值为 5,ALIGN_SIZE_LOG2 的值为 2,那么 FL_INDEX_SHIFT 的值将为 6。
* 这意味着,通过将一个内存块的大小右移 7 位,就可以得到对应的一级索引 fl。
* 例如,一个大小为 128 字节的内存块,右移 7 位后得到 1,表示它属于一级索引为 1 的范围内。
**/
FL_INDEX_SHIFT = (SL_INDEX_COUNT_LOG2 + ALIGN_SIZE_LOG2),
/**
* 这个成员表示一级索引的数量。
* 一级索引用于将内存块按照大小进行分类和管理。
* FL_INDEX_COUNT的值等于FL_INDEX_MAX减去FL_INDEX_SHIFT再加上1。
**/
FL_INDEX_COUNT = (FL_INDEX_MAX - FL_INDEX_SHIFT + 1),
/**
* 这个成员表示最小的内存块大小。
* 它的值等于2的FL_INDEX_SHIFT次方,也就是一级索引对应的内存块大小
**/
SMALL_BLOCK_SIZE = (1 << FL_INDEX_SHIFT),
};
typedef struct control_t {
/* Empty lists point at this block to indicate they are free. */
/**
* 这是一个特殊的内存块,用于表示空闲链表为空。
* 当一个链表为空时,它的指针会指向block_null。
* 同理,通过检查链表的指针是否等于block_null,可以判断链表是否为空
***/
block_header_t block_null;
/* Bitmaps for free lists. */
/**
* 这是一个位图,用于记录每个一级索引对应的二级索引链表是否为空。
* 位图的每一位表示一个二级索引链表,位图的第n位为1表示第n个二级索引链表为非空,为0表示第n个二级索引链表为空
**/
unsigned int fl_bitmap;
/**
* 这个数组用于记录每个一级索引对应的二级索引链表中是否存在空闲内存块。
* 数组的每个元素是一个位图,表示一个一级索引对应的二级索引链表中的每个内存块是否为空闲状态。
* 位图的每一位表示一个内存块,位图的第n位为1表示第n个内存块为非空闲状态,为0表示第n个内存块为空闲状态。
**/
unsigned int sl_bitmap[FL_INDEX_COUNT];
/* 二级链表的指针数组,空闲链表的头 Head of free lists.
* 这个二维数组,用于存储每个一级索引对应的二级索引链表的头指针。
* 数组的第一维表示一级索引,第二维表示二级索引。
* 每个元素是一个指针,指向对应的二级索引链表的头节点。
* 通过这个数组,可以快速找到每个一级索引对应的二级索引链表的头节点,从而可以快速访问和操作链表
**/
block_header_t * blocks[FL_INDEX_COUNT][SL_INDEX_COUNT];
} control_t;初始化TLSF控制器中一二级索引及各级链表
block_null.next_free = block_null;
block_null.prev_free = block_null;
一、一二级索引清零,fl_bitmap = 0;sl_bitmap[i] = 0;
二、二级索引中,各级内存块链表起始节点指向空,blocks[i][j] = block_null;
static void control_constructor(control_t * control)
{
int i, j;
control->block_null.next_free = &control->block_null;
control->block_null.prev_free = &control->block_null;
/*一级索引*/
control->fl_bitmap = 0;
/*二级索引*/
for(i = 0; i < FL_INDEX_COUNT; ++i) {
control->sl_bitmap[i] = 0;
for(j = 0; j < SL_INDEX_COUNT; ++j) {
/*二级索引各级内存块链表起始节点*/
control->blocks[i][j] = &control->block_null;
}
}
}将内存池添加到TLSF控制器中
添加的流程概述
/*为TLSF分配器添加内存池*/
/**
* tlsf: 分配器(实体存储在内存块的开头位置),可以管理多个内存池
* mem: 指向内存块数据存储区域的起始地址
* bytes: 数据存储区大小
**/
lv_pool_t lv_tlsf_add_pool(lv_tlsf_t tlsf, void * mem, size_t bytes)
主要由上述接口实现添加操作,主要步骤是,在块头位置创建块管理器并初始化,将其作为链表节点插入到TLSF管理器二级索引对应的链表中,更新一二级索引。
LVGL-TLSF算法中,在初始化时将一块指定位置的连续内存块声明成一个数组,并作为一个主空闲块放到链表中,并且创建一个大小为0的哨兵块放到最后,用于检索时判断预警。
内存池初始化后的动态存储区域结构示意图
+-------------------+
| lv_tlsf_t | - control_t TLSF分配器
+-------------------+
| Block Header | - block_header_t 块头
+-------------------+
| Main Free Block| - 主空闲块
+-------------------+
| Block Header | - block_header_t 块头
+-------------------+
| Sentinel Block | - 哨兵块 size = 0
+-------------------+具体的流程步骤
1、计算内存池的管理开销 pool_overhead,包括一个空闲块块头和一个哨兵块块头,共pool_overhead = 2 * block_header_overhead
2、计算主空闲内存块大小 pool_bytes,数据存储区大小减去内存池的管理开销,即pool_bytes = bytes - pool_overhead
3、创建主空闲内存块
1、其块管理(block_header_t * block)实体在数据存储区的头部
注意 block 的起始位置,在TLSF中,空闲内存块的块管理结构比已用块管理结构多一个 prev_phys_block 字段,
这个字段实际是处在上一个内存块的末尾空间的,之所以放在 block_header_t 结构体中,是为了简化实现,
因此这里 block 的实体起始地址应该是 block = mem - block_header_overhead。
2、初始设置块大小信息, block->size = pool_bytes | 0x11;
注意这里位运算或一个0x11,是因为内存块size通常是字节对齐,32位MCU环境下,通常是4字节对齐,
所以TLSF将size的最后两位用于存储内存块的相关信息(上一块是否空闲|本块是否已使用)。
3、初始设置块使用状态,初始设为空闲状态,block->size |= 1<<0;
4、初始设置内存卡前一块内存的使用状态,设为已使用状态,block->size &= ~1<<1;
4、将内存块插入TLSF内存池中
1、根据内存块的大小计算一级索引FL和二级索引SL

1.计算block->size 的最高非零位index
在另一篇文章中有计算变量最高非零位的宏实现方式源码原理分析,参考:
LVGL-TLSF内存管理算法-TLSF_LOG2_CEIL(n)宏详解:计算内存块所属内存池类别-CSDN博客
2.根据index计算二级索引
根据size的最高非零位index计算二级索引值(2的指数):
我们可以根据文章开头的一二级索引表总结除一个根据index计算二级索引值的公式:
上式中:
Size: 内存块大小
SL_INDEX_COUNT_LOG2:二级索引的颗粒度,2的指数,32位环境下通常为4或5,即颗粒度划分为16级或32级
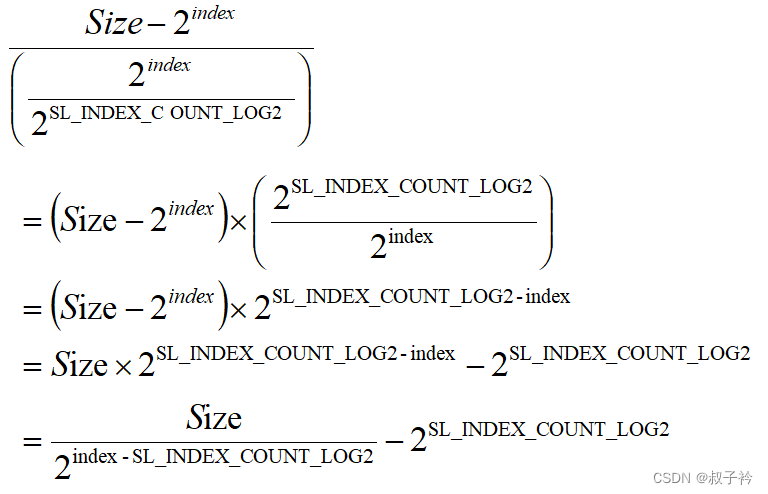
index:一级索引未偏移值,即size的最高非零位index
Size - 2^index:限定在一级索引级别范围内
2^index/2^SL_INDEX_COUNT_LOG2 :计算二级颗粒度
上式中简化目标是为了减少代码运算量,简化后仅通过位移和位运算既可得到结果:
// size >> (fl - SL_INDEX_COUNT_LOG2) 通过右移做2的整数幂除法运算 // ^ (1 << SL_INDEX_COUNT_LOG2) 通过异或2的整数幂减法运算 sl = size >> (fl - SL_INDEX_COUNT_LOG2) ^ (1 << SL_INDEX_COUNT_LOG2);
3.偏移index计算一级索引
size的最高非零整数位index,
通常TLSF的一级索引不会从2^0起始,这不利于节约RAM,而是会设置一个起始等级,将所有小于这个起始等级的内存块都统一放到起始等级中进行管理,
例如,小于二级索引颗粒度 SL_INDEX_COUNT_LOG2 的内存块,没必要单独设置等级,这将导致计算二级索引时出问题,
通常我们将这个起始等级设为二级颗粒度加字节对齐单位的和,这有利于通过内存块大小计算其所属一级索引,如下:
/** * 这个成员表示一级索引的偏移量。 * 用于通过内存块大小换算对应的一级索引时右移偏移 * 假设 SL_INDEX_COUNT_LOG2 的值为 5,ALIGN_SIZE_LOG2 的值为 2,那么 FL_INDEX_SHIFT 的值将为 6。 * 这意味着,通过将一个内存块的大小右移 7 位,就可以得到对应的一级索引 fl。 * 例如,一个大小为 128 字节的内存块,右移 7 位后得到 1,表示它属于一级索引为 1 的范围内。 **/ FL_INDEX_SHIFT = (SL_INDEX_COUNT_LOG2 + ALIGN_SIZE_LOG2),
具体源码及公式分析如下:
/*根据内存块的大小快速定位到对应的内存块列表和索引*/
static void mapping_insert(size_t size, int * fli, int * sli)
{
int fl, sl;
if(size < SMALL_BLOCK_SIZE) {
/*小块内存,将其存储在第一个列表中 Store small blocks in first list. */
fl = 0;
sl = tlsf_cast(int, size) / (SMALL_BLOCK_SIZE / SL_INDEX_COUNT); //计算该小块内存在二级列表中的位置
}
else {
/**
* Ex: 1011 1010 1011 1100B
* |->最高非零位索引 = 15
*/
fl = tlsf_fls_sizet(size);//将size转换为对应的最高非零位索引
/**
* 计算sl的公式可以根据文件头的表格总结得出
* 设: r = size; sli = SL_INDEX_COUNT_LOG2;
* 简化:(((size - 2^fl)*2^SL_INDEX_COUNT_LOG2) / 2^fl)
* = (r-2^fl)*2^sli/2^fl
* = (r-2^fl)*2^(sli -fl)
* = r*2^(sli-fl) - 2^sli
* = r*2^-(fl-sli) - 2^sli
* = r*?^(fl-sli) - 2^sli
* = r/2^(sli-fl) - 2^sli
* 根据上述公式理论得出直视经验方法:
* Ex: 1011 1010 1011 1100B
* ||| ||->这5位就是sl值(SL_INDEX_COUNT_LOG2=5)
* size >> (fl - SL_INDEX_COUNT_LOG2) 2的整数幂的除法运算可以通过右移
* ^ (1 << SL_INDEX_COUNT_LOG2) 减法运算
*/
sl = tlsf_cast(int, size >> (fl - SL_INDEX_COUNT_LOG2)) ^ (1 << SL_INDEX_COUNT_LOG2);// tlsf_cast: 格式转换
/**
* fl偏移,索引偏移之后得到对应的map映射位置
* Ex: fl = 15, FL_INDEX_SHIFT = 7
* fl真实最高非零位为15,像右偏移7位
* */
fl -= (FL_INDEX_SHIFT - 1);
}
*fli = fl;
*sli = sl;
}2、根据一二级索引,将block作为节点插入对应级别的链表,做为头节点,并更新一二级索引表
1.取出FL & SL对应链表的首节点,block_header_t * current = control->blocks[fl][sl];
2.将当前block作为首节点插入链表,即将 current 的前节点指向 block,将 block 后向节点指向 current ,将 block 的前向节点指向空,再更新FL & SL对应链表的首节点,即 control->blocks[fl][sl] = block;
3.更新一二级索引表位图
具体源码及公式分析如下:
/**
* 将空闲内存块插入空闲块链表
* control:TLSF算法的控制结构体指针。
* block:要插入的空闲块的头部指针。
* fl:一级列表的索引,用于确定插入的空闲块应该放在哪个一级列表中。
* sl:二级列表的索引,用于确定插入的空闲块应该放在哪个二级列表中。
* */
static void insert_free_block(control_t * control, block_header_t * block, int fl, int sl)
{
/**
* 取出fl、sl索引对应链表的当前节点或称首节点,
* Ex: control->blocks[0][1]对应的是一级索引2^7,二级索引2^7 + 1*2^7/2^5 = [132 - 136]区间范围的二级链表当前指向节点
* 这里一级索引偏移 FL_INDEX_SHIFT=7,二级颗粒度 SL_INDEX_COUNT_LOG2=5
* current 是链表第一个节点,它前向节点prev_free指向空节点
* */
block_header_t * current = control->blocks[fl][sl];
tlsf_assert(current && "free list cannot have a null entry");
tlsf_assert(block && "cannot insert a null entry into the free list");
/**
* 这里将block插入到current节点前面,
* 所以block->next_free指向current,prev_free指向空
* 再将 current->prev_free指向block既可
*/
block->next_free = current;
block->prev_free = &control->block_null;
current->prev_free = block;
tlsf_assert(block_to_ptr(block) == align_ptr(block_to_ptr(block), ALIGN_SIZE)
&& "block not aligned properly");
/*
** Insert the new block at the head of the list, and mark the first-
** and second-level bitmaps appropriately.
*/
/**
* 把block节点记录到控制块中
*/
control->blocks[fl][sl] = block;// 将要插入的空闲块设置为当前列表中的第一个空闲块
control->fl_bitmap |= (1U << fl);// 更新一级列表和二级列表的位图
control->sl_bitmap[fl] |= (1U << sl);
}参考文档:
TLSF Github官方库
TLSF官方文档库
TLSF官网
DSA之TLSF内存分配器源码分析 - 知乎 (zhihu.com)
实时系统动态内存算法分析dsa(二)——TLSF代码分析_lv tlsf-CSDN博客
TLSF内存分配英文文档




![哈夫曼树及哈夫曼编码详解及代码实现[C/C++]](https://img-blog.csdnimg.cn/df345d39818a4ddc8814afe10b52b4c3.png)



![ROS仿真软件Turtlebot-Gazebo的安装使用以及错误处理[机器人避障]](https://img-blog.csdnimg.cn/3056eb60d18f439286f287936dcd6ae1.png)